O compilador AOT otimizado geralmente é estruturado da seguinte maneira:
- frontend convertendo código fonte para representação intermediária
- pipeline de otimização independente de máquina (IR): uma sequência de passes que reescreve o IR para eliminar seções e estruturas ineficientes que não podem ser convertidas diretamente em código de máquina. Às vezes, essa parte é chamada de meio-termo.
- Back-end dependente de máquina para gerar código de montagem ou código de máquina.

Em alguns compiladores, o formato de IR permanece inalterado durante todo o processo de otimização; em outros, seu formato ou semântica é alterado. No LLVM, o formato e a semântica são fixos e, portanto, é possível executar passes em qualquer ordem, sem o risco de compilação incorreta ou falhas do compilador.
A sequência de passes de otimização foi desenvolvida pelos desenvolvedores do compilador, com o objetivo de concluir o trabalho em um tempo aceitável. Ele muda de tempos em tempos e, é claro, há um conjunto diferente de passes para executar em diferentes níveis de otimização. Um dos tópicos de longo prazo na pesquisa em computadores é o uso de aprendizado de máquina ou outros métodos para encontrar o melhor pipeline de otimização para uso geral e para aplicativos específicos para os quais o pipeline padrão não é adequado.
Os princípios de design das passagens são minimalismo e ortogonalidade: cada passagem deve fazer uma coisa bem, e sua funcionalidade não deve se sobrepor. Na prática, às vezes são possíveis compromissos. Na prática, quando duas passagens geram trabalho uma para a outra, elas podem ser combinadas em uma passagem maior. Além disso, algumas funcionalidades no nível de IR, como dobrar operadores constantes, são tão úteis que não faz sentido colocá-lo em uma passagem separada. O LLVM, por padrão, minimiza as operações constantes quando uma instrução é criada.
Neste post, veremos como algumas otimizações do LLVM funcionam. Quero dizer que você leu
esta parte sobre como o Clang compila a função ou que você entende mais ou menos como o LLVM IR funciona. Entender o formulário SSA (atribuição única estática) é especialmente útil: a
Wikipedia fornecerá uma introdução e
este livro fornecerá mais informações do que você gostaria de saber. Leia também a
Referência da linguagem LLVM e uma
lista de passes de otimização .
Vamos ver como o Clang / LLVM 6.0.1 otimiza esse código C ++:
bool is_sorted(int *a, int n) { for (int i = 0; i < n - 1; i++) if (a[i] > a[i + 1]) return false; return true; }
Ao mesmo tempo, lembramos que o pipeline de otimização é um local muito movimentado e vamos perder muitos momentos divertidos, como:
Inlining é uma otimização simples, mas muito importante, que não ocorre neste exemplo, porque consideramos apenas uma função. Quase todas as otimizações específicas para C ++, mas não para C. Vetorização automática, o que impede a saída antecipada do loop
No texto abaixo, ignorarei todas as passagens que não fizerem alterações no código. Além disso, não analisaremos o back-end, o que também dá muito trabalho. Mas até as passagens restantes são muitas! (Desculpe pelas fotos, mas esta parece ser a melhor maneira de evitar dificuldades de formatação).
Aqui está o arquivo IR criado por Clang (eu excluí manualmente o atributo “optnone” que Clang inseriu) e a linha de comando usada para ver o efeito de cada passo de otimização:
opt -O2 -print-before-all -print-after-all is_sorted2.ll
A primeira passagem é a
simplificação de CFG (gráfico de fluxo de controle). Como o Clang não realiza otimização, o IR que ele gera contém opções simples de otimização:

Aqui, a unidade base 26 simplesmente se move para o bloco 27. Esses blocos podem ser excluídos redirecionando referências a eles pelo bloco de destino. O LLVM renumerará automaticamente os blocos. A lista completa de conversões produzidas pelo SimplifyCFG está listada na parte superior do corredor.
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
A maioria das oportunidades para otimização do CFG aparece como resultado do trabalho de outros passes LLVM. Por exemplo, excluir a eliminação do código morto e mover invariantes de loop pode facilmente levar a blocos base vazios.
A próxima passagem,
SROA (substituição escalar de agregados), é uma das mais usadas. Seu nome gera confusão, porque o SROA é apenas uma de suas funções. O passe verifica cada instrução alloca (alocação de memória na pilha de funções) e tenta convertê-lo em registradores SSA. Uma instrução alloca (
que é, de fato, uma variável na pilha de aprox. Transl ..) se transforma em muitos registros se for atribuída estaticamente várias vezes e se alloca for uma classe ou estrutura, ela será dividida em componentes (denominada “escalar” substituição ”referida no nome da passagem). Uma versão simples do SROA renderia-se para empilhar variáveis para as quais a operação de obtenção de um endereço é usada, mas a versão LLVM interage com um algoritmo de análise de alias e age de maneira inteligente (embora isso não seja necessário no exemplo a seguir).

Após o SROA, as instruções alloca (e as instruções correspondentes de carregamento e armazenamento) desaparecem e o código se torna mais limpo e mais adequado para otimizações subsequentes (é claro, o SROA não pode excluir todo alloca no caso geral, isso só acontece se a análise do ponteiro se livrar completamente de pseudônimos). No processo, o SROA insere instruções phi no código. As instruções phi formam o núcleo da representação SSA, e a falta de phi no código que Clang gera nos diz que Clang gera uma versão trivial do SSA, na qual os blocos base são conectados através da memória e não através de registros SSA.
O que se segue é “
eliminação precoce precoce de subexpressão ”, CSE (remoção precoce de subexpressões comuns). O CSE tenta eliminar casos de subexpressões excessivas que podem ocorrer no código escrito por humanos e no código parcialmente otimizado. "Early CSE" é uma versão rápida e fácil do CSE que identifica cálculos redundantes triviais.

Aqui,% 10 e% 17 fazem a mesma coisa, ou seja, o código pode ser reescrito para que um valor seja usado e o segundo seja excluído. Isso fornece algumas informações sobre os benefícios do SSA: quando cada registro é atribuído apenas uma vez, não existem versões múltiplas de um único registro. Assim, cálculos redundantes podem ser detectados usando equivalência sintática, sem a análise aprofundada do programa (esse não é o caso dos locais de memória que existem fora do mundo da SSA).
Em seguida, são lançadas várias passagens que não têm efeito no nosso caso e, em seguida, o "
otimizador de variável global " é iniciado, descrito a seguir:
, . , , , , ..Esta passagem faz as seguintes alterações:
Ele adicionou um atributo de função: metadados usados por uma parte do compilador para armazenar informações sobre o que pode ser útil para outra parte do compilador. Você pode ler sobre a finalidade deste atributo
aqui .
Diferentemente de outras otimizações que consideramos, o otimizador de variáveis globais é interprocedural; ele analisa inteiramente o módulo LLVM. Um módulo é (mais ou menos) o equivalente a uma unidade de compilação em C e C ++. Em contraste com a otimização interprocedural, o intraprocedimento vê apenas uma função por vez.
A próxima passagem combina instruções e é chamada de "
combinador de instruções ", InstCombine. Essa é uma coleção grande e diversificada de
otimizações de
olho mágico , que (geralmente) reescrevem algumas instruções, combinadas por dados comuns, de uma forma mais eficiente. InstCombine não altera o fluxo de controle de uma função. No exemplo acima, ele não mudou muito:
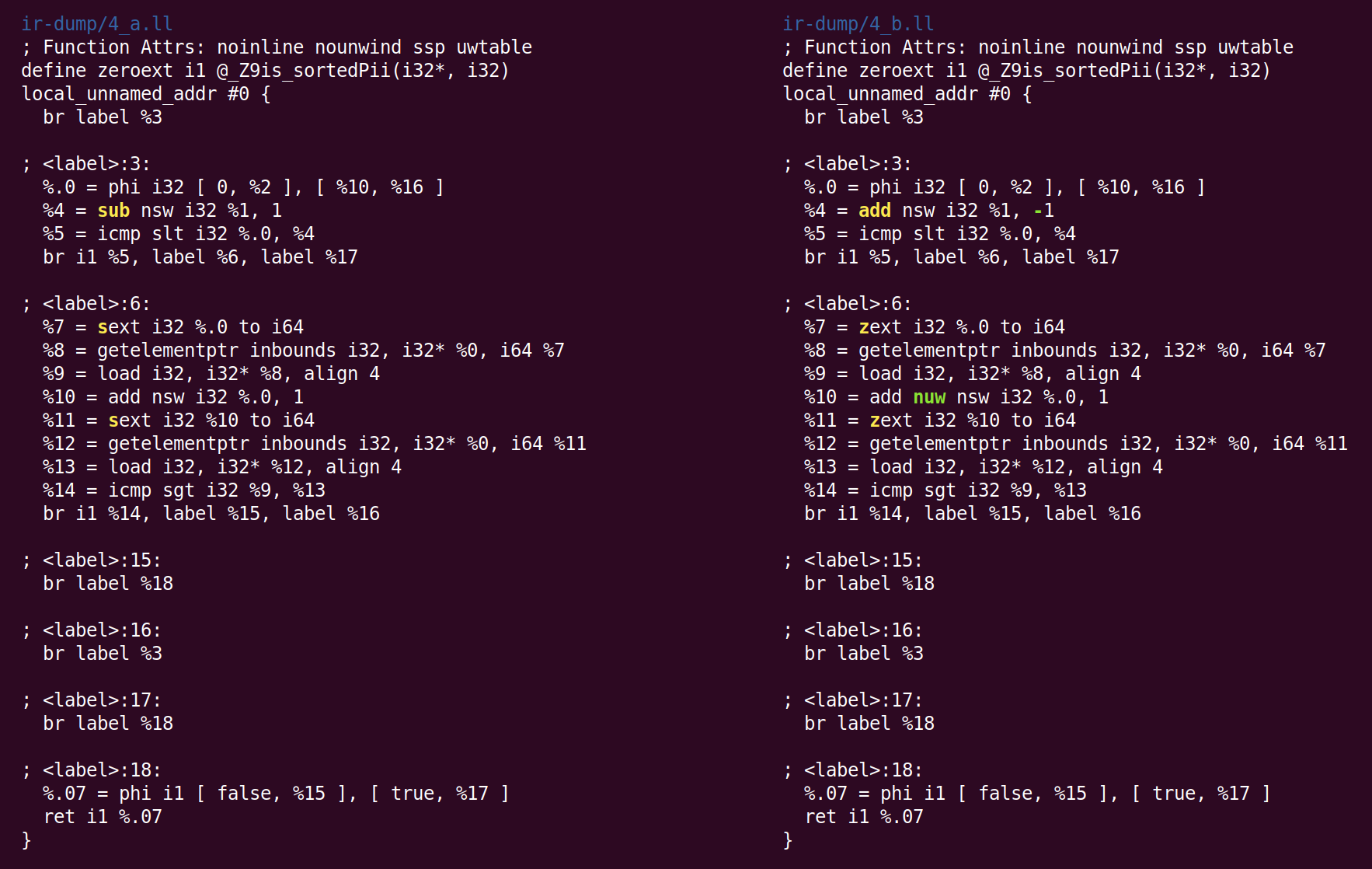
Aqui, em vez de subtrair 1 de% 1, para calcular% 4, adicionamos -1. Isso não é otimização, mas canonização. Quando existem muitas maneiras de fazer o cálculo, o LLVM tenta trazê-lo para a forma canônica (geralmente escolhida aleatoriamente) que passes e back-ends subsequentes esperam ver. A segunda alteração feita pelo InstCombine é a forma canônica de duas operações de expansão assinadas (a instrução sext), que calculam% 7 e% 11 convertidos em expansão zero (zext). Essa conversão é segura quando o compilador pode provar que o operando sext é não negativo. Nesse caso, isso ocorre porque a variável do loop muda de 0 para n (se n for negativo, o loop não será executado). A alteração mais recente foi a adição do sinalizador "nuw" (sem quebra automática não assinada) à instrução que calcula% 10. Podemos ver que isso é seguro, pois (1) a variável do loop sempre aumenta e (2) se a variável começa do zero e aumenta, ela fica indefinida quando o sinal muda na interseção INT_MAX antes de atingir um estouro sem sinal, seguindo UINT_MAX. Esse sinalizador pode ser usado para otimizações subsequentes.
Em seguida, o SimplifyCFG inicia pela segunda vez e remove dois blocos base vazios:
Em seguida, o passo “Deduzir atributos da função” anota a função:

“Norecurse” significa que a função não está incluída em nenhuma chamada recursiva, “somente leitura” significa que a função não altera o estado global. O atributo de parâmetro “nocapture” significa que o parâmetro não é salvo em nenhum lugar após a saída da função e “readonly” significa que a memória não é modificada pela função. Você pode ver uma
lista de atributos de função e
atributos de parâmetro .
Em seguida, o passe "
rodar loops " move o código na tentativa de melhorar as condições para otimizações subsequentes:

Embora a diferença pareça intimidadora, as mudanças são realmente pequenas. Podemos ver o que aconteceu, de uma maneira mais legível, se pedirmos ao LLVM para desenhar um gráfico de transferência de controle antes e depois de passar pelos ciclos de rotação. Aqui está a visão deles antes (esquerda) e depois (direita):
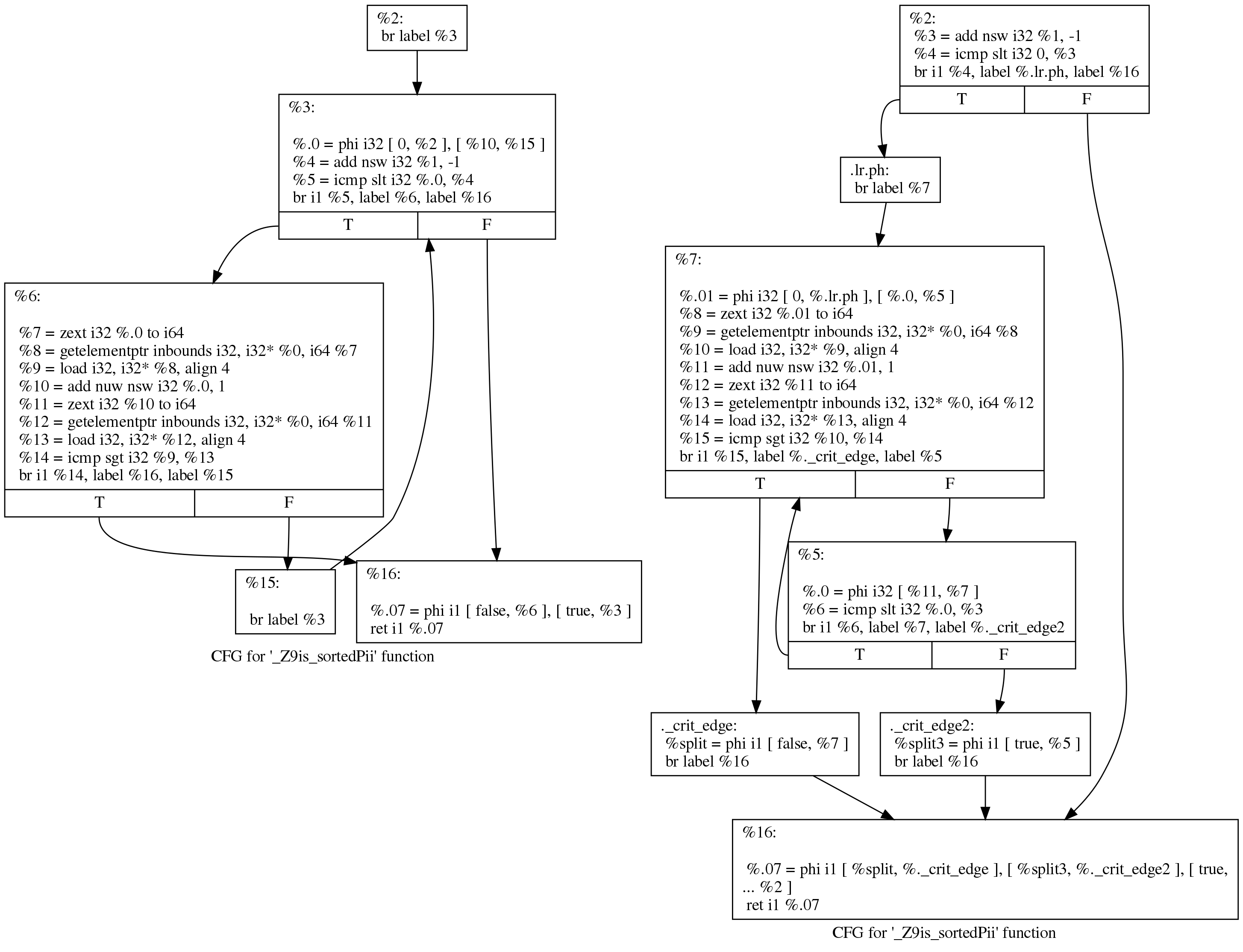
O código original ainda segue a estrutura do loop que Clang gerou:
initializer goto COND COND: if (condition) goto BODY else goto EXIT BODY: body modifier goto COND EXIT:
Após a execução, o loop fica assim:
initializer if (condition) goto BODY else goto EXIT BODY: body modifier if (condition) goto BODY else goto EXIT EXIT:
(As correções propostas por Johannes Durfert estão listadas abaixo - obrigado!)
O objetivo da passagem de rotação do loop é remover uma ramificação, o que permite otimizações adicionais. Não encontrei uma descrição melhor dessa conversão na Internet.
O passo de simplificação do CFG minimiza dois blocos básicos que contêm apenas instruções phi degeneradas (entrada única):

O passo do combinador de instruções transforma “% 4 = 0 s <(% 1 - 1)” em “% 4 =% 1 s> 1 ″ (onde s <e s> são operações para comparar operandos assinados), transformação útil, reduz o comprimento das cadeias de dependência e também pode criar instruções "inoperantes" (inatingíveis) (consulte o
patch que faz isso). Esse passe também remove as instruções triviais do phi que foram adicionadas pelo passe de rotação do loop.

A seguir, é apresentada a passagem “
canonicalize loops naturais ”, descrita em seu próprio código-fonte, da seguinte maneira:
, .
(Loop pre-header) , , . ,, LICM.
, , ( ) ( ). , , "store-sinking", LICM.
, (backedge).
Indirectbr . , . , , .
, simplifycfg , , , .
, , CFG, .
Aqui vemos que o bloco de saída foi inserido:
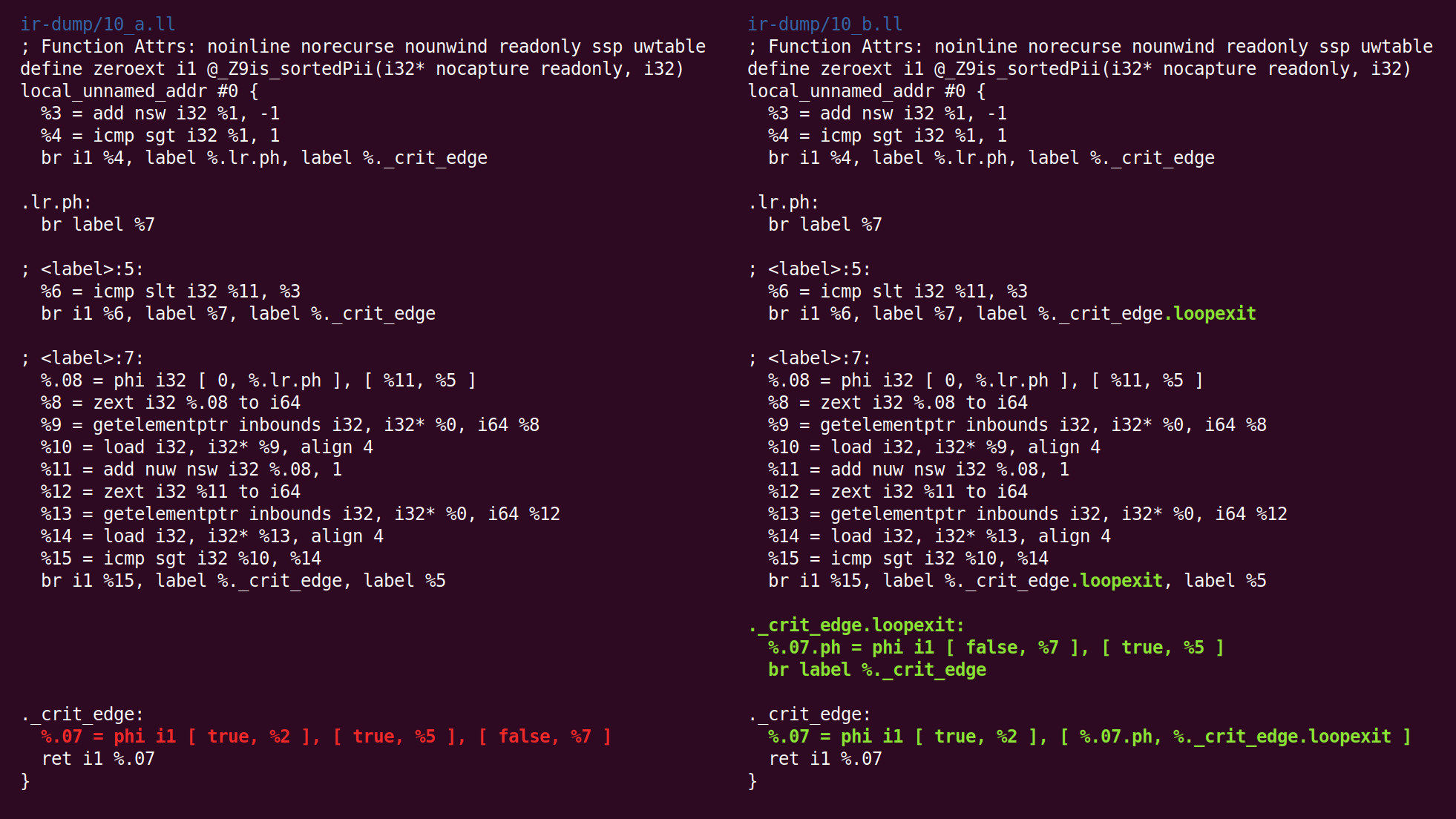
Em seguida, segue a "
simplificação da variável de loop ":
( , ), , .
, :
, . , 'for (i = 7; i*i < 1000; ++i)' 'for (i = 0; i != 25; ++i)'.
indvar , . , "".
O efeito dessa passagem será alterar a variável de loop de 32 bits para 64 bits:
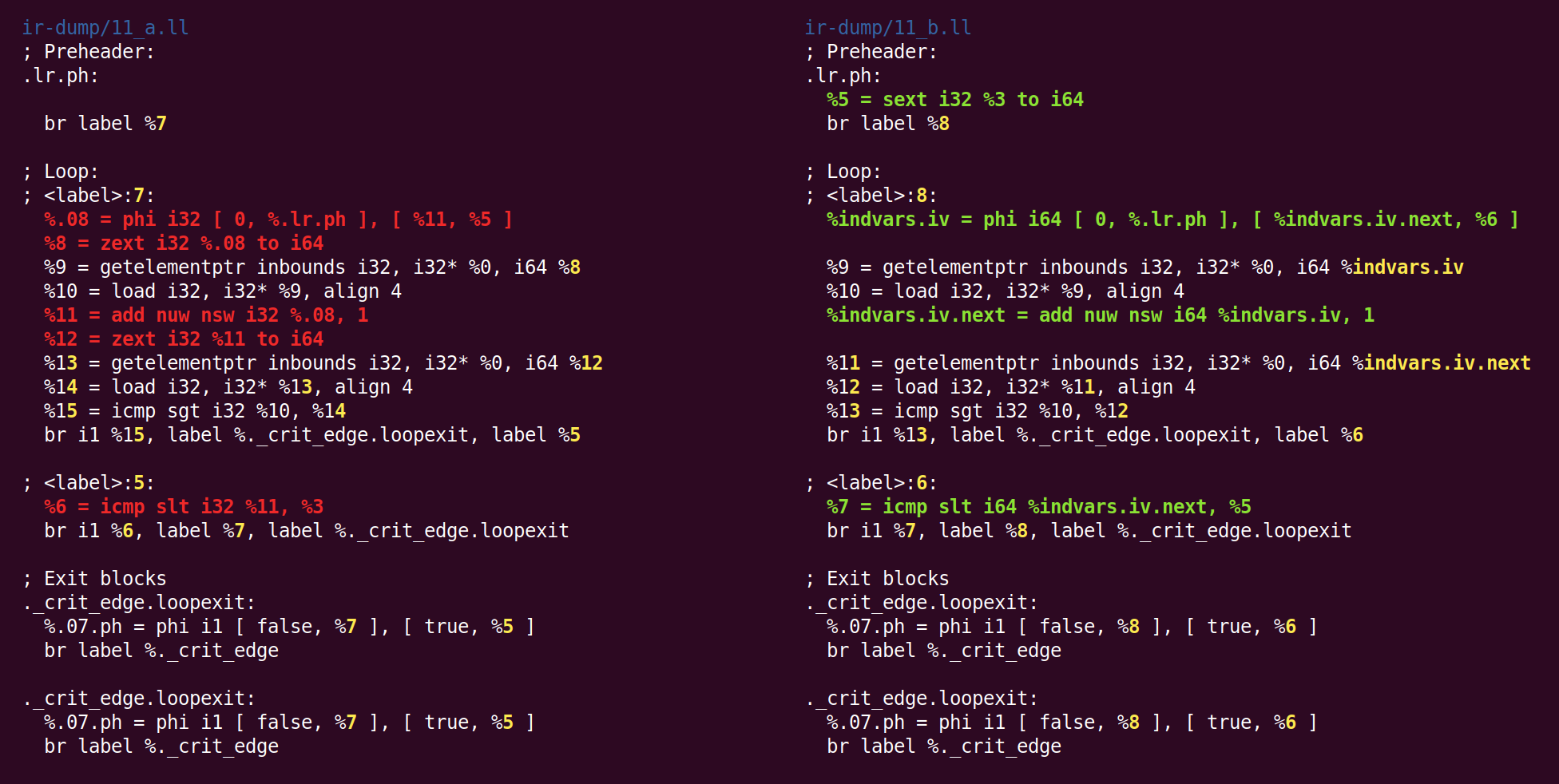
Não sei por que o zext - anteriormente convertido para a forma canônica do sext, retornou novamente ao sext.
Agora, o passe de "
numeração de valor global " está realizando uma otimização muito inteligente. Uma das razões para escrever este post é o desejo de mostrá-lo. Você pode vê-la aqui?

Você viu? Sim, duas instruções de carregamento no loop à esquerda, correspondentes a [i] e a [i + 1]. Aqui, o GVN descobriu que não era necessário carregar um [i], porque um [i + 1] de uma iteração do loop poderia ser transferido para o próximo, como um [i]. Esse truque simples reduz pela metade o número de leituras de memória executadas pela função. Tanto o LLVM quanto o
GCC aprenderam a realizar essa transformação apenas recentemente.
Você pode se perguntar se esse truque funcionará se compararmos um [i] com um [i + 2]. Acontece que não, mas o GCC pode alocar
até quatro registros para esses casos.
Em seguida, o passe "
eliminação do código morto de rastreamento de bits " é iniciado:
"Bit-Tracking Dead Code Elimination". (, "" "" ..) "" . , "" .Mas aqui acontece que esses truques não são necessários, porque o único código morto é a instrução GEP (obter elemento ponteiro), e é trivialmente morto (a passagem GVN excluiu a instrução load que usou o endereço calculado por esta instrução):
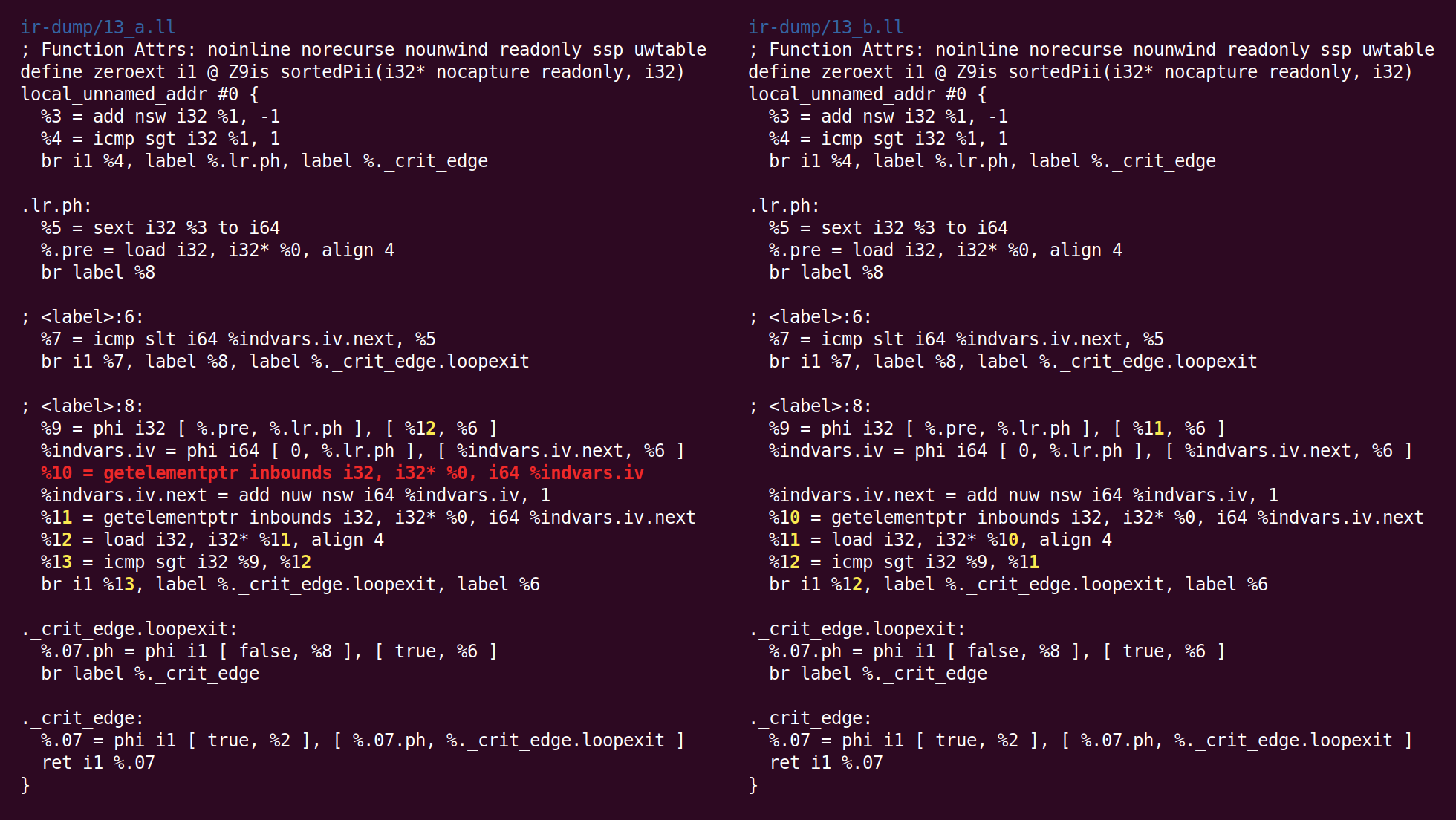
Agora, o algoritmo para combinar instruções colocou add em outra unidade base. A lógica pela qual essa transformação foi colocada no InstCombine não está clara para mim, talvez não houvesse um lugar óbvio onde pudesse ser colocada:

Algo mais estranho está acontecendo agora: o passe "
jump threading " excluiu o que o passe "canonicalize natural loops" já havia feito antes:

Então, novamente, lançamos a forma canônica:
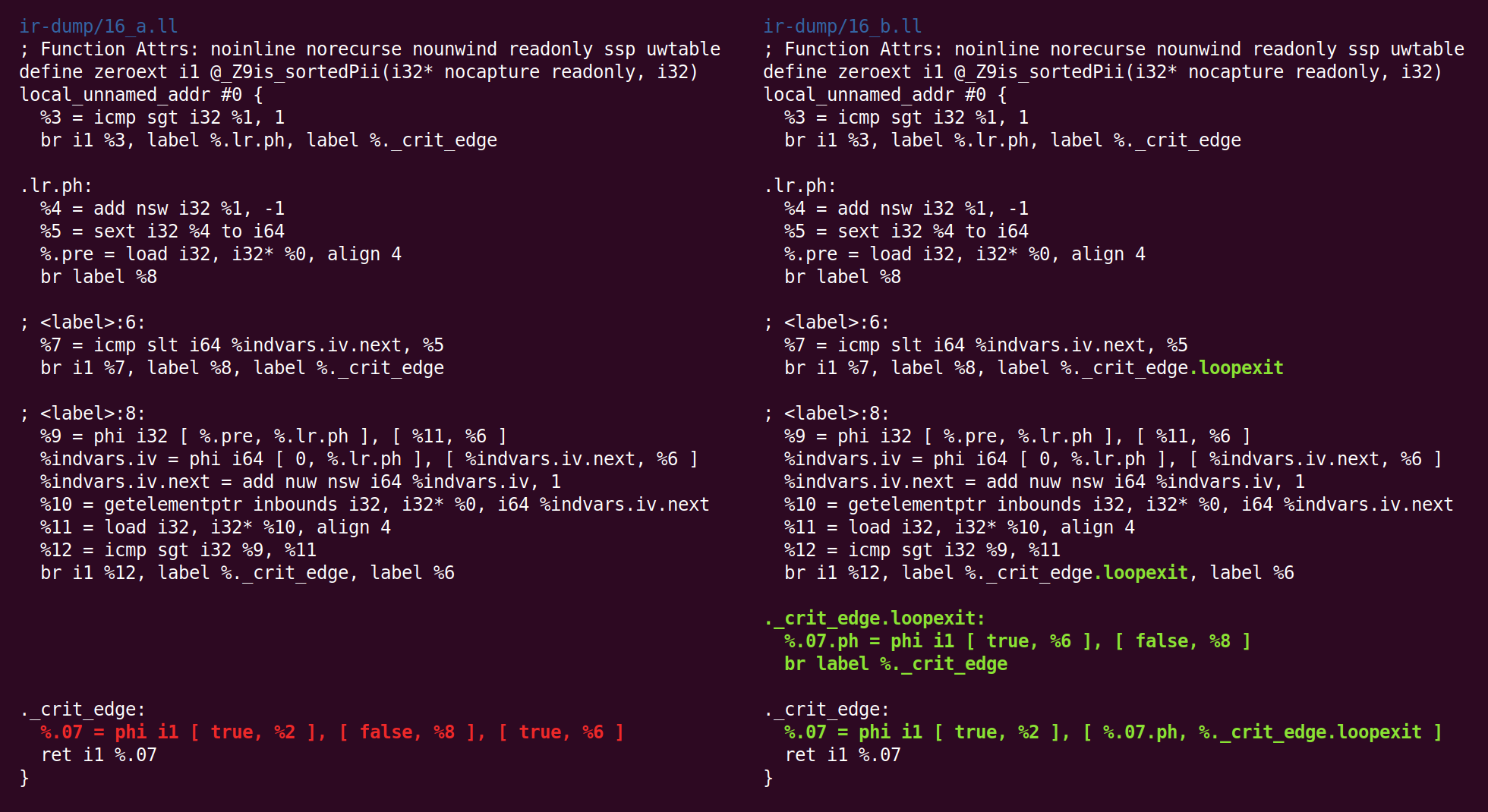
E a simplificação de CFG a transforma de maneira diferente:
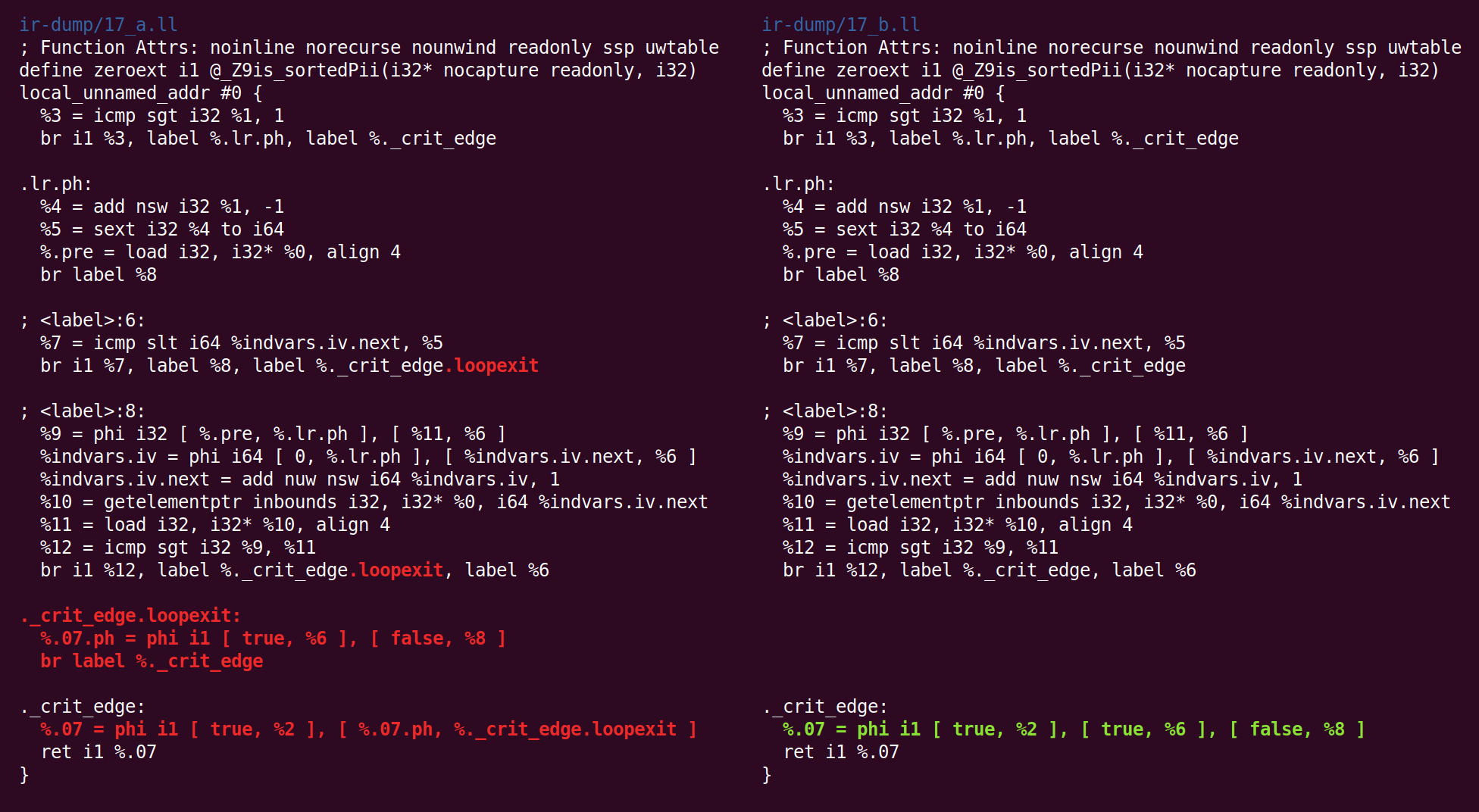
E de volta:
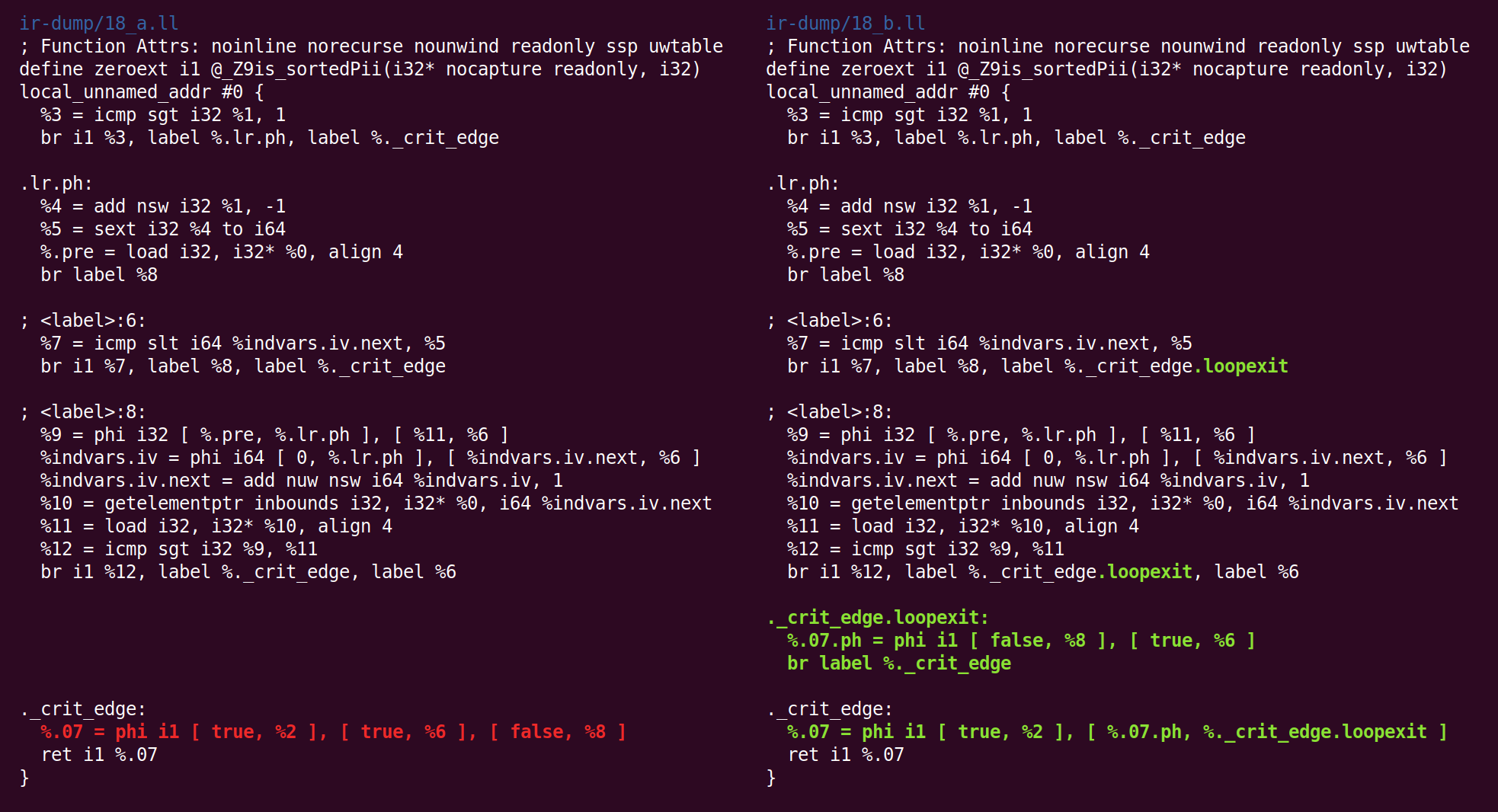
E aí novamente:

E de volta:
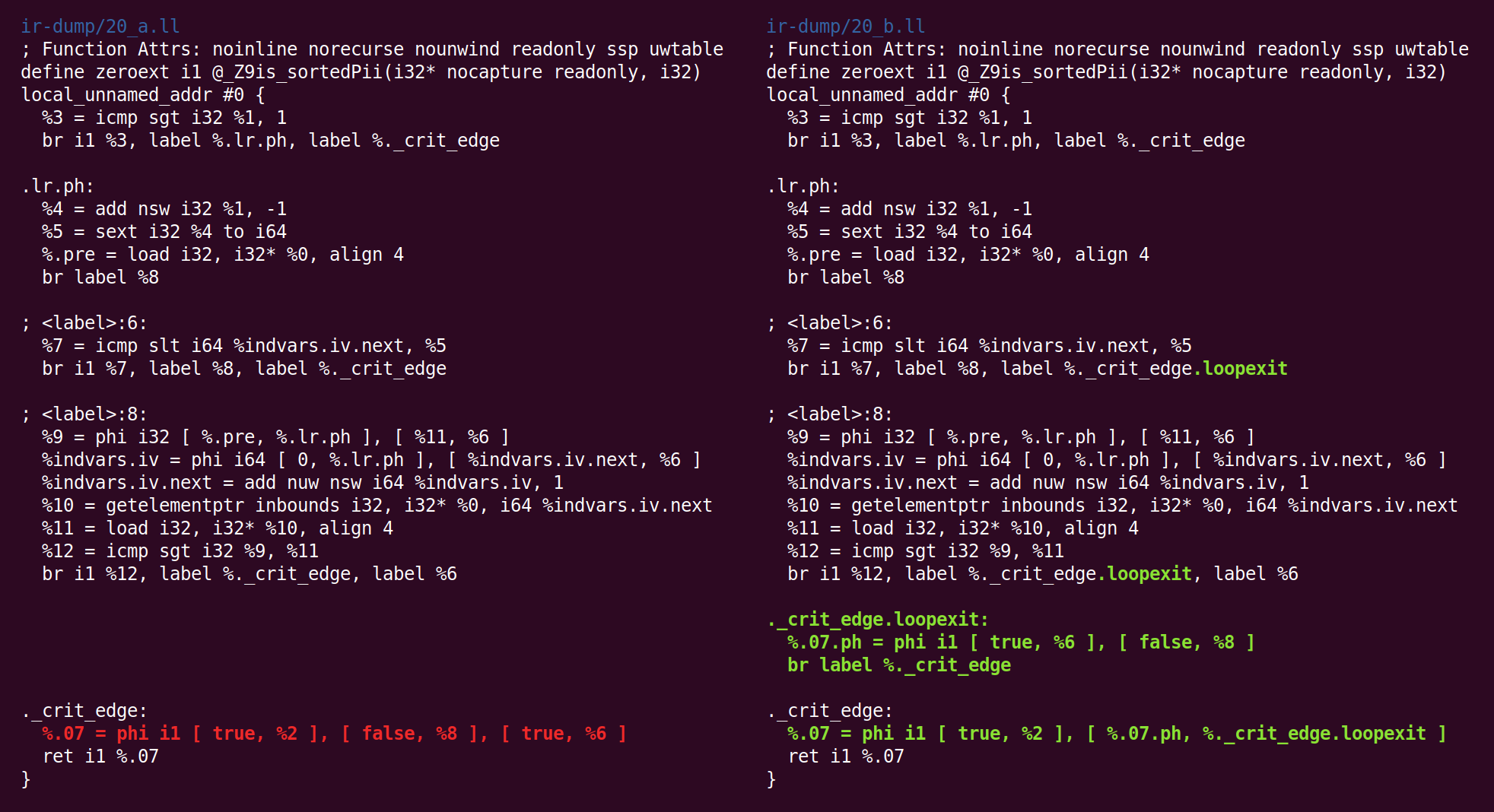
E aí:

E, finalmente, terminamos a região central! O código à direita é o código que passaremos (no nosso caso) para o back-end x86-64.
Você pode estar curioso para saber se as flutuações no comportamento no final do pipeline são o resultado de um erro do compilador, mas vamos considerar que essa função é muito, muito simples e há muitas passagens envolvidas no processamento, mas eu nem as mencionei porque elas não fez nenhuma alteração no código. Durante a segunda metade do pipeline de otimização, observamos principalmente casos degenerados para essa função.
Agradecimentos: alguns alunos do meu curso aprofundado de compilador neste outono deixaram comentários sobre um rascunho deste post (e eu também usei esse material para trabalhos de casa). Analisei as funções discutidas aqui
neste bom conjunto de palestras sobre otimização de loop.