Neste tutorial, mostrarei como escrever sua própria máquina virtual (VM) que pode executar programas assembler como
2048 (meu amigo) ou
Roguelike (meu). Se você sabe programar, mas deseja entender melhor o que está acontecendo dentro do computador e como as linguagens de programação funcionam, esse projeto é para você. Escrever sua própria máquina virtual pode parecer um pouco assustador, mas prometo que o tópico é surpreendentemente simples e instrutivo.
O código final possui cerca de 250 linhas em C. É suficiente conhecer apenas o básico de C ou C ++, como
aritmética binária . Qualquer sistema Unix (incluindo o macOS) é adequado para construção e execução. Várias APIs do Unix são usadas para configurar a entrada e a exibição do console, mas elas não são essenciais para o código principal. (A implementação do suporte do Windows é apreciada).
Nota: esta VM é um programa competente . Ou seja, você já está lendo o código fonte no momento! Cada pedaço de código será mostrado e explicado em detalhes, para que você tenha certeza de que nada está faltando. O código final é criado por um plexo de blocos de código. Repositório do projeto aqui .
1. Conteúdos
- Sumário
- 1. Introdução
- Arquitetura LC-3
- Exemplos de assembler
- Execução do programa
- Implementação de instruções
- Instruções Cheat Sheet
- Procedimentos de processamento de interrupção
- Folha de dicas para rotinas de interrupção
- Download de software
- Registros Mapeados na Memória
- Recursos da plataforma
- Inicialização da máquina virtual
- Método alternativo em C ++
2. Introdução
O que é uma máquina virtual?
Uma máquina virtual é um programa que age como um computador. Ele simula um processador com vários outros componentes de hardware, permitindo executar aritmética, ler e gravar na memória e interagir com dispositivos de entrada / saída como um computador físico real. Mais importante ainda, a VM entende uma linguagem de máquina que você pode usar para programação.
A quantidade de hardware que uma VM específica simula depende de sua finalidade. Algumas VMs reproduzem o comportamento de um computador específico. As pessoas não têm mais o NES, mas ainda podemos jogar para o NES simulando o hardware no nível do software. Esses emuladores devem
recriar com precisão todos os
detalhes e todos os principais componentes de hardware do dispositivo original.
Outras VMs não correspondem a nenhum computador em particular, mas correspondem parcialmente a várias de uma vez! Isso é feito principalmente para facilitar o desenvolvimento de software. Imagine que você deseja criar um programa que é executado em várias arquiteturas de computadores. A máquina virtual fornece uma plataforma padrão que fornece portabilidade. Não há necessidade de reescrever o programa em diferentes dialetos do assembler para cada arquitetura. Basta fazer apenas uma pequena VM em cada idioma. Depois disso, qualquer programa pode ser gravado apenas uma vez na linguagem assembly de uma máquina virtual.
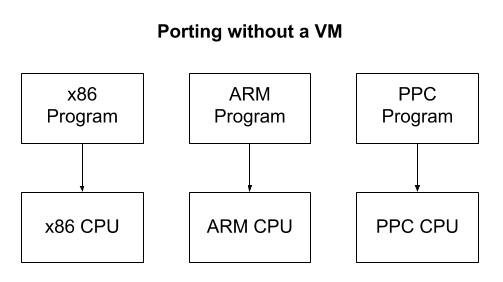

Nota: o compilador resolve esses problemas, compilando uma linguagem de alto nível padrão para diferentes arquiteturas de processador. A VM cria uma arquitetura de CPU padrão que é simulada em vários dispositivos de hardware. Uma das vantagens do compilador é que não há sobrecarga de tempo de execução como a VM. Embora os compiladores funcionem bem, escrever um novo compilador para várias plataformas é muito difícil, portanto, as VMs ainda são úteis. Na realidade, em diferentes níveis, VM e compiladores são usados juntos.
A Java Virtual Machine (JVM) é um exemplo de muito sucesso. A própria JVM é de tamanho relativamente médio; é pequena o suficiente para um programador entender. Isso permite que você escreva códigos para milhares de dispositivos diferentes, incluindo telefones. Após implementar a JVM no novo dispositivo, qualquer programa Java, Kotlin ou Clojure gravado pode trabalhar nele sem alterações. Os únicos custos serão apenas a sobrecarga da própria VM e
a abstração adicional do nível da máquina. Geralmente, esse é um bom compromisso.
Uma VM não precisa ser grande ou onipresente para fornecer benefícios semelhantes. Os
videogames mais antigos costumavam usar pequenas VMs para criar
sistemas de script simples.
As VMs também são úteis para isolar programas com segurança. Um aplicativo é a coleta de lixo.
Não há uma maneira trivial de implementar a coleta automática de lixo em cima de C ou C ++, pois o programa não pode ver sua própria pilha ou variáveis. No entanto, a VM está "fora" do programa em execução e pode observar todas as
referências a células de memória na pilha.
Outro exemplo desse comportamento é demonstrado pelos
contratos inteligentes da Ethereum . Contratos inteligentes são pequenos programas executados por cada nó de validação no blockchain. Ou seja, os operadores permitem a execução em suas máquinas de qualquer programa gravado por completamente estranhos, sem a oportunidade de estudá-los com antecedência. Para impedir ações maliciosas, elas são executadas em uma
VM que não tem acesso ao sistema de arquivos, rede, disco, etc. Ethereum também é um bom exemplo de portabilidade. Graças à VM, você pode escrever contratos inteligentes sem levar em conta os recursos de muitas plataformas.
3. Arquitetura LC-3
Nossa VM simulará um computador fictício chamado
LC-3 . É popular para ensinar aos alunos assembler. Aqui, um conjunto simplificado de comandos
comparado ao x86 , mas mantém todos os conceitos básicos que são usados nas CPUs modernas.
Primeiro, você precisa simular os componentes de hardware necessários. Tente entender o que é cada componente, mas não se preocupe se não tiver certeza de como ele se encaixa no cenário geral. Vamos começar criando um arquivo em C. Cada pedaço de código desta seção deve ser colocado no escopo global deste arquivo.
A memória
O LC-3 possui 65.536 células de memória (2
16 ), cada uma das quais contém um valor de 16 bits. Isso significa que ele só pode armazenar 128 KB - muito menos do que você está acostumado! Em nosso programa, essa memória é armazenada em uma matriz simples:
uint16_t memory[UINT16_MAX];
Registros
Um registro é um slot para armazenar um valor na CPU. Os registros são como um "ambiente de trabalho" da CPU. Para que ele possa trabalhar com alguns dados, ele deve estar em um dos registros. Porém, como existem apenas alguns registros, apenas uma quantidade mínima de dados pode ser baixada a qualquer momento. Os programas solucionam esse problema carregando valores da memória nos registradores, calculando valores em outros registradores e armazenando os resultados finais novamente na memória.
Existem apenas 10 registros no LC-3, cada um com 16 bits. A maioria deles é de uso geral, mas alguns têm funções atribuídas.
- 8 registradores de uso geral (
R0-R7 ) - 1 registro do contador de equipes (
PC ) - 1 registro de sinalizador de condição (
COND )
Registradores de uso geral podem ser usados para executar qualquer cálculo de software. O contador de instruções é um número inteiro não assinado que é o endereço de memória da próxima instrução a ser executada. Os sinalizadores de condição informam sobre o cálculo anterior.
enum { R_R0 = 0, R_R1, R_R2, R_R3, R_R4, R_R5, R_R6, R_R7, R_PC, R_COND, R_COUNT };
Como a memória, armazenaremos os registros em uma matriz:
uint16_t reg[R_COUNT];
Conjunto de instruções
Uma instrução é um comando que informa ao processador para executar algum tipo de tarefa fundamental, por exemplo, adicionar dois números. A instrução possui um
opcode (código de operação) indicando o tipo de tarefa que está sendo executada, bem como um conjunto de
parâmetros que fornecem entrada para a tarefa que está sendo executada.
Cada
opcode representa uma tarefa que o processador "sabe" como executar. Existem 16 opcodes no LC-3. Um computador pode calcular apenas a sequência dessas instruções simples. O comprimento de cada instrução é 16 bits e os 4 bits esquerdos armazenam o código de operação. O restante é usado para armazenar parâmetros.
Mais tarde discutiremos em detalhes o que cada instrução faz. Defina os seguintes opcodes no momento. Certifique-se de manter este pedido para obter o valor de enum correto:
enum { OP_BR = 0, OP_ADD, OP_LD, OP_ST, OP_JSR, OP_AND, OP_LDR, OP_STR, OP_RTI, OP_NOT, OP_LDI, OP_STI, OP_JMP, OP_RES, OP_LEA, OP_TRAP };
Nota: A arquitetura Intel x86 possui centenas de instruções, enquanto outras arquiteturas como ARM e LC-3 são muito poucas. Conjuntos pequenos de instruções são chamados RISC , enquanto conjuntos maiores são chamados CISC . Geralmente , grandes conjuntos de instruções não fornecem recursos fundamentalmente novos, mas frequentemente simplificam a escrita do código do assembler . Uma instrução CISC pode substituir várias instruções RISC. No entanto, os processadores CISC são mais complexos e caros para projetar e fabricar. Essa e outras compensações não permitem chamar o design "ideal" .
Sinalizadores de condição
O registro
R_COND armazena sinalizadores de condição que fornecem informações sobre o último cálculo realizado. Isso permite que os programas verifiquem condições lógicas, como
if (x > 0) { ... } .
Cada processador possui muitos sinalizadores de status para sinalizar várias situações. O LC-3 usa apenas três sinalizadores de condição que mostram o sinal do cálculo anterior.
enum { FL_POS = 1 << 0, FL_ZRO = 1 << 1, FL_NEG = 1 << 2, };
Nota: (O caractere << é chamado de operador de deslocamento à esquerda . (n << k) move os bits n esquerda por k lugares. Assim, 1 << 2 é igual a 4 Leia aqui se você não estiver familiarizado com o conceito. Isso será muito importante).
Concluímos a configuração dos componentes de hardware da nossa máquina virtual! Depois de adicionar inclusões padrão (veja o link acima), seu arquivo deve se parecer com o seguinte:
{Includes, 12} {Registers, 3} {Opcodes, 3} {Condition Flags, 3}
Aqui estão os links para as seções numeradas do artigo, de onde vêm os fragmentos de código correspondentes. Para uma lista completa, consulte o programa de trabalho - aprox. trans.4. Exemplos de assembler
Agora, vejamos o programa assembler LC-3 para ter uma idéia do que a máquina virtual realmente faz. Você não precisa saber como programar no assembler ou entender tudo aqui. Apenas tente ter uma idéia geral do que está acontecendo. Aqui está um simples "Olá Mundo":
.ORIG x3000 ; this is the address in memory where the program will be loaded LEA R0, HELLO_STR ; load the address of the HELLO_STR string into R0 PUTs ; output the string pointed to by R0 to the console HALT ; halt the program HELLO_STR .STRINGZ "Hello World!" ; store this string here in the program .END ; mark the end of the file
Como em C, o programa executa uma instrução de cima para baixo. Mas, diferentemente de C, não há áreas aninhadas
{} ou estruturas de controle como
if ou
while ; apenas uma lista simples de operadores. Portanto, é muito mais fácil de executar.
Observe que os nomes de alguns operadores correspondem aos códigos de operação que definimos anteriormente. Sabemos que as instruções são de 16 bits, mas cada linha parece com um número diferente de caracteres. Como é possível uma incompatibilidade?
Isso ocorre porque o código que estamos lendo é escrito em
linguagem assembly - em texto sem formatação, legível e gravável. Uma ferramenta, chamada
assembler , converte cada linha de texto em uma instrução binária de 16 bits que uma máquina virtual entende. Essa forma binária, que é essencialmente uma matriz de instruções de 16 bits, é chamada de
código de máquina e é realmente executada por uma máquina virtual.
Nota: embora o compilador e o montador tenham um papel semelhante no desenvolvimento, eles não são os mesmos. O assembler simplesmente codifica o que o programador escreveu no texto, substituindo os caracteres por sua representação binária e colocando-os em instruções.
Os
.STRINGZ e
.STRINGZ parecem instruções, mas não. Essas são diretivas de assembler que geram parte do código ou dados. Por exemplo,
.STRINGZ insere uma sequência de caracteres em um local especificado em um programa binário.
Loops e condições são executados usando uma instrução goto-like. Aqui está outro exemplo que conta até 10.
AND R0, R0, 0 ; clear R0 LOOP ; label at the top of our loop ADD R0, R0, 1 ; add 1 to R0 and store back in R0 ADD R1, R0, -10 ; subtract 10 from R0 and store back in R1 BRn LOOP ; go back to LOOP if the result was negative ... ; R0 is now 10!
Nota: este tutorial não precisa aprender a montagem. Mas se você estiver interessado, pode escrever e criar seus próprios programas LC-3 usando as Ferramentas LC-3 .
5. Execução do programa
Mais uma vez, os exemplos anteriores apenas dão uma idéia do que a VM faz. Para escrever uma VM, você não precisa de um entendimento completo do assembler. Desde que você siga o procedimento apropriado para ler e executar instruções,
qualquer programa LC-3 funcionará corretamente, independentemente de sua complexidade. Em teoria, uma VM pode até rodar um navegador ou um sistema operacional como o Linux!
Se você pensa profundamente, essa é uma ideia filosoficamente maravilhosa. Os próprios programas podem produzir ações arbitrariamente complexas que nunca esperávamos e que talvez não consigamos entender. Mas, ao mesmo tempo, toda a sua funcionalidade é limitada ao código simples, que escreveremos! Ao mesmo tempo, sabemos tudo e nada sobre como cada programa funciona. Turing mencionou essa idéia maravilhosa:
“A opinião de que as máquinas não podem surpreender uma pessoa com nada se baseia, acredito, em um erro, do qual matemáticos e filósofos são particularmente propensos. Quero dizer a suposição de que, como algum fato se tornou propriedade da mente, imediatamente todas as consequências desse fato se tornarão propriedade da mente. ” - Alan M. Turing
Procedimento
Aqui está a descrição exata do procedimento para escrever:
- Faça o download de uma instrução da memória no endereço do registro do
PC . - Aumente
PC registro do PC . - Veja o código de operação para determinar que tipo de instrução seguir.
- Siga as instruções usando seus parâmetros.
- Volte para a etapa 1.
Você pode fazer a pergunta: "Mas se o loop continuar aumentando o contador na ausência de
if ou
while , as instruções não terminarão?" A resposta é não. Como já mencionamos, algumas instruções do tipo goto alteram o fluxo de execução saltando pelo
PC .
Iniciamos o estudo desse processo como um exemplo do ciclo principal:
int main(int argc, const char* argv[]) { {Load Arguments, 12} {Setup, 12} enum { PC_START = 0x3000 }; reg[R_PC] = PC_START; int running = 1; while (running) { uint16_t instr = mem_read(reg[R_PC]++); uint16_t op = instr >> 12; switch (op) { case OP_ADD: {ADD, 6} break; case OP_AND: {AND, 7} break; case OP_NOT: {NOT, 7} break; case OP_BR: {BR, 7} break; case OP_JMP: {JMP, 7} break; case OP_JSR: {JSR, 7} break; case OP_LD: {LD, 7} break; case OP_LDI: {LDI, 6} break; case OP_LDR: {LDR, 7} break; case OP_LEA: {LEA, 7} break; case OP_ST: {ST, 7} break; case OP_STI: {STI, 7} break; case OP_STR: {STR, 7} break; case OP_TRAP: {TRAP, 8} break; case OP_RES: case OP_RTI: default: {BAD OPCODE, 7} break; } } {Shutdown, 12} }
6. Implementação de instruções
Agora sua tarefa é fazer a implementação correta para cada código de operação. Uma especificação detalhada de cada instrução está contida na
documentação do
projeto . A partir da especificação, você precisa descobrir como cada instrução funciona e escrever uma implementação. Isso é mais fácil do que parece. Aqui vou demonstrar como implementar dois deles. O código para o restante pode ser encontrado na próxima seção.
ADICIONAR
A instrução
ADD pega dois números, os adiciona e armazena o resultado em um registro. A especificação está na documentação na página 526. Cada instrução
ADD é a seguinte:
Existem duas linhas no diagrama, porque existem dois "modos" diferentes para esta instrução. Antes de explicar os modos, vamos tentar encontrar as semelhanças entre eles. Ambos começam com quatro bits idênticos
0001 . Este é o valor do opcode para
OP_ADD . Os próximos três bits são marcados como
DR para o registro de saída. O registro de saída é o local onde a quantidade é armazenada. Os três bits a seguir são:
SR1 . Este é um registro que contém o primeiro número a ser adicionado.
Assim, sabemos onde salvar o resultado e o primeiro número a ser adicionado. Resta apenas descobrir o segundo número para adição. Aqui as duas linhas começam a diferir. Observe que o quinto bit é 0 na parte superior e 1. na parte inferior, que corresponde ao
modo direto ou ao
modo de registro . No modo de registro, o segundo número é armazenado no registro, como o primeiro. É marcado como
SR2 e está contido nos bits dois a zero. Os bits 3 e 4 não são usados. No assembler, será escrito assim:
ADD R2 R0 R1 ; add the contents of R0 to R1 and store in R2.
No modo imediato, em vez de adicionar o conteúdo do registro, o valor imediato é incorporado na própria instrução. Isso é conveniente porque o programa não precisa de instruções adicionais para carregar esse número no registro da memória. Em vez disso, ele já está dentro da instrução quando precisamos. O problema é que apenas pequenos números podem ser armazenados lá. Para ser preciso, no máximo 2
5 = 32. Isso é mais útil para aumentar contadores ou valores. No assembler, você pode escrever assim:
ADD R0 R0 1 ; add 1 to R0 and store back in R0
Aqui está um trecho da especificação:
Se o bit [5] for 0, o segundo operando de origem será obtido do SR2. Se o bit [5] for 1, o segundo operando de origem será obtido expandindo imm5 para 16 bits. Nos dois casos, o segundo operando de origem é adicionado ao conteúdo do SR1 e o resultado é armazenado no DR. (p. 526)
Isso é semelhante ao que discutimos. Mas o que é uma "extensão de significado"? Embora no modo direto o valor tenha apenas 5 bits, ele precisa ser adicionado com um número de 16 bits. Esses 5 bits devem ser expandidos para 16 para corresponder a outro número. Para números positivos, podemos preencher os bits ausentes com zeros e obter o mesmo valor. No entanto, para números negativos, isso não funciona. Por exemplo, -1 em cinco bits é
1 1111 . Se você apenas preencher com zeros, obteremos
0000 0000 0001 1111 , que é 32! A expansão do valor evita esse problema preenchendo os bits com zeros para números positivos e os com números negativos.
uint16_t sign_extend(uint16_t x, int bit_count) { if ((x >> (bit_count - 1)) & 1) { x |= (0xFFFF << bit_count); } return x; }
Nota: se você estiver interessado em números binários negativos, pode ler sobre códigos adicionais . Mas isso não é essencial. Basta copiar o código acima e usá-lo quando a especificação indicar para expandir o valor.
A especificação tem a última frase:
Os códigos de condição são definidos dependendo do resultado ser negativo, zero ou positivo. (p. 526)
Anteriormente, definimos a condição de enumeração de sinalizadores e agora é hora de usá-los. Cada vez que um valor é gravado no registro, precisamos atualizar os sinalizadores para indicar seu sinal. Escrevemos uma função para reutilização:
void update_flags(uint16_t r) { if (reg[r] == 0) { reg[R_COND] = FL_ZRO; } else if (reg[r] >> 15) { reg[R_COND] = FL_NEG; } else { reg[R_COND] = FL_POS; } }
Agora estamos prontos para escrever o código para
ADD :
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t r1 = (instr >> 6) & 0x7; uint16_t imm_flag = (instr >> 5) & 0x1; if (imm_flag) { uint16_t imm5 = sign_extend(instr & 0x1F, 5); reg[r0] = reg[r1] + imm5; } else { uint16_t r2 = instr & 0x7; reg[r0] = reg[r1] + reg[r2]; } update_flags(r0); }
Esta seção tem muitas informações, então vamos resumir.
ADD pega dois valores e os armazena em um registro.- No modo de registro, o segundo valor a ser adicionado está no registro.
- No modo direto, o segundo valor é incorporado nos 5 bits certos da instrução.
- Valores menores que 16 bits devem ser expandidos.
- Cada vez que a instrução muda de caso, os sinalizadores de condição devem ser atualizados.
Você pode ficar impressionado escrevendo mais 15 instruções. No entanto, as informações obtidas aqui podem ser reutilizadas. A maioria das instruções usa uma combinação de expansão de valor, vários modos e atualizações de sinalizador.
LDI
LDI significa carregamento "indireto" ou "indireto" (carga indireta). Esta instrução é usada para carregar um valor de um local de memória em um registrador. Especificação na página 532.
Aqui está a aparência do layout binário:
Ao contrário do
ADD , não há modos e menos parâmetros. Desta vez, o código de operação é
1010 , que corresponde ao valor da enumeração
OP_LDI . Novamente, vemos um
DR três bits (registro de saída) para armazenar o valor carregado. Os bits restantes estão marcados como
PCoffset9 . Este é o valor imediato incorporado na instrução (semelhante ao
imm5 ). Como a instrução é carregada da memória, podemos supor que esse número seja um tipo de endereço que diz de onde carregar o valor. A especificação explica com mais detalhes:
O endereço é calculado expandindo os bits do valor [8:0] para 16 bits e adicionando esse valor ao PC ampliado. O que é armazenado na memória neste endereço é o endereço dos dados que serão carregados no DR . (p. 532)
Como antes, você precisa expandir esse valor de 9 bits, mas desta vez adicioná-lo ao
PC atual. (Se você observar o ciclo de execução, o
PC aumentou imediatamente após o carregamento desta instrução). A soma resultante é o endereço do local na memória e esse endereço
contém outro valor, que é o endereço do valor de carregamento.
Pode parecer uma maneira indireta de ler da memória, mas é necessário. A instrução
LD é limitada a um deslocamento de endereço de 9 bits, enquanto a memória requer um endereço de 16 bits.
LDI é útil para carregar valores armazenados em algum lugar fora do computador atual, mas para usá-los, o endereço do local final deve ser armazenado nas proximidades. Você pode pensar nisso como uma variável local em C, que é um ponteiro para alguns dados:
Como antes, depois de escrever o valor no
DR , os sinalizadores devem ser atualizados:
Os códigos de condição são definidos dependendo do resultado ser negativo, zero ou positivo. (p. 532)
Aqui está o código para este caso: (
mem_read discutido na próxima seção):
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t pc_offset = sign_extend(instr & 0x1ff, 9); reg[r0] = mem_read(mem_read(reg[R_PC] + pc_offset)); update_flags(r0); }
Como eu disse, para esta instrução usamos uma parte significativa do código e do conhecimento adquirido anteriormente ao escrever
ADD . O mesmo com o restante das instruções.
Agora você precisa implementar o restante das instruções. Siga as
especificações e use o código já escrito. O código para todas as instruções é fornecido no final do artigo. Dois dos opcodes mencionados anteriormente não serão necessários:
OP_RTI e
OP_RES . Você pode ignorá-los ou cometer um erro se eles forem chamados. Quando concluído, a maior parte da sua VM pode ser considerada completa!
7. Berço de acordo com as instruções
Esta seção contém implementações completas das instruções restantes, se você estiver preso.
RTI & RES
(não usado)
abort();
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t r1 = (instr >> 6) & 0x7; uint16_t imm_flag = (instr >> 5) & 0x1; if (imm_flag) { uint16_t imm5 = sign_extend(instr & 0x1F, 5); reg[r0] = reg[r1] & imm5; } else { uint16_t r2 = instr & 0x7; reg[r0] = reg[r1] & reg[r2]; } update_flags(r0); }
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t r1 = (instr >> 6) & 0x7; reg[r0] = ~reg[r1]; update_flags(r0); }
Branch
{ uint16_t pc_offset = sign_extend((instr) & 0x1ff, 9); uint16_t cond_flag = (instr >> 9) & 0x7; if (cond_flag & reg[R_COND]) { reg[R_PC] += pc_offset; } }
Jump
RET é indicado como uma instrução separada na especificação, pois esse é outro comando no assembler. Este é realmente um caso especial do
JMP .
RET ocorre sempre que
R1 é 7.
{ uint16_t r1 = (instr >> 6) & 0x7; reg[R_PC] = reg[r1]; }
Jump register
{ uint16_t r1 = (instr >> 6) & 0x7; uint16_t long_pc_offset = sign_extend(instr & 0x7ff, 11); uint16_t long_flag = (instr >> 11) & 1; reg[R_R7] = reg[R_PC]; if (long_flag) { reg[R_PC] += long_pc_offset; } else { reg[R_PC] = reg[r1]; } break; }
Carregar
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t pc_offset = sign_extend(instr & 0x1ff, 9); reg[r0] = mem_read(reg[R_PC] + pc_offset); update_flags(r0); }
Registro de carga
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t r1 = (instr >> 6) & 0x7; uint16_t offset = sign_extend(instr & 0x3F, 6); reg[r0] = mem_read(reg[r1] + offset); update_flags(r0); }
Endereço de carga efetivo
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t pc_offset = sign_extend(instr & 0x1ff, 9); reg[r0] = reg[R_PC] + pc_offset; update_flags(r0); }
Loja
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t pc_offset = sign_extend(instr & 0x1ff, 9); mem_write(reg[R_PC] + pc_offset, reg[r0]); }
Loja indireta
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t pc_offset = sign_extend(instr & 0x1ff, 9); mem_write(mem_read(reg[R_PC] + pc_offset), reg[r0]); }
Registro de loja
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t r1 = (instr >> 6) & 0x7; uint16_t offset = sign_extend(instr & 0x3F, 6); mem_write(reg[r1] + offset, reg[r0]); }
8. Procedimentos de manuseio de interrupção
O LC-3 fornece várias rotinas predefinidas para executar tarefas comuns e interagir com dispositivos de E / S. Por exemplo, existem procedimentos para receber linhas de entrada e saída do teclado no console. Eles são chamados de rotinas de trap, que você pode considerar o sistema operacional ou a API do LC-3. A cada subprograma é atribuído um código de interrupção (código de interceptação) que o identifica (semelhante a um código de operação).
Para executá-lo, uma instrução é chamada TRAPcom o código do subprograma desejado.Defina enum para cada código de interrupção: enum { TRAP_GETC = 0x20, TRAP_OUT = 0x21, TRAP_PUTS = 0x22, TRAP_IN = 0x23, TRAP_PUTSP = 0x24, TRAP_HALT = 0x25 };
Você pode estar se perguntando por que os códigos de interrupção não estão incluídos nas instruções. Isso ocorre porque eles realmente não adicionam ao LC-3 nenhuma nova funcionalidade, mas apenas fornecem uma maneira conveniente de concluir a tarefa (como as funções do sistema em C). No simulador oficial do LC-3, os códigos de interrupção são escritos no assembler . Quando um código de interrupção é chamado, o computador se move para o endereço desse código. A CPU executa as instruções do procedimento e, após a conclusão, é PCredefinida para o local em que a interrupção foi acionada.: 0x3000 0x0 . , .
Não há especificação sobre como implementar rotinas de interrupção: exatamente o que elas devem fazer. Em nossa VM, agiremos de maneira um pouco diferente, escrevendo-os em C. Quando o código de interrupção for chamado, a função C. será chamada. Após sua operação, a instrução continuará.Embora os procedimentos possam ser escritos no assembler e o computador físico LC-3 o seja, essa não é a melhor opção para a VM. Em vez de escrever seus próprios procedimentos primitivos de entrada e saída, você pode usar os que estão disponíveis em nosso sistema operacional. Isso melhorará a máquina virtual em nossos computadores, simplificará o código e fornecerá um nível mais alto de abstração para portabilidade.Nota: Um exemplo específico é a entrada do teclado. A versão do assembler usa um loop para verificar continuamente a entrada do teclado. Mas tanto tempo do processador é desperdiçado! Usando a função apropriada do sistema operacional, o programa pode dormir tranquilamente antes do sinal de entrada.
No operador de múltipla escolha para o código de operação, TRAPadicione outra opção: switch (instr & 0xFF) { case TRAP_GETC: {TRAP GETC, 9} break; case TRAP_OUT: {TRAP OUT, 9} break; case TRAP_PUTS: {TRAP PUTS, 8} break; case TRAP_IN: {TRAP IN, 9} break; case TRAP_PUTSP: {TRAP PUTSP, 9} break; case TRAP_HALT: {TRAP HALT, 9} break; }
Como nas instruções, mostrarei como implementar um procedimento e faça o resto você mesmo.Putts
O código de interrupção é PUTSusado para retornar uma string com um zero final (da mesma forma printfem C). Especificação na página 543.Para exibir uma sequência, devemos atribuir à rotina de interrupção uma sequência a ser exibida. Isso é feito armazenando o endereço do primeiro caractere R0antes do início do processamento.A partir da especificação:Exiba a cadeia de caracteres ASCII na tela do console. Os caracteres estão contidos em células de memória consecutivas, um caractere por célula, iniciando no endereço especificado em R0. A saída termina quando um valor é encontrado na memória x0000. (p. 543)
Observe que, diferentemente das cadeias C, aqui os caracteres são armazenados não em um byte, mas em um local na memória . A localização da memória do LC-3 é de 16 bits, portanto, cada caractere na sequência é de 16 bits. Para exibir isso na função C, você precisa converter cada valor em um caractere e imprimi-los separadamente. { uint16_t* c = memory + reg[R_R0]; while (*c) { putc((char)*c, stdout); ++c; } fflush(stdout); }
Nada mais é necessário para este procedimento. As rotinas de interrupção são bem diretas se você conhece C. Agora, volte para as especificações e implemente o restante. Como nas instruções, o código completo pode ser encontrado no final deste guia.9. Folha de dicas para rotinas de interrupção
Esta seção contém implementações completas das rotinas de interrupção restantes.Entrada de caracteres
reg[R_R0] = (uint16_t)getchar();
Saída de caracteres
putc((char)reg[R_R0], stdout); fflush(stdout);
Solicitação de entrada de caracteres
printf("Enter a character: "); reg[R_R0] = (uint16_t)getchar();
Saída de linha
{ uint16_t* c = memory + reg[R_R0]; while (*c) { char char1 = (*c) & 0xFF; putc(char1, stdout); char char2 = (*c) >> 8; if (char2) putc(char2, stdout); ++c; } fflush(stdout); }
Encerramento do Programa
puts("HALT"); fflush(stdout); running = 0;
10. Baixando Programas
Falamos muito sobre carregar e executar instruções da memória, mas como as instruções entram na memória em geral? Ao converter um programa assembler em código de máquina, o resultado é um arquivo que contém uma matriz de instruções e dados. Para fazer o download, basta copiar o conteúdo diretamente para um endereço na memória.Os primeiros 16 bits do arquivo de programa indicam o endereço na memória onde o programa deve iniciar. Este endereço é chamado de origem . Ele deve ser lido primeiro, após o qual o restante dos dados é lido na memória do arquivo.Aqui está o código para carregar o programa na memória LC-3: void read_image_file(FILE* file) { uint16_t origin; fread(&origin, sizeof(origin), 1, file); origin = swap16(origin); uint16_t max_read = UINT16_MAX - origin; uint16_t* p = memory + origin; size_t read = fread(p, sizeof(uint16_t), max_read, file); while (read-- > 0) { *p = swap16(*p); ++p; } }
Observe que para cada valor carregado é chamado swap16. Os programas LC-3 são escritos em ordem direta de bytes, mas a maioria dos computadores modernos usa a ordem inversa. Como resultado, precisamos inverter cada um carregado uint16. (Se você acidentalmente usar um computador estranho como o PPC , nada precisará ser alterado). uint16_t swap16(uint16_t x) { return (x << 8) | (x >> 8); }
Nota: A ordem dos bytes refere-se à forma como os bytes de um número inteiro são interpretados. Na ordem inversa, o primeiro byte é o dígito menos significativo e, na ordem inversa, vice-versa. Tanto quanto sei, a decisão é principalmente arbitrária. Empresas diferentes tomaram decisões diferentes, agora temos implementações diferentes. Para este projeto, você não precisa mais saber nada sobre a ordem de bytes.
Adicione também uma função conveniente para read_image_file, que segue o caminho da string: int read_image(const char* image_path) { FILE* file = fopen(image_path, "rb"); if (!file) { return 0; }; read_image_file(file); fclose(file); return 1; }
11. Registros mapeados
Alguns registros especiais não estão disponíveis na tabela de registros regulares. Em vez disso, um endereço especial é reservado para eles na memória. Para ler e gravar nesses registros, basta ler e escrever na memória deles. Eles são chamados de registros mapeados na memória . Geralmente eles são usados para interagir com dispositivos de hardware especiais.Para o nosso LC-3, precisamos implementar dois registros mapeáveis. Este é o registro de status do teclado ( KBSR) e o registro de dados do teclado ( KBDR). O primeiro indica se a tecla foi pressionada e o segundo determina qual tecla foi pressionada.Embora seja possível solicitar a entrada do teclado GETC, ela bloqueia a execução até que a entrada seja recebida. KBSRe KBDRpermitirinterrogar o estado do dispositivo enquanto continua a executar o programa, para que ele permaneça responsivo enquanto aguarda a entrada. enum { MR_KBSR = 0xFE00, MR_KBDR = 0xFE02 };
Registradores mapeados complicam um pouco o acesso à memória. Não podemos ler e gravar diretamente na matriz de memória, mas, em vez disso, devemos chamar funções especiais - setter e getter. Depois de ler a memória do registro KBSR, o getter verifica o teclado e atualiza os dois locais na memória. void mem_write(uint16_t address, uint16_t val) { memory[address] = val; } uint16_t mem_read(uint16_t address) { if (address == MR_KBSR) { if (check_key()) { memory[MR_KBSR] = (1 << 15); memory[MR_KBDR] = getchar(); } else { memory[MR_KBSR] = 0; } } return memory[address]; }
Este é o último componente de uma máquina virtual! Se você implementou o restante das rotinas e instruções de interrupção, está quase pronto para experimentá-lo!Tudo o que foi escrito deve ser adicionado ao arquivo C na seguinte ordem: {Memory Mapped Registers, 11} {TRAP Codes, 8} {Memory Storage, 3} {Register Storage, 3} {Functions, 12} {Main Loop, 5}
12. Recursos da plataforma
Esta seção contém alguns detalhes tediosos necessários para acessar o teclado e funcionar corretamente. Não há nada de interessante ou informativo sobre a operação de máquinas virtuais. Sinta-se copiar e colar gratuitamente!Se você estiver tentando iniciar a VM em um sistema operacional diferente do Unix, como o Windows, essas funções deverão ser substituídas pelas funções correspondentes do Windows. uint16_t check_key() { fd_set readfds; FD_ZERO(&readfds); FD_SET(STDIN_FILENO, &readfds); struct timeval timeout; timeout.tv_sec = 0; timeout.tv_usec = 0; return select(1, &readfds, NULL, NULL, &timeout) != 0; }
Código para extrair o caminho dos argumentos do programa e gerar um exemplo de uso, se estiverem ausentes. if (argc < 2) { printf("lc3 [image-file1] ...\n"); exit(2); } for (int j = 1; j < argc; ++j) { if (!read_image(argv[j])) { printf("failed to load image: %s\n", argv[j]); exit(1); } }
Código de configuração de entrada do terminal específico do Unix. struct termios original_tio; void disable_input_buffering() { tcgetattr(STDIN_FILENO, &original_tio); struct termios new_tio = original_tio; new_tio.c_lflag &= ~ICANON & ~ECHO; tcsetattr(STDIN_FILENO, TCSANOW, &new_tio); } void restore_input_buffering() { tcsetattr(STDIN_FILENO, TCSANOW, &original_tio); }
Quando o programa é interrompido, queremos retornar o console às suas configurações normais. void handle_interrupt(int signal) { restore_input_buffering(); printf("\n"); exit(-2); }
signal(SIGINT, handle_interrupt); disable_input_buffering();
restore_input_buffering();
{Sign Extend, 6} {Swap, 10} {Update Flags, 6} {Read Image File, 10} {Read Image, 10} {Check Key, 12} {Memory Access, 11} {Input Buffering, 12} {Handle Interrupt, 12}
#include <stdio.h> #include <stdlib.h> #include <stdint.h> #include <string.h> #include <signal.h> #include <unistd.h> #include <fcntl.h> #include <sys/time.h> #include <sys/types.h> #include <sys/termios.h> #include <sys/mman.h>
Inicialização da máquina virtual
Agora você pode criar e executar a máquina virtual LC-3!- Compile o programa com seu compilador favorito.
- Baixe a versão compilada de 2048 ou Rogue .
- Execute o programa com o arquivo obj como argumento:
lc3-vm path/to/2048.obj - Jogue em 2048!
Control the game using WASD keys. Are you on an ANSI terminal (y/n)? y +--------------------------+ | | | | | | | 2 | | | | 2 | | | | | | | +--------------------------+
Depuração
Se o programa não funcionar corretamente, provavelmente você codificou incorretamente algum tipo de instrução. Pode ser difícil depurar. Eu recomendo que você leia o código de montagem do programa ao mesmo tempo - e com a ajuda do depurador, siga as instruções passo a passo da máquina virtual, uma de cada vez. Ao ler o código, verifique se a VM vai para a instrução pretendida. Se ocorrer uma incompatibilidade, você descobrirá qual instrução causou o problema. Releia a especificação e verifique novamente o código.14. Método alternativo em C ++
Aqui está uma maneira avançada de executar instruções que reduzem significativamente o tamanho do código. Esta é uma seção completamente opcional.Como o C ++ suporta genéricos poderosos durante o processo de compilação, podemos criar partes das instruções usando o compilador. Esse método reduz a duplicação de código e, na verdade, está mais próximo do nível de hardware do computador.A idéia é reutilizar as etapas comuns a cada instrução. Por exemplo, algumas instruções usam endereçamento indireto ou extensão de um valor e adicionam-no ao valor atual PC. Concorda, seria bom escrever este código uma vez para todas as instruções?Considerando a instrução como uma sequência de etapas, vemos que cada instrução é apenas um rearranjo de várias etapas menores. Usaremos sinalizadores de bits para indicar quais etapas a seguir para cada instrução. O valor 1no bit do número da instrução indica que, para esta instrução, o compilador deve incluir esta seção do código. template <unsigned op> void ins(uint16_t instr) { uint16_t r0, r1, r2, imm5, imm_flag; uint16_t pc_plus_off, base_plus_off; uint16_t opbit = (1 << op); if (0x4EEE & opbit) { r0 = (instr >> 9) & 0x7; } if (0x12E3 & opbit) { r1 = (instr >> 6) & 0x7; } if (0x0022 & opbit) { r2 = instr & 0x7; imm_flag = (instr >> 5) & 0x1; imm5 = sign_extend((instr) & 0x1F, 5); } if (0x00C0 & opbit) {
static void (*op_table[16])(uint16_t) = { ins<0>, ins<1>, ins<2>, ins<3>, ins<4>, ins<5>, ins<6>, ins<7>, NULL, ins<9>, ins<10>, ins<11>, ins<12>, NULL, ins<14>, ins<15> };
Nota: Eu aprendi sobre essa técnica no emulador NES desenvolvido pela Bisqwit . Se você está interessado em emulação ou NES, recomendo seus vídeos.Outras versões do C ++ usam o código já escrito. Versão completa aqui . {Includes, 12} {Registers, 3} {Condition Flags, 3} {Opcodes, 3} {Memory Mapped Registers, 11} {TRAP Codes, 8} {Memory Storage, 3} {Register Storage, 3} {Functions, 12} int running = 1; {Instruction C++, 14} {Op Table, 14} int main(int argc, const char* argv[]) { {Load Arguments, 12} {Setup, 12} enum { PC_START = 0x3000 }; reg[R_PC] = PC_START; while (running) { uint16_t instr = mem_read(reg[R_PC]++); uint16_t op = instr >> 12; op_table[op](instr); } {Shutdown, 12} }