
Nós nos esforçamos para garantir que, depois de pedir um táxi para o usuário, um carro limpo e com manutenção dessa marca, cor e número que é exibido no aplicativo chegue ao usuário. E para isso usamos o controle remoto de qualidade (DCC).
Hoje vou contar aos leitores da Habr sobre como usar o aprendizado de máquina para reduzir o custo do controle de qualidade em um serviço que cresce rapidamente com centenas de milhares de máquinas e não colocar em linha uma máquina que não está em conformidade com as regras do serviço.
Como o DCC foi organizado antes do aprendizado de máquina
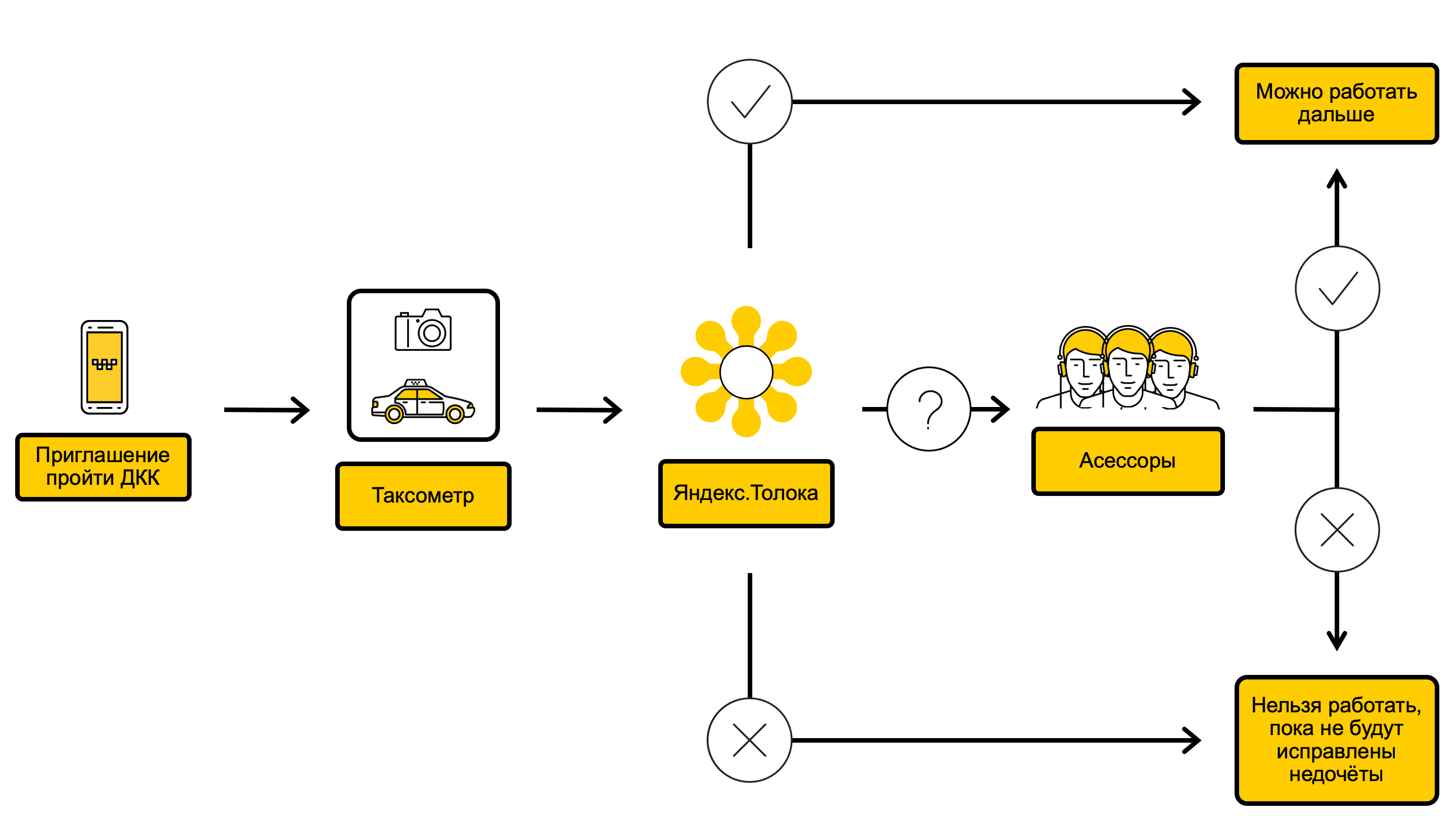
Diagrama do processo DCC
No processo DCC, verificamos as fotos do carro e tomamos uma decisão sobre se é possível atender aos pedidos desse carro ou, por exemplo, que ele deve ser lavado antes. Tudo começa com o fato de que, através do aplicativo Taximeter, chamamos o driver no DCC. Isso geralmente acontece uma vez a cada 10 dias, mas às vezes com menos frequência ou mais - dependendo do êxito do driver nas verificações anteriores. Imediatamente após uma chamada para o DCC, o motorista recebe uma mensagem convidando-os a passar por um controle de foto. Assim que o motorista aceitou o convite, no mesmo aplicativo, ele fotografa o exterior e o interior do carro de diferentes ângulos e envia fotos para o Yandex.Taxi. O motorista pode receber pedidos enquanto o DCC está ligado.

Tela inicial do DCC no aplicativo Taximeter

Tela para fotografar um carro no aplicativo Taximeter
As fotos resultantes são do Yandex.Toloka - um serviço no qual, usando o crowdsourcing, você pode executar rapidamente tarefas simples, mas grandes em volume. Sobre como ele funciona e por que o Yandex.Tolok é necessário, escrevemos em nosso blog .
No Yandex.Tolok, no decorrer de uma verificação, pelo menos três artistas respondem a perguntas sobre a condição do carro e, se os artistas concordam com base em suas respostas, é tomada uma decisão sobre se o motorista pode aceitar pedidos. As verificações no Yandex.Tolok têm dois resultados:
- Se tudo estiver bem visualmente com o carro, o motorista continuará a receber pedidos.
- Se o carro estiver sujo, danificado ou sua marca, cor ou número não corresponder aos indicados no cartão do motorista, o Yandex.Taxi limita temporariamente a capacidade do motorista de aceitar pedidos.
Se os artistas não chegarem a um consenso, as fotos são enviadas aos funcionários da Yandex.Taxi - avaliadores que verificam o carro mais detalhadamente e depois tomam a decisão final. Os avaliadores passam por um programa de treinamento especial e têm mais experiência.

Então, vê o executor do DCC Yandex.Tolki
Desafio
Com o crescimento do Yandex.Taxi, o número de inspeções de DCC também está aumentando, o que significa que os custos para profissionais e avaliadores estão aumentando. Além disso, a velocidade de verificação do carro diminui. Enquanto o DCC estiver em andamento, você pode permitir que os motoristas aceitem pedidos ou não. Ambas as opções têm suas desvantagens: no primeiro caso, um motorista inescrupuloso terá tempo para aceitar vários pedidos de um carro que não atenda aos padrões, no segundo - todos os motoristas chamados para controle de foto não poderão trabalhar até que a verificação seja concluída. Portanto, é importante verificar os carros rapidamente, para que usuários e motoristas não encontrem qualquer inconveniente.
Observando como os gráficos de custos e o tempo médio de verificação estão aumentando, percebemos que queremos reduzir o custo do Toloka, descarregar avaliadores e reduzir o tempo médio de verificação, em outras palavras, para automatizar parte das verificações. Naturalmente, não queríamos sacrificar a qualidade do serviço e perder mais carros que não atendiam aos padrões de qualidade da linha, e também não queríamos limitar a aceitação de pedidos por motoristas de boa-fé. Precisávamos automatizar o DCC e, ao mesmo tempo, não aumentar a parcela de erros no fluxo geral de verificações.
Como implementamos o aprendizado de máquina na DCC
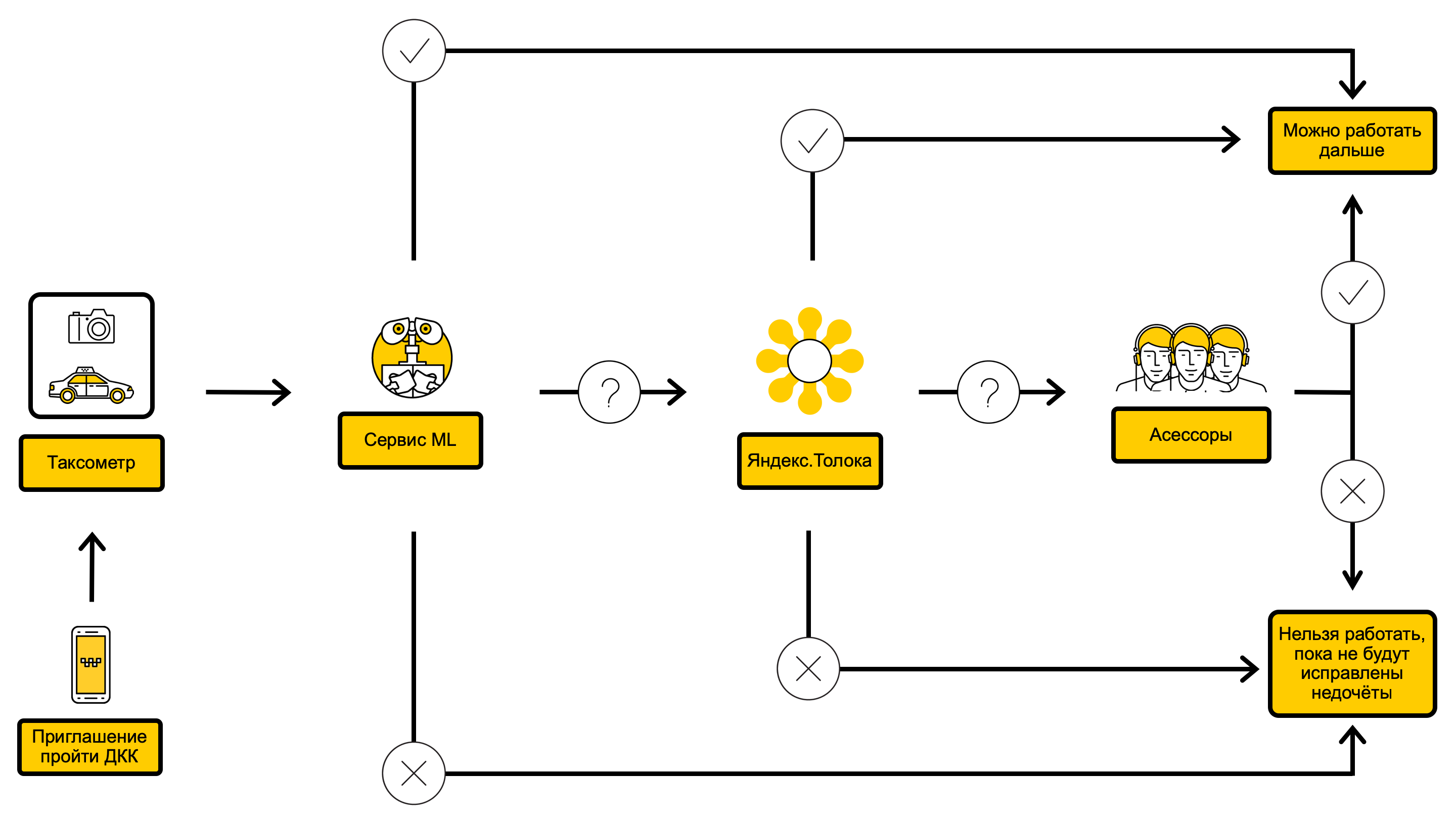
Diagrama de processo DCC com ML dentro
Para começar, decidimos pela declaração do problema: automatizar o maior número possível de verificações, sem aumentar a taxa de erro no fluxo geral.
Vamos descobrir quais erros estão em nossa tarefa. Eles vêm em duas formas: falso positivo e falso negativo . Em nossa terminologia, negativo é o resultado de uma verificação com a qual o motorista pode continuar trabalhando, e positivo é o resultado que implica um limite de tempo no recebimento de pedidos. Então, falso negativo é um caso em que fomos forçados a permitir que um motorista com carro ruim aceite ordens e falso positivo - pelo contrário, quando não permitimos que um motorista trabalhasse com um carro que estivesse bem. Acontece que a Taxa de Falso Negativo (FNR) é a parcela de motoristas com carros "ruins" que nos foi permitido aceitar pedidos, e a Taxa de Falso Positivo (FPR) é a porcentagem de motoristas com os quais não nos foi permitido trabalhar, embora eles estejam bem com carros. Assim, desde a introdução do aprendizado de máquina no sistema, queríamos o seguinte: automatizar o máximo de verificações possível, sem aumentar o FPR e o FNR em comparação com um sistema sem aprendizado de máquina.
Além disso, era necessário entender quais métricas deveriam ser guiadas ao escolher modelos e limites para a tomada de decisões com base em suas previsões. Fica claro pelas condições do problema que estamos interessados em três quantidades:
- A fração do segmento que os modelos de aprendizado de máquina podem responder automaticamente.
- Sistemas FNR.
- Sistemas FPR.
Maximizamos o primeiro valor enquanto observamos as restrições no segundo e no terceiro.
Isso pode levantar a questão: por que não maximizar a economia de dinheiro ou minimizar o tempo médio de digitalização diretamente, e não através do compartilhamento de verificações automatizadas? Otimizar dinheiro é uma ideia muito atraente, mas geralmente difícil de implementar. No nosso caso, a economia consiste em dois fatores: o primeiro é a economia de cada verificação automatizada, porque cada verificação nos avaliadores ou no Yandex.Tolok custa dinheiro; o segundo - economizando na redução do número de erros, porque cada erro custa dinheiro Yandex.Taxi. O cálculo objetivo de quanto nos custa os erros é uma tarefa muito difícil, portanto, estamos limitados a calcular a economia apenas pelo primeiro fator. Esse valor aumenta monotonicamente na proporção de verificações automatizadas, para que essa fração possa ser maximizada em vez de salvar. O mesmo raciocínio se aplica ao tempo médio do DCC; ele também diminui monotonamente de acordo com a parcela de verificações automatizadas.
Seleção de modelo
Podemos dizer que a verificação do DCC é reduzida à escolha de opções de resposta para várias perguntas sobre o estado do carro em suas fotografias, e isso parece uma tarefa de classificação de imagens. Tais tarefas são resolvidas pela visão computacional e, em nosso tempo - uma ferramenta específica, redes neurais convolucionais. Decidimos usá-los para automação DCC.
A primeira solução ou abordagem "de uma só vez"
Agora que entendemos o que otimizar e por que, é hora de coletar dados e treinar modelos sobre eles. Foi fácil coletar dados, porque todas as verificações do DCC são registradas e armazenadas em um formulário conveniente. Na primeira versão da solução, as fotos do exterior e do interior do carro de quatro ângulos, a marca, modelo e cor do carro, bem como os resultados de 10 inspeções anteriores do DCC, foram usados como sinais. Como variáveis-alvo, pegamos as respostas para todas as perguntas de verificação, por exemplo: "O carro está danificado?" ou "A cor do carro corresponde à do cartão do motorista?" A principal variável alvo foi a resposta à pergunta principal: "É necessário limitar a capacidade do motorista de receber pedidos?" Ensinamos um modelo grande, muito semelhante ao VGG com atenção do SENet, para responder a todas as perguntas ao mesmo tempo e, como resultado, encontramos vários problemas.

Abordagem tudo-em-um
Problemas da abordagem "tudo de uma vez":
- Não foi possível responder à pergunta sobre a correspondência do número do carro na foto indicada no cartão do motorista. Uma grande rede para classificar imagens não conseguiu lidar com essa tarefa; para isso, precisamos de um modelo especial de reconhecimento óptico de caracteres (OCR), afiado para reconhecer placas de carros.
- A variável alvo estava incompleta e barulhenta. Encontrando uma falha séria na aparência do carro, que foi suficiente para tomar uma decisão, os avaliadores frequentemente se esqueciam de responder a outras perguntas. Portanto, se o carro na foto estava sujo e quebrado, com alta probabilidade, observamos apenas uma das marcas: “carro sujo” ou “carro com danos”, enquanto os dois modelos eram necessários para o nosso modelo.
- Não houve interpretabilidade da solução do modelo. O modelo pode responder à pergunta principal de verificação com uma precisão maior que aleatória, mas essa resposta está fraca correlacionada com as respostas para outras perguntas. Em outras palavras, se a resposta fosse: “É necessário limitar a capacidade de receber pedidos”, quase nunca vimos o motivo dessa decisão nas respostas restantes do modelo. Em geral, a precisão das respostas a todas as perguntas, exceto a principal, foi quase aleatória. Não foi possível explicar ao motorista o que exatamente precisava ser consertado para receber pedidos novamente, o que significa que não poderíamos limitar a capacidade do motorista de receber pedidos.
- O número de erros falsos negativos na resposta à pergunta: "É necessário limitar a capacidade do motorista de receber pedidos?" - era muito grande para iniciar a aprovação automática de verificações. Não foi possível fornecer o mesmo FNR que em um sistema executado sem aprendizado de máquina, e esse era um dos requisitos de nossa tarefa.
Juntas, essas quatro razões não nos permitiram colocar em prática a primeira solução, mas não desanimamos e criamos a segunda.
A segunda solução, ou a abordagem "quase gradual"
Decidimos nos concentrar em verificar o exterior do carro, porque eles representam cerca de 70% do fluxo total. Além disso, decidimos dividir a tarefa geral em subtarefas e aprender a responder todas as perguntas do DCC separadamente.

Abordagem "tudo, mas gradualmente"
Era uma vez, nosso serviço já estava envolvido na automação do DCC e conseguiu introduzir um modelo que permite filtrar fotos escuras e irrelevantes. Continuamos a usar esse modelo ainda mais para responder à pergunta: “As seguintes fotos reais do carro estão presentes: frente, lado esquerdo, lado direito, atrás?”.
Nosso trabalho na segunda solução começou com o uso do Yandex. Pesquise o modelo de serviço de visão por computador (das pessoas que criaram o DeepHD ) para reconhecer placas de carros. Assim, pudemos responder à pergunta: "O número e o código da região do carro correspondem totalmente aos indicados no cartão do motorista?" Se falarmos sobre isso com mais detalhes, comparamos o resultado do reconhecimento com o número indicado no cartão do motorista e, dependendo da distância de Levenshtein entre eles, escolhemos uma das opções de resposta: "o número corresponde", "o número não corresponde" ou "a pergunta não pode ser respondida exatamente".
Em seguida, treinamos classificadores de carros para reconhecer marcas e modelos, além de cores. A partir desse momento, poderíamos responder à pergunta: "A marca, modelo e cor do carro indicado no cartão de motorista?"
Em conclusão, treinamos classificadores para encontrar carros danificados e sujos, o que nos permitiu encerrar as perguntas: “Há algum dano ou defeito na carroceria do carro?” e "Quão suja é a carroceria do carro?"
A abordagem "quase gradual" nos permitiu resolver o problema de verificar o número da placa. Também fomos capazes de nos livrar da incompletude e do ruído da variável de destino, porque agora tínhamos uma seleção em que objetos de classe negativos eram verificações totalmente bem-sucedidas e objetos de classe positiva verificados onde o avaliador ou todos os três executores Yandex. . Depois de resolver os dois primeiros problemas, nossos modelos se tornaram interpretáveis e pudemos explicar ao motorista o motivo da limitação, para que, no próximo teste, ele corrigisse as falhas. A qualidade geral das respostas às perguntas também aumentou significativamente, e o FPR e o FNR para algumas combinações de limites de confiança do modelo caíram para o nível Yandex.Tolki, que permitiu a introdução dos modelos na produção.
Implementação na produção
Tivemos uma escolha: iniciar um processo regular que aplicaria os modelos às verificações acumuladas na fila ou criar um serviço separado, onde você pode acessar a API e receber respostas do modelo em tempo real. Como é importante encontrar rapidamente carros "ruins", escolhemos a segunda opção. Assim que a parte principal do serviço foi escrita e foi capaz de suportar a funcionalidade necessária, começamos a adicionar modelos a ele.
Para aprovar completamente a verificação, você deve poder responder a todas as perguntas da instrução, mas, para limitar o acesso inescrupuloso de drivers ao serviço, em alguns casos é suficiente poder responder a pelo menos uma pergunta. Portanto, decidimos não esperar até que todos os modelos estejam prontos, mas adicioná-los assim que estiverem disponíveis. Um pipeline generalizado de adição de um modelo se parece com isso:
- Colete a amostra.
- Treine o modelo.
- Avalie a qualidade e escolha limites offline.
- Adicione um modelo ao serviço em segundo plano e meça a qualidade online.
- Inclua o modelo na produção e comece a tomar decisões com base em suas previsões.
Essa abordagem nos permitiu não apenas encontrar instantaneamente cada vez mais carros "ruins" à medida que novos modelos foram introduzidos, mas também medir a qualidade on-line sem custos adicionais de tempo enquanto os modelos estavam trabalhando em segundo plano.
No final, chegou o momento em que adicionamos ao serviço e testamos o modelo mais recente. Agora, poderíamos responder a todas as perguntas das inspeções, o que significa que elas serão automaticamente aprovadas. Como há muito mais carros “bons” em Yandex.Taxi do que carros “ruins”, a aprovação automática de inspeções levou a um forte aumento em nossa principal métrica - parte do fluxo de inspeções automatizadas. Só pudemos escolher os limites certos que maximizariam o compartilhamento de verificações automatizadas, mantendo o FPR e o FNR geral de todo o sistema no mesmo nível. Para selecionar os limites, usamos uma amostra que foi marcada de forma independente pelos executores, avaliadores e funcionários do Yandex.Tolki e um funcionário do Yandex.Taxi que treinou assessores para verificar carros. Usamos sua marcação como os valores verdadeiros da variável de destino.
Resultados
Assim que incluímos modelos na produção, era necessário medir a qualidade on-line das decisões tomadas com base em suas respostas. E aqui estão os números que vimos:
- Agora, 30% das verificações externas de veículos receberam uma resposta automática.
- O FNR permaneceu no mesmo nível, enquanto o FPR caiu, e começamos a restringir com menos frequência o acesso ao serviço àqueles que não o mereciam.
- A carga nos avaliadores diminuiu 14% e eles foram capazes de dedicar mais tempo a testes complexos que o serviço de aprendizado de máquina não podia suportar.
- O tempo de detecção de carros com falhas graves durante a inspeção foi reduzido de algumas horas para alguns segundos.
Assim, a introdução do aprendizado de máquina não apenas ajudou a economizar dinheiro, mas também tornou o serviço mais seguro e confortável para os usuários. No entanto, isso está longe do fim da história. Nossa equipe em rápido crescimento continuará trabalhando ativamente para automatizar ainda mais verificações e tornar o Yandex.Taxi ainda mais conveniente, confortável e seguro.
Moral da história
Enquanto trabalhava na automação DCC no Yandex.Taxi, encontramos muitos problemas, encontramos várias soluções bem-sucedidas e tiramos seis conclusões importantes:
- Nem sempre é possível resolver o problema de frente (mesmo se você tiver um aprendizado profundo).
- O modelo é tão bom quanto os dados nos quais foi treinado (soa brega, mas é).
- Para resolver qualquer problema, é importante aproveitar as reais necessidades dos negócios e não minimizar a entropia cruzada.
- Na solução de alguns problemas, as pessoas ainda são importantes, apesar da introdução do aprendizado de máquina (olá, Yandex.Toloka!).
- As decisões baseadas em previsões de modelos de aprendizado de máquina podem não ser tomadas em todos os casos, mas apenas na parte em que os modelos têm muita confiança em suas respostas. Em outros casos, provavelmente vale a pena tomar decisões à moda antiga - com a ajuda de pessoas.
- Além da escolha da arquitetura e do treinamento do modelo, há muitos estágios do projeto que podem afetar muito a resolução de um problema comercial. Esses estágios são: coleta de dados, seleção de métricas de qualidade, opções de implementação de modelo, lógica de tomada de decisão do produto com base em previsões de modelo e muito mais.
Mais do interessante sobre tecnologia Táxi
Preços dinâmicos ou How Yandex.Taxi prevê alta demanda .
Como o Yandex.Taxi prevê o tempo de entrega do carro usando o aprendizado de máquina .