Trollagem matemática é o que eu vou falar. Esses não são alguns truques de hackers da moda; é uma expressão artística, uma tecnologia inteligente e engraçada para que as pessoas o considerem um idiota. Agora vou verificar se meu relatório está pronto para ser exibido na tela. Tudo parece estar indo bem, para que eu possa me apresentar.

Meu nome é Frank Tu, soletrado frank ^ 2 e @franksquared no Twitter, porque o Twitter também possui algum tipo de spammer chamado "frank 2". Tentei aplicar a engenharia social a eles para que eles excluíssem sua conta, porque tecnicamente é spam e tenho o direito de me livrar dela como meu clone. Mas, aparentemente, se você os tratar honestamente, eles não retribuem, porque, apesar do meu pedido para excluir a conta do spammer, eles não fizeram nada com ela, então enviei essa merda do Twitter para o inferno.
Muitas pessoas me reconhecem pelo meu boné. Trabalho nos grupos regionais DefCon DC949 e DC310. Também trabalho com o Rapid7, mas não posso falar sobre isso aqui sem usar linguagem obscena, e meu gerente não quer que eu jure. Então, preparei esta apresentação para a DefCon e cumprirei o prazo de 15 minutos, embora esse seja um tópico bastante complicado. Esta é essencialmente uma apresentação padrão que se concentra em engenharia reversa e coisas engraçadas relacionadas.
Ao discutir este tópico no Twitter, dois campos se formaram. Um cara disse: "Eu não tenho idéia do que essa merda ^ 2 está falando, mas é incrível!" O segundo cara do Reddit viu meus slides e ficou chateado por causa de links para coisas que não estavam relacionadas ao tópico, fiquei com raiva por um assunto tão sério não ter sido totalmente abordado, então desejei que minha apresentação tivesse "mais conteúdo e menos lixo".

Portanto, quero focar nesta citação. Nada pessoal, cara do Reddit - digo isso não apenas no caso de ele estar presente nesta sala, mas também porque foi uma crítica justa. Porque uma conversa que não contém conteúdo útil suficiente é conversa vazia.
O tópico da minha conversa é uma rotina padrão para hackers, mas parece-me que, de fato, os palestrantes geralmente não tentam apresentar suas informações de maneira divertida, mesmo quando possível, preferindo conclusões secas e emasculadas. "Aqui está o IP, aqui está o ESP, aqui está como você pode executar uma exploração, aqui está o meu" dia zero ", agora aplaude!" - e todos batem palmas.
Obrigado pelos aplausos, agradeço! Parece-me que há muitos pontos interessantes no meu material, por isso merece ser declarado de uma maneira um tanto divertida, que tentarei fazer.
Você verá uma atitude excepcionalmente superficial em relação à ciência da computação e ao humor completamente infantil, por isso espero que você aprecie o que vou mostrar aqui. Sinto muito se você veio aqui à procura de uma conversa séria.
No slide, você vê uma análise científica do meu último relatório comparando o compartilhamento de uma abordagem estritamente científica e o compartilhamento de um "medicamento" que fornece segurança ao computador.

Você vê que existem muito mais "drogas", mas não se preocupe, agora a participação da ciência aumentou um pouco.

Então, há algum tempo, meu amigo Merlin, sentado aqui em primeiro plano, escreveu um incrível bot baseado no script IRC Python, que ocupa apenas uma linha.
Este é um exercício realmente incrível para aprender programação funcional, o que é muito divertido de se mexer. Você pode simplesmente adicionar uma função após a outra e obter combinações de todos os tipos de funções diferentes, e tudo isso é desenhado na tela como uma onda do arco-íris; em geral, essa é uma das coisas mais estúpidas que você pode fazer.
Eu pensei que se você aplicar esse princípio aos arquivos binários? Não sei de onde veio essa ideia, mas ficou incrível! No entanto, quero esclarecer alguns conceitos básicos.
É possível que seu professor de matemática tenha apresentado essas funções muito mais complicadas do que realmente são.

Portanto, a fórmula f (x) tem um significado muito simples, funciona como funções comuns. Você tem X, tem entrada e recebe X 7 vezes, e isso é igual ao seu valor. No Python, você pode criar uma função (lambda x: x * 7). Se você deseja trabalhar com Java - desculpe, espero que você nunca queira fazer isso -, você pode fazer algo como:
public static int multiplyBySevenAndReturn(Integer x) { return x * 7; }
Você sabe, funções matemáticas podem até ser muito mais complicadas, mas é tudo o que precisamos saber sobre elas no momento.
Se você observar o conjunto de códigos, notará que as instruções JMP e CALL não estão vinculadas a valores específicos, elas funcionam com um deslocamento. Se você usar um depurador, poderá ver que o JMP00401000 é mais uma instrução de salto para bytes a frente do que uma instrução específica para pular para 5 ou 10 bytes. O mesmo se aplica à função CALL, exceto que ela coloca várias coisas na sua pilha. A exceção ocorre quando você "cola" o endereço no registro, ou seja, está acessando um endereço específico. Tudo acontece aqui de uma maneira completamente diferente. Depois de conectar o endereço ao registro e fazer algo como CALL EAX, a função acessa o valor específico no EAX. O mesmo vale para CALL [EAX] ou JMP [EAX] - apenas desreferencia o EAX e vai para esse endereço. Ao usar um depurador, talvez você não consiga determinar qual endereço específico a CALL está acessando. Isso pode ser um problema, então você deve estar ciente disso.
Vejamos o recurso de salto curto JMP curto. Esta é uma instrução especial na arquitetura x86 que permite usar um deslocamento de 1 byte em vez de um deslocamento de 4 bytes, o que reduz o espaço de memória usado. Isso será importante mais tarde para todas as manipulações que ocorrerão com instruções individuais. É importante lembrar que o JMP SHORT possui um intervalo de 256 bytes. No entanto, não existe um CURSO DE CHAMADA.

Agora considere a bruxaria da ciência da computação. No meio da criação desses slides, percebi que, na verdade, você pode definir uma montagem como espaço zero, ou seja, tecnicamente, existe espaço zero entre cada instrução. Se você observar instruções individuais, verá que cada uma é executada uma após a outra. Tecnicamente, isso pode ser interpretado como um salto incondicional para a próxima instrução. Isso nos fornece um espaço entre cada instrução de montagem, enquanto cada instrução está associada a um salto incondicional.
Se você olhar para este exemplo de montagem, a propósito, estas são coisas muito simples que recomendo decodificar com ASCII, portanto, este é apenas um conjunto de instruções regulares.
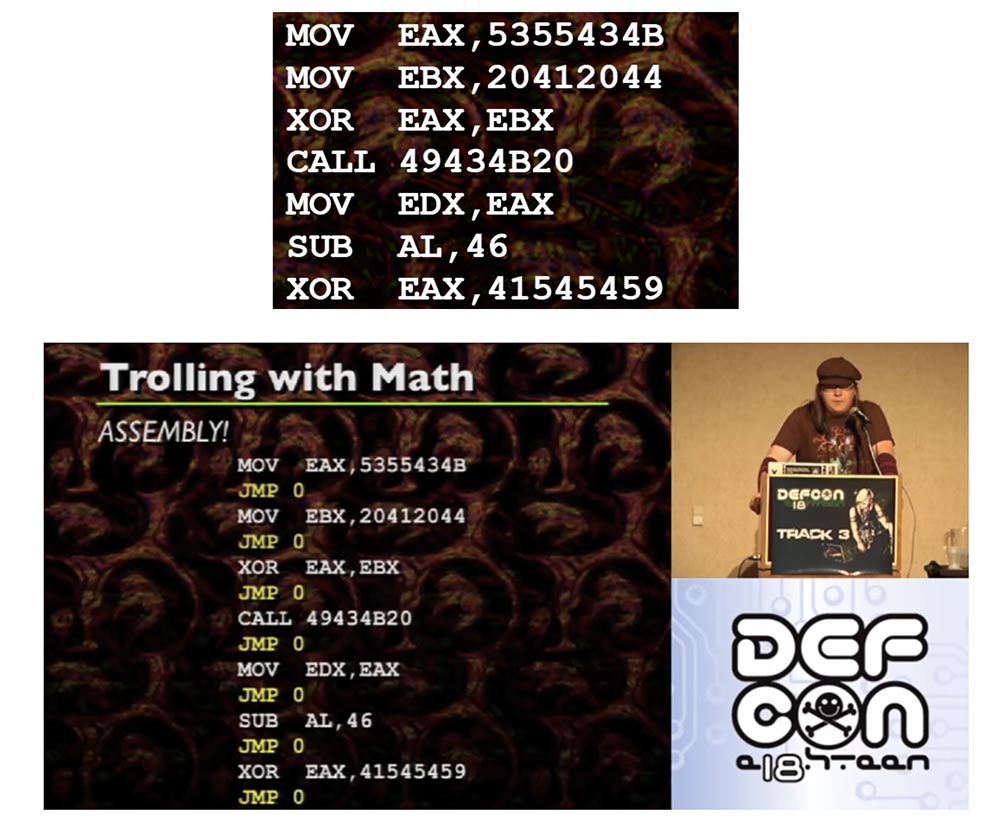
Os 0s do JMP localizados entre cada instrução são saltos incondicionais que você normalmente não vê. Eles se seguem após cada instrução. Portanto, é possível colocar cada instrução de montagem individual em um local de memória arbitrária se e somente se cada instrução de unidade for acompanhada de um salto incondicional para a próxima instrução. Porque se você transferir a montagem e precisar usar o mesmo código de antes, deverá anexar um salto incondicional a cada instrução.
Vamos olhar mais longe. Tecnicamente, uma matriz unidimensional pode ser interpretada como uma matriz bidimensional, requer apenas um pouco de matemática, linhas ou algo parecido, não vou dizer com certeza, mas não é muito difícil. Isso nos dá a oportunidade de interpretar o local na memória na forma de uma treliça (x, y). Em combinação com a interpretação do espaço vazio entre as instruções como saltos incondicionais que podem ser relacionados entre si, podemos literalmente desenhar instruções. Isso é demais!
Para implementar isso na prática, você precisa executar as seguintes etapas:
- desmonte cada instrução para descobrir qual é o código;
- Aloque um lugar na memória muito maior que o tamanho do conjunto de instruções. Eu costumo reservar 10 vezes mais memória que o tamanho do código;
- para cada instrução, determine f (x);
- defina cada instrução no local correspondente (x, y) na memória;
- anexar um salto incondicional à instrução;
- marque a memória como executável e execute o código.
Infelizmente, muitas questões surgem aqui. É como a gravidade, que funciona apenas na teoria, mas na prática vemos uma coisa completamente diferente. Porque, na realidade, o x86 envia para o inferno suas instruções JMP, instruções CALL, distorcem seu código auto-referencial, código auto-modificador que usa a iteração.

Vamos começar com as instruções do JMP. Como as instruções do JMP são tendenciosas, quando colocadas em um local arbitrário, elas não apontam mais para onde você acha que deveriam apontar. O JMP CURTO encontra-se em uma posição semelhante. Colocados acidentalmente pela sua função (x, y), eles não indicam o que você está contando. Porém, diferentemente dos JMPs longos, os JMPs curtos são mais fáceis de corrigir, especialmente se você estiver lidando com uma matriz unidimensional. O JMP CURTO é fácil de converter para o JMP normal, mas é preciso descobrir qual foi o novo deslocamento.
Trabalhar com JMPs baseados em registro ainda é uma dor de cabeça e, como eles exigem compensações apertadas e podem ser calculados em tempo de execução, não há uma maneira fácil de descobrir para onde estão indo. Para detectar automaticamente cada registro, você precisa usar um monte de conhecimentos da teoria da compilação. Em tempo de execução, pode haver ponteiros de função, ponteiros de classe e similares. É verdade que, se você não quiser fazer um trabalho extra para fazer tudo isso, não poderá fazê-lo. As funções f (x) funcionam em código real, não de maneira tão elegante quanto no papel. Se você quiser fazer isso corretamente, precisará fazer muito trabalho.
Para definir indicadores de classe e coisas assim, você precisa conjurar com C e C ++. Antes de salvar, durante a desmontagem, converta seu JMP CURTO em JMP regular, porque você precisa lidar com o viés, é bastante simples.
Tentar calcular os deslocamentos reais é uma enorme dor de cabeça. Todas as instruções encontradas têm deslocamentos que serão movidos quando o código for movido e deverão ser recalculados. Isso significa que você precisa seguir as instruções e para onde elas estão se movendo como metas. É difícil explicar para você nos slides, mas um exemplo de como conseguir isso está no CD com os materiais desta conferência.
Depois de colocar todas as instruções, substitua as compensações antigas pelas novas. Se você não danificou o deslocamento, tudo vai dar certo. Agora que você se preparou, há uma oportunidade real de implementar a ideia no nível mais alto. Para fazer isso, você precisa:
- desmontar instruções;
- prepare um buffer de memória;
- inicialize as constantes disponíveis f (x);
- itere sobre f (x) e determinados ponteiros de dados, segundo os quais o seu código será gravado ao rastrear instruções de merda;
- Atribua instruções aos índices criados correspondentes;
- corrija todos os saltos condicionais;
- marque a nova partição de memória como executável;
- executar código.
Se você colocar as coisas no lugar delas, então teremos coisas estranhas - tudo fica bagunçado, as instruções saltam para lugares obscuros da memória e tudo isso parece simplesmente encantador.

Tudo isso tem algum significado prático ou é apenas uma performance de circo? O valor aplicado de tais transformações é o seguinte. Isolar as instruções de montagem e algumas etapas para calcular f (x) nos permite colocar essas instruções de montagem em qualquer lugar do buffer sem nenhuma interação do usuário. Para confundir os caminhos de execução de código, tudo o que você precisa fazer é escrever matematicamente a função e os ponteiros em algum assembler, escolhendo-os aleatoriamente.
Isso simplifica bastante as técnicas de codificação polimórfica. Em vez de escrever código cada vez que manipula seu código de uma certa maneira, você pode escrever uma série de funções que determinam aleatoriamente a posição do seu código e, em seguida, seleciona essas funções como aleatórias etc.
O anti-reverso não é tão legal e atual quanto a técnica anti-depuração.
O Anti -version não é o quanto você se diverte ao tornar impossível o uso do IDA, e não o quanto você estraga o computador do Reverser com as imagens do GNAA Last Measure, embora seja muito divertido. Anti-reversão significa simplesmente ser um imbecil, porque se você, como o último imbecil, recebe um Reverser, um cara que quebra a proteção de diferentes sistemas, ele fica bravo, envia esse programa malicioso para o inferno e sai.
Enquanto isso, você poderá vender todos os seus bots para redes de negócios russas, porque com seu software você "reduz" todos os envolvidos na engenharia reversa. Todo mundo sabe como encontrar técnicas anti-depuração no Google, mas não encontra soluções para problemas decorrentes de coisas criativas no local. Os anti-revólveres mais criativos farão com que os reverters quebrem os dedos do teclado e deixem orifícios do tamanho de punhos nas paredes. Os inversores fervem de raiva, eles não entenderão o que diabos você fez, porque seu código estragou tudo.
Este é um tipo de jogo nervoso, uma coisa psicológica. Se você é criativo nessa questão e cria um anti-reverso realmente impressionante, pode se orgulhar disso. Mas você sabe que, na verdade, você está apenas tentando afastá-los do seu código.
Então o que eu vou fazer? Vou pegar as funções de ofuscação e ofuscá-las. Então, vou usar a segunda versão da ofuscação de funções emaranhadas e aplicar a ofuscação novamente. Então, vamos puxar o código. Este é um exemplo de trolling matemático, que tomei como exemplo.
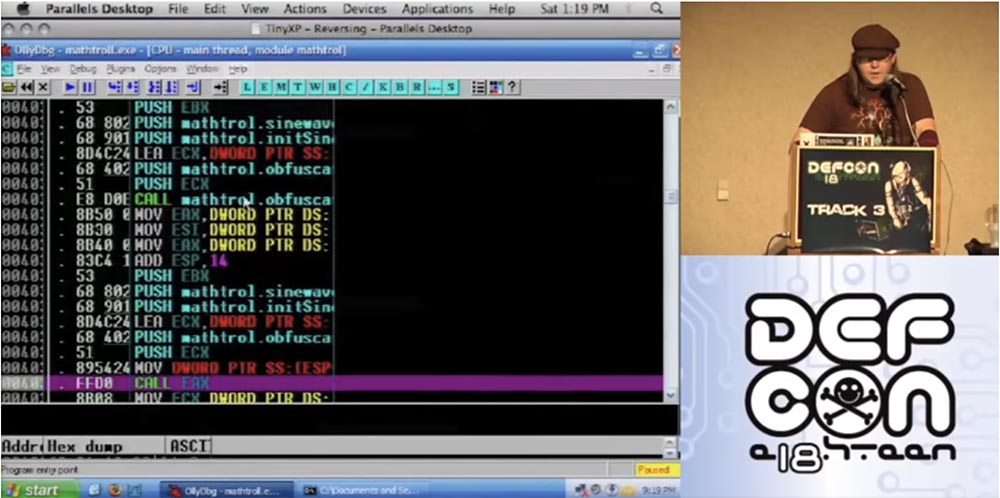
Então, insiro o comando "confundir pela fórmula" na janela que é aberta.
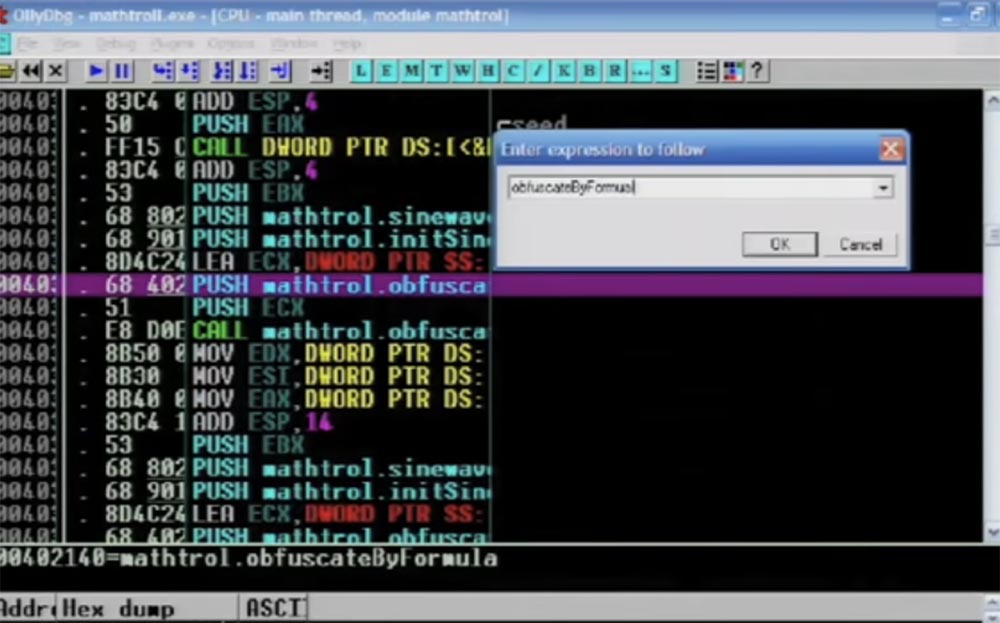
Em seguida, você vê instruções de montagem que fazem seu trabalho. Observe que eu uso C ++ aqui, embora na menor oportunidade eu tente evitar isso.
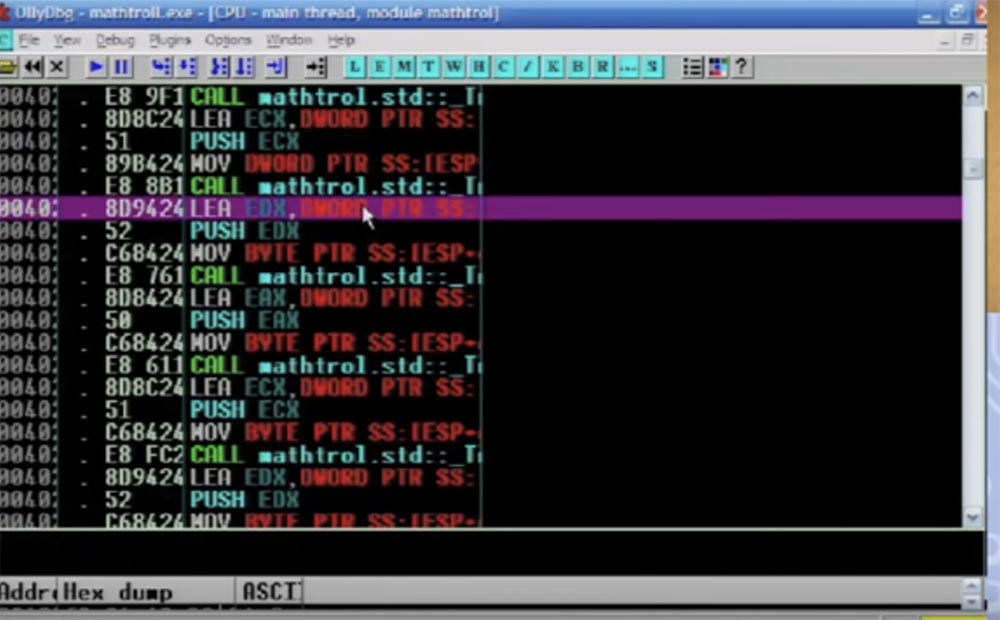
Aqui, a função ativa CALL EAX é destacada, seguida pela instrução de salto que será aplicada, você vê vários tipos de coisas diferentes no buffer, e tudo isso é feito com cada instrução individual.
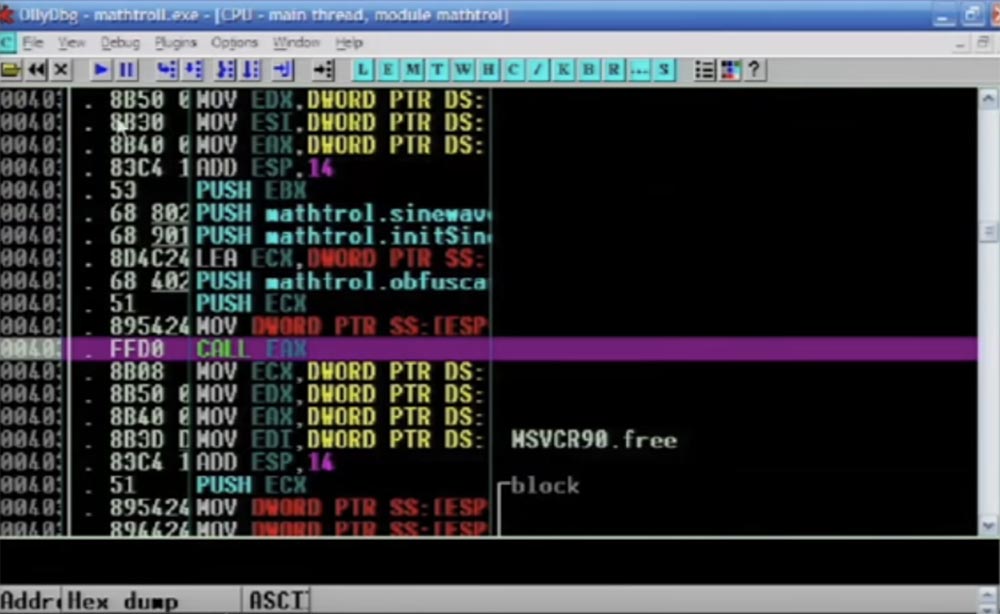

Agora eu rebobino o programa até o fim, e você verá o resultado. Portanto, o código ainda parece ótimo, várias instruções JMP são compiladas aqui, parece confuso e, na verdade, confuso.
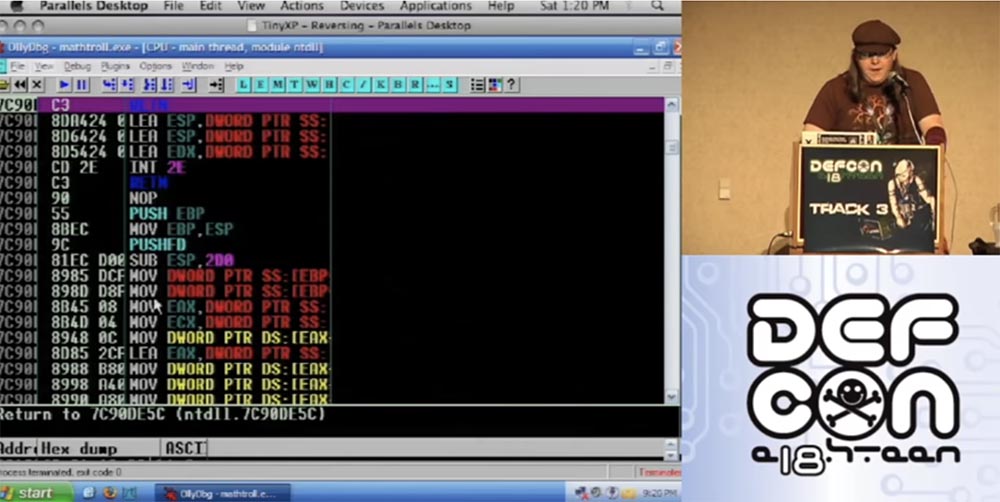
O próximo slide mostra uma representação gráfica da aparência da pilha.

Toda vez que isso acontece, eu gero uma fórmula aleatória de ondas senoidais com forma arbitrária, você vê aqui várias formas diferentes, e isso é legal. Acho que o código começa em algum lugar no canto superior esquerdo, mas não me lembro exatamente. Então ele torce tudo, você pode não apenas produzir sinusóides, mas também torcer as espirais.
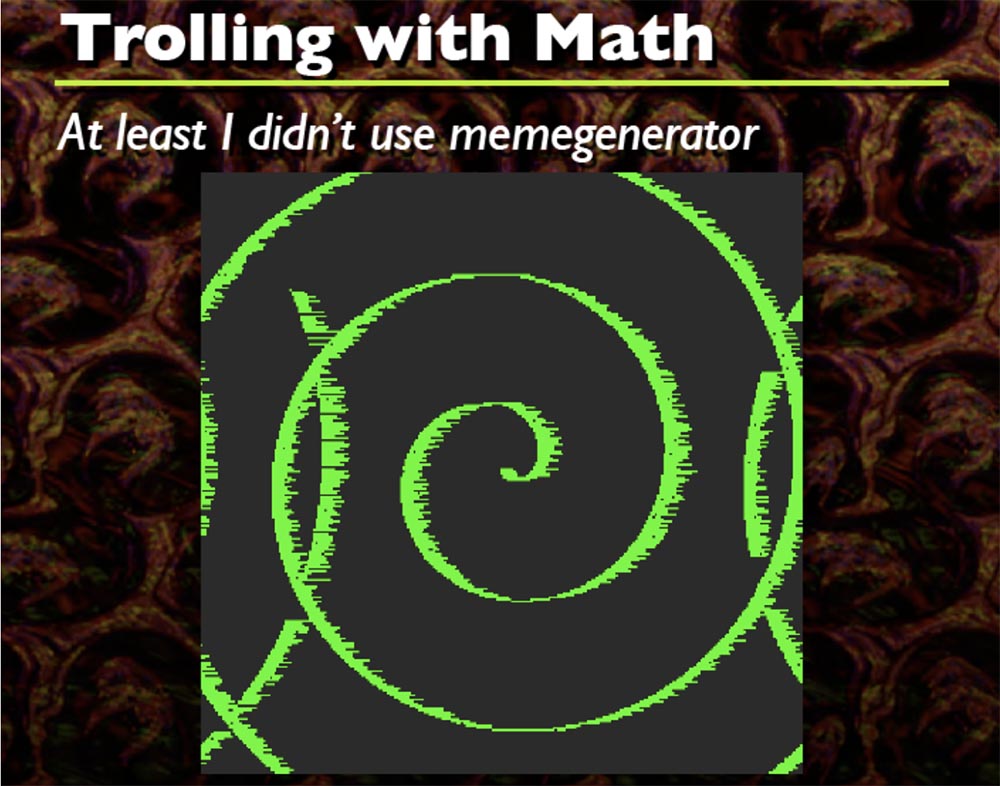
Apenas duas fórmulas funcionam aqui, que eu incluí no código fonte. Com base nisso, você pode fazer quantas coisas criativas quiser, basicamente é apenas DIFF do buffer inicial ao buffer final.
O problema é que este exemplo de código usa saltos incondicionais, o que é realmente ruim, porque o código deve ser exatamente o mesmo de antes, ou seja, saltos incondicionais seguem apenas uma direção. Portanto, você precisa ir do ponto de entrada até o final da mesma maneira, livrar-se das instruções de salto e pronto - você conseguiu seu código! O que fazer? É necessário transformar saltos incondicionais em condicionais. Saltos condicionais são feitos em duas direções, é muito melhor, podemos dizer que é 50% melhor.
Aqui temos um dilema interessante: se precisamos de saltos condicionais, ainda precisamos usar saltos incondicionais ... que diabos? Então o que fazemos? Predicados opacos nos salvarão! Para quem não sabe, um predicado opaco é essencialmente uma instrução booleana que é sempre executada para uma versão específica, independentemente de qualquer coisa.
Então, vejamos a extensão do espaço zero que mencionei anteriormente. Se você tiver um conjunto de instruções e eles tiverem saltos incondicionais, transições entre cada instrução, segue-se que uma série de instruções de montagem que não afetam diretamente as instruções de que precisamos podem preceder ou seguir uma única instrução.
Por exemplo, se você escreveu instruções muito específicas que não alteram a montagem principal do que você está tentando confundir, ou seja, tenta não se envolver com os registros, desde que mantenha o estado de cada instrução de montagem. E isso é ainda mais incrível.
Você pode considerar cada instrução de montagem, que pode ser confundida, como preâmbulo, dados de montagem e postscript. O preâmbulo é o que precede a instrução de montagem e o pós-escrito é o que segue. O preâmbulo é geralmente usado ou pode ser usado para duas coisas:
- correção das conseqüências do predicado opaco do preâmbulo anterior;
- fragmentos de código anti-depuração.
Mas o preâmbulo é essencialmente limitado porque você não pode fazer muito.
Postscript é uma coisa mais engraçada. Pode ser usado para:
- predicados opacos e saltos intrincados para as seguintes seções do código;
- anti-depuração e ofuscação da execução geral do código;
- criptografia e descriptografia de vários fragmentos de código no próprio programa.
No momento, estou trabalhando na possibilidade de criptografar e descriptografar cada instrução individual para que, quando cada instrução for executada, descriptografar a próxima seção, a próxima seção, a próxima e assim por diante. O slide a seguir mostra um exemplo disso.

As linhas de preâmbulo e a chamada do depurador são destacadas em verde. Tudo o que essa chamada faz é verificar se temos um depurador, após o qual vamos para uma seção arbitrária do código.
Abaixo, temos um predicado opaco muito simples. Se você mantiver o valor Eax no postscript na instrução superior, siga o operador XOR, para que o seu JZ pense: “OK, obviamente posso ir para a esquerda ou direita, acho melhor ir para a direita, porque existe 0”. Em seguida, o POP EAX é executado, seu EAX retorna, após o qual a próxima instrução é processada e assim por diante.
Obviamente, isso cria problemas muito maiores do que nossa estratégia básica, como efeitos residuais e a complicação de gerar diferentes conjuntos de instruções. Portanto, será muito difícil determinar como uma instrução afeta outra. Você pode jogar chinelos em mim, porque ainda não terminei este programa incrível, mas pode acompanhar o progresso do desenvolvimento em meu blog.

Observo que nossas fórmulas f (x) não precisam ser computadas iterativamente, por exemplo f (1), f (2), ... f (n). Nada impede que eles sejam calculados aleatoriamente. Se você for esperto, poderá determinar quantas instruções precisa e depois atribuir, por exemplo, f (27), f (54), f (9), e este será o local em que suas instruções serão colocadas aleatoriamente. Ao fazer isso, dependendo de como você escreveu seu código, você pode interrompê-lo antecipadamente, e o código ainda vinculará suas instruções aleatoriamente.
Se o seu código for gerado com base em uma fórmula previsível, o ponto de entrada também é previsível, para que você possa subir mais um nível antes de terminar de receber o código e confundir significativamente o ponto de entrada em um grau ou outro. Por exemplo, siga 300 instruções de montagem provenientes de um único ponto de entrada.
Agora vamos falar sobre as deficiências.

Esse método requer uma compilação cuidadosa do código, principalmente usando GCC ou, se Deus permitir, usando C ++. C ++ é na verdade uma linguagem bastante interessante por vários motivos, mas você sabe que todos os compiladores são péssimos. Portanto, o principal nesse assunto é uma compilação feita à mão, porque se sua tentativa de confundir sua própria assembléia causará a aprovação da quadrilha que inventou o worm Conficker, você estragou tudo.
Você precisará de uma grande quantidade de memória. Lembre-se da imagem com ondas senoidais. Vermelho é o código e azul é a memória necessária para que ele funcione, e deve ser suficiente para que tudo funcione como deveria.
Você provavelmente estará lidando com um conjunto de dados gigantesco depois de concluir o código. E aumentará significativamente se você quiser confundir mais de uma função.
Os ponteiros de função se comportam de forma imprevisível - às vezes corretamente, às vezes não. Depende do que você está fazendo, e definitivamente haverá um problema, porque você não poderá prever onde e quando o ponteiro da função será acionado em sua montagem.
Quanto mais complicado você gerar ofuscação e manipular a montagem no preâmbulo e no postscript, mais difícil é corrigir e depurar. Portanto, escrever esse código é como equilibrar entre "ok, vou inserir cuidadosamente um ou dois JMPs aqui" e "como diabos posso descobrir tudo isso em pouco tempo"? Então você só precisa inserir instruções e depois descobrir por vários meses o que fez.
Espero que você tenha aprendido algo útil hoje. Na minha opinião, fiquei muito bêbado e, portanto, não entendo o que aconteceu agora. O próximo slide mostra meus contatos no Twitter, meu blog e site, então me visite ou escreva.

Isso é tudo, obrigado por ter vindo!
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD de 1Gbps até janeiro de graça quando pagar por um período de seis meses, você pode fazer o pedido
aqui .
Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?