Vamos criar um agente de aprendizado de reforço de protótipo (RL) que domine a habilidade de negociação.
Dado que a implementação do protótipo funciona na linguagem R, incentivo os usuários e programadores a se aproximarem das idéias apresentadas neste artigo.
Esta é uma tradução do meu artigo em inglês:
Can Reforcement Learning Trade Stock? Implementação em R.Quero alertar os caçadores de código de que, nesta nota, existe apenas um código para uma rede neural adaptada para R.Se não me distingui em russo, aponte os erros (o texto foi preparado com a ajuda de um tradutor automático).
Introdução ao problema
Aconselho que você comece a mergulhar no tópico deste artigo:
DeepMindEle apresenta a idéia de usar a Deep Q-Network (DQN) para aproximar uma função de valor crítica nos processos de tomada de decisão de Markov.
Também recomendo aprofundar a matemática usando a pré-impressão deste livro de Richard S. Sutton e Andrew J. Barto:
Aprendizagem por ReforçoA seguir, apresentarei uma versão estendida do DQN original, que inclui mais idéias que ajudam o algoritmo a convergir de maneira rápida e eficiente, a saber:
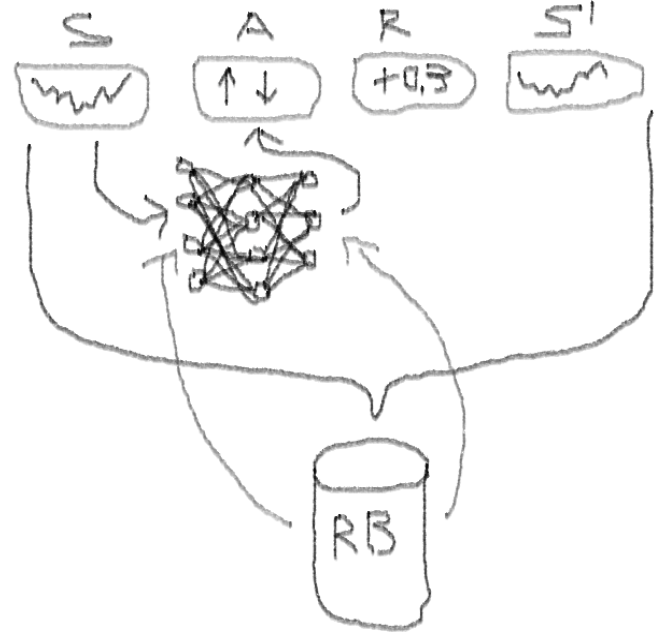
NN de duelo profundo profundo com seleção prioritária no buffer de reprodução da experiência.
O que torna essa abordagem melhor do que o DQN clássico?
- Duplo: existem duas redes, uma das quais é treinada e a outra avalia os seguintes valores de Q
- Duelo: Existem neurônios que claramente valorizam e beneficiam
- Barulhento: existem matrizes de ruído aplicadas aos pesos das camadas intermediárias, onde os desvios médios e padrão são pesos treinados
- Prioridade da amostragem: os lotes de observação do buffer de reprodução contêm exemplos, por causa dos quais o treinamento anterior de funções levou a grandes resíduos que podem ser armazenados na matriz auxiliar.
Bem, e o comércio realizado pelo agente DQN? Este é um tópico interessante como tal.
Existem razões pelas quais isso é interessante:
- Liberdade absoluta de escolha de representações de status, ações, prêmios e arquitetura da NN. Você pode enriquecer o espaço de entrada com tudo o que considerar digno de experimentar, desde notícias a outras ações e índices.
- A correspondência da lógica de negociação com a lógica de aprendizado por reforço é que: o agente executa ações discretas (ou contínuas), raramente é recompensado (após o fechamento da transação ou o prazo expirar), o ambiente é parcialmente observável e pode conter informações sobre as próximas etapas, a negociação é um jogo episódico.
- Você pode comparar os resultados do DQN com vários benchmarks, como índices e sistemas técnicos de negociação.
- O agente pode aprender continuamente novas informações e, assim, adaptar-se às novas regras do jogo.
Para não esticar o material, observe o código deste NN, que quero compartilhar, pois essa é uma das partes misteriosas de todo o projeto.
Código R para uma rede neural de valor usando Keras para criar nosso agente RL
Eu usei esta fonte para adaptar o código Python para a parte de ruído da rede:
github repoEssa rede neural é assim:
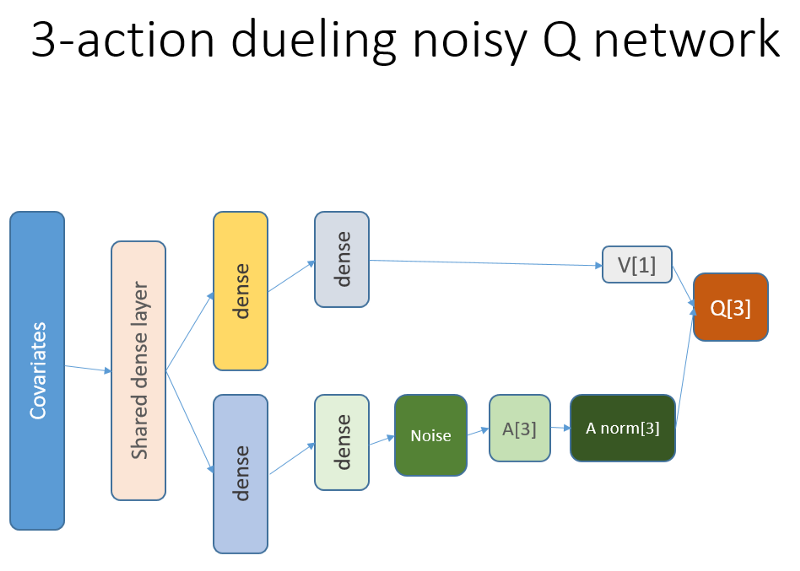
Lembre-se de que na arquitetura de duelo usamos igualdade (equação 1):
Q = A '+ V, onde
A '= A - média (A);
Q = valor da ação do estado;
V = valor do estado;
A = vantagem.
Outras variáveis no código falam por si. Além disso, essa arquitetura é boa apenas para uma tarefa específica, portanto, não a tome como garantida.
O restante do código provavelmente será genérico o suficiente para publicação, e será interessante para o programador escrever você mesmo.
E agora - os experimentos. Os testes do trabalho do agente foram realizados em uma caixa de areia, longe das realidades da negociação em um mercado ao vivo, com um corretor real.
Fase I
Executamos nosso agente em um conjunto de dados sintético. Nosso custo de transação é de 0,5:
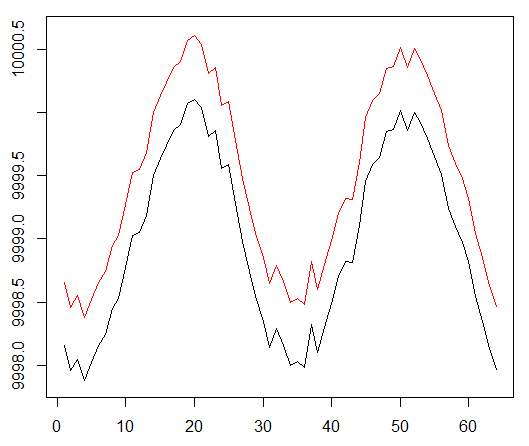
O resultado é excelente. A recompensa episódica média máxima neste experimento
deve ser 1,5.
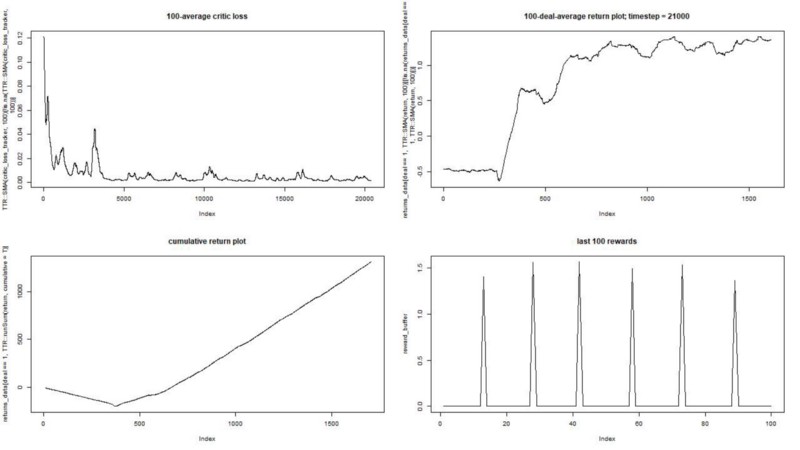
Vemos: perda de críticas (a chamada rede de valores na abordagem ator-crítico), recompensa média por um episódio, recompensa acumulada, amostra de recompensas recentes.
Fase II
Ensinamos a nosso agente um símbolo de ações escolhido arbitrariamente que demonstra um comportamento interessante: um início plano, rápido crescimento no meio e um final sombrio. Em nosso kit de treinamento, cerca de 4300 dias. O custo da transação é definido em 0,1 dólar (propositadamente baixo); A recompensa é lucro / perda em USD após o fechamento de um acordo para compra / venda de 1,0 ações.
Fonte:
finance.yahoo.com/quote/algn?ltr=1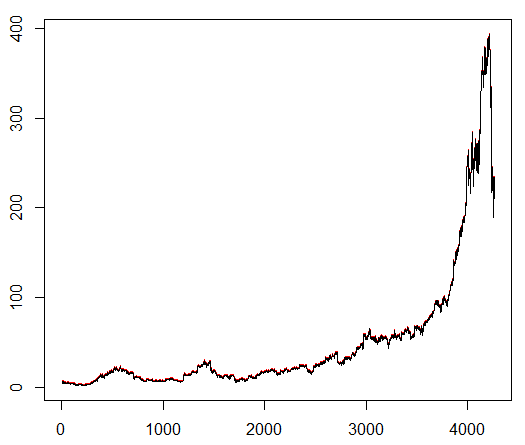 NASDAQ: ALGN
NASDAQ: ALGNApós definir alguns parâmetros (deixando a arquitetura NN a mesma), chegamos ao seguinte resultado:

Acabou não sendo ruim, pois no final o agente aprendeu a lucrar pressionando três botões no console.
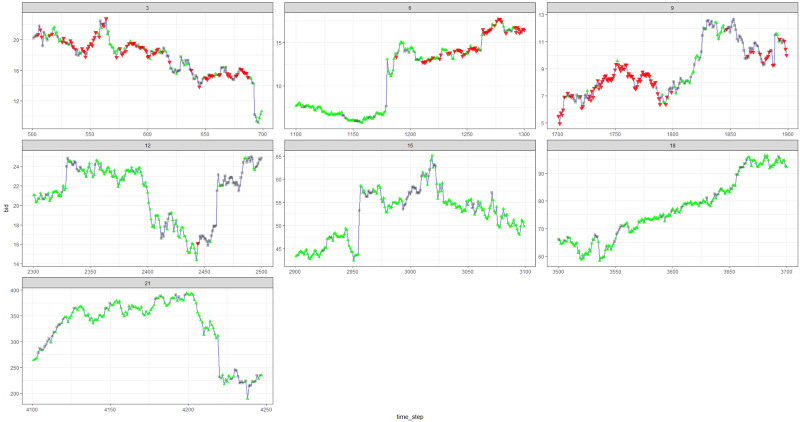 marcador vermelho = vender, marcador verde = comprar, marcador cinza = não fazer nada.
marcador vermelho = vender, marcador verde = comprar, marcador cinza = não fazer nada.Observe que, no auge, a recompensa média por episódio excedeu o valor realista da transação que pode ser encontrado em negociações reais.
É uma pena que as ações estejam caindo como loucas devido a más notícias ...
Observações finais
Negociar com a RL não é apenas difícil, mas também útil. Quando seu robô faz isso melhor do que você, é hora de gastar tempo pessoal para obter educação e saúde.
Espero que tenha sido uma viagem interessante para você. Se você gostou desta história, acene com a mão. Se houver muito interesse, posso continuar e mostrar como os métodos de gradiente de política funcionam usando a linguagem R e a API Keras.
Também quero agradecer aos meus amigos que estão interessados em redes neurais por seus conselhos.
Se você ainda tiver dúvidas, eu estou sempre aqui.