Para executar o JavaScript, o navegador precisa de um pouco de memória, mas em algum lugar é necessário armazenar objetos, primitivas, funções criadas para todas as ações do usuário. Portanto, o navegador primeiro aloca a quantidade necessária de RAM e, quando os objetos não são usados, ele a limpa independentemente.
Em teoria, parece bom. Na prática, o usuário abre 20 abas do YouTube, redes sociais, lê alguma coisa, funciona, o navegador consome memória, como o Hummer H2 - gasolina. O coletor de lixo, como esse monstro com uma esfregona, percorre toda a memória e acrescenta confusão, tudo fica mais lento e trava.

Para impedir que tais situações aconteçam e o desempenho de nossos sites e aplicativos não sofra, o desenvolvedor front-end deve saber como o lixo afeta os aplicativos, como o navegador o coleta e otimiza o tratamento da memória e como tudo difere da realidade dura. Este é apenas o relatório de
Andrei Roenko ( flapenguin ) no
Frontend Conf 2018 .
Usamos o coletor de lixo (não em casa - no desenvolvimento de front-end) todos os dias, mas realmente não pensamos sobre o que é, o que nos custa e as oportunidades e limitações que ele tem.
Se a coleta de lixo realmente funcionasse em JavaScript, a maioria dos módulos npm se excluiria imediatamente após a instalação.
Mas enquanto isso não for verdade, falaremos sobre o que é - sobre a montagem de objetos desnecessários.
Sobre o palestrante :
Andrei Roenko desenvolve
a API Yandex.Map , está na interface há seis anos, ele gosta de criar suas próprias abstrações altas e desce ao chão de estranhos.
Por que você precisa de coleta de lixo?
Considere o exemplo de Yandex.Maps. O Yandex.Maps é um serviço enorme e complexo que usa muitas JS e quase todas as APIs de navegador existentes, exceto as multimídia, e o tempo médio da sessão é de 5 a 10 minutos. A abundância de JavaScript cria muitos objetos. Arrastar e soltar um mapa, adicionar organizações, resultados de pesquisa e muitos outros eventos que ocorrem a cada segundo cria uma avalanche de objetos. Adicione a isso React e os objetos se tornam ainda mais.
No entanto, os objetos JS ocupam apenas 30 a 40 Mb no mapa. Para longas sessões Yandex.Maps e a alocação constante de novos objetos, isso não é suficiente.
O motivo do pequeno volume de objetos é que eles são coletados com sucesso pelo coletor de lixo e a memória é reutilizada.
Hoje falaremos sobre a coleta de lixo de quatro lados:
- Teoria Vamos começar com ela para falar a mesma língua e entender um ao outro.
- Realidade dura. Por fim, o computador executa o código da máquina em que nem todas as abstrações nos são familiares. Vamos tentar descobrir como a coleta de lixo funciona em um nível baixo.
- Realidade do navegador. Vamos ver como a coleta de lixo é implementada em mecanismos e navegadores modernos e que conclusões podemos tirar disso.
- Vida cotidiana - vamos falar sobre a aplicação prática do conhecimento adquirido na vida cotidiana.
Todas as instruções são copiadas com exemplos de como e como não fazê-lo.
Por que saber tudo isso?
A coleta de lixo é algo invisível para nós, no entanto, sabendo como é organizado, você irá:
- Tenha uma idéia da ferramenta que você está usando, que é útil no seu trabalho.
- Entenda onde otimizar os aplicativos já lançados e como projetar os futuros para que eles funcionem melhor e mais rapidamente.
- Saiba como não cometer erros comuns e parar de desperdiçar recursos em "otimizações" inúteis e prejudiciais.
Teoria
Joel Spolsky disse uma vez:
Todas as abstrações não triviais são vazadas.
O coletor de lixo é uma grande abstração não trivial que é corrigida por todos os lados. Felizmente, ele flui muito raramente.
Vamos começar com uma teoria, mas sem definições chatas. Vamos analisar o trabalho do coletor usando um código simples como exemplo:
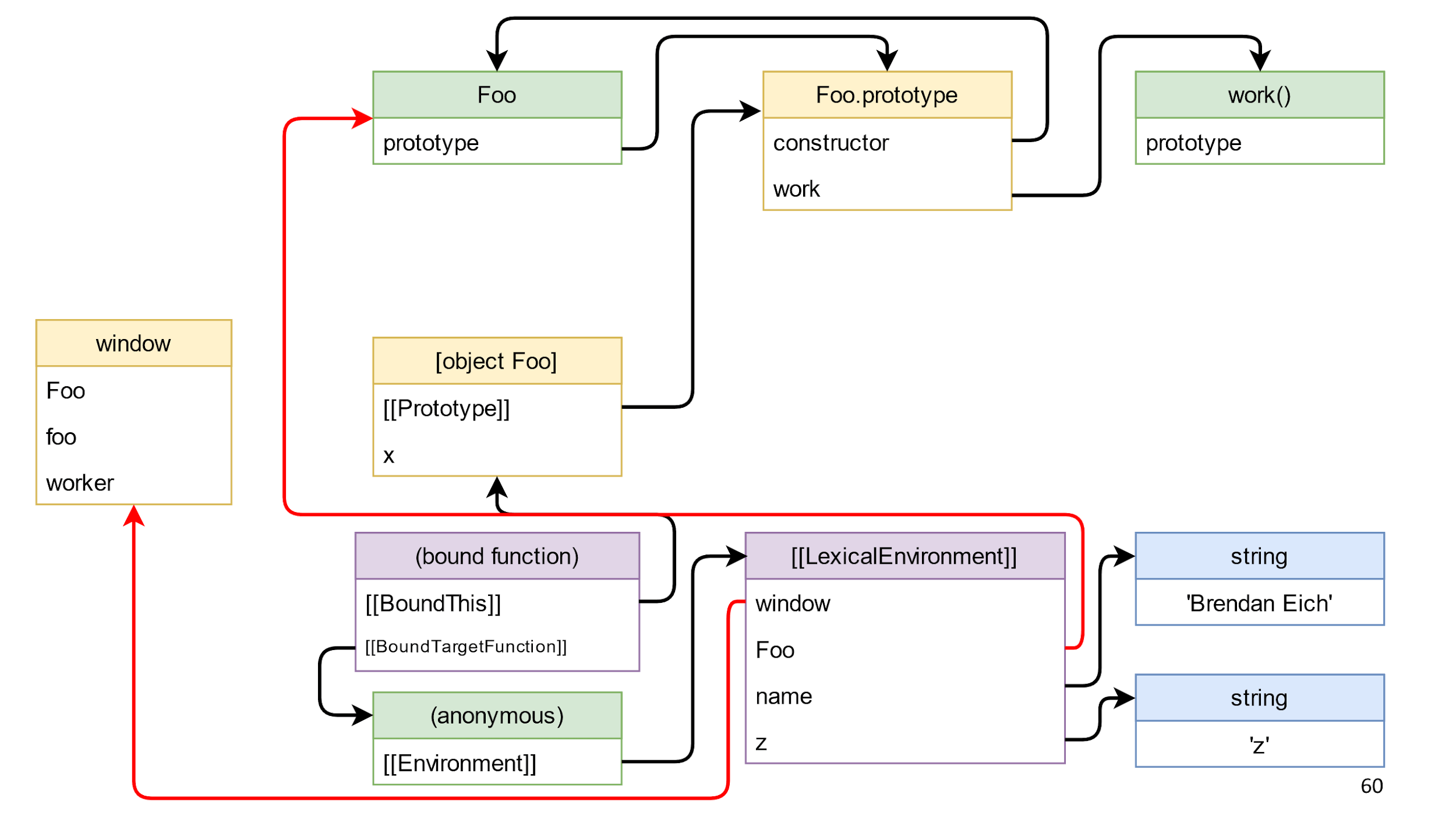
window.Foo = class Foo { constructor() { this.x = { y: 'y' }; } work(name) { let z = 'z'; return function () { console.log(name, this.xy, z); this.x = null; }.bind(this); } };
- Há uma classe no código.
- A classe tem um construtor .
- O método de trabalho retorna uma função relacionada.
- Dentro da função, essa e algumas variáveis do fechamento são usadas.
Vamos ver como esse código se comportará se for executado dessa maneira:
var foo = new Foo();
Vamos analisar o código e seus componentes com mais detalhes e começar com a classe.
Declaração de classe

Podemos assumir que as classes no ECMAScript 2015 são apenas açúcar sintático para funções. Todas as funções têm:
- Função. [[Prototype]] é o protótipo real da função.
- Foo.prototype é um protótipo para objetos criados recentemente.
- Foo.prototype possui um link para o construtor através do campo construtor. Este é um objeto, portanto herda de Object.prototype .
- O método de trabalho é uma função separada à qual existe um link, semelhante ao construtor, porque ambos são apenas funções. Ele também pode definir um protótipo e chamá-lo de novo, mas raramente alguém usa esse comportamento.
Os protótipos ocupam muito espaço no circuito, então vamos lembrar que são, mas os removemos por simplicidade.
Criando um objeto de classe
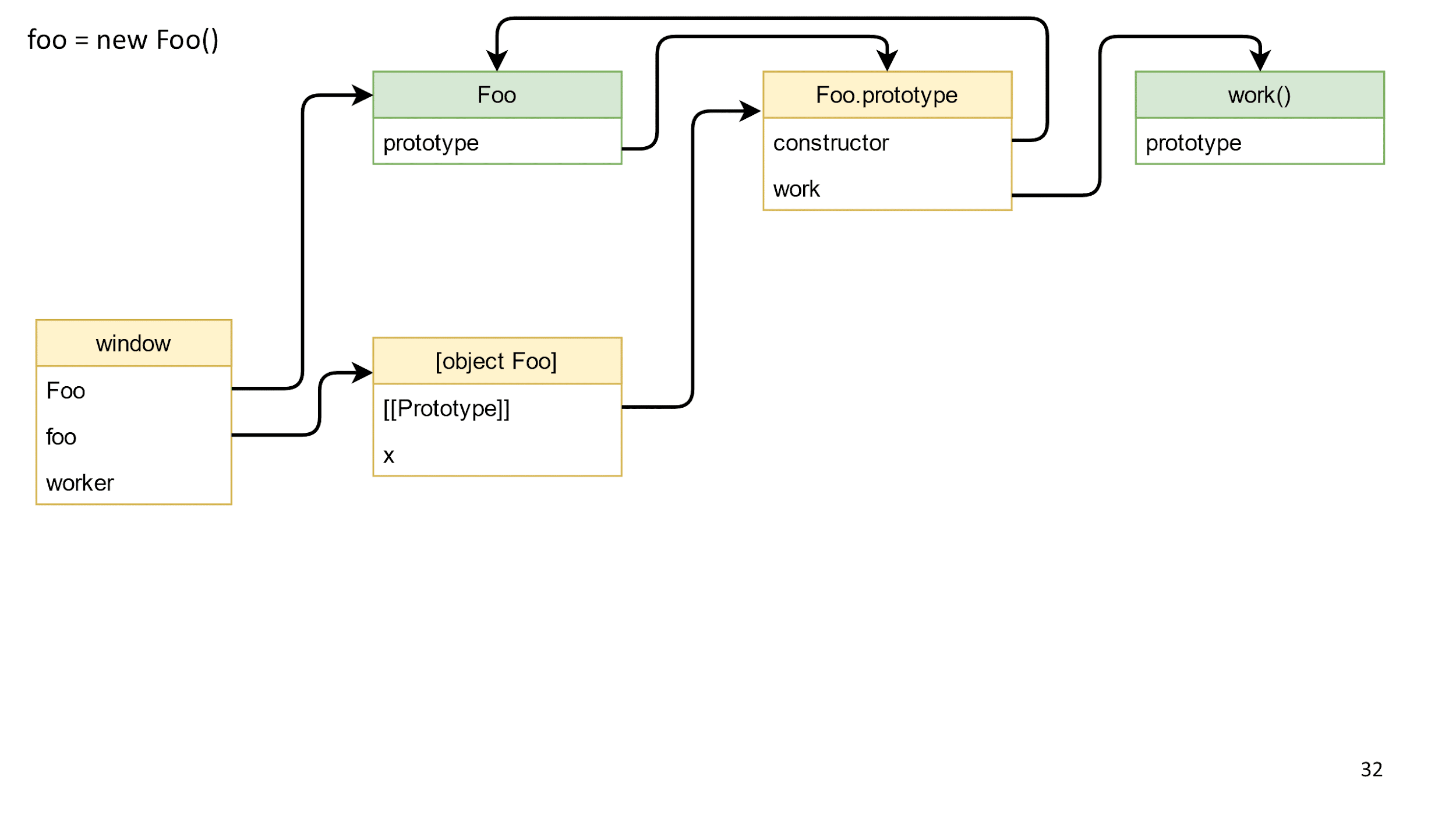
- Colocamos nossa classe na janela, porque as classes não chegam lá por padrão.
- Crie um objeto de classe.
- Criar um objeto expõe automaticamente o protótipo do objeto de classe no Foo.prototype. Portanto, quando você tenta chamar o método de trabalho em um objeto, ele saberá que tipo de trabalho é.
- Nosso construtor cria o campo x no objeto a partir do objeto com a string.
Aqui está o que aconteceu:
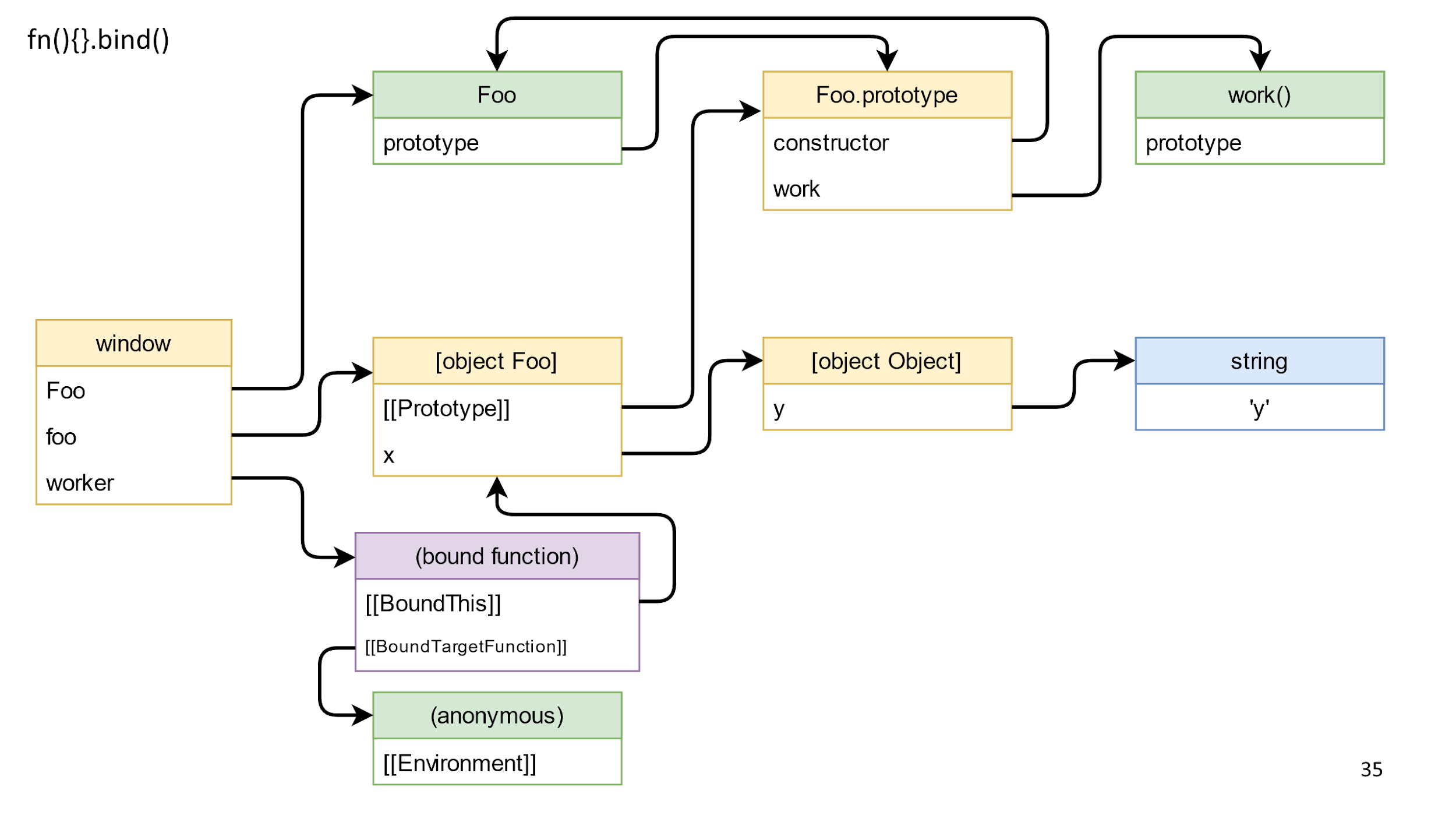
O método retorna uma função vinculada - este é um objeto “mágico” tão especial em JS, que consiste em uma ligação vinculada a isso e uma função que deve ser chamada. A função relacionada também possui um protótipo e outro protótipo, mas estamos interessados no fechamento. Por especificação, o fechamento é armazenado no ambiente. Provavelmente você está mais familiarizado com a palavra Escopo, mas
nas especificações o campo é chamado de Ambiente .
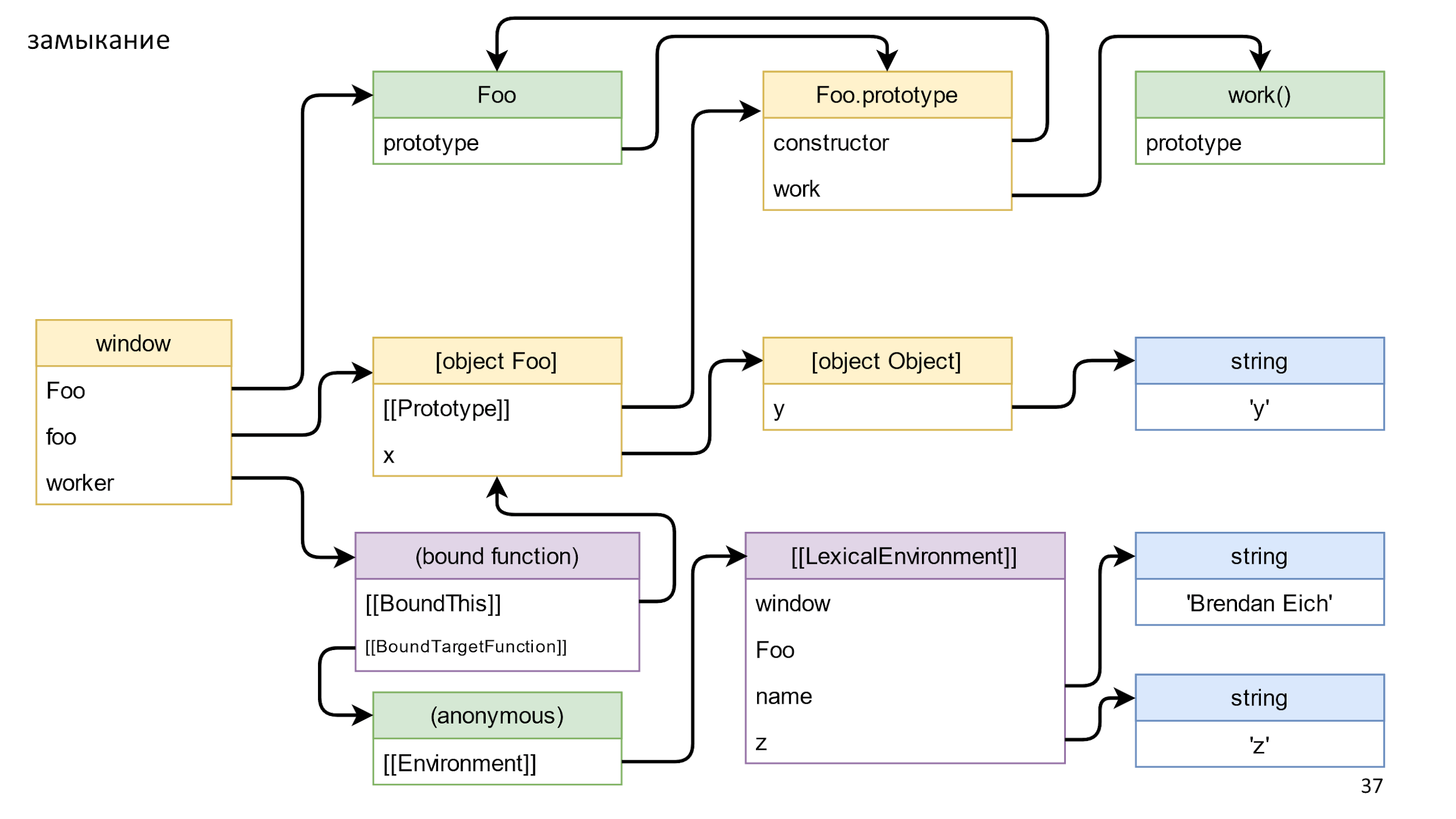
O Environment armazena uma referência ao LexicalEnvironment. Esse é um objeto complexo, mais complicado do que em um slide, que armazena links para tudo o que pode ser acessado a partir de uma função. Por exemplo, janela, Foo, nome ez. Ele também armazena links para o que você não está usando explicitamente. Por exemplo, você pode usar eval e acidentalmente objetos não utilizados, mas o JS não deve ser interrompido.
Então, nós construímos todos os objetos e agora vamos destruir tudo.
Exclua o link para o objeto
Vamos começar removendo o link para o objeto, esse link no diagrama é destacado em vermelho.
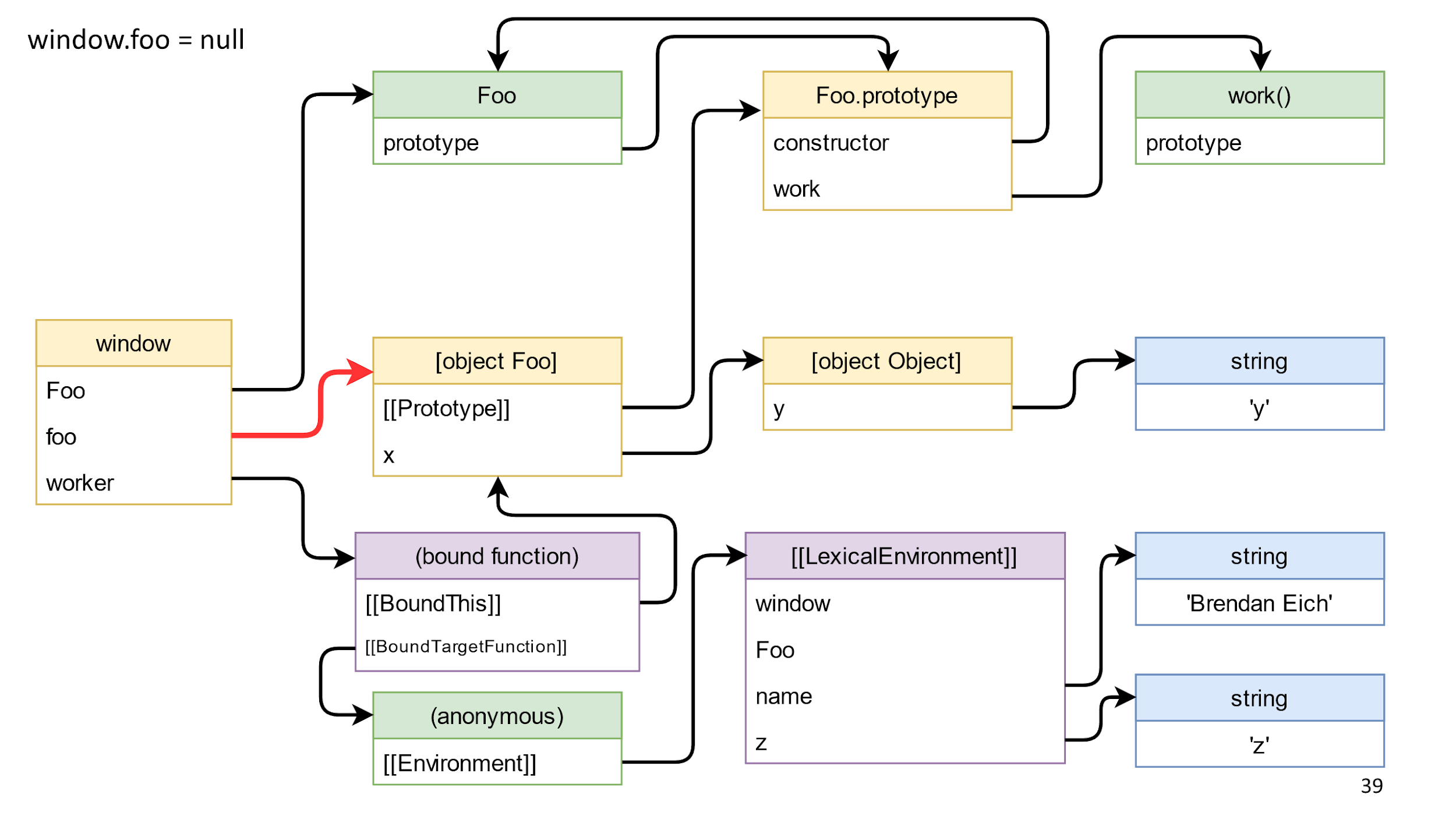
Excluímos e nada acontece, porque da
janela para o objeto existe um caminho através da
função de função
vinculada .
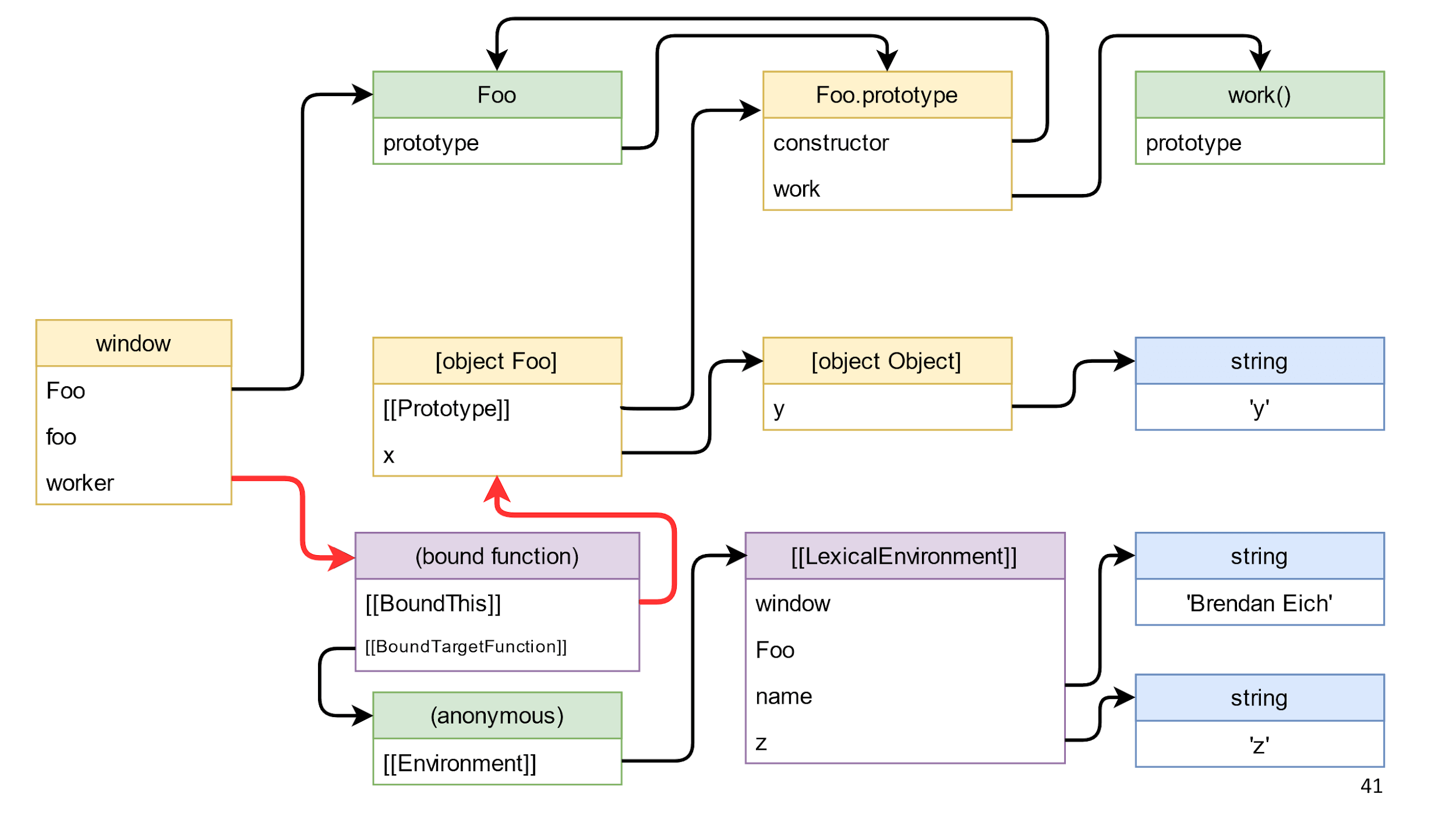
Isso nos leva a um erro típico.
Erro comum - assinatura esquecida
externalElement.addEventListener('click', () => { if (this.shouldDoSomethingOnClick) { this.doSomething(); } })
Ocorre quando você assina: usando
isso, explicitamente através das funções bind ou arrow; use algo no fechamento. Então você esquece de cancelar a inscrição e a vida útil do seu objeto ou o que está no circuito se torna o mesmo que a vida útil de uma assinatura. Por exemplo, se este é um elemento DOM em que você não toca, provavelmente é o tempo até o final da vida da página.
Para resolver esses problemas:
- Cancelar inscrição.
- Pense durante a vida útil da assinatura e quem é o proprietário.
- Se, por algum motivo, você não puder cancelar a inscrição, anule os links (qualquer que seja = nulo) ou limpe todos os campos do objeto. Se o seu objeto vazar, ele será pequeno e não será uma pena.
- Use o WeakMap, talvez isso ajude em algumas situações.
Exclua a referência da classe
Vá em frente e tente remover o link vermelho destacado da classe.
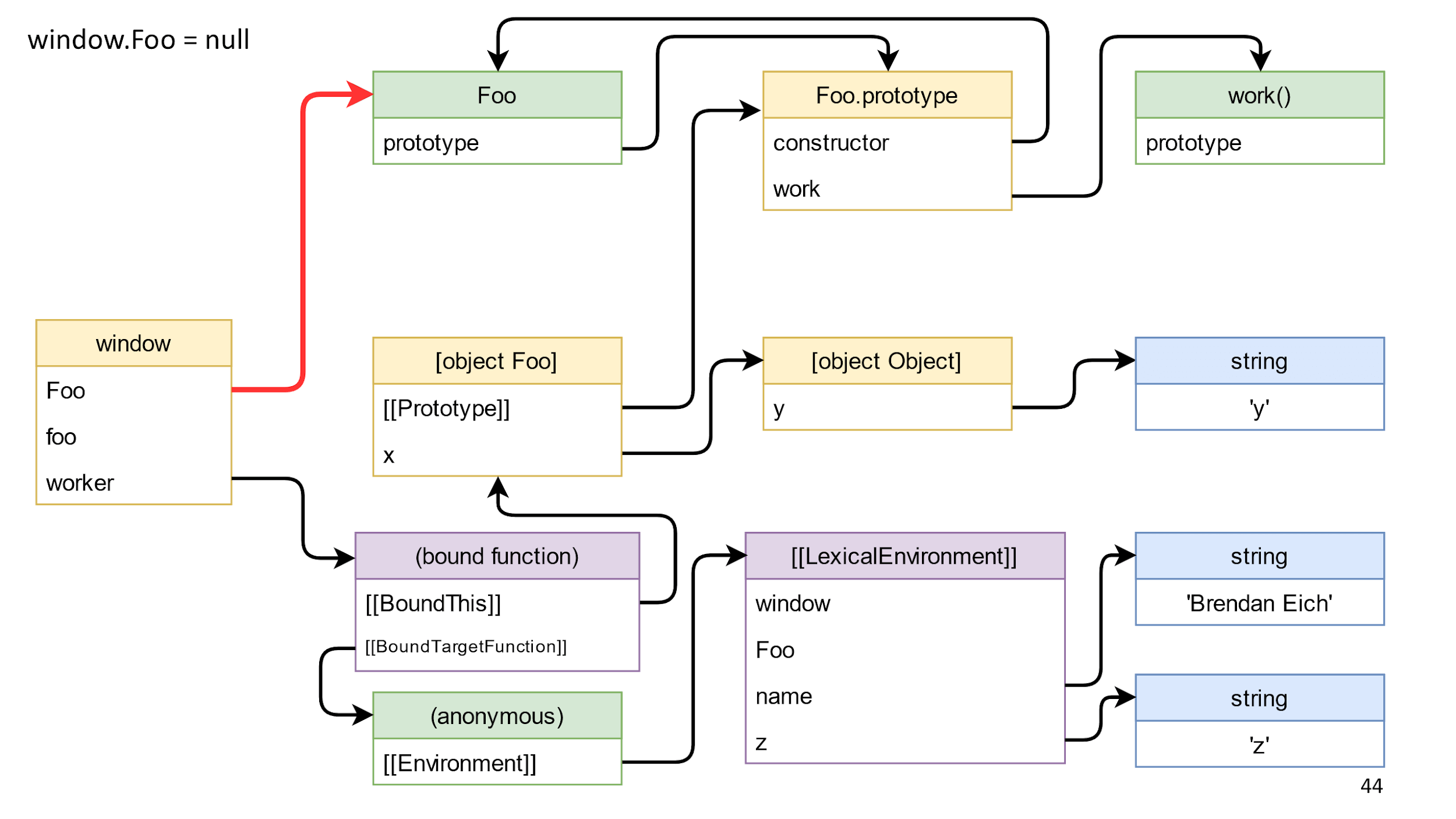
Excluímos o link e nada muda para nós. O motivo é que a classe é acessível através do BoundThis, no qual existe um link para o protótipo, e no protótipo existe um link para o construtor.
Erro típico trabalho inútil
Por que todas essas demonstrações são necessárias? Porque existe um outro lado do problema quando as pessoas seguem o conselho para anular links muito literalmente e anular tudo em geral.
destroy() { this._x = null; this._y = null;
Este é um trabalho inútil. Se o objeto consistir apenas em referências a outros objetos e não houver recursos, não será necessário destruir (). Basta perder a referência ao objeto, e ele morre por conta própria.
Não há conselho universal. Quando for necessário, anule e, quando não, não anule. Zerar não é um erro, mas simplesmente um trabalho inútil.
Vá em frente. Chame o método da função bound e ele removerá o link de [object Foo] para [object Object]. Isso levará ao fato de que objetos que estão separados em um retângulo azul aparecem no diagrama.
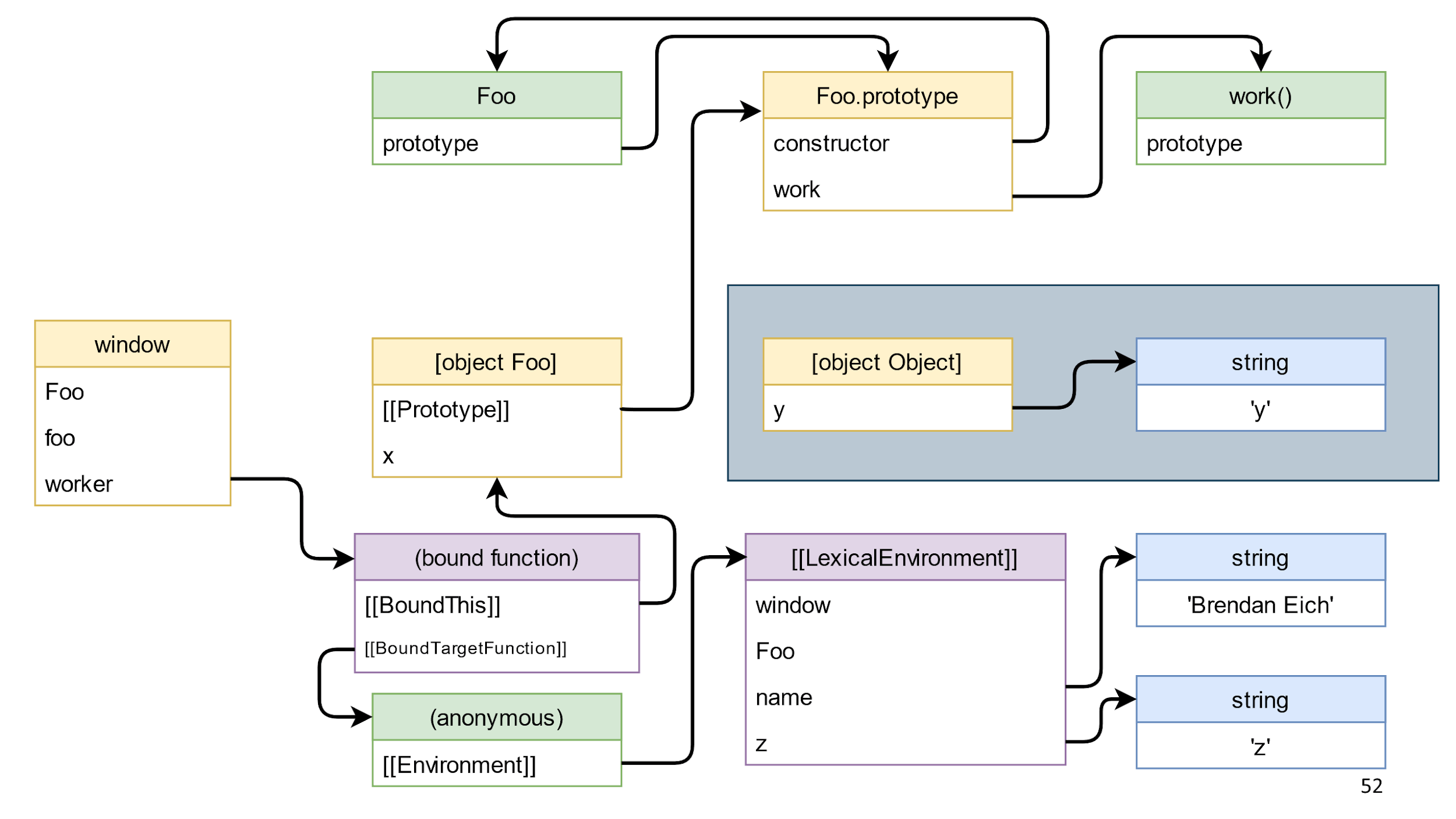
Esses objetos são lixo JS. Ele está indo muito bem. No entanto, há lixo que não pode ser coletado.
Lixo que não vai
Em muitas APIs do navegador, você pode criar e destruir um objeto. Se o objeto não for destruído, nenhum coletor poderá montá-lo.
Objetos com funções de criar / excluir pares:
- createObjectURL (), revokeObjectURL ();
- WebGL: criar / excluir Programa / Shader / Buffer / Textura / etc;
- ImageBitmap.close ();
- indexDb.close ().
Por exemplo, se você esquecer de excluir o ObjectURL de um vídeo de 200 MB, esses 200 MB permanecerão na memória até o final da vida útil da página e ainda mais, porque há troca de dados entre as guias. Da mesma forma, no WebGL, indexDb e outras APIs do navegador com recursos semelhantes.
Felizmente, em nosso exemplo, o retângulo azul contém apenas objetos JavaScript, portanto, isso é apenas lixo que pode ser removido.
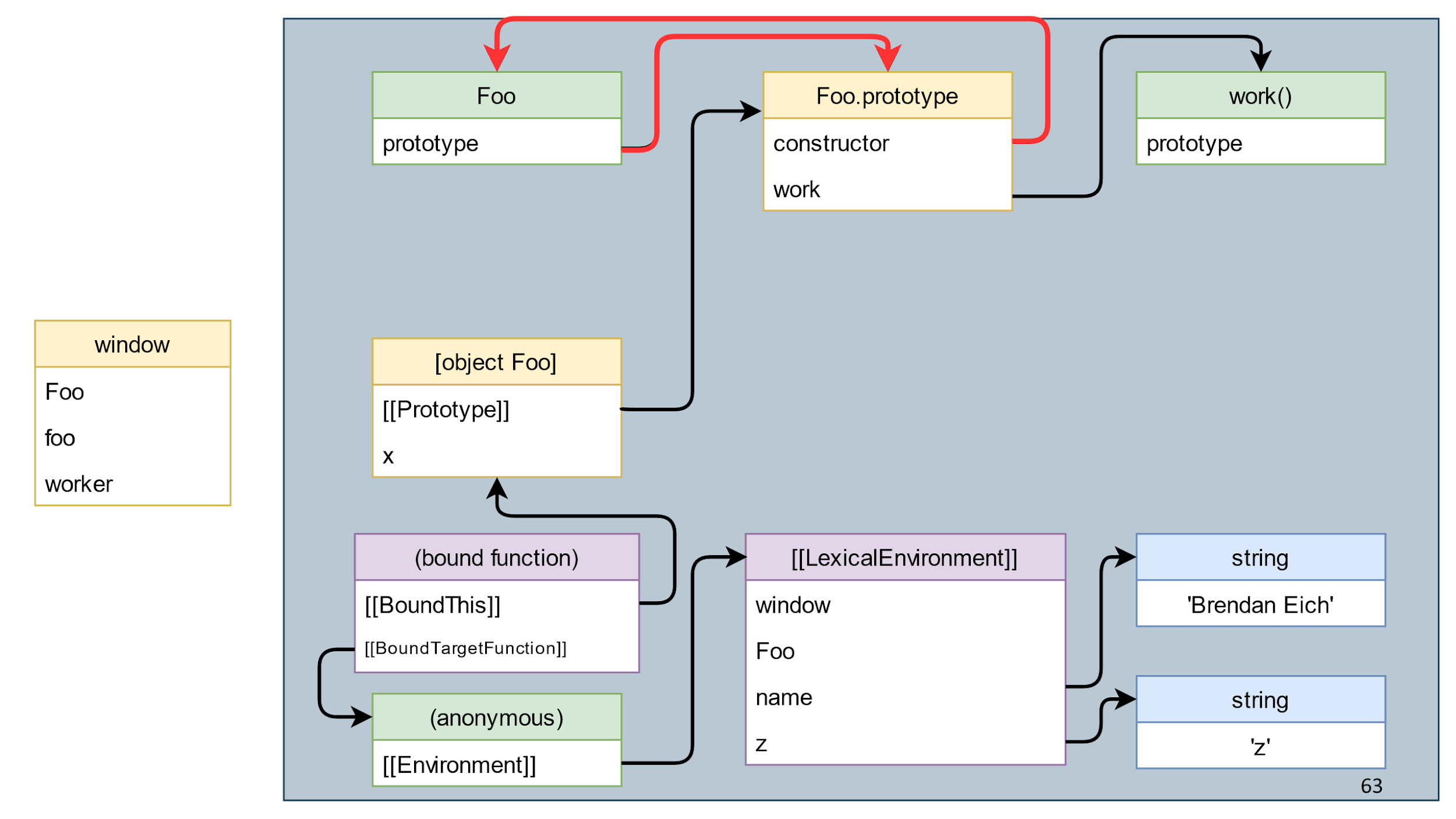
O próximo passo é limpar o último link da esquerda para a direita. Esta é uma referência ao método que recebemos, uma função relacionada.
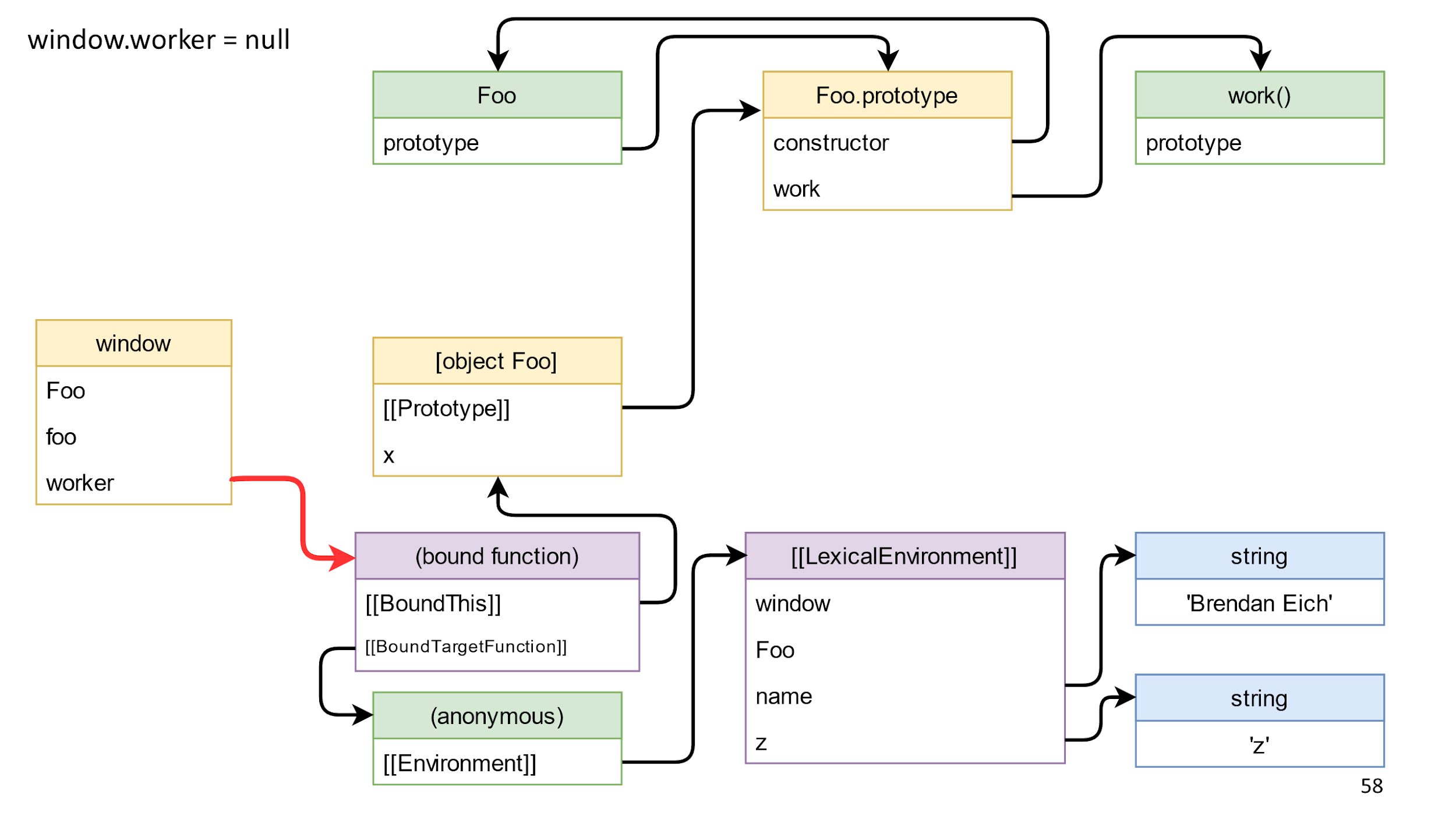
Após a sua remoção, não teremos links esquerdo e direito? De fato, ainda existem links do fechamento.
É importante que não haja links da esquerda para a direita; portanto, tudo, exceto a janela, é lixo e ele morre.
Nota importante : há referências circulares no lixo, ou seja, objetos que se referem um ao outro. A presença desses links não afeta nada, porque o coletor de lixo não coleta objetos individuais, mas todo o lixo.
Vimos os exemplos e agora, em um nível intuitivo, entendemos o que é lixo, mas vamos dar uma definição completa do conceito.
Lixo é tudo que não é um objeto vivo.
Tudo ficou muito claro. Mas o que é um objeto vivo?
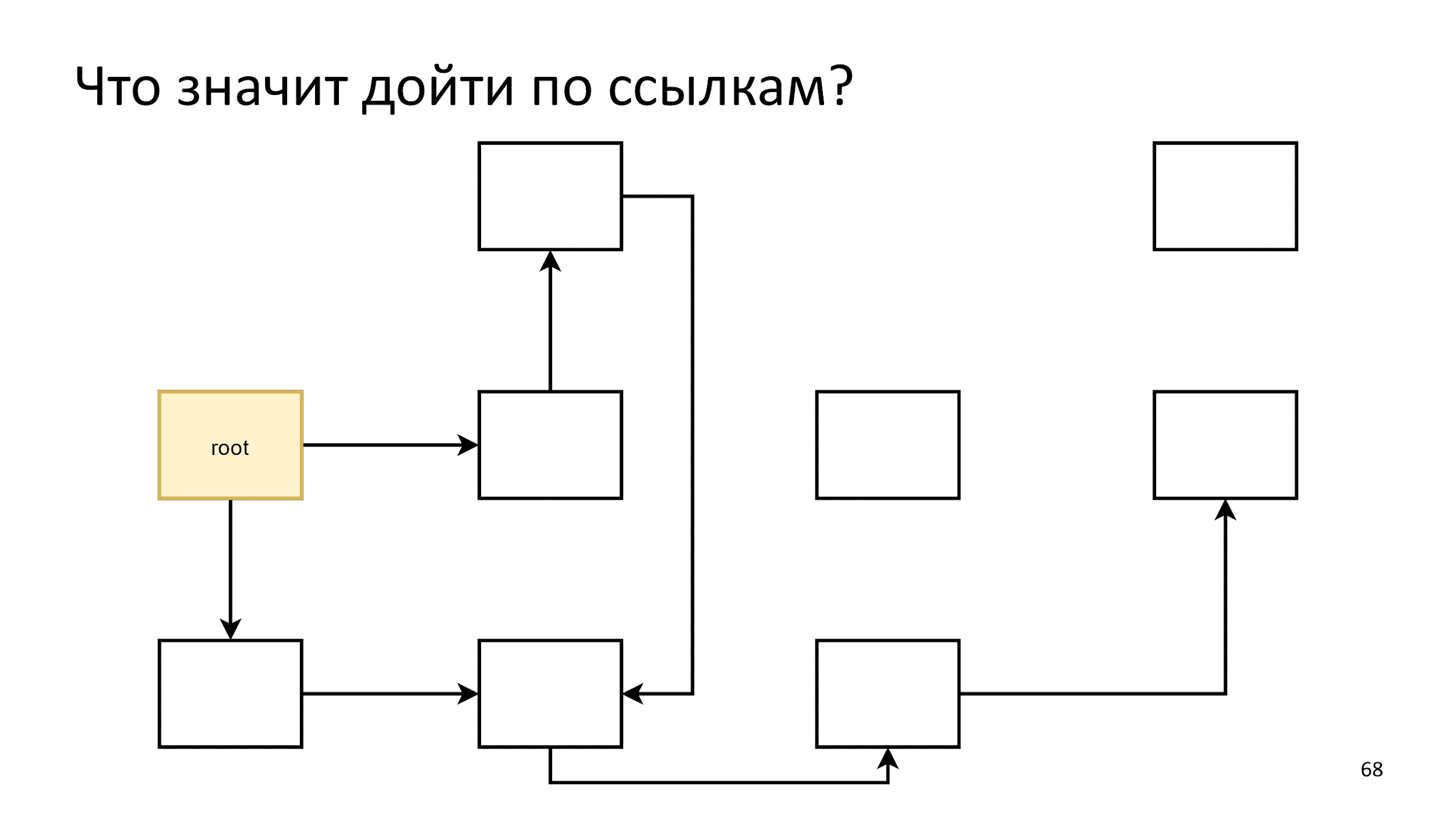
Um objeto vivo é um objeto que pode ser acessado por links do objeto raiz.Dois novos conceitos aparecem: "siga links" e "objeto raiz". Um objeto raiz que já conhecemos é window, então vamos começar com os links.
O que significa seguir os links?
Existem muitos objetos relacionados entre si e que se referem um ao outro. Vamos acenar ao longo deles, começando com o objeto raiz.
Inicializamos o primeiro passo e, em seguida, procedemos de acordo com o seguinte algoritmo: digamos que tudo na crista da onda seja objetos vivos e vejamos a que eles se referem.
Inicializamos o primeiro passo. Em seguida, agiremos de acordo com o seguinte algoritmo: digamos que tudo que está amarelo na crista da onda seja um objeto vivo e vejamos a que eles se referem.
A que eles se referem, faremos uma nova crista da onda:
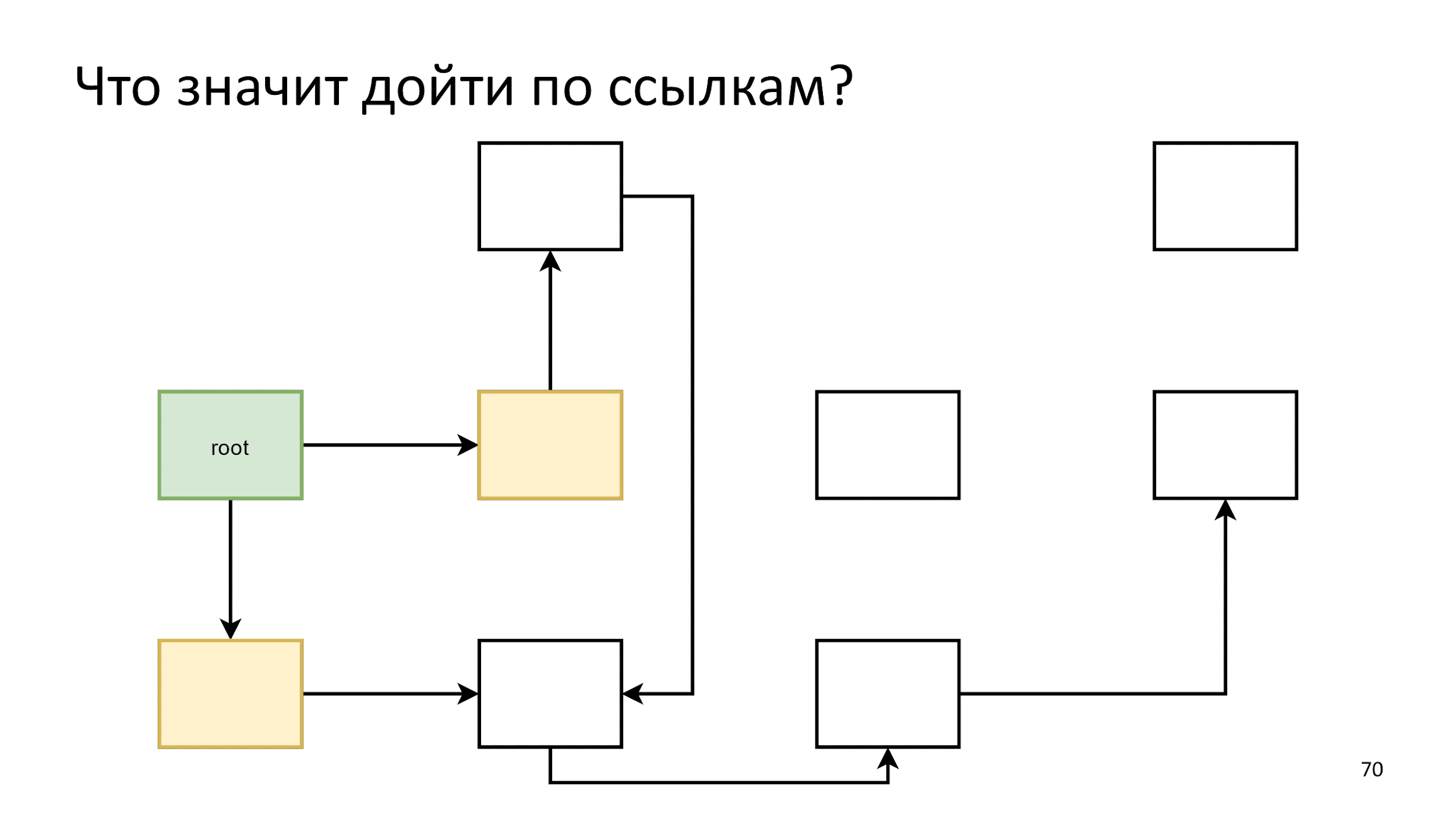
Concluído e começar de novo:
- Estamos revivendo.
- Nós olhamos para o que eles se referem.
- Crie uma nova crista de onda, anime objetos.
- Nós olhamos para o que eles se referem.
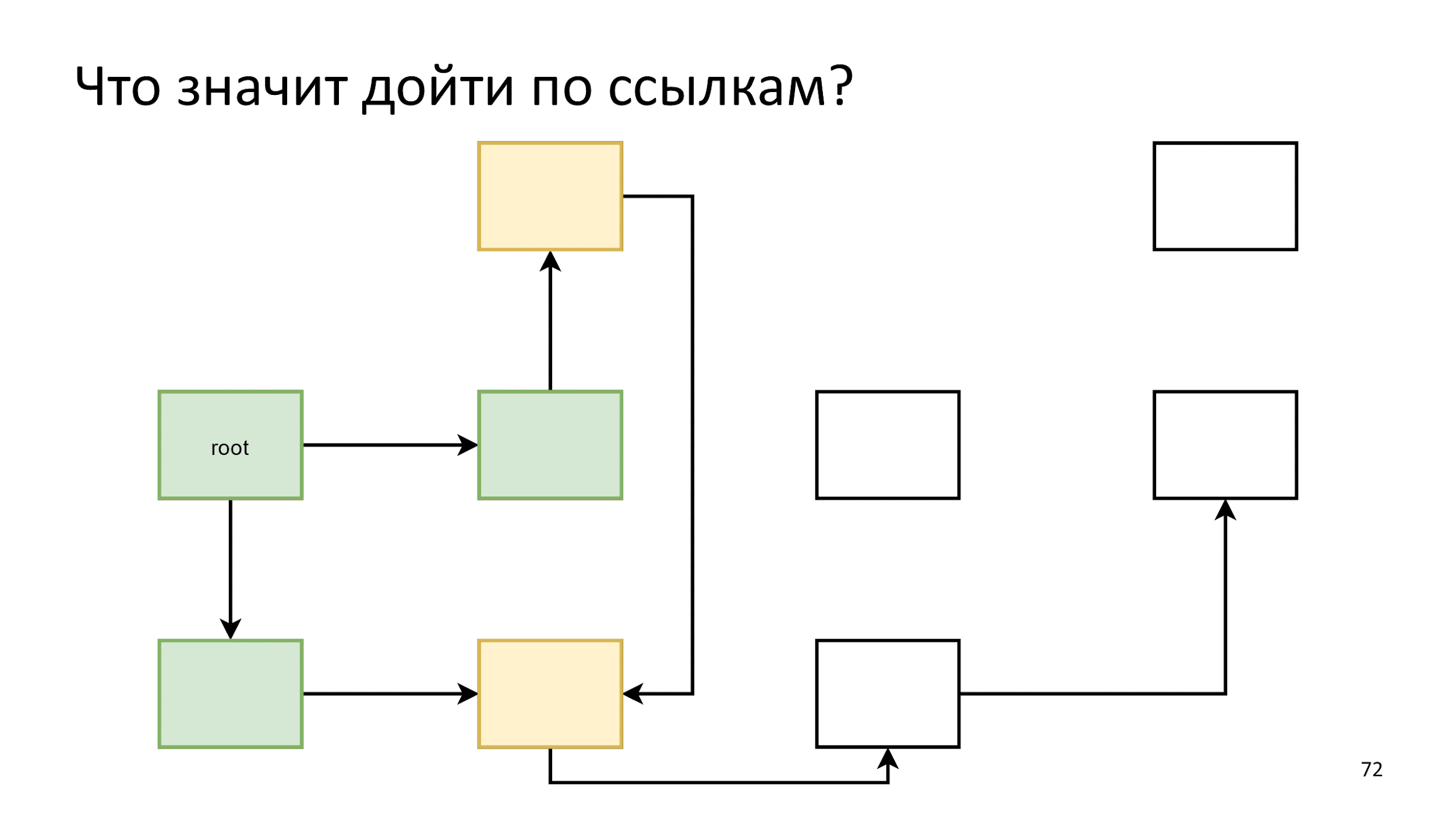
Percebendo que uma flecha aponta para um objeto já vivo, simplesmente não fazemos nada. Ainda de acordo com o algoritmo, até que os objetos a percorrer sejam esgotados. Então dizemos que encontramos todos os objetos vivos e todo o resto é lixo.
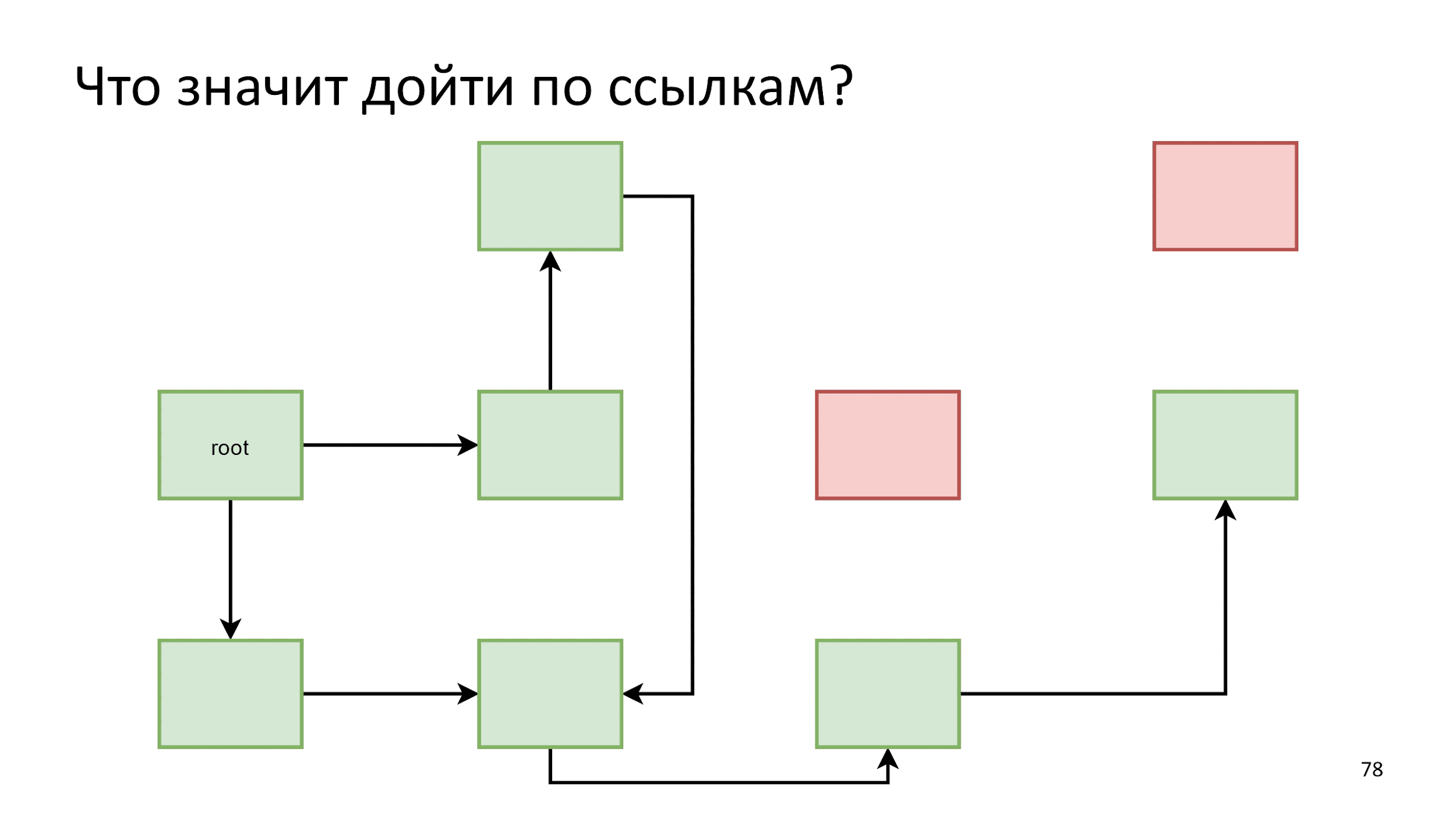
Esse processo é chamado de
marcação .
O que o objeto raiz significa?
- Janela
- Quase todas as APIs do navegador.
- Toda promessa.
- Tudo o que é colocado em Microtask e Macrotask.
- Observadores de mutação, RAF, retornos de chamada ociosa. Tudo o que pode ser alcançado a partir do que está no RAF não pode ser excluído, porque se você excluir o objeto usado no RAF, provavelmente haverá algo errado.
A montagem pode ocorrer a qualquer momento. Toda vez que chaves ou funções aparecem, um novo objeto é criado. Pode não haver memória suficiente, e o coletor irá procurar de graça:
function foo (a, b, c) { function bar (x, y, z) { const x = {};
Nesse caso, os objetos raiz serão tudo na pilha de chamadas. Se você, por exemplo, parar na linha com X e excluir o que Y se refere, seu aplicativo falhará. JS não nos permite tais frivolidades, portanto você não pode excluir um objeto de Y.
Se a parte anterior parecia complicada, será ainda mais difícil.
Realidade dura
Vamos falar sobre o mundo das máquinas em que lidamos com ferro, com mídia física.
A memória é uma grande matriz na qual apenas números estão, por exemplo: new Uint32Array (16 * 2 ** 30).
Vamos criar objetos na memória e adicioná-los da esquerda para a direita. Criamos um, segundo, terceiro - todos são de tamanhos diferentes. Colocamos links ao longo do caminho.
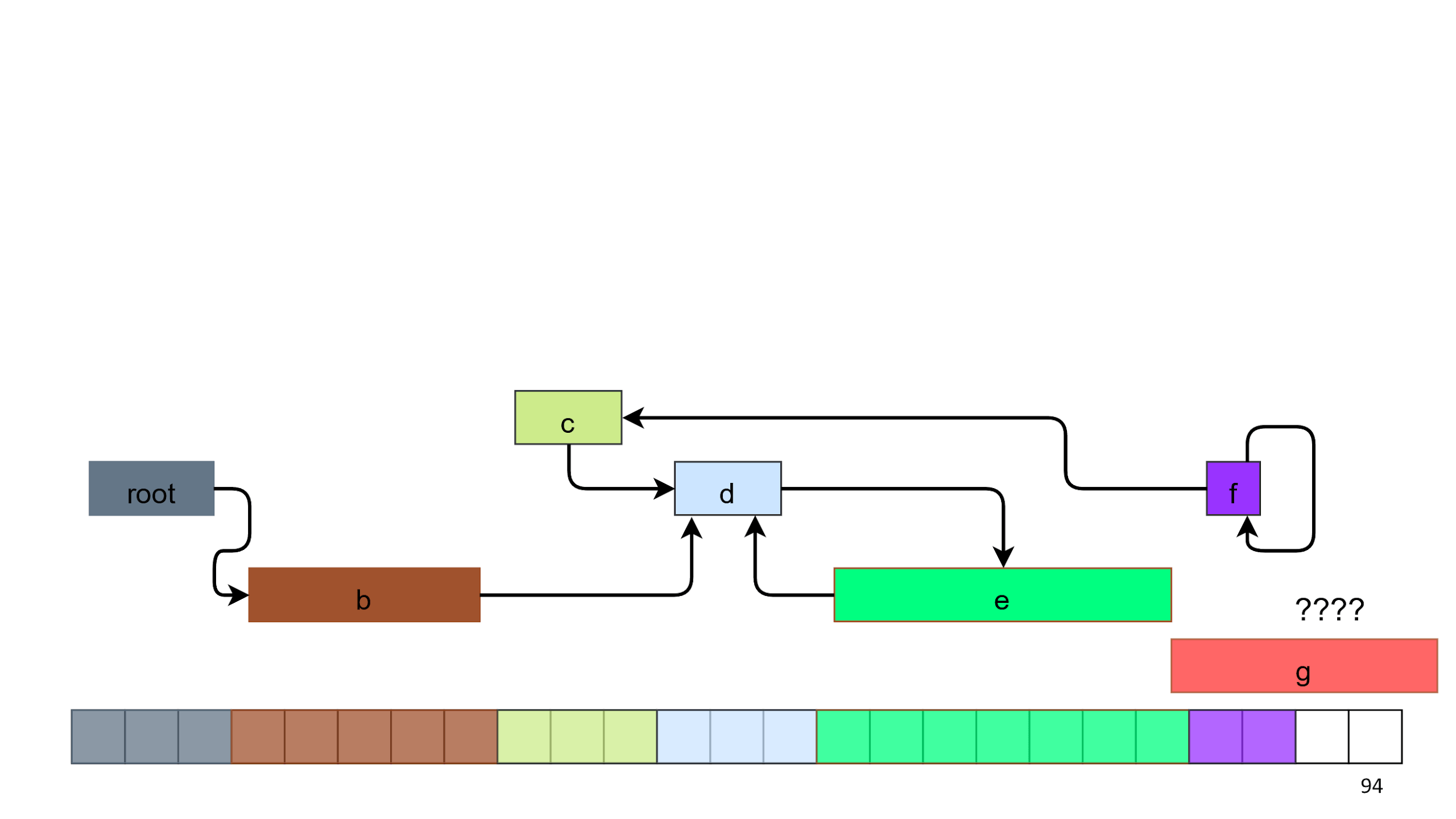
No sétimo objeto, o local terminou, porque temos 2 quadrados livres, mas precisamos de 5.
O que pode ser feito aqui? A primeira opção é travar. No quintal de 2018, todos têm os últimos MacBooks e 16 GB de RAM. Não há situações em que não há memória!
No entanto, deixar as coisas seguirem seu curso é uma péssima idéia, porque na web isso leva a uma tela semelhante:
Este não é o comportamento que queremos do programa, mas em geral é válido. Há uma categoria de colecionadores chamada
No-op .
Coletor não operacional
Prós:
- O colecionador é muito simples.
- Simplesmente não há coleta de lixo.
- Não há necessidade de escrever ou pensar em memória.
Contras:
- Tudo cai para que nunca mais suba.
Para o front-end, o coletor não operacional é irrelevante, mas é usado no back-end. Por exemplo, tendo vários servidores atrás dos balanceadores, o aplicativo recebe 32 GB de RAM e, em seguida, é completamente eliminado. É mais simples e o desempenho é aprimorado apenas reiniciando quando a memória fica baixa.
Na web, é impossível e você precisa limpá-lo.
Pesquisar e excluir lixo
Começamos a limpar com lixo. Nós já sabemos como fazê-lo. Lixo - objetos C e F no esquema anterior, porque você não pode alcançá-los ao longo das setas do objeto raiz.
Pegamos esse lixo, alimentamos com o amante do lixo e pronto.
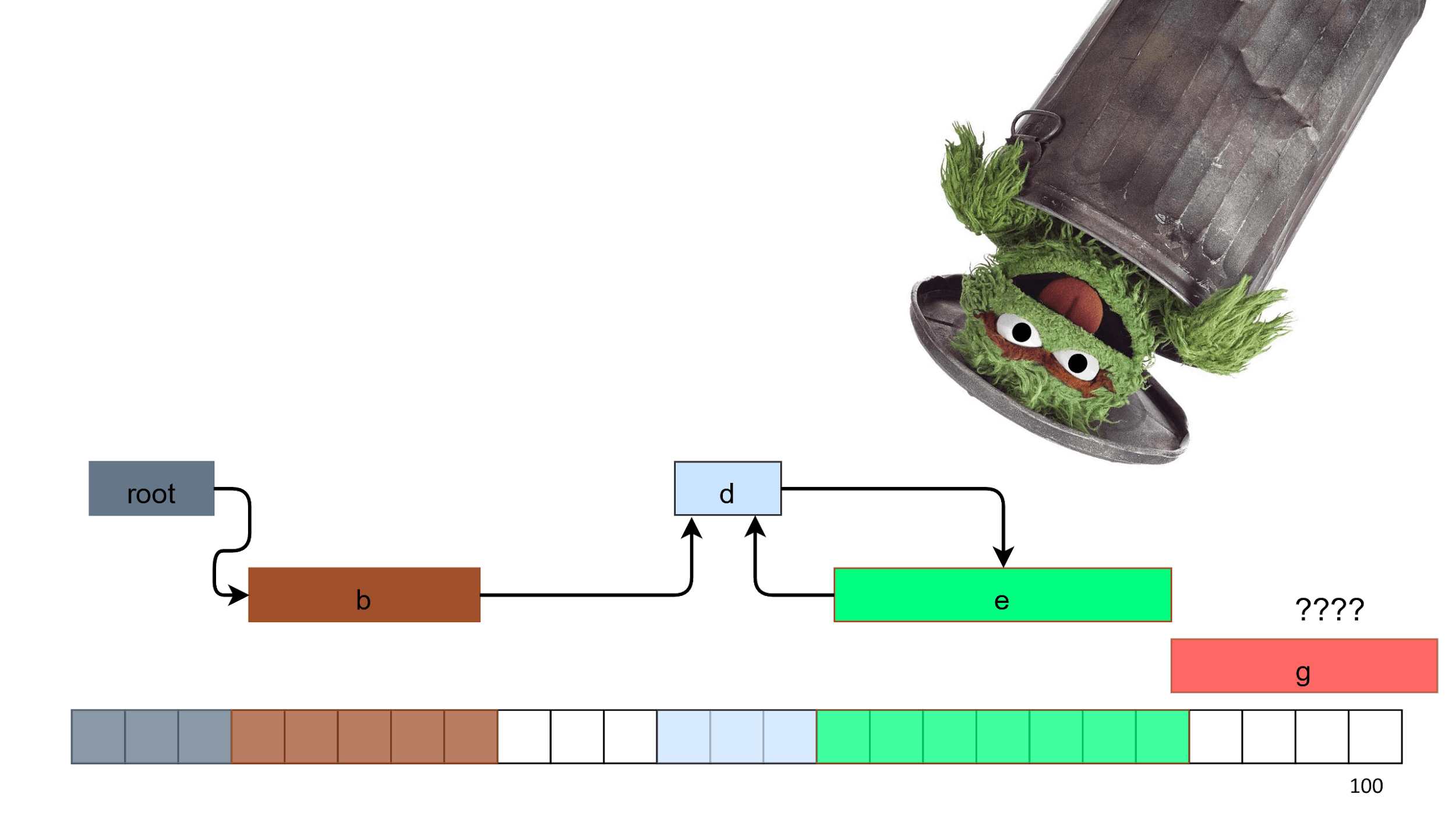
Após a limpeza, o problema não é resolvido, pois os furos permanecem na memória. Observe que existem 7 quadrados livres, mas 5 deles ainda não podemos alocar. Ocorreu fragmentação e a montagem terminou. Esse algoritmo com furos é chamado de
Mark and Sweep .
Marcar e varrer
Prós:
- Um algoritmo muito simples. Uma das primeiras que você aprenderá se começar a aprender sobre o coletor de lixo.
- Funciona proporcionalmente à quantidade de lixo, mas só lida quando há pouco lixo.
- Se você tem apenas objetos vivos, ele não perde tempo e simplesmente não faz nada.
Contras:
- Requer lógica complexa para procurar espaço livre, porque quando há muitos buracos na memória, é necessário tentar um objeto em cada um para entender se ele se encaixa ou não.
- Fragmenta a memória. Pode ocorrer uma situação em que, com 200 MB livres, a memória é dividida em pequenos pedaços e, como no exemplo acima, não há um pedaço sólido de memória para o objeto.
Estamos à procura de outras ideias. Se você olhar para a figura e pensar, o primeiro pensamento é mudar tudo para a esquerda. À direita, haverá uma peça grande e livre, na qual nosso objeto se ajustará calmamente.
Existe um algoritmo desse tipo e é chamado de
Mark e Compact .
Marca e compacta
Prós:
- Desfragmente a memória.
- Funciona proporcionalmente ao número de objetos vivos, o que significa que pode ser usado quando praticamente não há detritos.
Contras:
- Difícil no trabalho e na implementação.
- Move objetos. Nós movemos o objeto, copiámo-lo, agora ele está em um local diferente e toda a operação é bastante cara.
- Requer 2-3 passagens na memória, dependendo da implementação - o algoritmo é lento.
Aqui chegamos a outra ideia.
A coleta de lixo não é gratuita
Nas APIs de alto desempenho, como WebGL, WebAudio e WebGPU, que ainda estão em desenvolvimento, os objetos são criados e excluídos em fases separadas. Essas especificações foram escritas para que a coleta de lixo não esteja em andamento. Além disso, não há nem promessa lá, mas pull () - você apenas pergunta a cada quadro: “Algo aconteceu ou não?”.
Semispace aka Lisp 2
Há outro colecionador sobre o qual quero falar. E se você não liberar memória, mas copiar todos os objetos vivos de algum lugar para outro lugar.
Vamos tentar copiar o objeto raiz "como está", que se refere a algum lugar.
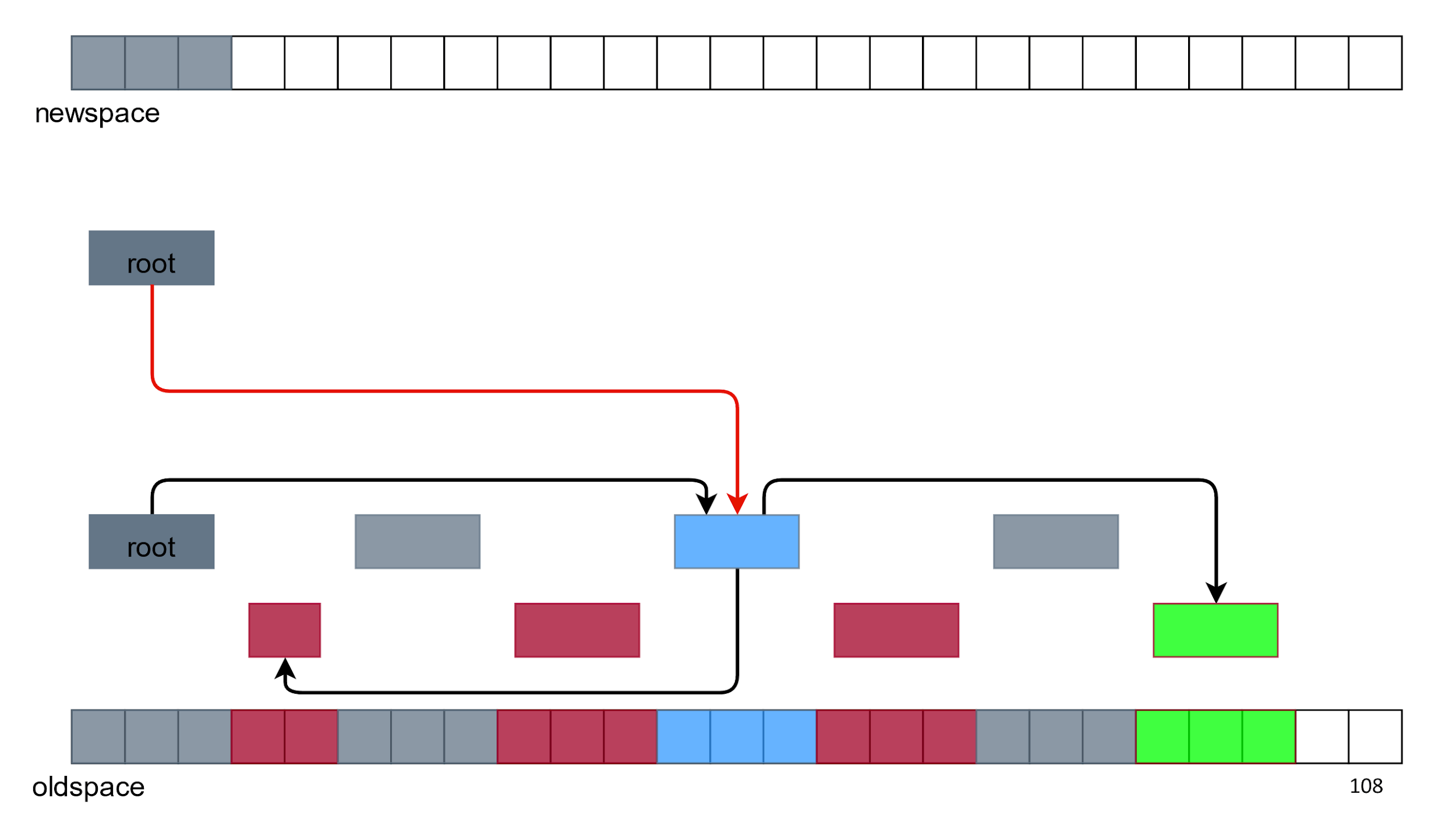
E então todo mundo.
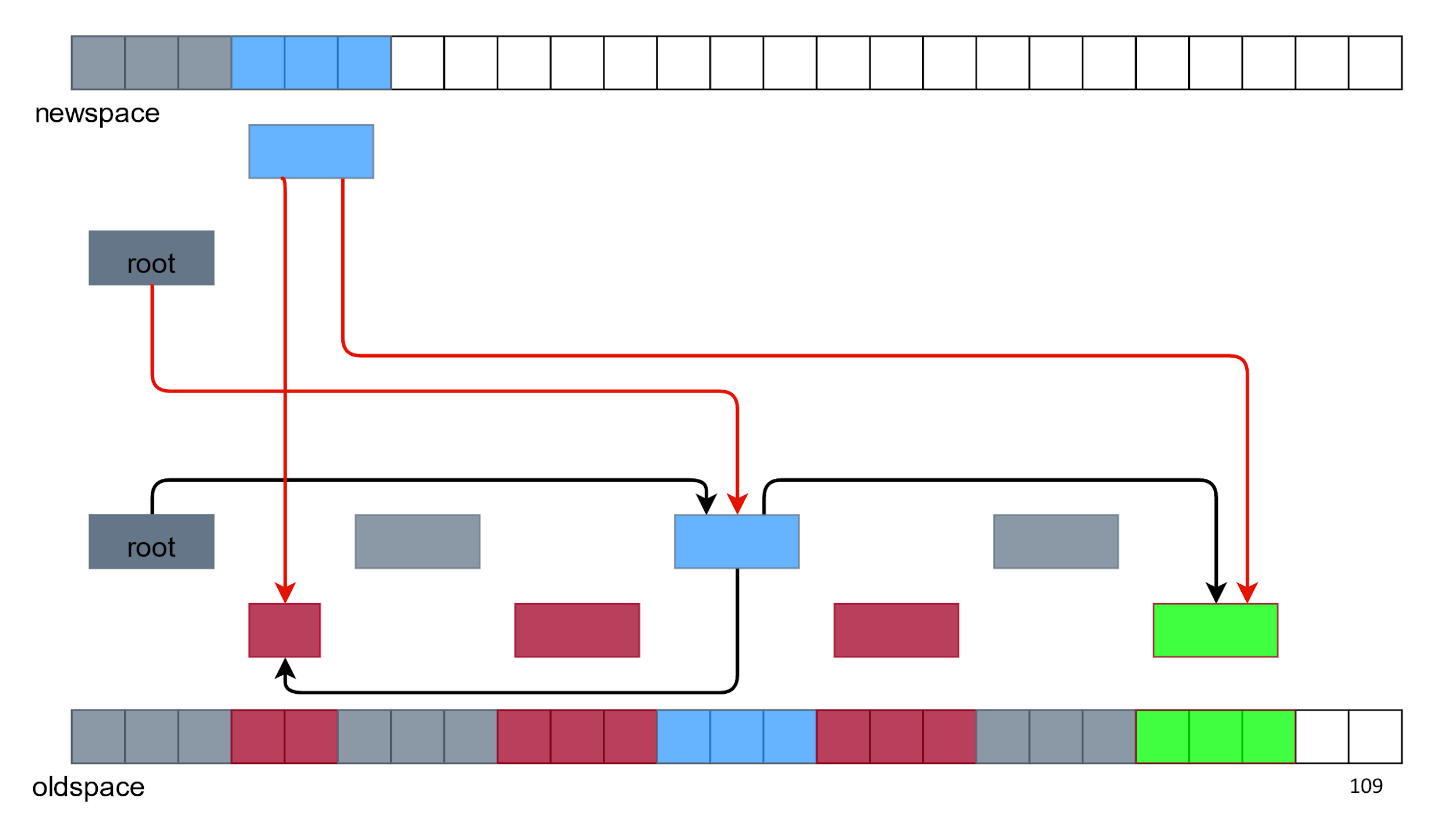
Não há detritos ou furos na memória acima. Tudo parece estar bem, mas surgem dois problemas:
- Objetos duplicados - temos dois objetos verdes e dois azuis. Qual usar?
- Links de novos objetos levam a objetos antigos, e não um ao outro.
Com os links, tudo é resolvido com a ajuda de uma “mágica” algorítmica especial, e podemos lidar com a duplicação de objetos excluindo tudo abaixo.
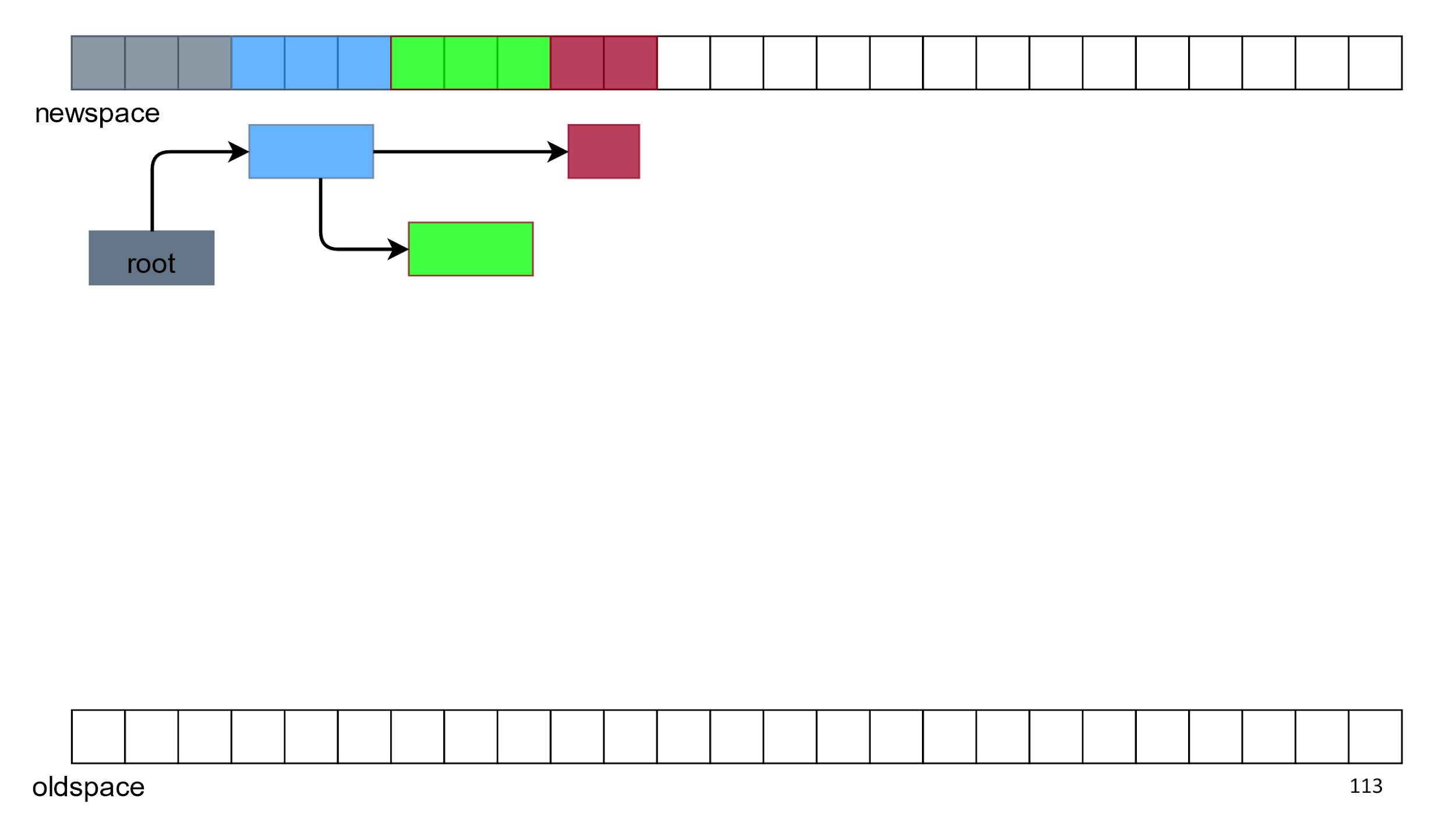
Como resultado, temos espaço livre e apenas objetos vivos na ordem normal acima. Esse algoritmo é chamado
Semispace ,
Lisp 2, ou simplesmente o "coletor de cópias".
Prós:
- Desfragmente a memória.
- Simples.
- Pode ser combinado com uma fase de derivação.
- Funciona proporcionalmente ao número de objetos vivos ao longo do tempo.
- Funciona bem quando há muito lixo. Se você tiver 2 GB de memória e 3 objetos, ignorará apenas 3 objetos e os 2 GB restantes parecem ter acabado.
Contras:
- Consumo de memória dupla. Você usa a memória 2 vezes mais que o necessário.
- Mover objetos também não é uma operação muito barata.
Nota: coletores de lixo podem mover objetos.
Na web, isso é irrelevante, mas no Node.js é bastante. Se você escrever a extensão em C ++, o idioma não saberá tudo sobre isso; portanto, haverá links duplos lá chamados handle e se parecerão com isso: v8 :: Local <v8 :: String>.
Portanto, se você estiver escrevendo plugins para o Node.js, as informações serão úteis.
Resumimos os diferentes algoritmos com seus prós e contras na tabela. Ele também tem um algoritmo Eden, mas mais tarde.

Eu realmente quero um algoritmo sem contras, mas isso não é. Portanto, tomamos o melhor de todos os mundos: usamos vários algoritmos ao mesmo tempo. Em um pedaço de memória, coletamos lixo com um algoritmo e em outro com outro algoritmo.
Como entender a eficácia do algoritmo em tal situação?
Podemos usar o conhecimento de maridos inteligentes dos anos 60 que analisaram todos os programas e perceberam:
Hipótese geracional fraca: a maioria dos objetos morre jovem.
Eles queriam dizer que todos os programas apenas produzem lixo. Na tentativa de usar o conhecimento, chegaremos ao que é chamado de “assembléia por gerações”.
Montagem geracional
Criamos dois pedaços de memória que não estão conectados de forma alguma: à esquerda é Eden e à direita está lento Mark and Sweep. No Éden, criamos objetos. Muitos objetos.
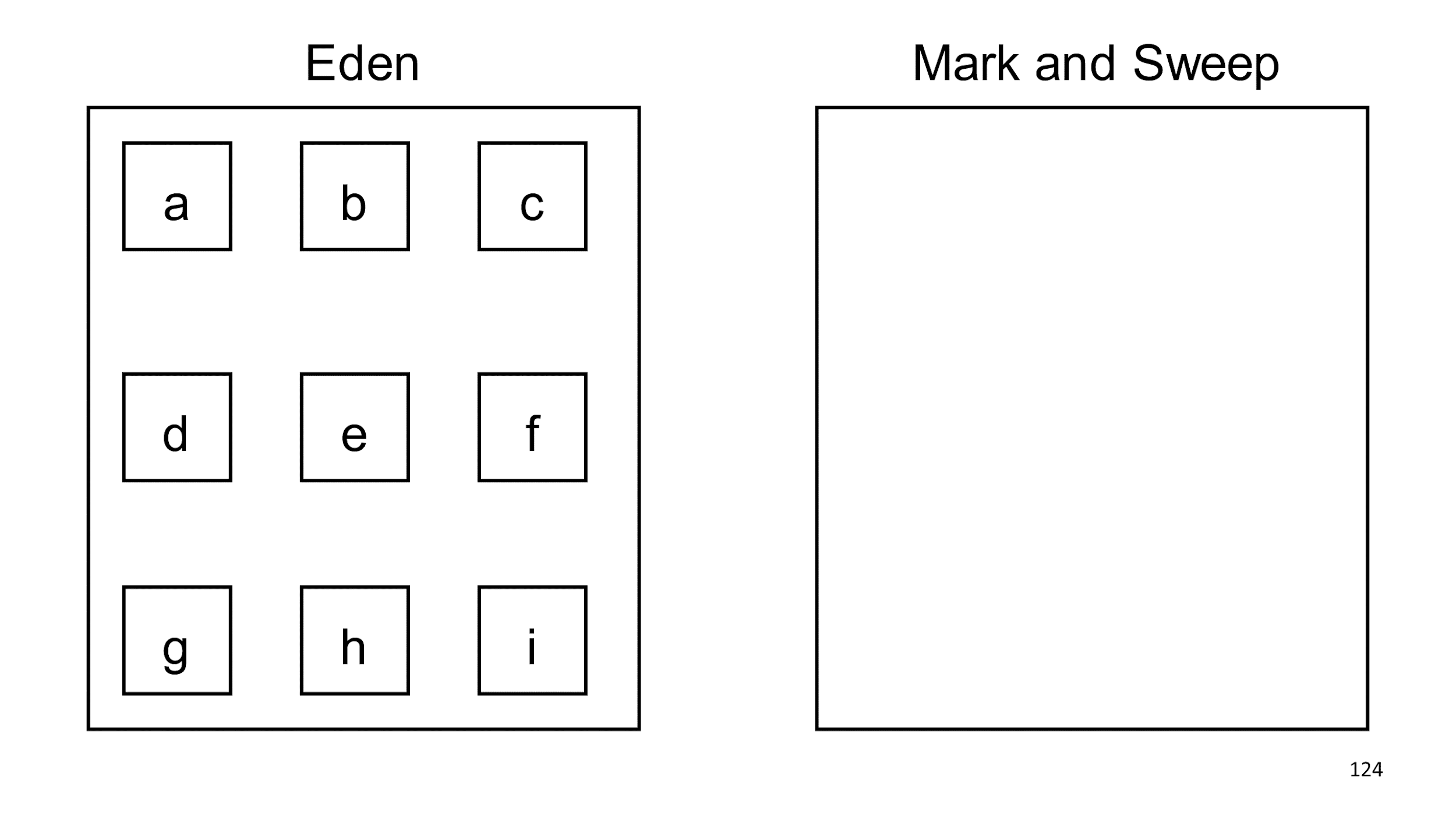
Quando o Eden diz que está cheio, iniciamos a coleta de lixo. Encontramos objetos ativos e os copiamos para outro colecionador.
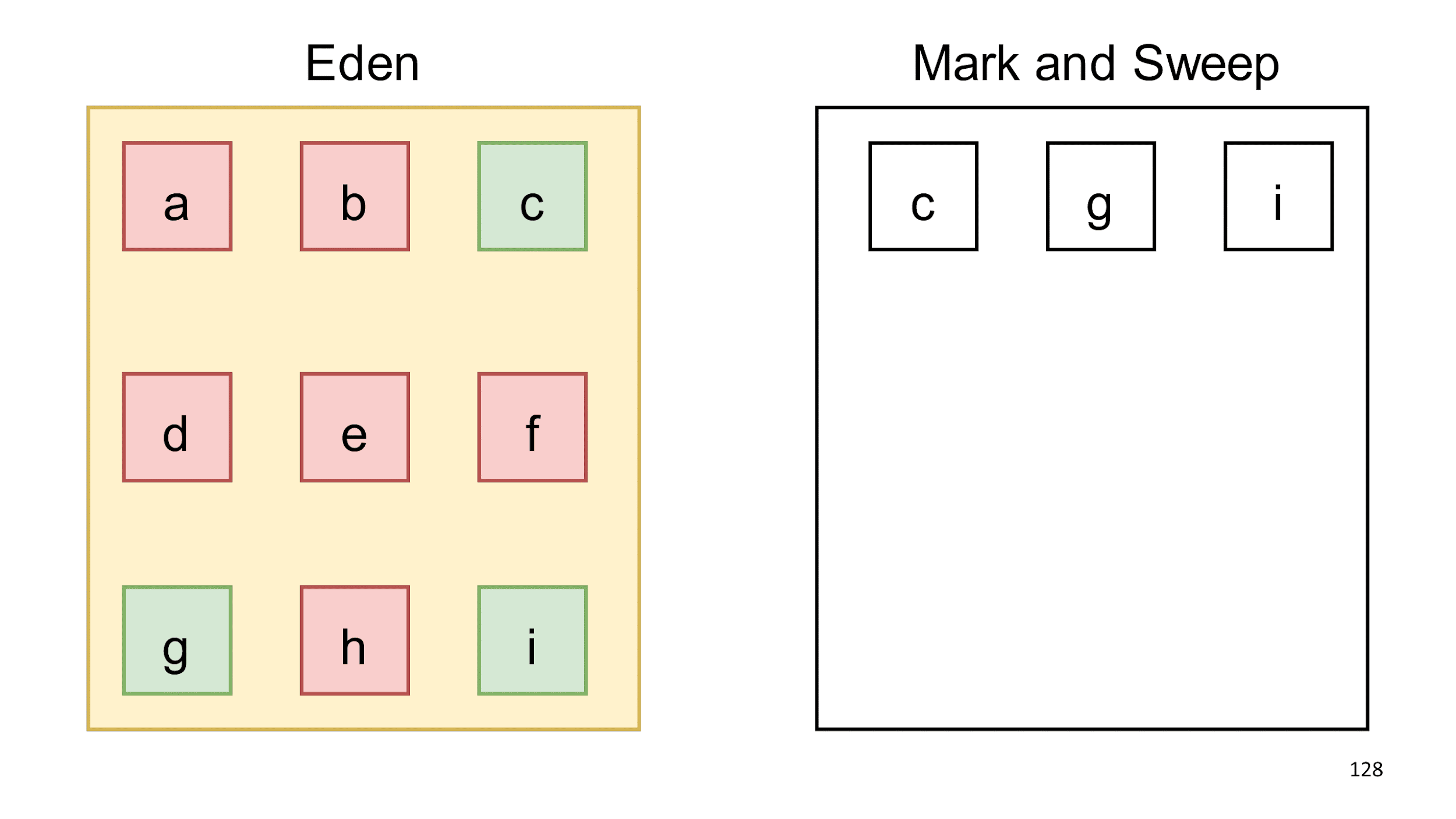
O próprio Eden é completamente limpo, e podemos adicionar objetos a ele.
Baseando-se na hipótese de gerações, decidimos que os objetos c, g, i provavelmente viverão por muito tempo e você poderá verificá-los com menos frequência. Conhecendo essa hipótese, você pode escrever programas que enganam o coletor. Isso pode ser feito, mas não o aconselho, porque quase sempre leva a efeitos indesejáveis. Se você criar lixo de longa duração, o coletor começará a acreditar que ele não precisa ser coletado.
Um exemplo clássico de trapaça é o cache LRU. Um objeto fica no cache por um longo tempo, o coletor o observa e acredita que ainda não o coletará, porque o objeto permanecerá por muito tempo. Em seguida, um novo objeto entra no cache e um grande e antigo é empurrado para fora dele e não é mais possível montar imediatamente esse objeto grande.
Como coletar agora sabemos. Fale sobre quando coletar.
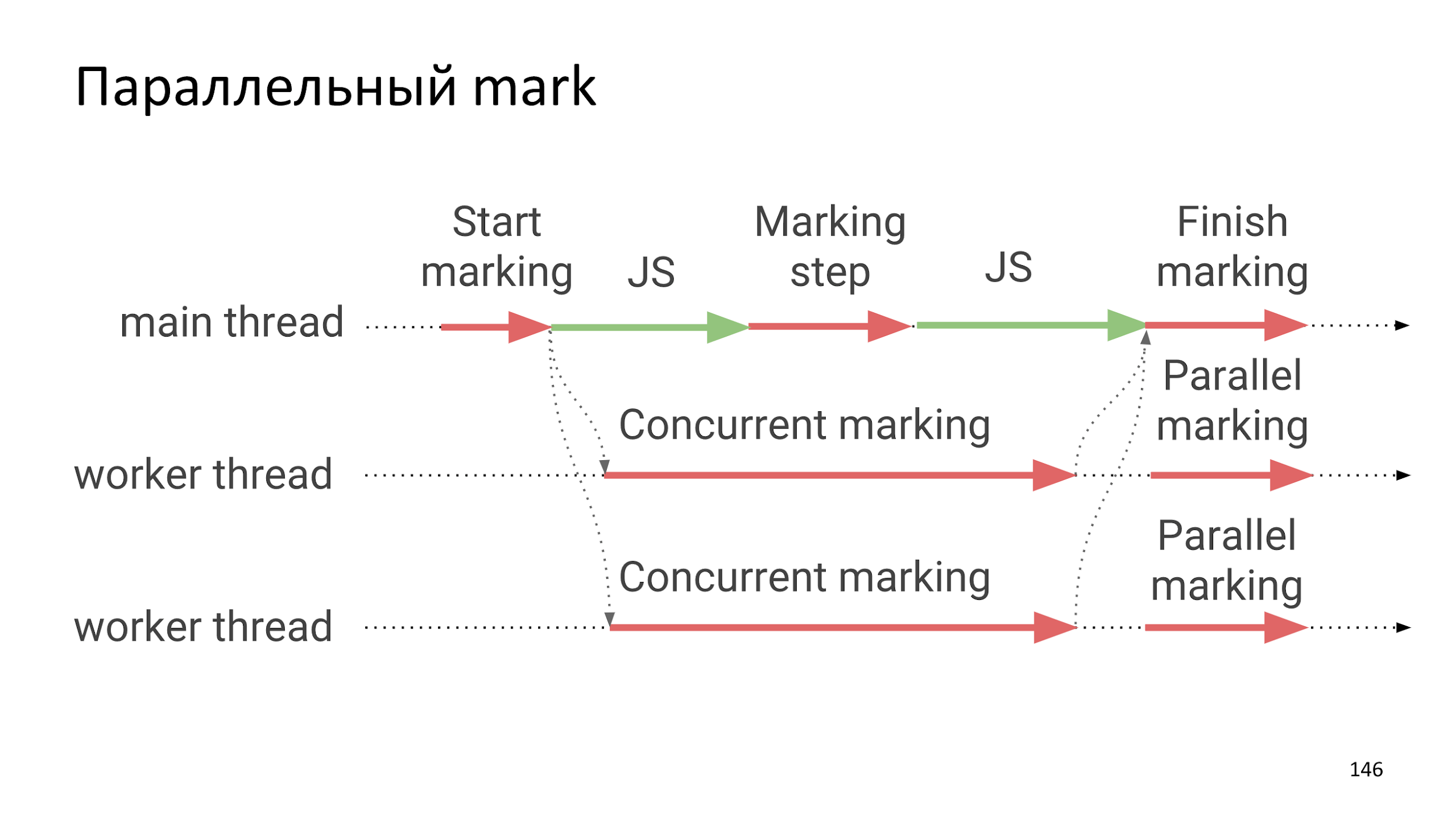
Quando recolher?
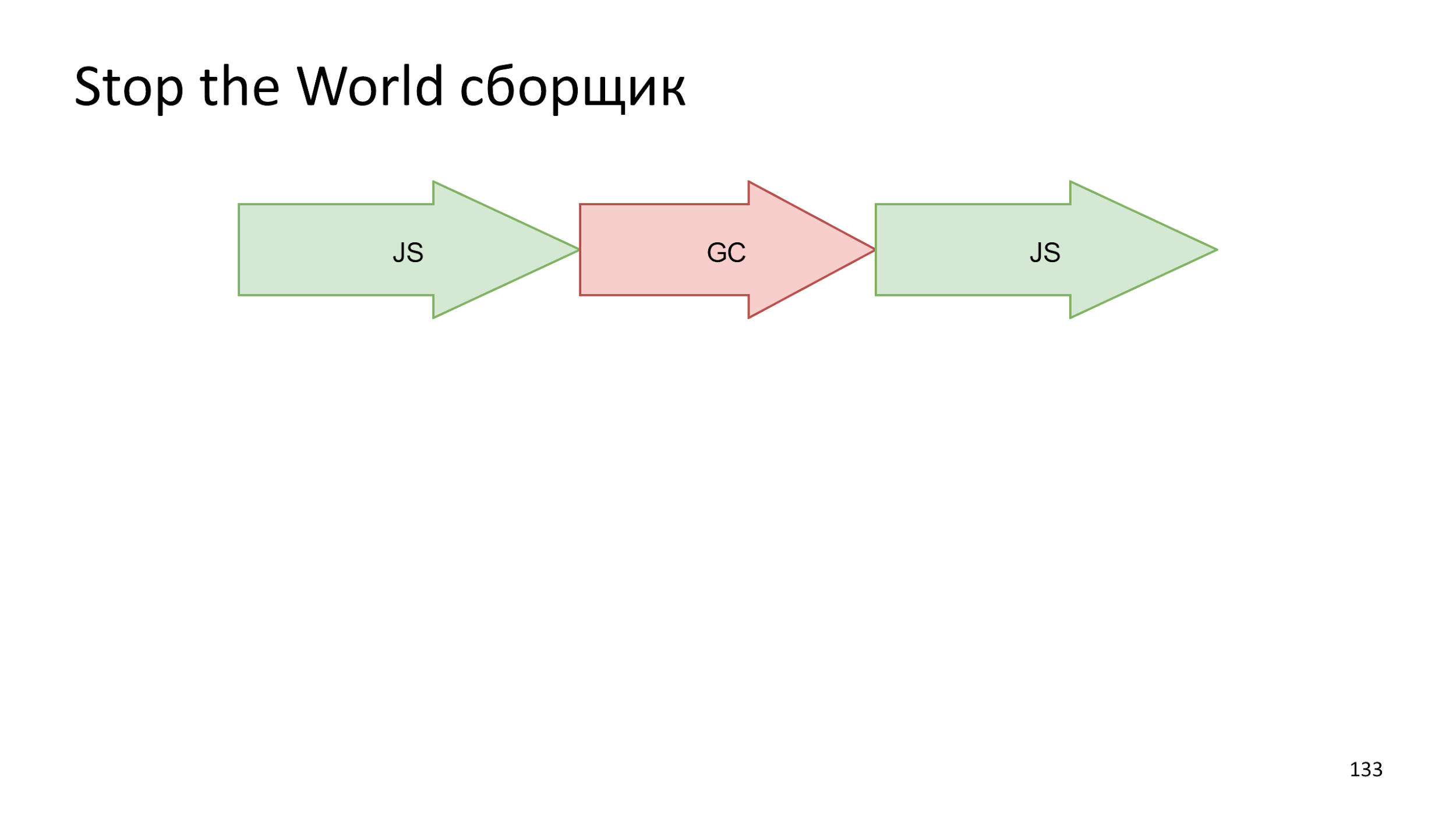
A opção mais fácil é quando
simplesmente paramos tudo , iniciamos a construção e, em seguida, iniciamos o trabalho JS novamente.
Nos computadores modernos, mais de um segmento de execução. Na Web, isso é familiar dos Trabalhadores da Web. Por que não tomar e
paralelizar o processo de montagem . Executar várias operações pequenas ao mesmo tempo será mais rápida que uma operação grande.
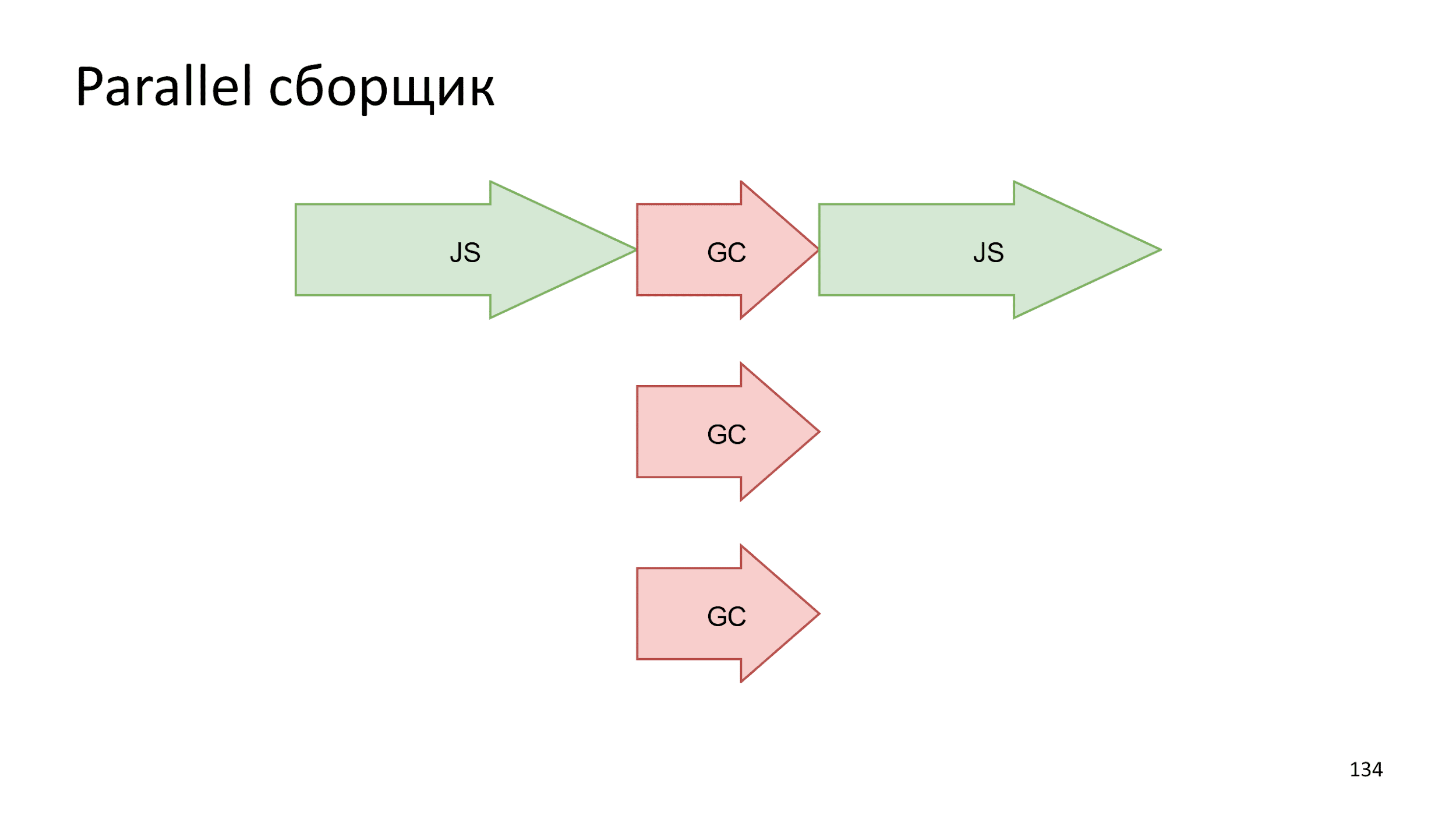
Outra idéia é fazer uma captura instantânea do estado atual com cuidado e
construir em paralelo com JS .
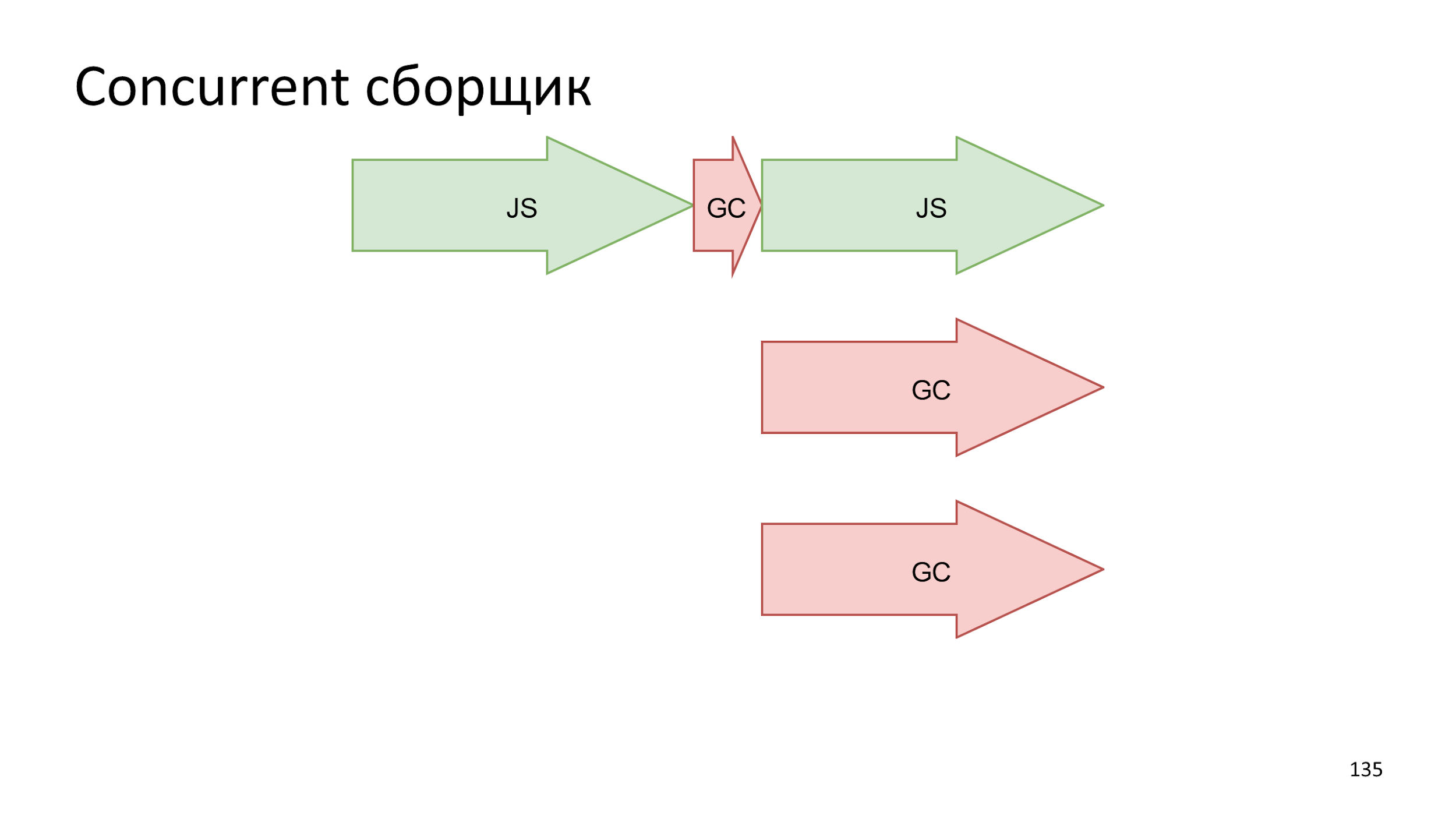
Se isso lhe interessa, recomendo que você leia:
- O único e principal livro de montagem, Garbage Collection Handbook.
- Wikipedia como um recurso universal.
- Site memorymanagement.org.
- Relatórios e artigos de Alexander Shepelev . Ele fala sobre Java, mas em termos de lixo, Java e V8 funcionam aproximadamente da mesma forma.
Realidade do navegador
Vamos seguir como os navegadores usam tudo o que falamos.
Motores IoT
Vamos começar não com navegadores, mas com os mecanismos da Internet das Coisas: JerryScript e Duktape. Eles usam os algoritmos Mark'n'sweep e Stop the world.
Os mecanismos de IoT funcionam em microcontroladores, o que significa: o idioma é lento; segundo trava; fragmentação e tudo isso para um bule com iluminação :)
Se você escreve Internet of Things em JavaScript, conte-nos nos comentários? existe algum ponto
Vamos deixar os mecanismos de IoT em paz, estamos interessados em:
- V8.
- SpiderMonkey Na verdade, ele não tem um logotipo. Logotipo caseiro :)
- JavaScriptCore usado pelo WebKit.
- ChakraCore usado no Edge.

Todos os motores são aproximadamente os mesmos, então falaremos sobre o V8, como o mais famoso.
V8
- Quase todo o JavaScript do lado do servidor, porque é Node.js.
- Quase 80% do JavaScript do cliente.
- Os desenvolvedores mais sociáveis, existem muitas informações e bons códigos-fonte mais fáceis de ler.
O V8 usa montagem geracional.
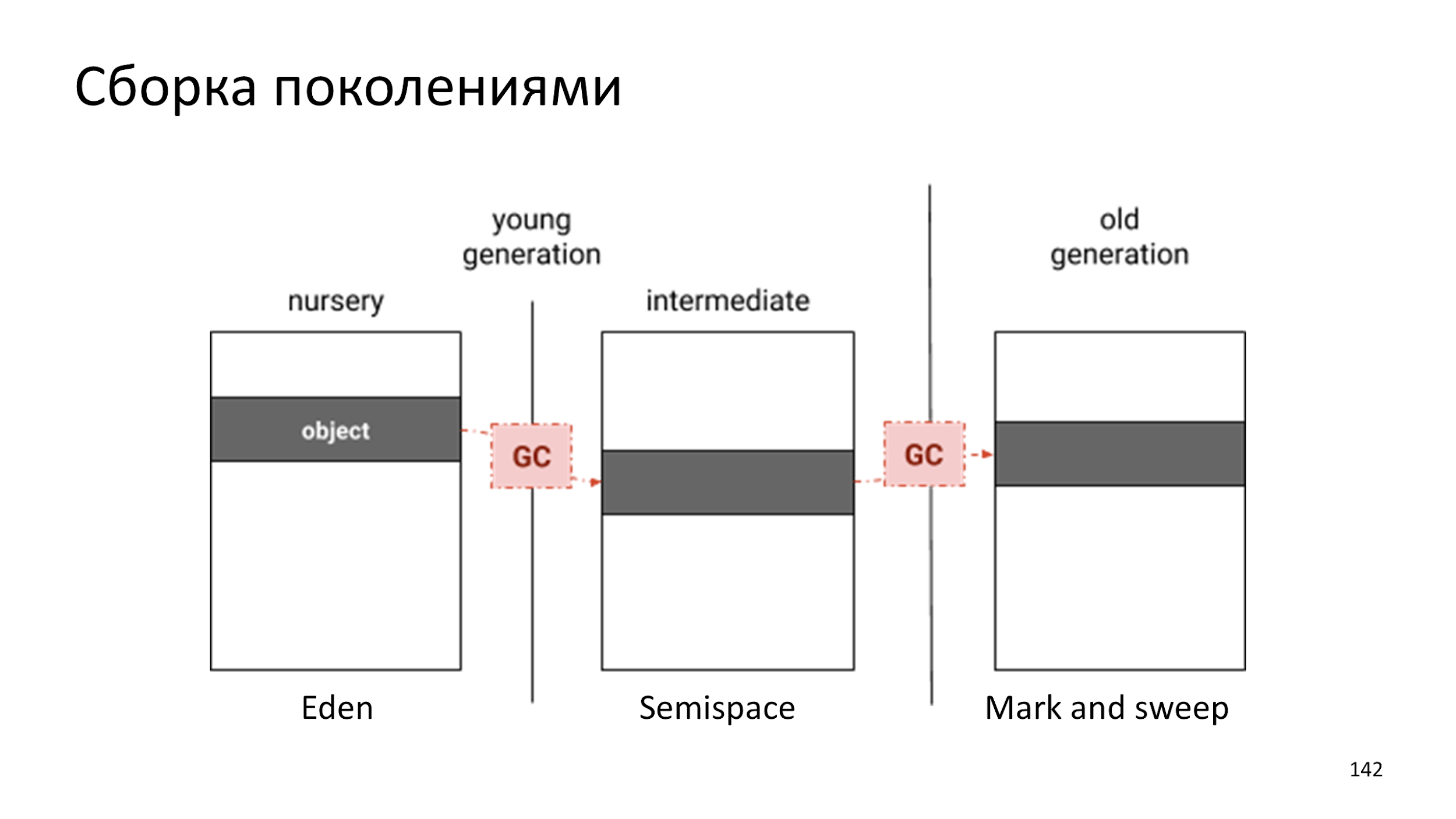
A única diferença é que tínhamos dois colecionadores e agora três:
- Um objeto é criado no Éden.
- Em algum momento no Éden, há muito lixo e o objeto é transferido para o Semispace.
- O objeto é jovem e, quando o colecionador percebe que é muito velho e chato, o joga no Mark and Sweep, no qual a coleta de lixo é extremamente rara.
Você pode ver claramente como fica no
rastreamento de memória .
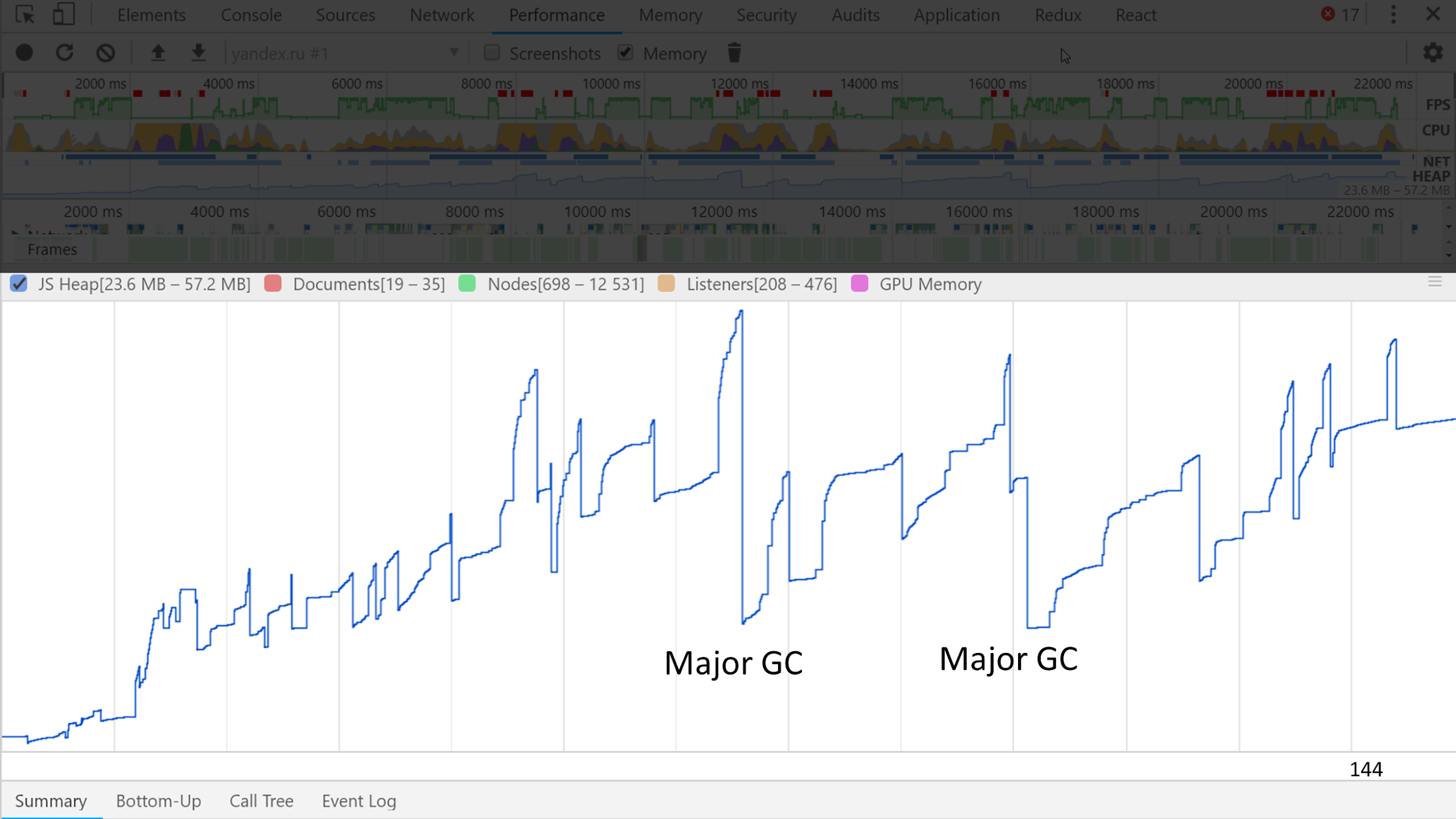
Várias ondas grandes com ondas pequenas são visíveis. As pequenas são assembleias menores e as grandes são as principais.
O significado de nossa existência, de acordo com a hipótese geracional, é gerar lixo, então o próximo erro é o medo de criar lixo.
O lixo pode ser criado quando realmente é lixo. , , , .
mark
V8 .
Stop the world, , JS, .
?
1 3%, .
3% = 1/33 GameDev. GameDev 3% 1 , . GameDev .
const pool = [new Bullet(), new Bullet(), ]; function getFromPool() { const bullet = pool.find(x => !x.inUse); bullet.isUse = true; return bullet; } function returnToPool(bullet) { bullet.inUse = false; }
, , 10 000 .
— . , . , .
: Chromium
, , , Chromium.
> performance.memory MemoryInfo { totalJSHeapSize: 10000000, usedJSHeapSize: 10000000, jsHeapSizeLimit: 2330000000 }
Chromium
performance.memory , , Chromium .
: Chromium 2 JavaScript.
, .
: Node
Node.js
process.memoryUsage , .
> process.memoryUsage() { rss: 22839296, heapTotal: 10207232, heapUsed: 5967968, external: 12829 }
, - , . . .
— , .
proposal , .
Node.js, c
node-weak , , .
let cached = new WeakRef(myJson);
, , - JS. , , , .
WebAssembly , . , , , .
: v8.dev JS.
?
DevTools :
Performance Memory . Chromium, , Firefox Safari .
Performance
Trace, «Memory» Performance, JS .
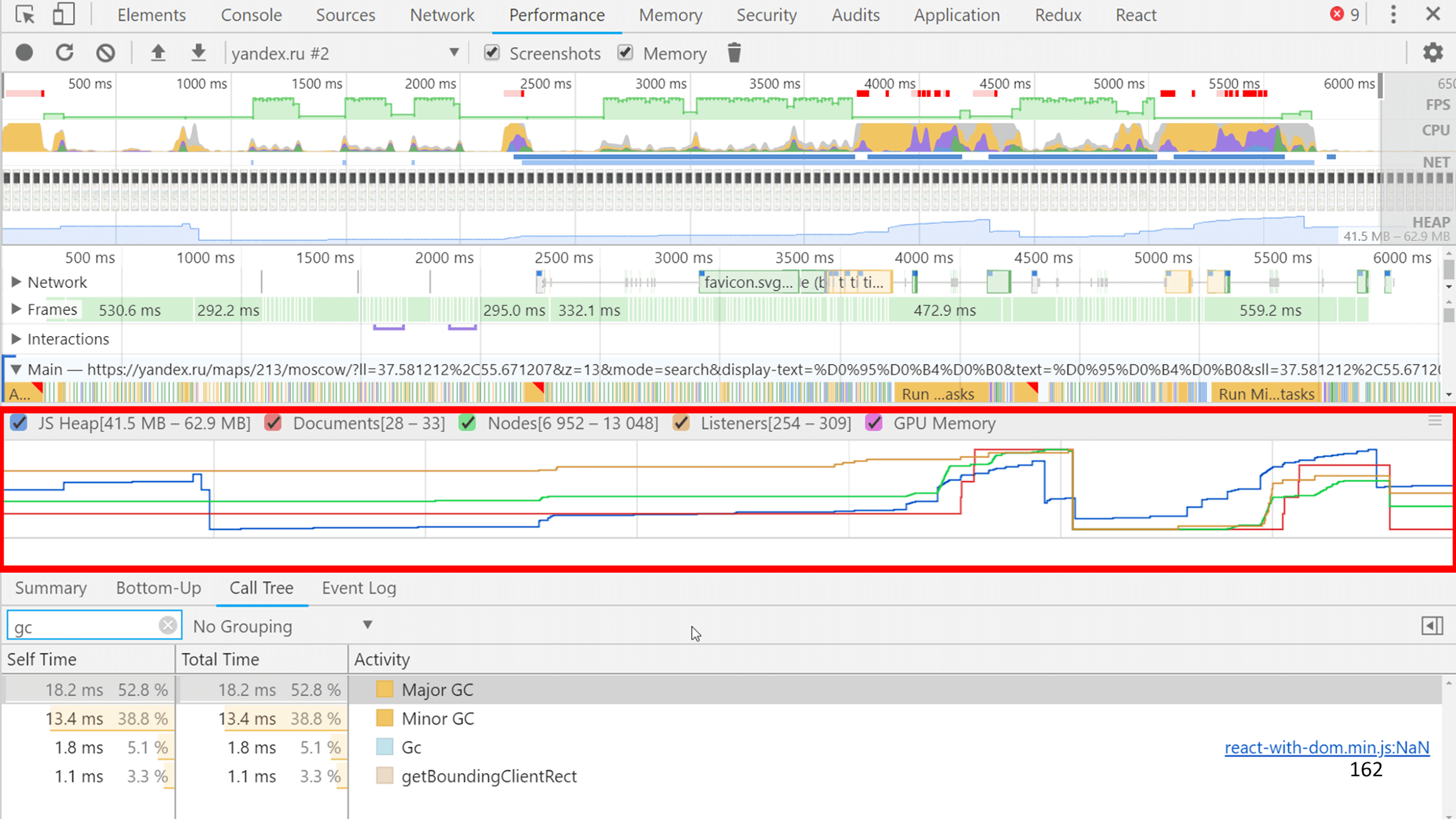
JS V8 , . . , GC 30 1200 JS, 1/40.
Memory
.
.
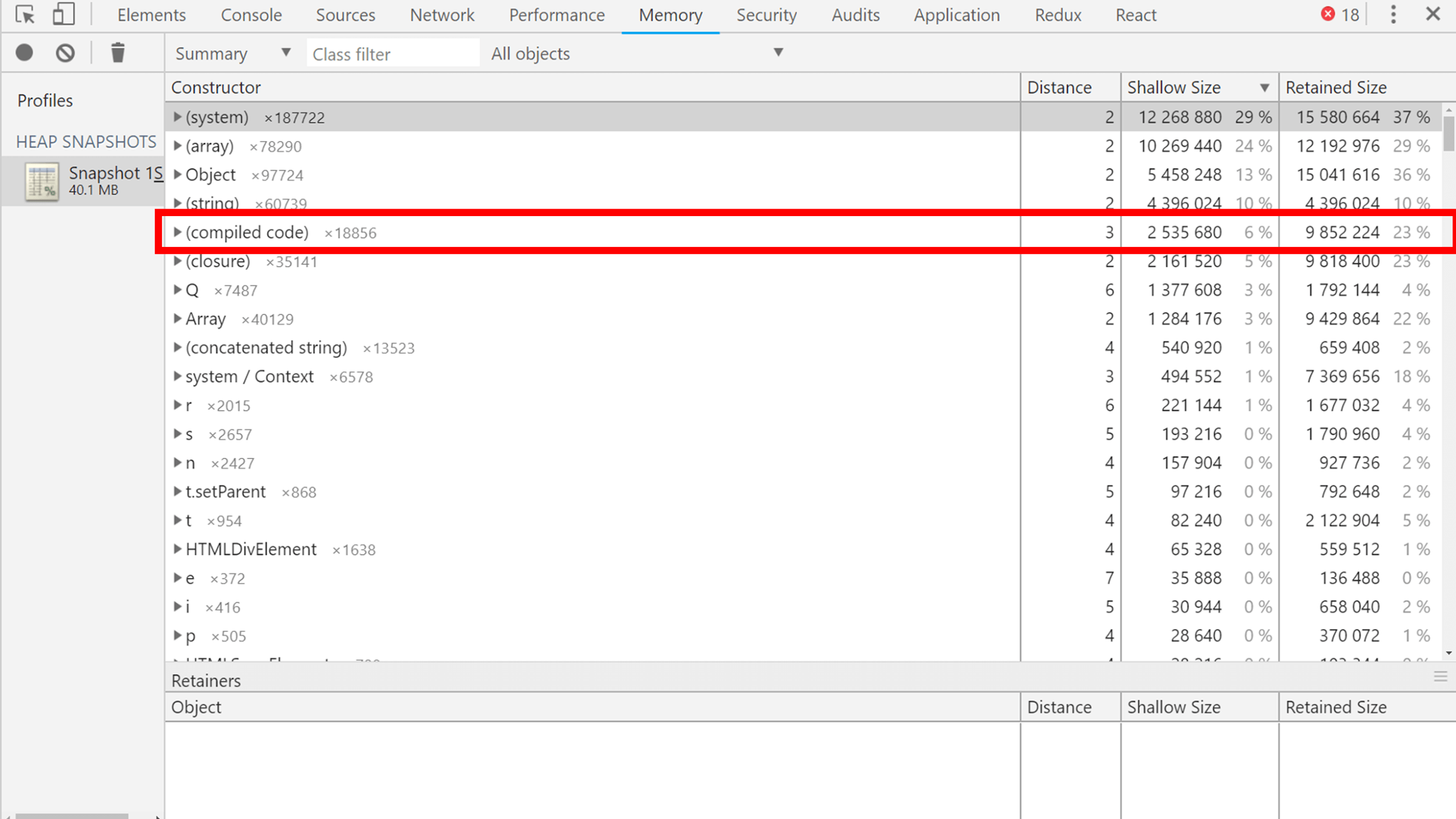
, . , , , V8 , . , .
, , Q ( compiled code) — React . , ?
, , , .
, .
, , , . , — 4 . , .
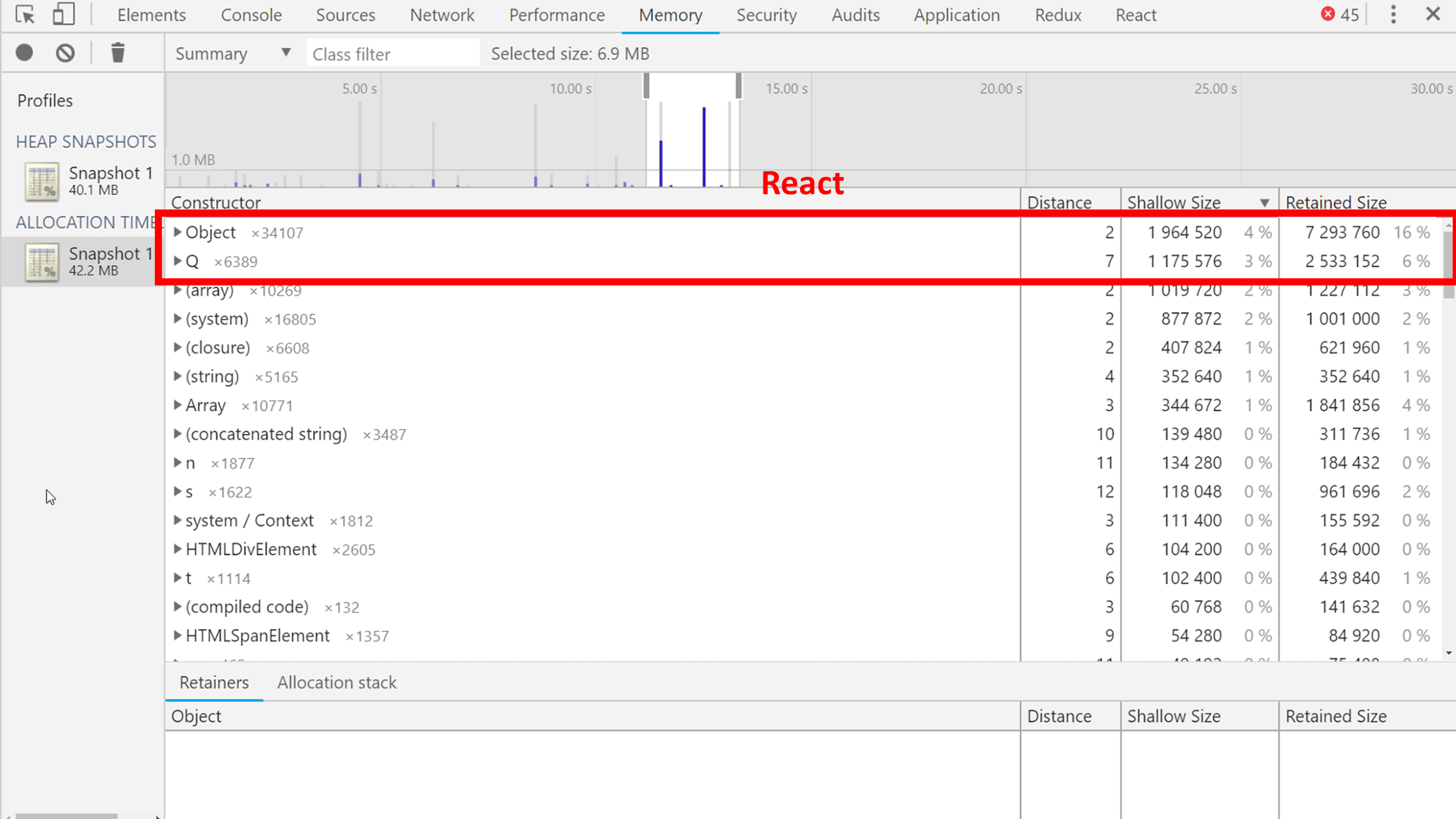
React, - : . , JSX.
Performance Memory , :
- Chromium: about:tracing.
- Firefox: about:memory about:performance, .
- Node — trace-gc, —expose-gc, require('trace_events'). trace_events .
Sumário
- , , , .
- .
- . , ?
- , - .
- SPA, , 1 , .
- , - .
:
flapenguin.me ,
Twitter ,
GitHub .
- ++ . YouTube-
.
, 2018 , . Frontend Conf 2018.
, :)