Recentemente,
conversamos sobre como obter um estágio no Google. Além do Google, nossos alunos experimentam JetBrains, Yandex, Acronis e outras empresas.
Neste artigo, compartilharei minha experiência de estágio na
JetBrains Research , falarei sobre as tarefas que eles resolvem lá e detalharei como o aprendizado de máquina pode procurar bugs no código do programa.

Sobre mim
Meu nome é Egor Bogomolov, sou aluno do quarto ano do curso de graduação em SSMA de São Petersburgo em Matemática Aplicada e Ciência da Computação. Nos primeiros três anos, eu, como meus colegas de classe, estudei na Universidade Acadêmica e, desde setembro, nos mudamos para a Escola Superior de Economia com todo o departamento.
Após o segundo ano, estive em um estágio de verão no Google Zurich. Lá, passei três meses trabalhando na equipe do Calendário Android, na maioria das vezes fazendo frontend'om e um pouco de pesquisa sobre UX. A parte mais interessante do meu trabalho foi a pesquisa sobre como as interfaces do calendário podem parecer no futuro. Acabou sendo agradável que quase todo o trabalho que fiz no final do estágio tenha terminado na versão principal do aplicativo. Mas o tópico de estágios no Google é muito bem abordado em uma postagem anterior, então vou falar sobre o que fiz neste verão.
O que é JB Research?
O JetBrains Research é um conjunto de laboratórios que trabalham em vários campos: linguagens de programação, matemática aplicada, aprendizado de máquina, robótica e outros. Dentro de cada área existem vários grupos científicos. Devido à minha direção, conheço melhor as atividades de grupos no campo de aprendizado de máquina. Cada um deles organiza seminários semanais nos quais os membros do grupo ou convidados conversam sobre seu trabalho ou artigos interessantes em seu campo. Muitos estudantes do HSE comparecem a esses seminários, pois atravessam a rua do edifício principal do Campus de HSE em São Petersburgo.
No nosso programa de bacharelado, estamos obrigatoriamente envolvidos em trabalhos de pesquisa (P&D) e apresentamos os resultados da pesquisa duas vezes por ano. Muitas vezes, esse trabalho gradualmente se transforma em estágios de verão. Isso também aconteceu com meu trabalho de pesquisa: neste verão, fiz um estágio no laboratório “Métodos de aprendizado de máquina em engenharia de software” com meu supervisor de pesquisa Timofey Bryksin. As tarefas que estão sendo trabalhadas neste laboratório incluem sugestões automáticas de refatoração, análise do estilo de código para programadores, conclusão de código, pesquisa de erros no código do programa.
Meu estágio durou dois meses (julho e agosto) e, no outono, continuei envolvido em tarefas designadas no âmbito da pesquisa. Trabalhei em várias áreas, a mais interessante delas, na minha opinião, foi a busca automática de bugs no código, e quero falar sobre isso. O ponto de partida foi
um artigo de Michael Pradel .
Pesquisa automática de bugs
Como os bugs são pesquisados agora?
Por que procurar bugs é mais ou menos claro. Vamos ver como eles estão indo agora. Os detectores de erros modernos são baseados principalmente na análise de código estático. Para cada tipo de erro, procure padrões observados anteriormente pelos quais ele possa ser determinado. Então, para reduzir o número de falsos positivos, são inventadas heurísticas, inventadas para cada caso individual. Os padrões podem ser pesquisados em uma árvore de sintaxe abstrata (AST) construída por código e em gráficos de um fluxo ou dados de controle.
int foo() { if ((x < 0) || x > MAX) { return -1; } int ret = bar(x); if (ret != 0) { return -1; } else { return 1; } }
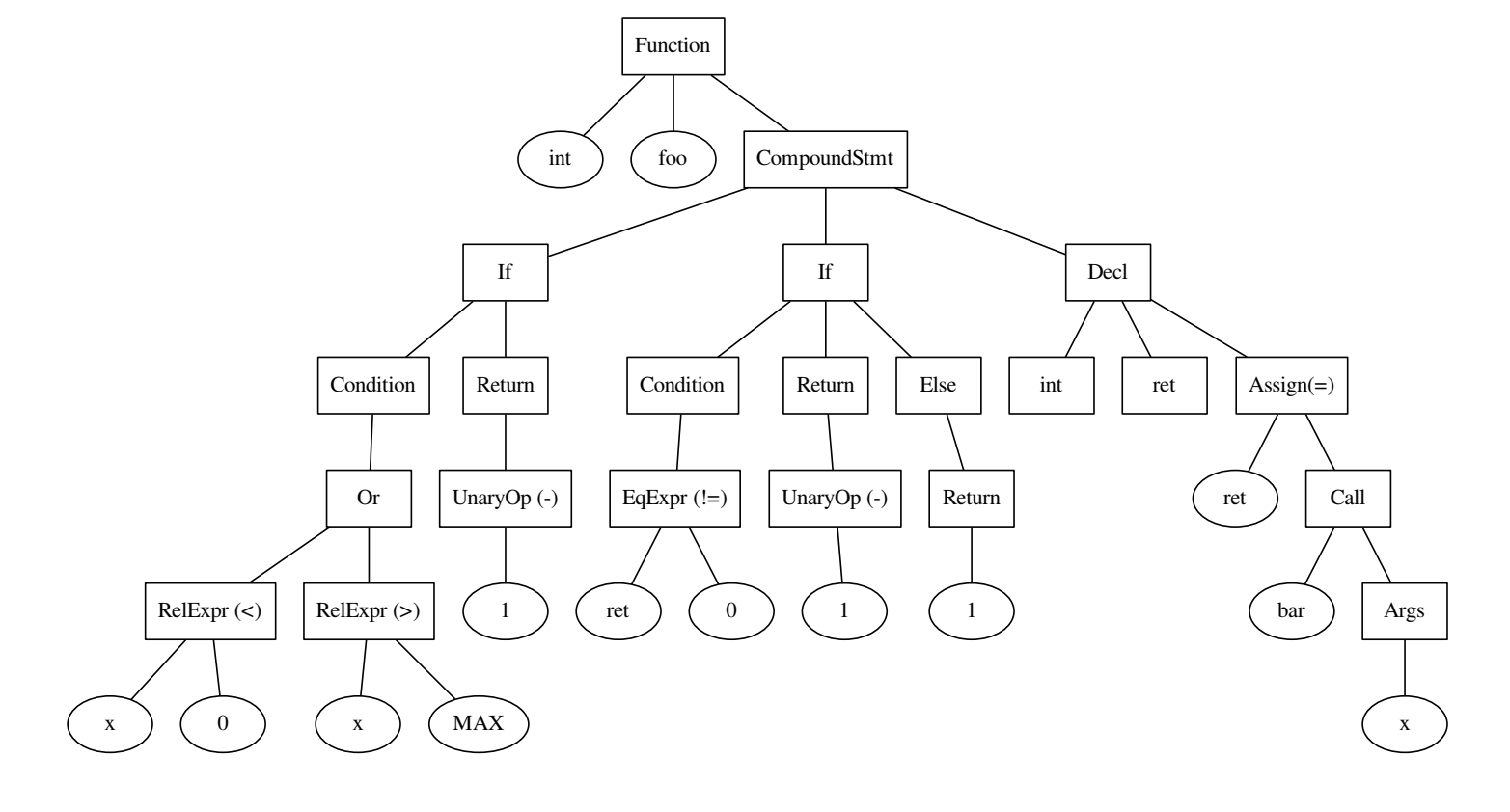
O código e a árvore que foi construída nele.
Para entender como isso funciona, considere um exemplo. O tipo de erro pode ser o uso de = em vez de == no C ++. Vejamos o seguinte trecho de código:
int value = 0; … if (value = 1) { ... } else { … }
Houve um erro na expressão condicional, enquanto o primeiro = na atribuição do valor à variável está correto. O padrão vem daqui: se a atribuição for usada dentro da condição em if, isso é um bug em potencial. Procurando um padrão desse tipo no AST, podemos detectar o erro e corrigi-lo.
int value = 0; … if (value == 1) { ... } else { … }
Em um caso mais geral, não conseguiremos encontrar uma maneira tão fácil de descrever o erro. Suponha que desejamos determinar a ordem correta dos operandos. Mais uma vez, observe os fragmentos de código:
for (int i = 2; i < n; i++) { a[i] = a[1 - i] + a[i - 2]; }
int bitReverse(int i) { return 1 - i; }
No primeiro caso, o uso de 1-i foi incorreto, e no segundo foi completamente correto, o que é claro a partir do contexto. Mas como descrevê-lo na forma de um padrão? Com a complicação do tipo de erros, temos que considerar uma seção maior do código e analisar cada vez mais casos individuais.
O último exemplo motivador: informações úteis também estão contidas nos nomes dos métodos e variáveis. É ainda mais difícil expressar por algumas condições especificadas manualmente.
int getSquare(int xDim, int yDim) { … } int x = 3, y = 4; int s = getSquare(y, x);
Uma pessoa entende que, muito provavelmente, os argumentos da chamada de função estão confusos, porque entendemos que x é mais parecido com xDim que com yDim. Mas como relatar isso ao detector? Você pode adicionar algum tipo de heurística da forma "o nome da variável é o prefixo do nome do argumento", mas suponha que x seja mais frequentemente uma largura do que uma altura, para que não seja mais expresso.
Total: o problema da abordagem moderna para encontrar erros é que muito trabalho deve ser feito com suas mãos: para determinar padrões, adicionar heurísticas, por isso, adicionar suporte a um novo tipo de erro no detector torna-se demorado. Além disso, é difícil usar uma parte importante das informações que o desenvolvedor deixou no código: os nomes das variáveis e métodos.
Como o aprendizado de máquina pode ajudar?
Como você deve ter notado, em muitos exemplos os erros são visíveis aos seres humanos, mas são difíceis de descrever formalmente. Nessas situações, os métodos de aprendizado de máquina geralmente podem ajudar. Vamos parar de procurar argumentos reorganizados em uma chamada de função e entender o que precisamos procurá-los usando o aprendizado de máquina:
- Um grande número de código de amostra sem erros
- Uma grande quantidade de código com erros de um determinado tipo
- Método para vetorizar fragmentos de código
- O modelo que vamos ensinar a distinguir entre código com e sem erros
Podemos esperar que, na maior parte do código apresentado em domínio público, os argumentos nas chamadas de função estejam na ordem correta. Portanto, para código de exemplo sem erros, você pode usar um grande conjunto de dados. No caso do autor do artigo original, era JS 150K (150 mil arquivos em Javascript), no nosso caso, um conjunto de dados semelhante para Python.
Encontrar código com bugs é muito mais difícil. Mas não podemos procurar os erros de outra pessoa, mas você mesmo! Para o tipo de erros, você precisa especificar uma função que, de acordo com o código correto, a corrompa. No nosso caso, reorganize os argumentos na chamada de função.
Como vetorizar o código?
Armado com muitos códigos bons e ruins, estamos quase prontos para ensinar alguma coisa. Antes disso, ainda precisamos responder à pergunta: como apresentar fragmentos de código?
Uma chamada de função pode ser representada como uma tupla do nome de um método, cujo nome é de qual método, os nomes e os tipos de argumentos transmitidos às variáveis. Se aprendermos como vetorizar tokens individuais (nomes de variáveis e métodos, todas as “palavras” encontradas no código), poderemos tomar a concatenação de vetores de tokens de seu interesse e obter o vetor desejado para o fragmento.
Para vetorizar tokens, vamos dar uma olhada em como as palavras em textos comuns se vetorizam. Uma das maneiras mais bem-sucedidas e populares é a word2vec proposta em 2013.
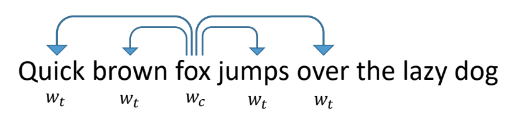
Funciona da seguinte forma: ensinamos à rede a prever por palavra outras palavras que aparecem próximas a ela nos textos. A rede ao mesmo tempo parece uma camada de entrada do tamanho de um dicionário, uma camada oculta do tamanho da vetorização que queremos obter e uma camada de saída, também do tamanho de um dicionário. Durante o treinamento, as redes são alimentadas com um vetor de unidade de entrada com uma unidade no lugar da palavra em questão (raposa) e, na saída, queremos obter palavras que ocorram dentro da janela em torno dessa palavra (rápido, marrom, saltos, sobre). Nesse caso, a rede primeiro traduz todas as palavras em um vetor em uma camada oculta e, em seguida, faz uma previsão.
Os vetores resultantes para palavras individuais têm boas propriedades. Por exemplo, vetores de palavras com significado semelhante estão próximos um do outro, e a soma e a diferença dos vetores são a adição e a diferença dos "significados" das palavras.
Para criar uma vetorização semelhante de tokens no código, você precisa definir de alguma forma o ambiente que será previsto. Eles podem ser informações do AST: tipos de vértices ao redor, tokens encontrados, posição em uma árvore.
Após receber uma vetorização, é possível ver quais tokens são semelhantes entre si. Para fazer isso, calcule a distância do cosseno entre eles. Como resultado, os seguintes vetores vizinhos são obtidos para Javascript (número é a distância do cosseno):
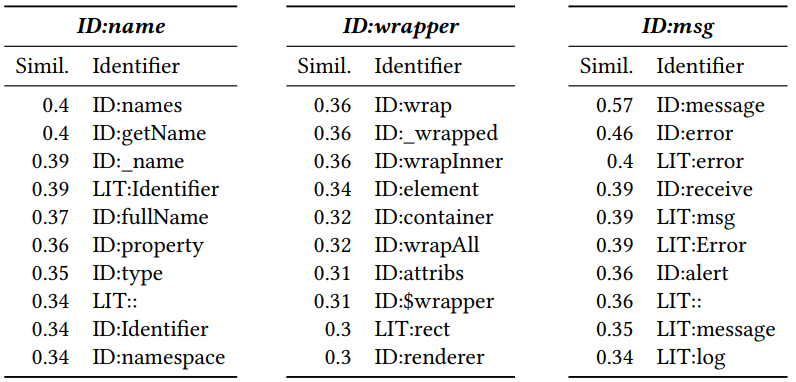
O ID e o LIT adicionados no início indicam se o token é um identificador (nome de uma variável, método) ou um literal (constante). Pode-se ver que a proximidade é significativa.
Treinamento do Classificador
Após receber uma vetorização para tokens individuais, obter uma exibição de um pedaço de código com um erro em potencial é bastante simples: é uma concatenação de vetores importantes para a classificação de tokens. Um perceptron de duas camadas é treinado em partes de código com ReLU como uma função de ativação e desistência para reduzir o sobreajuste. O aprendizado converge rapidamente, o modelo resultante é pequeno e pode fazer previsões para centenas de exemplos por segundo. Isso permite que você use em tempo real, o que será discutido mais adiante.
Resultados
A avaliação da qualidade do classificador resultante foi dividida em duas partes: avaliação em um grande número de exemplos gerados artificialmente e verificação manual em um número pequeno (50 para cada detector) de exemplos com a maior probabilidade prevista. Os resultados para os três detectores (argumentos reorganizados, a correção do operador binário e do operando binário) foram os seguintes:
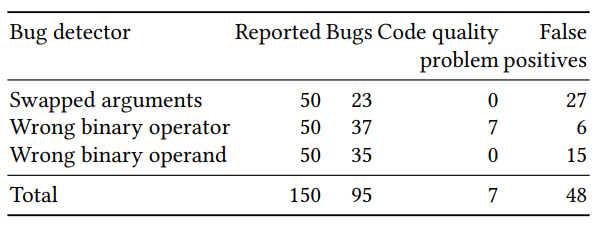
É difícil encontrar alguns dos erros previstos nos métodos de pesquisa clássicos. Um exemplo com res reorganizados e errar em uma chamada para p.done:
var p = new Promise (); if ( promises === null || promises . length === 0) { p. done (error , result ) } else { promises [0](error, result).then( function(res, err) { p.done(res, err); }); }
Havia também exemplos nos quais não havia erro, mas as variáveis deveriam ser renomeadas para não enganar a pessoa que tentava descobrir o código. Por exemplo, adicionar largura e cada um deles não parece uma boa ideia, apesar de não ser um bug:
var cw = cs[i].width + each;
Portabilidade Python
Eu estava envolvido em portar o trabalho de Michael Pradel de js para python e, em seguida, criar um plug-in para PyCharm que implementa inspeções com base no método descrito acima. Utilizamos o conjunto de dados
Python 150K (150 mil arquivos Python disponíveis no GitHub).
Primeiro, verificou-se que no Python existem mais tokens diferentes do que no javascript. Para js, os 10.000 tokens mais populares representavam mais de 90% de todos os encontrados, enquanto para o Python era necessário usar cerca de 40.000, o que levou a um aumento no tamanho do mapeamento de token em vetores, o que dificultou a portabilidade para o plug-in.
Em segundo lugar, tendo implementado para o Python uma busca por argumentos incorretos nas chamadas de função e analisando os resultados manualmente, obtive uma taxa de erro superior a 90%, que estava em desacordo com os resultados de js. Tendo entendido os motivos, descobriu-se que em javascript mais funções foram declaradas no mesmo arquivo que suas chamadas. Eu, seguindo o exemplo do autor do artigo, a princípio não permiti a declaração de funções de outros arquivos, o que levou a maus resultados.
No final de agosto, concluí a implementação do Python e escrevi a base do plug-in. O plugin continua a ser desenvolvido, agora a estudante Anastasia Tuchina do nosso laboratório está envolvida nisso.
Você pode encontrar as etapas para tentar como o plug-in funciona no wiki do repositório.
Links no github:
Repositório com implementação em pythonRepositório com plugin