É possível se defender completamente contra ataques cibernéticos? Provavelmente, você pode, se se cercar de todos os meios de proteção existentes e contratar uma grande equipe de especialistas para gerenciar os processos. No entanto, é claro que, na realidade, isso é impossível: o orçamento para segurança da informação não é infinito e, no entanto, ocorrerão incidentes. E já que eles acontecerão, você precisa se preparar para eles!
Neste artigo, compartilharemos cenários típicos para investigar incidentes de malware, informaremos o que procurar nos logs e forneceremos recomendações técnicas sobre como configurar as ferramentas de segurança da informação para aumentar as chances de sucesso de uma investigação.

O processo clássico de
resposta a um incidente relacionado a malware envolve estágios como detecção, contenção, recuperação etc., no entanto, todos os seus recursos, de fato, são determinados no estágio de preparação. Por exemplo, a taxa de detecção de infecções depende diretamente de quão bem a auditoria está configurada na empresa.
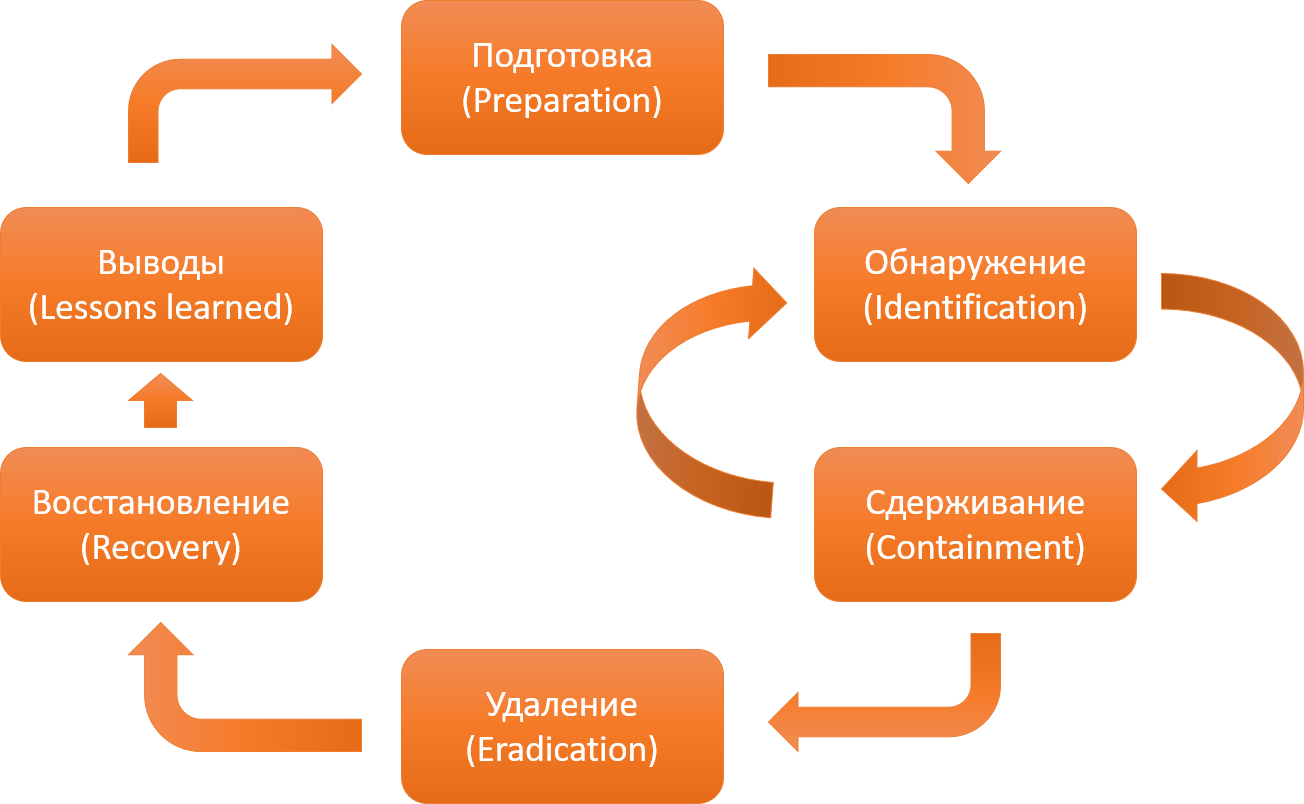 Ciclo clássico de resposta a incidentes SANS
Ciclo clássico de resposta a incidentes SANS
Em termos gerais, as ações dos analistas durante a investigação são as seguintes:
- Geração de versões explicando as causas do incidente (por exemplo, “o malware foi instalado no host porque o usuário o lançou a partir de um email de phishing” ou “o incidente é um alarme falso porque o usuário visitou um site legítimo localizado na mesma hospedagem que o servidor de gerenciamento malware ”).
- Priorização de versões por grau de probabilidade. A probabilidade é calculada (mas sim fingida) com base nas estatísticas de incidentes passados, na criticidade do incidente ou no sistema e também na experiência pessoal.
- Estudo de cada versão, procure fatos que a provem ou refutem.
Obviamente, não faz sentido testar todas as hipóteses possíveis - pelo menos porque o tempo é limitado. Portanto, veremos as versões mais prováveis e os cenários típicos para investigar incidentes de malware.
Cenário 1
Você suspeita que um sistema não crítico tenha sido comprometido por malware. Devido à natureza acrítica do sistema, um pouco de tempo foi alocado para verificação.
A primeira coisa que a maioria dos engenheiros de resposta faz é executar uma verificação antivírus. No entanto, como sabemos, um antivírus não é tão difícil de contornar. Portanto, vale a pena gerar e elaborar a seguinte versão altamente provável: malware é um arquivo ou serviço executável separado.
Como parte do desenvolvimento desta versão, há três etapas simples a serem seguidas:
- Filtre o log de segurança pelo evento 4688 - para obter uma lista de todos os processos iniciados.
- Filtre o log do sistema pelo evento 7045 - para obter uma lista de instalações de todos os serviços.
- Identifique novos processos e serviços que não estavam anteriormente no sistema. Copie esses módulos e analise-os quanto à presença de código malicioso (verifique com vários antivírus, verifique a validade da assinatura digital, descompile o código etc.).
 Listar todos os processos e serviços em execução no Event Log Explorer
Listar todos os processos e serviços em execução no Event Log Explorer
Em teoria, este é um processo bastante trivial. No entanto, na prática, existem várias armadilhas a serem preparadas.
Em primeiro lugar, a configuração de auditoria padrão do Windows não registra os fatos do início do processo (evento 4688); portanto, ela deve ser ativada com antecedência na diretiva de grupo de domínio. Se aconteceu que essa auditoria não foi incluída com antecedência, você pode tentar obter uma lista de arquivos executáveis de outros artefatos do Windows, por exemplo, no registro
Amcache . Você pode
extrair dados desse arquivo de registro usando o utilitário
AmcaheParser .
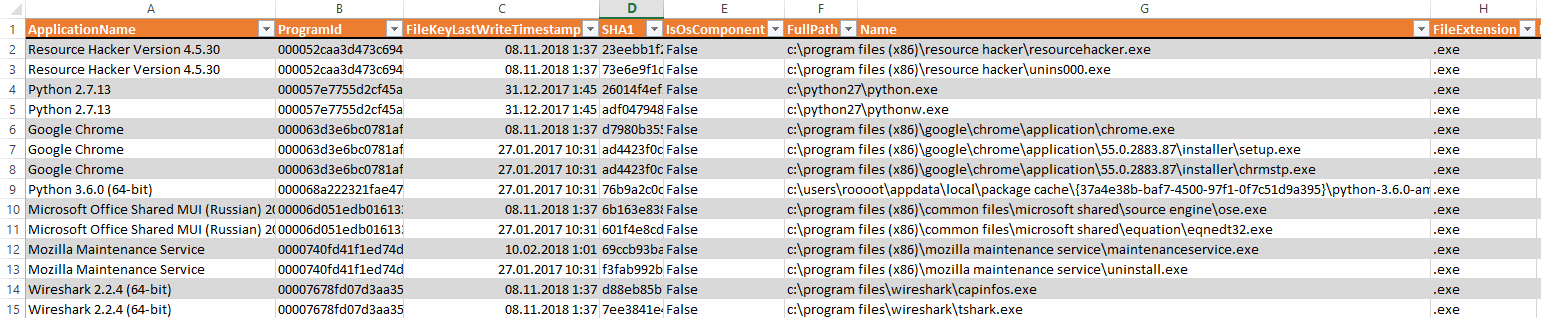 Um exemplo de extração dos fatos dos processos iniciais do Amcache.hve
Um exemplo de extração dos fatos dos processos iniciais do Amcache.hve
No entanto, esse método não é muito confiável, porque não fornece informações precisas sobre quando exatamente e quantas vezes o processo foi iniciado.
Em segundo lugar, as evidências do lançamento de processos como
cmd.exe, powershell.exe, wscript.exe e outros intérpretes serão de pouca utilidade sem informações sobre a linha de comando com a qual os processos foram iniciados, porque ele contém o caminho para um arquivo de script potencialmente malicioso.
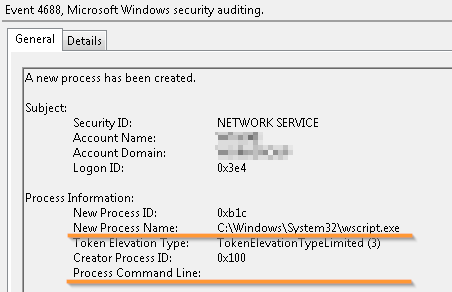 Executando o interpretador de script sem informações sobre qual script foi iniciado
Executando o interpretador de script sem informações sobre qual script foi iniciado
Outro recurso do Windows é que a auditoria de linha de comando do processo iniciado é realizada configurando separadamente a política de grupo de domínio:
Configuração do Computador -> Diretivas -> Modelos Administrativos -> Sistema -> Criação de Processo de Auditoria -> Incluir linha de comando nos eventos de criação de processo . Ao mesmo tempo, o bastante popular Windows 7/2008 não registra a linha de comando sem a atualização
KB3004375 instalada , portanto, coloque-a com antecedência.
Se aconteceu que você não configurou nada com antecedência ou se esqueceu da atualização, tente descobrir a localização do script nos arquivos de
Pré -
busca (um
utilitário para ajudar ). Eles contêm informações sobre todos os arquivos (principalmente DLLs) carregados no processo nos primeiros 10 segundos de vida. E o script contido nos argumentos da linha de comando do intérprete certamente estará presente lá.
 Exemplo de localização de um argumento de linha de comando "perdido" na pré-busca
Exemplo de localização de um argumento de linha de comando "perdido" na pré-busca
Mas esse método não é de todo confiável - na próxima vez em que você iniciar o processo, o cache de Pré-busca será substituído.
Preparação para a investigação:
- Inclua uma auditoria avançada da criação e conclusão dos processos.
- Ative o log de argumentos da linha de comandos do processo.
- Instale a atualização KB3004375 no Windows 7 / Server 2008.
Cenário 2
Um acesso ao servidor de gerenciamento de malware foi registrado no roteador de perímetro. O endereço IP do servidor malicioso foi obtido a partir de uma assinatura de inteligência de ameaças de segurança média.
Em
um de nossos artigos anteriores, dissemos que os analistas de TI pecam adicionando às listas de indicadores de comprometimento os endereços IP de servidores que hospedam centros de controle de malware e sites legítimos ao mesmo tempo. Se você começou a formular processos de resposta, nos primeiros estágios é melhor abandonar o uso desses indicadores, porque todas as tentativas de um usuário para entrar em um site legítimo parecerão um incidente completo.
Uma das opções para responder a esses alarmes pode ser reduzida à verificação de qual processo fez a conexão - se for um navegador da Internet, na ausência de outros fatos indicando comprometimento, o incidente pode ser considerado um alarme falso.
Existem várias maneiras de descobrir qual processo iniciou a conexão: você pode executar o
netstat e ver os soquetes atuais ou coletar um despejo de memória e definir
volatilidade nele, o que também pode mostrar conexões já concluídas. Mas tudo isso é longo, não escalável e o mais importante - não confiável. É muito mais confiável obter todas as informações necessárias no log de segurança do Windows.
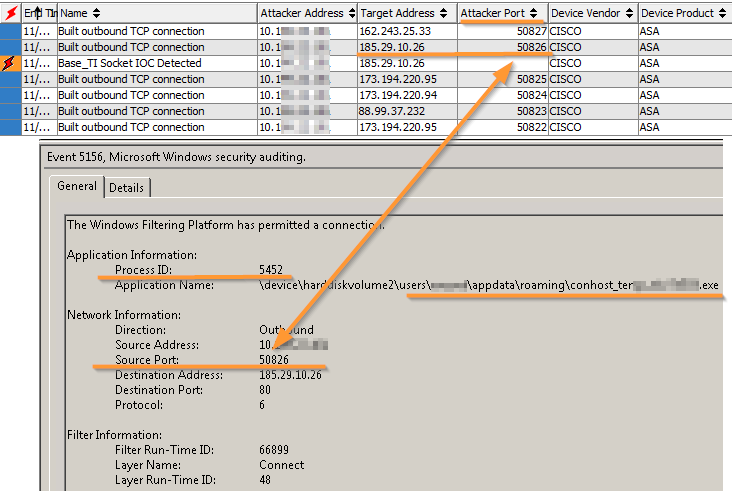 Correlação do evento "acesso ao endereço IP malicioso" no sistema HPE Arcsight SIEM e o processo correspondente no log de segurança do Windows
Correlação do evento "acesso ao endereço IP malicioso" no sistema HPE Arcsight SIEM e o processo correspondente no log de segurança do Windows
Preparação para Investigação
Para resolver esse cenário em uma máquina do usuário, você deve habilitar o log de todas as conexões de rede no log de segurança. Isso pode ser feito com base nos eventos de
auditoria da
plataforma de filtragem e na
auditoria de queda de pacotes .
Ao mesmo tempo, a revista pode começar a ficar entupida rapidamente, aumentando assim seu tamanho para 2-3 GB. Em nossa experiência, em um host de usuário comum, esse valor é suficiente por cerca de 3 dias para registrar todos os soquetes e esse período é suficiente para uma investigação bem-sucedida.
Em servidores altamente carregados, como controladores de domínio, servidores da web etc., você não deve fazer isso, o log irá estourar muito mais rapidamente.
Cenário 3
Seu sistema de detecção de anomalias NG / ML / Anti-APT relata que 30 hosts estão pesquisando para obter as mesmas contas.

Quando eles entram em uma nova rede, os atacantes geralmente tentam descobrir quais serviços estão presentes nela e quais contas são usadas - isso ajuda muito no processo de movimento adicional na infraestrutura. Em particular, essas informações podem ser obtidas no próprio Active Directory usando o comando
net user / domain .
Se uma inteligência em potencial for realizada a partir de um host, ela poderá ser investigada, inclusive usando os logs dos processos em execução. No entanto, se houver muitos hosts e os ataques forem do mesmo tipo (ocorreram ao mesmo tempo ou o mesmo conjunto de entidades foi solicitado ao AD), faz sentido, antes de tudo, excluir um falso positivo típico. Para fazer isso, crie e verifique as seguintes versões:
- A inteligência é fixada em 30 hosts para os mesmos objetos do AD porque o usuário legítimo da rede , o administrador, lançou o comando net .
- A inteligência é fixada em 30 hosts para os mesmos objetos do AD, porque criou o mesmo software legítimo.
A análise estatística dos logs ajudará a encontrar esses pontos nodais (um usuário ou processo comum). Demonstramos esse método em um artigo anterior, aplicado aos
logs do servidor DNS . No entanto, esses métodos eficazes de investigação não podem ser usados se o armazenamento de dados não tiver sido organizado com antecedência.
Preparação para Investigação
É necessário organizar o armazenamento de longo prazo de pelo menos os seguintes dados dos logs dos serviços de rede comuns:
- Controladores de domínio - entradas, saídas de contas e emissão de tíquetes Kerberos (categoria Logon da conta nas configurações avançadas de auditoria).
- Proxies - endereços, portas de origem e de servidor externo, bem como o URL completo.
- Servidores DNS - consultas DNS bem-sucedidas e malsucedidas e sua origem na rede.
- Roteadores de perímetro - criados e desmontados para todas as conexões TCP / UDP, bem como conexões que tentam violar as regras de acesso lógico: por exemplo, tenta enviar uma consulta DNS diretamente para fora, ignorando o servidor DNS corporativo.
Cenário 4
Seu domínio foi comprometido e você está preocupado com a possibilidade de um invasor ganhar uma posição na infra-estrutura usando a técnica DCShadow.

Suponha que algo terrível aconteceu: você descobre que a conta de administrador do domínio foi comprometida.
Responder a um incidente desse tipo inclui uma camada muito grande de trabalho, incluindo uma análise de todas as ações cometidas sob essa conta. Parte desta investigação pode ser feita usando apenas logs do controlador de domínio. Por exemplo, você pode estudar os eventos associados à emissão de tíquetes Kerberos para entender de onde eles foram nessa conta. Ou você pode analisar os eventos associados à alteração de objetos críticos do AD para verificar se a composição de grupos altamente privilegiados (os mesmos administradores de domínio) foi alterada. Naturalmente, tudo isso requer uma auditoria pré-configurada.
No entanto, há um problema em que um invasor com direitos de administrador de domínio pode modificar objetos do AD usando a técnica DCShadow, que se baseia no mecanismo de replicação entre controladores de domínio.
Sua essência é que o próprio invasor parece ser um controlador de domínio, faz alterações no AD e, em seguida, replica (sincroniza) essas alterações com controladores legítimos, ignorando a auditoria das alterações de objetos configuradas neles. O resultado desse ataque pode ser adicionar um usuário a um grupo de administradores de domínio ou ligações mais complicadas, alterando o atributo
Histórico do
SID ou modificando o objeto ACL
AdminSDHolder .
Para verificar a versão sobre a presença de alterações não confirmadas no AD, é necessário estudar os logs de replicação do controlador: se endereços IP diferentes dos controladores de domínio estiveram envolvidos na replicação, você pode dizer com grande confiança que o ataque foi bem-sucedido.
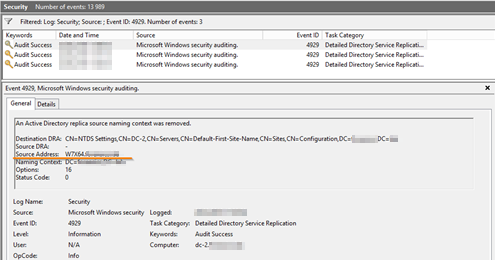 Removendo um controlador de domínio desconhecido da replicação do ADPreparação para a investigação:
Removendo um controlador de domínio desconhecido da replicação do ADPreparação para a investigação:- Para investigar ações cometidas por uma conta comprometida, você deve incluir antecipadamente:
- Auditar entradas e saídas da conta e emitir tíquetes Kerberos (categoria Logon da conta nas configurações avançadas de auditoria).
- Auditoria de alterações em contas e grupos (categoria Gerenciamento de Contas ).
- Para investigar versões relacionadas a possíveis ataques do DCShadow:
- Habilite a auditoria detalhada da replicação do serviço de diretório .
- Organize o armazenamento de eventos a longo prazo 4928/4929, no qual a fonte de eventos não é um controlador de domínio legítimo (atributo DCShadow).
Conclusão
Neste artigo, falamos sobre alguns cenários típicos para investigar incidentes de segurança da informação e medidas para sua preparação preventiva. Se você está interessado neste tópico e está pronto para ir além, recomendo prestar atenção a
este documento , que descreve em quais eventos do Windows você pode encontrar vestígios do uso de técnicas populares de hacking.
Gostaria de terminar com uma citação de um estudo recente de uma empresa de segurança cibernética:
“Na maioria das vezes, os diretores russos de segurança da informação tendem a dar respostas pessimistas [para perguntas de pesquisa]. Assim, metade (48%) acredita que o orçamento não vai mudar de forma alguma e 15% pensa que o financiamento será reduzido. ”
Para mim, pessoalmente, isso é um sinal de que o orçamento restante no ano novo é melhor gasto não na compra de SZI à moda, como detectores de Machine Learning, outro IDS de próxima geração etc., mas no ajuste fino dos SZI que já existem. E o melhor SZI está configurado corretamente nos logs do Windows. IMHO.