
Em artigos anteriores, tentei falar sobre o básico de preços e criar uma árvore de decisão do cliente para o varejo clássico. Neste artigo, falarei sobre um caso muito fora do padrão e tentarei convencê-lo de que o aprendizado de máquina não é tão difícil quanto parece. O artigo é menos técnico e tem mais chances de mostrar que você pode começar pequeno e isso já trará benefícios tangíveis para os negócios.
Problema inicial
Há uma cadeia de lojas em nosso continente que muda seu sortimento uma vez por semana, por exemplo, primeiro vende overlocks e depois roupas esportivas masculinas. Todas as mercadorias não vendidas são enviadas aos armazéns e, seis meses depois, devolvidas às lojas novamente. Ao mesmo tempo, a loja possui cerca de 6 categorias diferentes de mercadorias. I.e. A variedade de lojas para cada semana é a seguinte:
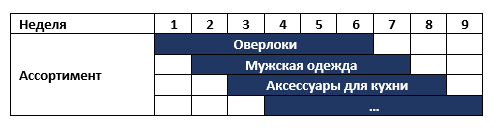
A rede solicitou um sistema de planejamento de alcance com um pré-requisito para suporte à decisão analítica para gerentes de categoria. Depois de conversar com a empresa, propusemos duas soluções em potencial muito rápidas que podem gerar resultados enquanto o sistema de planejamento está sendo implantado:
- vendas de mercadorias que não são vendidas durante as principais vendas
- melhorando a precisão da previsão de demanda nas lojas
O primeiro ponto do cliente não foi satisfeito - a empresa orgulha-se de não organizar as vendas e manter um nível constante de margem. Ao mesmo tempo, enormes quantias de dinheiro são gastas em logística e armazenamento de mercadorias. Como resultado, decidiu-se melhorar a precisão da demanda de previsão para uma distribuição mais precisa das lojas e armazéns.
Processo atual
Devido à natureza dos negócios, cada produto individual não é vendido por um longo tempo e é problemático obter histórico suficiente para a análise clássica. O processo de previsão atual é muito simples e está estruturado da seguinte forma - algumas semanas antes do início das principais vendas em uma pequena parte do teste de vendas das lojas. Com base nos resultados das vendas de teste, é tomada a decisão de introduzir mercadorias em toda a rede e pressupõe-se que cada loja venderá, em média, tanto quanto foi vendido nas lojas de teste.
Chegando ao cliente, analisamos os dados atuais, percebemos o que estava acontecendo e propusemos uma solução muito simples para melhorar a precisão da previsão.
Analisando dados
A partir dos dados que foram fornecidos:
- Histórico de transações por 1 ano e 2 meses
- Hierarquia do produto para planejamento. Infelizmente, quase não havia os atributos dos produtos, mas mais tarde
- Informações sobre a faixa e os preços para semanas específicas
- Informações sobre as cidades onde as lojas estão localizadas
Não foi possível descarregar informações sobre saldos em um curto espaço de tempo, o que é fundamental neste tipo de análise (se você não armazenar essas informações, inicie); portanto, no futuro, usamos a suposição de que os produtos estão nas prateleiras e não há escassez de produtos.
Separamos imediatamente 2 meses em uma amostra de teste para demonstrar os resultados. Em seguida, combinamos todos os dados disponíveis em uma grande vitrine, limpando-os de devoluções e vendas estranhas (por exemplo, o valor do cheque é de 0,51 por peça de mercadoria). Demorou vários dias. Depois de preparar a vitrine, examinamos a venda de mercadorias [unidades] no nível mais alto e vimos a seguinte imagem:
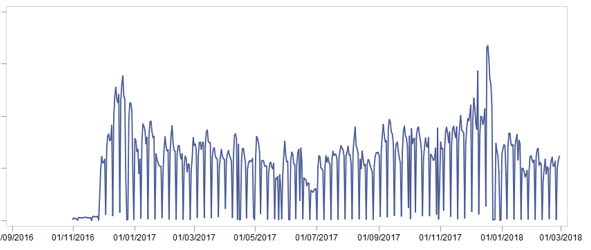
Como essa imagem pode nos ajudar? ... Mas com o que:
- Obviamente, há sazonalidade - as vendas no final do ano são maiores do que no meio
- Há sazonalidade dentro do mês - no meio do mês, as vendas são maiores do que no início e no final
- Há sazonalidade dentro de uma semana - não é tão interessante, porque Como resultado, a previsão foi feita por semanas
Os itens descritos confirmaram o negócio. Mas esses também são ótimos recursos para melhorar a previsão! Antes de adicioná-los ao modelo de previsão, vamos pensar em quais outros recursos de vendas devem ser levados em consideração ... Ideias "óbvias" me vêm à mente:
- As vendas variam em média entre diferentes grupos de produtos
- As vendas variam entre lojas diferentes
- (Semelhante ao parágrafo anterior) As vendas variam entre cidades diferentes
- (Ideia menos óbvia) devido às especificidades do negócio, é visível o seguinte relacionamento: se o sortimento futuro e anterior forem semelhantes, as vendas do novo sortimento serão menores.
Por isso, decidimos parar e construir um modelo.
Como parte da construção do modelo, todos os recursos encontrados foram traduzidos em "recursos" do modelo. Aqui está a lista de recursos usados como resultado:
- previsão atual, ou seja, vendas médias de lojas de teste em [unidades] distribuídas para todas as lojas
- número do mês e número da semana no mês
- todas as variáveis categóricas (cidade, loja, categorias de produtos) foram codificadas usando a probabilidade suavizada (técnica útil - quem ainda não a usa, usa)
- atraso calculado 4 vendas médias de categorias de produtos. I.e. se a empresa planeja vender uma camiseta azul, foi calculado um atraso nas vendas médias da categoria de camisetas
A ABT acabou sendo simples, cada parâmetro era compreensível para os negócios e não causou mal-entendidos ou rejeição. Depois, foi necessário entender como compararemos a qualidade da previsão.
Seleção de métricas
O cliente mediu a precisão da previsão atual usando a métrica MAPE . A métrica é popular e simples, mas possui algumas desvantagens quando se trata de prever a demanda. O fato é que, ao usar o MAPE, os erros do tipo de previsão têm maior impacto no indicador final:

Um erro de previsão relativa de 900% - parece grande, mas vejamos as vendas de outro produto:

O erro relativo de previsão é de 33%, que é muito inferior a 900%, mas o desvio absoluto do desvio de 100 [unidades] é muito mais importante para os negócios do que o desvio de 18 [unidades]. Para levar em consideração esses recursos, você pode criar suas próprias medidas interessantes ou usar outra medida popular na previsão de demanda - o WAPE . Essa medida dá mais peso aos produtos com vendas mais altas, o que é ótimo para a tarefa.
Falamos à empresa sobre várias abordagens para medir erros de previsão, e o cliente concordou de bom grado que o uso do WAPE nessa tarefa é mais razoável. Depois disso, lançamos o Random Forest quase sem ajustar os hiper parâmetros e obtivemos os seguintes resultados.
Resultados
Após a previsão do período de teste, comparamos os valores previstos com os reais, bem como com a previsão da empresa. Como resultado, o MAPE diminuiu mais de 15%, o WAPE mais de 10% . Tendo calculado o impacto da previsão aprimorada sobre os indicadores de negócios, foi obtida uma redução de custos em uma quantia bastante grande de milhões de dólares.
Foi gasta uma semana em todo o trabalho!
Passos adicionais
Como um bônus para o cliente, realizamos um pequeno experimento de QD . Para um grupo de produtos, a partir dos nomes dos produtos, analisamos as características (cor, tipo de produto, composição etc.) e as adicionamos à previsão. O resultado foi inspirador - nessa categoria, as duas medidas de erro melhoraram mais de 8%.
Como resultado, o cliente recebeu uma descrição de cada recurso, parâmetros do modelo, parâmetros de montagem da vitrine da ABT e descreveu outras etapas para melhorar a previsão (use dados históricos por mais de um ano; use saldos; use as características dos produtos, etc.).
Conclusão
Durante uma semana de colaboração com o cliente, foi possível aumentar significativamente a precisão da previsão, praticamente sem alterar o processo de negócios.
Agora, muitas pessoas agora pensam que esse caso é muito simples e não conseguem adotar essa abordagem na empresa. A experiência mostra que quase sempre existem lugares onde apenas premissas básicas e opiniões de especialistas são usadas. Nesses lugares, você pode começar a usar o aprendizado de máquina. Para fazer isso, você precisa preparar e estudar cuidadosamente os dados, conversar com a empresa e tentar aplicar modelos populares que não exigem ajuste longo. E empilhamento, recursos de incorporação, modelos complexos - isso é tudo para mais tarde. Espero ter convencido você de que não é tão difícil quanto parece, você só precisa pensar um pouco e não ter medo de começar.
Não tenha medo do aprendizado de máquina, procure lugares onde ele possa ser usado em processos, não tenha medo de pesquisar seus dados e deixe que os consultores os procurem e obtenham resultados interessantes.
PS Estamos recrutando jovens estudantes Padawan para estágios de varejo, sob a orientação de experientes Jedi. Para começar, o bom senso e o conhecimento de SQL são suficientes, ensinaremos o resto. Você pode se tornar um especialista em negócios ou consultor técnico, o que for mais interessante. Se houver interesse ou recomendações - escreva em um