Todos nós escrevemos código. Muito código. Claro, há erros. Às vezes, é apenas um código torto, e às vezes o preço de um erro é uma
nave espacial explodida. Obviamente, ninguém faz batidas intencionais, todos tentam monitorar a qualidade da melhor maneira possível, mas sem ferramentas de análise estática, dificilmente é possível ter certeza de que tudo está perfeito.
Os linters ajudam a trazer o código para um único estilo e evitam erros. É verdade, apenas se você estiver pronto para sofrer e, no final, não descartar "pylint: disable", apenas para ficar para trás. O que deveria ser um linter, e por que Pylint não pode fazer isso, conhece Nikita
Sobolevn , que entende e ama tanto os
linters que até nomeou sua empresa para não incomodá-los - wemake.services.
Abaixo está a versão em texto do relatório sobre o
Moscow Python Conf ++ sobre linters, como fazê-los corretamente e como não fazê-lo. A apresentação teve muita interatividade, online e comunicação com o público. O orador, ao longo do caminho, conduziu pesquisas e tentou convencer o público: ele olhou para a tendência e, como no debate, tentou igualar a proporção e mudar a opinião pública. Uma parte das pesquisas caiu em descriptografia, mas não todas, então um vídeo é anexado para completar a imagem.
Por que precisamos de linters?
A tarefa mais importante do linter é
trazer o código para a uniformidade . Existem muitas opções para escrever a mesma coisa no Python: coloque uma vírgula aqui ou ali, esqueça de fechar os colchetes ou não. Quando as pessoas escrevem código por um longo tempo, torna-se uma colcha de retalhos de peças diferentes costuradas em momentos diferentes. É desagradável trabalhar com um cobertor desses, desencoraja a leitura do código, o que é muito ruim.
Linters tornam a vida mais fácil em uma revisão . Venho para a revisão de código e penso: “Eu não quero fazer isso! Agora haverá espaços extras e outras bobagens! ” Gostaria que outra pessoa preparasse um bom código e depois disso eu aprecio as grandes coisas conceituais.
Às vezes, olho para o código e acho que está tudo bem, e então vejo em alguma função muitas variáveis ou um erro que não prestei atenção. A automação encontraria esse erro, mas eu olhei. Para não cair nessas situações - eu uso o
linter - ele
encontra tudo o que está oculto e difícil de encontrar.O que são linters?
Os mais simples verificam apenas o estilo , por exemplo,
Flake8 . Até certo ponto, também preto, mas é um autoformer-linter.
Os linters testam a semântica mais difícil , e não apenas a estilística: o que você faz, por que e o vence nas mãos se você escreve com erros. Um bom exemplo é o
Pylint , que todos conhecemos, usamos e amamos. Eu chamo esses linters -
Melhores práticas . O terceiro tipo é a
verificação de tipo , esses linter estão um pouco afastados. A verificação de tipo no Python é nova, agora está sendo feita por duas plataformas concorrentes:
Mypy e
Pyre .
Como usar o linter?
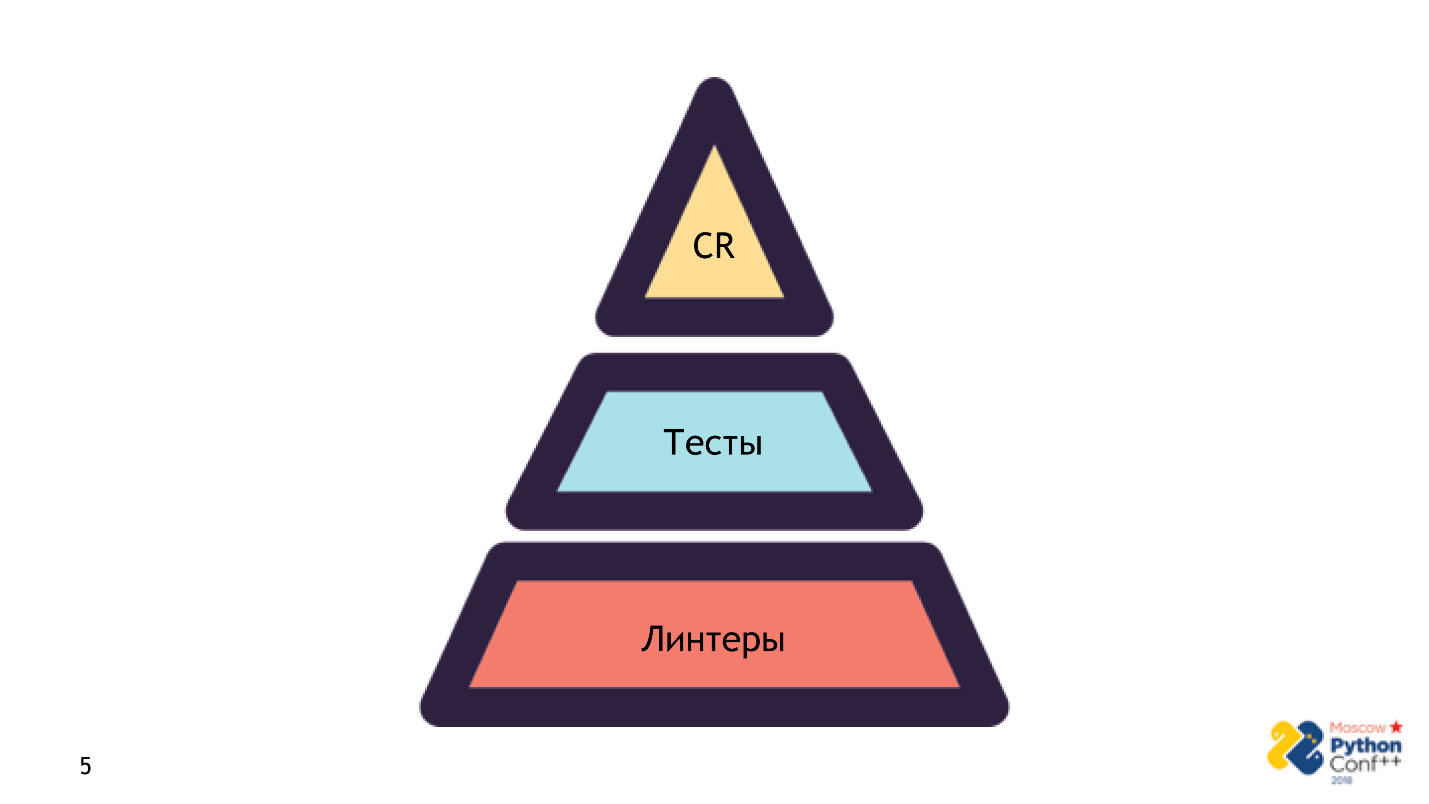
Não afirmo que o linter seja uma panacéia e um substituto para tudo. Isto não é verdade. Linter - o primeiro passo da pirâmide, pelo qual o código entra em produção.
Existem três etapas na pirâmide:
- Iniciar o linter . É muito rápido e não precisa de nada além do código fonte - sem infraestrutura, sem configurações. Verificação: a primeira verificação de sanidade passou - tudo está bem, estamos trabalhando.
- Estágio de teste . Esse processo é mais complicado e mais longo devido a erros que não são de código. Já precisaremos da configuração correta e completa de todo o aplicativo.
- Revisão de palco .
 Essas são as etapas necessárias
Essas são as etapas necessárias para o código entrar em produção. Se você não passou por uma etapa, esqueceu alguma coisa ou o revisor disse que não funcionaria, você verá a mensagem: falhou - o código incorreto não entra em produção.
Você usa um linter no trabalho?
Se você perguntar aos desenvolvedores de uma empresa severa, na qual trabalham 7 dias por semana, se usam um linter, acontece que pelo menos um terço deles usa linters de maneira muito rigorosa: o
IC cai, as verificações são severas . O restante aplica igualmente o linter
ao estilo de teste ,
nunca e como um
sistema de relatórios : eles iniciam o linter, geram um relatório e vêem como tudo está ruim. Linters são usados, e isso é bom. Em nossa empresa, tudo foi construído de maneira muito severa: vínculos físicos, muitas verificações, revisão dupla de código.
Revisão de código
Os problemas surgem exatamente nesta fase. Este é o passo mais difícil e mais difícil da pirâmide: a revisão de código não pode ser automatizada e, se possível, levará à automação da escrita do código. Então os programadores não serão necessários.
Por padrão, o processo se parece com o seguinte: o código entra para uma revisão, encontro erros e não quero mais fazê-los. Por exemplo, vi que o desenvolvedor capturou o BaseException: “Não faça isso. Por favor, não pegue! " Após 10 dias, a mesma coisa. Lembro novamente:
-
Nós não capturamos BaseException."
Bom, eu entendi."Um ano se passa - o mesmo erro. Um novo homem vem - o mesmo erro. Eu penso - como podemos automatizar tudo para que a situação não aconteça novamente, e só nos lembre: “
Vamos cortar nosso linter? »Vamos criar um pacote aberto, colocar lá todas as regras que usamos no trabalho e automatizar a verificação de regras, para que cada vez que não escrevamos à mão. Automatizamos tudo bem e imediatamente!
Naturalmente, você pode dizer: “
Linters prontos já existem, eles funcionam, todo mundo os usa - por que os próprios?”, E você estará absolutamente certo, porque existem realmente linters. Vamos ver quais e o que eles fazem.
Pylint
No cabeçalho "
Por que não Pylint?" "Eu ouvi essa pergunta muitas vezes. Eu responderei mais suavemente. O Pylint é uma ótima ferramenta de estrela do rock para código Python, mas possui recursos que eu não quero ver no meu linter.
Ele combina tudo: verificações estilísticas, práticas recomendadas e verificação de tipo . A verificação de tipo Pylint é subdesenvolvida porque não há informações de tipo: tenta exibi-la de alguma forma, mas não funciona muito bem. Portanto, frequentemente quando escrevo
model_name.some_property no Django, vejo o erro: "Desculpe, não existe essa propriedade - você não pode usá-la!" Lembro que existe um plugin, eu instalo, depois uso o Celery, também inicia algum tipo de problema, instalo o plugin para o Celery, uso alguma outra biblioteca mágica e, como resultado, escrevo em todos os lugares: “pylint: disable” ... Não é isso o que eu quero obter do linter.
Outro recurso oculto do usuário é
que o Pylint possui sua própria implementação da árvore de sintaxe Abstrata no Python . É assim que o código fica quando você o analisa e obtém informações sobre a árvore de nós que compõem o código. Eu realmente não confio em minhas próprias implementações, porque elas estão sempre erradas.
Além do Pylint, existem outros linters que também fazem seu trabalho.
Sonarquube
Uma ferramenta maravilhosa, mas separada, que mora em algum lugar próximo ao seu projeto.
- O SonarQube não poderá ser executado com freqüência : ele precisa ser implantado em algum lugar, assistir, monitorar, configurar.
- Está escrito em Java . Se você deseja consertar seu linter para Python, você escreverá código em Java. Eu acho que conceitualmente isso está errado - um desenvolvedor que possa escrever em Python deve ser capaz de escrever código para testar o Python.
A empresa que desenvolve o SonarQube analisa especificamente o conceito de desenvolvimento de produtos. Isso pode ser um problema.
A vantagem do SonarQube é que ele possui verificações muito interessantes que mostram complexidade, possíveis erros e erros ocultos. Gosto dos cheques, os deixaria e mudaria a plataforma.
Flake8
Um linter maravilhoso é muito simples, mas com um problema:
existem poucas regras pelas quais ele verifica quão bem o código é escrito. Ao mesmo tempo, o Flake8 possui muitos plugins muito simples: o plug-in mínimo é de 2 métodos que precisam ser implementados. Eu pensei - vamos tomar o Flake8 como base e escrever plugins, mas com nosso entendimento dos benefícios para a empresa. E assim fizemos.
O linter mais rigoroso do mundo
Criamos uma ferramenta na qual coletamos tudo o que achamos certo para o Python e chamamos
wemake-python-styleguide . O plug-in foi publicado publicamente, pois acredito que o
código-fonte aberto por padrão é uma boa prática . Estou profundamente convencido de que muitas ferramentas serão beneficiadas se forem carregadas no Open Source. Para o nosso instrumento, criamos o slogan:
"O linter mais rigoroso do mundo!"A palavra-chave em nosso linter é estrita, o que significa dor e sofrimento.
Se você usa o linter, e ele não o faz sofrer, então você aperta a cabeça: "Por que você não gosta, caramba?", Então este é um mau linter. Ignora erros, não monitora suficientemente a qualidade do código e não precisamos dele. Precisamos do mais rigoroso do mundo, o que verifica muito. Agora, temos cerca de
250 testes diferentes em ambas as categorias : estilística e práticas recomendadas, mas sem a verificação de tipo. Mypy está envolvido nisso, não o preocupamos de forma alguma.
Nosso linter
não tem
compromisso . Não temos regras da categoria "Eu não gostaria de fazer isso, mas se você realmente quiser, poderá." Não, sempre falamos severamente - não fazemos isso porque é ruim. Em seguida, as pessoas vêm e dizem: "Há 2,5 casos de uso em que isso é possível em princípio!". Se houver tais casos, escreva claramente que essa linha é permitida pelo linter ignorá-la, mas explique o porquê. Deve ser um comentário sobre por que você permitiu uma prática estranha e por que está fazendo isso. Essa abordagem também é útil para documentar código.
O linter mais rigoroso
não requer configurações (WIP) . Ainda temos configurações, mas queremos nos livrar delas: tendo liberdade, o usuário certamente irá configurar para que o linter não funcione corretamente.
Uma boa ferramenta não precisa de configurações - possui bons valores padrão.
Com essa abordagem, o código será consistente e funcionará da mesma maneira para todos, pelo menos em teoria. Ainda estamos trabalhando nisso e, enquanto houver configurações, você pode usar nossa ferramenta e personalizá-la por si mesmo.
De quem somos dependentes?
De um grande número de ferramentas.
- Flake8 .
- Eradicate é um plugin legal que encontra fragmentos comentados no código e faz com que você os exclua, porque armazenar código morto em um projeto é ruim. Não temos permissão para fazê-lo.
- O Isort é uma ferramenta que o força a classificar as importações corretamente: em ordem, recuando, citações bonitas.
- O Bandit é uma ótima ferramenta para verificar a segurança do código estaticamente. Ele encontra senhas com fio, uso desajeitado de
assert no código, chama Popen , sys.exit e diz que tudo isso não pode ser usado, mas se você quiser, ele pede para escrever o motivo. - E mais de 20 plugins que verificam colchetes, citações e vírgulas.
O que estamos verificando?
Existem 4 grupos de regras que usamos e aplicamos.
A complexidade é o maior problema. Não sabemos o que é complexidade e não a vemos no código. Observamos o código com o qual trabalhamos todos os dias e parece que não é complicado - pegue, leia, tudo funciona. Isto não é verdade. Código simples é um código familiar. A complexidade tem critérios claros que testamos. Sobre os próprios critérios - mais tarde. Se o código violar os critérios, dizemos: "O código é complexo, reescreva!"
Os nomes de variáveis são um problema de programação não resolvido. Quem vai ler quando e em que contexto não está claro. Tentamos tornar os nomes o mais consistente e compreensível possível, mas, embora tentemos, o problema ainda não foi totalmente resolvido.
Por
consistência , temos uma regra simples - escreva a mesma em todos os lugares. Se houver alguma abordagem aprovada, use-a em qualquer lugar. Não importa se você gosta ou não, a consistência é mais importante.
Tentamos usar apenas as
melhores práticas. Se sabemos que alguma prática não é muito boa, proibimos seu uso. Se o desenvolvedor quiser usar práticas proibidas, esperamos argumentos dele: por que e por que aplicar. Talvez, durante o processo de descrição, venha a entender por que isso é ruim.
O que é complexidade?
A complexidade tem métricas específicas que você pode analisar e dizer se é difícil ou não. Existem muitos deles.
Complexidade ciclomática - a complexidade ciclomática favorita de todos. Ele encontra no código um grande número de estruturas aninhadas
if ,
for outras estruturas, e indica muita ramificação do código e dificuldade na leitura. Tudo está ruim com o código incorporado: você lê, lê, lê - voltou, leu, leu, leu - pulou e depois entrou em outro ciclo. É impossível passar com segurança esse código de cima para baixo.
Argumentos, instruções e retornos. Essas são métricas quantitativas: quantos argumentos estão na função ou no método, quantos estão dentro do corpo dessa função ou no método de instruções e retornos.
Coesão e acoplamento são métricas populares de POO.
Coesão mostra a conexão da classe dentro. Por exemplo, há uma classe e, dentro de você, usam todos os métodos e propriedades - tudo o que você declarou. Esta é uma boa aula com alta conectividade interna.
Acoplamento é o quanto as diferentes partes do sistema estão conectadas: módulos e classes. Queremos alcançar conectividade máxima dentro da classe e conectividade mínima fora. Em seguida, o sistema é facilmente mantido e funciona bem.
Complexidade de Jones - peguei emprestada essa métrica, mas apenas porque é uma bomba! A complexidade de Jones determina a complexidade de uma linha - quanto mais complexa, mais difícil é entender, porque a memória humana de curto prazo não pode processar mais de 5 a 9 objetos de uma só vez. Essa é a chamada
carteira de Miller .
Examinamos essas métricas importantes e outras que são muito maiores e determinamos se o código é adequado ou não. No nosso entendimento, a
complexidade é uma cachoeira .
Dificuldade da cachoeira
A dificuldade começa com o fato de termos escrito a linha e ainda é boa. Mas então a empresa chega e diz que os preços dobraram e nós multiplicamos por 2. Nesse momento, a Jones Complexity enlouquece e relata que agora a linha é muito complicada - há muita lógica.
Bem, começamos uma nova variável, e o analisador de complexidade da função diz:
-
Não, não é assim - agora existem muitas variáveis dentro da função.Farei um novo
método e passarei argumentos para ele. Agora, verificar o número de argumentos da função ou o número de métodos dentro da
classe diz que isso também é impossível - a classe é muito complexa e deve ser dividida em duas partes. Falhando ao destacar outra classe. Agora, existem mais classes e tudo está bem, mas a verificação da complexidade do
módulo informa que o módulo agora é muito complexo e precisa ser refatorado. Porquê ?!
Isso se chama sofrimento. É por isso que digo que um linter deve fazer você sofrer. Começamos multiplicando por 2 em uma linha e acabamos
refatorando todo o sistema . Adicionar um pequeno pedaço de código leva à refatoração de módulos inteiros, porque a complexidade se espalha como uma cascata e cobre tudo o que é possível.
"Precisa refatorar" - isso faz você refatorar o código. Você não pode simplesmente ficar sentado: "Eu não toco esse código, parece funcionar". Não, um dia você mudará o código em outro lugar, e uma cascata de complexidade inundará o módulo que você não tocou e terá que refatorá-lo. Acredito que a refatoração é boa e, quanto mais, mais estável e melhor o seu sistema funciona.
E tudo o resto é subjetivo!Agora vamos falar sobre gostos. Esta é uma parte holística e interativa!
Holivar
Vamos apoiar, os comentários estão abertos. Primeiro, deixe-me lembrá-lo de que os nomes são um problema complexo e não resolvido. Você pode discutir como nomear uma variável, mas temos algumas abordagens que ajudam pelo menos a não cometer erros óbvios.
Nomes
Como você gosta:
var, valor, item, obj, dados, resultado ? O que são
dados ? Alguns dados. O que é
resultado ? Algum tipo de resultado. Muitas vezes, vejo a variável
resultado e uma chamada para algum método infernal em uma classe incompreensível - e penso: “Qual é esse resultado? Por que ele está aqui?
Muitos desenvolvedores discordam de mim e dizem que
valor é um nome de variável perfeitamente normal:
-
Eu sempre uso chave e valor!-
Por que não usar chave e valor, mas diga que a chave é o nome e o valor é o sobrenome? Por que é impossível nomear nome e sobrenome - agora existe um contexto.Geralmente as pessoas concordam, mas argumentam de qualquer maneira. Isso é uma coisa muito holística: pelo menos três pessoas passaram uma hora de sua vida comigo para discutir isso comigo.
É correto nomear variáveis com uma letra?
Por exemplo,
q ? Todos conhecemos o caso clássico:
for i in some_iterable: O que
eu sou ? Em C, essa é uma prática padrão e tudo vem dela. Mas em Python, coleções e iteradores. As coleções contêm elementos que têm nomes - vamos chamá-los de alguma maneira diferente.
Metade dos desenvolvedores acha que chamar variáveis i, x, y, z é normal.
Eu acredito que você não pode nomear nomes com uma letra. Quero mais contexto e é bom que a segunda metade dos desenvolvedores concorde comigo. Se em C isso ainda é permitido de alguma forma devido ao patrimônio histórico, então, em Python, esse é um problema muito grande e você não precisa fazer isso.
Consistência
Vamos apenas escolher uma maneira dentre muitas e dizer: "Vamos fazer isso". Se é bom ou ruim - não importa mais - é simplesmente consistente.
Estamos falando apenas de Python 3, o Legacy não é considerado.
Eu tenho um argumento: quando herdarmos de alguma coisa, deveríamos saber do que seria bom ver o nome do pai. O engraçado é que geralmente vemos o nome dos pais, exceto quando este é um
objeto . Portanto, formulei uma regra para mim: quando escrevo uma classe, herdo de algo - sempre escrevo o nome do pai. Não importa como será: modelo, objeto ou outra coisa.
Se houver uma opção para escrever
Class Some(object) ou
class Some , então eu escolherei a primeira. Por um lado, mostra que claramente sempre escrevemos do que herdamos. Por outro lado, não há
verbosidade específica: não perdemos nada com algumas teclas adicionais.
Dois terços dos desenvolvedores estão mais familiarizados com a segunda opção, e eu até sei o porquê. Minha hipótese: tudo porque há muito tempo migramos da segunda versão do Python para a terceira e agora mostramos que estamos escrevendo no terceiro Python. Não sei como a hipótese está correta, mas me parece que sim.
Linhas F são terríveis?
Opções de resposta:
- Sim: eles perdem o contexto, colocam lógica no modelo e não fiam - (38%).
- Não! Eles são um milagre! - (62%).
Existe uma hipótese de que as linhas f sejam terríveis. Eles enfiam qualquer coisa neles! As linhas f não são as mesmas que
.format , as diferenças são dramáticas. Quando declaramos um modelo e o formatamos, realizamos duas ações separadamente: primeiro, definimos o modelo e, em seguida, formatamos. Quando declaramos uma linha f, executamos duas ações simultaneamente: declaramos imediatamente o modelo e o formatamos no mesmo momento.
Existem dois problemas com as linhas f. Declaramos um modelo para a linha f e tudo funciona. E então decidimos mover as linhas do modelo 2 ou movê-lo para outra função - e tudo quebra.
Agora não há contexto que nos permita formatar seqüências de caracteres e não podemos processá-las corretamente. O segundo grande problema das linhas f: elas permitem que você faça a coisa terrível -
insira a lógica no modelo . Suponha que exista uma linha na qual simplesmente inserimos o nome de usuário e a palavra "Olá" - isso é normal. Não há nada particularmente terrível, mas depois vemos que o nome de usuário vem em maiúsculas, decidimos traduzi-lo para um caso de Título e escrevemos diretamente no modelo
username.title() . Em seguida, condições, ciclos, importações aparecem no modelo. E todas as outras partes do php.
Todos esses problemas me fazem dizer que
as linhas f são um tópico ruim , não as usamos. O engraçado é que não temos um caso em que apenas as linhas f sejam adequadas para nós. Normalmente, qualquer formatação é adequada, mas escolhemos
.format - tudo o mais é impossível - nem
% , nem f-lines. O trabalho de .format também
.format indicado, porque dentro dele você pode colocar aspas e escrever o nome da variável ou sua ordem.
Durante o relatório, o número de oponentes da linha f aumentou de 33 para 38% - essa é uma vitória pequena, mas positiva.
Os números
Você gosta de números como este:
final_score = 69 * previous result / 3.14 . Parece uma linha de código padrão, mas o que é 69? Tais perguntas geralmente surgem quando olho para o código que escrevi há algum tempo e o gerente naquele momento diz:
-
Por favor, multiplique por 147.-
Por que aos 147?-
Nós temos essas tarifas.Eu me multipliquei e esqueci, ou por muito tempo peguei algum valor do coeficiente para que tudo funcionasse - e então esqueci como o peguei e por quê. Acontece que importantes trabalhos de pesquisa permaneceram escondidos atrás de um número sem título. Eu nem sei qual é esse número, mas só consigo encontrá-lo, recuperá-lo e restaurá-lo de alguma forma, confirmando mais tarde
Por que não fazer isso de maneira diferente - coloque todos os números complexos em sua própria variável com o nome e a documentação? Por exemplo, para o número 69, escreva que este é o indicador médio no mercado e agora a constante tem um nome e um contexto. Vou escrever um comentário que tomei a constante no local desse estudo. Se a pesquisa mudar no futuro, irei atualizar os dados.
Assim, garantimos que nenhum número mágico passará pelo nosso código e o complicaria por dentro. Eles passam pela verificação da complexidade de cada linha e dizem: "Aqui está o número 4766. Não sei, resolva você mesmo!" Essa foi uma ótima descoberta para mim.
Como resultado, percebemos que precisamos seguir isso e não perdemos nenhum número mágico no código. É bom que quase 100% dos nossos colegas concordem conosco e também não usem esses números.
Mas há exceções - esses são números de -10 a 10, números 100, 1000 e similares, simplesmente porque são frequentemente encontrados e sem eles é difícil.
Somos durões, mas não sádicos e pensamos um pouco.
Você usa '@staticmethod'?
Vamos pensar sobre o que
é o
método estático . Você já se perguntou por que está em Python? Eu não Eu tinha um lindo Pylint que dizia:
-
Olha, você não está usando self ,
cls -
faça um método estático!-
Ok, Pylint, eu vou fazer um método estático.Depois, ensinei Python para iniciantes, e eles perguntaram o que é o método estático e por que é necessário. Eu não sabia a resposta e pensei se é possível escrever o mesmo com uma função ou não usar o
self em uma função regular, simplesmente porque é uma classe dessas e algo está acontecendo. Por que precisamos de uma construção de método static?
Pesquisei a pergunta no Google e ela acabou sendo tão profunda quanto uma toca de coelho. Existem muitas outras linguagens de programação nas quais o método static também não é apreciado. E bem fundamentado - o método static quebra o modelo de objeto. Como resultado, eu percebi - o
método estático não é o lugar aqui , e nós o cortamos. Agora, se usarmos o decorador staticmethod, o linter dirá: "Não, desculpe, refatorar!"
A maioria dos desenvolvedores discorda de mim, mas cerca da metade ainda pensa que é melhor escrever métodos ou funções regulares em vez do método static.
Lógica em __init __. Ru - bom ou ruim?
Este é o meu tópico favorito. Certamente, quando você cria um novo pacote e o chama de alguma forma - ele cria __init __. Ru e você quer saber o que colocar nele? O que colocar em __init __. Ru e o que - nos arquivos lado a lado? Para mim, essa era uma pergunta não trivial, e eu sempre estava perdido: provavelmente algo mais importante? Então pensei - não, pelo contrário, colocarei o mais importante no contexto mais compreensível. Se você colocar algo em __init __. Ru e depois importar tudo, as importações cíclicas também serão ruins.
Eu olhei para várias bibliotecas populares, subi o __init __. Ru e notei que basicamente há compatibilidade com versões anteriores ou com lixo. Para mim, essa questão surgiu bastante quando comecei a criar pacotes grandes com muitos subpacotes - você se perde. , . Python, , , __init__. , 90% .
— , API, , - , , ? , , . API . , __init__. - : , , .
,
I_CONTROL_CODE — . , . , , __init__. — . , , , - , .
hasattr ?
hasattr ? , , Python — . hasattr , ().
, , hasattr , , . , hasattr, , . - , Python -, hasattr . , .
getattr « , ». hasattr — getattr,
exception .
50 50 — , , .
,
layer-linter . ? : , , , . , - . - . .
cohesion . , . Cohesion , . False Positive , — , , .
vulture Python . - , Python , . ohesion.
Radon , :
Halstead ,
Maintainability Index , . , — .
Final type
Final- Python. Typing Extensions, , . , - , — , . , - - , ? Não precisa. . - — , , , .
Gratis
, .

, .
, . , . , Python- , .
, Moscow Python Conf++ , . , , Python-.
. . , , , .