Instituto de Tecnologia de Massachusetts. Curso de Aula nº 6.858. "Segurança de sistemas de computador". Nikolai Zeldovich, James Mickens. 2014 ano
Computer Systems Security é um curso sobre o desenvolvimento e implementação de sistemas de computador seguros. As palestras abrangem modelos de ameaças, ataques que comprometem a segurança e técnicas de segurança baseadas em trabalhos científicos recentes. Os tópicos incluem segurança do sistema operacional (SO), recursos, gerenciamento de fluxo de informações, segurança de idiomas, protocolos de rede, segurança de hardware e segurança de aplicativos da web.
Palestra 1: “Introdução: modelos de ameaças”
Parte 1 /
Parte 2 /
Parte 3Palestra 2: “Controle de ataques de hackers”
Parte 1 /
Parte 2 /
Parte 3Aula 3: “Estouros de Buffer: Explorações e Proteção”
Parte 1 /
Parte 2 /
Parte 3Palestra 4: “Separação de Privilégios”
Parte 1 /
Parte 2 /
Parte 3Palestra 5: “De onde vêm os sistemas de segurança?”
Parte 1 /
Parte 2Palestra 6: “Oportunidades”
Parte 1 /
Parte 2 /
Parte 3Palestra 7: “Sandbox do Cliente Nativo”
Parte 1 /
Parte 2 /
Parte 3Aula 8: “Modelo de Segurança de Rede”
Parte 1 /
Parte 2 /
Parte 3Aula 9: “Segurança de aplicativos da Web”
Parte 1 /
Parte 2 /
Parte 3Palestra 10: “Execução Simbólica”
Parte 1 /
Parte 2 /
Parte 3Aula 11: “Linguagem de Programação Ur / Web”
Parte 1 /
Parte 2 /
Parte 3Aula 12: Segurança de rede
Parte 1 /
Parte 2 /
Parte 3Aula 13: “Protocolos de Rede”
Parte 1 /
Parte 2 /
Parte 3Palestra 14: “SSL e HTTPS”
Parte 1 /
Parte 2 /
Parte 3Palestra 15: “Software Médico”
Parte 1 /
Parte 2 /
Parte 3Palestra 16: “Ataques de Canal Lateral”
Parte 1 /
Parte 2 /
Parte 3Palestra 17: “Autenticação de Usuário”
Parte 1 /
Parte 2 /
Parte 3Palestra 18: “Navegação Privada na Internet”
Parte 1 /
Parte 2 /
Parte 3Palestra 19: “Redes Anônimas”
Parte 1 /
Parte 2 /
Parte 3Palestra 20: “Segurança do telefone móvel”
Parte 1 /
Parte 2 /
Parte 3Palestra 21: “Rastreando Dados”
Parte 1 /
Parte 2 /
Parte 3 Aluno: Então, o suporte à arquitetura é a solução ideal?
Professor: sim, existem métodos para isso também. No entanto, isso é um pouco complicado, porque, como você pode ver, destacamos o estado de contaminação ao lado da própria variável. Portanto, se você pensar no suporte fornecido pelo próprio equipamento, pode ser muito difícil alterar o layout do hardware, porque aqui tudo é feito de silício. Mas se for possível em alto nível na máquina virtual Dalvic, pode-se imaginar que será possível colocar variáveis e sua infecção lado a lado no nível do hardware. Portanto, se você alterar o layout em silicone, provavelmente poderá fazer o trabalho.
 Aluno:
Aluno: o que o TaintDroid faz com informações baseadas em permissões de ramificação git, permissões de ramificação?
Professor: voltaremos a isso em um segundo, então, mantenha-se nesse pensamento até chegarmos a ele.
Aluno: Gostaria de saber se podem ocorrer estouros de buffer aqui, porque essas coisas - variáveis e suas infecções - se acumulam?
Professor: Essa é uma boa pergunta. Seria de esperar que, em uma linguagem como Java, não houvesse excesso de buffer. Mas no caso da linguagem C, algo catastrófico pode acontecer, porque se você de alguma forma exceder o buffer e reescrever as tags de contaminação das variáveis, seus valores zero serão definidos nas pilhas e os dados fluirão livremente para a rede.
Aluno: Eu acho que tudo isso pode ser previsto?
Professor: absolutamente verdade. A questão dos estouros de buffer pode ser resolvida com a ajuda de "canários" - indicadores da pilha, porque se você tiver esses dados na pilha, não desejará que eles não sejam substituídos ou que os valores já substituídos sejam quebrados de alguma forma. Portanto, você está absolutamente certo - você pode simplesmente evitar estouros de buffer.
Em resumo, o rastreamento de manchas pode ser fornecido nesse nível baixo de x86 / ARM, embora possa ser um pouco caro e um pouco difícil de implementar da maneira certa. Você pode perguntar por que estamos resolvendo antes de tudo a questão do rastreamento de infecções, em vez de monitorar como o programa tenta enviar algo pela rede, simplesmente verificando dados que nos parecem confidenciais. Isso parece bastante fácil, porque não precisamos monitorar dinamicamente tudo o que o programa faz.

O problema é que isso funcionará apenas no nível heurístico. De fato, se um invasor sabe que você está fazendo exatamente isso, ele pode facilmente quebrar você. Se você apenas ficar sentado e tentar cumprimentar os números de segurança social, um invasor poderá usar a codificação da base 64 ou fazer outra coisa estúpida, como a compactação. Ignorar esse tipo de filtro é bastante trivial; portanto, na prática, isso é completamente insuficiente para garantir a segurança.
Agora, voltemos à sua pergunta sobre como podemos rastrear os fluxos que fluem pelas filiais do ramo. Isso nos levará a um tópico chamado fluxos implícitos ou fluxos implícitos. Um fluxo implícito geralmente ocorre quando você tem um valor infectado que afetará como você atribui outra variável, mesmo que essa variável implícita de fluxo não atribua variáveis diretamente. Vou dar um exemplo concreto.
Suponha que você tenha uma declaração if que analise seu IMEI e diga: "se for maior que 42, atribuirei x = 0, caso contrário atribuirei x = 1".
É interessante observar primeiro os dados confidenciais do IMEI e compará-los com um certo número, mas, ao atribuir x, não atribuímos nada que seria obtido diretamente desses dados confidenciais.
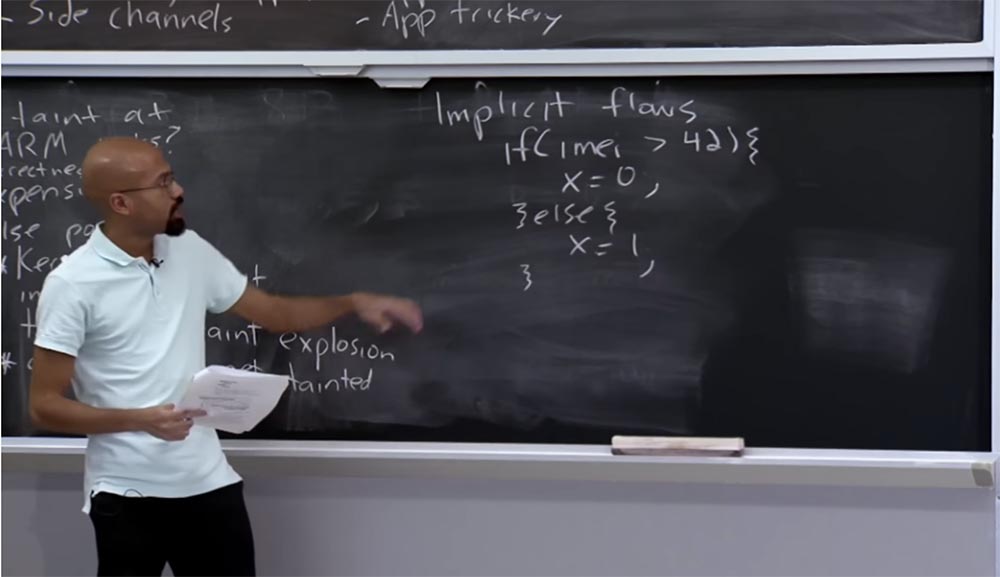
Este é um exemplo de um dos segmentos implícitos. O valor de x realmente depende da comparação acima, mas o adversário, se ele for inteligente, pode criar seu código de tal maneira que nenhuma conexão direta possa ser rastreada nele.
Observe que mesmo aqui, em vez de apenas atribuir x = 0, x = 1, você pode simplesmente colocar o comando para enviar algo pela rede, ou seja, você pode dizer pela rede que x = 0 ou x = 1, ou algo assim. Este é um exemplo de um desses threads implícitos que um sistema como o TaintDroid não pode controlar. Portanto, isso é chamado de fluxo implícito, em oposição a um fluxo explícito, por exemplo, um operador de atribuição. Portanto, os desenvolvedores estão cientes desse problema.
Se eu entendi corretamente, eles me perguntaram o que aconteceria se tivéssemos algum tipo de função da máquina que faça algo semelhante ao exemplo acima e, portanto, o sistema TaintDroid não precise saber disso, porque o TaintDroid não poderá analisar esse código da máquina e ver as coisas esse tipo. A propósito, os desenvolvedores afirmam que controlarão isso usando métodos orientados à máquina, determinados pela própria máquina virtual, e considerarão a maneira como esse método é implementado. Por exemplo, pegamos esses dois números e retornamos seu valor médio. Nesse caso, o sistema TaintDroid confiará na função da máquina, portanto, precisamos descobrir qual deve ser a política apropriada de infecção por contaminação.
No entanto, você está certo de que, se algo assim estava oculto no código da máquina e, por algum motivo, não foi submetido a uma revisão aberta, as políticas manuais inventadas pelos autores do TaintDroid podem não capturar esse fluxo implícito. De fato, isso pode permitir que as informações vazem de alguma forma. Além disso, pode até haver um fluxo direto, que os autores do TaintDroid não notaram, e podemos ter um vazamento ainda mais direto.
 Aluno:
Aluno: isto é, na prática, parece muito perigoso, certo? Como você pode literalmente apagar todos os valores infectados, basta olhar para as últimas 3 linhas.
Professor: Tivemos várias aulas que examinaram como os fluxos implícitos fazem essas coisas. Existem várias maneiras de corrigir isso. Uma maneira de impedir que isso aconteça é atribuir uma marca de contaminação ao PC, infectando-a essencialmente com o teste de ramificação. A ideia é que, do ponto de vista humano, possamos considerar esse código e dizer que esse fluxo implícito existe aqui, porque, para chegar aqui, tivemos que cavar dados confidenciais.
Então, o que isso significa no nível de implementação? Isso significa que, para chegar aqui, o PC deve ter algo que foi infectado com dados confidenciais. Ou seja, podemos dizer que recebemos esses dados porque o PC foi instalado aqui - x = 0 - ou aqui - x = 1.
Em geral, pode-se imaginar que o sistema realizará alguma análise e descobrirá que o PC não está infectado por fluxos implícitos nesse local, depois pega a infecção pelo IMEI e, nesse ponto, em que x = 0, o PC já está infectado. No final, o que acontece é que, se x é uma variável que é exibida inicialmente sem mácula, dizemos: “OK, neste ponto x = 0, obtemos a infecção do PC que foi realmente infectado acima no IMEI”. Existem algumas sutilezas aqui, mas, em geral, você pode rastrear como o PC está instalado e depois tentar espalhar a infecção para os operadores de destino.
Isso está claro? Se você quiser saber mais, podemos falar sobre esse tópico, porque eu fiz muitas pesquisas desse tipo. No entanto, o sistema que acabei de descrever pode ser conservador demais. Imagine que, em vez de x = 1, aqui, como acima, também temos x = 0. Nesse caso, não faz sentido infectar x com algo relacionado ao IMEI; portanto, nenhuma informação pode vazar dessas ramificações.
Mas se você usar um esquema de infecção por PC computadorizado, poderá superestimar quantas x variáveis foram corrompidas. Existem algumas sutilezas que você pode fazer para tentar solucionar alguns desses problemas, mas será um pouco difícil.
Aluno: ao sair da instrução if, você também sai do Branch e se livra da infecção?
Professor: como regra, sim, assim que o conjunto de variáveis terminar, o PC será limpo de infecções. A infecção é estabelecida apenas dentro desses ramos de x para x. O motivo é que, quando você desce aqui, faz o que quer que seja o IMEI.
Falamos sobre como o rastreamento de infecções nesse nível muito baixo é útil, embora muito caro, porque realmente permite que você veja qual é a vida útil dos seus dados. Algumas palestras atrás, falamos sobre o fato de que muitas vezes os principais dados permanecem na memória por muito mais tempo do que você pensa.
Você pode imaginar que, embora o rastreamento de infecções por x86 ou ARM seja bastante caro, você pode usá-lo para auditar seu sistema. Por exemplo, você pode infectar uma chave secreta inserida por um usuário e ver onde e como ela se move pelo sistema. Esta é uma análise off-line, não afeta os usuários, por isso é normal que seja lenta. Essa análise ajudará a descobrir, por exemplo, que esses dados caem no buffer do teclado, em um servidor externo, em outro lugar. Portanto, mesmo que seja um processo lento, ainda pode ser muito útil.
Como eu disse, um recurso útil do TaintDroid é que ele limita o "universo" de fontes de infecção e absorvedores de informações infectadas. Mas como desenvolvedor, você provavelmente deseja ter um controle mais preciso sobre as marcas de infecção com as quais seu programa interage. Portanto, como programador, você desejará fazer o seguinte.
Portanto, você declara algum int desse tipo e o chama X e depois vincula um rótulo a ele. O significado deste rótulo é que Alice é a proprietária das informações que ela permite que Bob visualize, ou que essas informações estão marcadas para visualização por Bob. O TaintDroid não permite que você faça isso, porque essencialmente controla esse universo de rótulos, mas como programador, você pode querer fazer isso.
Suponha que seu programa tenha canais de entrada e saída, e eles também são rotulados. Esses são os rótulos que você escolheu como programador, diferentemente do próprio sistema, tentando dizer que essas coisas são pré-determinadas previamente. Diga para os canais de entrada que você define valores de leitura que recebem o rótulo do canal.
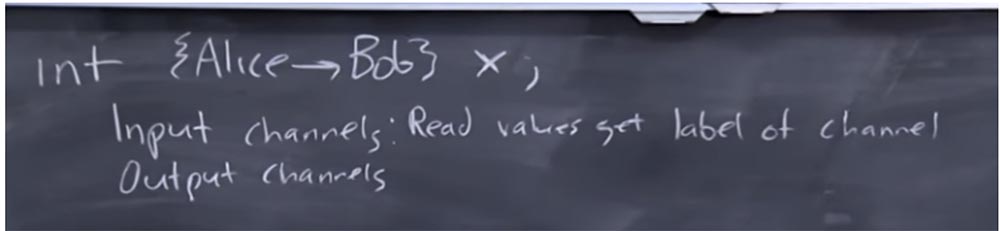
Isso é muito parecido com o funcionamento do TaintDroid - se os valores do sensor GPS são lidos, eles são marcados com a marca de contaminação do canal GPS, mas agora, como programador, você mesmo seleciona esses rótulos. Nesse caso, o rótulo do canal de saída deve corresponder ao valor do rótulo que gravamos.

Outras políticas podem ser introduzidas aqui, mas a idéia principal é que existem gerentes de programa que permitem ao desenvolvedor escolher que tipo de rótulo e qual pode ser sua semântica. Isso exigirá muito trabalho do programador, cujo resultado será a capacidade de realizar uma verificação estática. Por estática, quero dizer uma verificação que é executada em tempo de compilação e pode "capturar" muitos tipos de erros de fluxo de informações.
Portanto, se você rotular cuidadosamente todos os canais de rede e de tela com rótulos com as permissões apropriadas e, em seguida, colocar cuidadosamente seus dados, que são dados como exemplo no quadro, durante a compilação, o compilador poderá dizer: "ei, se você executar este programa, poderá ocorrer um vazamento de informações, porque parte dos dados passará por um canal não confiável. "
Em um nível alto, uma verificação estática pode detectar muitos desses erros, porque esses comentários int {Alice Bob} x são um pouco parecidos com os tipos. Assim como os compiladores podem detectar erros relacionados a tipos em uma linguagem de tipos, eles também podem funcionar com o código escrito na linguagem acima, dizendo que, se você executar este programa, pode ser um problema. Portanto, você precisa corrigir o funcionamento dos rótulos, desclassificar algo e assim por diante.
Portanto, dependendo do idioma, esses rótulos podem ser associados a pessoas, portas de E / S e similares. O TaintDroid oferece a você a oportunidade de se familiarizar com os princípios de operação dos fluxos e vazamentos de informações, no entanto, existem sistemas mais complexos com semântica mais pronunciada para gerenciar esses processos.
Lembre-se de que, quando falamos de verificação estática, é preferível detectar o maior número possível de falhas e erros com a ajuda da verificação estatística, em vez da verificação dinâmica. Há uma razão muito delicada para isso. Suponha que adiamos todas as verificações estáticas durante o período de um programa, o que definitivamente podemos fazer.
O problema é que a falha ou o êxito dessas verificações é um canal implícito. Assim, um invasor pode fornecer algumas informações ao programa e verificar se isso causou uma falha no programa. Se ocorrer uma falha, o hacker pode dizer: "Sim, passamos por uma verificação dinâmica do fluxo de informações, então há algum segredo aqui em relação aos valores que afetam o processo de cálculo". Portanto, você desejará tentar tornar essas verificações o mais estáticas possível.
Se você quiser obter mais informações sobre essas coisas, consulte o Jif. Este é um sistema muito poderoso que criou etiquetas de métodos de cálculo de etiquetas. Você pode começar com ele e seguir mais nessa direção. Meu colega, professor Zeldovich, fez muito bem nessa área, para que você possa conversar com ele sobre esse tópico.
Curiosamente, o TaintDroid é muito limitado em sua capacidade de visualizar e descrever tags. Existem sistemas que permitem fazer coisas mais poderosas.
Por fim, gostaria de falar sobre o que podemos fazer se quisermos rastrear fluxos de informações usando programas tradicionais ou programas escritos em C ou C ++ que não suportam todas essas coisas no processo de execução de código. Existe um sistema TightLip bastante razoável, e alguns dos autores do mesmo artigo estão pensando em como rastrear vazamentos de informações em um sistema no qual não queremos alterar nada no próprio aplicativo.
A idéia básica é que o conceito de processos doppelganger, ou "equivalentes de processos", seja usado aqui. O TightLip usa um processo duplo por padrão. A primeira coisa que ela faz é verificar periodicamente o sistema de arquivos do usuário, procurando tipos de arquivos confidenciais. Pode ser algo como arquivos de email, documentos de texto e assim por diante. Para cada um desses arquivos, o sistema cria sua versão "limpa". Ou seja, no arquivo de mensagens de email, ele substitui as informações "para" ou "de" por uma sequência do mesmo comprimento que contém dados fictícios, por exemplo, espaços. Isso é executado como um processo em segundo plano.
A segunda coisa que o TightLip faz quando um processo é iniciado é determinar se o processo está tentando acessar um arquivo confidencial. Se esse acesso ocorrer, o TightLip cria um dobro desse processo. Essa dupla se parece exatamente com o processo original, que tenta afetar dados confidenciais, mas a diferença fundamental é que a dupla, eu o designarei DG, lê os dados limpos.

Imagine que você está tentando acessar seu arquivo de email. O sistema gera esse novo processo, doppelganger, exatamente o mesmo que o original, mas agora ele lê os dados limpos em vez de dados reais reais. Essencialmente, o TightLip executa esses dois processos em paralelo e os observa para ver o que estão fazendo. , , , . , , - , , – , , , -, .

, , TightLip , . , . , , , , . , TaintDroid, , : «, , , , - ».
, , , - . TaintDroid, , - , . — , — . , , , , , .
: , - Word, , - .
: , . , . . Word. - , - , . .
: , , ? - .
: , . , , , - , . , . «» , , , .
, , , , , , , .

– , TightLip TCB, , -, . , . . , , . TightLip.
, . taint .
: , ? , ?
: ! - DG , , . , , , -, , .
, .
.
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps ,
.
Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?