Ao desenvolver um produto, eles raramente prestam a devida atenção ao seu desempenho com uma alta intensidade de solicitações recebidas. Pouco ou nada fazendo isso - não há tempo suficiente, especialistas, ou eles se justificam com a frase típica: "Tudo funciona rapidamente conosco no prod, então por que verificar outra coisa?" Nesses casos, pode chegar um momento em que uma produção que funcione bem repentinamente devido ao aumento do fluxo de visitantes, por exemplo, sob o efeito Habrae. Então fica claro que fazer pesquisas sobre produtividade é realmente necessário.
Essa tarefa é desconcertante para muitos, porque há uma necessidade, mas não há um entendimento claro do que e como medir e como interpretar o resultado, às vezes não há requisitos não funcionais formados. Em seguida, falarei sobre por onde começar, se você decidir seguir esse caminho, e explicarei quais métricas são importantes na pesquisa de desempenho e como usá-las.
Pouco de teoria
Imagine que temos uma aplicação esférica no vácuo - ela recebe solicitações e fornece respostas para elas. Por simplicidade, pode ser um microsserviço com um método que não vai a lugar nenhum e não depende de outros componentes ou aplicativos. Nesse caso, não estamos muito interessados no que está escrito, como funciona e em que ambiente é lançado.
O que queremos saber sobre o desempenho em geral? Provavelmente, é bom conhecer o fluxo máximo de solicitações recebidas no qual o serviço é estável, seu desempenho com esse fluxo e o tempo necessário para concluir uma solicitação. É muito bom se você puder determinar os motivos que limitam ainda mais o crescimento da produtividade.
Obviamente, você precisa medir o tempo de resposta à solicitação, respectivamente, pelo fluxo de solicitações ou intensidade de entrada, o número de solicitações por unidade de tempo, geralmente por segundo e desempenho - o número de respostas para a mesma unidade de tempo. Os tempos de resposta podem ser espalhados por uma ampla faixa; portanto, para começar, faz sentido apresentá-los como uma média por segundo.
Além disso, podem surgir problemas em vários níveis: começando pelo fato de o serviço responder com um erro (e é bom se for quinhentos, e não "200 OK {" status ":" error "}" e terminando com o fato de que para de responder ou as respostas começam a se perder no nível da rede. As solicitações malsucedidas precisam ser capazes de capturar e é conveniente apresentá-las como uma porcentagem do total. O gráfico de desempenho, tempo de resposta e taxa de erro versus intensidade é mais ou menos assim:
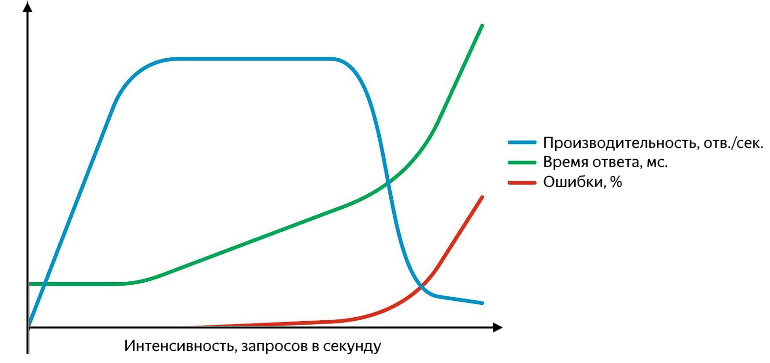
Com o aumento da intensidade da consulta, o tempo de resposta e a taxa de erros aumentam
Enquanto a produtividade cresce linearmente com intensidade, o serviço está indo bem. Ele processa com êxito todo o fluxo de solicitações recebidas, o tempo de resposta não muda, não há erros. Continuando a aumentar a intensidade, obtemos uma desaceleração no crescimento da produtividade até a saturação, na qual a produtividade atinge seu máximo e o tempo de resposta começa a crescer. Um aumento subsequente na intensidade levará a uma confusão - um aumento significativo no tempo de resposta e uma queda na produtividade, um crescimento ativo de erros começará. No estágio de crescimento e saturação, existem dois pontos importantes - desempenho normal e máximo.
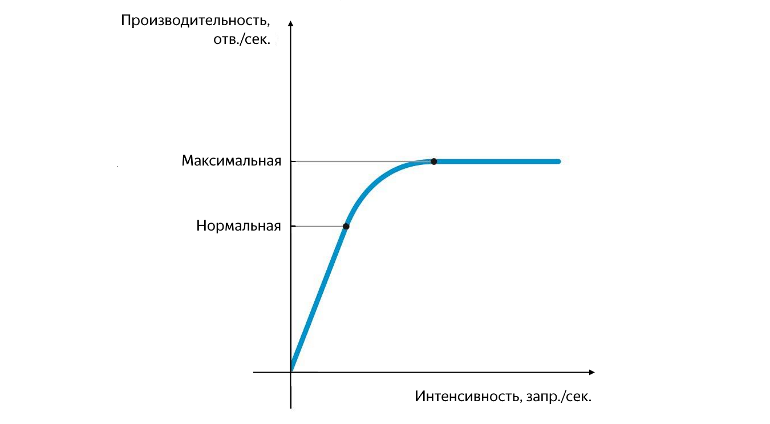
Posição de desempenho normal e máxima
A produtividade normal é alcançada no momento em que sua taxa de crescimento começa a diminuir e máxima - no momento em que sua taxa de crescimento se torna zero. Separar o desempenho entre o normal e o máximo é muito importante. Em uma intensidade que corresponde ao desempenho normal, o aplicativo deve funcionar de forma estável, e o valor do desempenho normal caracteriza o limite após o qual o gargalo do serviço começa a aparecer, afetando negativamente sua operação. Quando o desempenho máximo é atingido, o gargalo começa a limitar completamente o crescimento adicional, o serviço é instável e, como regra, neste momento, um pequeno mas estável histórico de erros começa a aparecer.
O problema pode ser causado por vários motivos - as filas estão bloqueadas, não há threads suficientes, o pool foi esgotado, a CPU ou a RAM foi completamente utilizada, velocidade de leitura / gravação insuficiente do disco e similares. É importante entender que a correção de um gargalo resultará na limitação do desempenho no próximo e assim por diante. É impossível se livrar completamente de um gargalo, ele só pode ser movido.
Os experimentos
Antes de tudo, é necessário determinar a magnitude da intensidade em que o serviço atinge desempenho normal e máximo e o tempo médio de resposta correspondente. Para fazer isso, em um experimento, basta simplesmente aumentar o fluxo de solicitações recebidas. É mais difícil determinar o valor da intensidade máxima e o tempo do experimento.
Você pode começar com o que está escrito em requisitos não funcionais (se houver), com a carga máxima do usuário na venda ou simplesmente obter valores no teto. Se a intensidade do fluxo de entrada não for suficiente, o serviço não terá tempo para atingir a saturação e será necessário repetir o experimento. Se a intensidade for muito alta, o serviço atingirá rapidamente a saturação e a depuração. Nesse caso, é conveniente ter um monitoramento para que, com um aumento significativo no número de erros, você não perca tempo em vão e interrompa o experimento.
Em nossas experiências, aumentamos gradualmente a intensidade de 0 a 1000 solicitações por segundo por 10 minutos. Isso é suficiente para que o serviço atinja a saturação e, se necessário, ajustamos o tempo e a intensidade no próximo experimento para obter um resultado mais preciso. Nos gráficos acima, tudo era suave e bonito, mas no mundo real pode ser difícil, à primeira vista, determinar o valor do desempenho normal.
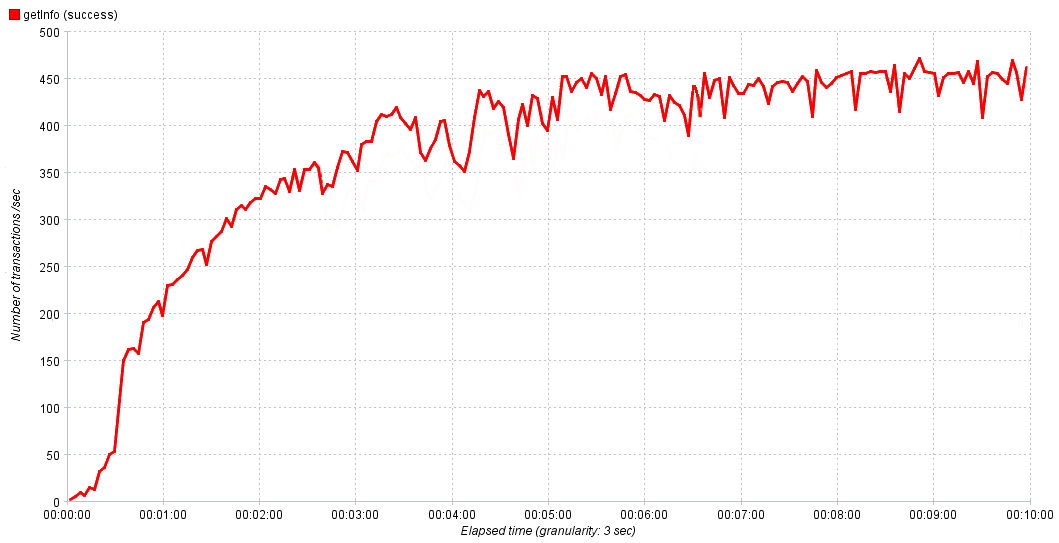
A dependência real do desempenho do serviço no tempo
Nesse caso, levamos de 80 a 90% do máximo para o desempenho normal. Se observarmos um crescimento ativo de erros após atingir a saturação, faz sentido investigá-los, porque são o resultado de um gargalo, estudá-los ajudará a localizá-lo e repassá-lo para correção.
Assim, os primeiros resultados são obtidos. Agora sabemos o desempenho normal e máximo do aplicativo, bem como os tempos de resposta correspondentes a eles. Isso é tudo? Claro que não! Com desempenho normal, o serviço deve funcionar de forma estável, o que significa que você precisa verificar seu funcionamento sob carga normal por um tempo. Qual? Você pode novamente examinar requisitos não funcionais, solicitar a analistas ou monitorar a duração dos períodos de atividade máxima no produto. Em nossos experimentos, aumentamos linearmente a carga de 0 para o normal e permanecemos nela por 10 a 15 minutos. Isso é suficiente se a carga máxima do usuário for significativamente menor que o normal, mas se forem comparáveis, o tempo da experiência deverá ser aumentado.
Para avaliar rapidamente o resultado de uma experiência, é conveniente agregar os dados obtidos na forma das seguintes métricas:
- tempo médio de resposta
- mediana
- Percentil 90%
- % de erros
- desempenho.
Qual é o tempo médio de resposta é compreensível, no entanto, a média é uma medida adequada apenas no caso de uma distribuição normal da amostra, uma vez que é sensível demais aos "valores extremos" - valores muito grandes ou muito pequenos que estão fortemente fora da tendência geral. A mediana é o meio de toda a amostra de tempos de resposta, metade dos valores é menor que o restante e o restante é maior. Por que é necessário?
Em primeiro lugar, com base em sua definição, é menos sensível a valores discrepantes, ou seja, é uma métrica mais adequada e, em segundo lugar, comparando-a com a média, é possível avaliar rapidamente as características da distribuição de respostas. Em uma situação ideal, eles são iguais - a distribuição dos tempos de resposta é normal e o serviço é bom!
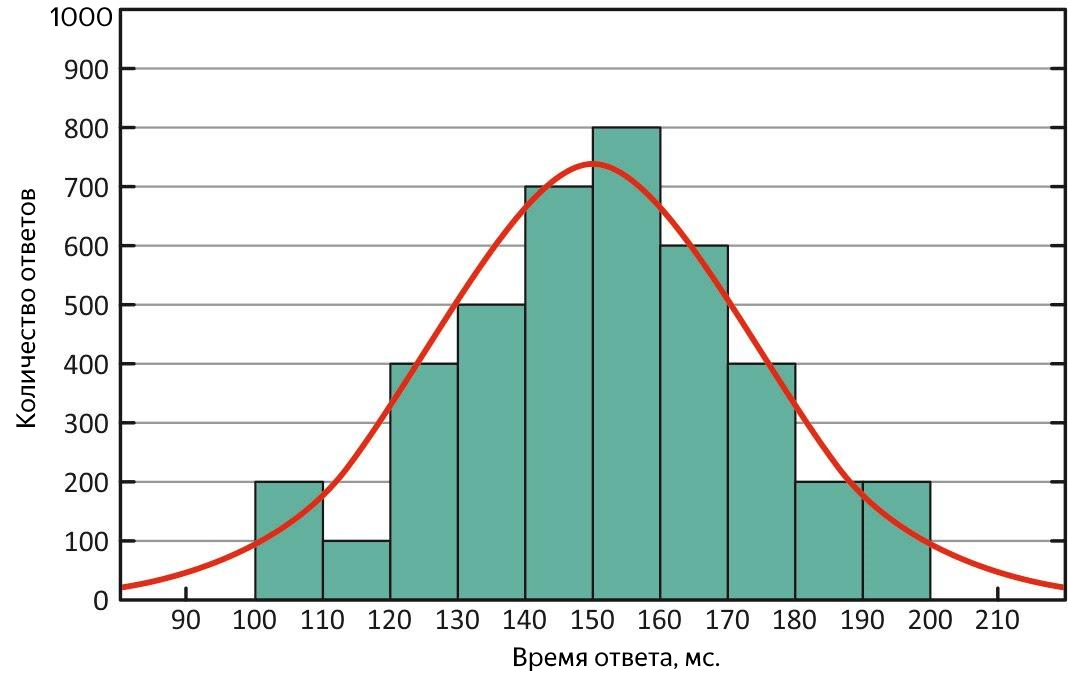
Distribuição normal dos tempos de resposta. Com essa distribuição, a média e a mediana são equivalentes
Se a média for muito diferente da mediana, a distribuição será distorcida e "outliers" poderão estar presentes durante o experimento. Se a média for maior - houve períodos em que o serviço respondeu muito lentamente, ou seja, diminuiu a velocidade.
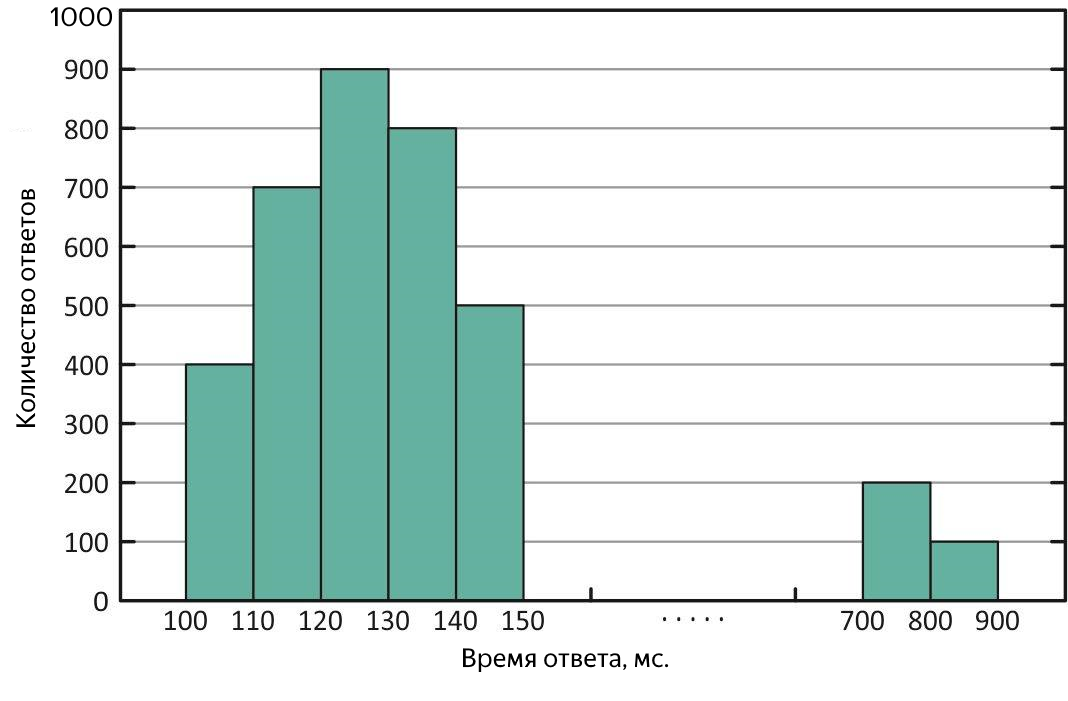
Distribuição dos tempos de resposta com "outliers" de respostas longas. Com essa distribuição, a média é maior que a mediana.
Tais casos requerem análises adicionais. Para estimar a escala de "emissões", quantis ou percentis vêm em socorro.
Um quantil, no contexto da amostra obtida, é o valor do tempo de resposta, ao qual a parte correspondente de todas as solicitações se encaixa. Se você usar% de consultas, esse é o percentil (a propósito, a mediana é de 50%). É conveniente usar um percentil 90% para estimar as emissões. Por exemplo, como resultado do experimento, foi obtida uma mediana de 100 ms e a média - 250 ms excede a mediana em 2,5 vezes! Obviamente, isso não é totalmente bom, analisamos um quantil de 90% e existem 1000 ms - até 10% de todas as solicitações bem-sucedidas foram concluídas por mais de um segundo, uma bagunça, você precisa descobrir. Para procurar consultas longas, você pode morder o arquivo com os resultados da experiência ou imediatamente nos logs de serviço, mas é ainda melhor apresentar o tempo médio de resposta na forma de um gráfico versus o tempo, mostrando imediatamente o tempo e a natureza dos "outliers" disponíveis.
Sumário
Então, você conduziu com sucesso os experimentos e obteve os resultados. Se é bom ou ruim, depende dos requisitos para o serviço, mas não os números obtidos são mais importantes, mas por que esses números são e para entender por que crescimento adicional é limitado. Se você conseguir encontrar um gargalo - muito bom, se não, mais cedo ou mais tarde a necessidade de produtividade poderá aumentar e você ainda precisará procurá-lo; portanto, às vezes é mais fácil evitar a situação.
Nesta nota, dei uma abordagem básica para pesquisar desempenho, respondendo às perguntas que eu tinha no início. Não tenha medo de pesquisar o desempenho, é necessário!
PS
Visite nossa aconchegante sala de bate-papo por telegrama, onde você pode fazer perguntas, ajudar com conselhos e apenas conversar sobre pesquisa de desempenho.