Parece que estamos tão imersos na selva do desenvolvimento de grandes cargas que simplesmente não pensamos nos problemas básicos. Tome, por exemplo, sharding. O que entender se é possível escrever shards = n condicionalmente nas configurações do banco de dados e tudo será feito por si só. Está certo, ele está, mas se, ao contrário, quando algo der errado, os recursos começarem a ser realmente escassos, eu gostaria de entender qual é o motivo e como corrigi-lo.
Em resumo, se você estava contribuindo com sua implementação alternativa de hash no Cassandra, dificilmente haverá revelações para você. Mas se a carga nos seus serviços já estiver chegando e o conhecimento do sistema não a acompanhar, será bem-vindo. O grande e terrível
Andrei Aksyonov (
shodan ), em sua maneira usual, dirá que o
sharding é ruim, não o sharding também é ruim , e como é organizado dentro. E por acidente, uma das partes da história sobre sharding não é realmente sobre sharding, mas o diabo sabe sobre o que - como mapear objetos para shards.

A foto das focas (apesar de acidentalmente serem filhotes) parece responder à pergunta de por que isso é tudo, mas vamos começar em sequência.
O que é sharding?
Se você persistentemente pesquisa no Google, verifica-se que há uma borda bastante desfocada entre o chamado particionamento e o chamado sharding. Todo mundo chama tudo o que ele quer do que ele quer. Algumas pessoas distinguem entre particionamento horizontal e sharding. Outros dizem que o sharding é um certo tipo de particionamento horizontal.
Não encontrei um único padrão terminológico que fosse aprovado pelos pais fundadores e certificado na ISO. Uma crença pessoal interna é mais ou menos assim:
particionar em média é "cortar a base em pedaços" de uma maneira arbitrária.
- Particionamento vertical Por exemplo, há uma tabela gigante com alguns bilhões de entradas em 60 colunas. Em vez de manter uma dessas tabelas gigantescas, mantemos 60 tabelas gigantescas com 2 bilhões de registros cada - e isso não é de meio período, mas de particionamento vertical (como um exemplo de terminologia).
- Particionamento horizontal - cortamos linha por linha, talvez dentro do servidor.
O momento embaraçoso aqui é a diferença sutil entre particionamento horizontal e sharding. Você pode me cortar em pedaços, mas não vou lhe dizer com certeza em que consiste. Há um sentimento de que sharding e particionamento horizontal são praticamente a mesma coisa.
O sharding é geralmente quando uma tabela grande em termos de bancos de dados ou uma coleção de documentos, objetos, se você não possui um banco de dados, mas um armazenamento de documentos, é cortada especificamente para objetos. Ou seja, peças de 2 bilhões de objetos são selecionadas, independentemente do tamanho. Os objetos por si mesmos dentro de cada objeto não são cortados em pedaços, não nos decompomos em colunas separadas, ou seja, colocamos feixes em lugares diferentes.
Link para a apresentação para mais detalhes.Já existem diferenças terminológicas sutis. Por exemplo, relativamente falando, os desenvolvedores do Postgres podem dizer que o particionamento horizontal ocorre quando todas as tabelas nas quais a tabela principal está dividida estão no mesmo esquema e, quando em máquinas diferentes, ele está compartilhando.
De um modo geral, sem estar vinculado à terminologia de um banco de dados específico e de um sistema de gerenciamento de dados específico, existe a sensação de que o sharding está apenas cortando linha por linha e assim por diante - e é tudo:
Sharding (~ =, \ in ...) Particionamento Horizontal == é típico.
Eu enfatizo, tipicamente. No sentido de que fazemos tudo isso não apenas para cortar 2 bilhões de documentos em 20 tabelas, cada um dos quais seria mais gerenciável, mas para distribuí-lo em vários núcleos, muitos discos ou muitos servidores físicos ou virtuais .
Entende-se que estamos fazendo isso para que todos os shard - todos os dados shatka - sejam replicados muitas vezes. Mas na verdade não.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
De fato, se você fizer uma fatia desses dados e de uma tabela gigante do SQL no MySQL, você gerará 16 pequenas tabelas no seu valioso laptop, sem ir além de um único laptop, nem de um esquema, nem de um banco de dados, etc. etc. - tudo, você já tem sharding.
Lembrando a ilustração com filhotes, isso leva ao seguinte:
- A largura de banda está aumentando.
- A latência não muda, ou seja, cada trabalhador ou consumidor, por assim dizer, nesse caso, recebe o seu. Não se sabe o que os filhotes aparecem na foto, mas os pedidos são atendidos aproximadamente ao mesmo tempo, como se o filhote estivesse sozinho.
- Ou ambos, e outro, e ainda alta disponibilidade (replicação).
Por que largura de banda? Às vezes, podemos ter esses volumes de dados que não se encaixam - não está claro onde, mas eles não se encaixam - por 1 {core | dirigir | servidor | ...}. Simplesmente não há recursos suficientes e é isso. Para trabalhar com esse grande conjunto de dados, é necessário cortá-lo.
Por que latência? Em um núcleo, a varredura de uma tabela de 2 bilhões de linhas é 20 vezes mais lenta que a varredura de 20 tabelas em 20 kernels, fazendo isso em paralelo. Os dados estão sendo processados muito lentamente em um recurso.
Por que alta disponibilidade? Ou cortamos os dados para fazer uma e outra ao mesmo tempo e, ao mesmo tempo, várias cópias de cada shard - replication fornecem alta disponibilidade.
Um exemplo simples de "como fazer isso com as mãos"
O sharding condicional pode ser cortado usando a tabela de teste test.documents para 32 documentos e gerando a partir desta tabela 16 tabelas de teste para cerca de 2 documentos test.docs00, 01, 02, ..., 15 cada.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
Porque? Como a priori, não sabemos como o ID é distribuído, se de 1 a 32 inclusive, haverá exatamente 2 documentos cada, caso contrário, não.
Estamos fazendo isso por quê. Depois de fazermos 16 tabelas, podemos “capturar” 16 do que precisamos. Independentemente do que apoiamos, podemos paralelizar esses recursos. Por exemplo, se não houver espaço em disco suficiente, fará sentido decompor essas tabelas em discos separados.
Infelizmente, tudo isso não é gratuito. Eu suspeito que, no caso do padrão SQL canônico (não reli o padrão SQL por um longo tempo, talvez ele não tenha sido atualizado por muito tempo), não há sintaxe padronizada oficial para dizer a qualquer servidor SQL: “Caro servidor SQL, faça-me 32 shards e coloque-os em 4 discos ". Mas em implementações individuais, geralmente há uma sintaxe específica para fazer o mesmo em princípio. O PostgreSQL possui mecanismos de particionamento, o MySQL MariaDB possui, a Oracle provavelmente já fez tudo isso há muito tempo.
No entanto, se fizermos isso manualmente, sem suporte ao banco de dados e dentro da estrutura do padrão,
pagaremos condicionalmente a complexidade do acesso aos dados . Onde havia um simples SELECT * FROM documentos WHERE id = 123, agora 16 x SELECT * FROM docsXX. E bem, se tentássemos obter o registro por chave. Significativamente mais interessante se tentássemos obter uma faixa inicial de registros. Agora (se, enfatizo, como se eu fosse tolo, e permaneço dentro do padrão), os resultados desses 16 SELECT * FROM deverão ser combinados no aplicativo.
Que mudança de desempenho esperar?- Intuitivamente linear.
- Teoricamente - sublinear, porque a lei de Amdahl .
- Na prática - talvez quase linearmente, talvez não.
De fato, a resposta correta é desconhecida. Com a aplicação inteligente da técnica de sharding, você pode obter uma deterioração super-linear significativa na operação do seu aplicativo, e até o DBA estará funcionando com um pôquer em brasa.
Vamos ver como isso pode ser alcançado. É claro que apenas definir a configuração como shards do PostgreSQL = 16 e depois decolar - isso não é interessante. Vamos pensar em como poderíamos conseguir que
reduziríamos a fragmentação em 32 vezes , o que é interessante do ponto de vista de como não fazer isso.
Nossas tentativas de acelerar ou desacelerar sempre ficarão contra os clássicos - a boa e velha lei da Amdahl, que diz que não há paralelização perfeita de nenhuma solicitação, sempre há uma parte consistente.
Lei Amdahl
Sempre há uma peça serializada.
Sempre há uma parte da execução da solicitação que é paralela e sempre há uma parte que não é paralela. Mesmo que pareça para você uma consulta perfeitamente paralela, pelo menos coletando uma linha do resultado que você enviará ao cliente, a partir das linhas recebidas de cada shard, sempre haverá e sempre será consistente.
Sempre há algum tipo de parte seqüencial. Pode ser minúsculo, absolutamente invisível no contexto geral, pode ser gigantesco e, consequentemente, afetar fortemente a paralelização, mas está sempre lá.
Além disso, sua influência está
mudando e pode crescer significativamente, por exemplo, se reduzirmos nossa tabela - vamos aumentar as taxas - de 64 registros para 16 tabelas de 4 registros, essa parte será alterada. Obviamente, a julgar por quantidades tão gigantescas de dados, trabalhamos em um telefone celular e processador de 86 MHz, não temos arquivos suficientes que possam ser mantidos abertos ao mesmo tempo. Aparentemente, com essa entrada, abrimos um arquivo por vez.
- Foi Total = Serial + Paralelo . Onde, por exemplo, paralelo é todo o trabalho dentro do banco de dados e o serial está enviando o resultado ao cliente.
- Tornou-se Total2 = Serial + Paralelo / N + Xserial. Por exemplo, quando o geral ORDER BY, Xserial> 0.
Com este exemplo simples, tento mostrar que algum Xserial aparece. Além do fato de sempre haver uma parte serializada e de estarmos tentando trabalhar com dados em paralelo, uma parte adicional aparece para garantir o corte desses dados. Grosso modo, podemos precisar de:
- encontre essas 16 tabelas no dicionário interno do banco de dados;
- abrir arquivos;
- alocar memória;
- realocar memória;
- manchar os resultados;
- sincronizar entre núcleos;
Os efeitos fora de sincronia sempre aparecem. Eles podem ser insignificantes e ocupar um bilionésimo do tempo total, mas são sempre diferentes de zero e sempre existem. Com a ajuda deles, podemos perder drasticamente a produtividade após o sharding.
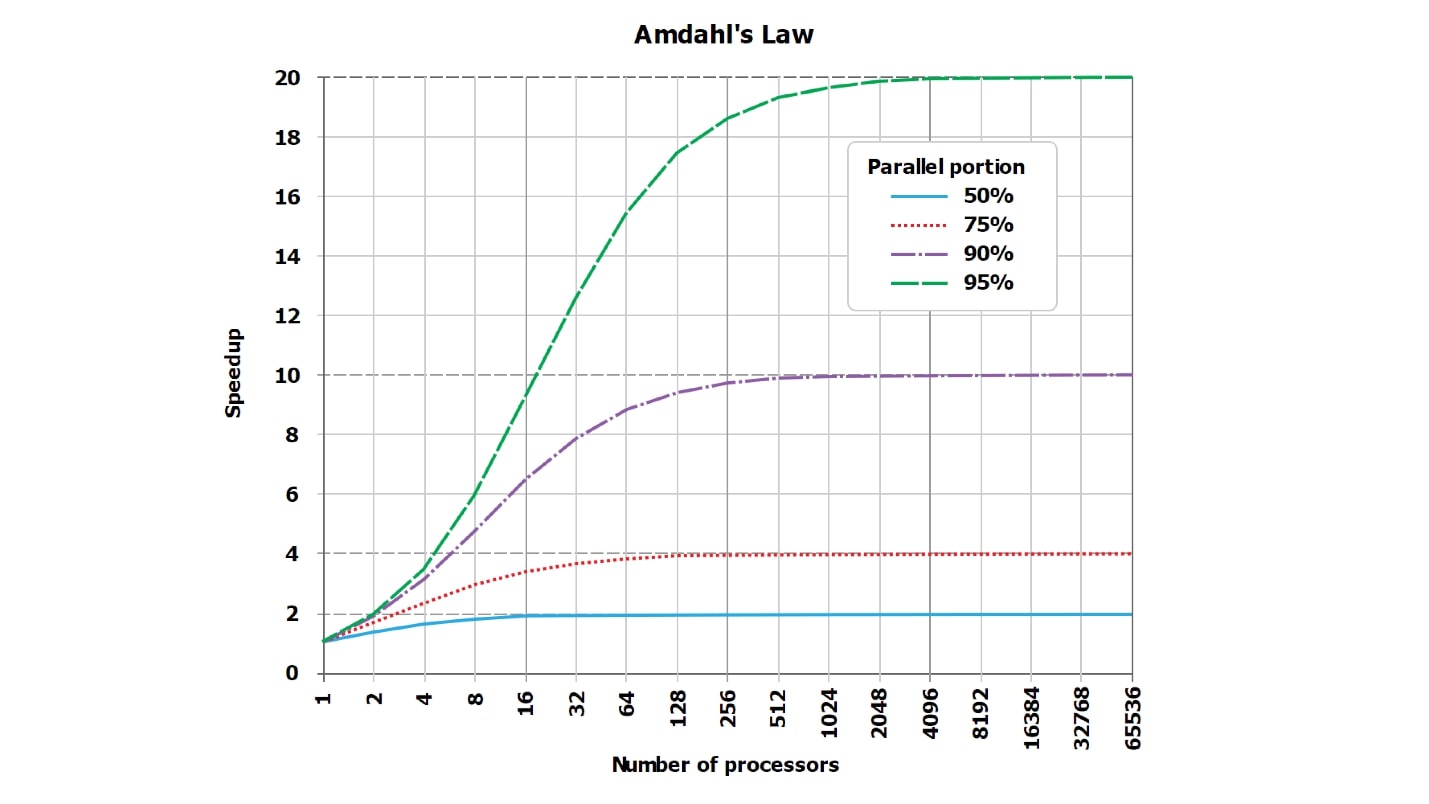
Esta é uma imagem padrão da lei de Amdahl. Não é muito legível, mas é importante que as linhas, que idealmente sejam retas e cresçam linearmente, encostem na assíntota. Mas como o gráfico da Internet é ilegível, criei, na minha opinião, mais tabelas visuais com números.
Suponha que tenhamos uma parte serializada do processamento da solicitação, que leva apenas 5%:
serial = 0,05 = 1/20.Intuitivamente, parece que, com a parte serializada, que leva apenas 1/20 do processamento da solicitação, se paralelizarmos o processamento da solicitação a 20 núcleos, ele se tornará cerca de 20, na pior das hipóteses, 18 vezes mais rápido.
De fato, a
matemática é uma coisa sem coração :
wall = 0.05 + 0.95/num_cores, speedup = 1 / (0.05 + 0.95/num_cores)Acontece que, se você calcular cuidadosamente, com uma parte serializada de 5%, a aceleração será 10 vezes (10,3), e isso é 51% comparado ao ideal teórico.
| 8 núcleos | = 5,9 | = 74% |
| 10 núcleos | = 6,9 | = 69% |
| 20 núcleos | = 10,3 | = 51% |
| 40 núcleos | = 13,6 | = 34% |
| 128 núcleos | = 17,4 | = 14% |
Usando 20 núcleos (20 discos, se você preferir) para a tarefa em que trabalhamos antes, teoricamente nunca obteremos aceleração mais de 20 vezes, mas praticamente muito menos. Além disso, com um aumento no número de paralelos, a ineficiência está crescendo rapidamente.
Quando apenas 1% do trabalho serializado permanece e 99% é paralelo, os valores de aceleração são um pouco melhorados:
| 8 núcleos | = 7,5 | = 93% |
| 16 núcleos | = 13,9 | = 87% |
| 32 núcleos | = 24,4 | = 76% |
| 64 núcleos | = 39,3 | = 61% |
Para uma consulta completamente termonuclear, que dura naturalmente por horas, e o trabalho preparatório e a montagem do resultado levam muito pouco tempo (serial = 0,001), já veremos uma boa eficiência:
| 8 núcleos | = 7,94 | = 99% |
| 16 núcleos | = 15,76 | = 99% |
| 32 núcleos | = 31,04 | = 97% |
| 64 núcleos | = 60,20 | = 94% |
Observe que
nunca veremos 100% . Em casos particularmente bons, é possível ver, por exemplo, 99,999%, mas não exatamente 100%.
Como embaralhar e quebrar N vezes?
Você pode embaralhar e interromper exatamente N vezes:
- Envie solicitações docs00 ... docs15 sequencialmente , não paralelamente.
- Em consultas simples, não selecione por chave , WHERE algo = 234.
Nesse caso, a parte serializada (serial) ocupa não 1% e não 5%, mas cerca de 20% nos bancos de dados modernos. Você pode obter 50% da parte serializada se acessar o banco de dados usando um protocolo binário extremamente eficiente ou vinculá-lo como uma biblioteca dinâmica a um script Python.
O restante do tempo de processamento de uma solicitação simples será ocupado por operações não paralelas de análise da solicitação, preparação do plano etc. Ou seja, fica mais lento sem ler o registro.
Se dividirmos os dados em 16 tabelas e executá-los seqüencialmente, como é habitual na linguagem de programação PHP, por exemplo, (ele não sabe como executar processos assíncronos muito bem), obtemos a desaceleração em 16 vezes. E, talvez, ainda mais, porque as viagens de ida e volta da rede também serão adicionadas.
De repente, ao compartilhar, a escolha de uma linguagem de programação é importante.
Lembramos da escolha de uma linguagem de programação, porque se você envia consultas ao banco de dados (ou servidor de pesquisa) sequencialmente, de onde vem a aceleração? Em vez disso, uma desaceleração aparecerá.
Bicicleta da vida
Se você escolher C ++,
escreva para Threads POSIX , não Boost I / O. Eu vi uma excelente biblioteca de desenvolvedores experientes da Oracle e do próprio MySQL, que escreveram a comunicação com o servidor MySQL no Boost. Aparentemente, eles foram forçados a escrever em C puro no trabalho, mas depois conseguiram se virar, usar o Boost com E / S assíncrona etc. Um problema - essa E / S assíncrona, que teoricamente deveria ter direcionado 10 solicitações em paralelo, por algum motivo, possuía um ponto de sincronização invisível. Ao iniciar 10 solicitações em paralelo, elas foram executadas exatamente 20 vezes mais devagar que uma, porque 10 vezes para as próprias solicitações e uma vez para o ponto de sincronização.
Conclusão: escreva em linguagens que implementem execução paralela e aguardem bem solicitações diferentes. Para ser sincero, não sei o que exatamente há para aconselhar além do Go. Não só porque eu realmente amo o Go, mas porque não sei nada mais adequado.
Não escreva em idiomas inadequados nos quais você não pode executar 20 consultas paralelas no banco de dados. Ou em todas as oportunidades, não faça tudo com as mãos - entenda como funciona, mas não faça manualmente.
Bicicleta de teste A / B
Às vezes, você pode desacelerar porque está acostumado com o fato de que tudo funciona e não percebeu que a peça serializada, em primeiro lugar, é, em segundo, grande.
- Imediatamente ~ 60 shards de índice de pesquisa, categorias
- Estes são fragmentos corretos e corretos, sob uma área de assunto.
- Havia até 1000 documentos e 50.000 documentos.
Esta é uma bicicleta de produção, quando as consultas de pesquisa foram ligeiramente alteradas e começaram a selecionar muito mais documentos de 60 shards do índice de pesquisa. Tudo funcionou rapidamente e com o princípio: “Funciona - não toque”, todos esqueceram, que na verdade está dentro de 60 estilhaços. Aumentamos o limite de amostragem para cada fragmento de mil para 50 mil documentos. De repente, começou a desacelerar e o paralelismo cessou. Os pedidos em si, que foram executados de acordo com os fragmentos, voaram muito bem, e o palco ficou mais lento, quando 50 mil documentos foram coletados de 60 fragmentos. Esses 3 milhões de documentos finais em um núcleo foram mesclados, classificados e os 3 milhões foram selecionados e entregues ao cliente. A mesma parte serial desacelerou, a mesma lei implacável de Amdal funcionou.
Então talvez você não deva fazer sharding com as mãos, mas apenas humanamente
diga ao banco de dados: "Faça!"
Disclaimer: Eu realmente não sei como fazer algo certo. Eu sou do andar errado !!!
Eu tenho promovido uma religião chamada "fundamentalismo algorítmico" durante toda a minha vida consciente. É brevemente formulado de maneira muito simples:
Você realmente não quer fazer nada com as mãos, mas é extremamente útil saber como está organizado dentro. Para que, no momento em que algo dê errado no banco de dados, você pelo menos entenda o que deu errado lá, como ele está organizado por dentro e aproximadamente como ele pode ser reparado.
Vejamos as opções:
- "Mãos" . Antes, dividimos os dados manualmente em 16 tabelas virtuais e reescrevemos todas as consultas com nossas mãos - isso é extremamente desconfortável. Se houver uma oportunidade de não embaralhar as mãos - não embaralhe as mãos! Mas às vezes isso não é possível, por exemplo, você possui o MySQL 3.23 e, em seguida, é necessário.
- "Automático". Acontece que você pode embaralhar automaticamente ou quase automaticamente, quando o banco de dados pode distribuir os dados em si, basta escrever aproximadamente em algum lugar uma configuração específica. Existem muitas bases e elas têm várias configurações diferentes. Estou certo de que em todo banco de dados em que é possível gravar shards = 16 (qualquer que seja a sintaxe), muitas outras configurações são coladas a esse caso pelo mecanismo.
- "Semi-automático" - um modo completamente cósmico, na minha opinião, e brutal. Ou seja, a própria base parece não conseguir, mas existem patches adicionais externos.
É difícil dizer algo sobre a máquina, exceto enviá-la para a documentação no banco de dados correspondente (MongoDB, Elastic, Cassandra, ... em geral, o chamado NoSQL). Se você tiver sorte, basta pressionar o botão "me faça 16 shards" e tudo funcionará. Nesse momento, quando não funciona, o restante do artigo pode ser necessário.
Sobre dispositivo semiautomático
Em alguns lugares, tecnologias sofisticadas de informação inspiram horror ctônico. Por exemplo, o MySQL pronto para uso não tinha implementação de sharding para determinadas versões, com certeza, no entanto, o tamanho das bases operadas em batalha cresce para valores indecentes.
O sofrimento da humanidade diante dos DBAs individuais tem sido atormentado por anos e cria várias soluções de fragmentação ruins criadas sem motivo. Depois disso, uma solução de sharding mais ou menos decente é escrita chamada ProxySQL (MariaDB / Spider, PG / pg_shard / Citus, ...). Este é um exemplo bem conhecido desse mesmo manto.
O ProxySQL como um todo, é claro, é uma solução completa de classe empresarial para código aberto, para roteamento e muito mais. Mas uma das tarefas a serem resolvidas é o sharding para um banco de dados, que por si só não sabe como fragmentar humanamente. Veja bem, não existe uma opção "shards = 16", você precisa reescrever cada solicitação no aplicativo e existem muitos locais ou colocar uma camada intermediária entre o aplicativo e o banco de dados com a seguinte aparência: "Hmm ... SELECT * FROM documentos? Sim, ele deve ser dividido em 16 pequenos SELECT * FROM server1.document1, SELECT * FROM server2.document2 - para este servidor com esse nome de usuário / senha, para este com outro. Se alguém não respondeu, então ... "etc.
Exatamente isso pode ser feito por patches intermediários. Eles são um pouco menores do que para todos os bancos de dados. Para o PostgreSQL, como eu o entendo, ao mesmo tempo, existem algumas soluções embutidas (PostgresForeign Data Wrappers, na minha opinião, está embutido no próprio PostgreSQL), existem patches externos.
A configuração de cada patch específico é um tópico gigante separado que não cabe em um relatório, portanto discutiremos apenas conceitos básicos.
Vamos falar um pouco mais sobre a teoria do zumbido.
Automação perfeita absoluta?
Toda a teoria do zumbido no caso do sharding nesta letra F (), o princípio básico é
sempre o mesmo bruto:
shard_id = F(object).Sharding é geralmente sobre o que? Temos 2 bilhões de registros (ou 64). Queremos dividi-los em vários pedaços. Surge uma pergunta inesperada - como? Por que princípio devo espalhar meus 2 bilhões de registros (ou 64) em 16 servidores disponíveis para mim?
O matemático latente em nós deve sugerir que, no final, sempre exista uma função mágica que, para cada documento (objeto, linha, etc.), determine em que peça colocá-lo.
Se aprofundarmos na matemática, essa função sempre depende não apenas do objeto em si (da própria linha), mas também de configurações externas, como o número total de fragmentos. A função, que para cada objeto deve dizer onde colocá-lo, não pode retornar um valor mais do que existem servidores no sistema. E as funções são um pouco diferentes:
- shard_func = F1 (objeto);
- shard_id = F2 (shard_func, ...);
- shard_id = F2 ( F1 (objeto), current_num_shards, ...).
Mas, além disso, não vamos nos aprofundar nessas selvas de funções individuais, apenas falamos sobre quais são as funções mágicas F ().
O que são F ()?
Eles podem apresentar muitos mecanismos de implementação diferentes e diferentes. Resumo da amostra:
- F = rand ()% nums_shards
- F = somehash (object.id)% num_shards
- F = object.date% num_shards
- F = object.user_id% num_shards
- ...
- F = shard_table [somehash () | ... object.date | ...]
Um fato interessante - você pode naturalmente espalhar todos os dados aleatoriamente - lançamos o próximo registro em um servidor arbitrário, em um núcleo arbitrário, em uma tabela arbitrária. Não haverá muita felicidade nisso, mas funcionará.
Existem métodos um pouco mais inteligentes de scamming para funções de hash reproduzíveis ou mesmo consistentes, ou scamming para algum atributo. Vamos passar por cada método.
F = rand ()
A dispersão não é um método muito correto. Um problema: dispersamos nossos 2 bilhões de registros por mil servidores aleatoriamente e não sabemos onde está o registro. Precisamos puxar user_1, mas não sabemos onde ele está. Vamos a milhares de servidores e resolvemos tudo - de alguma forma, é ineficiente.
F = somehash ()
Vamos espalhar os usuários de uma maneira adulta: leia a função de hash reproduzida em user_id, pegue o restante da divisão pelo número de servidores e acesse o servidor desejado imediatamente.
Por que estamos fazendo isso? E então, temos carga alta e não colocamos nada em um servidor. Se interferir, a vida seria tão simples.Bem, a situação já melhorou, para obter um registro, vamos a um servidor conhecido. Mas se tivermos um intervalo de chaves, em todo esse intervalo, precisamos classificar todos os valores de chave e, no limite, ir para o número de shards que tivermos chaves no intervalo ou para cada servidor em geral. A situação, é claro, melhorou, mas não para todos os pedidos. Alguns pedidos foram afetados.
Fragmento natural (F = object.date% num_shards)
Às vezes, ou seja, 95% do tráfego e 95% da carga são solicitações que possuem algum tipo de fragmentação natural. , 95% - 1 , 3 , 7 , 5% . 95% , , , .
, , , - .
— , . , , , , . 5 % .
, :
- , 95% .
- 95% , , . , . , .
, — , - .
, , , , . « - ».
«». , .
1. :
, , .
, / , , , PM ( , PM ), . .
, . , , 100 . .
, , , , - .
2. «» : , join
, ?
- «» … WHERE randcol BETWEEN aaa AND bbb?
- «» … users_32shards JOIN posts_1024 shards?
: , !
, , , . . (, , document store ), , .
—
- . . , . , , , . - , , , , — .
, .
3. / :
: , .
, .
, , , . , , , 10 , - 30, 100 . . — , - — , - .
, : 16 -, 32. , 17, 23 — . , , - ?
: , , .
, «», « ».
#1.
- NewF(object), .
- NewF()=OldF() .
- .
- Ai.
, 2 , , . : 17 , 6 , 2 , 17 23 . 10 , , . .
#2.
— — 17 23, 16 32 ! , .
- NewF(object), .
- 2^N, 2^(N+1) .
- NewF()=OldF() 0,5.
- 50% .
- , .
, , . , , .
, . , 16 16, — .
, — .
#3. Consistent hashing
, consistent hashing
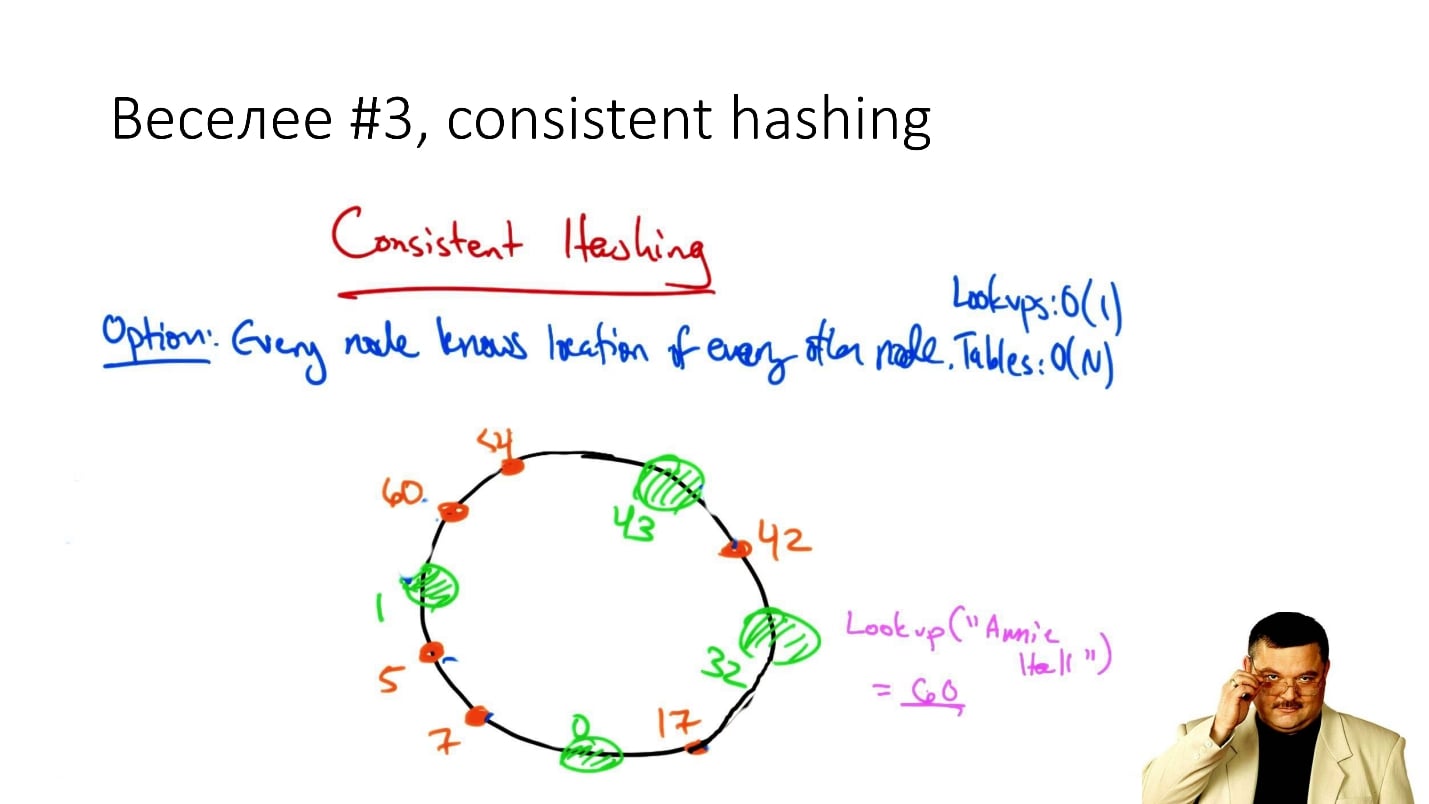
«consistent hashing», , .
: () , . , , , ( , ), .
, . , , , : , .
. , . , .., . , - , , .
, , , Cassandra . , , , , , .
, — / , , .
, : ? ? — , !
#4. Rendezvous/HRW
( , ):
shard_id = arg max hash(object_id, shard_id).Rendezvous hashing, , , Highest Random Weight. :
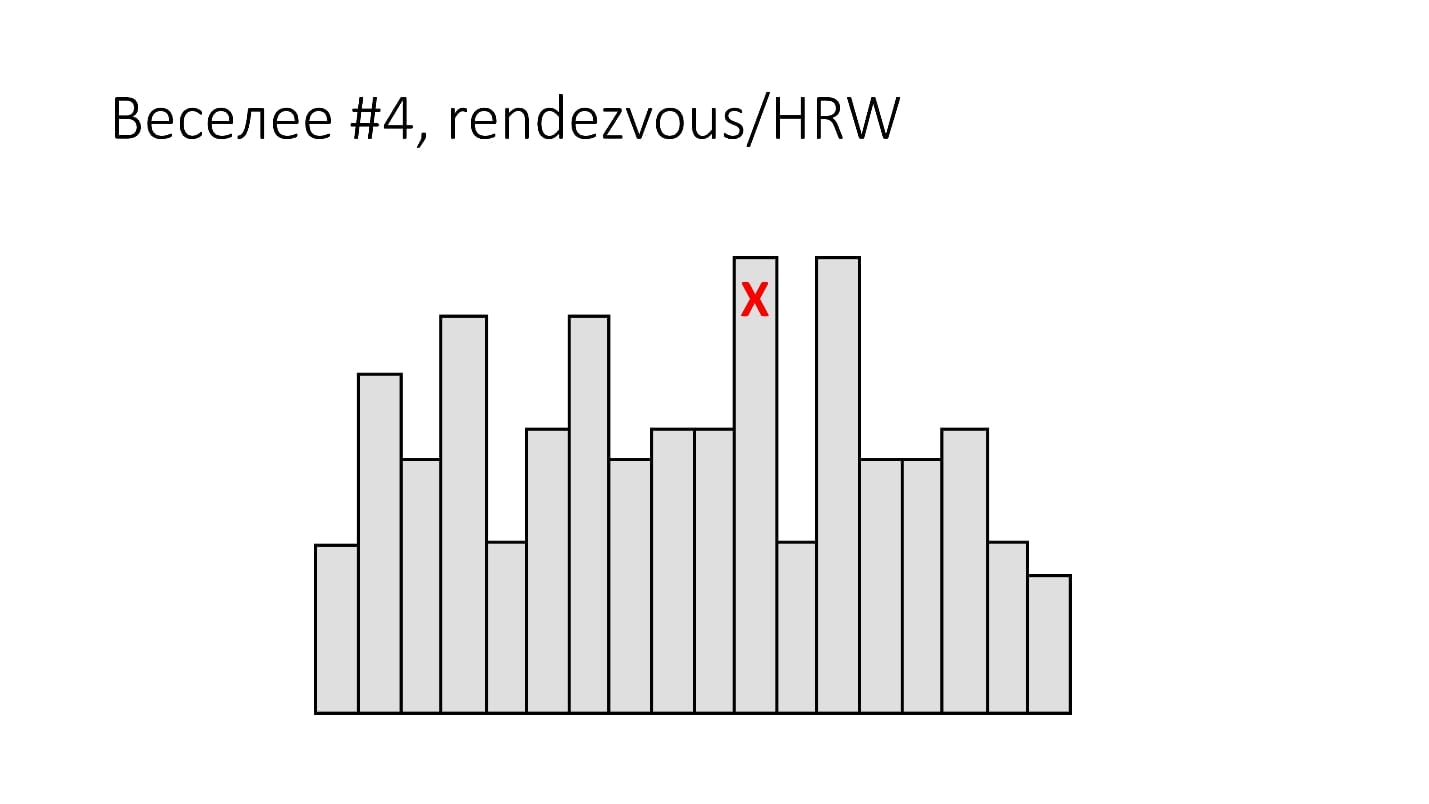
, , 16 . (), - , 16 , . -, .
HRW-hashing, Rendezvous hashing. , -, , .
, . , - - . .
, .
#5.
, Google - :
- Jump Hash — Google '2014.
- Multi Probe —Google '2015.
- Maglev — Google '2016.
, . , , , -, . .
#6.
— . ? , 2 , object_id 2 , .
, ? ?
. , - , , . , , , , .
:
- 1 .
- / / / : min/max_id => shard_id.
- 8 4 (4 !) — 20 .
- - , 20 — .
- 20 — .
2 - 16 — 100 - . : , , — 1 . , , .
, , , - , .
Conclusões
: « , !». , 20 .
, , . ,
— . 100$ , . -, . — .
, , «» (, DFS, ...) . , , highload - . , , - . —
, .
F() , , , .. , , 2
.
, , .
HighLoad++ , , —Sphinx—highload , .
Highload User Group. , .
, ,
HighLoad++ . , , . , , .
highload-, .
, , , . , , , .
24 - «», « ». , . ,
.
, , 8 9 - HighLoad++ early bird .