
Como sempre, obrigado a Fred Hebert e Sargun Dhillon por ler um rascunho deste artigo e oferecer alguns conselhos inestimáveis.
Em sua palestra sobre velocidade, Tamar Berkovichi, da Box, enfatizou a importância das verificações de desempenho para o failover automático do banco de dados. Em particular, ela observou que o monitoramento do tempo de execução de consultas ponto a ponto, como método para determinar a integridade de um banco de dados, é melhor do que o simples ping (ping).
... transferindo tráfego para outro nó (réplica) para eliminar a inação, é necessário criar proteção contra rejeição e outras situações de fronteira. Não é difícil. O foco na organização de um trabalho eficaz é saber quando colocar o banco de dados na primeira posição, ou seja, Você deve poder avaliar corretamente a integridade do banco de dados. Agora, muitos parâmetros aos quais estamos acostumados a prestar atenção - por exemplo, carga do processador, latência, taxa de erro - são sinais secundários. Na verdade, nenhum desses parâmetros fala da capacidade do banco de dados de processar o tráfego do cliente. Portanto, se você usá-los para tomar uma decisão sobre a alternância, poderá obter resultados falso-positivos e falso-negativos. Nosso verificador de integridade realmente realiza consultas simples nos nós do banco de dados e usa os dados em consultas concluídas e com falha para avaliar com mais precisão a integridade do banco de dados.
Eu discuti isso com um amigo, e ele sugeriu que as verificações de saúde sejam extremamente simples e que o tráfego real seja o melhor critério para avaliar a saúde de um processo.
Freqüentemente, discussões relacionadas à implementação de verificações de saúde giram em torno de duas opções opostas: testes simples de comunicação / sinal ou testes complexos de ponta a ponta. Neste artigo, quero enfatizar o problema associado ao uso da forma de verificações de integridade acima mencionada para certos tipos de soluções de balanceamento de carga, bem como a necessidade de uma abordagem mais detalhada para avaliar a integridade de um processo.
Dois tipos de exames de saúde
As verificações de integridade, mesmo em muitos sistemas modernos, em regra, se enquadram em duas categorias: verificações no nível do nó e no nível do serviço.
Por exemplo, o Kubernetes implementa a validação analisando a disponibilidade e a capacidade de sobrevivência . A verificação de disponibilidade é usada para determinar a capacidade da lareira de atender o tráfego. Se a verificação de prontidão não for executada, ela será excluída dos terminais que compõem o serviço e, por isso, no coração, até que a verificação seja concluída, nenhum tráfego será roteado. Por outro lado, uma verificação de sobrevivência é usada para determinar se um serviço está respondendo a um travamento ou travamento. Se falhar, o contêiner individual no kubelet será reiniciado . Da mesma forma, o Consul permite várias formas de checks : checks baseadas em script baseadas em HTTP direcionadas a um URL específico, verificações baseadas em TTL ou até mesmo aliases.
O método mais comum para implementar uma verificação de saúde no nível de serviço é determinar o ponto final da verificação de saúde. Por exemplo, no gRPC, uma própria verificação de saúde se torna uma chamada RPC. O gRPC também permite verificações de integridade do nível de serviço e verificações gerais de integridade do servidor gRPC .
No passado, as verificações de integridade no nível do host eram usadas como um sinal para disparar um alerta. Por exemplo, um alerta com uma carga média do processador (atualmente considerado um padrão anti-design). Mesmo que a verificação de integridade não seja usada diretamente para notificação, ela ainda serve de base para várias outras decisões automáticas de infraestrutura, por exemplo, em relação ao balanceamento de carga e (às vezes) circuito aberto. Em esquemas de dados da grade de serviço, como o Envoy, os dados de verificação de integridade , quando se trata de determinar o roteamento de tráfego para uma instância, avançam com relação aos dados de descoberta de serviço.
Eficiência é um espectro, não uma taxonomia binária
Uma solicitação de eco, ou ping, pode apenas estabelecer se o serviço está funcionando , enquanto testes de ponta a ponta são proxies para estabelecer se o sistema é capaz de executar uma unidade de trabalho específica, onde a unidade de trabalho pode ser uma consulta ao banco de dados ou um cálculo específico . Independentemente da forma de uma verificação de saúde, seu resultado é considerado puramente binário: "aprovado" ou "reprovado".
Nas opções de infraestrutura dinâmicas e muitas vezes "escaláveis automaticamente" de hoje, um único processo que simplesmente "funciona" não importa se não pode executar uma unidade de trabalho específica. Acontece que verificações simplificadas, como testes de eco, são quase inúteis.
É fácil determinar quando um serviço está completamente desconectado , mas estabelecer o grau de operacionalidade de um serviço em execução é muito mais difícil. É bem possível que o processo esteja em execução (ou seja, a verificação de integridade seja aprovada) e o tráfego seja roteado, mas para executar uma determinada unidade de trabalho, por exemplo, durante o período de atraso do serviço p99, isso não é suficiente.
Freqüentemente, o trabalho não pode ser concluído porque o processo está sobrecarregado. Em serviços altamente competitivos, o “congestionamento” está claramente correlacionado com o número de solicitações simultâneas processadas por apenas um processo com enfileiramento excessivo, o que pode levar a um aumento no atraso de uma chamada RPC (embora, na maioria das vezes, o serviço de nível inferior simplesmente coloque a solicitação em espera e tente novamente). timeout). Isso é especialmente verdadeiro se o terminal de verificação de integridade estiver configurado para retornar automaticamente ao código de status HTTP 200, enquanto a operação real realizada pelo serviço envolver E / S ou computação de rede.

O desempenho do processo é um espectro. Antes de tudo, estamos interessados na qualidade do serviço , por exemplo, no tempo necessário para o processo restaurar o resultado de uma unidade de trabalho específica e na precisão do resultado.
É possível que o processo flutue entre diferentes graus de capacidade de trabalho durante sua vida útil: da capacidade total de trabalho (por exemplo, a capacidade de funcionar no nível esperado de paralelismo) até o ponto de inoperabilidade (quando as filas começam a encher) e o ponto em que o processo entra completamente em uma zona inoperante (sentida qualidade de serviço reduzida). Somente os serviços mais triviais podem ser construídos com a suposição de que não há grau de falha parcial em nenhum período em que uma falha parcial implique que algumas funções funcionem e outras sejam desativadas, e não apenas “alguns pedidos são executados, outros não são executados”. Se a arquitetura do serviço não permitir corrigir corretamente a falha parcial, o cliente corrigirá automaticamente a tarefa de correção de erros.
Uma infra-estrutura adaptável e auto-reparável deve ser construída com o entendimento de que essas flutuações são perfeitamente normais . Também é importante lembrar que essa diferença só importa em relação ao balanceamento de carga - para o orquestrador, por exemplo, não faz sentido reiniciar o processo apenas porque o processo está à beira de sobrecarga.
Em outras palavras, para o nível de orquestração, é bastante razoável considerar a operacionalidade do processo como um estado binário e reiniciar o processo somente após uma falha ou congelamento. Mas na camada de balanceamento de carga (seja um proxy externo, por exemplo, o Envoy ou uma biblioteca interna no lado do cliente), é extremamente importante que ele atue com base em informações mais detalhadas sobre a operacionalidade do processo - quando tomar as decisões apropriadas sobre interromper o circuito e descarregar a carga. A degradação gradual do serviço é impossível se for impossível determinar com precisão o nível de desempenho do serviço a qualquer momento.
Deixe-me contar por experiência própria: a concorrência ilimitada é geralmente o principal fator que leva à degradação do serviço ou a uma diminuição permanente da produtividade. O balanceamento de carga (e, como conseqüência, a perda de carga) geralmente se resume ao gerenciamento eficiente da concorrência e à aplicação de contrapressão, impedindo a sobrecarga do sistema.
A necessidade de feedback ao aplicar a contrapressão
Matt Ranney escreveu um artigo fenomenal sobre concorrência ilimitada e a necessidade de contrapressão no Node.js. O artigo inteiro é curioso, mas a principal conclusão (pelo menos para mim) foi a necessidade de feedback entre o processo e sua unidade de saída (geralmente um balanceador de carga, mas às vezes outro serviço).
O truque é que, quando os recursos estão esgotados, algo deve ser dado em algum lugar. A demanda está crescendo e a produtividade não pode aumentar magicamente. Para limitar as tarefas recebidas, a primeira coisa a fazer é definir um limite de velocidade no nível do site, por endereço IP, usuário, sessão ou, na melhor das hipóteses, por algum elemento importante para o aplicativo. Muitos balanceadores de carga podem limitar a velocidade de uma maneira mais complicada do que o servidor Node.js.negociável, mas geralmente eles não percebem problemas até que o processo esteja em uma situação difícil.
Os limites de velocidade e os circuitos abertos baseados em limites e limites estáticos podem não ser confiáveis e instáveis em termos de correção e escalabilidade. Alguns balanceadores de carga (em particular, HAProxy) fornecem muitas estatísticas sobre o comprimento das filas internas para cada servidor e parte do servidor . Além disso, o HAProxy permite agent-check (uma verificação auxiliar independente da verificação de integridade normal), que permite que o processo forneça ao servidor proxy um feedback de integridade mais preciso e dinâmico. Link para documentos :
A verificação da integridade do agente é realizada pela conexão TCP com a porta, com base no parâmetro agent-port especificado e na leitura da sequência ASCII. Uma linha consiste em uma série de palavras separadas por espaços, tabulações ou vírgulas em qualquer ordem, terminando opcionalmente em /r / ou /n incluindo os seguintes elementos:
- Representação de um valor percentual inteiro positivo de ASCII, por exemplo, 75% . Os valores neste formato determinam o peso em proporção ao valor inicial
O valor do servidor ponderado configurado ao iniciar o HAProxy. Observe que um valor de peso zero é indicado na página de estatísticas como DRAIN partir do momento de um impacto semelhante no servidor (ele é removido do farm LB).
- Parâmetro de string maxconn : seguido por um número inteiro (sem espaço). Valores em
Este formato define o maxconn servidor maxconn . Número máximo
as conexões declaradas devem ser multiplicadas pelo número de balanceadores de carga e várias partes do servidor usando essa verificação de integridade para obter o número total de conexões que o servidor pode estabelecer. Por exemplo: maxconn:30
- A palavra ready . Isso traduz o estado administrativo do servidor em
READY , cancelando o MAINT DRAIN ou MAINT .
- A palavra drain . Isso traduz o estado administrativo do servidor em
Modo DRAIN ("drenagem"), após o qual o servidor não aceitará novas conexões, com exceção das conexões aceitas pelo banco de dados.
- A palavra maint . Isso traduz o estado administrativo do servidor em
Modo MAINT ("manutenção"), após o qual o servidor não aceita novas conexões, e as verificações de integridade são interrompidas.
- As palavras down , com failed ou stopped , que podem ser seguidas por uma linha de descrição após o símbolo acentuado (#). Todos eles indicam o status operacional do servidor DOWN ("desativado"), mas como a palavra em si é exibida na página de estatísticas, a diferença permite ao administrador determinar se a situação era esperada: o serviço pode ser intencionalmente parado, alguns testes de confirmação podem aparecer, mas não passam, ou ser considerado desativado (sem processo, sem resposta da porta).
- A palavra up indica o status operacional do servidor UP (“on”) se as verificações de integridade também confirmarem a disponibilidade do serviço.
Os parâmetros não reivindicados pelo agente não são alterados. Por exemplo, um agente pode ser projetado apenas para monitorar o uso do processador e relatar apenas um valor de peso relativo sem interagir com o estado operacional. Da mesma forma, o programa do agente pode ser projetado como uma interface de usuário final com 3 opções, permitindo que o administrador altere apenas o estado administrativo.
No entanto, deve-se ter em mente que apenas o agente pode desfazer suas próprias ações; portanto, se o servidor estiver definido como DRAIN ou DOWN usando o agente, ele deverá executar outras ações equivalentes para reiniciar o serviço.
A falha na conexão com o agente não é considerada um erro, porque a capacidade de conexão é testada executando regularmente uma verificação de saúde, que é iniciada usando o parâmetro check. No entanto, se uma mensagem de desligamento chegar, não será uma boa ideia interromper o agente, pois apenas o agente que está relatando o desligamento pode reativar o servidor.
Esse esquema de comunicação dinâmica do serviço com a unidade de saída é extremamente importante para criar uma infraestrutura auto-adaptável. Um exemplo seria a arquitetura com a qual trabalhei em um trabalho anterior.
Eu trabalhava na imgix , uma empresa iniciante de processamento de imagens em tempo real. Usando uma URL de API simples, as imagens são recuperadas e convertidas em tempo real e depois usadas em qualquer lugar do mundo via CDN. Nossa pilha era bastante complexa ( como descrito acima ), mas, em suma, nossa infraestrutura incluía um nível de balanceamento e balanceamento de carga (em conjunto com o nível de recebimento de dados da fonte), o nível de cache da fonte, o nível de processamento de imagem e o nível de entrega de conteúdo.

O nível de balanceamento de carga foi baseado no serviço Spillway, que atuava como um proxy reverso e intermediário de solicitação. Era um serviço puramente interno; no início, começamos o nginx, o HAProxy e o Spillway; portanto, ele não foi projetado para concluir o TLS ou executar outras funções desse conjunto incontável que geralmente é da competência do proxy de fronteira.
O Spillway consistia em dois componentes: a parte do cliente (Spillway FE) e a corretora. Embora inicialmente ambos os componentes estivessem no mesmo arquivo binário, em algum momento decidimos separá-los em arquivos binários separados que foram implantados simultaneamente no mesmo host. Principalmente porque esses dois componentes tinham perfis de desempenho diferentes e a parte do cliente estava quase completamente conectada ao processador. A tarefa da parte do cliente era executar o processamento preliminar de cada solicitação, incluindo a verificação preliminar no nível do cache de origem, para garantir que a imagem fosse armazenada em cache em nosso data center antes de enviar a solicitação de conversão de imagem ao executor.
A qualquer momento, tínhamos uma piscina fixa (cerca de uma dúzia, se a memória servir) de artistas que poderiam estar conectados ao mesmo corretor Spillway. Os artistas foram responsáveis pela conversão real da imagem (corte, redimensionamento, processamento de PDF, renderização de GIF etc.). Eles processaram tudo, desde PDFs de centenas de páginas e GIFs com centenas de quadros a arquivos de imagem simples. Outra característica do contratante era que, embora todas as redes fossem completamente assíncronas, não havia conversões reais na própria GPU. Como trabalhamos em tempo real, era impossível prever como seria o tráfego em um determinado momento. Nossa infraestrutura teve que se adaptar a várias formas de tráfego de entrada - sem intervenção manual do operador.
Dado os padrões de tráfego díspares e heterogêneos que encontramos com frequência, tornou-se necessário que os executores se recusassem a aceitar solicitações de entrada (mesmo quando totalmente operacionais) se aceitarem a conexão ameaçava sobrecarregar o executor. Cada solicitação ao executante continha um determinado conjunto de metadados sobre a natureza da solicitação, o que permitia ao executante determinar se ele era capaz de atender a essa solicitação. Cada executor tinha seu próprio conjunto de dados estatísticos sobre os pedidos com os quais ele estava trabalhando atualmente. O funcionário usou essas estatísticas em conjunto com os metadados da solicitação e outros dados heurísticos, como dados do tamanho do buffer do soquete, para determinar se ele recebeu a solicitação de entrada corretamente. Se o funcionário determinou que não podia aceitar a solicitação, ele criou uma resposta que não diferia da verificação do agente HAProxy, informando seu Spillway sobre sua operacionalidade.
Spillway monitorou o desempenho de todos os artistas da piscina. No início, tentei enviar uma solicitação três vezes seguidas para diferentes executores (era dada preferência àqueles que tinham a imagem original nos bancos de dados locais e que não estavam sobrecarregados) e, se todos os três executores se recusassem a aceitar a solicitação, a solicitação era enfileirada no broker na memória. O broker suportou três formas de filas: a fila LIFO, a fila FIFO e a fila prioritária. Se todas as três filas foram preenchidas, o broker simplesmente rejeitou a solicitação, permitindo que o cliente (HAProxy) tentasse novamente após o período de atraso. Quando uma solicitação foi colocada em uma das três filas, qualquer executor livre pode removê-la e processá-la. Existem certas dificuldades associadas à atribuição de uma prioridade a uma solicitação e à decisão de qual das três filas (LIFO, FIFO, filas baseadas em prioridade) deve ser colocada, mas este é um tópico para um artigo separado.
Para a operação eficaz do serviço, não precisamos discutir essa forma de feedback dinâmico. Monitoramos cuidadosamente o tamanho da fila do broker (todas as três filas) e o Prometheus emitiu um dos principais avisos quando o tamanho da fila excedeu um determinado limite (o que era bastante raro).
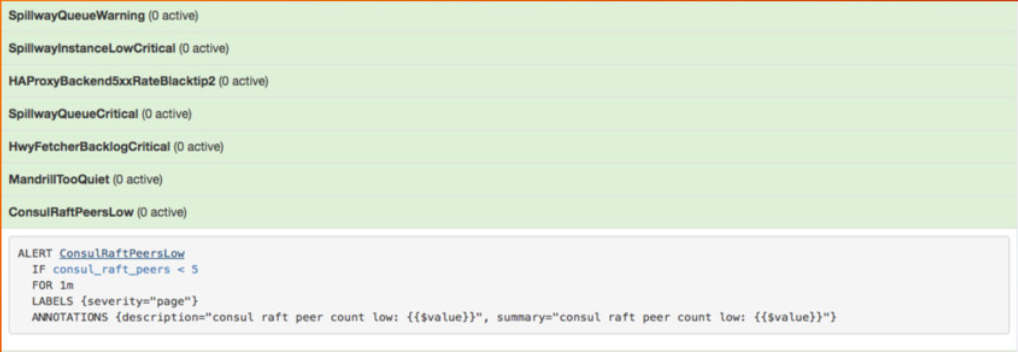
Imagem da minha apresentação no sistema de monitoramento Prometheus no Google NYC em novembro de 2016

O aviso é retirado da minha apresentação no sistema de monitoramento Prometheus na conferência OSCON em maio de 2017.
No início deste ano, a Uber publicou um artigo interessante no qual esclareceu sua abordagem para implementar um nível de redução de carga com base na qualidade do serviço.
Analisando falhas nos últimos seis meses, descobrimos que 28% delas poderiam ser mitigadas ou evitadas pela degradação suave .
Os três tipos mais comuns de falhas foram associados aos seguintes fatores:
- Alterações no esquema da solicitação recebida, incluindo congestionamento e nós do operador incorretos.
- Esgotamento de recursos como processador, memória, circuito de entrada / saída ou recursos de rede.
- Falhas de dependência, incluindo infraestrutura, data warehouse e serviços downstream.
Implementamos um detector de sobrecarga baseado no algoritmo CoDel . Para cada nó de extremidade ativado, um buffer de solicitação leve (implementado com base em gourutin e canais ) é adicionado para rastrear atrasos entre o momento de receber o pedido da origem da chamada e o início do processamento do pedido no manipulador. , , .
, , , - . 2013 Google «The Tail at Scale» , ( ), ( ) .
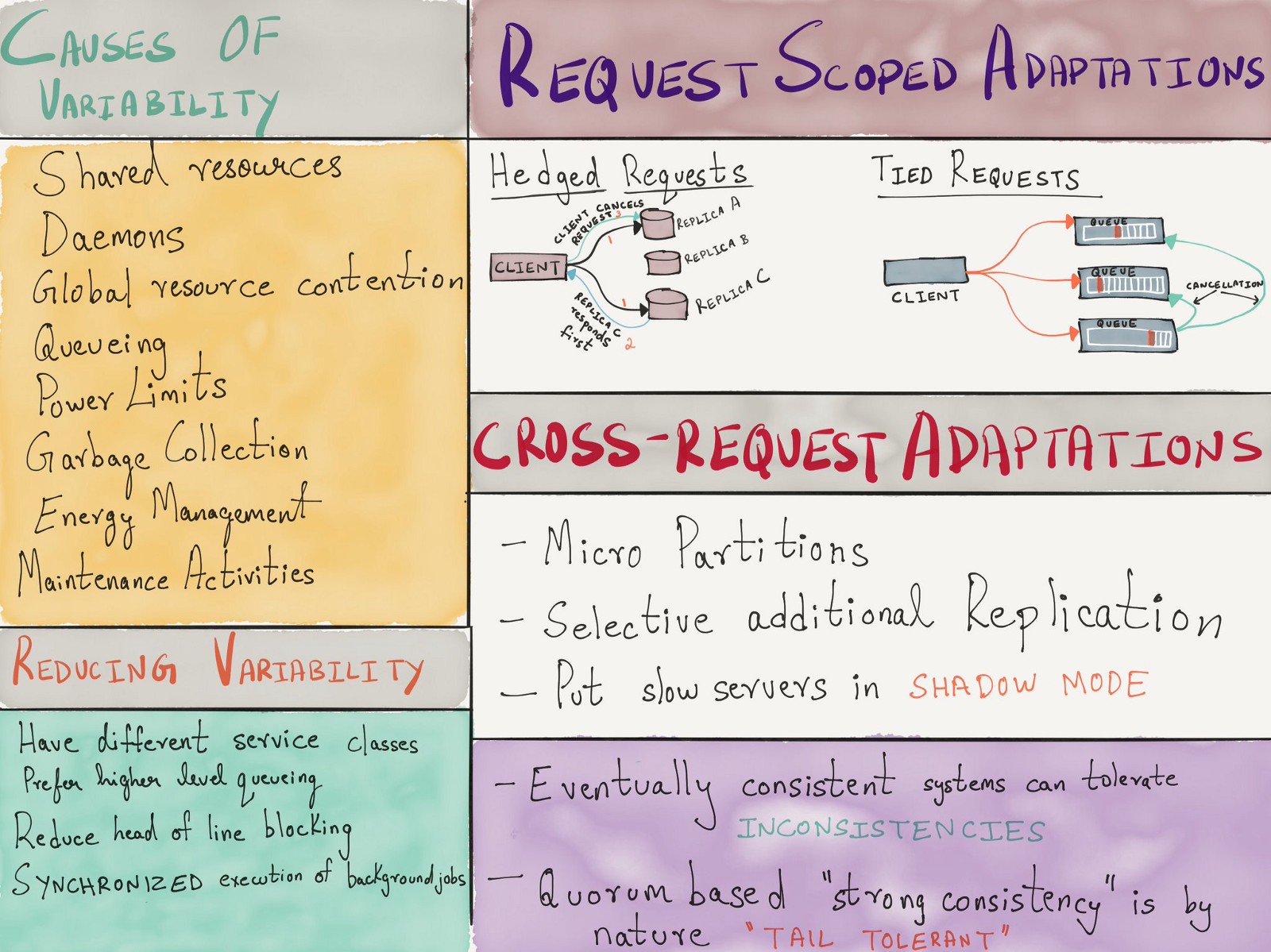
, . , .

( )
, , :
- , , QCon London 2018.
- : - , , LISA 2017.
- – , , Strangeloop 2017.
- : , , , Strangeloop 2017.
- « » .
Conclusão
, TCP/IP ( ), IP ECN ( IP ) Ethernet, , .
, . . , . .