Boa noite
Do nosso curso
"Desenvolvedor C ++", oferecemos um pequeno e interessante estudo sobre algoritmos paralelos.
Vamos lá
Com o advento dos algoritmos paralelos no C ++ 17, você pode atualizar facilmente seu código de “computação” e se beneficiar da execução paralela. Neste artigo, quero considerar o algoritmo STL, que naturalmente revela a ideia de computação independente. Podemos esperar uma aceleração de 10x com um processador de 10 núcleos? Ou talvez mais? Ou menos? Vamos conversar sobre isso.
Introdução aos algoritmos paralelos
O C ++ 17 oferece uma configuração de diretiva de execução para a maioria dos algoritmos:
- sequenced_policy - tipo de política de execução, usada como um tipo exclusivo para eliminar a simultaneidade do algoritmo paralelo e o requisito de que a paralelização da execução do algoritmo paralelo é impossível: o objeto global correspondente é
std::execution::seq ; - parallel_policy - um tipo de política de execução usada como um tipo exclusivo para eliminar a sobrecarga do algoritmo paralelo e indica que a paralelização da execução do algoritmo paralelo é possível: o objeto global correspondente é
std::execution::par ; - parallel_unsequenced_policy - um tipo de política de execução usada como um tipo exclusivo para eliminar a sobrecarga do algoritmo paralelo e indicar que a paralelização e a vetorização da execução do algoritmo paralelo são possíveis: o objeto global correspondente é
std::execution::par_unseq ;
Resumidamente:
- use
std::execution::seq para execução seqüencial do algoritmo; - use
std::execution::par para executar o algoritmo em paralelo (geralmente usando alguma implementação de Pool de Threads); - use
std::execution::par_unseq para execução paralela do algoritmo com a capacidade de usar comandos vetoriais (por exemplo, SSE, AVX).
Como um exemplo rápido, chame
std::sort em paralelo:
std::sort(std::execution::par, myVec.begin(), myVec.end());
Observe como é fácil adicionar um parâmetro de execução paralela ao algoritmo! Mas será alcançada uma melhoria significativa no desempenho? Aumentará a velocidade? Ou há desacelerações?
Paralelo std::transformNeste artigo, quero prestar atenção ao algoritmo
std::transform , que pode ser a base para outros métodos paralelos (junto com
std::transform_reduce ,
for_each ,
scan ,
sort ...).
Nosso código de teste será construído de acordo com o seguinte modelo:
std::transform(execution_policy,
Suponha que a função
ElementOperation não possua métodos de sincronização; nesse caso, o código tem o potencial de execução paralela ou mesmo vetorização. Cada cálculo de elemento é independente, a ordem não importa, portanto, uma implementação pode gerar vários encadeamentos (possivelmente em um conjunto de encadeamentos) para processamento independente de elementos.
Eu gostaria de experimentar o seguinte:
- o tamanho do campo vetorial é grande ou pequeno;
- uma conversão simples que passa a maior parte do tempo acessando a memória;
- operações mais aritméticas (ALU);
- ALU em um cenário mais realista.
Como você pode ver, quero não apenas testar o número de elementos que são “bons” para usar o algoritmo paralelo, mas também as operações da ALU que ocupam o processador.
Outros algoritmos, como classificação, acumulação (na forma de std :: reduzem) também oferecem execução paralela, mas também exigem mais trabalho para calcular os resultados. Portanto, os consideraremos candidatos a outro artigo.
Nota de Referência
Para meus testes, eu uso o Visual Studio 2017, 15.8 - já que esta é a única implementação na popular implementação do compilador / STL no momento (novembro de 2018) (GCC a caminho!). Além disso, concentrei-me apenas na
execution::par , já que a
execution::par_unseq não
execution::par_unseq disponível no MSVC (funciona da mesma forma que na
execution::par ).
Existem dois computadores:
- i7 8700 - PC, Windows 10, i7 8700 - 3,2 GHz, 6 núcleos / 12 threads (Hyperthreading);
- i7 4720 - Computador portátil, Windows 10, i7 4720, 2,6 GHz, 4 núcleos / 8 threads (Hyperthreading).
O código é compilado em x64. Libere mais, a vetorização automática é ativada por padrão. Também incluí um conjunto estendido de comandos (SSE2) e OpenMP (2.0).
O código está no meu github:
github / fenbf / ParSTLTests / TransformTests / TransformTests.cppPara o OpenMP (2.0), eu uso paralelismo apenas para loops:
#pragma omp parallel for for (int i = 0; ...)
Eu corro o código 5 vezes e olho para os resultados mínimos.
Aviso : Os resultados refletem apenas observações aproximadas; verifique seu sistema / configuração antes de usá-lo na produção. Seus requisitos e arredores podem diferir dos meus.Você pode ler mais sobre a implementação do MSVC
nesta postagem . E
aqui está o último
relatório de Bill O'Neill com o CppCon 2018 (Bill implementou o Parallel STL no MSVC).
Bem, vamos começar com exemplos simples!
Conversão simplesConsidere o caso ao aplicar uma operação muito simples a um vetor de entrada. Pode ser a cópia ou multiplicação de elementos.
Por exemplo:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(), [](double v) { return v * 2.0; } );
Meu computador possui 6 ou 4 núcleos ... posso esperar uma execução sequencial 4..6x mais rápida? Aqui estão meus resultados (tempo em milissegundos):
| Operação | Tamanho do vetor | i7 4720 (4 núcleos) | i7 8700 (6 núcleos) |
|---|
| Execução :: seq | 10k | 0,002763 | 0,001924 |
| Execução :: par | 10k | 0,009869 | 0,008983 |
| openmp paralelo para | 10k | 0,003158 | 0,002246 |
| Execução :: seq | 100k | 0,051318 | 0,028872 |
| Execução :: par | 100k | 0,043028 | 0,025664 |
| openmp paralelo para | 100k | 0,022501 | 0,009624 |
| Execução :: seq | 1000k | 1,69508 | 0,52419 |
| Execução :: par | 1000k | 1.65561 | 0,359619 |
| openmp paralelo para | 1000k | 1,50678 | 0,344863 |
Em uma máquina mais rápida, podemos ver que serão necessários cerca de 1 milhão de elementos para perceber uma melhoria no desempenho. Por outro lado, no meu laptop todas as implementações paralelas eram mais lentas.
Portanto, é difícil perceber qualquer melhoria significativa no desempenho usando essas transformações, mesmo com um aumento no número de elementos.
Porque assim?
Como as operações são elementares, os núcleos do processador podem chamá-lo quase instantaneamente, usando apenas alguns ciclos. No entanto, os núcleos do processador gastam mais tempo aguardando a memória principal. Portanto, nesse caso, na maioria das vezes, eles aguardam, não fazem cálculos.
A leitura e gravação de uma variável na memória leva cerca de 2 a 3 ciclos se estiver em cache e várias centenas de ciclos se não estiver em cache.https://www.agner.org/optimize/optimizing_cpp.pdfVocê pode observar aproximadamente que, se o seu algoritmo depende da memória, não deve esperar melhorias de desempenho com a computação paralela.
Mais cálculosComo a largura de banda da memória é crucial e pode afetar a velocidade das coisas ... vamos aumentar a quantidade de computação que afeta cada elemento.
A idéia é que é melhor usar ciclos de processador em vez de perder tempo aguardando memória.
Para começar, uso funções trigonométricas, por exemplo,
sqrt(sin*cos) (estes são cálculos condicionais de forma não ideal, apenas para ocupar o processador).
Usamos
sqrt ,
sin e
cos , que podem levar ~ 20 por
sqrt e ~ 100 por função trigonométrica. Essa quantidade de computação pode cobrir o atraso de acesso à memória.
Para obter mais informações sobre atrasos da equipe, consulte o excelente
Perf Perf, de Agner Fogh .
Aqui está o código de referência:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(), [](double v) { return std::sqrt(std::sin(v)*std::cos(v)); } );
E agora o que? Podemos contar com uma melhoria de desempenho em relação à tentativa anterior?
Aqui estão alguns resultados (tempo em milissegundos):
| Operação | Tamanho do vetor | i7 4720 (4 núcleos) | i7 8700 (6 núcleos) |
|---|
| Execução :: seq | 10k | 0,105005 | 0,070577 |
| Execução :: par | 10k | 0,055661 | 0,03176 |
| openmp paralelo para | 10k | 0,096321 | 0,024702 |
| Execução :: seq | 100k | 1.08755 | 0.707048 |
| Execução :: par | 100k | 0,259354 | 0,17195 |
| openmp paralelo para | 100k | 0.898465 | 0.189915 |
| Execução :: seq | 1000k | 10.5159 | 7.16254 |
| Execução :: par | 1000k | 2,44472 | 1.10099 |
| openmp paralelo para | 1000k | 4,78681 | 1.89017 |
Finalmente, vemos bons números :)
Para 1000 elementos (não mostrados aqui), os tempos de cálculo paralelo e seqüencial foram semelhantes; portanto, para mais de 1000 elementos, vemos uma melhoria na versão paralela.
Para 100 mil elementos, o resultado em um computador mais rápido é quase 9 vezes melhor que a versão serial (da mesma forma que na versão OpenMP).
Na versão maior de um milhão de elementos, o resultado é 5 ou 8 vezes mais rápido.
Para esses cálculos, consegui uma aceleração "linear", dependendo do número de núcleos do processador. O que era de se esperar.
Fresnel e vetores tridimensionaisNa seção acima, usei cálculos "inventados", mas e o código real?
Vamos resolver as equações de Fresnel que descrevem a reflexão e a curvatura da luz de uma superfície lisa e plana. Este é um método popular para gerar iluminação realista em jogos 3D.
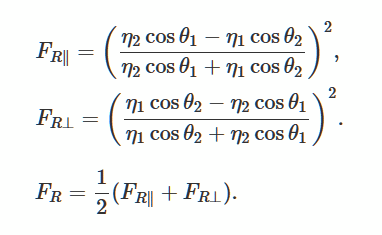
 Foto da Wikimedia
Foto da WikimediaComo um bom exemplo, encontrei
essa descrição e implementação .
Sobre o uso da biblioteca GLMEm vez de criar minha própria implementação, usei
a biblioteca glm . Costumo usá-lo em meus projetos OpenGl.
É fácil acessar a biblioteca através do
Conan Package Manager , então eu a usarei também.
Link para o pacote.
Arquivo Conan:
[requires] glm/0.9.9.1@g-truc/stable [generators] visual_studio
e a linha de comando para instalar a biblioteca (ela gera arquivos de suporte que eu posso usar em um projeto do Visual Studio):
conan install . -s build_type=Release -if build_release_x64 -s arch=x86_64
A biblioteca consiste em um cabeçalho, para que você possa baixá-lo manualmente, se desejar.
Código real e referênciaEu adaptei o código para glm do
scratchapixel.com :
O código usa várias instruções matemáticas, produto escalar, multiplicação, divisão, para que o processador tenha algo a fazer. Em vez do vetor duplo, usamos um vetor de 4 elementos para aumentar a quantidade de memória usada.
Referência:
std::transform(std::execution::par, vec.begin(), vec.end(), vecNormals.begin(),
E aqui estão os resultados (tempo em milissegundos):
| Operação | Tamanho do vetor | i7 4720 (4 núcleos) | i7 8700 (6 núcleos) |
|---|
| Execução :: seq | 1k | 0,032764 | 0,016361 |
| Execução :: par | 1k | 0,031186 | 0,028551 |
| openmp paralelo para | 1k | 0,005526 | 0,007699 |
| Execução :: seq | 10k | 0,246722 | 0,169383 |
| Execução :: par | 10k | 0,090794 | 0,067048 |
| openmp paralelo para | 10k | 0,049739 | 0,029835 |
| Execução :: seq | 100k | 2.49722 | 1,66968 |
| Execução :: par | 100k | 0.530157 | 0,283268 |
| openmp paralelo para | 100k | 0.495024 | 0,229609 |
| Execução :: seq | 1000k | 25/08/28 | 16,9457 |
| Execução :: par | 1000k | 5.15235 | 2,33368 |
| openmp paralelo para | 1000k | 5.11801 | 2,95908 |
Com a computação "real", vemos que algoritmos paralelos fornecem bom desempenho. Para essas operações em minhas duas máquinas Windows, alcancei uma aceleração com uma dependência quase linear do número de núcleos.
Para todos os testes, também mostrei resultados do OpenMP e duas implementações: MSVC e OpenMP funcionam de maneira semelhante.
ConclusãoNeste artigo, analisei três casos de uso de computação paralela e algoritmos paralelos. Substituir algoritmos padrão pela versão std :: Execution :: par pode parecer muito tentador, mas nem sempre vale a pena! Cada operação que você usa dentro do algoritmo pode funcionar de maneira diferente e depender mais do processador ou da memória. Portanto, considere cada alteração separadamente.
Coisas para lembrar:
- a execução paralela, geralmente, faz mais do que sequencial, pois a biblioteca deve se preparar para a execução paralela;
- não apenas o número de elementos é importante, mas também o número de instruções com as quais o processador está ocupado;
- é melhor executar tarefas independentes entre si e com outros recursos compartilhados;
- algoritmos paralelos oferecem uma maneira fácil de dividir o trabalho em threads separados;
- se suas operações dependem da memória, você não deve esperar melhorias no desempenho e, em alguns casos, os algoritmos podem ser mais lentos;
- Para obter uma melhoria de desempenho decente, sempre meça o tempo de cada problema; em alguns casos, os resultados podem ser completamente diferentes.
Agradecimentos especiais à JFT por ajudar com este artigo!
Também preste atenção às minhas outras fontes sobre algoritmos paralelos:
Dê uma olhada em outro artigo relacionado aos algoritmos paralelos:
Como aumentar o desempenho com Intel Parallel STL e C ++ 17 algoritmos paralelosO FIM
Estamos aguardando comentários e perguntas que você pode deixar aqui ou em nosso
professor na
porta aberta .