Você está aqui se quiser saber como domesticar uma estrutura amplamente conhecida nos círculos de desenvolvedores de Python chamada Celery. E mesmo que o Celery execute com confiança comandos básicos em seu projeto, a experiência na fintech pode abrir lados desconhecidos para você. Porque o fintech é sempre Big Data e, com ele, a necessidade de tarefas em segundo plano, processamento em lote, API assíncrona, etc.

A beleza da história de Oleg Churkin sobre o aipo no
Moscow Python Conf ++, além de instruções detalhadas sobre como configurar o aipo sob carga e como monitorá-lo, é que você pode emprestar idéias úteis.
Sobre o palestrante e o projeto: Oleg Churkin (
Bahusss ) desenvolve projetos em Python de várias complexidades há 8 anos, trabalhou em muitas empresas conhecidas: Yandex, Rambler, RBC, Kaspersky Lab. Agora, techlide na inicialização do fintech-StatusPoney.
O projeto trabalha com uma grande quantidade de dados financeiros de usuários (1,5 terabytes): contas, transações, comerciantes, etc. Ele executa até um milhão de tarefas todos os dias. Talvez esse número não pareça realmente grande para alguém, mas para uma pequena startup com capacidades modestas, essa é uma quantidade significativa de dados, e os desenvolvedores tiveram que enfrentar vários problemas no caminho para um processo estável.
Oleg falou sobre os principais pontos do trabalho:
- Quais tarefas você deseja resolver com a estrutura, por que você escolheu o Aipo.
- Como o aipo ajudou.
- Como configurar o aipo sob carga.
- Como monitorar o status do aipo.
E ele compartilhou alguns utilitários de design que implementam a funcionalidade ausente no Celery. Como se viu, em 2018, e isso pode ser. A seguir, é apresentada uma versão em texto do relatório na primeira pessoa.
Edição
Foi necessário resolver as seguintes tarefas:
- Execute tarefas em segundo plano separadas .
- Faça o processamento em lote de tarefas , ou seja, execute várias tarefas ao mesmo tempo.
- Incorporar o processo Extrair, Transformar, Carregar .
- Implemente a API assíncrona . Acontece que a API assíncrona pode ser implementada não apenas usando estruturas assíncronas, mas também completamente síncrona;
- Execute tarefas periódicas . Nem um único projeto pode prescindir de tarefas periódicas; para alguns, Cron pode ser dispensado, mas existem ferramentas mais convenientes.
- Construa uma arquitetura de acionador : para acionar um acionador, execute uma tarefa que atualize os dados. Isso é feito para compensar a falta de energia em tempo de execução pré-computando dados em segundo plano.
As tarefas em segundo plano incluem qualquer tipo de notificação: email, push, área de trabalho - tudo isso é enviado em tarefas em segundo plano por um gatilho. Da mesma maneira, uma atualização periódica dos dados financeiros é iniciada.
Em segundo plano, várias verificações específicas são realizadas, por exemplo, verificando se há fraude em um usuário. Nas startups financeiras,
é prestado muito esforço e atenção especificamente à segurança dos dados , pois permitimos que os usuários adicionem suas contas bancárias ao nosso sistema e podemos ver todas as suas transações. Os fraudadores podem tentar usar nosso serviço para algo ruim, por exemplo, para verificar o saldo de uma conta roubada.
A última categoria de tarefas em segundo plano são
as tarefas de manutenção : ajustar algo, ver, corrigir, monitorar etc.
Para notificações em massa, o
processamento em lote é usado . Uma grande quantidade de dados que recebemos de nossos usuários deve ser calculada e processada de uma certa maneira, incluindo no modo de lote.
O mesmo conceito inclui o clássico
Extrair, Transformar, Carregar :
- carregar dados de fontes externas (API externa);
- mantenha não processado;
- executar tarefas que leem e processam dados;
- salvamos os dados processados no lugar certo, no formato certo, para que mais tarde seja conveniente usar na interface do usuário, por exemplo.
Não é segredo que a API assíncrona pode ser feita com uma simples solicitação de pesquisa: o front-end inicia o processo no back-end, o back-end inicia uma tarefa que se lança periodicamente, "derrama" os resultados e atualiza o estado no banco de dados. O frontend mostra ao usuário que esse estado interativo está mudando. Isso permite que você:
- executar tarefas de pesquisa de outras tarefas;
- execute tarefas diferentes, dependendo das condições.
Em nosso serviço, isso é suficiente por enquanto, mas no futuro provavelmente teremos que reescrever outra coisa.
Requisitos da ferramenta
Para implementar essas tarefas, tínhamos os seguintes requisitos para ferramentas:
- Funcionalidade necessária para realizar nossas ambições.
- Escalabilidade sem muletas.
- Monitorando o sistema para entender como ele funciona. Nós usamos relatórios de bugs, então a integração com o Sentry não ficará fora do lugar, com o Django também.
- Desempenho , porque temos muitas tarefas.
- Maturidade, confiabilidade e desenvolvimento ativo são coisas óbvias. Estávamos procurando uma ferramenta que será suportada e desenvolvida.
- Adequação da documentação - sem documentação em nenhum lugar .
Qual ferramenta escolher?
Quais são as opções no mercado em 2018 para resolver esses problemas?
Era uma vez para tarefas menos ambiciosas, escrevi uma
biblioteca útil que ainda é usada em alguns projetos. É fácil de operar e executa tarefas em segundo plano. Mas, ao mesmo tempo, não são necessários corretores (nem o Celery nem outros), apenas o servidor de aplicativos
uwsgi , que possui um spooler, é algo que começa como um trabalhador separado. Esta é uma solução muito simples - todas as tarefas são armazenadas condicionalmente em arquivos. Para projetos simples, basta, mas para os nossos, não é suficiente.
De alguma forma, consideramos:
- Aipo (10 mil estrelas no GitHub);
- RQ (5 mil estrelas no GitHub);
- Huey (2 mil estrelas no GitHub);
- Dramatiq (1 mil estrelas no GitHub);
- Tasktiger (estrelas de 0,5 mil no GitHub);
- Fluxo de ar? Luigi
Candidato promissor 2018
Agora, gostaria de chamar sua atenção para
Dramatiq . Esta é uma biblioteca do adepto do aipo, que conhecia todas as desvantagens do aipo e decidiu reescrever tudo, muito bem. Benefícios do Dramatiq:
- Um conjunto de todos os recursos necessários.
- Afiando a produtividade.
- Suporte de métricas e sentinelas para o Prometheus pronto para uso
- Uma base de código pequena e claramente escrita, carregamento automático de código.
Há algum tempo, Dramatiq teve problemas com licenças: primeiro houve AGPL, depois foi substituído por LGPL. Mas agora você pode tentar.
Mas em 2016, além do aipo, não havia nada de especial para levar. Gostamos da sua rica funcionalidade e, então, ela se adequava idealmente às nossas tarefas, porque mesmo assim era madura e funcional:
- teve tarefas periódicas prontas para uso;
- apoiou vários corretores;
- Integrado com Django e Sentry.
Recursos do projeto
Vou falar sobre o nosso contexto, para que a história seja mais clara.
Usamos o
Redis como um intermediário de mensagens . Ouvi muitas histórias e rumores de que o Redis está perdendo mensagens, que não está adaptado para ser um intermediário de mensagens. Na experiência de produção, isso não está confirmado, mas, como se vê, o Redis agora funciona mais eficientemente que o RabbitMQ (é com o Celery, pelo menos, aparentemente, o problema está no código de integração com os corretores). Na versão 4, o corretor Redis foi corrigido, ele realmente parou de perder tarefas durante as reinicializações e funciona de maneira bastante estável. Em 2016, o Celery abandonaria o Redis e se concentraria na integração com o RabbitMQ, mas, felizmente, isso não aconteceu.
Em caso de problemas com o Redis, se precisarmos de alta disponibilidade séria, nós, porque usamos o poder da Amazon, mudaremos para o Amazon SQS ou o Amazon MQ.
Não
usamos backend de resultados para armazenar os resultados , porque preferimos armazenar os resultados onde queremos e verificá-los da maneira que queremos. Não queremos que o aipo faça isso por nós.
Usamos um
pool de pefork , ou seja, trabalhadores de processo que criam bifurcações de processos separados para simultaneidade adicional.
Unidade de trabalho
Discutiremos os elementos básicos para atualizar aqueles que ainda não experimentaram o aipo, mas que apenas o farão.
Unidade de trabalho para o aipo é um desafio . Vou dar um exemplo de uma tarefa simples que envia um email.
Função simples e decorador:
@current_app.task def send_email(email: str): print(f'Sending email to email={email}')
O início da tarefa é simples: chamamos a função e a tarefa será executada em tempo de execução (send_email (email = "python@example.com")) ou no trabalhador, ou seja, o próprio efeito da tarefa em segundo plano:
send_email.delay(email="python@example.com") send_email.apply_async( kwargs={email: "python@example.com"} )
Por dois anos trabalhando com o aipo sob altas cargas, criamos as regras de boa forma. Houve muitos ancinhos, aprendemos a contorná-los e vou compartilhar como.
Code Design
A tarefa pode conter uma lógica diferente. Em geral, o Aipo ajuda a manter as tarefas em arquivos ou pacotes ou a importá-las de algum lugar. Às vezes, você obtém uma pilha de lógica de negócios em um módulo. Em nossa opinião, a abordagem correta do ponto de vista da modularidade do aplicativo é manter um
mínimo de lógica na tarefa . Usamos quebra-cabeças apenas como "gatilhos" do código. Ou seja, a tarefa não possui lógica em si mesma, mas aciona o lançamento do código em segundo plano.
@celery_app.task(queue='...') def run_regular_update(provider_account_id, *args, **kwargs): """...""" flow = flows.RegularSyncProviderAccountFlow(provider_account_id) return flow.run(*args, **kwargs)
Colocamos todo o código em classes externas que usam outras classes. Todas as tarefas consistem essencialmente em duas linhas.
Objetos simples em parâmetros
No exemplo acima, um determinado ID é passado para a tarefa. Em todas as tarefas que usamos,
transferimos apenas pequenos dados escalares , id. Não serializamos modelos do Django para transmiti-los. Mesmo no ETL, quando um grande blob de dados vem de um serviço externo, primeiro o salvamos e, em seguida, executamos uma tarefa que lê todo esse blob por id e o processa.
Se você não fizer isso, vimos uma mistura muito grande de memória consumida no Redis. A mensagem começa a ocupar mais memória, a rede está muito carregada, o número de tarefas processadas (desempenho) diminui. Desde que o objeto chegue à conclusão, as tarefas se tornam irrelevantes, o objeto já foi excluído. Os dados precisavam ser serializados - nem tudo está bem serializado no JSON no Python. Precisávamos da oportunidade, ao tentar novamente as tarefas, para decidir rapidamente o que fazer com esses dados, obtê-los novamente e executar algumas verificações.
Se você transferir dados grandes em parâmetros, pense novamente! É melhor transferir um pequeno escalar com uma pequena quantidade de informações no problema e dessas informações na tarefa para obter tudo o que você precisa.
Problemas Idempotentes
Os desenvolvedores de aipo recomendam essa abordagem. Quando a seção de código é repetida, nenhum efeito colateral deve ocorrer, o resultado deve ser o mesmo. Isso nem sempre é fácil de conseguir, especialmente se houver uma interação com muitos serviços ou confirmações de duas fases.
Mas quando você faz tudo localmente, sempre pode verificar se os dados recebidos existem e são relevantes, pode realmente trabalhar com eles e usar transações. Se houver muitas consultas no banco de dados para uma tarefa e algo puder dar errado no tempo de execução, use transações para reverter alterações desnecessárias.
Compatibilidade com versões anteriores
Tivemos alguns efeitos colaterais interessantes quando implantamos o aplicativo. Independentemente do tipo de implantação usada (atualização azul + verde ou contínua), sempre haverá uma situação em que o código de serviço antigo cria mensagens para o novo código do trabalhador e vice-versa, o trabalhador antigo recebe mensagens do novo código de serviço, porque foi lançado “primeiro” e lá o tráfego passou.
Detectamos erros e perdemos tarefas até aprendermos a manter a
compatibilidade com versões anteriores entre as versões . A compatibilidade com versões anteriores é que, entre os lançamentos, as tarefas devem funcionar com segurança, independentemente dos parâmetros que entram nessa tarefa. Portanto, em todas as tarefas, agora estamos fazendo uma assinatura "borracha" (** kwargs). Quando você precisar adicionar um novo parâmetro no próximo release, você o usará ** kwargs no novo release, mas não no antigo - nada será interrompido. Assim que a assinatura é alterada, e o Celery não sabe disso, ela falha e gera um erro de que não existe tal parâmetro na tarefa.
Uma maneira mais rigorosa de evitar esses problemas é a versão das filas de tarefas entre os lançamentos, mas é bastante difícil de implementar e a deixamos no backlog por enquanto.
Timeouts
Podem surgir problemas devido a números insuficientes ou tempos limite incorretos.
Não definir um tempo limite para uma tarefa é ruim. Isso significa que você não entende o que está acontecendo na tarefa, como a lógica de negócios deve funcionar.
Portanto, todas as nossas tarefas são interrompidas com tempos limite, incluindo globais para todas as tarefas, e também são definidos tempos limite para cada tarefa específica.
Deve ser afixado: soft_limit_timeout e
expira.Expira é quanto uma tarefa pode viver na linha. É necessário que as tarefas não se acumulem nas filas em caso de problemas. Por exemplo, se agora queremos relatar algo ao usuário, mas algo aconteceu, e a tarefa pode ser concluída apenas amanhã - isso não faz sentido, amanhã a mensagem não será mais relevante. Portanto, para notificações, expiramos razoavelmente pequenos.
Observe o uso de
eta (contagem regressiva) + visibilidade _timeout . As perguntas frequentes descrevem esse problema com o Redis - o chamado tempo limite de visibilidade do broker Redis. Por padrão, seu valor é de uma hora: se após uma hora o trabalhador vê que ninguém levou a tarefa para execução, ele a adiciona novamente à fila. Portanto, se a contagem regressiva for de duas horas, após uma hora, o broker descobrirá que essa tarefa ainda não foi concluída e criará outra da mesma. E em duas horas, duas tarefas idênticas serão concluídas.
Se o tempo estimado ou a contagem regressiva exceder 1 hora, provavelmente o uso do Redis resultará na duplicação de tarefas, a menos que, é claro, você tenha alterado o valor visible_timeout nas configurações de conexão com o broker.
Política de Repetição
Para as tarefas que podem ser repetidas ou que podem falhar, usamos a política de Repetir. Mas nós o usamos com cuidado para não sobrecarregar os serviços externos. Se você repetir rapidamente as tarefas sem especificar um retorno exponencial, um serviço externo, ou talvez interno, pode simplesmente não suportá-lo.
Os parâmetros
retry_backoff ,
retry_jitter e
max_retries seriam bons para especificar explicitamente, especialmente max_retries. retry_jitter - um parâmetro que permite trazer um pouco de caos para que as tarefas não comecem a se repetir ao mesmo tempo.
Vazamentos de memória
Infelizmente, os vazamentos de memória são muito fáceis e é difícil encontrá-los e corrigi-los.
Em geral, trabalhar com memória em Python é muito controverso. Você gastará muito tempo e nervosismo para entender por que o vazamento ocorre e, em seguida, acontece que ele não está no seu código. Portanto, sempre, ao iniciar um projeto, coloque um
limite de memória no worker : worker_max_memory_per_child.
Isso garante que o OOM Killer não chegue um dia, não mate todos os trabalhadores e você não perca todas as tarefas. O aipo reiniciará os trabalhadores quando necessário.
Tarefas prioritárias
Sempre há tarefas que devem ser concluídas antes de todos, mais rápido que qualquer outra pessoa - elas devem ser concluídas agora mesmo! Existem tarefas que não são tão importantes - que sejam concluídas durante o dia. Para isso, a tarefa possui um parâmetro de
prioridade. No Redis, ele funciona de maneira bastante interessante - uma nova fila é criada com um nome no qual a prioridade é adicionada.
Utilizamos uma abordagem diferente -
separar trabalhadores para prioridades , ou seja, à moda antiga, criamos trabalhadores de aipo com diferentes "importância":
celery multi start high_priority low_priority -c:high_priority 2 -c:low_priority 6 -Q:high_priority urgent_notifications -Q:low_priority emails,urgent_notifications
O Celery multi start é um auxiliar que ajuda você a executar toda a configuração do Celery em uma máquina e na mesma linha de comando. Neste exemplo, criamos nós (ou trabalhadores): high_priority e low_priority, 2 e 6 são simultaneidade.
Dois trabalhadores de alta prioridade processam constantemente a fila de notificações urgentes. Ninguém mais aceitará esses trabalhadores, eles apenas lerão tarefas importantes da fila de urgências.
Para tarefas sem importância, há uma fila de baixa prioridade. Existem 6 trabalhadores que recebem mensagens de todas as outras filas. Também inscrevemos trabalhadores de baixa prioridade em notificações urgentes, para que possam ajudar se os trabalhadores de alta prioridade não puderem lidar com isso.
Usamos esse esquema clássico para priorizar tarefas.
Extrair, transformar, carregar
Na maioria das vezes, o ETL se parece com uma cadeia de tarefas, cada uma das quais recebe entrada da tarefa anterior.
@task def download_account_data(account_id) … return account_id @task def process_account_data(account_id, processing_type) … return account_data @task def store_account_data(account_data) …
O exemplo tem três tarefas. O aipo tem uma abordagem para o processamento distribuído e vários utilitários úteis, incluindo a função de
cadeia , que faz um pipeline de três dessas tarefas:
chain( download_account_data.s(account_id), process_account_data.s(processing_type='fast'), store_account_data.s() ).delay()
O aipo desmontará o pipeline, executará a primeira tarefa em ordem, depois transferirá os dados recebidos para o segundo e os dados que a segunda tarefa retornará para a terceira. É assim que implementamos pipelines simples de ETL.
Para cadeias mais complexas, é necessário conectar lógica adicional. Mas é importante ter em mente que, se um problema surgir nessa cadeia em uma tarefa,
toda a cadeia desmoronará . Se você não deseja esse comportamento, lide com a exceção e continue a execução ou pare toda a cadeia por exceção.
De fato, essa cadeia dentro parece uma grande tarefa, que contém todas as tarefas com todos os parâmetros. Portanto, se você abusar do número de tarefas na cadeia, obterá um consumo de memória muito alto e uma lentidão no processo geral.
Criar cadeias de milhares de tarefas é uma má ideia.Processamento de tarefas em lote
Agora, a coisa mais interessante: o que acontece quando você precisa enviar um email para dois milhões de usuários.
Você escreve essa função para ignorar todos os usuários:
@task def send_report_emails_to_users(): for user_id in User.get_active_ids(): send_report_email.delay(user_id=user_id)
No entanto, na maioria das vezes a função receberá não apenas a identificação do usuário, mas também lavará toda a tabela de usuários em geral. Cada usuário terá sua própria tarefa.
Existem vários problemas nesta tarefa:
- As tarefas são iniciadas seqüencialmente, ou seja, a última tarefa (dois milhões de usuários) será iniciada em 20 minutos e, talvez, por esse tempo limite já funcione.
- Todo o ID do usuário é carregado primeiro na memória do aplicativo e, em seguida, na fila - delay () executará 2 milhões de tarefas.
Eu chamei de inundação de tarefas, o gráfico se parece com isso.
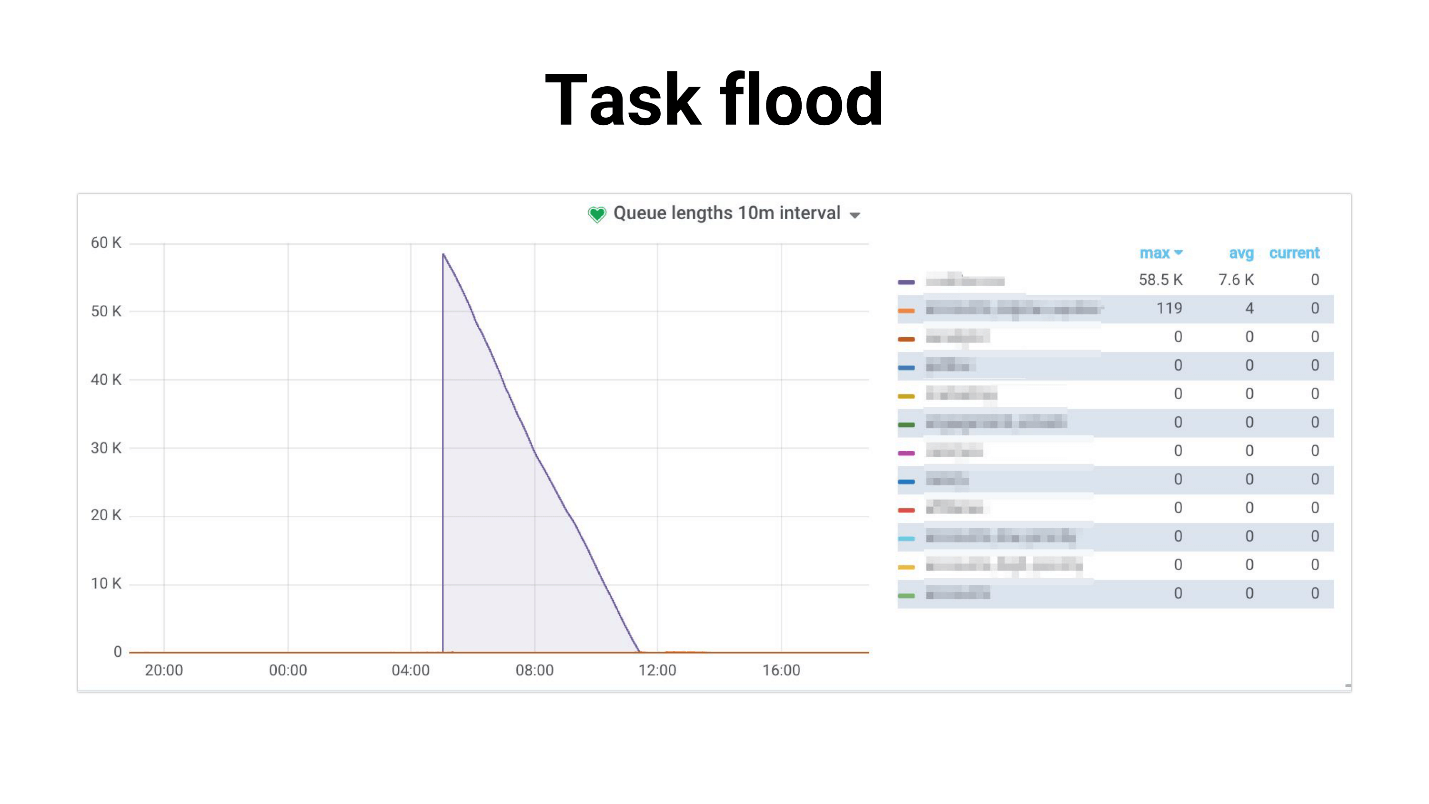
Há um afluxo de tarefas que os trabalhadores começam lentamente a processar. O seguinte acontece se as tarefas usam uma réplica master, todo o projeto começa a quebrar, nada funciona. Abaixo está um exemplo de nossa prática, em que o uso da CPU do banco de dados foi de 100% por várias horas, para ser sincero, conseguimos ficar com medo.

O problema é que o sistema está bastante degradado com um aumento no número de usuários. A tarefa que lida com o planejamento:
- requer mais e mais memória;
- corre mais tempo e pode ser "morto" por tempo limite.
Ocorre inundação de tarefas: as tarefas se acumulam nas filas e criam uma grande carga não apenas nos serviços internos, mas também nos externos.
Tentamos
reduzir a competitividade dos trabalhadores , isso ajuda em certo sentido - a carga no serviço é reduzida. Ou você pode
dimensionar serviços internos . Mas isso não resolverá o problema do gerador, que ainda leva muito. E de forma alguma afeta a dependência no desempenho de serviços externos.
Geração de tarefas
Decidimos seguir um caminho diferente. Na maioria das vezes, não precisamos executar todos os 2 milhões de tarefas no momento. É normal que o envio de notificações a todos os usuários leve, por exemplo, 4 horas se essas cartas não forem tão importantes.
Primeiro, tentamos usar o
Celery.chunks :
send_report_email.chunks( ({'user_id': user.id} for user in User.objects.active()), n=100 ).apply_async()
Isso não mudou a situação, porque, apesar do iterador, todo o user_id será carregado na memória. E todos os trabalhadores recebem uma cadeia de tarefas e, embora os trabalhadores relaxem um pouco, não ficamos satisfeitos com essa decisão no final.
Tentamos definir
rate_limit como workers para que eles processem apenas um certo número de tarefas por segundo, e descobrimos que, na verdade, rate_limit especificado como para a tarefa é rate_limit para o worker. Ou seja, se você especificar rate_limit para a tarefa, isso não significa que a tarefa será executada 70 vezes por segundo. Isso significa que o trabalhador executará 70 vezes por segundo e, dependendo do que você tem com os trabalhadores, esse limite pode mudar dinamicamente, ou seja, limite real rate_limit * len (trabalhadores).
Se o trabalhador iniciar ou parar, o total rate_limit será alterado. Além disso, se suas tarefas forem lentas, toda a pré-busca na fila que preenche o trabalhador ficará obstruída com essas tarefas lentas. O trabalhador parece: “Ah, eu tenho essa tarefa no rate_limit, não posso mais realizá-la. E todas as tarefas a seguir na fila são exatamente as mesmas - deixe-as travar! ” - e esperando.
Chunkificator
No final, decidimos escrever nossa própria e criamos uma pequena biblioteca, chamada Chunkificator.
@task @chunkify_task(sleep_timeout=...l initial_chunk=...) def send_report_emails_to_users(chunk: Chunk): for user_id in User.get_active_ids(chunk=chunk): send_report_email.delay(user_id=user_id)
Leva sleep_timeout e initial_chunk e chama a si próprio com um novo pedaço. Chunk é uma abstração sobre listas inteiras ou sobre listas de data ou data e hora. Passamos um pedaço para uma função que recebe usuários apenas com esse pedaço e executa tarefas apenas para esse pedaço.
Portanto, o gerador de tarefas executa apenas o número de tarefas necessárias e não consome muita memória. A imagem ficou assim.

O destaque é que usamos partes esparsas, ou seja, usamos instâncias no banco de dados como identificação de parte (algumas delas podem ser ignoradas, portanto, pode haver menos tarefas). Como resultado, a carga ficou mais uniforme, o processo ficou mais longo, mas todos estão vivos e bem, a base não está sobrecarregada.
A biblioteca é implementada para Python 3.6+ e está disponível no GitHub. Pretendo corrigir uma nuance, mas por enquanto o datetime-chunk precisa de um serializador de pickles - muitos não serão capazes de fazer isso.
Algumas perguntas retóricas - de onde veio toda essa informação? Como descobrimos que tínhamos problemas? Como você sabe que um problema logo se tornará crítico e você precisa começar a resolvê-lo?
A resposta é, obviamente, o monitoramento.
Monitoramento
Eu realmente gosto de monitorar, gosto de monitorar tudo e manter meu dedo no pulso. Se você não mantiver o dedo no pulso, pisará constantemente no rake.
Perguntas padrão de monitoramento:
- A configuração atual do trabalhador / simultaneidade lida com a carga?
- Qual é a degradação do tempo de execução da tarefa?
- Quanto tempo as tarefas ficam na fila? De repente a fila já está cheia?
Tentamos várias opções. O aipo tem uma interface
CLI , é bastante rico e fornece:
- inspecionar - informações sobre o sistema;
- controle - gerencie as configurações do sistema;
- purgar - limpar filas (força maior);
- events - UI do console para exibir informações sobre as tarefas que estão sendo executadas.
Mas é difícil realmente monitorar alguma coisa. É mais adequado para babados locais, ou se você deseja alterar algum rate_limit no tempo de execução.
Nota: você precisa acessar o intermediário de produção para usar a interface CLI.
O Aipo Flor permite que você faça a mesma coisa que a CLI, apenas através da interface da web, e isso não é tudo. Mas ele cria alguns gráficos simples e permite alterar as configurações em tempo real.
Em geral, o Aipo Flor é adequado apenas para ver como tudo funciona em pequenas configurações. Além disso, ele suporta a API HTTP, o que é conveniente se você estiver escrevendo automação.
Mas decidimos
por Prometeu. Eles pegaram o
exportador atual: vazamentos fixos de memória; métricas adicionadas para tipos de exceção; métricas adicionadas para o número de mensagens nas filas; Integrado com alertas no Grafana e se alegrar. Também está publicado no GitHub, você pode vê-lo
aqui .
Exemplos em Grafana

Estatísticas acima para todas as exceções: quais exceções para quais tarefas. Abaixo está o tempo para concluir as tarefas.

O que falta no aipo?
Esta é uma estrutura frondosa, tem muitas coisas, mas estamos perdendo! Não há recursos pequenos suficientes, como:
- Recarregar automaticamente o código durante o desenvolvimento - não suporta este aipo - reinicie.
- As métricas para Prometheus estão prontas para uso, mas Dramatiq pode.
- Suporte para bloqueio de tarefas - para que apenas uma tarefa seja executada por vez. Você pode fazer isso sozinho, mas Dramatiq e Tasktiger têm um decorador conveniente que garante que todas as outras tarefas do mesmo tipo sejam bloqueadas.
- Limite de taxa para uma tarefa - não para o trabalhador.
Conclusões
Apesar do Celery ser um framework que muitos usam na produção, ele consiste em 3 bibliotecas - Celery, Kombu e Billiard. Todas essas três bibliotecas são desenvolvidas por co-desenvolvedores e podem liberar uma dependência e interromper seu assembly.
Portanto, espero que você já tenha resolvido de alguma forma e tenha tornado suas assembléias determinísticas.
De fato, as conclusões não são tão tristes.
O aipo lida com suas tarefas em nosso projeto fintech sob nossa carga. Adquirimos experiência que compartilhei com você, e você pode aplicar nossas soluções ou refiná-las e também superar todas as suas dificuldades.
Não esqueça que o
monitoramento deve ser uma parte essencial do seu projeto . Somente através do monitoramento você pode descobrir onde há algo errado, o que precisa ser corrigido, adicionado, corrigido.
Orador de contato Oleg Churkin :
Bahusss ,
facebook e
github .
O próximo grande Moscow Python Conf ++ será realizado em Moscou no dia 5 de abril . Este ano, tentaremos ajustar todos os benefícios em um dia em um modo experimental. Não haverá menos relatórios; alocaremos um fluxo inteiro para desenvolvedores estrangeiros de bibliotecas e produtos conhecidos. Além disso, sexta-feira é um dia ideal para festas depois, o que, como você sabe, é parte integrante da conferência sobre comunicação.
Participe da nossa conferência profissional em Python - envie seu relatório aqui , reserve seu ingresso aqui . Enquanto isso, os preparativos estão em andamento, artigos sobre o Moscow Python Conf ++ 2018 aparecerão aqui.