Olá novamente!
Em dezembro, começaremos o treinamento para o próximo
grupo de cientistas de dados , para que haja mais e mais lições abertas e outras atividades. Por exemplo, outro dia, um webinar foi realizado com o nome longo "Feature Engineering no exemplo do conjunto de dados clássico do Titanic". Foi conduzido por
Alexander Sizov , um desenvolvedor experiente, Ph.D., especialista em Machine / Deep Learning e participante de vários projetos comerciais internacionais relacionados à inteligência artificial e análise de dados.
Uma lição aberta levou cerca de uma hora e meia. Durante o webinar, o professor falou sobre a seleção de recursos, a transformação de dados de origem (codificação, dimensionamento), a definição de parâmetros, o treinamento do modelo e muito mais. Durante a lição, os participantes receberam um caderno Jupyter. Para o trabalho, usamos dados abertos da plataforma
Kaggle (o conjunto de dados clássico sobre o Titanic, a partir do qual muitos começam a se familiarizar com a Ciência de Dados). Abaixo, oferecemos um vídeo e uma transcrição do evento passado, e
aqui você pode pegar a apresentação e os códigos em um laptop Jupiter.
Seleção de Recursos
O tema foi escolhido, embora clássico, mas ainda um pouco sombrio. Em particular, foi necessário resolver o problema de classificação binária e prever a partir dos dados disponíveis se o passageiro sobreviverá ou não. Os dados em si foram divididos em duas amostras de treinamento e teste. A variável chave é Survival (sobreviveu / não sobreviveu; 0 = Não, 1 = Sim).
Dados de treinamento de entrada:
- classe de ingresso
- idade e sexo do passageiro;
- estado civil (se há parentes a bordo);
- preço do bilhete;
- número da cabine;
- porto de embarque.
Como você pode ver, os tipos de variáveis são diferentes: numérico, texto. Nesse caleidoscópio, foi necessário formar um conjunto de dados para o próximo treinamento do modelo.
Resumimos:
- train.csv - conjunto de treinamento - conjunto de dados de treinamento. A resposta é conhecida neles - sobrevivência - um sinal binário 0 (não sobreviveu) / 1 (sobreviveu);
- test.csv - conjunto de teste - conjunto de dados de teste. A resposta é desconhecida. Esta é uma amostra a ser enviada à plataforma kaggle para calcular a métrica de qualidade do modelo;
- gender_submission.csv é um exemplo do formato dos dados a serem enviados ao kaggle.
Algoritmo de trabalho
- O trabalho ocorreu em etapas:
- Análise de dados de train.csv.
- Manipulação de valores ausentes.
- Dimensionamento.
- Codificação de recursos categóricos.
- Construindo um modelo e selecionando parâmetros, escolhendo o melhor modelo nos dados convertidos em train.csv.
- Fixação e modelo do método de transformação.
- Aplicando as mesmas conversões ao test.csv usando o pipeline.
- Aplicação do modelo em test.csv.
- Salvando o arquivo de resultados do aplicativo no mesmo formato que em gender_submission.csv.
- Enviando resultados para a plataforma kaggle.
A parte prática do webinarA primeira coisa que precisava ser feita foi ler o conjunto de dados e exibir nossos dados na tela:
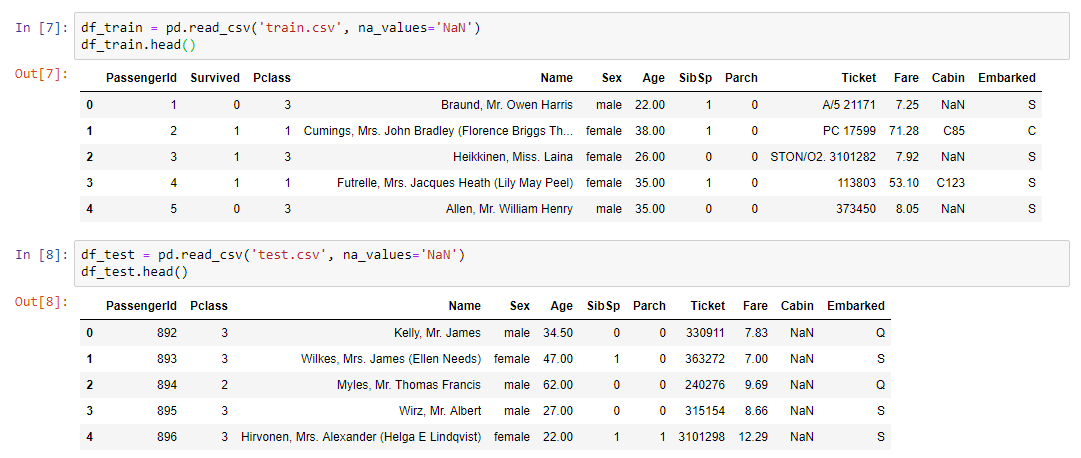
Para análise dos dados, foi utilizada uma biblioteca de perfis pouco conhecida, mas bastante útil:
pandas_profiling.ProfileReport(df_train)Mais sobre criação de perfilEsta biblioteca faz tudo o que pode ser feito a priori sem conhecer os detalhes sobre os dados. Por exemplo, exiba estatísticas sobre os dados (quantas variáveis e que tipo são, quantas linhas, valores ausentes etc.). Além disso, estatísticas separadas para cada variável são fornecidas com um mínimo e um máximo, um gráfico de distribuição e outros parâmetros.
Como você sabe, para criar um bom modelo, você precisa se aprofundar no processo que estamos tentando simular e entender quais são os principais atributos. Além disso, longe de sempre em nossos dados, há tudo o que é necessário e, mais precisamente, quase nunca neles há tudo o que é necessário, determinando e determinando completamente nosso processo. Como regra, sempre precisamos combinar algo, talvez adicionar recursos adicionais que não são representados no conjunto de dados (por exemplo, a previsão do tempo). É para entender o processo que precisamos da análise de dados, o que pode ser feito usando a biblioteca de criação de perfil.
Valores em faltaO próximo passo é resolver o problema dos valores ausentes, porque na maioria dos casos os dados não são completamente preenchidos.
As seguintes soluções estão disponíveis para esse problema:
- excluir linhas com valores ausentes (lembre-se de que você pode perder alguns valores importantes);
- excluir um sinal (relevante se houver muito poucos dados nele);
- substitua valores ausentes por outra coisa (mediana, média ...).
Um exemplo de uma conversão simples usando o método fillna, que atribui os valores da variável mediana apenas às células que não são preenchidas:

Além disso, o professor mostrou exemplos de uso do Imputer e do pipeline.
Escala de recursosA operação do modelo e a decisão final dependem da escala dos recursos. O fato é que não é fato que qualquer recurso que tenha uma escala maior seja mais importante do que um recurso que tenha uma escala menor. É por isso que o modelo precisa enviar recursos dimensionados de forma idêntica, ou seja, tendo o mesmo peso para o modelo.
Existem diferentes técnicas de dimensionamento, no entanto, o formato da lição aberta nos permitiu considerar apenas duas delas em mais detalhes:
 Combinações de recursos
Combinações de recursosCombinações de recursos existentes usando operações aritméticas (soma, multiplicação, divisão) permitem obter qualquer recurso que torne o modelo mais eficiente. Isso nem sempre é bem sucedido e não sabemos qual combinação dará o efeito desejado, mas a prática mostra que faz sentido tentar. É conveniente aplicar transformações de recursos usando o pipeline.
CodificaçãoPortanto, temos dados de diferentes tipos: numéricos e de texto. Atualmente, a maioria dos modelos no mercado não pode funcionar com dados de texto. Como resultado, todos os sinais categóricos (textuais) devem ser convertidos em uma representação numérica, para a qual a codificação é usada.
Codificação de etiquetas . Este é um mecanismo implementado na estrutura de muitas bibliotecas que podem ser chamadas e aplicadas:

A codificação de etiqueta atribui um identificador exclusivo a cada valor exclusivo. Menos - introduzimos a ordem em uma determinada variável que não foi ordenada, o que não é bom.
OneHotEncoder. Os valores exclusivos da variável de texto são expandidos na forma de colunas, que são adicionadas aos dados de origem, em que cada coluna é uma variável binária na forma de 0 e 1. Essa abordagem não possui deficiências na codificação da etiqueta, mas tem seu menos: se houver muitos valores exclusivos, adicionamos muitas colunas e, em alguns casos, o método simplesmente não é aplicável (o conjunto de dados cresce demais).
Modelo de treinamentoDepois de executar as etapas acima, um pipeline final é compilado com um conjunto de todas as operações necessárias. Agora basta pegar o conjunto de dados de origem e aplicar o pipeline resultante a esses dados usando a operação fit_transform:
x_train = vec.fit_transform(df_train)Como resultado, obtemos o conjunto de dados x_train, que está pronto para uso no modelo. A única coisa a fazer é separar o valor da nossa variável de destino para que possamos realizar o treinamento.
Em seguida, selecione o modelo. Como parte do webinar, o professor propôs uma regressão logística simples. O modelo foi treinado usando a operação de ajuste, resultando em um modelo na forma de regressão logística com certos parâmetros:
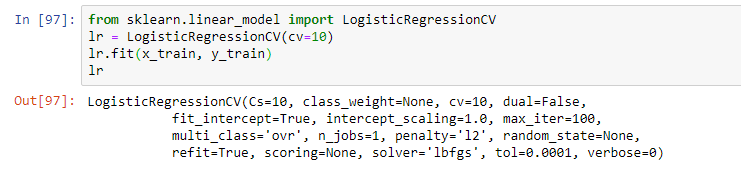
No entanto, na prática, geralmente são usados vários modelos que parecem ser os mais eficazes. E a solução final geralmente é uma combinação desses modelos usando técnicas de empilhamento e outras abordagens para montar modelos (usando vários modelos no mesmo modelo híbrido).
Após o treinamento, o modelo pode ser aplicado aos dados de teste, avaliando sua qualidade na estrutura de algumas métricas. No nosso caso, a qualidade dentro do precision_score foi de 0,8:

Isso significa que, nos dados obtidos, a variável é prevista corretamente em 80% dos casos. Após receber os resultados do treinamento, podemos melhorar o modelo (se a precisão não for satisfatória) ou prosseguir diretamente para a previsão.
Este foi o tópico principal da lição, mas o professor falou com mais detalhes sobre os recursos do modelo em diferentes tarefas e respondeu a perguntas da platéia. Portanto, se você não quer perder nada, assista ao seminário on-line completo se estiver interessado neste tópico.
Como sempre, estamos aguardando seus comentários e perguntas que você pode deixar aqui ou perguntar a
Alexander , indo até ele em um
dia aberto.