O HTTP é uma coisa bonita: um protocolo que existe há mais de 20 anos sem muita alteração.
 Esta é a parte dois da série de segurança da Web: a primeira parte foi Como os navegadores funcionam .
Esta é a parte dois da série de segurança da Web: a primeira parte foi Como os navegadores funcionam .Como vimos no artigo anterior, os navegadores interagem com aplicativos da Web usando o protocolo HTTP, e esse é o principal motivo para nos aprofundarmos neste tópico. Se os usuários digitarem as informações do cartão de crédito no site e um invasor puder interceptar os dados antes de chegar ao servidor, provavelmente teremos problemas.
Compreender como o HTTP funciona, como podemos proteger as comunicações entre clientes e servidores e quais recursos relacionados à segurança o protocolo oferece é o primeiro passo para melhorar nossa segurança.
Ao discutir o HTTP, no entanto, sempre devemos distinguir entre semântica e implementação técnica, pois esses são dois aspectos completamente diferentes do HTTP.
A principal diferença entre eles pode ser explicada por uma analogia muito simples: 20 anos atrás, as pessoas cuidavam de seus parentes da mesma maneira que agora, mesmo que a maneira como interagiram tenha mudado significativamente. É provável que nossos pais tomem o carro e dirijam até a irmã para conversar e passar algum tempo com a família.
Hoje em dia, eles costumam enviar mensagens para o WhatsApp, fazer ligações ou usar um grupo no Facebook, o que antes era impossível. Isso não significa que as pessoas se comunicam ou se importam mais ou menos, mas simplesmente que sua interação mudou.
O HTTP não é diferente: a semântica do protocolo não mudou muito, enquanto a implementação técnica da interação de clientes e servidores foi otimizada ao longo dos anos. Se você observar a solicitação HTTP de 1996, será muito semelhante à que vimos no artigo anterior, embora a maneira como esses pacotes passem pela rede seja muito diferente.
Revisão
Como vimos, o HTTP segue um modelo de solicitação / resposta quando um cliente conectado a um servidor envia uma solicitação e o servidor responde a ela.
Uma mensagem HTTP (solicitação ou resposta) consiste em várias partes:
- "Primeira linha" (primeira linha)
- cabeçalhos (solicitar cabeçalhos)
- body (corpo do pedido)
Na solicitação, a primeira linha indica o método usado pelo cliente, o caminho para o recurso que ele deseja, bem como a versão do protocolo que ele usará:
GET /players/lebron-james HTTP/1.1Nesse caso, o cliente tenta obter o recurso (
GET ) em
/Players/Lebron-James através do protocolo versão
1.1 - nada complicado de entender.
Após a primeira linha, o HTTP nos permite adicionar metadados à mensagem por meio de cabeçalhos que assumem a forma de valor-chave, separados por dois pontos:
GET /players/lebron-james HTTP/1.1
Host: nba.com
Accept: */*
Coolness: 9000Por exemplo, nesta solicitação, o cliente adicionou 3 cabeçalhos adicionais à solicitação:
Host ,
Accept e
Coolness .
Espere,
Coolness ?!?!
Os cabeçalhos não devem usar nomes reservados específicos, mas geralmente é recomendável confiar naqueles padronizados na especificação HTTP: quanto mais você se desvia dos padrões, menos será compreendido por outro participante da troca.
Cache-Control é, por exemplo, um cabeçalho usado para determinar se (e como) uma resposta é armazenável em cache: a maioria dos proxies e dos proxies reversos o entendem seguindo a especificação HTTP à risca. Se você tivesse que renomear o cabeçalho
Cache-Control para
Awesome-Cache-Control , os proxies não teriam idéia de como armazenar em cache a resposta, pois eles não foram projetados para atender às especificações que você acabou de inventar.
No entanto, às vezes faz sentido incluir um cabeçalho "personalizado" na mensagem, pois você pode adicionar metadados que realmente não fazem parte da especificação HTTP: o servidor pode decidir incluir informações técnicas em sua resposta para que o cliente possa executar simultaneamente solicitações e receber informações importantes sobre estado do servidor que retorna uma resposta:
...
X-Cpu-Usage: 40%
X-Memory-Available: 1%
...Ao usar cabeçalhos personalizados, é sempre preferível colocar um prefixo com uma chave na frente deles, para que não entrem em conflito com outros cabeçalhos que possam se tornar padrão no futuro: historicamente isso funcionou bem até que todos começaram a usar os prefixos
X "não padrão", que por sua vez se tornaram a norma. Os cabeçalhos
X-Forwarded-For e
X-Forwarded-Proto são exemplos de cabeçalhos personalizados
amplamente usados e compreendidos por balanceadores de carga e proxies , mesmo que
não façam parte do padrão HTTP .
Se você precisar adicionar seu próprio cabeçalho personalizado, geralmente é melhor usar um prefixo proprietário, como
Acme-Custom-Header ou
A-Custom-Header .
Após os cabeçalhos, a solicitação pode conter um corpo que é separado dos cabeçalhos por uma linha vazia:
POST /players/lebron-james/comments HTTP/1.1
Host: nba.com
Accept: */*
Coolness: 9000
Best Player Ever
Nossa solicitação foi concluída: primeira linha (informações sobre localização e protocolo), cabeçalhos e corpo. Observe que o corpo é completamente opcional e, na maioria dos casos, é usado apenas quando queremos enviar dados para o servidor, portanto, o método
POST é usado no exemplo acima.
A resposta não é muito diferente:
HTTP/1.1 200 OK
Content-Type: application/json
Cache-Control: private, max-age=3600
{"name": "Lebron James", "birthplace": "Akron, Ohio", ...}As primeiras informações enviadas na resposta são a versão do protocolo que ele usa, junto com o status dessa resposta. A seguir, estão os cabeçalhos e, se necessário, uma quebra de linha seguida pelo corpo.
Como já mencionado, o protocolo passou por várias revisões e, com o tempo, novas funções foram adicionadas (novos cabeçalhos, códigos de status etc.), mas a estrutura principal não mudou muito (primeira linha, cabeçalhos e corpo). O que realmente mudou é como clientes e servidores trocam essas mensagens - vamos dar uma olhada mais de perto nisso.
HTTP vs HTTPS vs H2
Houve duas alterações semânticas significativas no
HTTP / 1.0 :
HTTP / 1.0 e
HTTP / 1.1.“Onde estão o HTTPS e o
HTTP2 ?”, Você pergunta.
HTTPS e HTTP2 (abreviado como H2) são mudanças mais técnicas, pois introduziram novas maneiras de entregar mensagens pela Internet, sem afetar significativamente a semântica do protocolo.
HTTPS é uma extensão
HTTP "segura" e inclui o estabelecimento de uma chave secreta compartilhada entre o cliente e o servidor, garantindo que nos comuniquemos com a parte certa e criptografemos as mensagens que trocam uma chave secreta compartilhada (mais sobre isso mais adiante). Enquanto o HTTPS visava melhorar a segurança do protocolo HTTP, o H2 buscava fornecer alta velocidade.
O H2 usa mensagens binárias em vez de de texto, suporta multiplexação, usa o algoritmo HPACK para compactar cabeçalhos ... ... Em resumo, o H2 melhora o desempenho em relação ao HTTP / 1.1.
Os proprietários de sites relutaram em mudar para HTTPS, pois isso incluía soluções adicionais entre o cliente e o servidor (como mencionado, é necessário estabelecer uma chave secreta compartilhada entre as duas partes), diminuindo a velocidade do usuário: com H2, que é criptografado por padrão, não há mais desculpas já que recursos como multiplexação e envio de servidor o
tornam melhor que o HTTP / 1.1 simples .
Https
O HTTPS (HTTP seguro) permite que clientes e servidores se comuniquem com segurança por meio do TLS (Transport Layer Security), o sucessor do SSL (Secure Socket Layer).
O problema no qual o TLS se concentra é bastante simples e pode ser ilustrado com uma simples metáfora: sua alma gêmea liga para você no meio do dia, quando você está em uma reunião, e pede que você informe a senha da sua conta bancária on-line, pois ela deve ser concluída. transferência para garantir o pagamento oportuno da educação do seu filho. É muito importante que você a relate agora, caso contrário, você corre o risco de seu filho ser expulso da escola na manhã seguinte.
Agora você enfrenta dois problemas:
- autenticando que você está realmente conversando com sua alma gêmea, pois pode ser alguém fingindo ser ela
- criptografia : transmitindo sua senha para que seus colegas não possam entender e anotá-la
O que você vai fazer? Esse é exatamente o problema que o HTTPS está tentando resolver.
Para verificar com quem você está falando, o HTTPS usa Certificados de Chave Pública (certificados de chave pública), que nada mais são do que certificados que indicam a identidade de um servidor específico: quando você se conecta via HTTPS a um endereço IP, o servidor por trás desse endereço apresenta a você O certificado dele é para você provar sua identidade. Voltando à nossa analogia, você pode simplesmente pedir à sua alma gêmea para dizer o seu número de segurança social. Assim que você verifica se o número está correto, obtém um nível adicional de confiança.
Isso, no entanto, não impede que os "atacantes" descubram o número de segurança social da vítima, roubando o smartphone da sua alma gêmea e ligando para você. Como verificamos a identidade do chamador?
Em vez de pedir diretamente à sua alma gêmea que escreva seu número de previdência social, você liga para sua mãe (que mora ao lado) e pede que ela vá ao seu apartamento e certifique-se de que a outra metade diga o número da previdência social. Isso adiciona um nível adicional de confiança, já que você não considera sua mãe uma ameaça e depende dela para verificar a identidade do chamador.
Em termos de HTTPS, sua mãe se chama CA, abreviação de Autoridade de Certificação: o trabalho de uma CA é verificar a identidade de um servidor específico e emitir um certificado com sua própria assinatura digital: isso significa que, quando eu me conectar a um domínio específico, não receberei um certificado gerado pelo proprietário do domínio (o chamado
autoassinado) certificado ) e CA.
A tarefa da CA é verificar a autenticidade do domínio e emitir o certificado de acordo: quando você "pede" um certificado (geralmente chamado de certificado SSL, embora o TLS seja usado atualmente - os nomes realmente se mantêm!), A CA pode ligar para você ou Peça para alterar a configuração de DNS para garantir que você controle este domínio. Após a conclusão do processo de verificação, ele emitirá um certificado, que poderá ser instalado nos servidores web.
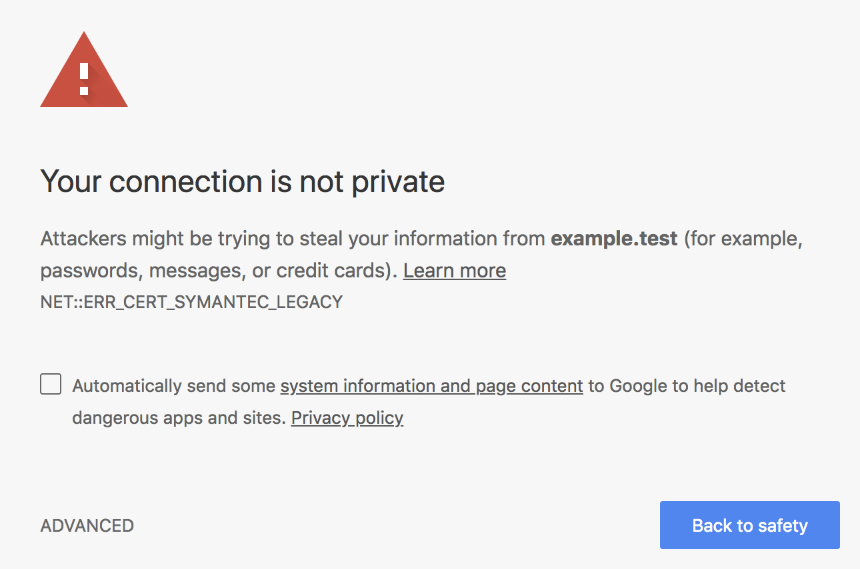
Então, clientes, como navegadores, se conectarão aos seus servidores e receberão esse certificado para que possam verificar sua autenticidade: os navegadores têm um tipo de "relacionamento" com a CA, no sentido de acompanhar a lista de domínios confiáveis na CA para garantir O certificado é realmente confiável. Se o certificado não for assinado por uma autoridade confiável, o navegador exibirá um grande aviso informativo para os usuários:
Estamos a meio caminho de garantir a comunicação entre você e sua outra metade: agora que passamos a autenticação (verificação da identidade do chamador), precisamos garantir que possamos nos comunicar com segurança sem a intervenção de outras pessoas no processo. Como mencionei, você está bem no meio da reunião e precisa anotar sua senha para serviços bancários online. Você precisa encontrar uma maneira de criptografar sua comunicação para que somente você e sua alma gêmea possam entender sua conversa.
Você pode fazer isso definindo uma chave secreta comum entre os dois e criptografar as mensagens com essa chave: por exemplo, você pode usar
a opção de
cifra de César com base na data do seu casamento.

Isso funcionará bem se ambas as partes tiverem estabelecido relacionamentos, como você e sua alma gêmea, pois poderão criar uma chave com base na memória compartilhada que ninguém conhece. Navegadores e servidores, no entanto, não podem usar o mesmo mecanismo, pois não se conhecem antecipadamente.
Em vez disso, são usadas variações do
protocolo de troca de chaves Diffie-Hellman , o que garante que as partes sem conhecimento prévio estabeleçam uma chave secreta compartilhada e ninguém mais possa "roubá-la". Isso inclui o
uso de matemática .
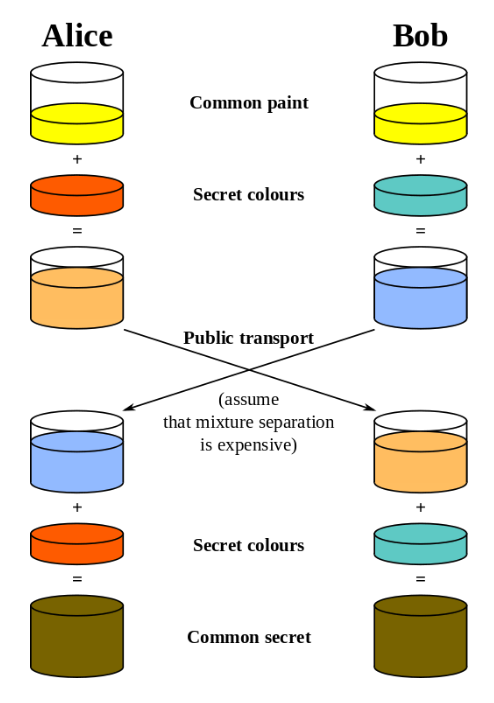
Depois que a chave secreta é instalada, o cliente e o servidor podem se comunicar sem medo de que alguém possa interceptar suas mensagens. Mesmo que os invasores façam isso, eles não terão uma chave secreta compartilhada necessária para descriptografar as mensagens.
Para obter mais informações sobre HTTPS e Diffie-Hellman, recomendo a leitura de "
Como o HTTPS protege as conexões " de Hartley Brody e "
Como o HTTPS realmente funciona?" Robert Heaton. Além disso,
Nove algoritmos que mudaram o futuro têm um capítulo incrível que explica a criptografia de chave pública, e eu o recomendo calorosamente aos entusiastas da ciência da computação interessados em algoritmos originais.
Https em todos os lugares
Ainda está decidindo se você deve oferecer suporte a HTTPS no seu site? Tenho más notícias para você: os navegadores começaram a proteger os usuários de sites que não suportam HTTPS para "forçar" os desenvolvedores da Web a fornecer recursos de navegação totalmente criptografados.
Seguindo o lema "
HTTPS em todos os lugares "
, os navegadores começaram a se opor às conexões não criptografadas - o Google foi o primeiro provedor de navegador a dar um prazo para os desenvolvedores da web anunciando que, começando com o Chrome 68 (julho de 2018), marcaria sites HTTP como "inseguros" :
Ainda mais preocupante para sites que não tiram proveito do HTTPS é o fato de que, assim que um usuário digita algo em uma página da web, o rótulo “Inseguro” fica vermelho - essa etapa deve incentivar os usuários a pensar duas vezes antes de trocar dados. com sites que não suportam HTTPS.
Compare isso com a aparência de um site HTTPS com um certificado válido:
Teoricamente, um site não deve ser seguro, mas, na prática, afugenta os usuários - e com razão. Nos dias em que o H2 não era uma realidade, faria sentido manter o tráfego HTTP simples e não criptografado. Atualmente, não há razão para isso. Participe do movimento HTTPS Everywhere e ajude a tornar a Internet
um lugar mais seguro para navegar .
GET vs POST
Como vimos anteriormente, uma solicitação HTTP começa com um tipo de "primeira linha":
Primeiro, o cliente informa ao servidor quais métodos ele usa para executar a solicitação: os métodos HTTP básicos incluem
GET, POST, PUT DELETE, mas a lista pode continuar com métodos menos comuns (mas ainda padrão), como
TRACE, OPTIONS ou
HEADTeoricamente, nenhum método é mais seguro que outros; na prática, nem tudo é tão simples.
As solicitações GET geralmente não contêm um corpo; portanto, os parâmetros são incluídos no URL (por exemplo,
www.example.com/articles?article_id=1 ), enquanto as solicitações POST geralmente são usadas para enviar ("publicar") dados incluídos no corpo. Outra diferença são os efeitos colaterais desses métodos:
GET é um método idempotente, o que significa que, independentemente de quantas solicitações você enviar, você não alterará o estado do servidor da web. Em vez disso, o
POST não
POST idempotente: para cada solicitação enviada, você pode alterar o estado do servidor (pense, por exemplo, em fazer um novo pagamento - agora você provavelmente entende por que os sites solicitam que você não atualize a página ao concluir uma transação).
Para ilustrar a diferença importante entre esses métodos, precisamos dar uma olhada nos logs do servidor da web com os quais você já deve estar familiarizado:
192.168.99.1 - [192.168.99.1] - - [29/Jul/2018:00:39:47 +0000] "GET /?token=1234 HTTP/1.1" 200 525 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" 404 0.002 [example-local] 172.17.0.8:9090 525 0.002 200
192.168.99.1 - [192.168.99.1] - - [29/Jul/2018:00:40:47 +0000] "GET / HTTP/1.1" 200 525 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" 393 0.004 [example-local] 172.17.0.8:9090 525 0.004 200
192.168.99.1 - [192.168.99.1] - - [29/Jul/2018:00:41:34 +0000] "PUT /users HTTP/1.1" 201 23 "http://example.local/" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" 4878 0.016 [example-local] 172.17.0.8:9090 23 0.016 201Como você pode ver, os servidores da Web registram o caminho da solicitação: isso significa que, se você incluir dados confidenciais em sua URL, eles serão ignorados pelo servidor da Web e armazenados em algum lugar nos seus logs - seus dados confidenciais estarão em algum lugar texto simples, que precisamos evitar completamente.
Imagine que um invasor possa obter acesso a um de seus arquivos de log antigos , que podem conter informações de cartão de crédito, tokens de acesso para seus serviços privados etc., isso será um desastre completo.
Os servidores da Web não registram cabeçalhos e corpos HTTP, pois os dados armazenados serão muito volumosos - e é por isso que o envio de informações pelo corpo da solicitação e não pela URL geralmente é mais seguro. A partir daqui, podemos deduzir que
POST (e métodos semelhantes não idempotentes) é mais seguro que
GET , mesmo que dependa mais de como os dados são enviados ao usar um método específico, e não do fato de um método específico ser essencialmente mais seguro que outros: se você incluísse informações confidenciais no corpo da solicitação
GET , não teria mais problemas do que usar o
POST , mesmo que essa abordagem seja considerada incomum.
Acreditamos em cabeçalhos HTTP
Neste artigo, analisamos o HTTP, sua evolução e como sua extensão segura combina autenticação e criptografia para permitir que clientes e servidores se comuniquem através de um canal seguro: isso não é tudo o que o HTTP tem a oferecer em termos de segurança.
A tradução foi apoiada pela EDISON Software , uma empresa de segurança profissional, e também está desenvolvendo sistemas eletrônicos de verificação médica .