O link no artigo de hoje é diferente do habitual. Este não é um projeto para o qual o código fonte foi analisado, mas uma série de respostas da mesma regra de diagnóstico em vários projetos diferentes. Qual é o interesse aqui? O fato de que alguns dos fragmentos de código considerados contêm erros que são reproduzíveis ao trabalhar com o aplicativo, enquanto outros contêm completamente vulnerabilidades (CVE). Além disso, no final do artigo, discutiremos um pouco sobre o tópico de defeitos de segurança.
Prefácio breve
Todos os erros que serão considerados hoje no artigo têm um padrão semelhante:
- o programa recebe dados do fluxo stdin ;
- é feita uma verificação para o sucesso da leitura dos dados;
- se os dados foram lidos com êxito, o caractere de transporte é removido da linha.
No entanto, todos os fragmentos que serão considerados contêm erros e são vulneráveis a dados manipulados. Como os dados são recebidos do usuário, que pode violar a lógica de execução do aplicativo, houve uma grande tentação de tentar quebrar alguma coisa. O que eu fiz.
Todos os problemas abaixo foram descobertos pelo
analisador estático PVS-Studio , que procura erros no código não apenas para C, C ++, mas também para C #, Java.
Obviamente, é bom encontrar um problema com um analisador estático, mas encontrar e reproduzir é um nível de prazer completamente diferente. :)
Freeswitch
O primeiro fragmento de código suspeito foi encontrado no código do módulo
fs_cli.exe , que faz parte do kit de distribuição do FreeSWITCH:
static const char *basic_gets(int *cnt) { .... int c = getchar(); if (c < 0) { if (fgets(command_buf, sizeof(command_buf) - 1, stdin) != command_buf) { break; } command_buf[strlen(command_buf)-1] = '\0'; break; } .... }
Aviso do PVS-Studio :
V1010 CWE-20 Dados contaminados não verificados são usados no índice: 'strlen (command_buf)'.
O analisador avisa sobre uma chamada suspeita pelo índice para a matriz
command_buf . É considerado suspeito pelo motivo pelo qual dados externos não verificados são usados como um índice. Externo - porque eles são obtidos através da função
fgets no fluxo
stdin . Não verificado - já que nenhuma verificação foi realizada antes do uso. A expressão
fgets (command_buf, ....)! = Command_buf não conta, pois dessa maneira verificamos apenas o fato de receber os dados, mas não o conteúdo.
O problema com esse código é que, sob certas condições, '\ 0' será gravado fora da matriz, o que levará a um comportamento indefinido. Para fazer isso, basta inserir uma sequência de comprimento zero (uma sequência de comprimento zero do ponto de vista da linguagem C, ou seja, aquela na qual o primeiro caractere será '\ 0').
Vamos estimar o que acontece se você passar uma string de comprimento zero para a entrada:
- fgets (command_buf, ....) -> command_buf ;
- fgets (....)! = command_buf -> false ( o ramo da instrução if é ignorado);
- strlen (command_buf) -> 0 ;
- command_buf [strlen (command_buf) - 1] -> command_buf [-1] .
Opa!
O interessante aqui é que esse aviso do analisador pode ser "sentido com as mãos". Para repetir o problema, você precisa:
- trazer o programa para esta função;
- ajuste a entrada para que a chamada getchar () retorne um valor negativo;
- passar para a função fgets uma linha com um terminal zero no início, que deve ser lido com sucesso.
Revirando um pouco a fonte, criei uma sequência específica para reproduzir o problema:
- Execute fs_cli.exe no modo em lote ( fs_cli.exe -b ). Observo que, para executar etapas adicionais, a conexão fs_cli.exe com o servidor deve ser bem-sucedida. Para fazer isso, é suficiente, por exemplo, executar o FreeSwitchConsole.exe localmente como administrador.
- Realizamos a entrada para que a chamada getchar () retorne um valor negativo.
- Digite uma linha com um terminal zero no início (por exemplo, '\ 0Oooops').
- ....
- LUCRO!
A seguir está uma reprodução de vídeo do problema:
Ncftp
Um problema semelhante foi descoberto no projeto NcFTP, mas ele já foi encontrado em dois locais. Como o código parece semelhante, considere apenas um lugar problemático:
static int NcFTPConfirmResumeDownloadProc(....) { .... if (fgets(newname, sizeof(newname) - 1, stdin) == NULL) newname[0] = '\0'; newname[strlen(newname) - 1] = '\0'; .... }
PVS-Studio Warning :
V1010 CWE-20 Dados contaminados não verificados são usados no índice: 'strlen (newname)'.
Aqui, diferentemente do exemplo do FreeSWITCH, o código é escrito pior e mais propenso a problemas. Por exemplo, a escrita '\ 0' ocorre independentemente de a leitura ter sido bem-sucedida usando
fgets ou não. Ou seja, existem ainda mais possibilidades de como quebrar a lógica normal de execução. Vamos de maneira comprovada - através de linhas de comprimento zero.
O problema reproduzido é um pouco mais complicado do que com o FreeSWITCH. A sequência das etapas é descrita abaixo:
- iniciando e conectando-se ao servidor a partir do qual você pode baixar o arquivo. Por exemplo, usei speedtest.tele2.net (no final, o comando de inicialização do aplicativo se parece com: ncftp.exe speedtest.tele2.net );
- baixar um arquivo do servidor. Localmente, um arquivo com o mesmo nome, mas com propriedades diferentes, já deve existir. Você pode, por exemplo, baixar um arquivo do servidor, alterá-lo e tentar executar o comando de download novamente (por exemplo, obtenha 512KB.zip );
- responda à pergunta sobre a escolha de uma ação com uma linha começando com o caractere 'N' (por exemplo, Agora vamos nos divertir );
- digite '\ 0' (ou algo mais interessante);
- ....
- LUCRO!
A reprodução do problema também é gravada em vídeo:
Openldap
No projeto OpenLDAP (mais precisamente, em um dos utilitários acompanhantes), eles pisaram no mesmo rake que no FreeSWITCH. Uma tentativa de excluir um caractere de quebra de linha ocorre apenas se a linha foi lida com êxito, mas também não há proteção contra linhas de comprimento zero.
Snippet de código:
int main( int argc, char **argv ) { char buf[ 4096 ]; FILE *fp = NULL; .... if (....) { fp = stdin; } .... if ( fp == NULL ) { .... } else { while ((rc == 0 || contoper) && fgets(buf, sizeof(buf), fp) != NULL) { buf[ strlen( buf ) - 1 ] = '\0'; if ( *buf != '\0' ) { rc = dodelete( ld, buf ); if ( rc != 0 ) retval = rc; } } } .... }
PVS-Studio Warning :
V1010 CWE-20 Dados contaminados não verificados são usados no índice: 'strlen (buf)'.
Jogamos fora o excesso para que a essência do problema se torne mais óbvia:
while (.... && fgets(buf, sizeof(buf), fp) != NULL) { buf[ strlen( buf ) - 1 ] = '\0'; .... }
Este código é melhor que o NcFTP, mas ainda é vulnerável. Se, a pedido,
pretende passar uma sequência de comprimento zero para a entrada:
- fgets (buf, ....) -> buf ;
- fgets (....)! = NULL -> true (o corpo do loop while começa a executar);
- strlen (buf) - 1 -> 0 - 1 -> -1 ;
- buf [-1] = '\ 0' .
libidn
Apesar de os erros discutidos acima serem bastante interessantes (eles são reproduzidos de forma estável e podem ser "tocados" (exceto que eu não pude alcançar minhas mãos no problema do OpenLDAP)), eles não podem ser chamados de vulnerabilidades, apenas porque problemas não recebem identificadores do CVE.
No entanto, algumas vulnerabilidades reais têm o mesmo padrão de problema. Ambos os trechos de código abaixo se aplicam ao projeto libidn.
Snippet de código:
int main (int argc, char *argv[]) { .... else if (fgets (readbuf, BUFSIZ, stdin) == NULL) { if (feof (stdin)) break; error (EXIT_FAILURE, errno, _("input error")); } if (readbuf[strlen (readbuf) - 1] == '\n') readbuf[strlen (readbuf) - 1] = '\0'; .... }
Aviso do PVS-Studio :
V1010 CWE-20 Dados contaminados não verificados são usados no índice: 'strlen (readbuf)'.
A situação é semelhante, exceto que, diferentemente dos exemplos anteriores, onde a gravação foi realizada no índice
-1 , a leitura ocorre aqui. No entanto, esse ainda é um comportamento indefinido. Este erro foi
atribuído ao seu próprio identificador
CVE (
CVE-2015-8948 ).
Depois de detectar um problema, esse código foi alterado da seguinte maneira:
int main (int argc, char *argv[]) { .... else if (getline (&line, &linelen, stdin) == -1) { if (feof (stdin)) break; error (EXIT_FAILURE, errno, _("input error")); } if (line[strlen (line) - 1] == '\n') line[strlen (line) - 1] = '\0'; .... }
Um pouco surpreso? Isso acontece Nova vulnerabilidade, identificador CVE correspondente:
CVE-2016-6262 .
PVS-Studio Warning :
V1010 CWE-20 Dados contaminados não verificados são usados no índice: 'strlen (line)'.
Em outra tentativa, o problema foi corrigido adicionando uma verificação para o comprimento da sequência de entrada:
if (strlen (line) > 0) if (line[strlen (line) - 1] == '\n') line[strlen (line) - 1] = '\0';
Vamos dar uma olhada nas datas. O commit 'fechamento' CVE-2015-8948 - 08/10/2015. Confirmar fechamento CVE-2016-62-62 - 14/01/2016. Ou seja, a diferença entre as correções acima é de
5 meses ! Aqui você se lembra de uma vantagem da análise estática como detectar erros nos estágios iniciais da escrita de código ...
Análise estática e segurança
Não haverá mais exemplos de código; em vez disso, estatísticas e raciocínio. Nesta seção, a opinião do autor pode não coincidir com a opinião do leitor muito mais do que antes neste artigo.
Nota Eu recomendo que você leia outro artigo sobre um tópico semelhante - "
Como o PVS-Studio pode ajudar a encontrar vulnerabilidades? ". Existem exemplos interessantes de vulnerabilidades que parecem erros simples. Além disso, nesse artigo, falei um pouco sobre terminologia e por que a análise estática é essencial se você estiver preocupado com o tópico de segurança.
Vejamos as estatísticas sobre o número de vulnerabilidades descobertas nos últimos 10 anos para avaliar a situação. Peguei os dados do site
CVE Details .
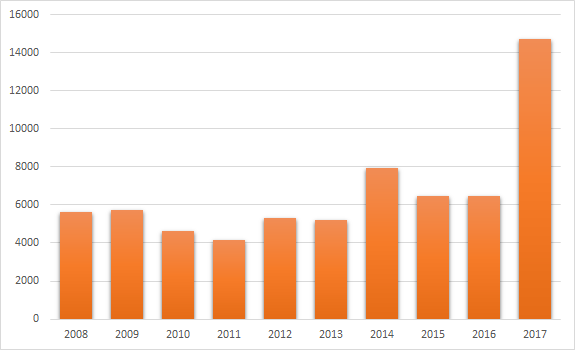
Uma situação interessante se aproxima. Até 2014, o número de CVEs registradas não excedia a marca de 6.000 unidades e, a partir de - não caiu abaixo. Mas o mais interessante aqui, é claro, são as estatísticas para 2017 - o líder absoluto (14.714 unidades). Quanto ao ano atual de 2018, ele ainda não terminou, mas já está quebrando recordes - 15.310 unidades.
Isso significa que todo novo software está cheio de buracos como uma peneira? Eu não acho, e aqui está o porquê:
- Maior interesse no tópico de vulnerabilidades. Certamente, mesmo que você não esteja muito perto do tópico de segurança, você encontrou repetidamente artigos, notas, relatórios e vídeos sobre o tópico de segurança. Em outras palavras, um tipo de "hype" foi criado. Isso é ruim? Provavelmente não. No final, tudo se resume ao fato de que os desenvolvedores estão mais preocupados com a segurança dos aplicativos, o que é bom.
- Um aumento no número de aplicativos desenvolvidos. Mais código - é mais provável que ocorra qualquer vulnerabilidade que reabasteça as estatísticas.
- Ferramentas aprimoradas de pesquisa de vulnerabilidades e garantia de qualidade de código. Mais demanda -> mais oferta. Analisadores, fuzzers e outras ferramentas estão se tornando mais avançados, o que está nas mãos de quem deseja procurar vulnerabilidades (independentemente de qual lado das barricadas estejam).
Portanto, a tendência emergente não pode ser chamada de exclusivamente negativa - os editores estão mais preocupados com a segurança da informação, as ferramentas para encontrar problemas estão sendo aprimoradas e tudo isso é sem dúvida positivo.
Isso significa que você pode relaxar e não "tomar banho"? Eu acho que não. Se você está preocupado com o tópico de segurança de seus aplicativos, deve tomar o maior número possível de medidas de segurança. Isto é especialmente verdade se o código fonte estiver no domínio público, pois:
- mais suscetível à incorporação de vulnerabilidades externas;
- mais propenso a "investigar" por aqueles "cavalheiros" que estão interessados em falhas no seu aplicativo com o objetivo de explorá-las. Embora os que desejam bem neste caso possam ajudá-lo mais.
Não quero dizer que você não precisa traduzir seus projetos em código aberto. Lembre-se dos controles adequados de qualidade / segurança.
A análise estática é uma medida adicional? Sim A análise estática faz um bom trabalho ao detectar possíveis vulnerabilidades que podem se tornar reais no futuro.
Parece-me (admito que estou enganado) que muitos consideram as vulnerabilidades um fenômeno de alto nível. Sim e não Problemas de código que parecem simples erros de programação também podem ser sérias vulnerabilidades. Novamente, alguns exemplos dessas vulnerabilidades são fornecidos no
artigo mencionado anteriormente . Não subestime os erros "simples".
Conclusão
Não esqueça que os dados de entrada podem ter comprimento zero e isso também precisa ser levado em consideração.
Conclusões sobre se todo o hype com vulnerabilidades é apenas hype ou se o problema existe, faça você mesmo.
Pela minha parte, a menos que eu proponha experimentar seu projeto
PVS-Studio , se você ainda não o fez.
Tudo de bom!

Se você deseja compartilhar este artigo com um público que fala inglês, use o link para a tradução: Sergey Vasiliev.
Dê um tiro no pé ao manusear dados de entrada