"
Empresa " - operadora de telecomunicações PJSC "Megafon"
"
Noda " é o servidor RabbitMQ.
Um "
cluster " é uma combinação, no nosso caso de três, de nós RabbitMQ que funcionam como um todo.
"
Contorno " - um conjunto de clusters RabbitMQ, cujas regras de trabalho são determinadas no balanceador à sua frente.
"
Balancer ", "
hap " - Haproxy - balancer que executa a função de alternar a carga em clusters dentro do loop. Um par de servidores Haproxy em execução em paralelo é usado para cada loop.
"
Subsistema " - o editor e / ou consumidor de mensagens transmitidas através do coelho
"
SISTEMA " - um conjunto de subsistemas, uma solução única de software e hardware usada pela Companhia, caracterizada pela distribuição em toda a Rússia, mas com vários centros onde todas as informações fluem e onde ocorrem os principais cálculos e cálculos.
SYSTEM - um sistema geograficamente distribuído - de Khabarovsk e Vladivostok a São Petersburgo e Krasnodar. Arquitetonicamente, esses são vários contornos centrais, divididos pelos recursos dos subsistemas conectados a eles.
Qual é a tarefa do transporte nas realidades das telecomunicações?
Em poucas palavras: segue a resposta dos subsistemas à ação de cada assinante, que por sua vez informa os outros subsistemas sobre eventos e alterações subseqüentes. As mensagens são geradas por quaisquer ações com o SISTEMA, não apenas dos assinantes, mas também do lado dos funcionários da Empresa e dos Subsistemas (um número muito grande de tarefas é executado automaticamente).
Características do transporte em telecomunicações: fluxo grande, não errado, GRANDE de dados diversos transmitidos por transporte assíncrono.
Alguns subsistemas vivem em Clusters separados devido ao peso dos fluxos de mensagens - simplesmente não há recursos restantes no cluster, por exemplo, com um fluxo de mensagens de 5-6 mil mensagens / segundo, a quantidade de dados transferidos pode atingir 170-190 Megabytes / segundo. Com esse perfil de carga, uma tentativa de desembarcar qualquer outra pessoa neste cluster levará a tristes conseqüências: como não há recursos suficientes para processar todos os dados ao mesmo tempo, o coelho começará a direcionar as conexões de entrada - um processo simples de publicação começará, com todas as conseqüências para todos os subsistemas e sistemas em inteiro.
Requisitos básicos para o transporte:
- A acessibilidade dos veículos deve ser de 99,99%. Na prática, isso se traduz em um requisito operacional 24 horas por dia, 7 dias por semana e na capacidade de responder automaticamente a qualquer situação de emergência.
- Segurança dos dados:% de mensagens perdidas no transporte deve tender a 0.
Por exemplo, ao fazer uma chamada, várias mensagens diferentes passam pelo transporte assíncrono. algumas mensagens destinam-se a subsistemas que vivem no mesmo circuito e outras destinam-se à transmissão para nós centrais. A mesma mensagem pode ser reivindicada por vários subsistemas; portanto, na fase de publicação da mensagem no coelho, ela é copiada e enviada para diferentes consumidores. E, em alguns casos, a cópia de mensagens é obrigatoriamente implementada em um circuito intermediário - quando as informações precisam ser fornecidas do circuito em Khabarovsk para o circuito em Krasnodar. A transmissão é feita através de um dos contornos centrais, onde são feitas cópias das mensagens, para os destinatários centrais.
Além dos eventos causados pelas ações do assinante, as mensagens de serviço que trocam os subsistemas passam pelo transporte. Assim, vários milhares de rotas de mensagens diferentes são obtidas, algumas se cruzam, outras existem isoladamente. Basta nomear o número de filas envolvidas nas rotas em diferentes contornos para entender a escala aproximada do mapa de transporte: nos circuitos centrais 600, 200, 260, 15 ... e nos circuitos remotos 80-100 ...
Com esse envolvimento do transporte, os requisitos para 100% de acessibilidade de todos os nós de transporte não parecem mais excessivos. Estamos avançando na implementação desses requisitos.
Como resolvemos tarefas
Além do
RabbitMQ , o
Haproxy é usado para equilibrar a carga e fornecer uma resposta automática a emergências.
Algumas palavras sobre o ambiente de hardware e software em que nossos coelhos existem:
- Todos os servidores coelho são virtuais, com parâmetros de 8 a 12 CPU, 16 Gb Mem, 200 Gb HDD. Como a experiência demonstrou, mesmo o uso de servidores não virtuais assustadores com 90 núcleos e um monte de RAM fornece um pequeno aumento no desempenho a custos significativamente mais altos. Versões usadas: 3.6.6 (na prática - o mais estável de 3.6) com um erlang de 18.3, 3.7.6 com um erlang de 20.1.
- Para o Haproxy, os requisitos são muito mais baixos: 2 CPU, 4 Gb Mem, a versão do haproxy é 1,8 estável. A carga nos recursos em todos os servidores haproxy não excede 15% da CPU / Mem.
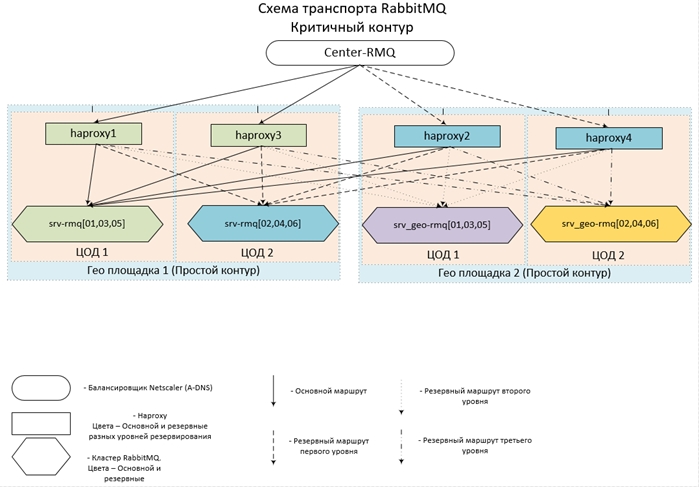
- Todo o zoológico está localizado em 14 data centers em 7 locais em todo o país, unidos em uma única rede. Em cada um dos datacenters, há um cluster de três nós e um hub.
- Para circuitos remotos, são utilizados 2 data centers, para cada um dos circuitos centrais - 4.
- Os circuitos centrais interagem entre si, bem como com os circuitos remotos; por sua vez, os circuitos remotos funcionam apenas com os circuitos centrais; eles não têm comunicação direta entre si.
- As configurações de Haps e Clusters dentro do mesmo circuito são completamente idênticas. O ponto de entrada para cada circuito é um alias para vários registros A-DNS. Assim, para impedir que isso aconteça, pelo menos um hap e pelo menos um dos Clusters (pelo menos um nó no Cluster) em cada Circuito estarão disponíveis. Como o caso de falha de até 6 servidores em dois data centers ao mesmo tempo é extremamente improvável, a aceitabilidade é assumida como próxima de 100%.
Parece concebido (e implementado) tudo isso assim:

Agora algumas configurações.
Configuração Haproxy| frontend center-rmq_5672 | |
| amarrar | *: 5672 |
| modo | tcp |
| maxconn | 10.000 |
| cliente de tempo limite | 3h |
| opção | tcpka |
| opção | tcplog |
| default_backend | center-rmq_5672 |
| frontend center-rmq_5672_lvl_1 | |
| amarrar | localhost: 56721 |
| modo | tcp |
| maxconn | 10.000 |
| cliente de tempo limite | 3h |
| opção | tcpka |
| opção | tcplog |
| default_backend | center-rmq_5672_lvl_1 |
| backend center-rmq_5672 |
| equilibrar | lessconn |
| modo | tcp |
| fullconn | 10.000 |
| timeout | servidor 3h |
| servidor | srv-rmq01 10/10/10/10/106767 cheque inter 5s aumento 2 queda 3 sessões de desligamento-backup-marcadas |
| servidor | srv-rmq03 10/10/10/2011 11672 check inter 5s aumento 2 queda 3 sessões de desligamento-backup-marcadas |
| servidor | srv-rmq05 10/10/10/126767 cheque inter 5s aumento 2 queda 3 sessões de desligamento-backup-marcadas |
| servidor | localhost 127.0.0.1 6721 check inter 5s aumento 2 queda 3 backup em sessões de desligamento marcadas para baixo |
| backend center-rmq_5672_lvl_1 |
| equilibrar | lessconn |
| modo | tcp |
| fullconn | 10.000 |
| timeout | servidor 3h |
| servidor | srv-rmq02 10/10/10/136767 cheque inter 5s aumento 2 queda 3 sessões de desligamento-backup-marcadas |
| servidor | srv-rmq04 10/10/10/14/1067 cheque inter 5s aumento 2 queda 3 em sessões marcadas de desligamento-backup |
| servidor | srv-rmq06 10.10.10.5.0767 cheque inter 5s aumento 2 queda 3 sessões de desligamento-backup-marcadas |
A primeira seção da frente descreve o ponto de entrada - levando ao cluster principal, a segunda seção é projetada para equilibrar o nível de reserva. Se você simplesmente descrever todos os servidores de backup de coelho na seção de back-end (instruções de backup), funcionará da mesma maneira - se o cluster principal estiver completamente inacessível, as conexões irão para o backup, no entanto, todas as conexões irão para o PRIMEIRO servidor de backup na lista. Para garantir o balanceamento de carga em todos os nós de backup, apenas apresentamos mais uma frente, que disponibilizamos apenas com o host local e atribuímos a ele o servidor de backup.
O exemplo acima descreve o balanceamento do loop remoto - que opera em dois datacenters: o servidor srv-rmq {01,03,05} - vive no datacenter nº 1, srv-rmq {02,04,06} - no datacenter nº 2. Portanto, para implementar a solução de quatro coda, precisamos adicionar apenas mais duas frentes locais e duas seções de back-end dos servidores coelho correspondentes.
O comportamento do balanceador com esta configuração é o seguinte: Enquanto pelo menos um servidor principal estiver ativo, nós o usamos. Se os principais servidores não estiverem disponíveis, trabalhamos com uma reserva. Se pelo menos um servidor principal estiver disponível, todas as conexões com os servidores de backup serão desconectadas e, quando a conexão for restaurada, elas já estarão no Cluster primário.
A experiência operacional dessa configuração mostra quase 100% de disponibilidade de cada um dos circuitos. Essa solução exige que os subsistemas sejam completamente legais e simples: sejam capazes de se reconectar com o coelho após desconectar.
Portanto, fornecemos balanceamento de carga para um número arbitrário de clusters e alternamos automaticamente entre eles, é hora de ir diretamente para os coelhos.
Cada cluster é criado a partir de três nós, como mostra a prática - o número mais ótimo de nós, o que garante o equilíbrio ideal entre disponibilidade / tolerância a falhas / velocidade. Como o coelho não é dimensionado horizontalmente (o desempenho do cluster é igual ao desempenho do servidor mais lento), criamos todos os nós com os mesmos parâmetros ideais para CPU / Mem / Hdd. Posicionamos os servidores o mais próximo possível - no nosso caso, estamos arquivando máquinas virtuais no mesmo farm.
Quanto às condições prévias, as quais, por parte dos Subsistemas, garantirão a operação e o cumprimento mais estáveis do requisito de salvar as mensagens recebidas:
- O trabalho com o coelho é somente via protocolo amqp / amqps - através do balanceamento. Autorização em contas locais - dentro de cada cluster (poço e todo o circuito)
- Os subsistemas são conectados ao coelho no modo passivo: nenhuma manipulação com as entidades dos coelhos (criação de filas / exchendzhe / bind) é permitida e limitada no nível de direitos de conta - simplesmente não concedemos direitos de configuração.
- Todas as entidades necessárias são criadas centralmente, não por meio de subsistemas, e em todos os Clusters de cluster são feitas da mesma maneira - para garantir a alternância automática para o Cluster de backup e vice-versa. Caso contrário, podemos obter uma imagem: mudamos para a reserva, mas a fila ou a ligação não existe, e podemos escolher um erro de conexão ou perda de mensagens.
Agora configurações diretamente em coelhos:
- Os hosts locais não têm acesso à interface da web
- O acesso à Web é organizado por meio do LDAP - nos integramos ao AD e registramos quem e onde foi na webcam. No nível da configuração, restringimos os direitos das contas do AD, não apenas exigimos estar em um determinado grupo, mas também concedemos direitos de "ver". Grupos de monitoramento são mais que suficientes. E suspendemos os direitos de administrador em outro grupo no AD, portanto, o círculo de influência no transporte é bastante limitado.
- Para facilitar a administração e o rastreamento:
Em todos os VHOSTs, desligamos imediatamente uma política de nível 0 com aplicação em todas as filas (padrão :. *):
- ha-mode: all - armazena todos os dados em todos os nós do cluster, a velocidade de processamento das mensagens diminui, mas sua segurança e disponibilidade são garantidas.
- ha-sync-mode: automatic - instrui o rastreador a sincronizar dados automaticamente em todos os nós do cluster: a segurança e a disponibilidade dos dados também aumentam.
- modo de fila: preguiçoso - talvez uma das opções mais úteis que apareceram em coelhos desde a versão 3.6 - gravação imediata de mensagens no disco rígido. Essa opção reduz drasticamente o consumo de RAM e aumenta a segurança dos dados durante paradas / quedas de nós ou no cluster como um todo.
- Configurações no arquivo de configuração ( rabbitmq-main / conf / rabbitmq.config ):
- Coelho de seção: {vm_memory_high_watermark_paging_ratio, 0.5} - limite para baixar mensagens no disco 50%. Com o preguiçoso ativado, ele serve mais como seguro quando desenhamos uma política, por exemplo, nível 1, na qual esquecemos de incluir o preguiçoso .
- {vm_memory_high_watermark, 0,95} - limitamos o coelho a 95% da RAM total, uma vez que apenas o coelho vive nos servidores, não faz sentido introduzir restrições mais rigorosas. 5% "amplo gesto" assim seja - deixe o sistema operacional, monitoramento e outras pequenas coisas úteis. Como esse valor é o limite superior, há o suficiente para todos.
- {cluster_partition_handling, pause_minority} - descreve o comportamento do cluster quando a Partição de Rede ocorre, para três ou mais clusters de nós, esse sinalizador é recomendado - permite que o cluster se recupere.
- {disk_free_limit, "500MB"} - tudo é simples, quando há 500 MB de espaço livre em disco - a publicação de mensagens será interrompida, apenas subtração estará disponível.
- {auth_backends, [rabbit_auth_backend_internal, rabbit_auth_backend_ldap]} - ordem de autorização para coelhos: Primeiro, a presença de um ultrassom no banco de dados local é verificada e, caso contrário, vá para o servidor LDAP.
- Seção rabbitmq_auth_backend_ldap - configuração para interação com o AD: {servers, ["srv_dc1", "srv_dc2"]]} - uma lista de controladores de domínio nos quais a autenticação ocorrerá.
- Os parâmetros que descrevem diretamente o usuário no AD, a porta LDAP e assim por diante são puramente individuais e são descritos em detalhes na documentação.
- O mais importante para nós é uma descrição dos direitos e restrições de administração e acesso à interface da Web de coelhos: tag_queries:
[{administrator, {in_group ", cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = Meu_domínio, dc = ru"}},
{monitoramento,
{in_group ", cn = rabbitmq-web, ou = GRP, ou = GRP_MAIN, dc = Meu_domínio, dc = ru"}
}] - esse design fornece privilégios administrativos para todos os usuários do grupo rabbitmq-admins e direitos de monitoramento (minimamente suficientes para visualizar o acesso) para o grupo rabbitmq-web.
- resource_access_query :
{para,
[{permissão, configuração, {no_grupo ", cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = Meu_domínio, dc = ru"}},
{permissão, gravação, {no_grupo ", cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = Meu_domínio, dc = ru"}},
{permissão, leitura, {constante, verdadeiro}}
]
} - fornecemos os direitos de configurar e gravar apenas para o grupo de administradores, para todos os que efetuam login com êxito, os direitos são somente leitura - ele pode ler mensagens através da interface da Web.
Obtemos um cluster configurado (no nível do arquivo de configuração e das configurações no próprio coelho) que maximiza a disponibilidade e a segurança dos dados. Com isso, implementamos o requisito - garantindo a disponibilidade e a segurança dos dados ... na maioria dos casos.
Há vários pontos que devem ser considerados ao operar esses sistemas altamente carregados:
- É melhor organizar todas as propriedades adicionais das filas (TTL, expirar, comprimento máximo etc.) pelos políticos, em vez de interromper os parâmetros ao criar filas. Acontece uma estrutura flexível e personalizável que pode ser personalizada rapidamente para mudar as realidades.
- Usando TTL. Quanto maior a fila, maior a carga na CPU. Para evitar "romper o teto", é melhor limitar também o comprimento da fila via comprimento máximo.
- Além do próprio coelho, vários aplicativos utilitários estão girando no servidor, o que, curiosamente, também requer recursos da CPU. Um coelho guloso, por padrão, ocupa todos os núcleos disponíveis ... Uma situação desagradável pode acontecer: uma luta por recursos, que pode facilmente levar a freios no coelho. Para evitar a ocorrência de tal situação, por exemplo, da seguinte forma: Altere os parâmetros do lançamento do erlang - introduza um limite obrigatório no número de núcleos usados. Fazemos o seguinte: localize o arquivo rabbitmq-env , procure o parâmetro SERVER_ERL_ARGS = e adicione + sct L0-Xc0-X + SY: Y a ele. Onde X é o número de núcleos-1 (a contagem começa em 0), Y - O número de núcleos -1 (contando em 1). + sct L0-Xc0-X - altera a ligação aos kernels, + SY: Y - altera o número de shedulers iniciados pelo erlang. Portanto, para um sistema de 8 núcleos, os parâmetros adicionados terão a forma: + sct L0-6c0-6 + S 7: 7. Dessa maneira, damos ao coelho apenas 7 núcleos e esperamos que o sistema operacional, ao lançar outros processos, atue de maneira ideal e os pendure em um kernel descarregado.
As nuances da operação do zoológico resultante
O que qualquer configuração não pode proteger é a base colapsada da mnésia - infelizmente, isso acontece com uma probabilidade diferente de zero. Um resultado tão desastroso não é causado por falhas globais (por exemplo, uma falha completa de um data center inteiro - a carga simplesmente mudará para outro cluster), mas mais falhas locais - dentro do mesmo segmento de rede.
Além disso, são assustadoras as falhas na rede local, porque o desligamento de emergência de um ou dois nós não levará a consequências fatais - simplesmente todas as solicitações vão para um nó e, como lembramos, o desempenho depende do desempenho apenas do próprio nó. Falhas na rede (não levamos em conta pequenas interrupções na comunicação - elas ocorrem sem dor) levam a uma situação em que os nós iniciam o processo de sincronização entre si e, em seguida, a conexão é interrompida várias vezes por alguns segundos.
Por exemplo, várias piscadas na rede e com uma frequência de mais de 5 segundos (exatamente esse tempo limite é definido nas configurações do Hapov, você certamente pode reproduzi-las, mas para verificar a eficácia, será necessário repetir a falha, o que ninguém deseja).
O cluster ainda pode suportar uma ou duas dessas iterações, mas mais - as chances já são mínimas. Em tal situação, a parada de um nó caído pode ser salva, mas é quase impossível fazê-lo manualmente. Mais frequentemente, o resultado não é apenas a perda de um nó do cluster com a mensagem
“Partição de rede” , mas também a imagem em que os dados da parte das filas viviam apenas nesse nó e não tinham tempo para sincronizar com os demais. Visualmente - na fila, os dados são
NaN .
E agora esse é um sinal inequívoco - mude para o cluster de backup. A mudança fornecerá um hap, você só precisa interromper os coelhos no cluster principal - em questão de alguns minutos. Como resultado, obtemos a restauração da capacidade de trabalho do transporte e podemos proceder com segurança à análise do acidente e sua eliminação.
Para remover um aglomerado danificado da carga, a fim de evitar mais degradação, a coisa mais simples é fazer o coelho trabalhar em portas que não sejam 5672. Como estamos monitorando os coelhos pela porta normal, seu deslocamento, por exemplo, 5673 nas configurações do coelho, ele permitirá que você inicie completamente o cluster sem problemas e tente restaurar sua operacionalidade e as mensagens restantes nele.
Fazemos isso em algumas etapas:
- Pare todos os nós do cluster com falha - o hap mudará a carga para o cluster de backup
- RABBITMQ_NODE_PORT=5673 rabbitmq-env – , Web - 15672.
- .
Na inicialização, os índices serão reconstruídos e, na grande maioria dos casos, todos os dados serão restaurados na íntegra. Infelizmente, ocorrem falhas que resultam na exclusão física de todas as mensagens do disco, deixando apenas a configuração - os diretórios msg_store_persistent , msg_store_transient , as filas (para a versão 3.6) ou msg_stores (para a versão 3.7) são excluídos na pasta do banco de dados .Após essa terapia radical, o cluster é lançado com a preservação da estrutura interna, mas sem mensagens.E a opção mais desagradável (observada uma vez): os danos à base eram de tal ordem que era necessário remover completamente toda a base e reconstruir o cluster do zero.Para a conveniência de gerenciar e atualizar coelhos, não é usada uma montagem pronta em rpm, mas um coelho desmontado com cpio e reconfigurado (alterado os caminhos nos scripts). A principal diferença: não requer privilégios de root para instalar / configurar, não está instalado no sistema (o coelho reconstruído é perfeitamente compactado em tgz) e é executado a partir de qualquer usuário. Essa abordagem permite atualizar de forma flexível as versões (se não exigir uma parada completa do cluster - nesse caso, basta alternar para o cluster de backup e atualizar, sem esquecer de especificar a porta deslocada para operação). É até possível executar várias instâncias do RabbitMQ na mesma máquina - a opção é muito conveniente para testes - você pode implantar uma cópia arquitetural reduzida do zoológico de batalha.Como resultado do xamanismo com cpio e caminhos nos scripts, obtivemos uma opção de construção: duas pastas rabbitmq-base (na montagem original - a pasta mnesia) e rabbimq-main - aqui coloquei todos os scripts necessários do rabbit e erlang-se.Em rabbimq-main / bin - links simbólicos para scripts rabbit e erlang e um script de rastreamento de coelho (descrição abaixo).Em rabbimq-main / init.d - o script rabbitmq-server através do qual os logs iniciam / param / giram; em lib, o próprio coelho; na lib64 - erlang (usando uma versão simplificada, apenas para coelhos, de erlang).É extremamente fácil atualizar o assembly resultante quando novas versões são lançadas - adicione o conteúdo de rabbimq-main / lib e rabbimq-main / lib64 das novas versões e substitua os links simbólicos no bin. Se a atualização também afetar os scripts de controle - basta alterar os caminhos para os nossos.Uma vantagem significativa dessa abordagem é a continuidade completa das versões - todos os caminhos, scripts, comandos de controle permanecem inalterados, o que permite o uso de qualquer script de utilitário auto-escrito sem dopagem para cada versão.Desde a queda dos coelhos, embora rara, mas ocorrendo, era necessário implementar um mecanismo para monitorar seu bem-estar - elevar em caso de queda (mantendo os registros das razões da queda). A falha de um nó em 99% dos casos é acompanhada de uma entrada de log, e até mata até deixa rastros, o que possibilitou implementar o monitoramento do estado do coelho usando um script simples.Para as versões 3.6 e 3.7, o script é um pouco diferente devido às diferenças nas entradas do log.Para 3.7, apenas duas linhas são alteradas if (os.path.isfile('/data/logs/rabbitmq/startup_log')) and (os.path.isfile('/data/logs/rabbitmq/startup_err')): if ((b' OK ' in LastRow('/data/logs/rabbitmq/startup_log')) or (b'FAILED' in LastRow('/data/logs/rabbitmq/startup_log'))) and not (b'Gracefully halting Erlang VM' in LastRow('/data/logs/rabbitmq/startup_err')):
Configuramos uma conta crontab sob a qual o coelho funcionará (por padrão rabbitmq) executando este script (nome do script: check_and_run) a cada minuto (primeiro, solicitamos ao administrador que dê à conta o direito de usar o crontab, mas se tivermos direitos de root, nós mesmos o faremos):
* / 1 * * * * ~ / rabbitmq-main / bin / check_and_runO segundo ponto do uso do coelho remontado é a rotação dos toros.
Como não estamos vinculados ao sistema de logrotate, usamos a funcionalidade fornecida pelo desenvolvedor: o script
rabbitmq-server do init.d (para a versão 3.6)
Fazendo pequenas alterações em
rotate_logs_rabbitmq ()Adicionar:
find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.log.*.back -maxdepth 0 -type f | xargs -i gzip {} find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
O resultado da execução do script rabbitmq-server com a chave rotate-logs: logs são compactados pelo gzip e armazenados apenas nos últimos 30 dias.
http_api - o caminho em que o coelho coloca os logs http - configurado no arquivo de configuração:
{rabbitmq_management, [{rates_mode, detail}, {http_log_dir, path_to_logs / http_api "}]}Ao mesmo tempo,
presto atenção a
{rates_mode, detail} - a opção aumenta um pouco a carga, mas permite que você veja informações sobre o usuário que publica mensagens no EXCHENGE na interface WEB (e, portanto, acessa a API). A informação é extremamente necessária, porque todas as conexões passam pelo balanceador - veremos apenas o IP dos próprios balanceadores. E se você confundir todos os subsistemas que trabalham com o coelho para que eles preencham os parâmetros de propriedades do cliente nas propriedades de suas conexões com os coelhos, será possível obter informações detalhadas no nível da conexão sobre quem exatamente, onde e com que intensidade publica as mensagens.
Com o lançamento das novas versões 3.7, houve uma rejeição completa do script
rabbimq-server no init.d. Para facilitar a operação (a uniformidade dos comandos de controle, independentemente da versão do coelho) e uma transição mais suave entre as versões, no coelho remontado, continuamos a usar esse script. A verdade é outra vez:
mudaremos um pouco
rotate_logs_rabbitmq () , pois o mecanismo para nomear logs após a rotação mudou na
versão 3.7:
mv ${RABBITMQ_LOG_BASE}/$NODENAME.log.0 ${RABBITMQ_LOG_BASE}/$NODENAME.log.$(date +%Y%m%d-%H%M%S).back mv ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.0 ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.$(date +%Y%m%d-%H%M%S).back find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
Agora, resta apenas adicionar a tarefa de rotação de log ao crontab - por exemplo, todos os dias às 23h:
00 23 * * * ~ / rabbitmq-main / init.d / rabbitmq-server rotate-logsVamos seguir para as tarefas que precisam ser resolvidas no âmbito da operação da "fazenda de coelhos":
- Manipulações com entidades de coelho - criação / exclusão de entidades de coelho: ekschendzhey, filas, ligações, pás, usuários, políticas. E fazer isso é absolutamente idêntico em todos os Clusters de Cluster.
- Após alternar para / do cluster de backup, é necessário transferir as mensagens que permaneceram nele para o cluster atual.
- Criando cópias de backup das configurações de todos os Clusters de todos os circuitos
- Sincronização completa das configurações de Cluster no Contour
- Parar / iniciar coelhos
- Para analisar os fluxos de dados atuais: todas as mensagens são enviadas e, se forem, então para onde devem ir ou ...
- Encontre e capture mensagens que passam por qualquer critério
A operação do nosso zoológico e a solução de tarefas
sonoras por meio do plug-in
rabbitmq_management regular fornecido é possível, mas extremamente inconveniente, e é por isso que um shell foi desenvolvido e implementado para
controlar toda a variedade de coelhos .