O escritório de Nizhny Novgorod da Intel, entre outras coisas, está desenvolvendo algoritmos de visão computacional baseados em redes neurais profundas. Muitos de nossos algoritmos são publicados no repositório do
Open Model Zoo . O treinamento do modelo requer um grande número de dados marcados. Teoricamente, existem muitas maneiras de prepará-los, mas a disponibilidade de software especializado acelera esse processo muitas vezes. Portanto, para melhorar a eficiência e a qualidade da marcação, desenvolvemos nossa própria ferramenta -
Ferramenta de Anotação de Visão por Computador (CVAT) .
Obviamente, na Internet, você pode encontrar muitos dados anotados, mas existem alguns problemas. Por exemplo, surgem constantemente novas tarefas para as quais simplesmente não existem dados. Outra questão é que nem todos os dados são adequados para uso no desenvolvimento de produtos comerciais, devido a seus contratos de licença. Assim, além do desenvolvimento e treinamento de algoritmos, nossa atividade também inclui marcação de dados. Este é um processo bastante demorado e demorado, o que não seria razoável para se apoiar nos desenvolvedores. Por exemplo, para treinar um de nossos algoritmos, cerca de 769.000 objetos foram marcados por mais de 3.100 horas por homem.
Existem duas soluções para o problema:
- O primeiro é transferir os dados da marcação para empresas de terceiros, com a especialização apropriada. Tivemos uma experiência semelhante. Vale ressaltar o processo complicado de validação e particionamento de dados, bem como a presença de burocracia.
- O segundo, mais conveniente para nós, é a criação e o suporte de nossa própria equipe de anotações. A conveniência reside na capacidade de definir rapidamente novas tarefas, gerenciar o progresso de sua implementação e o equilíbrio facilitado entre preço e qualidade. Além disso, é possível implementar algoritmos de automação personalizados e melhorar a qualidade da marcação.
Inicialmente, a Computer Vision Annotation Tool foi desenvolvida especificamente para nossa equipe de anotações.

Obviamente, nosso objetivo não era criar o "15º padrão". Inicialmente, usamos uma solução pronta -
Vatic , mas, no processo, as equipes de anotação e algoritmos apresentaram novos requisitos, cuja implementação acabou levando a uma reescrita completa do código do programa.
Mais adiante no artigo:
- Informações gerais (funcionalidade, aplicativos, vantagens e desvantagens da ferramenta)
- História e evolução (uma breve história sobre como o CVAT viveu e se desenvolveu)
- Dispositivo interno (descrição da arquitetura de alto nível)
- Instruções de desenvolvimento (um pouco sobre os objetivos que eu gostaria de alcançar e possíveis caminhos para eles)
Informação geral
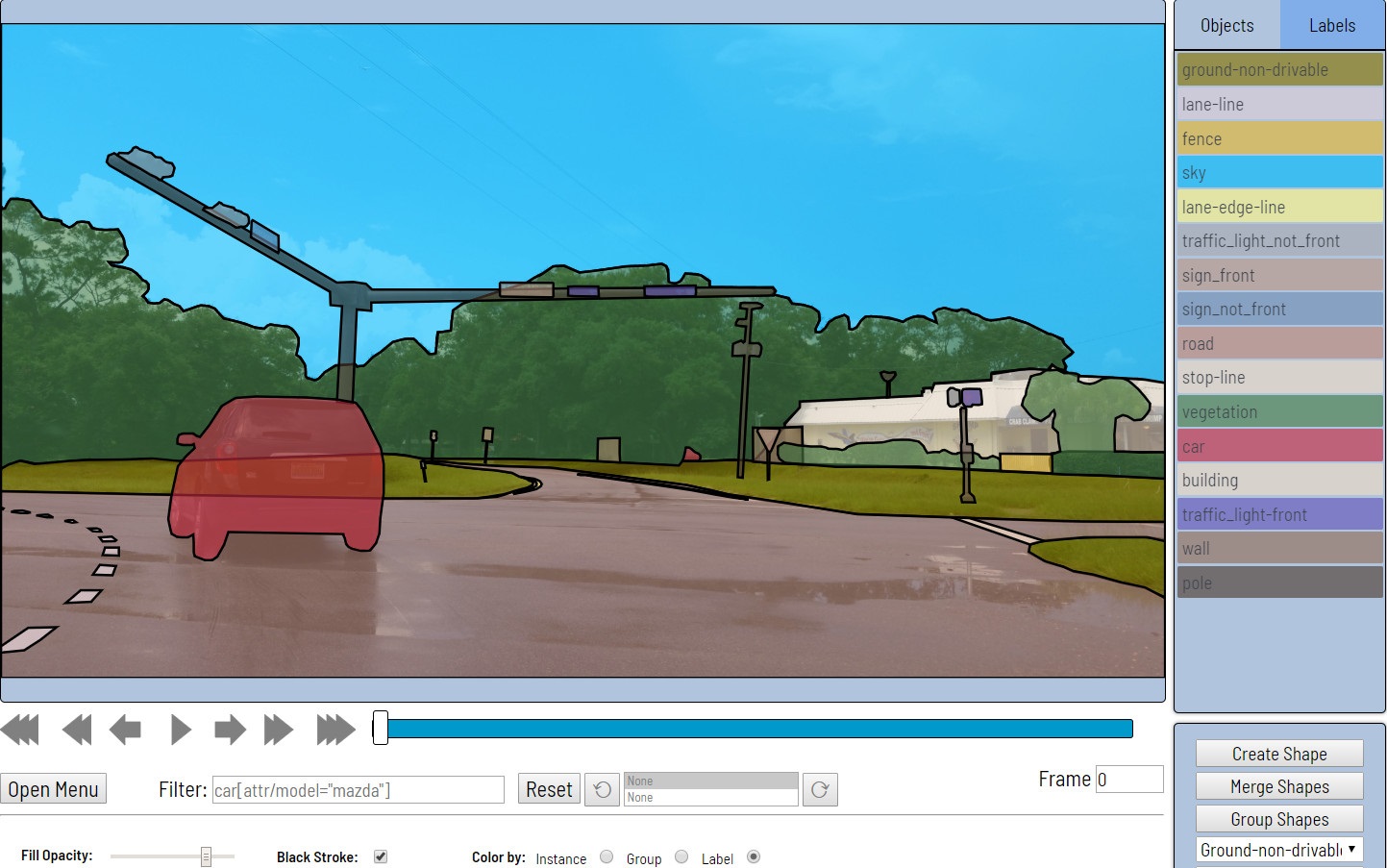
O Computer Vision Annotation Tool (CVAT) é uma ferramenta de código aberto para marcar imagens e vídeos digitais. Sua principal tarefa é fornecer ao usuário meios convenientes e eficazes de marcar conjuntos de dados. Criamos o CVAT como um serviço universal que suporta diferentes tipos e formatos de marcação.
Para usuários finais, o CVAT é um aplicativo da web baseado em navegador. Ele suporta vários cenários de trabalho e pode ser usado tanto para trabalho pessoal quanto para equipe. As principais tarefas de aprendizado de máquina com um professor na área de processamento de imagens podem ser divididas em três grupos:
- Detecção de Objetos
- Classificação da imagem
- Segmentação de imagem
O CVAT é adequado em todos esses cenários.
Vantagens:- Falta de instalação pelos usuários finais. Para criar uma tarefa ou marcar dados, basta abrir um link específico no navegador.
- A capacidade de trabalhar juntos. Há uma oportunidade de disponibilizar publicamente a tarefa aos usuários e paralelizar o trabalho nela.
- Fácil de implantar. A instalação do CVAT na rede local é um par de comandos através do uso do Docker .
- Automação do processo de marcação. A interpolação, por exemplo, permite obter marcações em muitos quadros, com trabalho real apenas em alguns dos principais.
- A experiência dos profissionais. A ferramenta foi desenvolvida com a participação de anotações e várias equipes algorítmicas.
- A capacidade de integrar. O CVAT é adequado para integração em uma plataforma mais ampla. Por exemplo, Onepanel .
- Suporte opcional para várias ferramentas:
- Deep Learning Deployment Toolkit (componente como parte do OpenVINO)
- API de detecção de objeto de fluxo de tensão (TF OD API)
- Sistema de análise ELK (Elasticsearch + Logstash + Kibana)
- Kit de ferramentas NVIDIA CUDA
- Suporte para vários cenários de anotação.
- Código aberto sob uma licença MIT simples e gratuita.
Desvantagens:- Suporte limitado ao navegador. O desempenho da parte do cliente é garantido apenas no navegador Google Chrome. Não testamos o CVAT em outros navegadores, mas teoricamente, a ferramenta pode funcionar no Opera, no Yandex Browser e em outros com o mecanismo Chromium.
- O sistema de testes automáticos não foi desenvolvido. Todas as verificações de integridade são realizadas manualmente, o que diminui significativamente o desenvolvimento. No entanto, já estamos trabalhando em uma solução para esse problema em conjunto com os alunos da UNN. Lobachevsky como parte do projeto IT Lab .
- Nenhuma documentação do código fonte disponível. Envolver-se no desenvolvimento pode ser bastante difícil.
- Limitações de desempenho. Com as crescentes demandas no volume de marcação, enfrentamos vários problemas, como a limitação do Chrome Sandbox ao uso da RAM.
Obviamente, essas listas não são exaustivas, mas contêm disposições básicas.
Como mencionado anteriormente, o CVAT suporta vários componentes adicionais. Entre eles estão:
O Deep Learning Deployment Toolkit como parte do
OpenVINO Toolkit - é usado para acelerar o lançamento do modelo TF OD API na ausência de uma GPU. Estamos trabalhando em alguns outros usos úteis para esse componente.
API de detecção de objetos do Tensorflow - usada para marcar objetos automaticamente. Por padrão, usamos o modelo Faster RCNN Inception Resnet V2, treinado em
COCO (80 classes), mas não deve haver dificuldade em conectar outros modelos.
Logstash, Elasticsearch, Kibana - permitem visualizar e analisar os logs acumulados pelos clientes. Isso pode ser usado, por exemplo, para monitorar o processo de marcação ou procurar erros e as causas de sua ocorrência.
 NVIDIA CUDA Toolkit
NVIDIA CUDA Toolkit - um conjunto de ferramentas para executar cálculos no processador gráfico (GPU). Ele pode ser usado para acelerar o layout automático com a API TF OD ou em outros complementos personalizados.
Marcação de dados
- O processo começa com a declaração do problema para o layout. A preparação inclui:
- Especificando um nome de tarefa
- Enumeração de classes a serem marcadas e seus atributos
- Especificando arquivos para download
- Os dados são baixados do sistema de arquivos local ou de um sistema de arquivos distribuído montado em um contêiner
- Uma tarefa pode conter um arquivo com imagens, um vídeo, um conjunto de imagens e até uma estrutura de diretório com imagens ao fazer o download via armazenamento distribuído
- Opcionalmente, defina:
- Link para especificações detalhadas de marcação, bem como outras informações adicionais (Bug Tracker)
- Link para um repositório Git remoto para armazenar anotações (repositório de conjunto de dados)
- Gire todas as imagens em 180 graus (Flip Images)
- Suporte de camada para tarefas de segmentação (Z-Order)
- Tamanho do segmento Uma tarefa para download pode ser dividida em várias subtarefas para trabalho paralelo
- Área de interseção de segmento (sobreposição). Usado no vídeo para mesclar anotações em diferentes segmentos
- Nível de qualidade ao converter imagens (Qualidade da imagem)
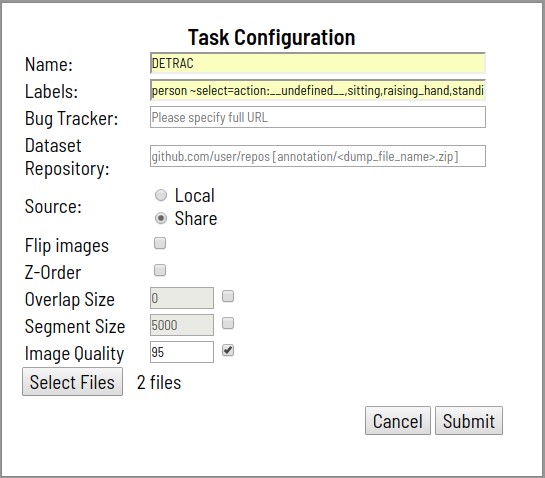
- Após o processamento da solicitação, a tarefa criada aparecerá na lista de tarefas.

- Cada um dos links na seção Trabalhos corresponde a um segmento. Nesse caso, a tarefa não foi segmentada anteriormente. Clicar em qualquer um dos links abre a página de marcação.

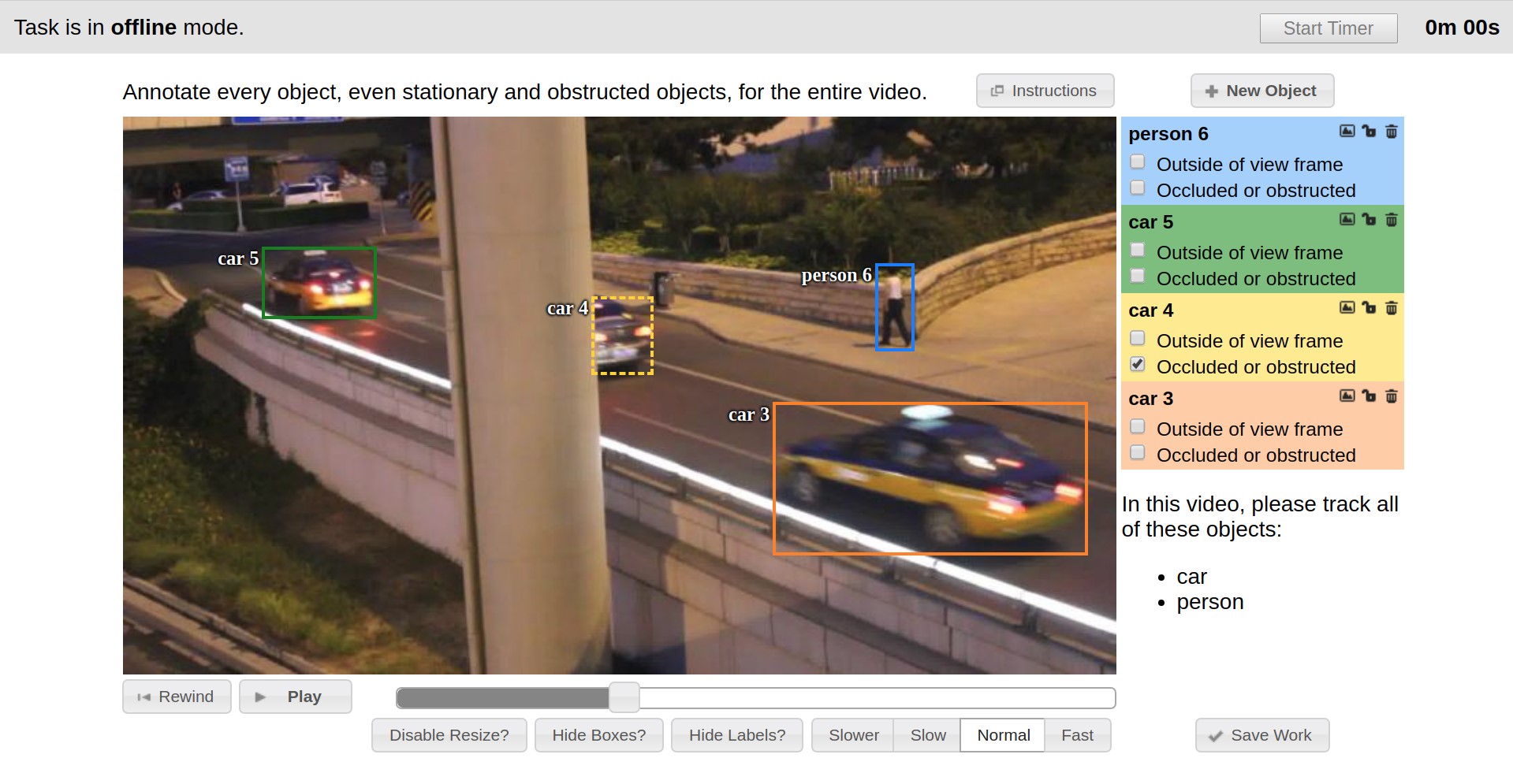
- Em seguida, os dados são marcados diretamente. Retângulos, polígonos (principalmente para tarefas de segmentação), polilinhas (podem ser úteis, por exemplo, para marcação de estradas) e muitos pontos (por exemplo, marcação de marcos de face ou estimativa de pose) são fornecidos como primitivos.
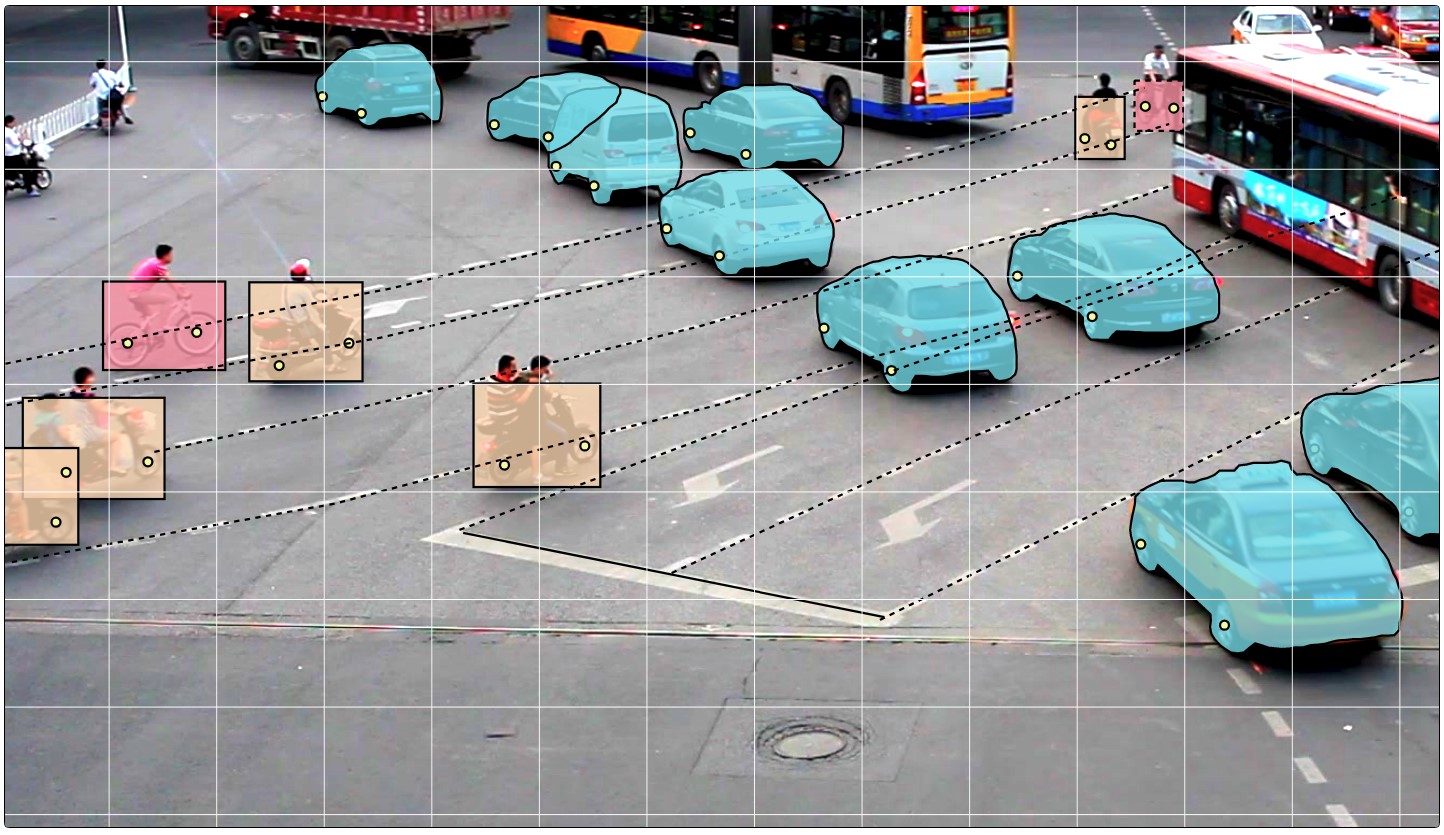
Várias ferramentas de automação também estão disponíveis (cópia, multiplicação para outros quadros, interpolação, marcação preliminar com a API TF OD), configurações visuais, muitas teclas de atalho, pesquisa, filtragem e outras funcionalidades úteis. Na janela de configurações, você pode alterar vários parâmetros para um trabalho mais confortável.
A caixa de diálogo de ajuda contém muitos atalhos de teclado suportados e algumas outras dicas.

O processo de marcação pode ser visto nos exemplos abaixo.
O CVAT pode interpolar linearmente retângulos e atributos entre quadros-chave em um vídeo. Por esse motivo, a anotação no conjunto de quadros é exibida automaticamente.
O Modo de anotação de atributo foi desenvolvido para o cenário de classificação, que permite acelerar a anotação de atributos, concentrando a marcação em uma propriedade específica. Além disso, a marcação aqui ocorre através do uso de "teclas de atalho".
Os polígonos suportam scripts de segmentação semântica e de segmentação de instância. Diferentes configurações visuais facilitam o processo de validação.
- Receber anotação
Pressionar o botão “Dump Annotation” inicia o processo de preparação e carregamento dos resultados da marcação como um único arquivo. Um arquivo de anotação é um arquivo .xml especificado que contém alguns metadados da tarefa e a anotação inteira. A marcação pode ser baixada diretamente no repositório Git, se o último estiver conectado no estágio de criação da tarefa.
História e evolução
Inicialmente, não tínhamos unificação e cada tarefa de marcação era realizada com suas próprias ferramentas, escritas principalmente em C ++ usando a
biblioteca OpenCV . Essas ferramentas foram instaladas localmente em máquinas de usuários finais, não havia mecanismo para compartilhar dados, um pipeline comum para tarefas de configuração e marcação; muitas coisas tinham que ser feitas manualmente.
O ponto de partida da história do CVAT pode ser considerado no final de 2016, quando o
Vatic foi introduzido como uma ferramenta de layout, cuja interface é apresentada abaixo. O Vatic era de código aberto e introduziu algumas idéias gerais excelentes, como a marcação interpolada entre quadros-chave em uma arquitetura de aplicativo de vídeo ou cliente-servidor. No entanto, em geral, ele forneceu uma funcionalidade de marcação bastante modesta e fizemos muito trabalho por conta própria.
Assim, por exemplo, nos primeiros seis meses, foi implementada a capacidade de anotar imagens, foram adicionados atributos de objetos ao usuário, uma página foi desenvolvida com uma lista de tarefas existentes e a capacidade de adicionar novas por meio da interface da web.
Durante o segundo semestre de 2017, introduzimos a API de detecção de objetos do Tensorflow como um método para obter a marcação preliminar. Houve muitas pequenas melhorias no cliente, mas no final fomos confrontados com o fato de que a parte do cliente começou a trabalhar muito lentamente. O fato foi que, o tamanho das tarefas aumentou, o tempo de abertura aumentou proporcionalmente ao número de quadros e dados marcados, a interface do usuário diminuiu devido à apresentação ineficiente dos objetos marcados; o progresso foi muitas vezes perdido ao longo das horas de trabalho. A produtividade caiu principalmente nas tarefas com imagens, pois a base da arquitetura da época foi originalmente projetada para trabalhar com vídeo. Havia uma necessidade de uma mudança completa na arquitetura do cliente, com a qual lidamos com sucesso. A maioria dos problemas de desempenho da época se foi. A interface da web se tornou muito mais rápida e mais estável. A marcação de tarefas maiores tornou-se possível. No mesmo período, houve uma tentativa de introduzir testes de unidade para fornecer, em certa medida, a automação de verificações durante as alterações. Esta tarefa não foi resolvida com tanto sucesso. Configuramos o QUnit, Karma, Chrome sem cabeça no contêiner do Docker, escrevemos alguns testes e lançamos tudo isso no CI. No entanto, uma grande parte do código permaneceu, e ainda permanece, descoberta por testes. Outra inovação foi um sistema de registro de ações do usuário com pesquisa e visualização subsequentes baseadas no ELK Stack. Permite monitorar o processo de anotadores e procurar cenários de ação que levam a exceções de software.
No primeiro semestre de 2018, expandimos a funcionalidade de nosso cliente. Foi adicionado o Modo de anotação de atributo, que implementa um script eficaz para a marcação de atributos, cuja ideia pedimos emprestada aos colegas e generalizamos; Agora você pode filtrar objetos de acordo com vários sinais, conectar um armazenamento comum para fazer o download de dados ao definir tarefas para visualizá-los através de um navegador e muitos outros. As tarefas ficaram mais volumosas e os problemas de desempenho começaram a surgir novamente, mas desta vez a parte do servidor era o gargalo. O problema com o Vatic era que ele continha muito código auto-escrito para tarefas que poderiam ser resolvidas com mais facilidade e eficiência usando soluções prontas. Por isso, decidimos refazer o lado do servidor. Escolhemos o Django como estrutura de servidor, em grande parte devido à sua popularidade e à disponibilidade de muitas coisas, como se costuma dizer, prontas para uso. Após a alteração da parte do servidor, quando não havia mais nada do Vatic, decidimos que já tínhamos feito muito trabalho, que pode ser compartilhado com a comunidade. Por isso, foi decidido ir para o código aberto. Obter permissão para isso dentro de uma grande empresa é um processo bastante complicado. Há uma grande lista de requisitos para isso. Inclusive, era necessário inventar um nome. Esboçamos opções e realizamos uma série de pesquisas entre colegas. Como resultado, nossa ferramenta interna foi denominada CVAT e, em 29 de junho de 2018, o código fonte foi publicado no
GitHub na organização OpenCV, sob a licença MIT e com a versão inicial 0.1.0. Desenvolvimento adicional ocorreu em um repositório público.
No final de setembro de 2018, a versão principal 0.2.0 foi lançada. Houve muitas pequenas alterações e correções, mas o foco principal foi no suporte a novos tipos de anotações. Assim, surgiram várias ferramentas para marcar e validar a segmentação, bem como a capacidade de anotar com polilinhas ou pontos.
O próximo lançamento, assim como um presente de Natal, está agendado para 31 de dezembro de 2018. Os pontos mais significativos aqui são a integração opcional do Deep Learning Deployment Toolkit como parte do OpenVINO, que é usado para acelerar o lançamento da API TF OD na ausência de uma placa gráfica NVIDIA; sistema de análise de log do usuário que não estava disponível anteriormente na versão pública; muitas melhorias no lado do cliente.
Resumimos o histórico do CVAT até a data (dezembro de 2018) e revisamos os eventos mais significativos. Você sempre pode ler mais sobre o histórico de alterações no
changelog .
Dispositivo interno
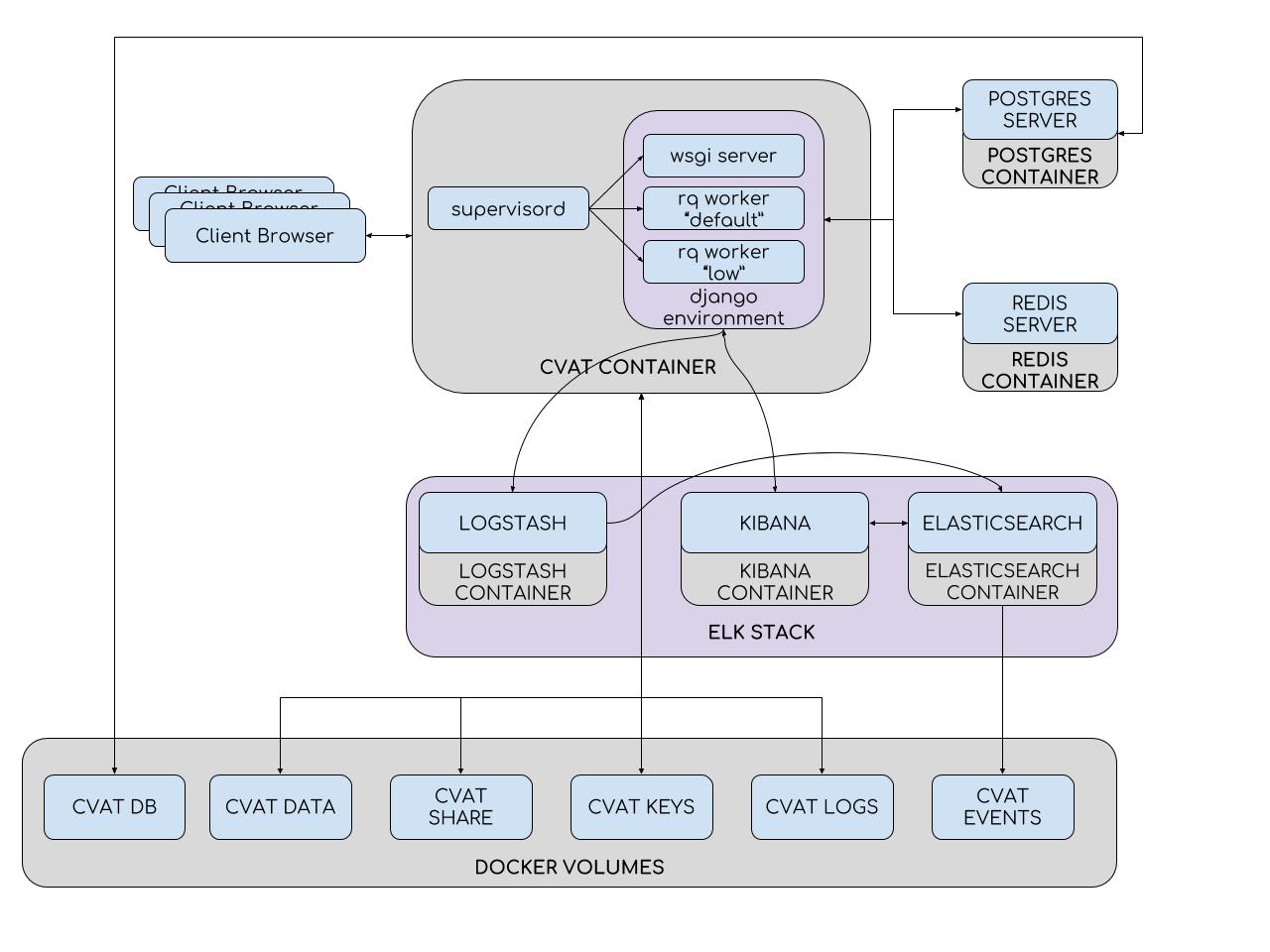
Para simplificar a instalação e a implantação, o CVAT usa contêineres do Docker. O sistema consiste em vários contêineres. Um processo supervisord é executado no contêiner CVAT, que gera vários processos Python no ambiente Django. Um deles é o servidor wsgi, que lida com solicitações do cliente. Outros processos, rq workers, são usados para processar tarefas "longas" das filas do Redis: padrão e baixa. Essas tarefas incluem aquelas que não podem ser processadas em uma única solicitação do usuário (configuração de uma tarefa, preparação de um arquivo de anotação, marcação com a API TF OD e outras). O número de trabalhadores pode ser configurado no arquivo de configuração da supervisord.
O ambiente do Django interage com dois servidores de banco de dados. O servidor Redis armazena o status das filas de tarefas e o banco de dados CVAT contém todas as informações sobre tarefas, usuários, anotações etc. O PostgreSQL (e o SQLite 3 em desenvolvimento) é usado como o DBMS para CVAT. Todos os dados são armazenados em uma partição conectável (volume cvat db). Seções são usadas onde é necessário evitar a perda de dados ao atualizar o contêiner. Assim, o seguinte é montado no contêiner CVAT:
- Seção com vídeo e imagens (volume de dados cvat)
- Seção com chaves (volume de chaves cvat)
- Seção com logs (volume de logs do cvat)
- Armazenamento de arquivo compartilhado (volume compartilhado cvat)
O sistema de análise consiste em Elasticsearch, Logstash e Kibana envoltos em contêineres Docker. Ao salvar o trabalho no cliente, todos os dados, incluindo logs, são transferidos para o servidor. O servidor, por sua vez, os envia ao Logstash para filtragem. Além disso, existe a capacidade de enviar notificações automaticamente para e-mails quando ocorrerem erros. Em seguida, os logs caem no Elasticsearch. O último os salva em uma partição conectável (volume de eventos cvat). Em seguida, o usuário pode usar a interface do Kibana para visualizar estatísticas e logs. Ao mesmo tempo, o Kibana irá interagir ativamente com o Elasticsearch.
No nível da fonte, o CVAT consiste em muitos aplicativos Django:
- autenticação - autenticação de usuários no sistema (básico e LDAP)
- engine - um aplicativo essencial (modelos básicos de banco de dados; tarefas de carregamento e salvamento; carregamento e descarregamento de anotações; interface do cliente de marcação; interface do servidor para criação, alteração e exclusão de tarefas)
- dashboard - interface do cliente para criar, editar, pesquisar e excluir tarefas
- documentation - exibição da documentação do usuário na interface do cliente
- tf_annotation - anotação automática com a API de detecção de objetos do Tensorflow
- log_viewer - enviando logs do cliente para o Logstash ao salvar uma tarefa
- log_proxy - conexão de proxy CVAT → Kibana
- git - Integração do repositório Git para armazenar anotações
Nós nos esforçamos para criar um projeto com uma estrutura flexível. Por esse motivo, os aplicativos opcionais não possuem incorporação de código rígido. Infelizmente, embora não tenhamos um protótipo ideal do sistema de plug-in, mas gradualmente, com o desenvolvimento de novos aplicativos, a situação aqui está melhorando.
A parte do cliente é implementada nos modelos JavaScript e Django. JavaScript , , - ( ) model-view-controller. , (, , ) , . ( - UI), (, , : , , models, views controllers).
open source, . , . . , CVAT. , , . :
- CVAT , , , , . UI .
- . , .
- , . , .
- . deep learning , . , Deep Learning Deployment Toolkit OpenVINO - . , . , .
- demo- CVAT, , , . demo- Onepanel, CVAT .
- Amazon Mechanical Turk CVAT . SDK .
, . , , . open source . – , .
, PR . , ,
Gitter . , ! !
Referências