Recentemente, o desenvolvimento web foi dividido. Agora não somos todos programadores de pilha cheia - somos front-end e back-end. E a coisa mais difícil sobre isso, como em outros lugares, é o problema de interação e integração.
O front-end com o back-end interage através da API. E todo o resultado do desenvolvimento depende de qual API é, quão bom ou ruim o back-end e o front-end concordaram entre si. Se todos começarmos a discutir juntos como fazer a atualização e passarmos o dia inteiro reformulando-a, talvez não possamos realizar tarefas comerciais.
Para não derrapar e criar holivares sobre os nomes das variáveis, você precisa de uma boa especificação. Vamos falar sobre como deve tornar a vida mais fácil para todos. Ao mesmo tempo, nos tornaremos especialistas em galpões de bicicletas.

Vamos começar de longe - com o problema que estamos resolvendo.
Há muito tempo, em 1959,
Cyril Parkinson (que não deve ser confundido com a doença, é escritor e figura econômica) apresentou várias leis interessantes. Por exemplo, essas despesas aumentam com a renda etc. Um deles é chamado de Lei da Trivialidade:
O tempo gasto discutindo o item é inversamente proporcional ao valor considerado.
Parkinson era economista, então explicou suas leis em termos econômicos, algo assim. Se você for ao conselho de administração e disser que precisa de US $ 10 milhões para construir uma usina nuclear, provavelmente essa questão será discutida muito menos do que a alocação de 100 libras para uma bicicleta que é usada pelos funcionários. Como todo mundo sabe construir um galpão para bicicletas, todo mundo tem sua própria opinião, todo mundo se sente importante e quer participar, e a usina nuclear é algo abstrato e distante, 10 milhões também nunca foram vistos - há menos perguntas.
Em 1999, a lei da trivialidade de Parkinson apareceu na programação, que foi então ativamente desenvolvida. Na programação, essa lei foi encontrada principalmente na literatura em inglês e soou como uma metáfora. Foi chamado de
efeito Bikeshed (o efeito de um galpão de bicicleta), mas a essência é a mesma - estamos prontos para um galpão de bicicleta e queremos discutir muito mais do que a construção de uma usina.
Este termo foi cunhado pelo desenvolvedor dinamarquês Poul-Henning Kamp, que esteve envolvido na criação do FreeBSD. Durante o processo de design, a equipe passou muito tempo discutindo como a função do sono deveria funcionar. Esta é uma citação de uma
carta de Poul-Henning Kamp (o desenvolvimento foi realizado em correspondência por e-mail):
Foi uma proposta para adormecer (1) DTRT Se dado um argumento não inteiro que desencadeou esse incêndio em particular, não vou dizer mais nada sobre isso, porque é um item muito menor do que se poderia dizer. esperar do comprimento do segmento, e ele já recebeu muito mais atenção do que alguns dos * problemas * que temos por aqui.
Nesta carta, ele diz que existem muitos problemas não resolvidos muito mais importantes: "Não vamos lidar com o barracão de bicicleta, faremos algo com isso e seguiremos em frente!"
Assim, Poul-Henning Kamp, em 1999, introduziu o termo efeito ciclado na literatura em inglês, que pode ser reformulado como:
A quantidade de ruído criada pela alteração no código é inversamente proporcional à complexidade da alteração.
Quanto mais simples a adição ou alteração que fazemos, mais opiniões precisamos ouvir sobre isso. Eu acho que muitos já encontraram isso. Se resolvermos uma pergunta simples, por exemplo, como nomear variáveis, isso não importa para uma máquina - essa pergunta causará um grande número de holivares. Porém, problemas sérios e realmente importantes para os negócios não são discutidos e vão em segundo plano.
O que você acha mais importante: como nos comunicamos entre o back-end e o front-end, ou as tarefas de negócios que realizamos? Todo mundo pensa de maneira diferente, mas qualquer cliente, uma pessoa que espera que você traga dinheiro para ele, dirá: "Realize minhas tarefas de negócios!" Ele absolutamente não se importa como você transfere dados entre o back-end e o front-end. Talvez ele nem saiba o que é um back-end e front-end.
Para resumir a introdução, eu gostaria de dizer:
API é um galpão de bicicleta.Link de apresentaçãoSobre o palestrante: Alexey Avdeev (
Avdeev ) trabalha para a empresa Neuron.Digital, que lida com neurônios e cria uma interface interessante para eles. Alex também presta atenção ao OpenSource e aconselha a todos. Ele está envolvido no desenvolvimento há muito tempo - desde 2002, ele encontrou a Internet antiga, quando os computadores eram grandes, a Internet era pequena e a falta de JS não incomodava ninguém e todos criavam sites nas mesas.
Como lidar com barracões de bicicleta?
Depois que o respeitado Cyril Parkinson deduziu a lei da trivialidade, ele foi muito discutido. Acontece que o efeito de um galpão de bicicleta aqui pode ser facilmente evitado:
- Não dê ouvidos a conselhos. Eu acho que a idéia é mais ou menos. Se você não ouvir as dicas, poderá fazer isso, especialmente na programação e, principalmente, se for um desenvolvedor iniciante.
- Faça como quiser. "Eu sou um artista, pelo visto!" - sem efeito de bicicleta, tudo o que você precisa está pronto, mas coisas muito estranhas aparecem na saída. Isso geralmente é encontrado em freelancers. Certamente, você se deparou com tarefas que tinha que concluir para outros desenvolvedores e cuja implementação causou confusão.
- É importante se perguntar? Caso contrário, você simplesmente não pode discutir o assunto, mas é uma questão de consciência pessoal.
- Use critérios objetivos. Vou falar sobre este ponto no relatório. Para evitar o efeito de um galpão de bicicleta, você pode usar critérios que digam objetivamente qual é o melhor. Eles existem.
- Não fale sobre o que você não quer ouvir conselhos. Em nossa empresa, os desenvolvedores de back-end iniciantes são introvertidos, então acontece que eles fazem algo que não contam aos outros. Como resultado, encontramos surpresas. Este método funciona, mas na programação não é a melhor opção.
- Se você não se importa com o problema, pode simplesmente deixá- lo ir ou escolher qualquer uma das opções propostas que surgiram no processo de holivarov.
Ferramenta anti-ciclismo
Quero falar sobre
ferramentas objetivas para resolver o problema de um barracão de bicicleta. Para demonstrar o que é uma ferramenta anti-ciclismo, vou contar uma pequena história.
Imagine que temos um desenvolvedor iniciante de back-end. Ele veio recentemente à empresa e foi instruído a criar um pequeno serviço, por exemplo, um blog, para o qual você precisa escrever um protocolo REST.
 Roy Fielding, autor de REST
Roy Fielding, autor de RESTNa foto, Roy Fielding, que em 2000 defendeu sua tese "Estilos arquitetônicos e design de arquiteturas de software de rede" e, assim, introduziu o termo REST. Além disso, ele inventou o HTTP e, de fato, é um dos fundadores da Internet.
REST é um conjunto de princípios de arquitetura que dizem como projetar protocolos REST, APIs REST, serviços RESTful. Estes são princípios arquitetônicos bastante abstratos e complexos. Estou certo de que nenhum de vocês jamais viu uma API feita completamente de acordo com todos os princípios RESTful.
Requisitos de arquitetura REST
Vou dar alguns requisitos para os protocolos
REST , dos quais vou me referir e confiar. Existem muitos deles, você pode ler mais sobre isso na Wikipedia.
1.
O modelo cliente-servidor.O princípio mais importante do REST, ou seja, nossa interação com o back-end. De acordo com o REST, o back-end é um servidor, o front-end é um cliente e nos comunicamos em um formato cliente-servidor. Os dispositivos móveis também são um cliente. Desenvolvedores de relógios, geladeiras e outros serviços - também desenvolvem a parte do cliente. A API RESTful é o servidor que o cliente acessa.
2.
Falta de condição.Não deve haver estado no servidor, ou seja, tudo o que é necessário para uma resposta vem na solicitação. Quando uma sessão é armazenada no servidor e, dependendo dessa sessão, surgem respostas diferentes, isso é uma violação do princípio REST.
3.
Uniformidade da interface.Esse é um dos principais princípios subjacentes nos quais a API REST deve ser construída. Inclui o seguinte:
- A identificação de recursos é como devemos construir uma URL. No REST, recorremos ao servidor para algum tipo de recurso.
- Manipulação de recursos através da apresentação. O servidor nos retorna uma visão diferente da que está no banco de dados. Não importa se você armazena as informações no MySQL ou PostgreSQL - temos uma visão.
- Mensagens autoexplicativas - ou seja, a mensagem contém identificação, links onde você pode obter essa mensagem novamente - tudo o que é necessário para trabalhar com esse recurso novamente.
- Hipermídia é um link para as seguintes ações com um recurso. Parece-me que nem uma única API REST faz isso, mas é descrita por Roy Fielding.
Existem mais três princípios que não cito porque não são importantes para a minha história.
Blog RESTful
De volta ao desenvolvedor de back-end inicial, que foi solicitado a fazer um serviço para o blog no RESTful. Abaixo está um exemplo de um protótipo.
Este é um site no qual existem artigos, você pode comentar sobre eles, o artigo e os comentários têm um autor - uma história padrão. Nosso desenvolvedor iniciante de back-end fará uma API RESTful para este blog.
Trabalhamos com todos os dados do blog com base no
CRUD .
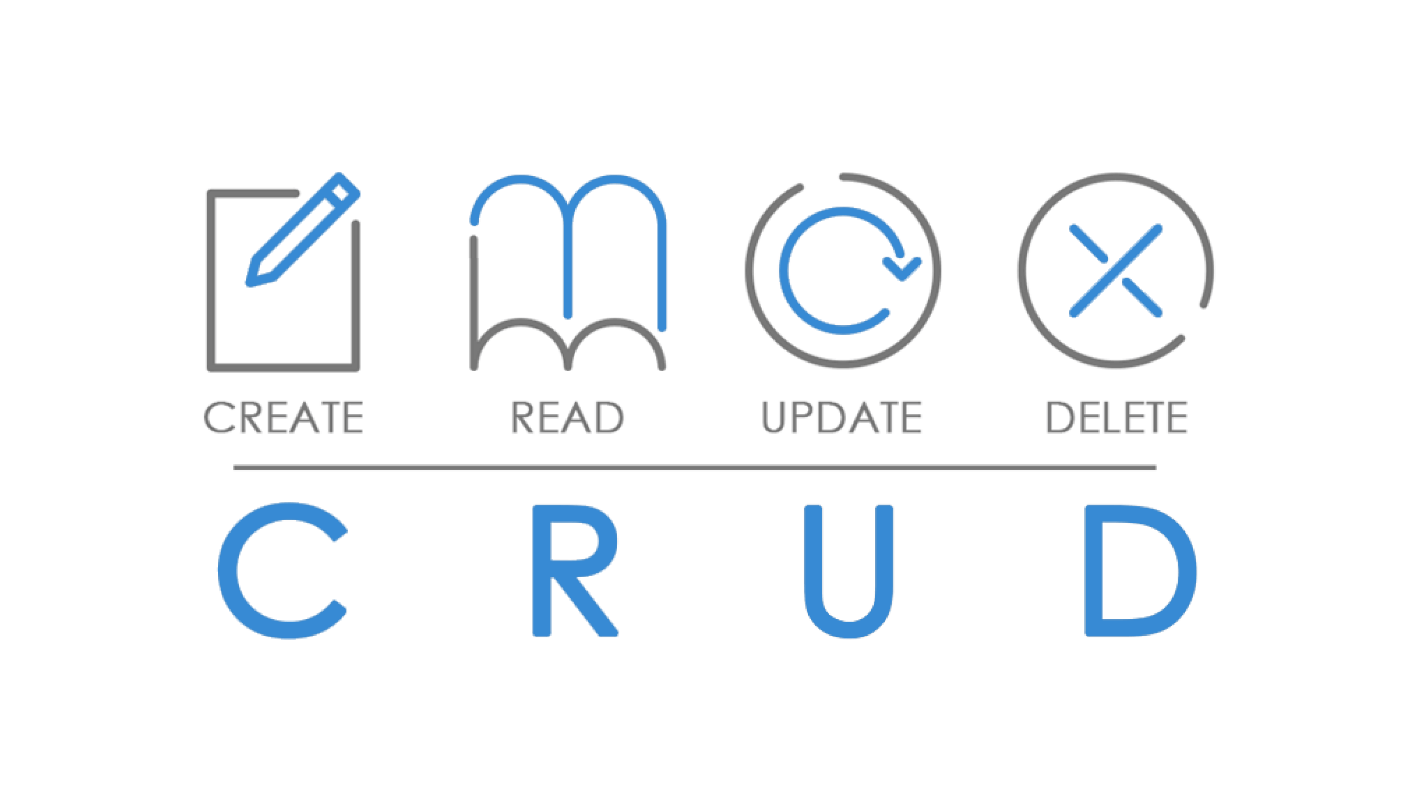
Deve ser possível criar, ler, atualizar e excluir qualquer recurso. Vamos tentar pedir ao nosso desenvolvedor de back-end para criar um AP RESTful com base no princípio do CRUD. Ou seja, escreva métodos para criar artigos, obtenha uma lista de artigos ou um único artigo, atualize e exclua.
Vamos ver como ele conseguiu.
 Tudo está errado aqui em relação a todos os princípios do REST
Tudo está errado aqui em relação a todos os princípios do REST . O mais interessante é que funciona. Na verdade, eu tenho APIs que se parecem com isso. Para o cliente, é um galpão de bicicleta, para os desenvolvedores é uma ocasião para relaxar e discutir, e para um desenvolvedor iniciante, é apenas um mundo novo enorme e corajoso, no qual ele tropeça toda vez, cai e esmaga sua cabeça. Ele precisa refazê-lo repetidamente.

Esta é uma opção REST. Com base nos princípios de identificação de recursos, trabalhamos com recursos - com artigos e usamos os métodos HTTP propostos por Roy Fielding. Ele não pôde deixar de usar seu trabalho anterior em seu próximo trabalho.
Para atualizar artigos, muitos usam o método PUT, que possui semântica ligeiramente diferente. O método PATCH atualiza os campos que foram passados e o PUT simplesmente substitui um artigo por outro. Por semântica, PATCH é mesclagem e PUT é substituída.
Nosso desenvolvedor iniciante de back-end caiu, eles pegaram e disseram: "Está tudo em ordem, faça assim", e ele honestamente o refez. Mas então ele encontrará um longo caminho através dos espinhos.
Por que isso é tão certo?- porque Roy Fielding disse isso;
- porque é REST;
- porque esses são os princípios arquitetônicos nos quais nossa profissão se baseia agora.
No entanto, este é um "depósito de bicicletas" e o método anterior funcionará. Os computadores se comunicaram antes do REST e tudo funcionou. Mas agora um padrão apareceu no setor.
Excluir o artigo
Considere o exemplo de exclusão de um artigo. Suponha que exista um método de recurso normal DELETE / articles, que remova o artigo pelo ID. HTTP contém cabeçalhos. O cabeçalho Accept aceita o tipo de dados que o cliente deseja receber em resposta. Nosso junior escreveu um servidor que retorna 200 OK, Content-Type: application / json, e passa um corpo vazio:
01. DELETE /articles/ 1 /1.1
02. Accept: application/json01. HTTP/1.1 200 OK
02. Content-Type: application/json
03. null
Um
erro muito
comum foi cometido aqui - um corpo vazio . Tudo parece lógico - o artigo foi excluído, 200 OK, o cabeçalho application / json está presente, mas o cliente provavelmente cairá. Irá gerar um erro porque um corpo vazio não é válido. Se você já tentou analisar uma string vazia, se depara com o fato de que qualquer analisador json tropeça e trava com isso.
Como consertar essa situação? Provavelmente a melhor opção é passar json. Se declaramos: “Aceite, nos dê json”, o servidor diz: “Tipo de conteúdo, eu te dou json”, dê json. Um objeto vazio, uma matriz vazia - coloque algo lá - esta será a solução e funcionará.
Ainda existe uma solução. Além de 200 OK, há um código de resposta 204 - sem conteúdo. Com ele, você não pode transmitir o corpo. Nem todo mundo sabe disso.
Então eu levei aos tipos de mídia.
Tipos de mímica
Os tipos de mídia são como uma extensão de arquivo, apenas na web. Quando transmitimos dados, devemos informar ou solicitar que tipo de resposta queremos receber.
- Por padrão, isso é texto / sem formatação - apenas texto.
- Se nada for especificado, o navegador provavelmente significará application / octet-stream - apenas um bit stream.
Você pode especificar apenas um tipo específico:
- application / pdf;
- imagem / png;
- application / json;
- application / xml;
- application / vnd.ms-excel.
Os cabeçalhos Content-Type e Accept são e são importantes.
A API e o cliente devem passar os cabeçalhos Content-Type e Accept.
Se sua API for construída em JSON, sempre passe Accept: application / json e application-Type application / json.
Tipos de arquivo de exemplo.

Os tipos de mídia são semelhantes a esses tipos de arquivos, apenas na Internet.
Códigos de resposta
O próximo exemplo das aventuras de nosso desenvolvedor júnior são os códigos de resposta.

A taxa de resposta mais engraçada é 200 OK. Todo mundo o ama - significa que tudo deu certo. Eu até tive um caso - recebi
erros 200 OK . Algo realmente caiu no servidor; em resposta à resposta, surge uma página HTML na qual um erro HTML foi compilado. Solicitei um aplicativo json com o código 200 OK e pensei em como trabalhar com ele? Você responde, procura a palavra "erro", acha que isso é um erro.
Isso funciona, no entanto, no HTTP, existem muitos outros códigos que você pode usar e o REST recomenda que você os use no REST. Por exemplo, a criação de uma entidade (artigo) pode ser respondida:
- 201 Criado é um código bem-sucedido. O artigo é criado. Em resposta, você precisa retornar o artigo criado.
- 202 Aceito significa que a solicitação foi aceita, mas seu resultado será posterior. Essas são operações de execução longa. Em Aceito, nenhum corpo pode ser devolvido. Ou seja, se você não fornecer o Tipo de Conteúdo na resposta, o corpo também poderá não ser. Ou texto / plano de tipo de conteúdo - isso é tudo, sem perguntas. Uma sequência vazia é um texto / plano válido.
- 204 Sem conteúdo - o corpo pode estar completamente ausente.
- 403 Proibido - Você não tem permissão para criar este artigo.
- 404 Não encontrado - você subiu em algum lugar errado, não existe, por exemplo.
- 409 Conflito é um caso extremo que poucas pessoas usam. Às vezes, é necessário se você estiver gerando um ID no cliente, e não no back-end, e naquele momento alguém já conseguiu criar este artigo. Conflito é a resposta certa neste caso.
Criação de Entidades
O exemplo a seguir: criamos uma entidade, digamos Content-Type: application / json, e passamos esse aplicativo / json. Isso torna o cliente - nosso front-end. Vamos criar este mesmo artigo:
01. POST /articles /1.1
02. Content-Type: application/json
03. { "id": 1, "title": " JSON API"}O código pode vir em resposta:
- 422 Entidade não processável - Uma entidade não processada. Tudo parece ótimo - semântica, há código;
- 403 Proibido
- 500 Erro interno do servidor.
Mas é absolutamente incompreensível o que exatamente aconteceu: que tipo de entidade não é processada, por que não devo ir até lá e o que finalmente aconteceu com o servidor?
Retornar erros
Certifique-se (e os juniores não sabem disso) em resposta, retorne erros. Isso é semântico e correto. A propósito, Fielding não escreveu sobre isso, ou seja, foi inventado mais tarde e construído sobre o REST.
O back-end pode retornar uma matriz com erros de resposta, pode haver vários.
01. HTTP/1.1 422 Unprocessable Entity
02. Content-Type: application/json
03.
04. { "errors": [{
05. "status": "422",
06. "title": "Title already exist",
07. }]}Cada erro pode ter seu próprio status e título. Isso é ótimo, mas já está no nível da convenção, além do REST. Essa pode ser a nossa ferramenta anti-bikeshedding para parar de discutir e criar uma API correta e imediata.
Adicionar paginação
O exemplo a seguir: os designers chegam ao nosso desenvolvedor de back-end e dizem: “Temos muitos artigos, precisamos de paginação. Nós desenhamos este.

Vamos considerar com mais detalhes. Primeiro de tudo, 336 páginas são impressionantes. Quando vi isso, pensei em como obter esse valor. Onde obter 336, porque quando solicito uma lista de artigos, recebo uma lista de artigos. Por exemplo, existem 10 mil deles, ou seja, eu preciso baixar todos os artigos, dividir pelo número de páginas e descobrir esse número. Durante muito tempo, carregarei esses artigos, preciso de uma maneira de obter o número de entradas rapidamente. Porém, se nossa API retornar uma lista, onde colocar esse número de registros em geral, porque uma variedade de artigos vem em resposta. Acontece que, como o número de registros não é colocado em lugar algum, ele deve ser adicionado a cada artigo para que cada artigo diga: "E há tantos de todos nós!"
No entanto, existe uma convenção na parte superior da API REST que resolve esse problema.
Solicitação de lista
Para tornar a API extensível, você pode usar imediatamente os parâmetros GET para paginação: o tamanho da página atual e seu número, para que exatamente a parte da página solicitada nos seja devolvida. Isso é conveniente. Em resposta, você não pode fornecer imediatamente uma matriz, mas adicionar aninhamento adicional. Por exemplo, a chave de dados conterá uma matriz, os dados solicitados e a meta-chave, que não existia antes, conterá o total.
01. GET /articles? page[size]=30&page[number]=2
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
Dessa maneira, a API pode retornar informações adicionais. Além da contagem, pode haver outras informações - elas são extensíveis. Agora, se o júnior não fez isso imediatamente, e somente depois que ele foi solicitado a fazer a pajinização, ele
fez a alteração incompatível com a versão
anterior , quebrou a API e todos os clientes tiveram que refazê-la - geralmente dói muito.
Pajinização é diferente. Eu ofereço vários hacks que você pode usar.
[deslocamento] ... [limite]
01. GET /articles? page[offset]=30&page[limit]=30
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
Quem trabalha com bancos de dados já pode ter um subcórtex [deslocamento] ... [limite]. Usá-lo em vez do tamanho da página ... página [número] será mais fácil. Essa é uma abordagem um pouco diferente.
Posicionamento do cursor
01. GET /articles? page[published_at]=1538332156
02. Content-Type: application/json01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }A localização do cursor usa um ponteiro para a entidade com a qual iniciar o carregamento de registros. Por exemplo, é muito conveniente quando você usa paginação ou carregamento em listas que mudam frequentemente. Digamos que novos artigos sejam constantemente escritos em nosso blog. A terceira página agora não é a mesma terceira página em um minuto, mas se formos para a quarta página, obteremos alguns registros da terceira página, porque a lista inteira será movida.
Esse problema é resolvido pela paginação do cursor. Dizemos: “Carregue os artigos que vêm depois do artigo publicado naquele momento” - não pode haver mais mudança puramente tecnológica, e isso é legal.
Problema N +1
O próximo problema que nosso desenvolvedor júnior definitivamente encontrará é o problema N + 1 (os backenders entenderão). Suponha que você queira listar uma lista de 10 artigos. Carregamos uma lista de artigos, cada artigo tem um autor e, para cada um, você precisa fazer o download de um autor. Nós enviamos:
- 1 pedido de uma lista de artigos;
- 10 pedidos para os autores de cada artigo.
Total: 11 consultas para exibir uma pequena lista.
Adicionar links
No back-end, esse problema é resolvido em todos os ORMs - você só precisa se lembrar de adicionar esta conexão. Essas conexões também podem ser usadas no front-end. Isso é feito da seguinte maneira:
01. GET /articles? include =author
02. Content-Type: application/json
Você pode usar um parâmetro GET especial, chame-o de incluir (como no back-end), dizendo quais links precisamos carregar junto com os artigos. Suponha que façamos o upload de artigos e queremos que o autor entre imediatamente com os artigos. A resposta é assim:
01. /1.1 200
02. { "data": [{
03. { attributes: { "id": 1, "title": "JSON API" },
04. { relationships: {
05. "author": { "id": 1, "name": "Avdeev" } }
06. }, ...
07. }]}Os próprios atributos do artigo foram transferidos para os dados e os principais relacionamentos foram adicionados. Colocamos todas as conexões nessa chave. Assim, com uma solicitação, recebemos todos os dados que recebiam 11 solicitações anteriormente. Este é um truque interessante que resolve o problema com o N + 1 no front end.
O problema da duplicação de dados
Suponha que você queira exibir 10 artigos indicando o autor, todos os artigos têm um autor, mas o objeto com o autor é muito grande (por exemplo, um sobrenome muito longo, com um megabyte). Um autor é incluído na resposta 10 vezes e 10 inclusões do mesmo autor na resposta terão 10 MB.
Como todos os objetos são iguais, o problema de um autor ser incluído 10 vezes (10 MB) é resolvido com a ajuda da normalização, usada em bancos de dados. No front-end, você também pode usar a normalização ao trabalhar com a API - isso é muito legal.
01. /1.1 200
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": "JSON API" },
05. "relationships": { ... }
06. "author": { "id": 1, "type": "people" } }
07. }, ... ]
08. }Marcamos todas as entidades com algum tipo (este é um tipo de representação, um tipo de recurso). Roy Fielding introduziu o conceito de recurso, ou seja, eles solicitaram artigos - receberam um "artigo". Nos relacionamentos, colocamos um link para o tipo de pessoas, ou seja, ainda temos o recurso de pessoas em outro lugar. E o próprio recurso que utilizamos em uma chave separada incluída, que fica no mesmo nível dos dados.
01. /1.1 200
02. {
03. "data": [ ... ],
04. "included": [{
05. "id": 1, "type": "people",
06. "attributes": { "name": "Avdeev" }
07. }]
08. }Assim, todas as entidades relacionadas em uma única instância caem na chave especial incluída. Armazenamos apenas links e as próprias entidades são armazenadas em incluídas.
O tamanho da solicitação diminuiu. Este é um truque de vida sobre o qual o back-end inicial não sabe. Ele descobrirá mais tarde quando precisar quebrar a API.
Nem todos os campos de recursos são necessários
O seguinte truque de vida pode ser aplicado quando nem todos os campos de recursos são necessários. Isso é feito usando um parâmetro GET especial, que lista os atributos a serem retornados, separados por vírgulas. Por exemplo, o artigo é grande e pode haver megabytes no campo de conteúdo, e precisamos exibir apenas a lista de cabeçalhos - não precisamos do conteúdo na resposta.
GET /articles ?fields[article]=title /1.101. /1.1 200 OK
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": " JSON API" },
05. }, ... ]
06. }Se você precisar, por exemplo, também da data de publicação, poderá escrever uma "data publicada" separada por vírgula. Em resposta, dois campos virão em atributos. Esta é uma convenção que pode ser usada como uma ferramenta anti-ciclismo.
Pesquisa por artigos
Muitas vezes, precisamos de pesquisas e filtros. Existem convenções para isso - filtros especiais parâmetros GET:
●
GET /articles ?filters[search]=api HTTP/1.1 - pesquisa;
●
GET /articles ?fiIters[from_date]=1538332156 HTTP/1.1 - faça o download de artigos a partir de uma data específica;
●
GET /articles ?filters[is_published]=true HTTP/1.1 - baixar artigos que acabam de ser publicados;
●
GET /articles ?fiIters[author]=1 HTTP/1.1 - faça o download de artigos com o primeiro autor.
Classificando artigos
●
GET /articles ?sort=title /1.1 - por título;
●
GET /articles ?sort=published_at HTTP/1.1 - por data de publicação;
●
GET /articles ?sort=-published_at HTTP/1.1 - por data de publicação na direção oposta;
●
GET /articles ?sort=author,-publisbed_at HTTP/1.1 - primeiro pelo autor, depois pela data de publicação na direção oposta, se os artigos forem do mesmo autor.
Precisa alterar URLs
Solução: a hipermídia, que eu já mencionei, pode ser feita da seguinte maneira. Se quisermos que o objeto (recurso) seja auto-descritivo, o cliente poderá entender por meio da hipermídia o que pode ser feito com ele e o servidor poderá desenvolver-se independentemente do cliente. Em seguida, você poderá adicionar links à lista de artigos, ao próprio artigo usando chaves de links especiais :
01. GET /articles /1.1
02. {
03. "data": [{
04. ...
05. "links": { "self": "http://localhost/articles/1" },
06. "relationships": { ... }
07. }],
08. "links": { "self": " http://localhost/articles " }
09. }
Ou relacionado, se quisermos dizer ao cliente como fazer upload de um comentário neste artigo:
01. ...
02. "relationships": {
03. "comments": {
04. "links": {
05. "self": "http://localhost/articles/l/relationships/comments ",
06. "related": " http://localhost/articles/l/comments "
07. }
08. }
09. }O cliente vê que existe um link, segue-o, carrega um comentário. Se não houver link, não haverá comentários. Isso é conveniente, mas poucos o fazem. Fielding apresentou os princípios do REST, mas nem todos eles entraram em nosso setor. Nós usamos principalmente dois ou três.
Em 2013, todos os hacks que eu contei, Steve Klabnik foram combinados com a especificação da API JSON e registrados como um
novo tipo de mídia, além do JSON . Portanto, nosso desenvolvedor júnior de back-end, evoluindo gradualmente, chegou à API JSON.
API JSON
Tudo é descrito em detalhes em
http://jsonapi.org/implementations/ : há até uma lista de 170 implementações de especificações diferentes para 32 linguagens de programação - e elas são adicionadas apenas ao catálogo. Bibliotecas, analisadores, serializadores etc. já foram gravados.
Como essa especificação é de código aberto, todos estão investindo nela. Entre outras coisas, eu mesmo escrevi algo. Estou certo de que existem muitas dessas pessoas. Você pode participar deste projeto você mesmo.
Profissionais da API JSON
A especificação da API JSON resolve vários problemas - um
acordo comum para todos . Como existe um acordo geral, não discutimos
dentro da equipe - o depósito de bicicletas está documentado. Nós temos um acordo sobre quais materiais fabricar uma bicicleta e como pintá-la.
Agora, quando o desenvolvedor faz algo errado e eu o vejo, não inicio a discussão, mas digo: "Não pela API JSON!" e mostrar no lugar na especificação. Eles me odeiam na empresa, mas gradualmente se acostumam e todos começaram a gostar da API JSON. Criamos novos serviços padrão de acordo com esta especificação. Temos uma chave de data, estamos prontos para adicionar meta, incluir chaves. Há um filtro de parâmetro GET reservado para filtros. Não discutimos o que chamar de filtro - usamos essa especificação. Ele descreve como criar um URL.
Como não estamos discutindo, mas realizando tarefas de negócios, a
produtividade do desenvolvimento é maior . Temos as especificações descritas, o desenvolvedor leu o back-end, criou a API, nós estragamos tudo - o cliente está feliz.
Problemas populares já foram resolvidos , por exemplo, com paginação. Há muitas dicas nas especificações.
Como é JSON (graças a Douglas Crockford por esse formato), é mais conciso que XML, é bastante
fácil de ler e entender .
O fato de ser um
código aberto pode ser um sinal de mais e de menos, mas eu amo o código aberto.
Contras API JSON
O objeto cresceu (data, atributos, incluídos etc.) - o
front -
end precisa analisar as respostas: seja capaz de iterar sobre matrizes, caminhar ao redor do objeto e saber como reduzir funciona. Nem todos os desenvolvedores iniciantes sabem essas coisas complexas. Existem bibliotecas de serializadores / desserializadores, você pode usá-los. Em geral, isso é apenas trabalhar com dados, mas os objetos são grandes.
E o
back-end tem dor:
- Controle de aninhamento - incluir pode ser escalado muito longe;
- A complexidade das consultas ao banco de dados - elas às vezes são criadas automaticamente e se tornam muito difíceis;
- Segurança - você pode subir na selva, principalmente se conectar algum tipo de biblioteca;
- A especificação é difícil de ler. Ela está em inglês, e isso assustou alguns, mas gradualmente todos se acostumaram;
- Nem todas as bibliotecas implementam bem a especificação - esse é um problema de código aberto.
API JSON de armadilhas
Um pouco de hardcore.
O número de relacionamentos no problema não é limitado. Se incluirmos, solicitarmos artigos, adicionar comentários a eles, em resposta, receberemos todos os comentários deste artigo. Existem 10.000 comentários - obtenha todos os 10.000 comentários:
GET /articles/1?include=comments /1.101. ...
02. "relationships": {
03. "comments": {
04. "data": [0 ... ∞]
05. }
06. }Assim, na verdade, 5 MB chegaram ao nosso pedido em resposta: “Está escrito na especificação - é necessário reformular o pedido corretamente:
GET /comments? filters[article]=1& page[size]=30 HTTP/1.101. {
02. "data": [0 ... 29]
03. }Solicitamos comentários com um filtro por artigo, digamos: "30 peças, por favor" e recebemos 30 comentários. Isso é ambiguidade.
As mesmas coisas podem ser formuladas de forma ambígua :
●
GET /articles/1 ?include=comments HTTP/1.1 - solicita um artigo com comentários;
●
GET /articles/1/comments HTTP/1.1 - solicita comentários sobre o artigo;
●
GET /comments ?filters[article]=1 HTTP/1.1 - solicita comentários com um filtro por artigo.
É o mesmo - os mesmos dados, obtidos de maneiras diferentes, há alguma ambiguidade. Esta armadilha não é imediatamente visível.
Um-para-muitos relacionamentos polimórficos rastejam no REST muito rapidamente.
01. GET /comments?include=commentable /1.1
02.
03. ...
04. "relationships": {
05. "commentable" : {
06. "data": { "type": "article", "id": "1″ }
07. }
08. }Há uma conexão polimórfica comentável no back-end - ela rastreia para o REST. Então isso deve acontecer, mas pode ser disfarçado. Você não pode disfarçar a API JSON - ela será lançada.
Relacionamentos muitos para muitos complexos com opções avançadas . Além disso, todas as tabelas de conexão são exibidas:
01. GET /users?include =users_comments /1.1
02.
03. ...
04. "relationships": {
05. "users_comments": {
06. "data": [{ "type": "users_comments", "id": "1″ }, ...]
07. },
08. }Swagger
O Swagger é uma ferramenta de escrita de documentação on-line.
Digamos que nosso desenvolvedor de back-end foi convidado a escrever a documentação para sua API e ele a escreveu. Isso é fácil se a API for simples. Se essa é uma API JSON, o Swagger não pode ser gravado tão facilmente.
Exemplo: loja de animais Swagger. Cada método pode ser aberto, consulte resposta e exemplos.
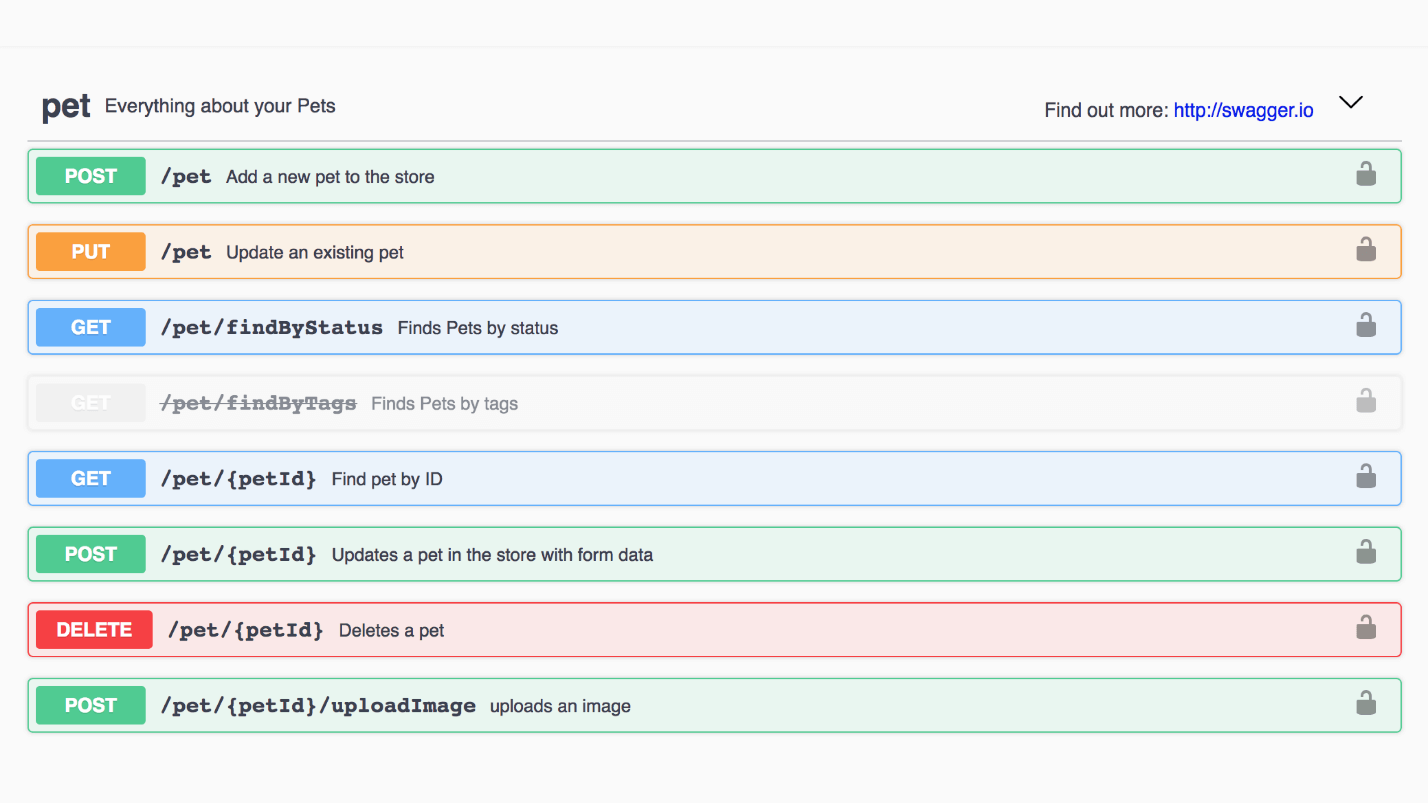
Este é um exemplo de um modelo de animal de estimação. Aqui está uma interface legal, tudo é fácil de ler.
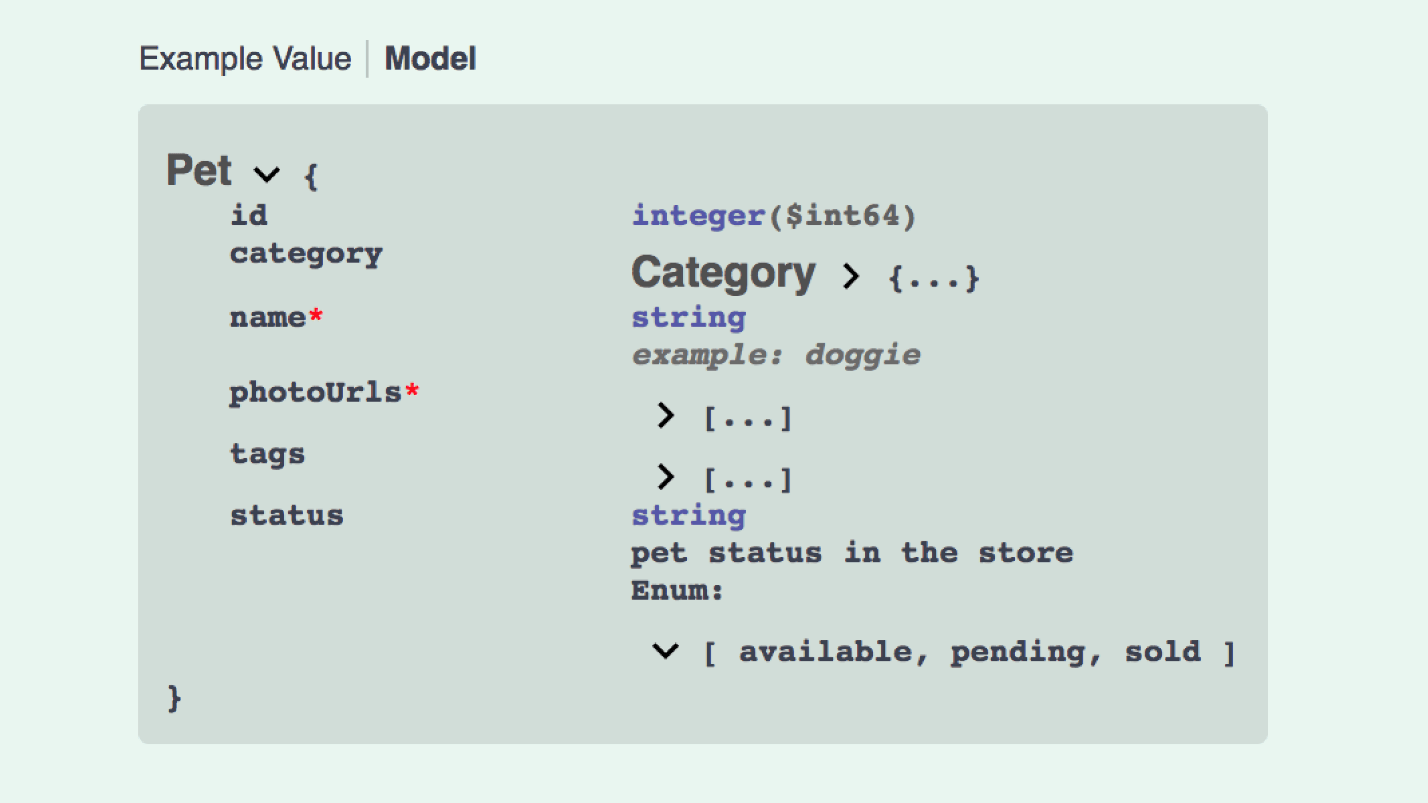
E é assim que a criação do modelo da API JSON se parece:

Isso não é tão bom. Precisamos de dados, em dados com relacionamentos, incluídos 5 tipos de modelos, etc. Você pode escrever o Swagger, a API aberta é uma coisa poderosa, mas complicada.
Alternativa
Existe uma especificação OData, que apareceu um pouco mais tarde - em 2015. Esta é "a melhor maneira de descansar", como garante o site oficial. É assim:
01. GET http://services.odata.org/v4/TripRW/People HTTP/1.1 - solicitação GET;
02. OData-Version: 4.0 - cabeçalho especial com versão;
03. OData-MaxVersion: 4.0 - Segundo cabeçalho da versão especial
A resposta é assim:
01. HTTP/1.1 200 OK
02. Content-Type: application/json; odata.metadata=minimal
03. OData-Version: 4.0
04. {
05. '@odata.context': 'http://services.odata.org/V4/
06. '@odata.nextLink' : 'http://services.odata.org/V4/
07. 'value': [{
08. '@odata.etag': 1W/108D1D5BD423E51581′,
09. 'UserName': 'russellwhyte',
10. ...
Aqui está o aplicativo / json e o objeto estendidos.
Primeiro, não usamos o OData, pois é o mesmo que a API JSON, mas não é conciso. Existem objetos enormes e me parece que tudo é muito pior. O OData também saiu em código aberto, mas é mais complicado.
E o GraphQL?
Naturalmente, quando procurávamos um novo formato de API, encontramos esse hype.
●
Limiar alto de entrada.Do ponto de vista do frontend, tudo parece legal, mas você não pode fazer o novo desenvolvedor escrever o GraphQL, porque você precisa estudá-lo primeiro. É como o SQL - você não pode escrever o SQL imediatamente, você deve pelo menos ler o que é, seguir os tutoriais, ou seja, o limite de entrada aumenta.
●
O efeito do big bang.Se não havia API no projeto e começamos a usar o GraphQL, depois de um mês percebemos que isso não nos convinha, será tarde demais. Tem que escrever muletas. Você pode evoluir com a API JSON ou OData - o RESTful mais simples, que melhora progressivamente, se transforma em uma API JSON.
●
Inferno no back-end.O GraphQL chama o inferno no back-end - um a um, assim como a API JSON totalmente implementada, porque o GraphQL obtém controle total sobre as consultas, e essa é uma biblioteca, e você precisará resolver várias perguntas:
- controle de aninhamento;
- recursão
- limitação de frequência;
- controle de acesso.
Em vez de conclusões
Eu recomendo parar de discutir sobre o galpão da bicicleta e usar a ferramenta anti-ciclismo como uma especificação e apenas fazer uma API com uma boa especificação.
Para encontrar seu padrão para resolver o problema de um galpão de bicicleta, você pode olhar para estes links:
●
http://jsonapi.org●
http://www.odata.org●
https://graphgl.org●
http://xmlrpc.scripting.com●
https://www.jsonrpc.org: alexey-avdeev.com github .
, Frontend Conf , 27 28 ++ . , .
? ? ? , ? !
, , , , .