 De um tradutor:
De um tradutor: hoje estamos
publicando para você um artigo conjunto de três desenvolvedores, Akaash Chikarmane, Erte Bablu e Nikhil Gaur, que descreve o método para prever a classificação de aplicativos na Google Play Store.
Neste artigo, mostraremos como processamos as informações que usamos para prever classificações. Também explicaremos por que usamos esses ou aqueles deles. Falaremos sobre as transformações do pacote de dados com as quais trabalhamos e sobre o que pode ser alcançado usando a visualização.
A Skillbox recomenda: Curso prático de dois anos "Eu sou um desenvolvedor Web PRO" .
Lembramos que: para todos os leitores de "Habr" - um desconto de 10.000 rublos ao se inscrever em qualquer curso Skillbox usando o código promocional "Habr".
Por que decidimos fazer isso
As aplicações móveis há muito se tornam parte integrante da vida, cada vez mais desenvolvedores estão envolvidos apenas em sua criação. Além disso, muitos são diretamente dependentes da renda que os aplicativos trazem. Portanto, prever o sucesso é de grande importância para eles.
Nosso objetivo é determinar a classificação geral do aplicativo, para fazer isso de maneira abrangente, porque muitas pessoas julgam o programa, contando apenas com o número de "estrelas" definidas pelos usuários. Aplicações com 4-5 pontos são mais confiáveis.
Preparação
A maior parte deste projeto está trabalhando com dados, incluindo pré-processamento. Como todas as informações foram coletadas da Google Play Store, as matrizes resultantes continham muitos erros. Utilizamos vários modelos de regressão, incluindo o Gradient-Boosting Regressor do pacote XGBoost, Linear Regression e RidgeRegression.
Coleta e análise de dados
O conjunto de dados com o qual trabalhamos pode ser
encontrado aqui . Consiste em duas partes. O primeiro são informações objetivas, como tamanho do aplicativo, número de instalações, categoria, número de revisões, tipo de aplicativo, gênero, data da última atualização etc., e subjetivas, ou seja, revisões do usuário.
As próprias revisões foram submetidas a análise. Após comparar os resultados, decidimos incluir ou não os dados da pesquisa no modelo final.
Formamos um conjunto de dados objetivos com 12 funções e uma variável alvo (classificação). O pacote incluiu 10,8 mil unidades de informação. Quanto às análises de usuários, selecionamos as 100 mais relevantes e usamos cinco funções para 64,3 mil elementos. Todos os dados foram coletados diretamente da Google Play Store, na última vez em que foram atualizados há três meses.
Pré-processamento de dados
O conjunto inicial de informações era mais ou menos assim:
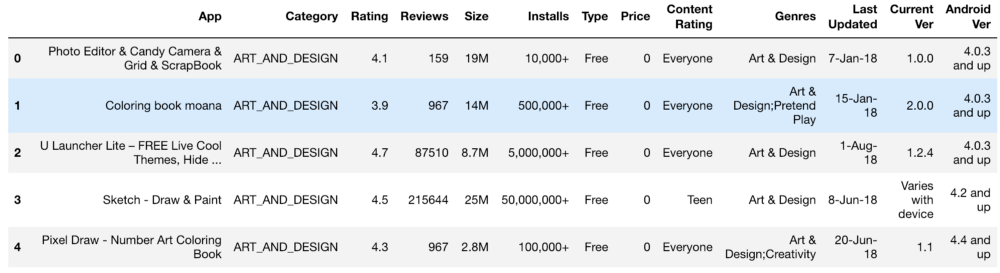
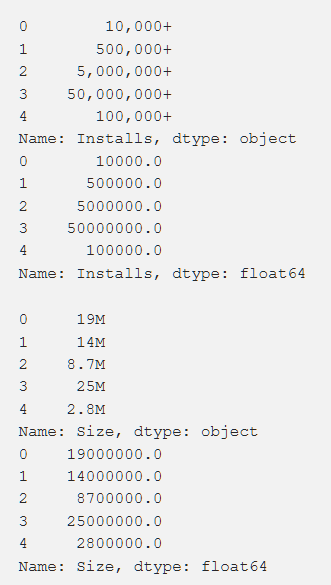
Configurações, classificação, custo e tamanho - processamos tudo isso de forma a obter números acessíveis ao entendimento da máquina. Ao processar várias funções, surgiram problemas, como a necessidade de remover o "+". No custo, removemos $. O volume do aplicativo acabou sendo o mais problemático em termos de processamento, uma vez que o KB e o MB apareceram, por isso foi necessário trabalhar para reduzir tudo para um único formato. Os dados primários são mostrados abaixo e também são após o processamento.
Além disso, transformamos alguns dados, tornando-os mais relevantes para o nosso trabalho. Por exemplo, informações sobre a atualização mais recente do aplicativo não foram muito úteis. Para torná-los mais significativos, convertemos isso em informações sobre o tempo decorrido desde a última atualização. O código para esta tarefa é mostrado abaixo.
from datetime import datetime from dateutil.relativedelta import relativedelta n = 3
Também era necessário trazer para um único padrão variáveis com vários valores diferentes (por exemplo, "Gênero"). Como isso foi feito é mostrado abaixo.
from copy import deepcopy from sklearn.preprocessing import LabelEncoder def one_hot_encode_by_label(df, labels): df_new = deepcopy(df) for label in labels: dummies = df_new[label].str.get_dummies(sep = ";") df_new = df_new.drop(labels = label, axis = 1) df_new = df_new.join(dummies) return df_new def label_encode_by_label(df, labels): df_new = deepcopy(df) le = LabelEncoder() for label in labels: print(label + " is label encoded") le.fit(df_new[label]) dummies = le.transform(df_new[label]) df_new.drop(label, axis = 1) df_new[label] = pd.Series(dummies) return df_new
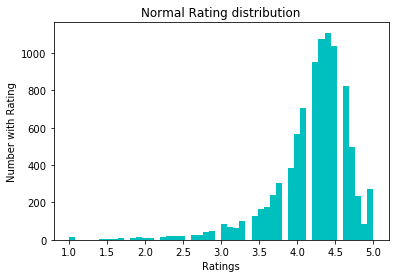
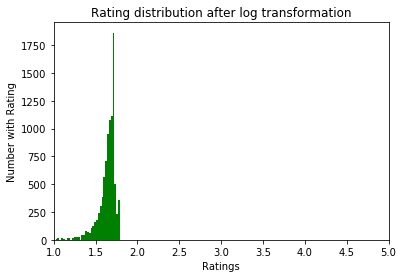
Para normalizar os dados, tentamos a conversão log1p. Antes dele:
Depois:
Exploração de dados
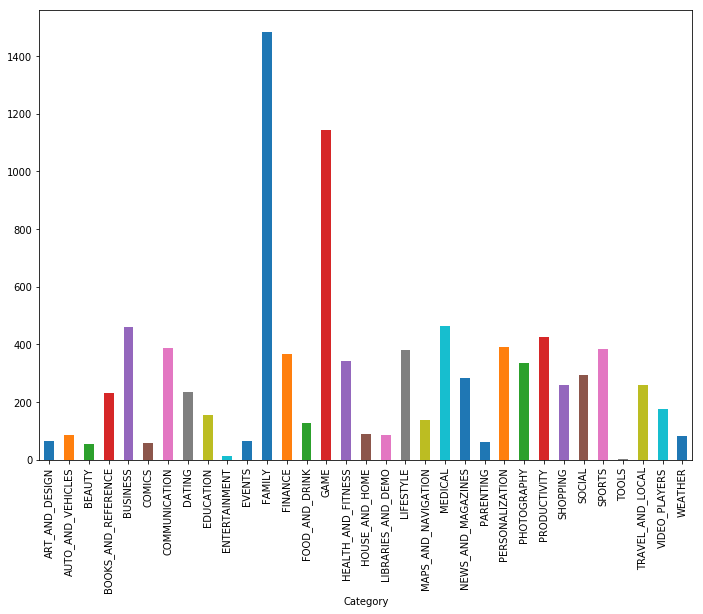
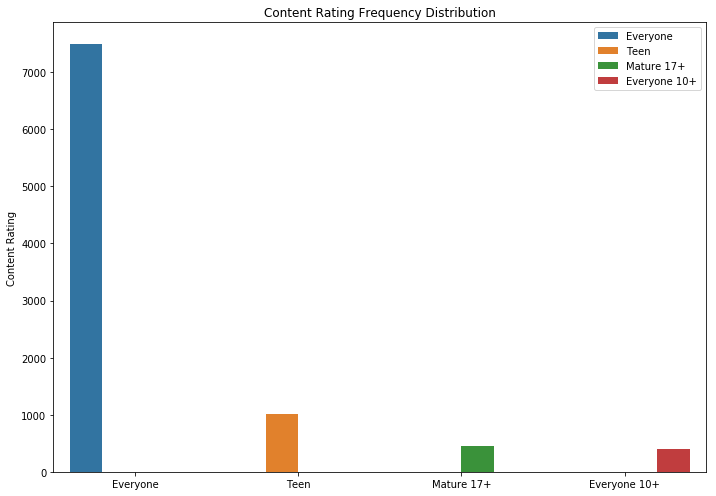
Como você pode ver, jogos e aplicativos para a família são as duas categorias mais populares. A maioria dos aplicativos também estava na categoria "Para todas as idades".

É lógico que aplicativos com uma classificação máxima tenham mais avaliações do que aquelas com baixa classificação. Alguns deles têm muito mais críticas do que todos os outros. Talvez a razão para isso seja uma mensagem pop-up, uma chamada para avaliar ou outras técnicas semelhantes.

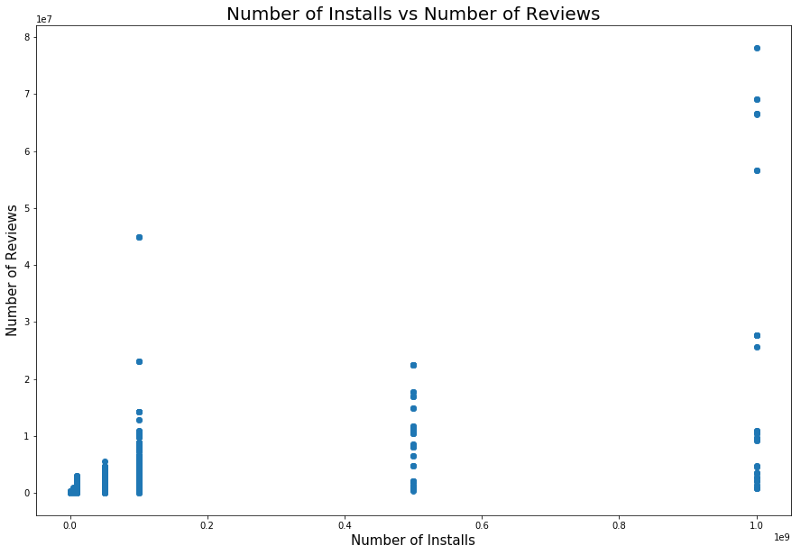
Há também uma relação entre o número de instalações e o número de revisões. A correlação é mostrada na captura de tela abaixo.
Uma análise detalhada dessa dependência pode fornecer uma compreensão do porquê de categorias populares de aplicativos terem mais instalações e mais revisões.
Modelos e Resultados
Usamos a divisão de teste para dividir os dados em conjuntos de teste e treinamento. A validação cruzada com o GridSearchCV foi usada para melhorar os resultados do treinamento do modelo, a fim de encontrar o melhor alfa com Lasso, Ridge Regression e XGBRegressor do pacote XGBoost. O último modelo geralmente é extremamente eficaz, mas, ao usá-lo, é preciso ter cuidado em ajustar os resultados - esse é um dos perigos que os pesquisadores aguardam. O valor rms inicial sem qualquer processamento particularmente cuidadoso dos objetos (apenas codificação e limpeza) foi de cerca de 0,228.
Após a conversão logarítmica das classificações, o erro padrão caiu para 0,219, o que foi uma ligeira melhora, mas percebemos que fizemos tudo certo.
Utilizamos regressão linear após avaliar a relação entre revisões, atitudes e classificações. Em particular, analisamos as informações estatísticas dessas variáveis, incluindo r ao quadrado ep, tomando uma decisão sobre regressão linear como resultado. O primeiro modelo de regressão linear usado mostrou uma correlação entre configurações e uma classificação de 0,2233, o modelo de regressão linear Nossas análises e classificações nos deram um MSE de 0,2107, e o modelo de regressão linear combinado, pesquisas, configurações e classificações ", Nos deu um MSE de 0,214.
Além disso, usamos o modelo KNeighborsRegressor. Os resultados de seu uso são mostrados abaixo.

Conclusões
Depois que os dados primários da Google Play Store foram convertidos em um formato utilizável, plotamos e derivamos funções para entender as correlações entre os valores individuais. Em seguida, esses resultados foram usados para construir um modelo ideal.
Inicialmente, pensamos que não seria muito difícil encontrá-lo, para que pudéssemos construir um modelo preciso. Mas a tarefa foi mais difícil do que esperávamos.
Além do que foi feito, você também pode:
- crie um modelo separado para cada gênero;
- Crie novos recursos a partir das versões do sistema operacional Android, como fizemos anteriormente com as datas;
- para aprender o algoritmo mais profundamente - tivemos um número suficiente de pontos de dados categóricos e numéricos;
- analisar e limpar dados de forma independente da Google App Store.
Todos os resultados estão
disponíveis aqui .
A Skillbox recomenda: