A semântica aberta do idioma russo, sobre a história da qual você pode ler
aqui e
aqui , recebeu uma grande atualização. Coletamos dados suficientes para aplicar o aprendizado de máquina sobre a marcação coletada e criar um modelo de linguagem semântica. O que saiu disso, veja abaixo do corte.

O que fazemos
Tome dois grupos de palavras:
- corrida, tiro, plotagem, caminhada, caminhada;
- corredor, fotógrafo, engenheiro, turista, atleta.
Não é difícil para uma pessoa determinar que o primeiro grupo contém substantivos que nomeiam
ações ou eventos ; na segunda
pessoa que chama. Nosso objetivo é ensinar uma máquina a resolver esses problemas.
Para fazer isso, você deve:
- Descubra quais classes naturais existem no idioma.
- Marque um número suficiente de palavras sobre o assunto de pertencer às classes do parágrafo 1 .
- Crie um algoritmo que aprenda sobre a marcação do item 2 e reproduza a classificação em palavras desconhecidas.
É possível resolver esse problema com a ajuda da semântica de distribuição?O word2vec é uma excelente ferramenta, mas ainda prefere a proximidade temática das palavras, em vez da semelhança de suas classes semânticas. Para demonstrar esse fato, execute o algoritmo com as palavras do exemplo:
w1 | w2 | cosine_sim | | | | | | 1.0000 | | | 0.6618 | | | 0.5410 | | | 0.3389 | | | 0.1531 | | | 0.1342 | | | 0.1067 | | | 0.0681 | | | 0.0458 | | | 0.0373 | | | | | | 1.0000 | | | 0.5782 | | | 0.2525 | | | 0.2116 | | | 0.1644 | | | 0.1579 | | | 0.1342 | | | 0.1275 | | | 0.1100 | | | 0.0975 | | | | | | 1.0000 | | | 0.3575 | | | 0.2116 | | | 0.1587 | | | 0.1207 | | | 0.1067 | | | 0.0889 | | | 0.0794 | | | 0.0705 | | | 0.0430 | | | | | | 1.0000 | | | 0.1896 | | | 0.1753 | | | 0.1644 | | | 0.1548 | | | 0.1531 | | | 0.0889 | | | 0.0794 | | | 0.0568 | | | -0.0013 | | | | | | 1.0000 | | | 0.5410 | | | 0.3442 | | | 0.2469 | | | 0.1753 | | | 0.1650 | | | 0.1207 | | | 0.1100 | | | 0.0673 | | | 0.0642 | | | | | | 1.0000 | | | 0.6618 | | | 0.4909 | | | 0.3442 | | | 0.1548 | | | 0.1427 | | | 0.1422 | | | 0.1275 | | | 0.1209 | | | 0.0705 | | | | | | 1.0000 | | | 0.5782 | | | 0.3687 | | | 0.2334 | | | 0.1911 | | | 0.1587 | | | 0.1209 | | | 0.0642 | | | 0.0373 | | | -0.0013 | | | | | | 1.0000 | | | 0.3575 | | | 0.2334 | | | 0.1579 | | | 0.1503 | | | 0.1447 | | | 0.1422 | | | 0.0673 | | | 0.0568 | | | 0.0458 | | | | | | 1.0000 | | | 0.3687 | | | 0.2525 | | | 0.1896 | | | 0.1650 | | | 0.1503 | | | 0.1495 | | | 0.1427 | | | 0.0681 | | | 0.0430 | | | | | | 1.0000 | | | 0.4909 | | | 0.3389 | | | 0.2469 | | | 0.1911 | | | 0.1495 | | | 0.1447 | | | 0.0975 | | | 0.0889 | | | 0.0889 |
Como a semântica aberta resolve esse problemaUma pesquisa no
dicionário semântico fornece o seguinte resultado:
| | | | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | HUMAN | | HUMAN | | HUMAN | | HUMAN | | HUMAN |
O que foi feito e onde fazer o download
O resultado do trabalho publicado no
repositório no GC e disponível para download é uma descrição da hierarquia de classes e marcação (manual e automática) de substantivos para essas classes.
Para se familiarizar com o conjunto de dados, você pode usar o navegador interativo (link no repositório). Há também uma versão simplificada do conjunto em que removemos toda a hierarquia e atribuímos uma única tag semântica grande a cada palavra: "pessoas", "animais", "lugares", "coisas", "ações" etc.
Link para o Github: semântica aberta do idioma russo (conjunto de dados) .
Sobre classes de palavras
Em problemas de classificação, as próprias classes geralmente são ditadas pelo problema que está sendo resolvido, e o trabalho do engenheiro de dados se resume a encontrar um conjunto bem-sucedido de atributos sobre os quais você pode construir um modelo de trabalho.
No nosso problema, as classes de palavras, estritamente falando, não são conhecidas antecipadamente. Aqui, uma grande quantidade de pesquisas semânticas feitas por linguistas nacionais e estrangeiros, familiaridade com os dicionários semânticos existentes e o WordNet, vem em socorro.
Essa é uma boa ajuda, mas ainda assim a decisão final já está formada em nossa própria pesquisa. Aqui está a coisa. Muitos recursos semânticos começaram a ser criados na era pré-computador (pelo menos na compreensão moderna do computador) e a escolha de classes foi amplamente ditada pela intuição da linguagem de seus criadores. No final do século anterior, o WordNet era usado ativamente nas tarefas de análise automática de texto e muitos recursos recém-criados foram aprimorados para aplicações práticas específicas.
O resultado foi que esses recursos linguísticos contêm simultaneamente informações lingüísticas e extralinguísticas e enciclopédicas sobre as unidades da língua. É lógico supor que é impossível construir um modelo que verifique informações extralinguísticas, baseando-se apenas na análise estatística de textos, porque a fonte de dados simplesmente não contém as informações necessárias.
Com base nessa premissa, procuramos apenas classes naturais que possam ser detectadas e verificadas automaticamente com base em um modelo puramente linguístico. Ao mesmo tempo, a arquitetura do sistema permite a adição de um número arbitrariamente grande de camadas adicionais de informações sobre unidades linguísticas, o que pode ser útil em aplicações práticas.
Demonstraremos o acima com um exemplo específico, analisando a palavra "geladeira". A partir do modelo linguístico, podemos descobrir que um "refrigerador" é um objeto material, um design, um contêiner do tipo "caixa ou bolsa", ou seja, não se destina ao armazenamento de líquidos ou sólidos sem um recipiente adicional. Além disso, não está claro nesse modelo que o "refrigerador" é uma mercadoria, além disso, um produto durável, e também não está claro que esse seja um artefato, ou seja, objeto feito humano. Esta é uma informação não linguística, que deve ser fornecida separadamente.
O resultado do modelo para a palavra "geladeira" Por que tudo isso é necessário
Seja como for, no processo de aprendizado e cognição da realidade, uma pessoa fornece informações adicionais sobre os objetos e fenômenos que a cercam na estrutura natural que aprendeu na infância. No entanto, alguns conceitos são universais, independentes da área de assunto e podem ser reutilizados com sucesso.
Digamos que "vendedor" seja uma
pessoa + um
papel funcional . Em alguns casos, o vendedor pode ser um grupo de pessoas ou uma organização, mas a subjetividade é sempre preservada: caso contrário, a ação-alvo não será possível. As palavras "troca" ou "treinamento" se referem a ações, ou seja, eles têm participantes, duração e resultado. O conteúdo exato dessas ações pode variar significativamente, dependendo da situação e da área de assunto, mas certos aspectos serão invariáveis. Essa é a estrutura da linguagem na qual o conhecimento extralinguístico variável é colocado em camadas.
Nosso objetivo é encontrar e explorar o máximo de informações intralinguísticas disponíveis e construir com base em um modelo explicativo da linguagem. Isso melhorará os algoritmos existentes para o processamento automático de palavras, incluindo complexos, como resolver ambiguidade lexical, resolver anáfora, casos complicados de marcação morfológica. Nesse processo, estaremos necessariamente em algum lugar contra a necessidade de atrair conhecimento extra-lingüístico, mas pelo menos saberemos para onde a fronteira vai quando o conhecimento interno da língua não for mais suficiente.
Classificação e treinamento, conjunto de atributos
Por enquanto, trabalhamos apenas com substantivos; portanto, abaixo, quando dizemos “palavra”, significaremos sinais que se relacionam apenas a essa parte do discurso. Como decidimos usar apenas informações intralinguísticas, trabalharemos com textos equipados com marcação morfológica.
Como sinais, tomamos todos os microcontextos possíveis nos quais essa palavra ocorre. Para substantivos, estes serão:
- APP + X (X bonito: olhos)
- GLAG + X (vdite X: segmento)
- VL + PRED + X (digite X: porta)
- X + SUSCH_ROD (X: borda da tabela)
- SUSHCH + X_ROD (identificador X: sabres)
- X_ ASSUNTO + GL (X: o gráfico está em desenvolvimento)
Existem mais tipos de microcontextos, mas os itens acima são os mais frequentes e já dão um bom resultado ao aprender.
Todos os microcontextos são reduzidos à forma básica e compomos um conjunto de recursos a partir deles. Em seguida, para cada palavra, compomos um vetor cuja
i-ésima coordenada se correlacionará com a ocorrência de uma determinada palavra no
i-ésimo microcontext.
Tabela de microcontext para a palavra "mochila" | | | | | | | | | VBP_ | 3043 | 1.0000 | | ADJ | 2426 | 0.9717 | | NX_NG | 1438 | 0.9065 | | VBP_ | 1415 | 0.9045 | | VBP__ | 1300 | 0.8940 | | NX_NG | 1292 | 0.8932 | | NX_NG | 1259 | 0.8900 | | ADJ | 1230 | 0.8871 | | ADJ | 1116 | 0.8749 | | ADJ | 903 | 0.8485 | | ADJ | 849 | 0.8408 | | NX_NG | 814 | 0.8356 | | ADJ | 795 | 0.8326 | | ADJ | 794 | 0.8325 | | VBP_ | 728 | 0.8217 | | ADJ | 587 | 0.7948 | | ADJ | 587 | 0.7948 | | VBP__ | 567 | 0.7905 | | VBP_ | 549 | 0.7865 | | VBP__ | 538 | 0.7840 | | VBP_ | 495 | 0.7736 | | VBP_ | 484 | 0.7708 | | NX_NG | 476 | 0.7687 | | ADJ | 463 | 0.7652 | | NX_NG | 459 | 0.7642 |
Valor alvo, hierarquia de fatiamento semântico
A linguagem possui mecanismos naturais para a reutilização de palavras, o que causa o surgimento de um fenômeno como a polissemia. Além disso, às vezes não apenas palavras individuais são reutilizadas, mas é feita uma transferência metafórica de conceitos inteiros. Isso é especialmente perceptível na transição dos conceitos materiais para os abstratos.
Esse fato determina a necessidade de classificação hierárquica, na qual as seções semânticas são organizadas em uma estrutura em árvore e a partição ocorre em cada nó interno. Isso permite que você lide com a ambiguidade em microcontextos com muito mais eficiência.
Exemplos de transferência de conceito metafóricoAlém de resolver problemas práticos da linguística de computadores, nosso trabalho tem como objetivo estudar a palavra e vários fenômenos linguísticos. A transferência metafórica de conceitos do plano real para o abstrato é um fenômeno bem conhecido pelos linguistas cognitivos. Assim, por exemplo, um dos conceitos mais brilhantes do mundo material é a classe "contêiner" (na literatura em língua russa é freqüentemente chamada de "contêiner").
Outra metáfora ontológica onipresente é a metáfora do contêiner, ou contêiner, que implica traçar limites no continuum de nossa experiência e entendê-la através de categorias espaciais. Segundo os autores, a maneira como uma pessoa percebe o mundo ao seu redor é determinada por sua experiência em lidar com objetos materiais discretos e, em particular, por sua percepção de si mesma, de seu corpo. O homem é uma criatura delimitada pelo resto do mundo pela pele. Ele é um contêiner e, portanto, é comum perceber outras entidades como contêineres com uma parte interna e uma superfície externa.
Skrebtsova T. G. Linguística Cognitiva: Teorias Clássicas, Novo
abordagens
O modelo que construímos opera em um único espaço de atributos e nos permite aprender com exemplos reais e fazer previsões no campo do abstrato. Isso permite que você faça a transferência descrita acima. Assim, por exemplo, as seguintes palavras são contêineres abstratos, o que é consistente com a ideia intuitiva:

Outro exemplo interessante é a transferência do conceito de "líquido" para a esfera do intangível:
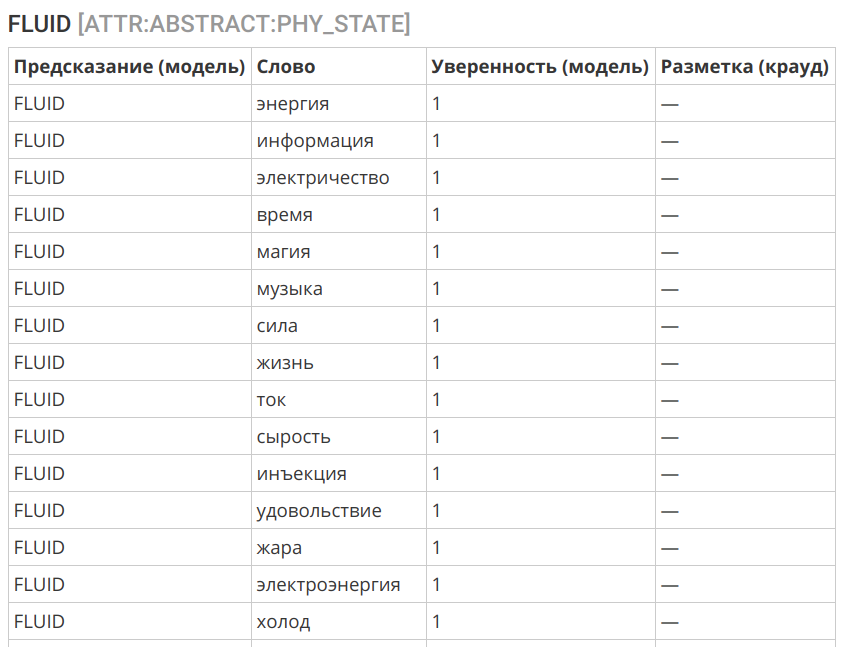
Seleção de algoritmo
Como algoritmo, usamos regressão logística. Isso ocorre devido a vários fatores:
- De uma forma ou de outra, a marcação inicial contém uma certa quantidade de erros e ruídos.
- Os sinais podem ser desequilibrados e também conter erros - polissemia e uso metafórico (figurativo) da palavra.
- A análise preliminar sugere que uma interface adequadamente selecionada seja corrigida com um algoritmo bastante simples.
- A boa interpretabilidade do algoritmo é importante.
O algoritmo mostrou uma precisão bastante boa:
Logs do algoritmo de marcação == ENTITY == slice | label | count | correctCount | accuracy | | | | | | ENTITY | PHYSICAL | 12249 | 11777 | 0.9615 | ENTITY | ABSTRACT | 9854 | 9298 | 0.9436 | | | | | | | | | | 0.9535 | == PHYSICAL:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:ROLE | ORGANIC | 7001 | 6525 | 0.9320 | PHYSICAL:ROLE | INORGANIC | 3805 | 3496 | 0.9188 | | | | | | | | | | 0.9274 | == PHYSICAL:ORGANIC:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:ORGANIC:ROLE | HUMAN | 4879 | 4759 | 0.9754 | PHYSICAL:ORGANIC:ROLE | ANIMAL | 675 | 629 | 0.9319 | PHYSICAL:ORGANIC:ROLE | FOOD | 488 | 411 | 0.8422 | PHYSICAL:ORGANIC:ROLE | ANATOMY | 190 | 154 | 0.8105 | PHYSICAL:ORGANIC:ROLE | PLANT | 285 | 221 | 0.7754 | | | | | | | | | | 0.9474 | == PHYSICAL:INORGANIC:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:INORGANIC:ROLE | CONSTRUCTION | 1045 | 933 | 0.8928 | PHYSICAL:INORGANIC:ROLE | THING | 2385 | 2123 | 0.8901 | PHYSICAL:INORGANIC:ROLE | SUBSTANCE | 399 | 336 | 0.8421 | | | | | | | | | | 0.8859 | == PHYSICAL:CONSTRUCTION:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:CONSTRUCTION:ROLE | TRANSPORT | 188 | 178 | 0.9468 | PHYSICAL:CONSTRUCTION:ROLE | APARTMENT | 270 | 241 | 0.8926 | PHYSICAL:CONSTRUCTION:ROLE | TERRAIN | 285 | 253 | 0.8877 | | | | | | | | | | 0.9044 | == PHYSICAL:THING:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:THING:ROLE | WEARABLE | 386 | 357 | 0.9249 | PHYSICAL:THING:ROLE | TOOLS | 792 | 701 | 0.8851 | PHYSICAL:THING:ROLE | DISHES | 199 | 174 | 0.8744 | PHYSICAL:THING:ROLE | MUSIC_INSTRUMENTS | 63 | 51 | 0.8095 | PHYSICAL:THING:ROLE | WEAPONS | 107 | 69 | 0.6449 | | | | | | | | | | 0.8739 | == PHYSICAL:TOOLS:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:TOOLS:ROLE | PHY_INTERACTION | 213 | 190 | 0.8920 | PHYSICAL:TOOLS:ROLE | INFORMATION | 101 | 71 | 0.7030 | PHYSICAL:TOOLS:ROLE | EM_ENERGY | 72 | 49 | 0.6806 | | | | | | | | | | 0.8031 | == ATTR:INORGANIC:WEARABLE == slice | label | count | correctCount | accuracy | | | | | | ATTR:INORGANIC:WEARABLE | NON_WEARABLE | 538 | 526 | 0.9777 | ATTR:INORGANIC:WEARABLE | WEARABLE | 282 | 269 | 0.9539 | | | | | | | | | | 0.9695 | == ATTR:PHYSICAL:CONTAINER == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:CONTAINER | CONTAINER | 636 | 627 | 0.9858 | ATTR:PHYSICAL:CONTAINER | NOT_A_CONTAINER | 1225 | 1116 | 0.9110 | | | | | | | | | | 0.9366 | == ATTR:PHYSICAL:CONTAINER:TYPE == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:CONTAINER:TYPE | CONFINED_SPACE | 291 | 287 | 0.9863 | ATTR:PHYSICAL:CONTAINER:TYPE | CONTAINER | 140 | 131 | 0.9357 | ATTR:PHYSICAL:CONTAINER:TYPE | OPEN_AIR | 72 | 64 | 0.8889 | ATTR:PHYSICAL:CONTAINER:TYPE | BAG_OR_BOX | 43 | 31 | 0.7209 | ATTR:PHYSICAL:CONTAINER:TYPE | CAVITY | 30 | 20 | 0.6667 | | | | | | | | | | 0.9253 | == ATTR:PHYSICAL:PHY_STATE == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:PHY_STATE | SOLID | 308 | 274 | 0.8896 | ATTR:PHYSICAL:PHY_STATE | FLUID | 250 | 213 | 0.8520 | ATTR:PHYSICAL:PHY_STATE | FABRIC | 72 | 51 | 0.7083 | ATTR:PHYSICAL:PHY_STATE | PLASTIC | 78 | 42 | 0.5385 | ATTR:PHYSICAL:PHY_STATE | SAND | 70 | 31 | 0.4429 | | | | | | | | | | 0.7853 | == ATTR:PHYSICAL:PLACE == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:PLACE | NOT_A_PLACE | 855 | 821 | 0.9602 | ATTR:PHYSICAL:PLACE | PLACE | 954 | 914 | 0.9581 | | | | | | | | | | 0.9591 | == ABSTRACT:ROLE == slice | label | count | correctCount | accuracy | | | | | | ABSTRACT:ROLE | ACTION | 1497 | 1330 | 0.8884 | ABSTRACT:ROLE | HUMAN | 473 | 327 | 0.6913 | ABSTRACT:ROLE | PHYSICS | 257 | 171 | 0.6654 | ABSTRACT:ROLE | INFORMATION | 222 | 146 | 0.6577 | ABSTRACT:ROLE | ABSTRACT | 70 | 15 | 0.2143 | | | | | | | | | | 0.7896 |
Análise de erro
Erros decorrentes da classificação automática são causados por três fatores principais:
- Homonímia e polissemia: palavras que têm o mesmo tipo podem ter significados diferentes (atormentar a e mu ka, parar como um processo e parar como um local ). Isso também pode incluir o uso metafórico de palavras e metonímia (por exemplo, uma porta será classificada como um espaço fechado - esse é um recurso esperado do idioma).
- Desequilíbrio no contexto do uso da palavra. Alguns usos orgânicos podem não estar disponíveis na embalagem original, causando erros de classificação.
- Limite de classe inválido. Você pode traçar limites que não são computáveis a partir de contextos e exigem o envolvimento de conhecimento extra-linguístico. Aqui o algoritmo será impotente.
Nesta fase, prestamos atenção apenas aos erros do terceiro tipo e ajustamos o limite selecionado entre as classes. Os erros dos dois primeiros tipos em uma determinada configuração do sistema não podem ser eliminados, mas com uma quantidade suficiente de dados rotulados, eles não representam um grande problema - isso pode ser visto pela precisão da marcação das projeções superiores.
O que vem a seguir
No momento, o conjunto de dados cobre a maioria dos substantivos existentes no idioma russo e representados no corpus em uma variedade suficiente de contextos. O foco principal foi colocado nos objetos materiais - como os mais compreensíveis e elaborados em trabalhos científicos. As tarefas permanecem para refinar a marcação existente, levando em consideração os dados recebidos do algoritmo e trabalhar com classes nas camadas inferiores, onde é observada uma diminuição na precisão da previsão, devido ao desfoque dos limites entre as categorias.
Mas este é um tipo de trabalho de rotina, que está sempre lá. Uma nova camada qualitativa de pesquisa diz respeito à possibilidade de classificar uma palavra específica em um contexto ou sentença específica, o que permitirá levar em consideração os fenômenos da homonímia e da polissemia, incluindo a metáfora (significados figurativos).
Além disso, atualmente estamos trabalhando em vários projetos relacionados:
- dicionário de reconhecibilidade das palavras RY: uma variação do dicionário de frequência, em que a compreensibilidade e a familiaridade da palavra são avaliadas como resultado da marcação de crowdsourcing e não calculadas de acordo com o corpo dos textos.
- corpo aberto para resolver ambiguidade lexical: com base no concurso Tarefa compartilhada RUSSE 2018 WSI & D, realizada como parte da conferência Dialogue 2018 , ficou clara a utilidade do corpus com a ambiguidade lexical removida para testar algoritmos automáticos para desambiguação e agrupamento de significados de palavras. Também precisaremos desse corpo para ir ao estágio de trabalho sobre semântica aberta descrito no parágrafo anterior.
Dicionário tonal da língua russa
O dicionário tonal são as palavras e expressões do JO, marcadas pela tonalidade e força da gravidade da carga emocional-avaliadora. Simplificando, quanto uma palavra em particular é "ruim" ou "boa".
No momento, estão marcados 67.392 caracteres (dos quais 55.532 palavras e 11.860 expressões).
Feedback e distribuição
Agradecemos qualquer feedback nos comentários - desde críticas ao trabalho e nossas abordagens a links para estudos interessantes e artigos relacionados.
Se você tiver conhecidos ou colegas que possam estar interessados no conjunto de dados publicado, envie um link para o artigo ou repositório para ajudar a disseminar dados abertos.
Link e licença para download
Conjunto de dados: semântica aberta do idioma russoO conjunto de dados é licenciado sob
CC BY-NC-SA 4.0 .