Deve-se notar imediatamente que este artigo é apenas uma reflexão subjetiva sobre como o comportamento dos elementos da interface que sabem o que o usuário está fazendo em um determinado momento pode parecer e ser implementado. Os pensamentos, no entanto, são respaldados por um pouco de pesquisa e implementação. Vamos lá
No início da Internet, os sites não buscavam individualidade no estilo dos elementos básicos da interface. Como a variabilidade era pequena, as páginas eram bastante uniformes em seus componentes.
Cada link parecia um link, um botão como um botão e uma caixa de seleção como uma caixa de seleção. O usuário sabia a que sua ação levaria, porque tinha uma ideia clara do princípio de operação de cada elemento.
O link deve ser enviado para outra página, independentemente da origem do link, no menu de navegação ou no texto na descrição. O botão alterará o conteúdo da página atual, possivelmente enviando uma solicitação ao servidor. O estado da caixa de seleção, provavelmente, não afetará o conteúdo de nenhuma maneira, até pressionarmos o botão de alguma ação que use esse estado. Assim, bastava ao usuário olhar para o elemento da interface para entender com alto grau de probabilidade como interagir com ele e para o que ele levaria.
Sites modernos fornecem ao usuário um número muito maior de quebra-cabeças. Todos os links parecem completamente diferentes, botões não se parecem com botões e assim por diante. Para entender se uma linha é um link, o usuário deve passar o mouse sobre ela para ver a cor mudar para uma mais contrastante. Para entender se um elemento é um botão, também passamos o mouse para ver a alteração no tom de preenchimento. Com os elementos de vários menus, tudo também é complicado, alguns deles provavelmente expandirão um submenu adicional e outros não, embora externamente sejam idênticos.
No entanto, nos acostumamos rapidamente às interfaces que usamos regularmente e não estamos mais confusos na funcionalidade dos elementos. Um papel importante é desempenhado pela continuidade geral das interfaces. Tendo examinado a página acima, provavelmente perceberemos imediatamente que a seta amarela com as palavras "Localizar" não é apenas um elemento decorativo, mas um botão, embora não pareça um botão HTML padrão. Portanto, em termos de previsibilidade e personalidade, a maioria dos recursos chegou a um consenso estável aceito pelos usuários.
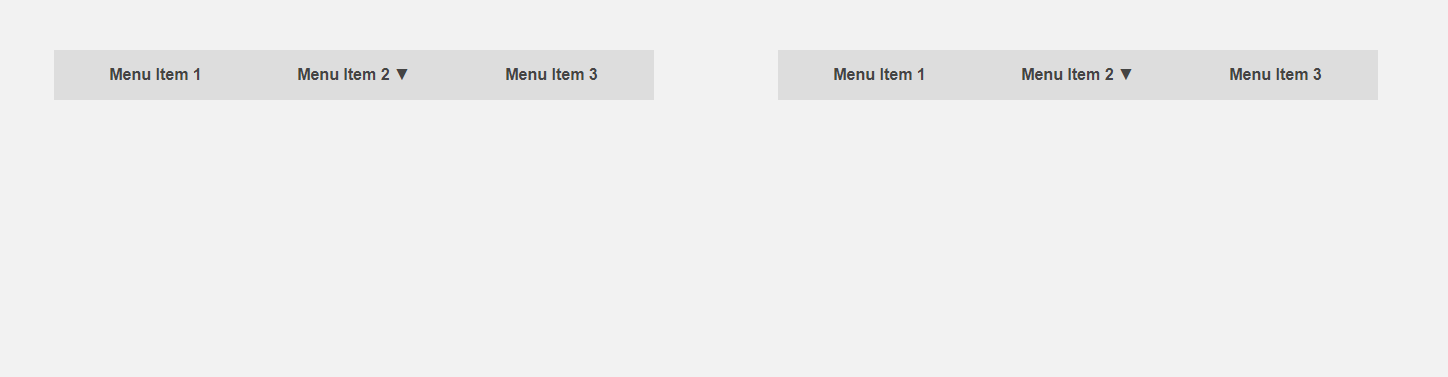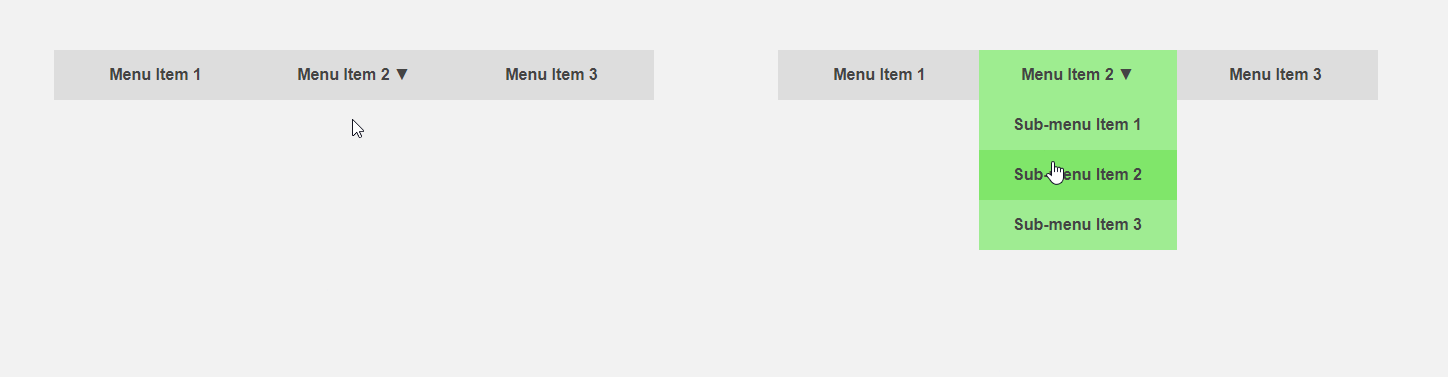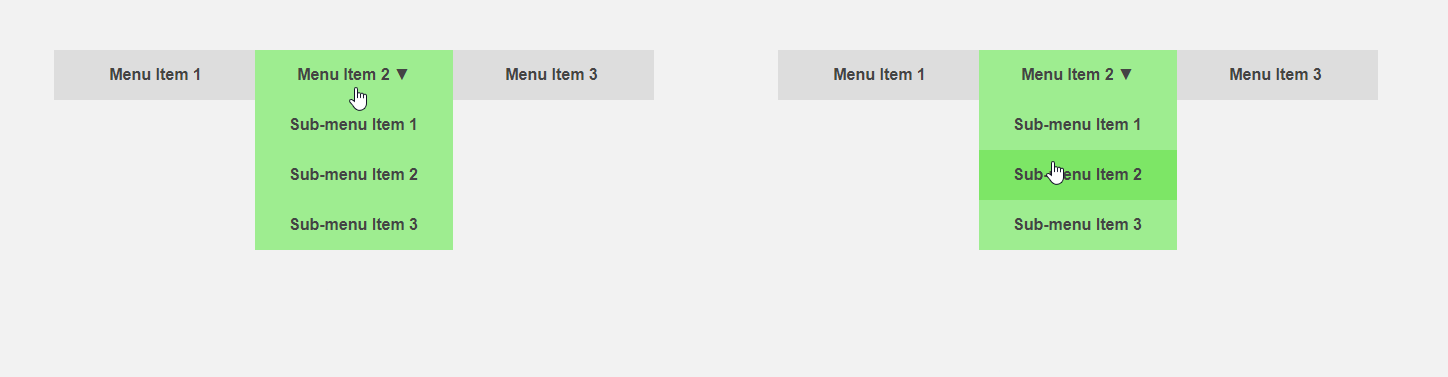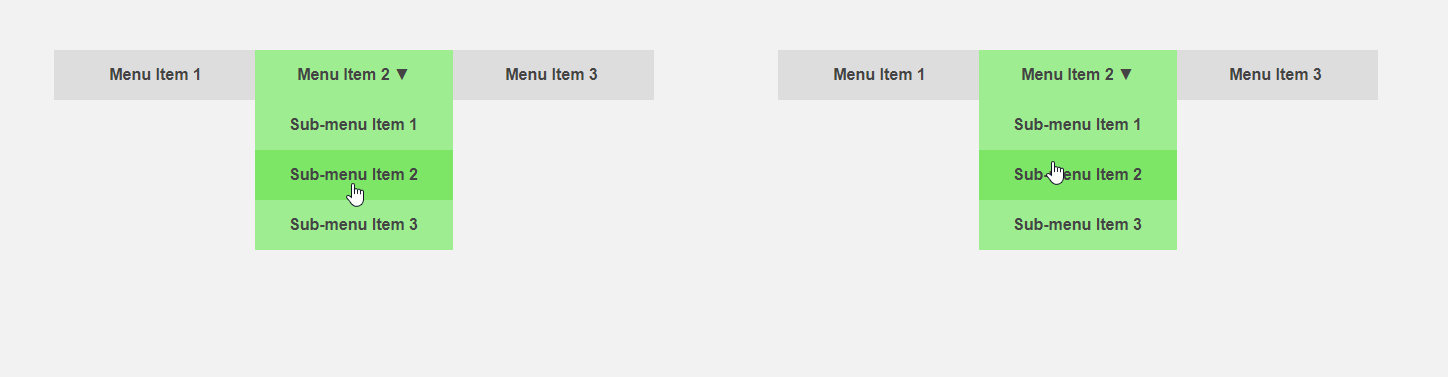
Por outro lado, seria interessante obter uma interface que informe ao usuário antecipadamente sobre as especificidades de um elemento ou faça parte da rotina de trabalho para ele. O cursor se move em direção ao item de menu - você pode expandir o submenu antecipadamente, acelerando a interação com a interface, o usuário move o cursor para o botão - você pode carregar conteúdo adicional necessário somente após clicar. O cabeçalho do artigo compara a interface padrão (esquerda) e preditiva.
Um teste visual simples mostra que, analisando a velocidade do cursor e suas derivadas, é possível prever a direção do movimento e as coordenadas da parada em um determinado número de etapas. Dado que os eventos de movimento são acionados com uma frequência constante em relação à magnitude da aceleração, a velocidade diminui ao se aproximar do alvo. Assim, você pode descobrir antecipadamente a ação planejada pelo usuário, o que leva aos benefícios já anunciados.

Assim, o problema inclui duas tarefas: determinar as coordenadas futuras do cursor e determinar as intenções do usuário (passe o mouse, clique, realce e assim por diante). Todos esses dados devem ser obtidos apenas com base na análise dos valores anteriores das coordenadas do cursor.
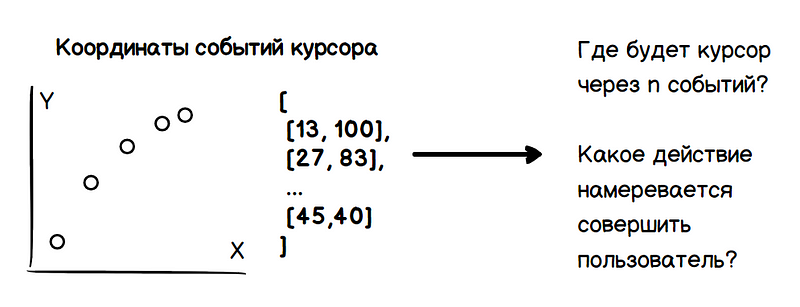
A tarefa principal é avaliar a direção do movimento do cursor em vez de prever o momento de parada, que é um problema mais complexo. Como estimativa dos parâmetros de uma quantidade barulhenta, o problema de calcular a direção do movimento pode ser resolvido por uma massa de métodos conhecidos.
A primeira opção que vem à mente é um filtro de
média móvel . Média da velocidade em momentos anteriores, você pode obter seu valor a seguir. Os valores anteriores podem ser ponderados de acordo com uma determinada lei (linear, exponencial, exponencial) para aumentar a influência dos estados mais próximos, reduzindo a contribuição de valores mais distantes.
Outra opção é usar um algoritmo recursivo, como
um filtro de partículas . Para avaliar a velocidade do cursor, o filtro cria muitas hipóteses sobre o valor atual da velocidade, também chamado de partículas. No momento inicial, essas hipóteses são completamente aleatórias, mas mais adiante, o filtro remove hipóteses inválidas e periodicamente, no estágio de redistribuição, gera novas baseadas em confiáveis. Assim, a partir do conjunto de hipóteses como resultado, apenas aquelas mais próximas ao verdadeiro valor da velocidade permanecem.
No exemplo abaixo, ao mover o cursor de cada partícula para visualização, o valor do raio é diretamente proporcional ao seu peso. Assim, a região com maior concentração de partículas pesadas caracteriza a direção mais provável do movimento do cursor.
No entanto, a direção de movimento obtida não é suficiente para determinar as intenções do usuário. Com uma alta densidade de elementos de interface, o caminho do cursor pode estar sobre muitos deles, o que levará a uma massa de falsos positivos do algoritmo de previsão. Aqui os métodos de aprendizado de máquina são úteis, nomeadamente redes neurais recorrentes.
As coordenadas do cursor são uma sequência de valores fortemente correlacionados. Quando o movimento é mais lento, a diferença entre as coordenadas das posições vizinhas na linha do tempo diminui de evento para evento. A tendência inversa é perceptível no início do movimento - os intervalos de coordenadas aumentam. Provavelmente, com precisão aceitável, esse problema também pode ser resolvido analiticamente examinando os valores das derivadas em diferentes partes do caminho e codificando o limite de resposta com base no comportamento desses valores. Mas, por sua natureza, a sequência de coordenadas das posições dos cursores parece um conjunto de dados que se encaixa bem com os princípios de operação de redes de memória de longo prazo e curto prazo.
As redes
LSTM são um tipo específico de arquitetura de redes neurais recorrentes, adaptadas ao treinamento de dependências de longo prazo. Isso é facilitado pela capacidade de armazenar informações pelos módulos de rede em vários estados. Assim, a rede pode identificar sinais com base, por exemplo, em quanto tempo o cursor diminuiu a velocidade, o que o precedeu, como a velocidade do cursor mudou no início da desaceleração e assim por diante. Esses sinais caracterizam padrões específicos de comportamento do usuário durante determinadas ações, por exemplo, clicando em um botão.
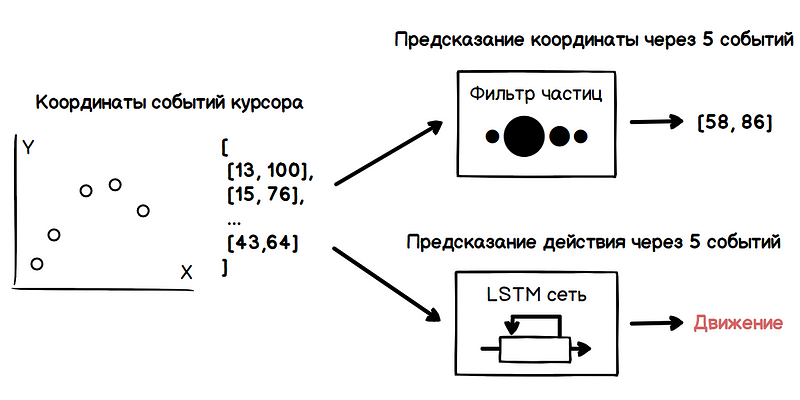
Assim, analisando continuamente os dados obtidos na saída do filtro de partículas e na rede neural, obtemos um momento em que, por exemplo, você pode mostrar um menu suspenso, enquanto o usuário move o cursor para ele para abri-lo no próximo segundo. Ao realizar essa análise para cada evento do mouse, é difícil perder o momento certo.
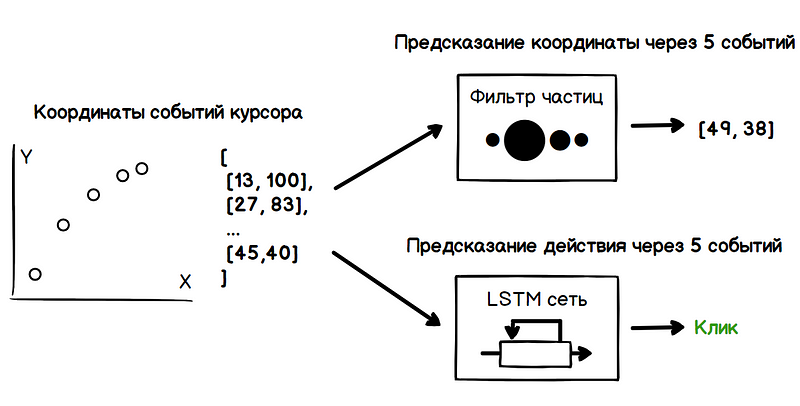
O treinamento em rede LSTM pode ser realizado em um conjunto de dados obtido durante a análise do comportamento do usuário, executando uma série de tarefas projetadas para identificar seus recursos ao interagir com a interface: clique no botão, mova o cursor sobre o link, abra o menu e assim por diante. A seguir, é apresentado um exemplo de acionamento de uma matriz de elementos preditivos baseados apenas em um filtro de partículas, sem análise de rede neural.

As animações abaixo demonstram a contribuição da rede neural para o processo de previsão do comportamento do usuário. Os falsos positivos se tornam muito menos.

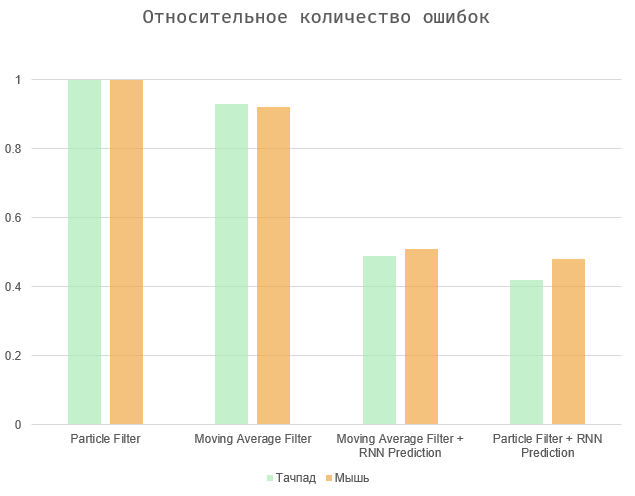
Em geral, a tarefa se resume ao equilíbrio entre duas quantidades - o período de tempo entre a ação e sua previsão e o número de erros (falsos positivos e omissões). Dois casos extremos são selecionar todos os elementos da página (o período máximo de previsão, um grande número de erros) ou fazer com que o algoritmo funcione imediatamente quando o usuário agir (período de previsão zero e erros ausentes).
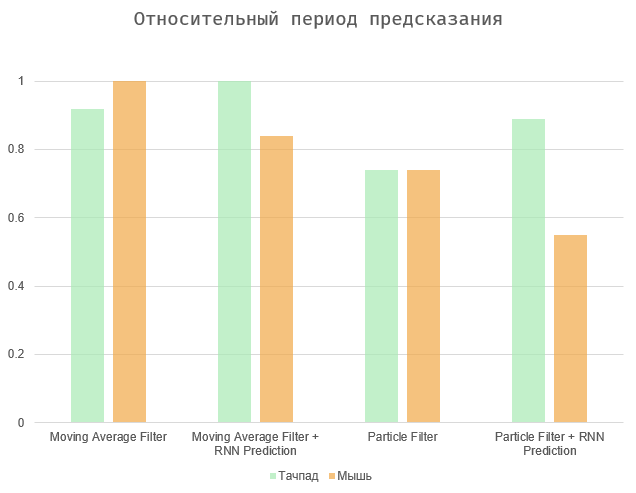
Os diagramas mostram os resultados normalizados para valores máximos, uma vez que a velocidade do usuário é puramente individual e o número de erros depende da interface em questão. Os algoritmos de média móvel e filtro de partículas mostram resultados aproximadamente semelhantes. O segundo é um pouco mais preciso, especialmente no caso de usar o touchpad. Por fim, todas essas opções podem ser altamente dependentes do usuário e dispositivo específicos.
Em conclusão, uma pequena demonstração do comportamento preditivo dos elementos HTML, longe do ideal, mas um pouco revelador.
Obviamente, nessas tarefas, é fundamental encontrar um equilíbrio entre funcionalidade e previsibilidade. Se o comportamento resultante não estiver claro para o usuário, a irritação causada anulará todos os esforços. É difícil discutir se é possível tornar o processo de aprendizado do algoritmo invisível para o usuário, por exemplo, nas primeiras sessões de sua comunicação com a interface da página, para que, usando os algoritmos treinados, faça com que os elementos da interface se comportem de forma preditiva. Em qualquer caso, será necessário treinamento adicional devido às características individuais de cada pessoa e esse é o assunto de pesquisas adicionais.