O segundo artigo da série "Desenvolvimento orientado a teste de aplicativos no Spring Boot" e desta vez vou falar sobre o teste de acesso ao banco de dados, um aspecto importante do teste de integração. Explicarei como determinar a interface de um serviço futuro para acesso a dados por meio de testes, como usar bancos de dados incorporados na memória para testes, trabalhar com transações e fazer upload de dados de teste no banco de dados.
Eu não vou falar muito sobre TDD e testes em geral, convido todos a ler o primeiro artigo - Como construir uma pirâmide no porta-malas ou Desenvolvimento orientado a testes de aplicativos na revista Spring Boot / geek
Começarei, como da última vez, com uma pequena parte teórica, e passarei ao teste de ponta a ponta.
Testando a pirâmide
Para começar, uma descrição pequena, mas necessária, de uma entidade tão importante em testes como A Pirâmide de Testes ou a pirâmide de testes .
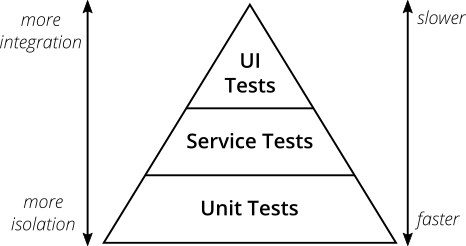
(extraído da pirâmide de teste prático )
A pirâmide de teste é a abordagem quando os testes são organizados em vários níveis.
- Os testes de interface do usuário (ou de ponta a ponta, E2E ) são poucos e lentos, mas testam o aplicativo real - sem zombarias e homólogos de teste. As empresas geralmente pensam nesse nível e todas as estruturas do BDD vivem aqui (consulte Pepino em um artigo anterior).
- Eles são seguidos por testes de integração (serviço, componente - cada um tem sua própria terminologia), que já se concentra em um componente específico (serviço) do sistema, isolando-o de outros componentes através de moki / doubles, mas ainda verificando a integração com sistemas externos reais - esses testes são conectados para o banco de dados, envie solicitações REST, eu trabalho com uma fila de mensagens. De fato, são testes que verificam a integração da lógica de negócios com o mundo exterior.
- No fundo, há testes rápidos de unidade que testam os blocos mínimos de código (classes, métodos) em completo isolamento.
O Spring ajuda a escrever testes para cada nível - mesmo para testes de unidade , embora isso possa parecer estranho, porque no mundo dos testes de unidade, nenhum conhecimento sobre a estrutura deveria existir. Depois de escrever o teste E2E, mostrarei como o Spring permite que até coisas tão puramente de "integração", como controladores, sejam testadas isoladamente.
Mas vou começar do topo da pirâmide - o teste lento da interface do usuário, que inicia e testa um aplicativo completo.
Teste de ponta a ponta
Então, um novo recurso:
Feature: A list of available cakes Background: catalogue is updated Given the following items are promoted | Title | Price | | Red Velvet | 3.95 | | Victoria Sponge | 5.50 | Scenario: a user visiting the web-site sees the list of items Given a new user, Alice When she visits Cake Factory web-site Then she sees that "Red Velvet" is available with price £3.95 And she sees that "Victoria Sponge" is available with price £5.50
E aqui está um aspecto imediatamente interessante - o que fazer com o teste anterior, sobre a saudação na página principal? Parece não ser mais relevante, depois de iniciar o site na página principal, já haverá um diretório, não uma saudação. Não há uma resposta única, eu diria - depende da situação. Mas o principal conselho - não se apegue aos testes! Exclua quando perderem relevância, reescreva para facilitar a leitura. Especialmente testes E2E - essa deve ser, de fato, uma especificação ativa e atual . No meu caso, acabei de excluir os testes antigos e substituí-los por novos, usando algumas das etapas anteriores e adicionando outras inexistentes.
Agora cheguei a um ponto importante - a escolha da tecnologia para armazenar dados. De acordo com a abordagem enxuta , gostaria de adiar a escolha até o último momento - quando saberei com certeza se o modelo relacional ou não, quais são os requisitos de consistência, transacionalidade. Em geral, existem soluções para isso - por exemplo, a criação de gêmeos de teste e vários armazenamentos na memória , mas até agora não quero complicar o artigo e escolher imediatamente a tecnologia - bancos de dados relacionais. Mas, a fim de preservar pelo menos alguma possibilidade de escolha de um banco de dados, adicionarei uma abstração - Spring Data JPA . A própria JPA é uma especificação bastante abstrata para acessar bancos de dados relacionais, e o Spring Data torna seu uso ainda mais fácil.
O Spring Data JPA usa o Hibernate como um provedor por padrão, mas também suporta outras tecnologias, como EclipseLink e MyBatis. Para pessoas que não estão muito familiarizadas com a Java Persistence API - JPA, é como uma interface e o Hibernate é uma classe que a implementa.
Portanto, para adicionar suporte ao JPA, adicionei algumas dependências:
implementation('org.springframework.boot:spring-boot-starter-data-jpa') runtime('com.h2database:h2')
Como banco de dados, usarei o H2 - um banco de dados incorporado escrito em Java, com a capacidade de trabalhar no modo de memória.
Usando o Spring Data JPA, defino imediatamente uma interface para acessar dados:
interface CakeRepository extends CrudRepository<CakeEntity, String> { }
E a essência:
@Entity @Builder @AllArgsConstructor @Table(name = "cakes") class CakeEntity { public CakeEntity() { } @Id @GeneratedValue(strategy = GenerationType.IDENTITY) Long id; @NotBlank String title; @Positive BigDecimal price; @NotBlank @NaturalId String sku; boolean promoted; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; CakeEntity cakeEntity = (CakeEntity) o; return Objects.equals(title, cakeEntity.title); } @Override public int hashCode() { return Objects.hash(title); } }
Existem algumas coisas menos óbvias na descrição da entidade.
@NaturalId para o campo sku . Este campo é usado como um "identificador natural" para verificar a igualdade de entidades - o uso de todos os campos ou campos @Id nos métodos equals / hashCode é um anti-padrão. Está bem escrito sobre como verificar corretamente a igualdade de entidades, por exemplo, aqui .- Para reduzir um pouco o código padrão, eu uso o Project Lombok - processador de anotação para Java. Ele permite que você adicione várias coisas úteis, como
@Builder - para gerar automaticamente um construtor para uma classe e o @AllArgsConstructor para criar um construtor para todos os campos.
Uma implementação de interface será fornecida automaticamente pelo Spring Data.
Abaixo da pirâmide
Agora é a hora de descer para o próximo nível da pirâmide. Como regra geral, eu recomendaria que você sempre iniciasse com o teste e2e , pois isso permitirá que você determine o "objetivo final" e os limites do novo recurso, mas não existem mais regras rígidas. Não é necessário escrever um teste de integração primeiro, antes de passar para o nível da unidade. Na maioria das vezes, é mais conveniente e mais simples - e é natural que ocorra.
Mas agora, especificamente, gostaria de quebrar imediatamente essa regra e escrever um teste de unidade que ajudará a determinar a interface e o contrato de um novo componente que ainda não existe. O controlador deve retornar um modelo que será preenchido a partir de um determinado componente X, e eu escrevi este teste:
@ExtendWith(MockitoExtension.class) class IndexControllerTest { @Mock CakeFinder cakeFinder; @InjectMocks IndexController indexController; private Set<Cake> cakes = Set.of(new Cake("Test 1", "£10"), new Cake("Test 2", "£10")); @BeforeEach void setUp() { when(cakeFinder.findPromotedCakes()).thenReturn(cakes); } @Test void shouldReturnAListOfFoundPromotedCakes() { ModelAndView index = indexController.index(); assertThat(index.getModel()).extracting("cakes").contains(cakes); } }
Este é um teste de unidade puro - sem contextos, sem bancos de dados aqui, apenas Mockito para mok. E esse teste é apenas uma boa demonstração de como o Spring ajuda os testes de unidade - o controlador no Spring MVC é apenas uma classe cujos métodos aceitam parâmetros de tipos comuns e retornam objetos POJO - View Models . Não há solicitações HTTP, respostas, cabeçalhos, JSON, XML - tudo isso será aplicado automaticamente na pilha na forma de conversores e serializadores. Sim, existe uma pequena "dica" para Spring na forma de ModelAndView , mas esse é um POJO comum e você pode até se livrar dele, se desejar, é necessário especificamente para os controladores da interface do usuário.
Não vou falar muito sobre Mockito, você pode ler tudo na documentação oficial. Especificamente, existem apenas pontos interessantes neste teste - eu uso o MockitoExtension.class como MockitoExtension.class teste e ele gera automaticamente mokas para os campos anotados por @Mock e injeta esses mokas como dependências no construtor do objeto no campo marcado como @InjectMocks . Você pode fazer tudo isso manualmente usando o método Mockito.mock() e, em seguida, crie uma classe.
E esse teste ajuda a determinar o método do novo componente - findPromotedCakes , uma lista de bolos que queremos mostrar na página principal. Ele não determina o que é ou como deve funcionar com o banco de dados. A única responsabilidade do controlador é pegar o que foi transferido para ele e devolver os modelos ("bolos") em um campo específico. No entanto, o CakeFinder já possui o primeiro método na minha interface, o que significa que você pode escrever um teste de integração para ele.
Eu deliberadamente tornei todas as classes dentro do pacote de cakes privadas, para que ninguém fora do pacote pudesse usá-las. A única maneira de obter dados do banco de dados é com a interface CakeFinder, que é o meu “componente X” para acessar o banco de dados. Torna-se um "conector" natural, que eu posso travar facilmente se precisar testar algo isoladamente e não tocar na base. E sua única implementação é o JpaCakeFinder. E se, por exemplo, o tipo de banco de dados ou a fonte de dados mudar no futuro, será necessário adicionar uma implementação da interface CakeFinder sem alterar o código que a utiliza.
Teste de integração para JPA usando @DataJpaTest
Os testes de integração são pão com manteiga. De fato, tudo foi feito tão bem para testes de integração que, às vezes, os desenvolvedores não querem ir para o nível da unidade ou negligenciar o nível da interface do usuário. Isso não é ruim nem bom - repito que o objetivo principal dos testes é a confiança. E um conjunto de testes de integração rápidos e eficazes pode ser suficiente para fornecer essa confiança. No entanto, existe o perigo de que, com o tempo, esses testes sejam mais lentos ou lentos ou simplesmente iniciem o teste dos componentes isoladamente, em vez da integração.
Os testes de integração podem executar o aplicativo como está ( @SpringBootTest ) ou seu componente separado (JPA, Web). No meu caso, quero escrever um teste focado para JPA - portanto, não preciso configurar controladores ou outros componentes. A anotação @DataJpaTest é responsável por isso no Spring Boot Test. Esta é uma meta- anotação, ou seja, Ele combina várias anotações diferentes que configuram diferentes aspectos do teste.
- @AutoConfigureDataJpa
- @AutoConfigureTestDatabase
- @AutoConfigureCache
- @AutoConfigureTestEntityManager
- @Transactional
Primeiro, vou falar sobre cada um individualmente e depois mostro o teste concluído.
@AutoConfigureDataJpa
Ele carrega um conjunto inteiro de configurações e define repositórios (geração automática de implementações para CrudRepositories ), ferramentas de migração para os bancos de dados FlyWay e Liquibase, conectando-se ao banco de dados usando o DataSource, o gerenciador de transações e, finalmente, o Hibernate. De fato, este é apenas um conjunto de configurações relevantes para acessar dados - nem o DispatcherServlet do Web MVC, nem outros componentes estão incluídos aqui.
@AutoConfigureTestDatabase
Este é um dos aspectos mais interessantes do teste JPA. Essa configuração procura no caminho de classe um dos bancos de dados incorporados suportados e reconfigura o contexto para que o DataSource aponte para um banco de dados na memória criado aleatoriamente . Como adicionei a dependência à base H2, não preciso fazer mais nada, apenas ter essa anotação automaticamente para cada execução de teste fornecerá uma base vazia, e isso é incrivelmente conveniente.
Vale lembrar que essa base estará completamente vazia, sem um esquema. Para gerar o circuito, existem algumas opções.
- Use o recurso DDL automático do Hibernate. O Spring Boot Test definirá automaticamente esse valor como
create-drop para que o Hibernate gere um esquema a partir da descrição da entidade e o exclua no final da sessão. Este é um recurso incrivelmente poderoso do Hibernate, que é muito útil para testes. - Use migrações criadas pelo Flyway ou Liquibase .
Você pode ler mais sobre as diferentes abordagens para inicializar o banco de dados na documentação .
@AutoConfigureCache
Apenas configura o cache para usar o NoOpCacheManager - ou seja, não armazene em cache nada. Isso é útil para evitar surpresas nos testes.
@AutoConfigureTestEntityManager
Adiciona um objeto TestEntityManager especial ao TestEntityManager , que por si só é uma fera interessante. EntityManager é a classe principal da JPA, responsável por adicionar entidades à sessão, excluir e coisas semelhantes. Somente quando, por exemplo, o Hibernate entra em operação - adicionar uma entidade a uma sessão não significa que uma solicitação ao banco de dados será executada e o carregamento de uma sessão não significa que uma solicitação de seleção será executada. Devido aos mecanismos internos do Hibernate, operações reais com o banco de dados serão executadas no momento certo, que a própria estrutura determinará. Mas nos testes, pode ser necessário enviar algo forçosamente ao banco de dados, porque o objetivo dos testes é testar a integração. E TestEntityManager é apenas um auxiliar que ajudará algumas operações com o banco de dados a serem executadas à força - por exemplo, persistAndFlush() forçará o Hibernate a executar todas as solicitações.
@Transactional
Essa anotação torna todos os testes da classe transacionais, com reversão automática da transação após a conclusão do teste. Este é apenas um mecanismo para "limpar" o banco de dados antes de cada teste, porque, caso contrário, você teria que excluir manualmente os dados de cada tabela.
Se um teste deve gerenciar uma transação não é uma pergunta tão simples e óbvia quanto parece. Apesar da conveniência do estado “limpo” do banco de dados, a presença de @Transactional nos testes pode ser uma surpresa desagradável se o código de “batalha” não iniciar a transação em si, mas exigir uma já existente. Isso pode levar ao fato de o teste de integração ser aprovado, mas quando o código real é executado a partir do controlador e não do teste, o serviço não terá uma transação ativa e o método lançará uma exceção. Embora isso pareça perigoso, com testes de alto nível de testes de interface do usuário, os testes transacionais não são tão ruins. Na minha experiência, vi apenas uma vez, quando um teste de integração aprovado travou o código de produção, o que claramente exigia a existência de uma transação existente. Mas se você ainda precisar verificar se os serviços e os componentes gerenciam corretamente as transações, poderá "bloquear" a anotação @Transactional no teste com o modo desejado (por exemplo, não inicie a transação).
Teste de integração com @SpringBootTest
Também quero observar que o @DataJpaTest não é um exemplo exclusivo de teste de integração focal, existem o @WebMvcTest , o @DataMongoTest e muitos outros. Mas uma das anotações de teste mais importantes continua sendo o @SpringBootTest , que inicia o aplicativo "como está" para os testes - com todos os componentes e integrações configurados. Uma questão lógica surge - se você pode executar o aplicativo inteiro, por que os testes focados no DataJpa, por exemplo? Eu diria que não há regras estritas aqui novamente.
Se for possível executar aplicativos sempre, isolar falhas nos testes, não sobrecarregar e não complicar novamente a instalação do teste, é claro que você pode e deve usar o @SpringBootTest.
No entanto, na vida real, os aplicativos podem exigir muitas configurações diferentes, conectar-se a sistemas diferentes e eu não gostaria que meus testes de acesso ao banco de dados caíssem, porque a conexão com a fila de mensagens não está configurada. Portanto, é importante usar o bom senso e, para que o teste com a anotação @SpringBootTest funcione, você precisa bloquear metade do sistema - isso faz sentido no @SpringBootTest?
Preparação de dados para o teste
Um dos pontos principais para o teste é a preparação de dados. Cada teste deve ser realizado isoladamente e preparar o ambiente antes de iniciar, levando o sistema ao estado desejado original. A opção mais fácil de fazer isso é usar as anotações @BeforeAll / @BeforeAll e adicionar entradas ao banco de dados usando o repositório, EntityManager ou TestEntityManager . Mas há outra opção que permite executar um script preparado ou executar a consulta SQL desejada, que é a anotação @Sql . Antes de executar o teste, o Spring Boot Test executará automaticamente o script especificado, eliminando a necessidade de adicionar o bloco @BeforeAll , e o @Transactional cuidará da @Transactional dos dados.
@DataJpaTest class JpaCakeFinderTest { private static final String PROMOTED_CAKE = "Red Velvet"; private static final String NON_PROMOTED_CAKE = "Victoria Sponge"; private CakeFinder finder; @Autowired CakeRepository cakeRepository; @Autowired TestEntityManager testEntityManager; @BeforeEach void setUp() { this.testEntityManager.persistAndFlush(CakeEntity.builder().title(PROMOTED_CAKE) .sku("SKU1").price(BigDecimal.TEN).promoted(true).build()); this.testEntityManager.persistAndFlush(CakeEntity.builder().sku("SKU2") .title(NON_PROMOTED_CAKE).price(BigDecimal.ONE).promoted(false).build()); finder = new JpaCakeFinder(cakeRepository); } ... }
Ciclo vermelho-verde-refatorador
Apesar dessa quantidade de texto, para o desenvolvedor, o teste ainda parece uma classe simples com a anotação @DataJpaTest, mas espero que eu tenha sido capaz de mostrar quantas coisas úteis estão acontecendo sob o capô, nas quais o desenvolvedor não consegue pensar. Agora podemos avançar para o ciclo TDD e desta vez mostrarei algumas iterações do TDD, com exemplos de refatoração e código mínimo. Para tornar mais claro, eu recomendo que você analise a história no Git, onde cada commit é uma etapa separada e significativa com uma descrição do que e como ele faz.
Preparação de dados
Eu uso a abordagem com @BeforeAll / @BeforeEach e crio manualmente todos os registros no banco de dados. O exemplo com a anotação @Sql é movido para uma classe separada JpaCakeFinderTestWithScriptSetup , ele duplica os testes, o que, é claro, não deveria existir, e existe com o único objetivo de demonstrar a abordagem.
O estado inicial do sistema - há duas entradas no sistema, um bolo participa da promoção e deve ser incluído no resultado retornado pelo método, o segundo - não.
Primeiro teste de integração de teste
O primeiro teste é o mais simples - findPromotedCakes deve incluir uma descrição e preço do bolo participando da promoção.
Vermelho
@Test void shouldReturnPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle).contains(PROMOTED_CAKE); assertThat(promotedCakes).extracting(Cake::getPrice).contains("£10.00"); }
O teste, é claro, falha - a implementação padrão retorna um conjunto vazio.
Verde
Naturalmente, gostaríamos de escrever imediatamente a filtragem, fazer uma solicitação ao banco de dados com where e assim por diante. Mas, seguindo a prática do TDD, tenho que escrever o código mínimo para que o teste seja aprovado . E esse código mínimo é para retornar todos os registros no banco de dados. Sim, tão simples e brega.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); } private String formatPrice(BigDecimal price) { return "£" + price.setScale(2, RoundingMode.DOWN).toPlainString(); }
Provavelmente, alguns argumentariam que aqui você pode tornar o teste verde mesmo sem uma base - apenas codifique o resultado esperado pelo teste. Ocasionalmente ouço esse argumento, mas acho que todo mundo entende que o TDD não é um dogma ou uma religião, não faz sentido levar isso ao ponto do absurdo. Mas se você realmente deseja, pode, por exemplo, randomizar dados na instalação para que não sejam codificados.
Refatorar
Não vejo muita refatoração aqui, então essa fase pode ser pulada para esse teste em particular. Mas eu ainda não recomendaria ignorar esta fase, é melhor parar e pensar sempre no estado “verde” do sistema - é possível refatorar algo para torná-lo melhor e mais fácil?
Segundo teste
Mas o segundo teste já verificará que nenhum bolo promovido cairá no resultado retornado por findPromotedCakes .
@Test void shouldNotReturnNonPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle) .doesNotContain(NON_PROMOTED_CAKE); }
Vermelho
O teste, como esperado, falha - há dois registros no banco de dados e o código simplesmente retorna todos eles.
Verde
E, novamente, você pode pensar - e qual é o código mínimo que você pode escrever para passar no teste? Como já existe um fluxo e sua montagem, você pode simplesmente adicionar um bloco de filter lá.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false) .filter(cakeEntity -> cakeEntity.promoted) .map(cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
Reiniciamos os testes - os testes de integração agora estão verdes. Chegou um momento importante - devido à combinação do teste de unidade do controlador e do teste de integração para trabalhar com o banco de dados, meu recurso está pronto - e o teste de interface do usuário agora passa!
Refatorar
E como todos os testes são ecológicos - é hora de refatorar. Eu acho que não há necessidade de esclarecer que filtrar na memória não é uma boa ideia, é melhor fazer isso no banco de dados. Para fazer isso, adicionei um novo método no CakesRepository - findByPromotedIsTrue :
interface CakeRepository extends CrudRepository<CakeEntity, String> { Iterable<CakeEntity> findByPromotedIsTrue(); }
Para esse método, o Spring Data gerou automaticamente um método que executará uma consulta no formulário, select from cakes where promoted = true . Leia mais sobre geração de consultas na documentação do Spring Data.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findByPromotedIsTrue() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
Este é um bom exemplo da flexibilidade que os testes de integração e a abordagem da caixa preta fornecem. Se o repositório estava bloqueado, a adição de um novo método sem alterar os testes não era impossível.
Conexão à base de produção
Para adicionar um pouco de "realismo" e mostrar como você pode separar a configuração para testes e o aplicativo principal, adicionarei uma configuração de acesso a dados para o aplicativo "produção".
Tudo é adicionado tradicionalmente pela seção em application.yml :
datasource: url: jdbc:h2:./data/cake-factory
Isso salvará automaticamente os dados no sistema de arquivos na pasta ./data . Observo que esta pasta não será criada nos testes - o @DataJpaTest substituirá automaticamente a conexão com o banco de dados de arquivos por um banco de dados aleatório na memória devido à presença da anotação @AutoConfigureTestDatabase .
, — data.sql schema.sql . , Spring Boot . , , , .
Conclusão
, , , TDD .
Spring Security — Spring, .