Neste artigo, você aprenderá tudo sobre a biblioteca da Babilônia e, o mais importante - como recriá-la e, de fato, qualquer biblioteca.
Vamos começar com as citações da
Biblioteca Babilônica de
Luis Borges .
Citação“O universo - alguns chamam de Biblioteca - consiste em um número enorme e possivelmente infinito de galerias hexagonais, com amplas câmaras de ventilação fechadas por trilhos baixos. De cada hexágono, dois andares superiores e dois inferiores são visíveis - até o infinito. ”
“Uma biblioteca é uma bola, cujo centro exato está em um dos hexágonos e a superfície é inacessível. Em cada parede de cada hexágono há cinco prateleiras, em cada prateleira há trinta e dois livros do mesmo formato, cada livro tem quatrocentos e dez páginas, cada página tem quarenta linhas, cada linha contém cerca de oitenta letras pretas. Há letras na lombada do livro, mas elas não definem nem prenunciam o que as páginas dirão. Essa discrepância, eu sei, parecia misteriosa.
Se você digitar um hexágono aleatório, vá até qualquer parede, olhe para qualquer prateleira e pegue o livro que mais gosta, e provavelmente ficará chateado. Afinal, você esperava descobrir o significado da vida lá, mas viu um conjunto estranho de caracteres. Mas não fique chateado tão rapidamente! A maioria dos livros não tem sentido, porque é uma pesquisa combinatória de todas as variantes possíveis de vinte e cinco caracteres (
é esse alfabeto que Borges usou em sua biblioteca, mas o leitor descobrirá que pode haver qualquer número de caracteres na biblioteca ). A principal lei da biblioteca é que não há dois livros absolutamente idênticos, portanto seu número é finito e a biblioteca também terminará um dia. Borges acreditava que a biblioteca é periódica:
Citação“Talvez o medo e a velhice estejam me enganando, mas acho que a raça humana - a única - está perto da extinção e a Biblioteca sobreviverá: iluminada, desabitada, infinita, absolutamente imóvel, cheia de volumes preciosos, inútil, incorrupta, misteriosa. Eu apenas escrevi sem fim. Eu não coloquei essa palavra por amor à retórica; Eu acho que é lógico supor que o mundo é interminável. Aqueles que o consideram limitado admitem que em algum lugar à distância, corredores, escadas e hexágonos podem terminar por algum motivo desconhecido - tal suposição é absurda. Quem o imagina sem limites esquece que o número de livros possíveis é limitado. Atrevo-me a propor uma solução para esse problema antigo: a biblioteca é ilimitada e periódica. Se o andarilho eterno embarcasse em uma jornada em qualquer direção, ele seria capaz de verificar, após séculos, que os mesmos livros são repetidos na mesma bagunça (que, quando repetidos, se torna ordem - Ordem). Essa graciosa esperança ilumina minha solidão.
Comparado ao absurdo, existem muito poucos livros cujo conteúdo uma pessoa possa pelo menos entender de alguma forma, mas isso não muda o fato de a biblioteca conter todos os textos que foram e serão sempre inventados por uma pessoa. Além disso, desde a infância você está acostumado a considerar significativas algumas seqüências de símbolos, enquanto outras não. De fato, no contexto da biblioteca, não há diferença entre eles. Mas o que faz sentido tem uma porcentagem muito menor, e chamamos isso de linguagem. Este é um meio de comunicação entre as pessoas. Qualquer idioma contém apenas algumas dezenas de milhares de palavras, das quais sabemos 70% da força; portanto, não podemos interpretar a maior parte da pesquisa combinatória de livros. E alguém sofre de
apofenia e, mesmo em conjuntos aleatórios de caracteres, vê um significado oculto. Mas essa é uma boa ideia para
esteganografia ! Bem, continuo discutindo esse tópico nos comentários.
Antes de prosseguir com a implementação desta biblioteca, surpreenderei você com um fato interessante: se você deseja recriar a biblioteca babilônica de Louis Borges, não terá êxito, porque seus volumes excedem o volume do Universo visível 10 ^ 611338 (!) Times. E sobre o que acontecerá em bibliotecas ainda maiores, tenho medo de pensar.
Implementação da biblioteca
Descrição do módulo
Nossa pequena introdução acabou. Mas não é sem sentido: agora você entende como é a biblioteca da Babilônia, e continuar lendo será apenas mais interessante. Mas vou me afastar da idéia original, queria criar uma biblioteca "universal", que será discutida mais adiante. Escreverei em JavaScript em Node.js. O que a biblioteca deve fazer?
- Encontre rapidamente o texto desejado e exiba sua localização na biblioteca
- Definir um título de livro
- Encontre um livro com o título certo rapidamente
Além disso, deve ser universal, ou seja, qualquer um dos parâmetros da biblioteca pode ser alterado, se eu quiser. Bem, acho que vou mostrar primeiro o código inteiro do módulo, vamos analisá-lo em detalhes, ver como ele funciona e vou dizer algumas palavras.
Repositório do GithubO arquivo principal é index.js, toda a lógica da biblioteca é descrita lá, explicarei o conteúdo desse arquivo.
let sha512 = require(`js-sha512`);
Conectamos o módulo implementando o
algoritmo de hash
sha512 . Pode parecer estranho para você, mas ainda será útil para nós.
Qual é a saída do nosso módulo? Ele retorna uma função, uma chamada à qual retornará um objeto de biblioteca com todos os métodos necessários. Poderíamos devolvê-lo imediatamente, mas o gerenciamento da biblioteca não seria tão conveniente quando passamos parâmetros para a função e obtivemos a biblioteca "necessária". Isso nos permitirá criar uma biblioteca "universal". Como tento escrever no estilo ES6, minha função de seta aceita um objeto como parâmetro, que posteriormente será destruído nas variáveis necessárias:
module.exports = ({ lengthOfPage = 4819, lengthOfTitle = 31, digs = '0123456789abcdefghijklmnopqrstuvwxyz', alphabet = ', .', wall = 5, shelf = 7, volume = 31, page = 421, } = {}) => {
Agora vamos revisar os parâmetros. Como parâmetros numéricos padrão, decidi escolher números primos, porque me pareceu que seria mais interessante.
- lengthOfPage - número, número de caracteres em uma página. O padrão é 4819. Se fatorarmos esse número, obtemos 61 e 79. 61 linhas de 79 caracteres, ou vice-versa, mas prefiro a primeira opção.
- lengthOfTitle - número, número de caracteres no título do título do livro.
- digs - uma string, possíveis dígitos de um número com uma base igual ao comprimento dessa string. Para que serve esse número? Ele conterá o número (identificador) do hexágono para o qual queremos ir. Por padrão, é minúsculo em latim e os números de 0 a 9. A maior parte do texto é codificada aqui, então será um número grande - vários milhares de bits (dependendo do número de caracteres na página), mas será processado caractere por caractere.
- alfabeto - a sequência, os caracteres que queremos ver na biblioteca. Será preenchido com eles. Para que tudo funcione corretamente, o número de caracteres no alfabeto deve ser igual ao número de caracteres na sequência com possíveis dígitos do número que identifica o hexágono.
- número da parede , número máximo da parede, padrão 5
- prateleira - número, número máximo de prateleira , padrão 7
- volume - número, número máximo de livros, por padrão 31
- page - number, número máximo de páginas, padrão 421
Como você pode ver, isso é um pouco como a verdadeira biblioteca babilônica de Luis Borges. Mas eu já disse mais de uma vez que criaremos bibliotecas "universais" que podem ser da maneira que queremos vê-las (portanto, o número hexadecimal pode ser interpretado de alguma maneira diferente, por exemplo, apenas o identificador de algum lugar onde o desejado é armazenado informações). A biblioteca babilônica é apenas uma delas. Mas todos eles têm muito em comum - um algoritmo é responsável por seu desempenho, que será discutido agora.
Pesquisa de página e algoritmos de exibição
Quando vamos a algum endereço, vemos o conteúdo da página. Se formos para o mesmo endereço novamente, o conteúdo deve ser exatamente o mesmo. Essa propriedade de bibliotecas fornece um algoritmo para gerar números pseudo-aleatórios - o
método congruente linear . Quando precisamos selecionar um caractere para gerar o endereço ou, inversamente, o conteúdo da página, isso nos ajudará, e o grão usará números de página, prateleiras etc. A configuração do meu PRNG: m = 2 ^ 32 (4294967296), a = 22695477, c = 1. Gostaria também de acrescentar que em nossa implementação apenas o princípio da geração de números permanece a partir do método congruente linear, o resto é alterado. Seguimos adiante na lista de programas:
Código module.exports = ({ lengthOfPage = 4819, lengthOfTitle = 31, digs = '0123456789abcdefghijklmnopqrstuvwxyz', alphabet = ', .', wall = 5, shelf = 7, volume = 31, page = 421, } = {}) => { let seed = 13;
Como você pode ver, o grão PRNG muda após cada recebimento do número, e os resultados dependem diretamente do chamado ponto de referência - o grão, após o qual os números nos interessarão. (geramos o endereço ou obtemos o conteúdo da página)
A função
getHash nos ajudará a gerar um ponto de referência. Nós apenas obtemos um hash de alguns dados, pegamos 7 caracteres, convertemos em um sistema de números decimais e pronto!
A função
mod se comporta da mesma forma que o operador%. Mas se o dividendo for <0 (tais situações são possíveis), a função
mod retornará um número positivo devido à estrutura especial, precisamos disso para selecionar corretamente os caracteres da sequência do
alfabeto ao receber o conteúdo da página no endereço.
E a última parte do código de sobremesa é o objeto de biblioteca retornado:
Código return { wall, shelf, volume, page, lengthOfPage, lengthOfTitle, search(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), page = pad(`${(Math.random()* this.page + 1 ^ 0)}`, 3), locHash = getHash(`${wall}${shelf}${volume}${page}`), hex = ``, depth = Math.random() * (this.lengthOfPage - searchStr.length) ^ 0; for (let i = 0; i < depth; i++){ searchStr = alphabet[Math.random() * alphabet.length ^ 0] + searchStr; } seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]] || -1, rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}-${+page}`; }, searchExactly(text) { const pos = Math.random() * (this.lengthOfPage - text.length) ^ 0; return this.search(`${` `.repeat(pos)}${text}${` `.repeat(this.lengthOfPage - (pos + text.length))}`); }, searchTitle(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), locHash = getHash(`${wall}${shelf}${volume}`), hex = ``; searchStr = searchStr.substr(0, this.lengthOfTitle); searchStr = searchStr.length == this.lengthOfTitle ? searchStr : `${searchStr}${` `.repeat(this.lengthOfTitle - searchStr.length)}`; seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]], rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}`; }, getPage(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}${pad(addressArray[4], 3)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfPage) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfPage); }, getTitle(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfTitle) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfTitle); } };
No começo, escrevemos para ele as propriedades da biblioteca que descrevi anteriormente. Você pode alterá-los mesmo depois que a função principal é chamada (que, em princípio, pode ser chamada de construtor, mas meu código é ligeiramente semelhante à implementação de classe da biblioteca, portanto, eu me limitarei à palavra "principal"). Talvez esse comportamento não seja totalmente adequado, mas flexível. Agora repasse cada método.
Método de pesquisa
search(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random() * this.volume + 1 ^ 0)}`, 2), page = pad(`${(Math.random() * this.page + 1 ^ 0)}`, 3), locHash = getHash(`${wall}${shelf}${volume}${page}`), hex = ``, depth = Math.random() * (this.lengthOfPage - searchStr.length) ^ 0; for (let i = 0; i < depth; i++){ searchStr = alphabet[Math.random() * alphabet.length ^ 0] + searchStr; } seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]] || -1, rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}-${+page}`; }
Retorna o endereço da string
searchStr na biblioteca. Para fazer isso, selecione aleatoriamente
parede, prateleira, volume, página .
volume e
página também preenchidos com zeros no comprimento desejado. Em seguida, concatene-os em uma sequência para passar para a função
getHash . O
locHash resultante é o ponto de partida, ou seja, o grão.
Para maior imprevisibilidade, suplementamos a
profundidade da busca com caracteres pseudo
- aleatórios do alfabeto, configuramos a semente
inicial para
locHash . Nesse estágio, não importa como complementamos a linha, para que você possa usar o JavaScript PRNG interno, isso não é crítico. Você pode abandoná-lo completamente para que os resultados de seu interesse estejam sempre no topo da página.
A única coisa que resta é gerar o identificador hexagonal. Para cada caractere da string
searchStr , executamos o algoritmo:
- Obtenha o número do caractere de índice no alfabeto do objeto alphabetIndexes . Caso contrário, retorne -1, mas se isso acontecer, você definitivamente está fazendo algo errado.
- Gere um número pseudo-aleatório usando nosso PRNG, no intervalo de 0 ao comprimento do alfabeto.
- Calcule o novo índice, que é calculado como a soma do número do índice de símbolos e o número pseudo-aleatório rand , dividido em módulo, o comprimento das escavações .
- Assim, obtivemos o dígito do identificador hexagonal - newChar (retirando-o das escavações ).
- Adicionar newChar ao identificador hexadecimal hex
Após a conclusão da geração
hexadecimal , retornamos o endereço completo do local em que a linha desejada está contida. Os componentes de endereço são separados por um hífen.
Método SearchExactly
searchExactly(text) { const pos = Math.random() * (this.lengthOfPage - text.length) ^ 0; return this.search(`${` `.repeat(pos)}${text}${` `.repeat(this.lengthOfPage - (pos + text.length))}`); }
Esse método faz o mesmo que o método de
pesquisa , mas preenche todo o espaço livre (faz com que a cadeia de caracteres de
pesquisa searchStr tenha um comprimento de caracteres
lengthOfPage ). Ao visualizar uma página, parece que não há nada além do seu texto.
Método SearchTitle
searchTitle(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), locHash = getHash(`${wall}${shelf}${volume}`), hex = ``; searchStr = searchStr.substr(0, this.lengthOfTitle); searchStr = searchStr.length == this.lengthOfTitle ? searchStr : `${searchStr}${` `.repeat(this.lengthOfTitle - searchStr.length)}`; seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]], rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}`; }
O método
searchTitle retorna o endereço de um livro chamado
searchStr . No interior, é muito semelhante à
pesquisa . A diferença é que, ao calcular o
locHash , não usamos a página para vincular seu nome ao livro. Não deve depender da página.
searchStr é truncado para
lengthOfTitle e preenchido com espaços, se necessário. Da mesma forma, o identificador hexagonal é gerado e o endereço recebido é retornado. Observe que não há nenhuma página nela, como era ao procurar o endereço exato do texto arbitrário. Portanto, se você quiser descobrir o que há no livro com o nome que você cunhou, decida a página que deseja acessar.
Método GetPage
getPage(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}${pad(addressArray[4], 3)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfPage) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfPage); }
O oposto do método de
pesquisa . Sua tarefa é retornar o conteúdo da página para o endereço especificado. Para fazer isso, convertemos o endereço em uma matriz usando o separador "-". Agora, temos uma variedade de componentes de endereço: identificador hexagonal, parede, estante, livro, página.
Computamos o
locHash da mesma maneira que fizemos no método de
pesquisa . Obtemos o mesmo número que estava ao gerar o endereço. Isso significa que o PRNG produzirá os mesmos números, é esse comportamento que garante a reversibilidade de nossas transformações sobre o texto de origem. Para calcular, executamos o algoritmo em cada caractere (de fato, este é um dígito) do identificador hexagonal:
- Computamos o índice nas escavações de string. Tomá-lo de digsIndexes .
- Usando o PRNG, geramos um número pseudo-aleatório no intervalo 0 até a base do sistema numérico de um número grande igual ao comprimento da string que contém os dígitos desse belo número. Tudo é óbvio.
- Calculamos a posição do símbolo do texto fonte newIndex como a diferença entre índice e rand , dividido em módulo, o comprimento do alfabeto. Uma situação é possível em que a diferença é negativa, então o módulo de divisão usual fornecerá um índice negativo, o que não nos convém, portanto, usamos uma versão modificada da divisão de módulo. (você pode tentar a opção de usar o valor absoluto da fórmula acima, isso também resolve o problema dos números negativos, mas na prática isso ainda não foi testado)
- O caractere do texto da página é newChar , obtemos o índice do alfabeto.
- Adicione um caractere de texto ao resultado.
O resultado obtido nesta etapa nem sempre preencherá a página inteira, portanto, calcularemos a nova granulação a partir do resultado atual e preencheremos o espaço livre com caracteres do alfabeto. O PRNG nos ajuda a escolher um símbolo.
Isso completa o cálculo do conteúdo da página, retornamos, não esquecendo de cortar no tamanho máximo. Talvez o identificador hexagonal tenha sido indecentemente grande no endereço de entrada.
Método GetTitle
getTitle(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfTitle) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfTitle); }
Bem, a história é a mesma. Imagine ler a descrição do método anterior, apenas ao calcular os grãos do PRNG, não leve em consideração o número da página e adicione e recorte o resultado ao tamanho máximo do título do livro -
lengthOfTitle .
Testando o módulo para criar bibliotecas
Depois de examinarmos o princípio de operação de qualquer biblioteca parecida com a da Babilônia - é hora de tentar tudo na prática. Usarei a configuração o mais próximo possível da criada por Louis Borges. Procuraremos uma frase simples "habr.com":
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
Execute, o resultado:

No momento, isso não nos dá nada. Mas vamos descobrir o que está oculto por trás desse endereço! O código será assim:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
Resultado:
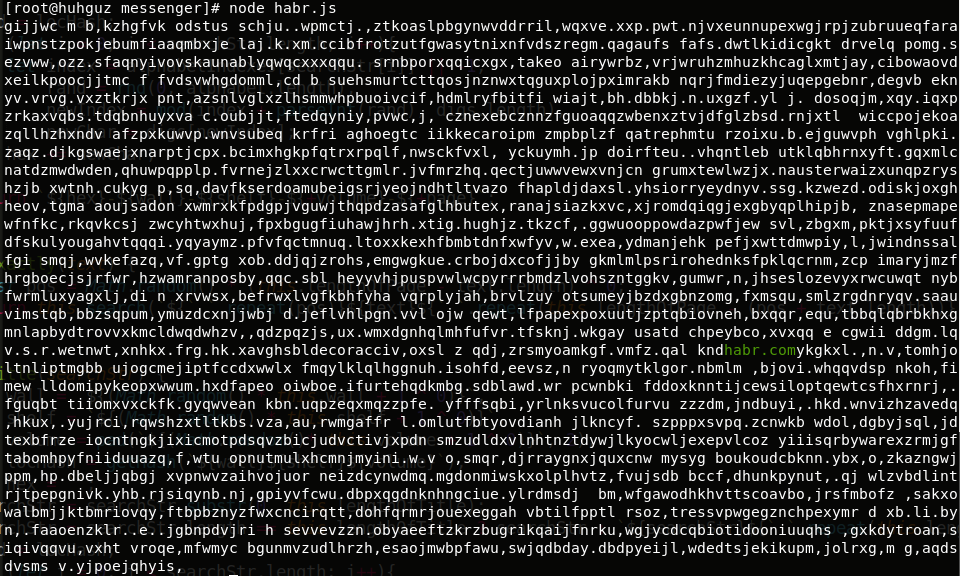
Encontramos o que procurávamos em um número infinito de páginas sem sentido (aposto)!
Mas este está longe de ser o único local onde esta frase está localizada. Na próxima vez que o programa iniciar, outro endereço será gerado. Se quiser, você pode salvar um e trabalhar com ele. O principal é que o conteúdo das páginas nunca muda. Vejamos o título do livro em que nossa frase está localizada. O código será o seguinte:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
O título do livro é mais ou menos assim:
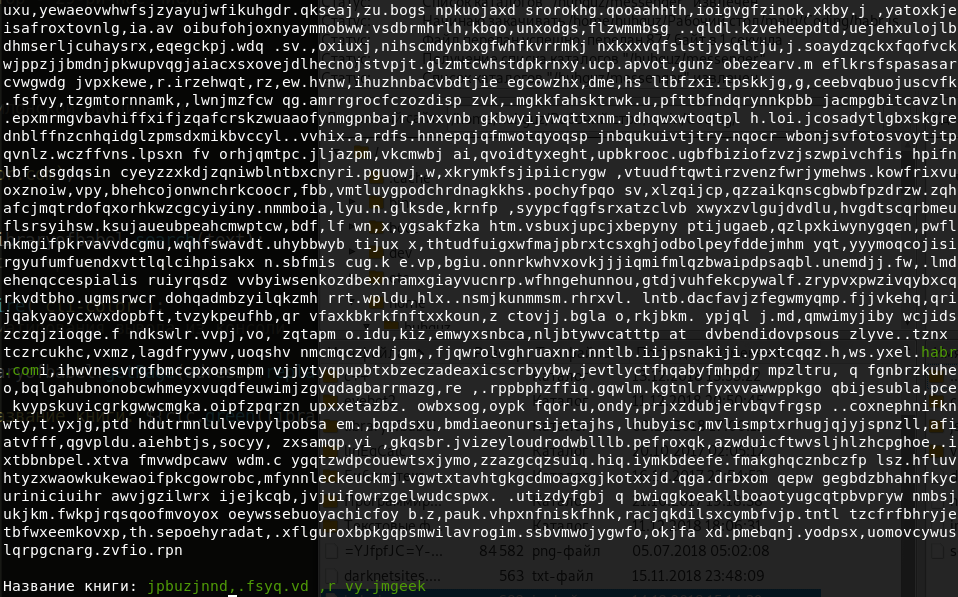
Honestamente, não parece muito atraente. Então vamos encontrar um livro com a nossa frase no título:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
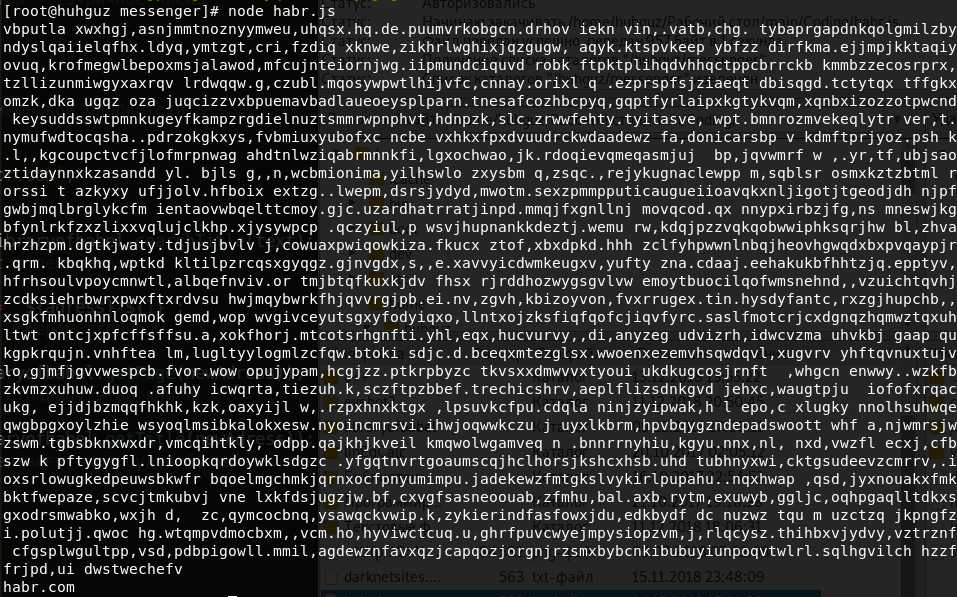
Agora você entende como usar esta biblioteca. Deixe-me demonstrar a possibilidade de criar uma biblioteca completamente diferente. Agora ele será preenchido com uns e zeros, cada página terá 100 caracteres e o endereço será um número hexadecimal. Não se esqueça de observar a condição de igualdade dos comprimentos do alfabeto e a sequência de dígitos do nosso grande número. Procuraremos, por exemplo, "10101100101010111001000000". Nós olhamos:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 100, alphabet: `1010101010101010`,

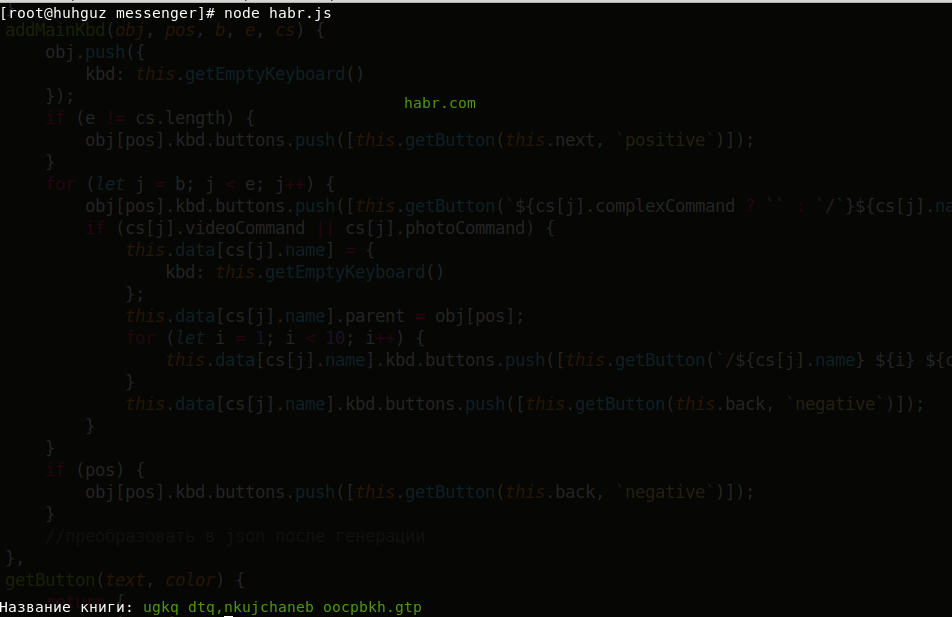
Vamos dar uma olhada em encontrar uma correspondência completa. Para fazer isso,
vamos voltar ao exemplo antigo e no código substituir
libraryofbabel.search por
libraryofbabel.searchExactly :
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
Conclusão
Depois de ler a descrição do algoritmo de operação da biblioteca, você provavelmente já adivinhou que isso era uma espécie de engano. - , . , . . , , , . , , .
.
: , . — . , ,
base64 , ?
— - . , , (-, . , ?), . , - , . , . , , . ? , .
Essa idéia pode ser usada para criar uma variedade de "bibliotecas". Você pode interagir não apenas com personagens, mas também com palavras inteiras ou até sons! Imagine um lugar onde você possa ouvir absolutamente qualquer som disponível para a percepção humana ou encontrar algum tipo de música. No futuro, definitivamente tentarei implementar isso.A versão web em russo está disponível aqui , é implantada no meu servidor virtual. Não conheço todas as pesquisas agradáveis sobre o sentido da vida na biblioteca da Babilônia ou o que você deseja criar. Tchau! :)