Sob condições de carga alta, a complexidade de otimizar bancos de dados relacionais aumenta em uma ordem de magnitude, uma vez que a compra de hardware ainda mais poderoso é cara e não há como simplesmente desligar o aplicativo à noite para um longo processo de alteração de banco de dados e migração de dados.
Recentemente, conversamos sobre como
otimizamos o código PHP para nosso aplicativo . Agora, chegou a vez do artigo como alteramos completamente a estrutura interna do banco de dados mais carregado e importante do Badoo, sem perder uma única solicitação.
Paciente
O DataBase de usuários, ou UDB, é um serviço que inicia praticamente qualquer solicitação para o Badoo. Ele resolve vários problemas: primeiro, é o repositório central dos principais dados do usuário para os quais a autorização ocorre (por exemplo, email, user_id ou facebook_id). Além de armazenar esses dados, o serviço oferece controle de exclusividade (para que dois usuários com o mesmo email, facebook_id etc. não possam se registrar no sistema). E o mesmo serviço fornece informações sobre qual dos milhares de shards contém todos os outros dados do usuário.
No final de 2018, o UDB armazena dados de mais de 800 milhões de usuários, que ocupam cerca de 1 TB de espaço em disco. Tudo isso é servido por pares de servidores MySQL master-slave em cada um de nossos data centers. No total, eles processam mais de 140.000 solicitações por segundo.
A queda do UDB significa a inacessibilidade de todo o Badoo, já que o código não pode encontrar o fragmento no qual os dados do usuário estão. Portanto, são feitas grandes demandas por confiabilidade e disponibilidade.
Devido a essa especificidade, é muito caro fazer alterações na estrutura de armazenamento, por isso levamos o design do UDB em 2013 muito a sério. No entanto, com o tempo, os requisitos e os perfis de carga mudam. Em um esforço para adaptar o sistema a novos requisitos e níveis de carga, muitas mudanças pequenas e simples foram feitas, mas, infelizmente, essas mudanças estão longe de ser as mais eficazes. E chegou o dia em que, em vez do próximo hack ou da compra de hardware caro, era mais prudente fazer a otimização mais globalmente. Além disso, consideraremos os principais estágios desse caminho.
Otimizações não invasivas
Quaisquer alterações na estrutura de um banco de dados grande e carregado são bastante caras devido à complexidade do processo de migração de dados. Portanto, antes de tudo, você deve esgotar todas as opções de otimização que não afetam a estrutura de dados, mas estão limitadas a consultas de código e SQL. Talvez isso seja suficiente para adiar o problema da carga de trabalho excessiva por alguns anos, o que permitirá que você faça algo mais importante para os negócios no momento.
Quanto melhor você entender seu sistema, mais fácil será encontrar abordagens para essas otimizações. Certifique-se de coletar todas as métricas que podem ajudá-lo. Não se trata apenas de métricas do sistema, como o uso da CPU e da RAM ou as métricas de um banco de dados específico, mas também as métricas no nível de aplicativo de um aplicativo vinculado a um banco de dados otimizado. Quantas solicitações por segundo os diferentes tipos de operações possuem? Qual é o tempo de resposta deles? Qual é o tamanho da entrada e saída? É nessas métricas que você pode julgar o sucesso da otimização. É improvável que você precise de otimização que reduza levemente o uso da CPU no servidor de banco de dados, mas ao mesmo tempo aumente o tempo de resposta do seu aplicativo em dez vezes.

Depois de começar a coletar métricas adicionais no nível de aplicativo para o UDB, conseguimos entender melhor quais das operações executadas geram 80% da carga e são os primeiros candidatos ao estudo e quais são usadas pouco ou nem mais.
Uma análise detalhada da operação mais frequente (extração de usuários que atendem a determinados critérios) mostrou que, apesar de todos os dados de usuário disponíveis serem solicitados no banco de dados, na realidade o aplicativo em 95% dos casos usa apenas user_id. Apenas separando esse caso em um método API separado, que extrai apenas uma coluna da tabela, pudemos nos beneficiar do uso do índice de cobertura e usá-lo para remover cerca de 5% da carga da CPU do servidor de banco de dados.
A análise de outra operação frequente mostrou que, apesar de ser realizado para cada solicitação HTTP, na realidade, os dados recuperados são extremamente raros. Traduzimos essa solicitação para um modelo lento.
O principal objetivo das métricas no caso de um projeto de otimização é entender melhor seu banco de dados e encontrar as partes mais importantes. Não faz sentido gastar muito tempo e esforço para otimizar consultas que representam menos de 1% do seu perfil de carregamento. Se você não possui métricas que permitam entender o perfil de sua carga, colete-as. Com essas otimizações no lado do código, conseguimos remover cerca de 15% do uso da CPU de 80% do banco de dados consumido.
Testando idéias
Se você quiser otimizar um banco de dados carregado alterando sua estrutura, comece verificando suas idéias em um banco de testes, pois mesmo as otimizações que parecem muito promissoras em teoria podem não ter um efeito positivo na prática (e às vezes podem até ter um efeito negativo). E é improvável que você queira saber sobre isso somente após uma longa migração de dados na produção.
Quanto mais próxima a configuração do seu suporte da configuração da produção, mais confiável você obterá os resultados. Um ponto importante é garantir a carga correta do suporte. A execução aleatória ou as mesmas consultas podem levar a resultados falsos. A melhor opção é usar solicitações reais da produção. Para o UDB, registramos na produção cada décima solicitação de leitura da API (incluindo parâmetros) na forma de apenas um log JSON em um arquivo. Por um dia, coletamos um log de 65 GB de tamanho de 700 milhões de solicitações.
Não testamos o registro, em comparação com o número de solicitações de leitura, é muito pequeno e não afeta nossa carga. No entanto, este pode não ser o seu caso. Se você deseja carregar a bancada de testes com solicitações de gravação, precisará coletar cada solicitação, pois ignorar as solicitações de gravação pode levar a erros de consistência na bancada de testes.
O próximo passo é perder corretamente o log no suporte. Usamos 400 trabalhadores de PHP, lançados de nossa
nuvem de scripts , que liam o log coletado da fila rápida e executavam solicitações sequencialmente. Nesse caso, a fila é preenchida com outro script com uma velocidade estritamente definida. Para testar idéias, usamos a velocidade de x10, que multiplicada pelo fato de coletarmos da produção apenas a cada décimo pedido, fornecia o mesmo número de RPS da produção.
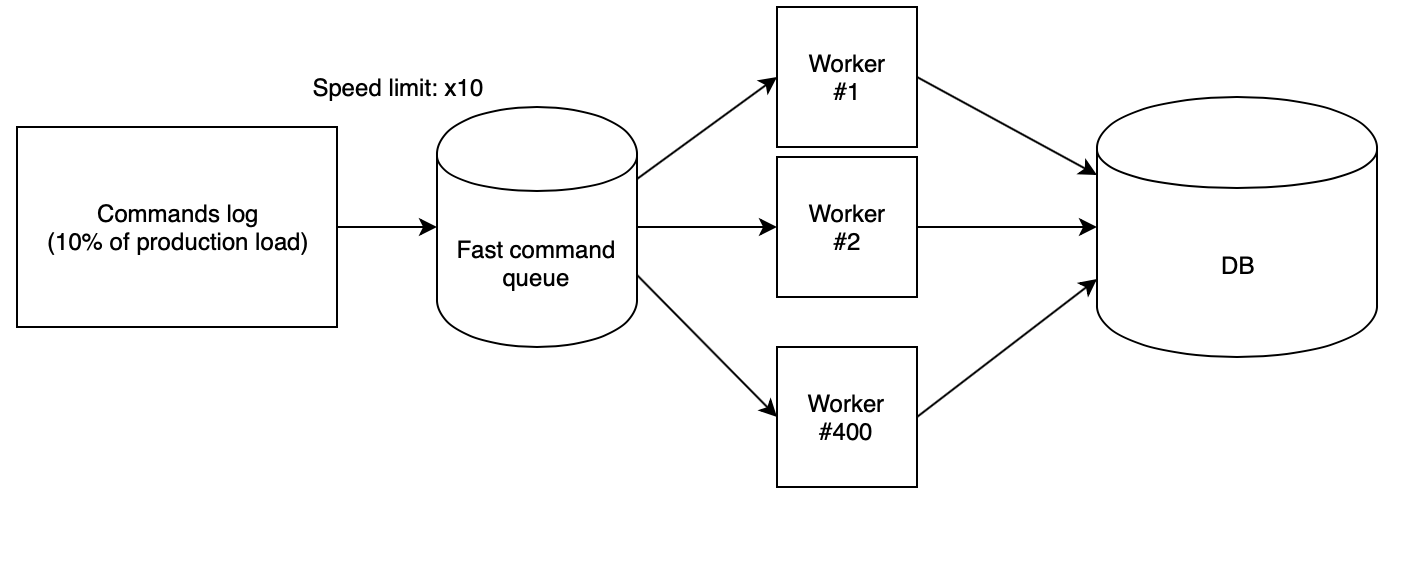
Com esses coeficientes, verifica-se que o dia de produção com toda a carga cai na bancada de testes voa em apenas duas horas e meia.
Assim, por exemplo, o primeiro teste que executamos a uma velocidade de x5 (50% da carga da produção) no log de consultas por meio dia parecia:
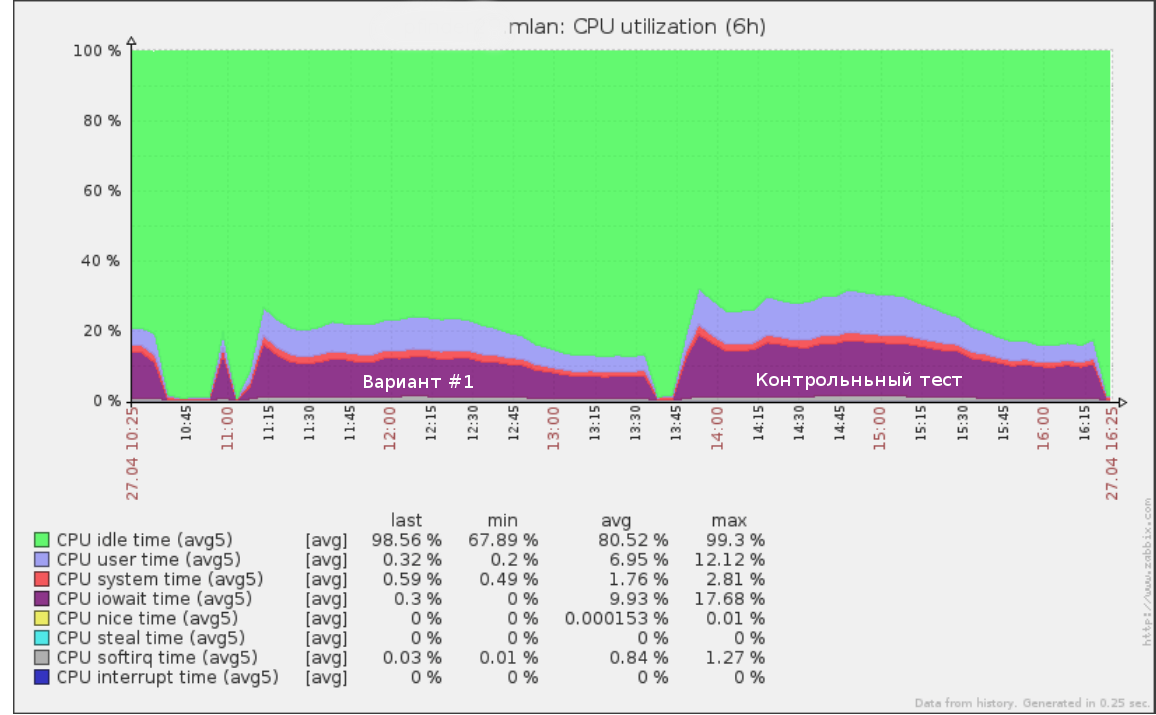
As mesmas ferramentas podem ser usadas para realizar um teste de falha: aumentando a velocidade (e, portanto, o RPS) até que a base no suporte comece a se degradar. Isso lhe dará uma compreensão clara de quanto mais carga seu banco de dados pode suportar.
Após testar o novo esquema de dados, também é importante realizar um teste de controle na estrutura original do banco de dados. Se os resultados e o desempenho atual da produção forem muito diferentes, primeiro você deve entender os motivos. Talvez o servidor de teste esteja configurado incorretamente e você não possa confiar nos dados de teste de carga.
Também vale a pena garantir que o novo código esteja funcionando corretamente. Não faz sentido testar o desempenho de consultas que não fazem o trabalho. Você será bem atendido por testes de integração que verificam se as APIs antigas e novas retornam os mesmos valores nas mesmas chamadas de API.
Após receber os resultados de todas as idéias, resta apenas escolher opções com o melhor equilíbrio entre preço e qualidade e introduzir um novo esquema de produção.
Alteração de esquema
Antes de tudo, observo que alterar o esquema de dados sem interromper a operação do serviço é sempre bastante difícil, caro e arriscado. Portanto, se você tiver a oportunidade de interromper seu aplicativo enquanto altera a estrutura - basta fazê-lo. No caso do UDB, infelizmente, não podíamos pagar por isso.
O segundo fator que afeta a complexidade de mudar um circuito é a escala planejada da mudança. Se todas as alterações propostas nas tabelas não ultrapassarem apenas uma alteração (por exemplo, adicionando um par de novos índices ou colunas), elas podem ser desativadas por processos típicos como
pt-online-schema-change e
gh-ost para MySQL ou um escravo alternativo seguido de mudança de lugar .
No nosso caso, um excelente resultado foi mostrado no sharding vertical de uma tabela gigante cerca de uma dúzia menor com outras colunas, índices e dados em um formato diferente. Essa conversão com ferramentas típicas não é mais possível. Então o que fazer?
Aplicamos o seguinte algoritmo:
- Alcançamos um estado em que os esquemas antigo e novo com dados atuais existem simultaneamente. A gravação ocorre nos dois e, ao mesmo tempo, há uma garantia de consistência dos dados nas duas versões. Vamos considerar este item em detalhes abaixo.
- Gradualmente, mude toda a leitura para um novo circuito, controlando a carga.
- Desligue a gravação no esquema antigo e exclua-o.
As principais vantagens dessa abordagem:
- segurança: existe a possibilidade de reversão instantânea até o último estágio (basta mudar a leitura de volta para o esquema antigo, se algo der errado);
- controle de carga total durante a migração de dados;
- nenhuma alteração pesada da grande mesa do circuito antigo é necessária
No entanto, também existem desvantagens:
- a necessidade de manter ambas as versões dos esquemas em disco durante o processo de migração (isso pode ser um problema se você tiver pouco espaço e a tabela sendo migrada for muito grande);
- muito código temporário para dar suporte ao processo de migração, que será cortado após a conclusão;
- é possível lavar o cache lendo dois esquemas em paralelo; havia o medo de que as versões antiga e nova competissem pela RAM, o que poderia levar à degradação do serviço (na realidade, isso realmente criou uma carga adicional, no entanto, uma vez que a migração foi realizada fora do pico, isso não criou problemas para nós).
A principal dificuldade desse algoritmo é o primeiro ponto. Vamos considerá-lo em detalhes.
Alterar sincronização
A migração de dados estáticos não é particularmente difícil. No entanto, e se você não puder simplesmente parar a gravação inteira enquanto o banco de dados estiver migrando?
Existem várias opções para obter a sincronização do novo esquema: migração com rolagem do registro e gravação idempotente da migração.
Migrando um instantâneo de dados seguido pela reprodução do log das seguintes alterações
Cada transação de atualização de dados é registrada em uma tabela especial por meio de gatilhos no nível do aplicativo ou o log de bin de replicação é usado como um log. Depois de ter esse log, você pode abrir uma transação e migrar um instantâneo de dados, lembrando-se da posição no log. Resta então começar a aplicar o log coletado no novo esquema. Da mesma forma, por exemplo, a popular
ferramenta de backup MySQL
Percona XtraBackup funciona .
Após o novo esquema recuperar o registro do registro atual, o estágio mais crucial começa: você ainda precisa pausar a gravação no esquema antigo por um curto período de tempo e garantir que todo o log disponível seja aplicado ao novo esquema, o que significa que os dados entre os esquemas são consistentes, No nível do aplicativo, ative a gravação de uma vez nas duas fontes.
As principais desvantagens dessa abordagem são que você precisará armazenar de alguma forma o log de operações, o que por si só pode criar uma carga no complexo processo de comutação, bem como na probabilidade de quebrar o recorde se, por algum motivo, os circuitos se mostrarem inconsistentes.
Registro Idempotente
A idéia principal dessa abordagem é começar a gravar no novo esquema paralelamente à gravação no antigo antes que as alterações sejam completamente sincronizadas e, em seguida, concluir a migração dos dados restantes. Da mesma forma, geralmente novas colunas são preenchidas em tabelas grandes.
A gravação síncrona pode ser implementada nos gatilhos do banco de dados e no código-fonte. Aconselho que você faça isso precisamente no código, pois, em qualquer caso, você precisará escrever um código que gravará dados no novo esquema, e a implementação da migração no lado do código fornecerá mais controle.
Um ponto importante a considerar é que, até a conclusão da migração, o novo esquema estará em um estado inconsistente. Por esse motivo, um cenário é possível quando a atualização de uma nova tabela leva a uma violação da constante do banco de dados (chaves estrangeiras ou um índice exclusivo), enquanto, do ponto de vista do esquema atual, a transação está completamente correta e deve ser realizada.
Essa situação pode levar a uma reversão de boas transações devido ao processo de migração. A maneira mais fácil de contornar esse problema é adicionar o modificador IGNORE a todas as solicitações para gravar dados em um novo esquema ou interceptar a reversão dessa transação e executar a versão sem gravar no novo esquema.
O algoritmo de sincronização através da gravação idempotente no nosso caso é o seguinte:
- Ativamos a gravação em um novo esquema em paralelo com a gravação no antigo no modo de compatibilidade (IGNORE).
- Executamos um script que ignora gradualmente o novo esquema e captura dados inconsistentes. Depois disso, os dados nas duas tabelas devem ser sincronizados, mas isso é impreciso devido a possíveis conflitos na cláusula 1.
- Iniciamos o verificador de consistência dos dados - abrimos a transação e lemos sequencialmente as linhas dos esquemas novos e antigos, comparando sua correspondência.
- Se houver conflitos, terminamos e retornamos ao parágrafo 3.
- Depois que o verificador mostrou que os dados nos dois esquemas estão sincronizados, não haverá mais discrepâncias entre os esquemas, a menos que, obviamente, tenhamos perdido algumas nuances. Portanto, esperamos algum tempo (por exemplo, uma semana) e executamos uma verificação de controle. Se ele mostrar que está tudo bem, a tarefa será concluída com êxito e você poderá traduzir a leitura.
Resultados
Como resultado da alteração do formato dos dados, conseguimos reduzir o tamanho da tabela principal de 544 GB para 226 GB, reduzindo assim a carga no disco e aumentando a quantidade de dados úteis que cabem na RAM.
No total, desde o início do projeto, usando todas as abordagens descritas, conseguimos reduzir o uso da CPU do servidor de banco de dados de 80% para 35% no tráfego de pico. Os resultados do teste de estresse subsequente mostraram que, na atual taxa de crescimento da carga, podemos permanecer no hardware existente por pelo menos mais três anos.
Dividir uma tabela enorme em várias simplificou o processo de realizar alterações futuras no banco de dados e também acelerou significativamente alguns scripts que coletavam dados para BI.