
Trabalho na equipe da plataforma Odnoklassniki e hoje falarei sobre os detalhes de arquitetura, design e implementação do serviço de distribuição de músicas.
O artigo é uma transcrição do relatório no Joker 2018 .
Algumas estatísticas
Primeiro, algumas palavras sobre OK. Este é um serviço gigantesco usado por mais de 70 milhões de usuários. São atendidos por 7 mil carros em 4 data centers. Recentemente, ultrapassamos a marca de tráfego de 2 Tb / s sem levar em conta os inúmeros sites da CDN. Tiramos o máximo proveito do nosso hardware, os serviços mais carregados atendem até 100.000 solicitações por segundo a partir de um nó quad-core. Além disso, quase todos os serviços são escritos em Java.
Há muitas seções em OK, uma das mais populares é "Música". Nele, os usuários podem fazer upload de suas faixas, comprar e baixar músicas de qualidade diferente. A seção possui um catálogo maravilhoso, sistema de recomendação, rádio e muito mais. Mas o principal objetivo do serviço, é claro, é tocar música.
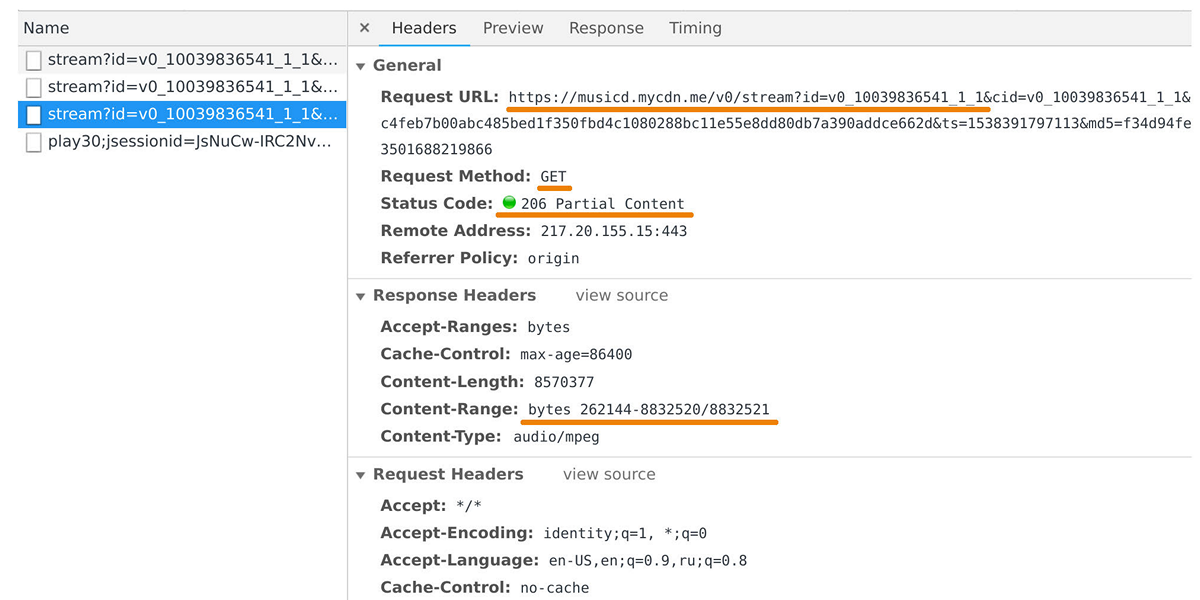
O distribuidor de música é responsável por transferir dados para players do usuário e aplicativos móveis. Você pode capturá-lo no inspetor da web se observar as solicitações para o domínio musicd.mycdn.me. A API do distribuidor é extremamente simples. Ele responde às solicitações
GET HTTP e emite o intervalo de faixas solicitado.
No pico, a carga atinge 100 Gb / s através de meio milhão de conexões. De fato, o distribuidor de música é uma interface de cache em frente ao nosso repositório interno de faixas, que é baseado no
One Blob Storage e
One Cold Storage e contém petabytes de dados.
Desde que eu falei sobre cache, vejamos as estatísticas de reprodução. Vemos um TOP pronunciado.
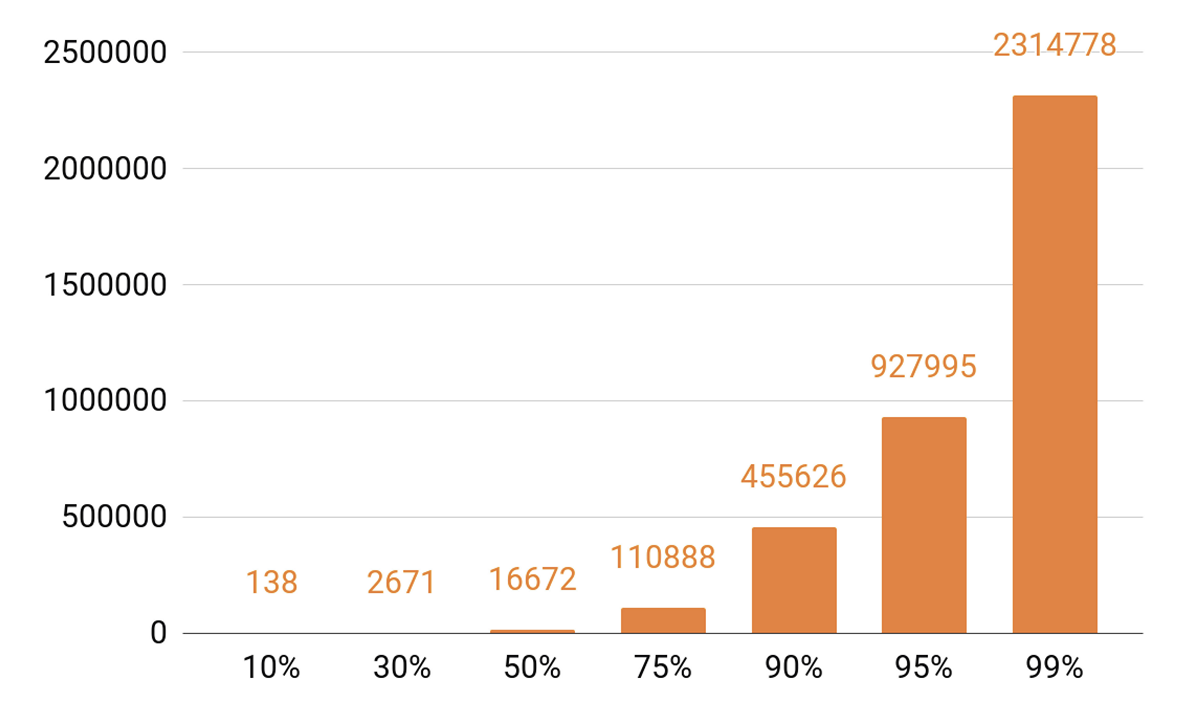
Aproximadamente 140 faixas cobrem 10% de todas as execuções por dia. Se queremos que nosso servidor de cache tenha um hit de cache de pelo menos 90%, precisamos de meio milhão de faixas para caber nele. 95% - quase um milhão de faixas.
Requisitos do Distribuidor
Que objetivos nos estabelecemos ao desenvolver a próxima versão do distribuidor?
Queríamos que um nó pudesse armazenar 100 mil conexões. E essas são conexões lentas do cliente: um monte de navegadores e aplicativos móveis em redes com velocidades variadas. Ao mesmo tempo, o serviço, como todos os nossos sistemas, deve ser escalável e tolerante a falhas.
Antes de tudo, precisamos escalar a largura de banda do cluster para acompanhar a crescente popularidade do serviço e poder fornecer mais e mais tráfego. Também é necessário poder dimensionar a capacidade total do cache do cluster, porque o acerto do cache e a porcentagem de solicitações que cairão no armazenamento de trilhas dependem diretamente dele.
Hoje é necessário poder escalar qualquer sistema distribuído horizontalmente, ou seja, adicionar máquinas e data centers. Mas também queríamos implementar a escala vertical. Nosso servidor moderno típico contém 56 núcleos, 0,5-1 TB de RAM, uma interface de rede de 10 ou 40 Gb e uma dúzia de discos SSD.
Falando em escalabilidade horizontal, surge um efeito interessante: quando você tem milhares de servidores e dezenas de milhares de discos, algo constantemente quebra. A falha no disco é uma rotina, nós as alteramos de 20 a 30 peças por semana. E as falhas no servidor não surpreendem ninguém; 2-3 carros por dia estão sendo substituídos. Eu também tive que lidar com falhas no data center, por exemplo, em 2018, ocorreram três falhas, e essa provavelmente não é a última vez.
Por que eu sou tudo isso? Quando projetamos qualquer sistema, sabemos que eles serão interrompidos mais cedo ou mais tarde. Portanto, sempre
estudamos cuidadosamente os cenários de falha de todos os componentes do sistema. A principal maneira de lidar com falhas é através da replicação de dados: várias cópias dos dados são armazenadas em nós diferentes.
Também reservamos largura de banda da rede. Isso é importante porque se um componente do sistema falhar, não será permitido o carregamento da carga nos componentes restantes.
Balanceamento
Primeiro, você precisa aprender a equilibrar as consultas dos usuários entre os data centers e fazê-lo automaticamente. Isso ocorre caso você precise realizar um trabalho em rede ou se o data center falhar. Mas o balanceamento também é necessário dentro dos data centers. E queremos distribuir solicitações entre nós não aleatoriamente, mas com pesos. Por exemplo, quando carregamos uma nova versão de um serviço e queremos inserir sem problemas um novo nó em rotação. Os pesos também ajudam bastante durante o teste de estresse: aumentamos o peso e colocamos uma carga muito mais pesada no nó para entender os limites de suas capacidades. E quando um nó falha sob carga, rapidamente zeramos o peso e o removemos da rotação usando mecanismos de balanceamento.
Como é o caminho da solicitação do usuário para o nó, que retornará os dados levando em consideração o balanceamento?

O usuário efetua login pelo site ou aplicativo móvel e recebe o URL da faixa:
musicd.mycdn.me/v0/stream?id=...Para obter o endereço IP do nome do host na URL, o cliente entra em contato com o DNS GSLB, que conhece todos os nossos datacenters e sites CDN. O DNS GSLB fornece ao cliente o endereço IP do balanceador de um dos data centers, e o cliente estabelece uma conexão com ele. O balanceador conhece todos os nós nos datacenters e seu peso. Ele, em nome do usuário, estabelece uma conexão com um dos nós. Usamos
balanceadores L4 baseados em N4Ware . Noda fornece os dados do usuário diretamente, ignorando o balanceador. Em serviços como um distribuidor, o tráfego de saída é significativamente maior que o de entrada.
Se um data center falha, o GSLB DNS detecta isso e o remove rapidamente da rotação: deixa de fornecer aos usuários o endereço IP do balanceador desse data center. Se um nó no datacenter falhar, seu peso será redefinido e o balanceador dentro do datacenter deixará de enviar solicitações para ele.
Agora considere equilibrar as faixas por nós dentro de um datacenter. Consideraremos os data centers como unidades autônomas independentes, cada um deles viverá e trabalhará, mesmo que todos os outros tenham morrido. As faixas precisam ser equilibradas entre as máquinas de maneira uniforme para que não haja distorções de carga e replicá-las em nós diferentes. Se um nó falhar, a carga deverá ser distribuída igualmente entre os demais.
Este problema pode ser
resolvido de diferentes maneiras . Decidimos
um hash consistente . Envolvemos todo o intervalo possível de hashes de identificadores de faixa em um anel e, em seguida, cada faixa é exibida em um ponto desse anel. Em seguida, distribuímos de maneira mais ou menos uniforme os intervalos de anéis entre os nós no cluster. Os nós que armazenam a faixa são selecionados com hash das faixas até um ponto no anel e movendo no sentido horário.
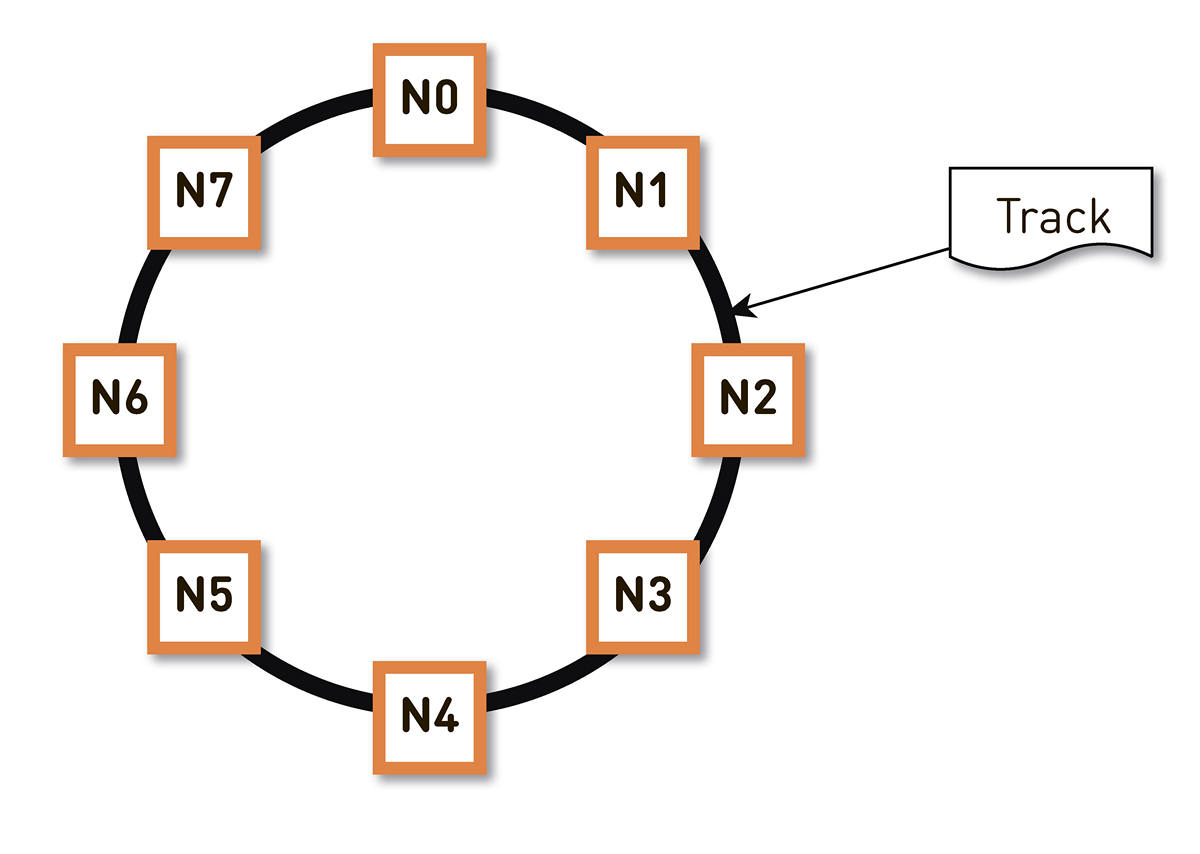
Mas esse esquema tem uma desvantagem: em caso de falha do nó N2, por exemplo, toda a sua carga cairá na próxima réplica no anel - N3. E se ele não tiver uma margem dupla de desempenho - e isso não for economicamente justificado -, provavelmente o segundo nó também terá problemas. N3 com um alto grau de probabilidade se desenvolverá, a carga irá para N4 e assim por diante - haverá uma falha em cascata ao longo de todo o anel.
Esse problema pode ser resolvido aumentando o número de réplicas, mas a capacidade útil total do cluster no anel diminui. Portanto, fazemos o contrário. Com o mesmo número de nós, o anel é dividido em um número significativamente maior de intervalos espalhados aleatoriamente pelo anel. As réplicas para a faixa são selecionadas de acordo com o algoritmo acima.

No exemplo acima, cada nó é responsável por dois intervalos. Se um dos nós falhar, sua carga inteira não ficará no próximo nó do anel, mas será distribuída entre os outros dois nós do cluster.
O anel é calculado com base em um pequeno conjunto de parâmetros algoritmicamente e é determinado em cada nó. Ou seja, não o armazenamos em algum tipo de configuração. Temos mais de cem mil dessas faixas em produção e, em caso de falha de qualquer um dos nós, a carga é distribuída de maneira absolutamente uniforme entre todos os outros nós vivos.
Como é a faixa de retorno para o usuário em um sistema com hash consistente?
O usuário através do balanceador L4 chega a um nó aleatório. A seleção do nó é aleatória, porque o balanceador não sabe nada sobre a topologia. Mas todas as réplicas do cluster sabem disso. O nó que recebeu a solicitação determina se é uma réplica da faixa solicitada. Caso contrário, alterna para o modo proxy com uma das réplicas, estabelece uma conexão com ela e procura dados em seu armazenamento local. Se a faixa não estiver lá, a réplica a puxa do armazenamento de faixas, salva no armazenamento local e fornece o proxy, que redireciona os dados para o usuário.
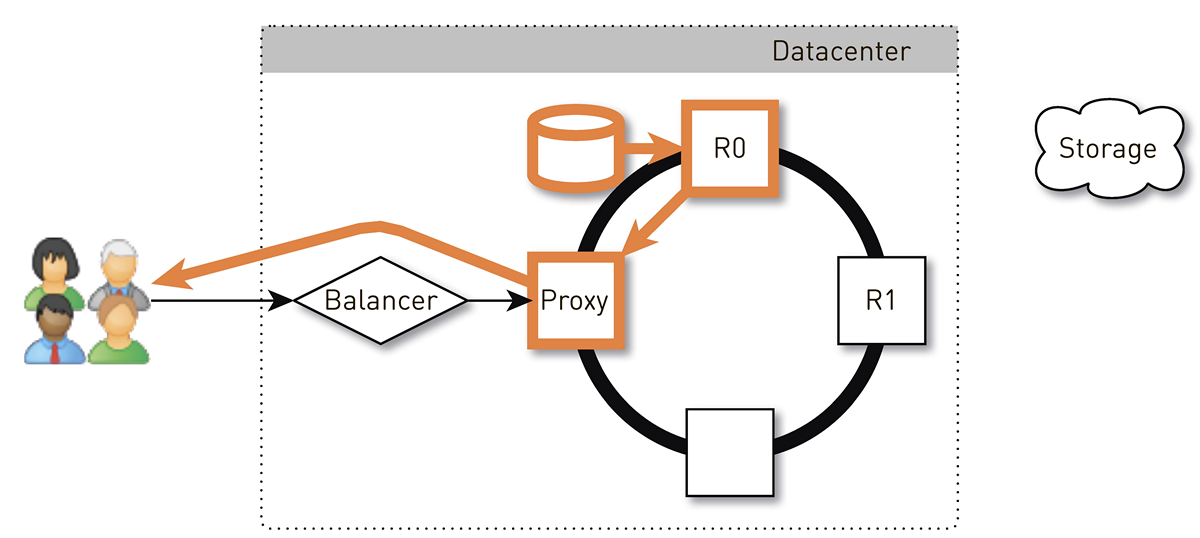
Se a unidade na réplica falhar, os dados do armazenamento serão transferidos diretamente para o usuário. E se a réplica falhar, o proxy conhecerá todas as outras réplicas dessa faixa, estabelecerá uma conexão com outra réplica ao vivo e receberá dados dela. Portanto, garantimos que, se um usuário solicitar uma faixa e pelo menos uma réplica estiver ativa, ele receberá uma resposta.
Como um nó funciona?
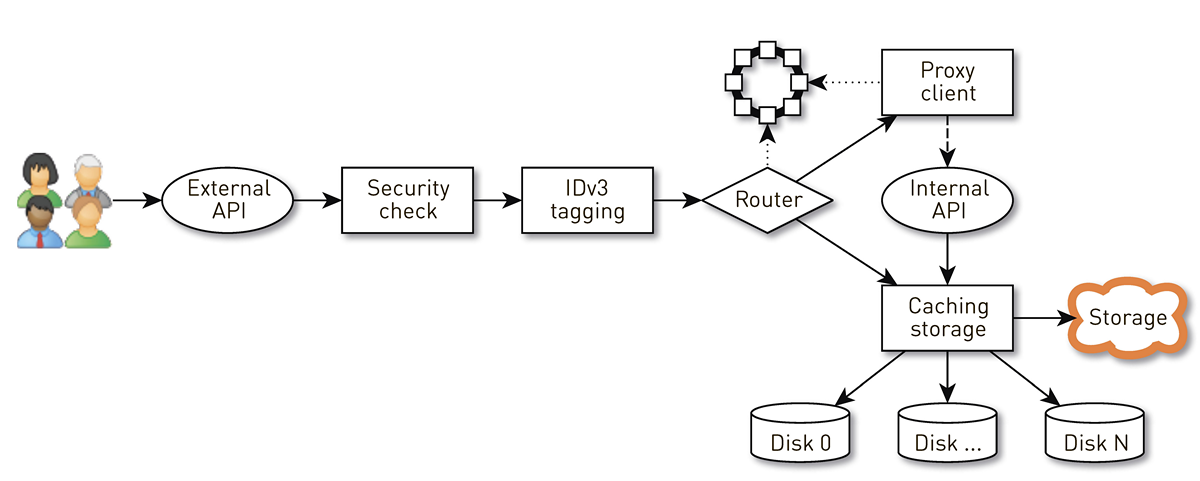
Um nó é um pipeline de um conjunto de estágios pelos quais a solicitação de um usuário passa. Primeiro, a solicitação vai para uma API externa (enviamos tudo via HTTPS). Em seguida, a solicitação é validada - as assinaturas são verificadas. Em seguida, as tags IDv3 são construídas, se necessário, por exemplo, ao comprar uma faixa. A solicitação vai para o estágio de roteamento, onde, com base na topologia do cluster, é determinado como os dados serão retornados: ou o nó atual é uma réplica para essa trilha ou faremos proxy de outro nó. No segundo caso, o nó através do cliente proxy estabelece uma conexão com a réplica por meio da API HTTP interna sem verificação de assinaturas. A réplica procura dados no armazenamento local, se encontrar uma faixa, fornece-os a partir do seu disco; e, se não, ele pega faixas do armazenamento, armazena em cache e dá.
Carga do nó
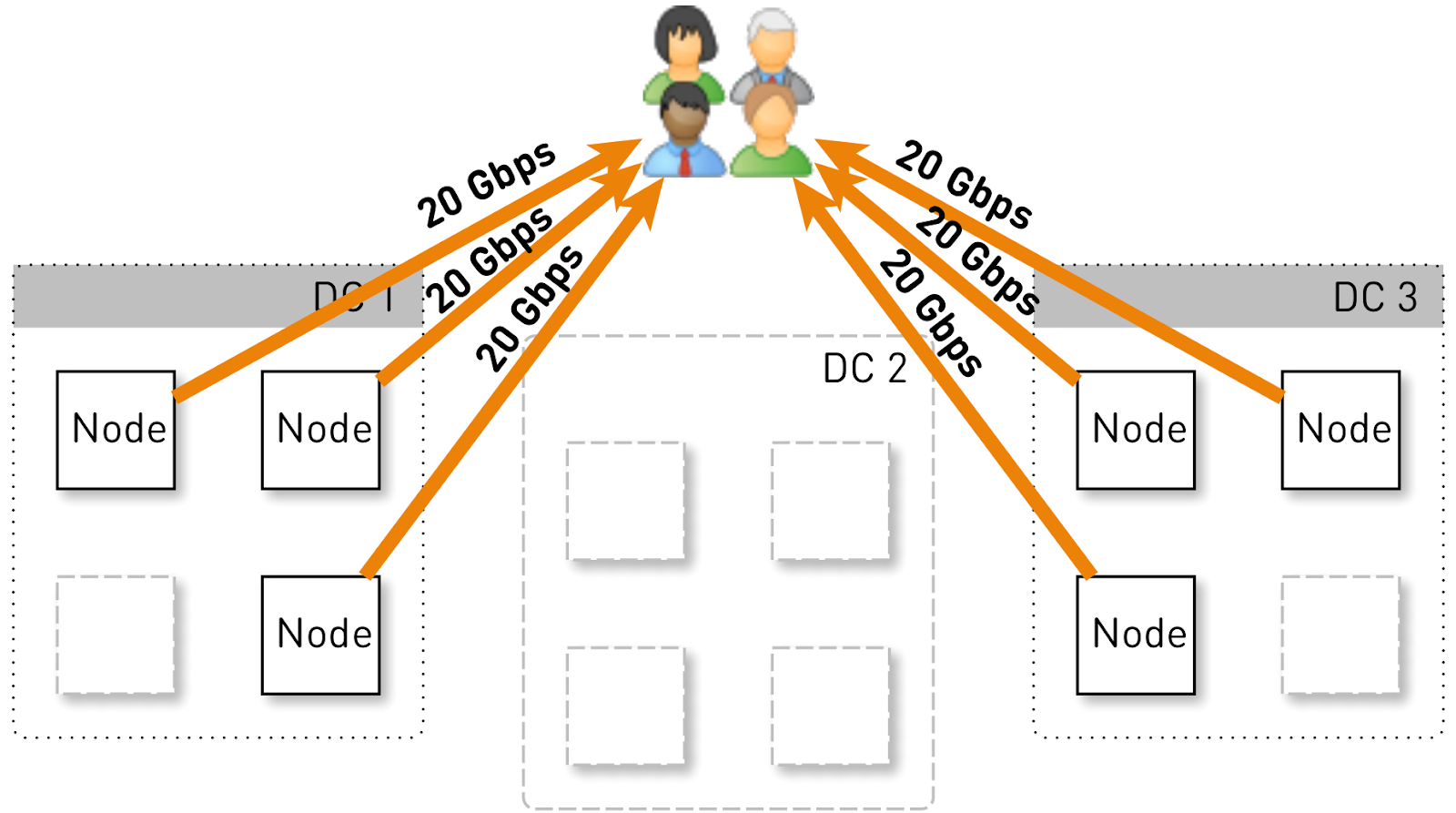
Vamos estimar qual carga um nó deve conter nessa configuração. Vamos ter três data centers com quatro nós cada.

Todo o serviço deve servir 120 Gbit / s, ou seja, 40 Gbit / s por data center. Suponha que os operadores de rede tenham feito manobras ou que tenham ocorrido um acidente e que restem dois data centers DC1 e DC3. Agora, cada um deles deve fornecer 60 Gbit / s. Mas aqui cabia aos desenvolvedores lançar alguma atualização, em cada data center havia 3 nós ativos restantes e cada um deles deveria fornecer 20 Gbit / s.
Porém, inicialmente em cada data center havia 4 nós. E se armazenarmos duas réplicas no data center, com uma probabilidade de 50%, o nó que recebeu a solicitação não será uma réplica da faixa solicitada e fará proxy dos dados. Ou seja, metade do tráfego dentro do datacenter é proxy.
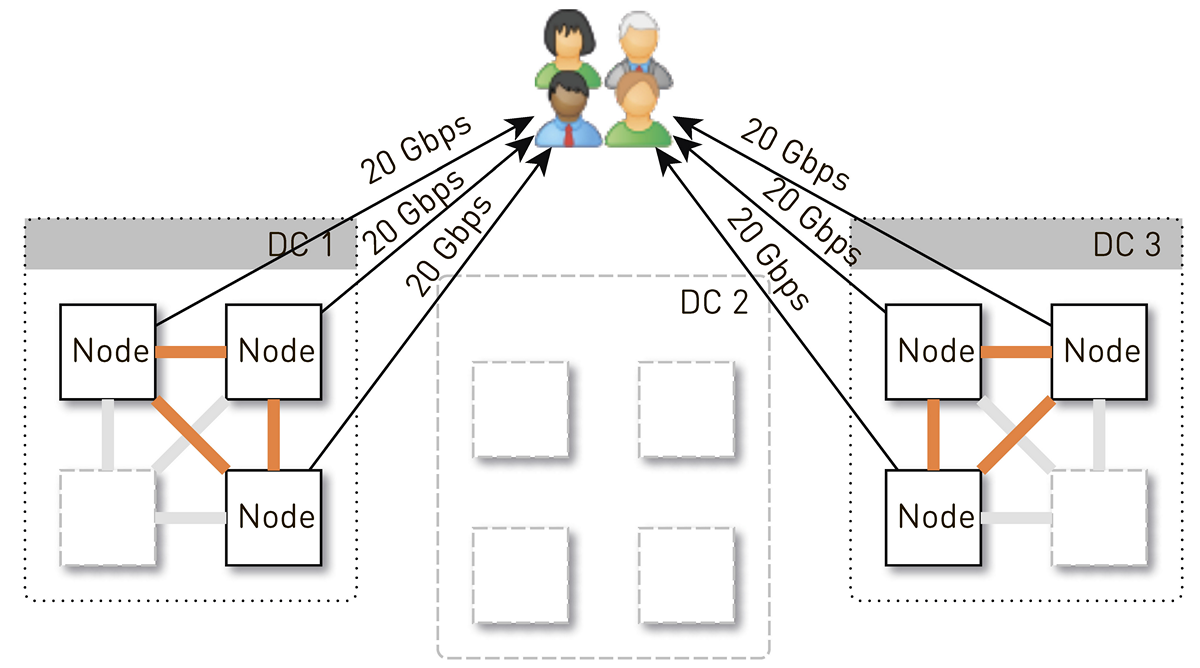
Portanto, um nó deve fornecer aos usuários 20 Gb / s. Destes, 10 Gb / s são extraídos de seus vizinhos no data center. Mas o esquema é simétrico: o nó fornece os mesmos 10 Gb / s para os vizinhos no data center. Acontece que 30 Gbit / s saem do nó, dos quais 20 Gbit / s devem ser atendidos por si só, uma vez que é uma réplica dos dados solicitados. Além disso, os dados serão provenientes de discos ou da RAM, que contém cerca de 50 mil faixas "quentes". Com base em nossas estatísticas de reprodução, isso permite remover 60 a 70% da carga dos discos e permanecerá em torno de 8 Gb / s. Esse segmento é capaz de fornecer uma dúzia de SSDs.
Armazenamento de dados em um nó
Se você colocar cada faixa em um arquivo separado, a sobrecarga de gerenciamento desses arquivos será enorme. Mesmo reiniciando os nós e varrendo os dados nos discos levará minutos, se não dezenas de minutos.
Existem limitações menos óbvias para esse esquema. Por exemplo, você pode carregar faixas apenas desde o início. E se o usuário solicitou a reprodução do meio e o cache foi perdido, não poderemos enviar um único byte até carregarmos os dados no local desejado no repositório de trilhas. Além disso, podemos armazenar as faixas apenas como um todo, mesmo que seja um audiolivro gigante que elas parem de ouvir no terceiro minuto. Ele continuará a ter peso morto no disco, desperdiçar espaço caro e reduzir a ocorrência de cache desse nó.
Portanto, fazemos isso de uma maneira completamente diferente: dividimos as faixas em blocos de 256 KB, porque isso se correlaciona com o tamanho do bloco no SSD e já estamos operando com esses blocos. Um disco de 1 TB contém 4 milhões de blocos. Cada disco em um nó é um armazenamento independente e todos os blocos de cada faixa são distribuídos por todos os discos.
Não chegamos imediatamente a esse esquema, a princípio todos os blocos de uma faixa estavam em um disco. Mas isso levou a uma forte distorção da carga entre os discos, pois se uma faixa popular atingir um dos discos, todos os pedidos de dados serão direcionados para um disco. Para evitar isso, distribuímos os blocos de cada trilha em todos os discos, equilibrando a carga.
Além disso, não esquecemos que temos um monte de RAM, mas decidimos não fazer o cache semântico, pois temos um maravilhoso cache de páginas no Linux.
Como armazenar blocos em discos?
Primeiro, decidimos obter um arquivo XFS gigante do tamanho de um disco e colocar todos os blocos nele. Então surgiu a ideia de trabalhar diretamente com um dispositivo de bloco. Implementamos as duas opções, comparamos-as e, ao trabalhar diretamente com um dispositivo de bloco, a gravação é 1,5 vezes mais rápida, o tempo de resposta é 2-3 vezes menor, a carga total do sistema é 2 vezes menor.
Índice
Mas não basta armazenar blocos; você precisa manter um índice de blocos de faixas de música para blocos em disco.

Acabou sendo bastante compacto, uma entrada de índice leva apenas 29 bytes. Para um armazenamento de 10 TB, o índice é um pouco acima de 1 GB.
Há um ponto interessante aqui. Em cada um desses registros, você deve armazenar o tamanho total de toda a faixa. Este é um exemplo clássico de desnormalização. O motivo é que, de acordo com a especificação na resposta do intervalo HTTP, devemos retornar o tamanho total do recurso, bem como formar um cabeçalho de comprimento de conteúdo. Se não fosse isso, tudo seria ainda mais compacto.
Formulamos vários requisitos para o índice: trabalhar rapidamente (de preferência armazenado na RAM), ser compacto e não ocupar espaço no cache da página. Outro índice deve ser persistente. Se o perdermos, perderemos informações sobre o local no disco em que faixa está armazenada e isso equivale à limpeza dos discos. E, em geral, eu gostaria que os blocos antigos, que não são acessados há muito tempo, fossem de alguma forma suplantados, abrindo espaço para faixas mais populares. Escolhemos
a política de exclusão de LRU : os blocos são bloqueados a cada minuto, 1% dos blocos são mantidos livres. Obviamente, a estrutura do índice deve ser segura para threads, porque temos 100 mil conexões por nó. Todas essas condições são idealmente satisfeitas pelo
SharedMemoryFixedMap da nossa biblioteca de código aberto
one-nio .
Colocamos o índice em
tmpfs , ele funciona rapidamente, mas há uma nuance. Quando a máquina é reiniciada, tudo o que estava no
tmpfs , incluindo o índice, é perdido. Além disso, se devido ao
sun.misc.Unsafe nosso processo travou, não está claro em que estado o índice permaneceu. Portanto, fazemos uma impressão disso uma vez por hora. Mas isso não é suficiente: como usamos a extrusão de bloco, precisamos oferecer suporte ao
WAL , no qual escrevemos informações sobre blocos extrudados. Entradas sobre blocos em elencos e WALs precisam ser classificadas de alguma forma durante a recuperação. Para fazer isso, usamos o bloco de geração. Ele desempenha o papel de um contador de transações globais e é incrementado sempre que o índice é alterado. Vejamos um exemplo de como isso funciona.
Faça um índice com três entradas: dois blocos da faixa nº 1 e um bloco da faixa nº 2.
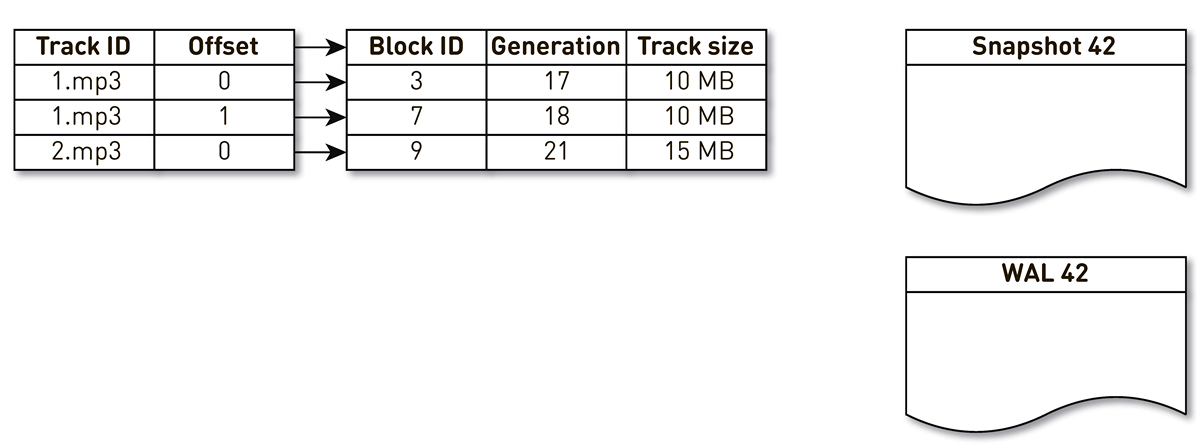
O fluxo de criação de lançamentos é despertado e iterado por este índice: a primeira e a segunda tuplas se enquadram no elenco. Em seguida, o fluxo de aglomeração se volta para o índice, percebe que o sétimo bloco não foi acessado por um longo tempo e decide usá-lo para outra coisa. O processo força o bloqueio e grava um registro no WAL. Ele chega ao bloco 9, vê que ele não é contatado há muito tempo e também o marca como lotado. Aqui, o usuário acessa o sistema e ocorre uma falha no cache - é solicitada uma faixa que não temos. Nós salvamos o bloco dessa faixa em nosso repositório, substituindo o bloco 9. Ao mesmo tempo, a geração é incrementada e se torna igual a 22. Em seguida, é ativado o processo de criação de um molde, que não concluiu seu trabalho, atinge o último registro e o grava no molde. Como resultado, temos dois registros ao vivo no índice, um elenco e o WAL.
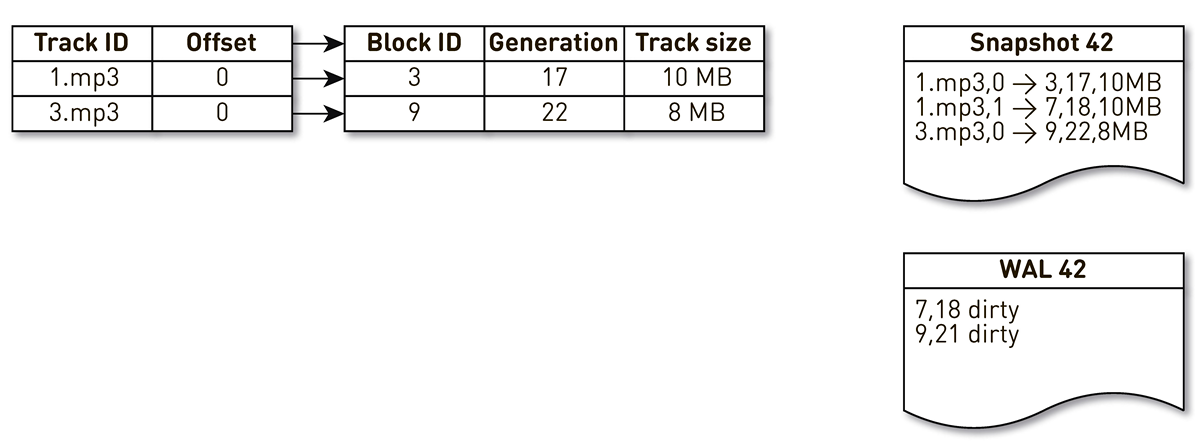
Quando o nó atual cai, ele restaurará o estado inicial do índice da seguinte maneira. Primeiro, verifique o WAL e crie um mapa de blocos sujo. O cartão armazena o mapeamento do número do bloco até a geração em que esse bloco foi substituído.
Depois disso, começamos a iterar sobre o molde usando o mapa como filtro. Olhamos para o primeiro registro do elenco, que se refere ao bloco número 3. Ele não é mencionado entre os sujos, o que significa que ele está vivo e entra no índice. Chegamos ao bloco número 7 com a décima oitava geração, mas o mapa sujo diz-nos que apenas na 18ª geração o bloco estava lotado. Portanto, ele não se enquadra no índice. Chegamos ao último registro, que descreve o conteúdo do bloco 9 com 22 gerações. Este bloco é mencionado no mapa de blocos sujo, mas foi substituído anteriormente. Portanto, é reutilizado para novos dados e entra no índice. O objetivo é alcançado.
Otimizações
Mas isso não é tudo, vamos mais fundo.
Vamos começar com o cache da página. Contamos com isso inicialmente, mas quando começamos a realizar testes de carga da primeira versão,
a taxa de acertos no cache da página não atingiu 20%. Eles sugeriram que o problema fosse lido adiante: não armazenamos arquivos, mas bloqueia, enquanto servimos várias conexões e, nessa configuração, trabalhar com o disco é aleatoriamente eficiente. Quase nunca lemos nada sequencialmente. Felizmente, no Linux, existe uma chamada
posix_fadvise que permite que você informe ao kernel como vamos trabalhar com o descritor de arquivo - em particular, podemos dizer que não precisamos ler adiante, passando a flag
POSIX_FADV_RANDOM . Essa chamada do sistema está disponível no
one-nio . Em operação, nosso acerto de cache é de 70 a 80%. O número de leituras físicas de discos diminuiu mais de 2 vezes, o atraso na resposta HTTP diminuiu 20%.
. heap. TLB- , Huge Pages Java-. (GC Time/Safepoint Total Time 20-30% ), , HTTP latency .
( ) .
. , , , , . , - . , . , , . , Daft Punk №2 sdc, sdd.
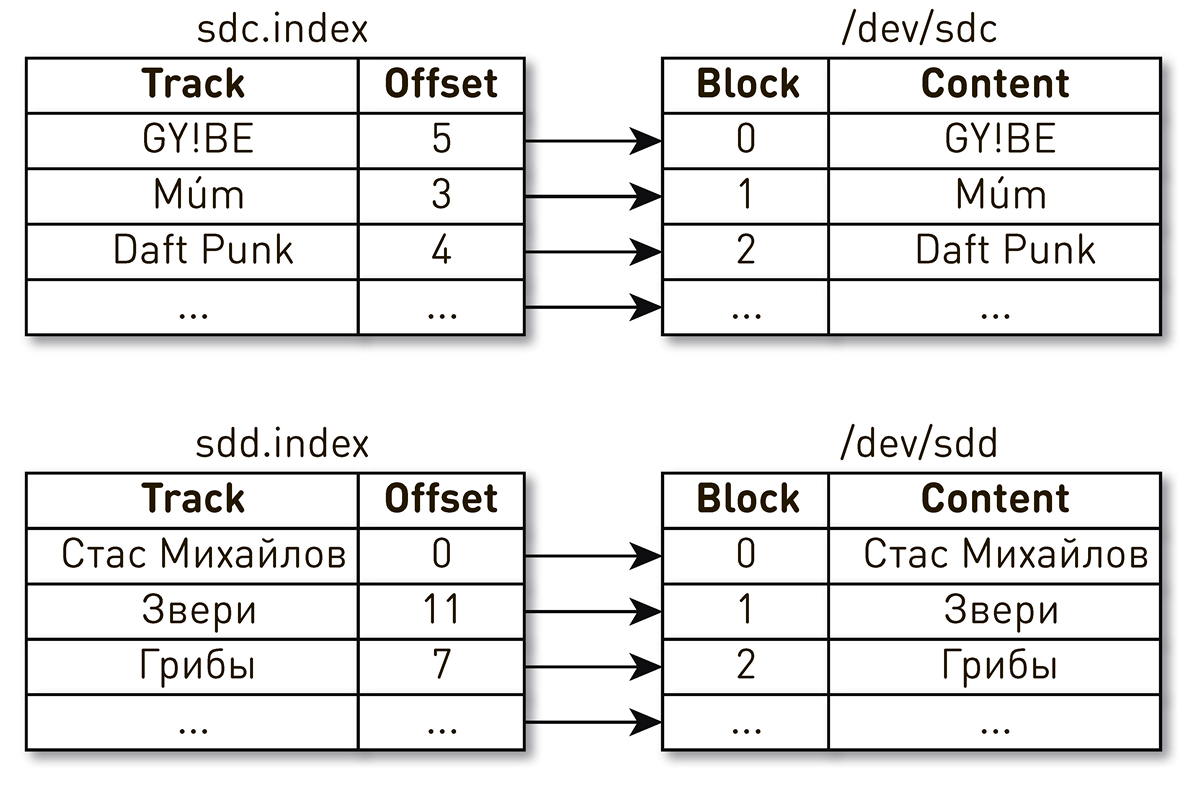
, . Linux
: , .

. ID.
WWN , WAL. , , .
A análise de problemas nesses sistemas distribuídos é difícil porque uma solicitação do usuário passa por muitos estágios e atravessa os limites dos nós. No caso da CDN, tudo se torna ainda mais complicado, porque, para a CDN, o upstream é o data center doméstico. Pode haver muitas dessas esperanças. Além disso, o sistema atende centenas de milhares de conexões de usuários. É muito difícil entender em que estágio há um problema no processamento de uma solicitação de um usuário específico.Nós simplificamos nossas vidas assim. No login, marcamos todas as solicitações com uma tag semelhante a Open Tracing e Zipkin . , . , , HTTP- . , , , , , , .
. , : , , .
ByteBuffer buffer = ByteBuffer.allocate(size); int count = fileChannel.read(buffer, position); if (count <= 0) {
, :
FileChannel.read() kernel space user space;SocketChannel.write() , user space kernel space.
, Linux
sendfile() , , user space. ,
one-nio . ,
sendfile() — 10 /
sendfile() 0.
user-space SSL-
sendfile() , . .
SocketChannel FileChannel ,
Async Profiler ,
sun.nio.ch.IOUtil ,
read() write() . .
ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining()); try { int n = readIntoNativeBuffer(fd, bb, position, nd); bb.flip(); if (n > 0) dst.put(bb); return n; } finally { Util.offerFirstTemporaryDirectBuffer(bb); }
. heap
ByteBuffer , , , heap
ByteBuffer , . .
.
one-nio .
MallocMT — , . SSL , Java heap,
ByteBuffer ,
FileChannel . .
final Allocator allocator = new MallocMT(size, concurrency); int write(Socket socket) { if (socket.getSslContext() != null) { long address = allocator.malloc(size); ByteBuffer buf = DirectMemory.wrap(address, size); int available = channel.read(buf, offset); socket.writeRaw(address, available, flags);
100 000
Mas o sucesso do sistema não é garantido por uma implementação razoável nos níveis mais baixos. Há outro problema aqui. O transportador em cada nó atende até 100 mil conexões simultâneas. Como organizar os cálculos nesse sistema?A primeira coisa que vem à mente é criar um encadeamento de execução para cada cliente ou conexão, e nele realizamos os estágios do pipeline um após o outro. Se necessário, bloqueie e siga em frente. Mas, com esse esquema, os custos das trocas de contexto e das pilhas de fluxos serão excessivos, pois estamos falando de um distribuidor e há muitos fluxos. Portanto, seguimos o outro caminho.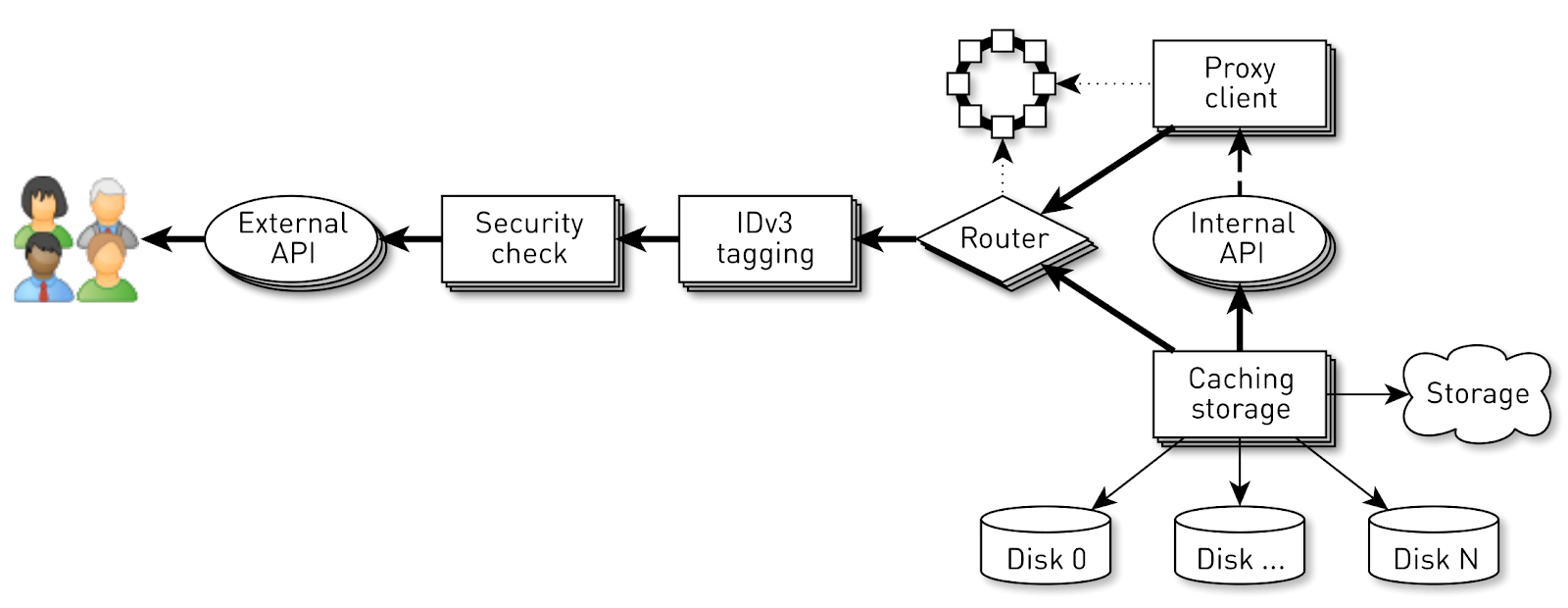 Um pipeline lógico é criado para cada conexão, que consiste em estágios interagindo entre si de forma assíncrona. Cada estágio tem uma curva que armazena solicitações recebidas. Para a execução de estágios, pequenos conjuntos de encadeamentos comuns são usados. Se você precisar processar uma mensagem da fila de solicitações, pegamos um fluxo do pool, processamos a mensagem e retornamos o fluxo ao pool. Com esse esquema, os dados são enviados do armazenamento para o cliente.Mas esse esquema não é isento de falhas. Os back-ends são muito mais rápidos que as conexões do usuário. Quando os dados passam pelo pipeline, eles se acumulam no estágio mais lento, ou seja, no estágio de gravação de blocos no soquete de conexão do cliente. Cedo ou tarde, isso levará ao colapso do sistema. Se você tentar limitar as filas nesses estágios, tudo será interrompido instantaneamente, porque os pipelines da cadeia para o soquete do usuário serão bloqueados. E como eles usam conjuntos de encadeamentos compartilhados, eles bloquearão todos os encadeamentos neles. Precisa de contrapressão.Para fazer isso, usamos fluxos de jato. A essência da abordagem é que o assinante controla a velocidade dos dados provenientes do editor usando a demanda. Demanda significa quanto mais dados o assinante está pronto para processar, juntamente com a demanda anterior que já sinalizou. O editor tem o direito de enviar dados, mas não excedendo a demanda total acumulada no momento, menos os dados já enviados.Assim, o sistema alterna dinamicamente entre os modos push e pull. No modo push, o assinante é mais rápido que o editor, o que significa que o editor sempre tem uma demanda insatisfatória do assinante, mas não há dados. Assim que os dados aparecem, ele os envia imediatamente para o assinante. O modo pull ocorre quando o editor é mais rápido que o assinante. Ou seja, o editor ficaria feliz em enviar dados, apenas a demanda é zero. Assim que o assinante diz que está pronto para processar um pouco mais, o editor envia imediatamente um pedaço de dados como parte da demanda.Nosso transportador se transforma em um fluxo de jato. Cada estágio se transforma em editor para o estágio anterior e assinante no próximo.A interface dos fluxos de jato parece extremamente simples.
Um pipeline lógico é criado para cada conexão, que consiste em estágios interagindo entre si de forma assíncrona. Cada estágio tem uma curva que armazena solicitações recebidas. Para a execução de estágios, pequenos conjuntos de encadeamentos comuns são usados. Se você precisar processar uma mensagem da fila de solicitações, pegamos um fluxo do pool, processamos a mensagem e retornamos o fluxo ao pool. Com esse esquema, os dados são enviados do armazenamento para o cliente.Mas esse esquema não é isento de falhas. Os back-ends são muito mais rápidos que as conexões do usuário. Quando os dados passam pelo pipeline, eles se acumulam no estágio mais lento, ou seja, no estágio de gravação de blocos no soquete de conexão do cliente. Cedo ou tarde, isso levará ao colapso do sistema. Se você tentar limitar as filas nesses estágios, tudo será interrompido instantaneamente, porque os pipelines da cadeia para o soquete do usuário serão bloqueados. E como eles usam conjuntos de encadeamentos compartilhados, eles bloquearão todos os encadeamentos neles. Precisa de contrapressão.Para fazer isso, usamos fluxos de jato. A essência da abordagem é que o assinante controla a velocidade dos dados provenientes do editor usando a demanda. Demanda significa quanto mais dados o assinante está pronto para processar, juntamente com a demanda anterior que já sinalizou. O editor tem o direito de enviar dados, mas não excedendo a demanda total acumulada no momento, menos os dados já enviados.Assim, o sistema alterna dinamicamente entre os modos push e pull. No modo push, o assinante é mais rápido que o editor, o que significa que o editor sempre tem uma demanda insatisfatória do assinante, mas não há dados. Assim que os dados aparecem, ele os envia imediatamente para o assinante. O modo pull ocorre quando o editor é mais rápido que o assinante. Ou seja, o editor ficaria feliz em enviar dados, apenas a demanda é zero. Assim que o assinante diz que está pronto para processar um pouco mais, o editor envia imediatamente um pedaço de dados como parte da demanda.Nosso transportador se transforma em um fluxo de jato. Cada estágio se transforma em editor para o estágio anterior e assinante no próximo.A interface dos fluxos de jato parece extremamente simples. Publishervamos assinarSubscriber , e ele deve implementar apenas quatro manipuladores: interface Publisher<T> { void subscribe(Subscriber<? super T> s); } interface Subscriber<T> { void onSubscribe(Subscription s); void onNext(T t); void onError(Throwable t); void onComplete(); } interface Subscription { void request(long n); void cancel(); }
Subscription permite sinalizar a demanda e cancelar a inscrição. Nenhum lugar é mais fácil.
Como elemento de dados, não passamos matrizes de bytes, mas uma abstração como chunk. Fazemos isso para não arrastar os dados na pilha, se possível. Chunk é um link de dados com uma interface muito limitada que permite apenas ler dados ByteBuffer, gravar em um soquete ou em um arquivo. interface Chunk { int read(ByteBuffer dst); int write(Socket socket); void write(FileChannel channel, long offset); }
Existem muitas implementações de chunks:- O mais popular, usado no caso de acerto no cache e ao enviar dados do disco, é a implementação no topo
RandomAccessFile. O pedaço contém apenas um link para o arquivo, o deslocamento nesse arquivo e o tamanho dos dados. Ele percorre todo o pipeline, atinge o soquete de conexão do usuário e ali se transforma em uma chamada sendfile(). Ou seja, a memória não é consumida. - cache miss : . , — , , — .
- , - heap.
ByteBuffer .
Apesar da simplicidade desta API, ela deve ser segura por thread por especificação e a maioria dos métodos deve ser sem bloqueio. Escolhemos o caminho no espírito do Modelo de ator digitado, inspirado em exemplos do repositório oficial de jet stream . Para fazer chamadas de método sem bloqueio, quando chamamos o método, pegamos todos os parâmetros, envolvemos em uma mensagem, colocamos na fila para execução e retornamos o controle. As mensagens da fila são processadas estritamente em sequência.Sem sincronização, o código é simples e direto.. publisher subscriber , , executor, .
AtomicBoolean happens before .
:
@Override void request(final long n) { enqueue(new Request(n)); } void enqueue(final M message) { mailbox.offer(message); tryScheduleToExecute(); }
tryScheduleToExecute() :
if (on.compareAndSet(false, true)) { try { executor.execute(this); } catch (Exception e) { ... } }
run() :
if (on.get()) try { dequeueAndProcess(); } finally { on.set(false); if (!messages.isEmpty()) { tryScheduleToExecute(); } } }
dequeueAndProcess() :
M message; while ((message = mailbox.poll()) != null) {
Temos uma implementação completamente sem bloqueio. código simples e consistente, sem volatile, Atomic*, contenção, e outros. Em todo o nosso sistema, há um total de 200 threads para atender 100.000 conexões.No final
production 12 , . 10 / . . Java
one-nio .
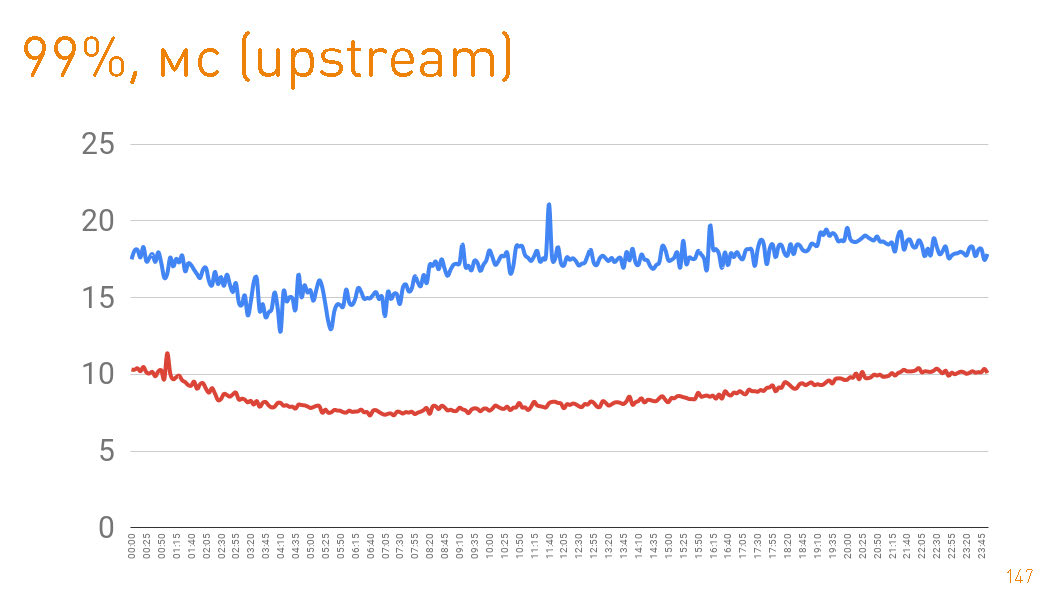
, . 99- 20 . — HTTPS-. —
sendfile() HTTP.
cache hit production 97%, latency , , , .
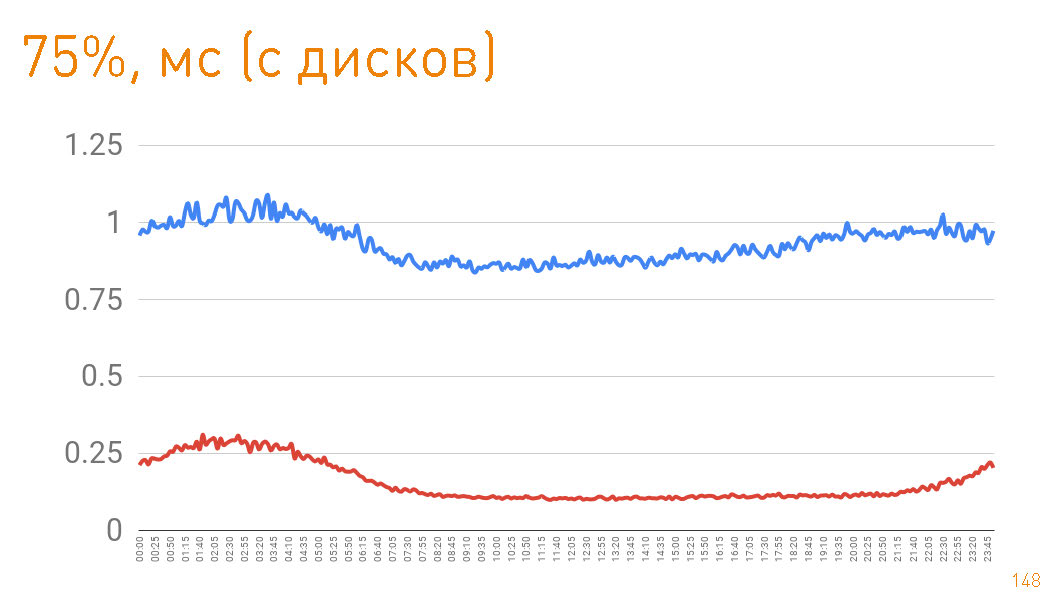 Se você observar o 75º percentil ao retornar de discos, o primeiro byte voará para o usuário após 1 ms. As réplicas dentro do cluster se comunicam com velocidade ainda maior - elas são responsáveis por 300 μs.
Se você observar o 75º percentil ao retornar de discos, o primeiro byte voará para o usuário após 1 ms. As réplicas dentro do cluster se comunicam com velocidade ainda maior - elas são responsáveis por 300 μs. I.e.
0,7 ms é o custo de proxy.Neste artigo, queríamos demonstrar como construímos sistemas escaláveis e altamente carregados, com alta velocidade e excelente tolerância a falhas. Esperamos ter conseguido.