Neste artigo, simulamos e examinamos um protocolo de confirmação de duas fases usando o TLA +.
O protocolo de confirmação de duas fases é prático e é usado hoje em muitos sistemas distribuídos. No entanto, é bastante curto. Portanto, podemos modelá-lo rapidamente e aprender muito. De fato, com este exemplo, ilustraremos qual resultado em sistemas distribuídos é
fundamentalmente impossível .
O problema de confirmação bifásica
A transação passa pelos
gerenciadores de recursos (RM) . Todos os RMs devem concordar se a transação será
concluída ou
abortada .
O Transaction Manager (TM) toma a decisão final:
confirmar ou
cancelar . A condição para o commit é a disposição de confirmar todos os RMs. Caso contrário, a transação deve ser cancelada.
Algumas notas sobre modelagem
Para simplificar, realizamos simulações em um modelo de memória compartilhada, não em um sistema de mensagens. Ele também fornece validação rápida de modelo. Mas adicionaremos não atomicidade às ações “lendo o nó vizinho e atualizando o estado” para capturar um comportamento interessante ao enviar mensagens.
O RM pode apenas ler o status da TM e ler / atualizar seu próprio estado. Ele não pode ler o status de outro gerenciador de recursos. Uma TM pode ler o estado de todos os nós do RM e ler / atualizar seu próprio estado.
Definições

As linhas 9 a 10 definem o
rmState inicial de cada RM para
working e a TM para
init .
O predicado
canCommit é
true se todos os RMs estiverem "preparados" (prontos para confirmar). Se o RM existir no estado final, o predicado
canAbort se tornará
canAbort .

Modelar TM é simples. O gerenciador de transações verifica a possibilidade de uma confirmação ou cancelamento - e atualiza o
tmState .
Existe a possibilidade de a TM não conseguir tornar o
tmState "inacessível", mas apenas se a constante
TMMAYFAIL configurada como
true antes que o modelo seja validado. Nos rótulos TLA +, determine o grau de atomicidade, ou seja, sua granularidade. Pelas etiquetas F1 e F2, denotamos que os operadores correspondentes são executados de maneira não-atômica (após um tempo indeterminado) em relação aos operadores anteriores.
Modelo RM

O modelo RM também é simples. Como os estados “trabalhando” e “preparado” são não finais, a RM escolhe de forma não determinística entre as ações até atingir o estado final. Um RM "trabalhando" pode entrar em um estado "interrompido" ou "preparado". O RM "preparado" espera uma confirmação / cancelamento da TM - e age de acordo. A figura abaixo mostra as possíveis transições de estado para um RM. Mas observe que temos vários RMs, cada um dos quais passa por seus estados em seu próprio ritmo, sem conhecer o estado dos outros RMs.
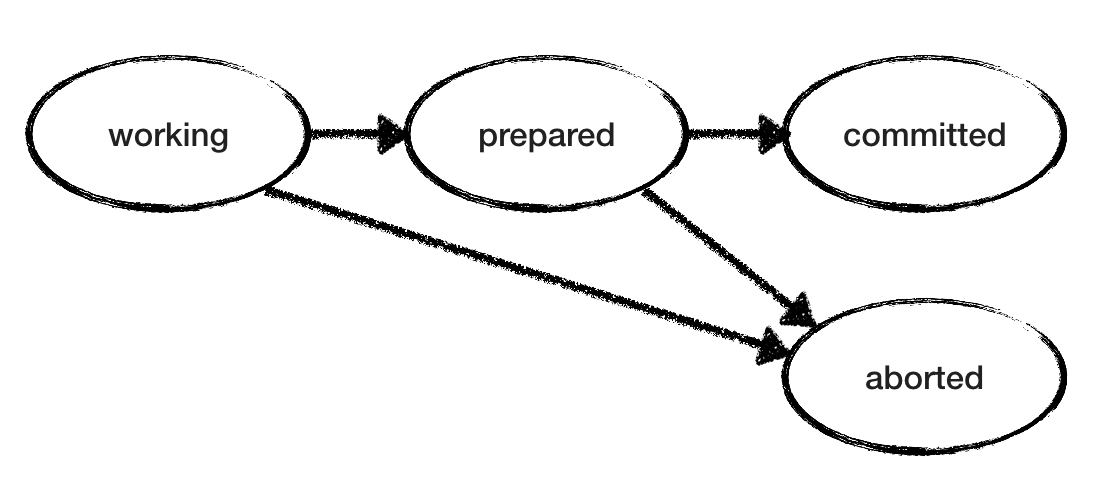
Modelo de confirmação de duas fases

Precisamos verificar a consistência do nosso comprometimento em duas fases: para que não haja RMs diferentes, um dos quais diz "comprometer" e o outro "aborto".
O predicado
Completed verifica se o protocolo não é
aborted para sempre: no final, cada RM atinge o estado final de
committed ou
aborted .
Agora estamos prontos para testar o modelo de protocolo. Inicialmente, definimos
TMMAYFAIL=FALSE, RM=1..3 para iniciar o protocolo com três RM e uma TM, ou seja, em uma configuração confiável. Testar o modelo leva 15 segundos e diz que não há erros.
Consistency e
Completed satisfeitos com qualquer possível execução de protocolo com qualquer alternância de ações de RM e ações de TM.

Agora defina
TMMAYFAIL=TRUE e reinicie a verificação. O programa produz rapidamente o resultado oposto, onde o RM ficou parado aguardando uma resposta de uma TM indisponível.

Vemos que no
State=4 transições RM2 são interrompidas, no
State=7 transições RM3 são interrompidas, no
State=8 MT entra no estado "desligado" e cai para o
State=9 . No
State=10 sistema congela porque o RM1 permanece para sempre em um estado preparado, aguardando uma decisão de uma MT caída.
Simulação BTM
Para evitar congelamentos de transações, adicionamos uma TM (BTM) de backup, que assume rapidamente o controle se a TM principal estiver indisponível. A BTM usa a mesma lógica da TM para tomar decisões. E, por simplicidade, assumimos que o BTM nunca falha.

Quando testamos o modelo com o processo BTM adicionado, recebemos uma nova mensagem de erro.

A BTM não pode aceitar uma confirmação porque nossa condição original,
canCommit afirma que todos os
RMstates devem ser "preparados" e não leva em conta a condição de que alguns RMs já tenham recebido uma decisão de confirmação da TM original antes que o TMB assuma o controle. É necessário reescrever as condições do
canCommit levando em consideração essa situação.

Sucesso! Quando testamos o modelo, obtemos consistência e integridade, pois o BTM assume o controle e conclui a transação se o TM cair.
Aqui está o modelo 2PCwithBTM no TLA + (o BTM e a segunda linha do canCommit são inicialmente não comentadas) e o
pdf correspondente .
E se o RM falhar também?
Assumimos que a RM é confiável. Agora cancele esta condição e veja como o protocolo se comporta quando o RM falha. Adicione o estado "inacessível" ao modelo de falha. Para investigar o comportamento e simular a perda intermitente de disponibilidade, permita que o RM de emergência se recupere e continue trabalhando lendo seu status no log. Aqui está outro diagrama de transição de estado RM com o estado "inacessível" adicionado e as transições marcadas em vermelho. E abaixo está o modelo revisado para RM.
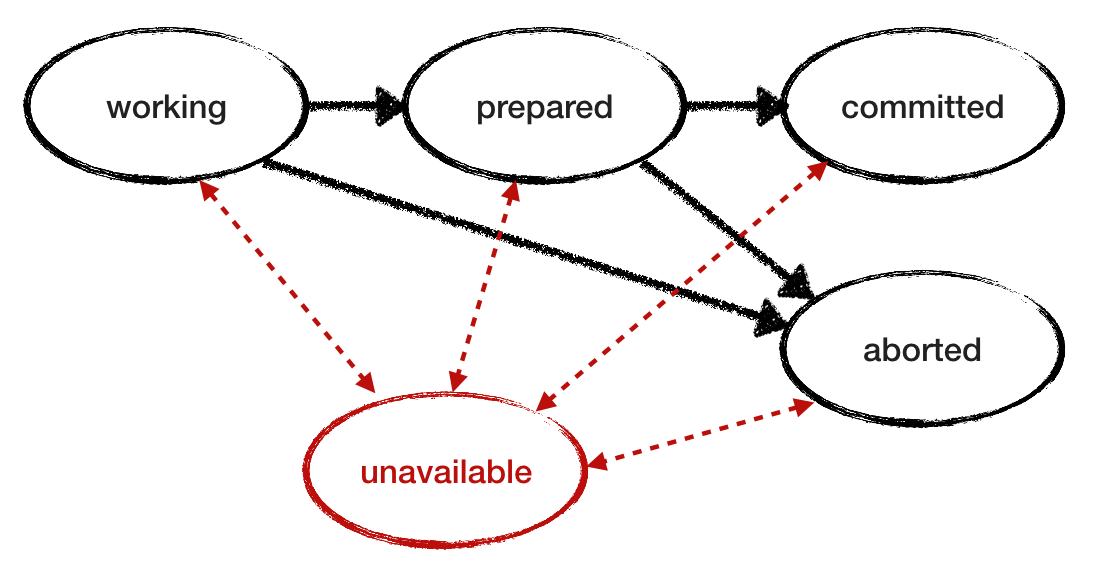

Também é necessário refinar o
canAbort levando em consideração o estado de indisponibilidade. A TM pode tomar a decisão de "desligar" se algum dos serviços estiver em um estado interrompido ou inacessível. Se essa condição for omitida, um RM caído e não restaurado interromperá o andamento da transação. Obviamente, novamente, você deve considerar os RMs que aprenderam a decisão de concluir a transação na TM de origem.
Verificação do modelo
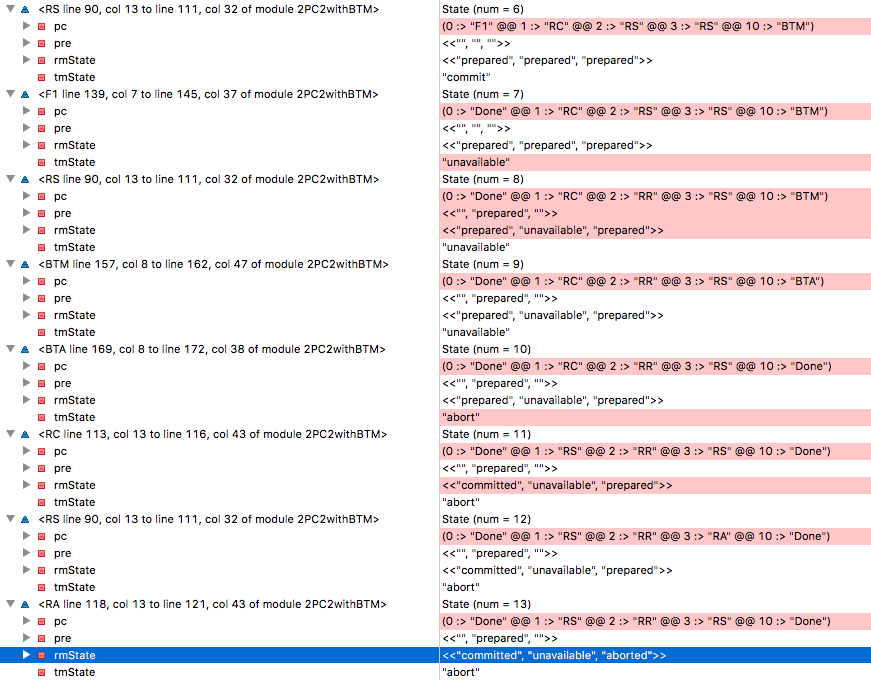
Quando testamos o modelo, há um problema de inconsistência! Como isso pôde acontecer? Nós rastreamos o rastreamento.
Com
State=6 todos os RMs estão em um estado preparado, a TM tomou a decisão de concluir a transação, o RM1 viu essa decisão e passou para o rótulo RC, o que significa prontidão para alterar seu estado para “concluído”. (Lembre-se de RM1, esta arma será disparada no último ato). Infelizmente, a TM cai no
State=7 e o RM2 fica indisponível no
State=8 . Na nona etapa, o BTM de backup assume o controle e lê o status dos três RMs como "preparados, inacessíveis, preparados" - e decide cancelar a transação na décima etapa. Lembra do RM1? Ele decide concluir a transação porque recebeu essa decisão da TM original e entra no estado
committed na etapa 11. No
State=13 RM3 cumpre a decisão de abortar a transação da BTM e entra no estado
aborted - e agora interrompemos a coordenação com o RM1.
Nesse caso, a BTM tomou uma decisão que violava a
consistência . Por outro lado, se você fizer com que o BTM aguarde o RM deixar o estado inacessível, ele poderá congelar para sempre em caso de acidente no nó, o que violará a condição de
cumprimento (progresso).
Um arquivo de modelo TLA + atualizado está disponível aqui , bem como o
pdf correspondente .
Impossibilidade FLP
Então o que aconteceu? Tropeçamos no
teorema de Fisher, Lynch, Paterson (FLP) sobre a impossibilidade de consenso em um sistema assíncrono com falhas.
Em nosso exemplo, a BTM não pode decidir corretamente se o RM2 está em um estado com falha ou não - e decide incorretamente abortar a transação. Se apenas a TM original tomou a decisão, essa imprecisão no reconhecimento de uma falha não seria um problema. O RM obedecerá a qualquer decisão da TM, para que a consistência e o progresso sejam mantidos.
O problema é que temos dois objetos que tomam decisões: TM e BTM, eles analisam o estado da RM em momentos diferentes e tomam decisões diferentes. Essa assimetria de informação é a raiz de todo mal nos sistemas distribuídos.
O problema não desaparece mesmo com a expansão para um commit trifásico.
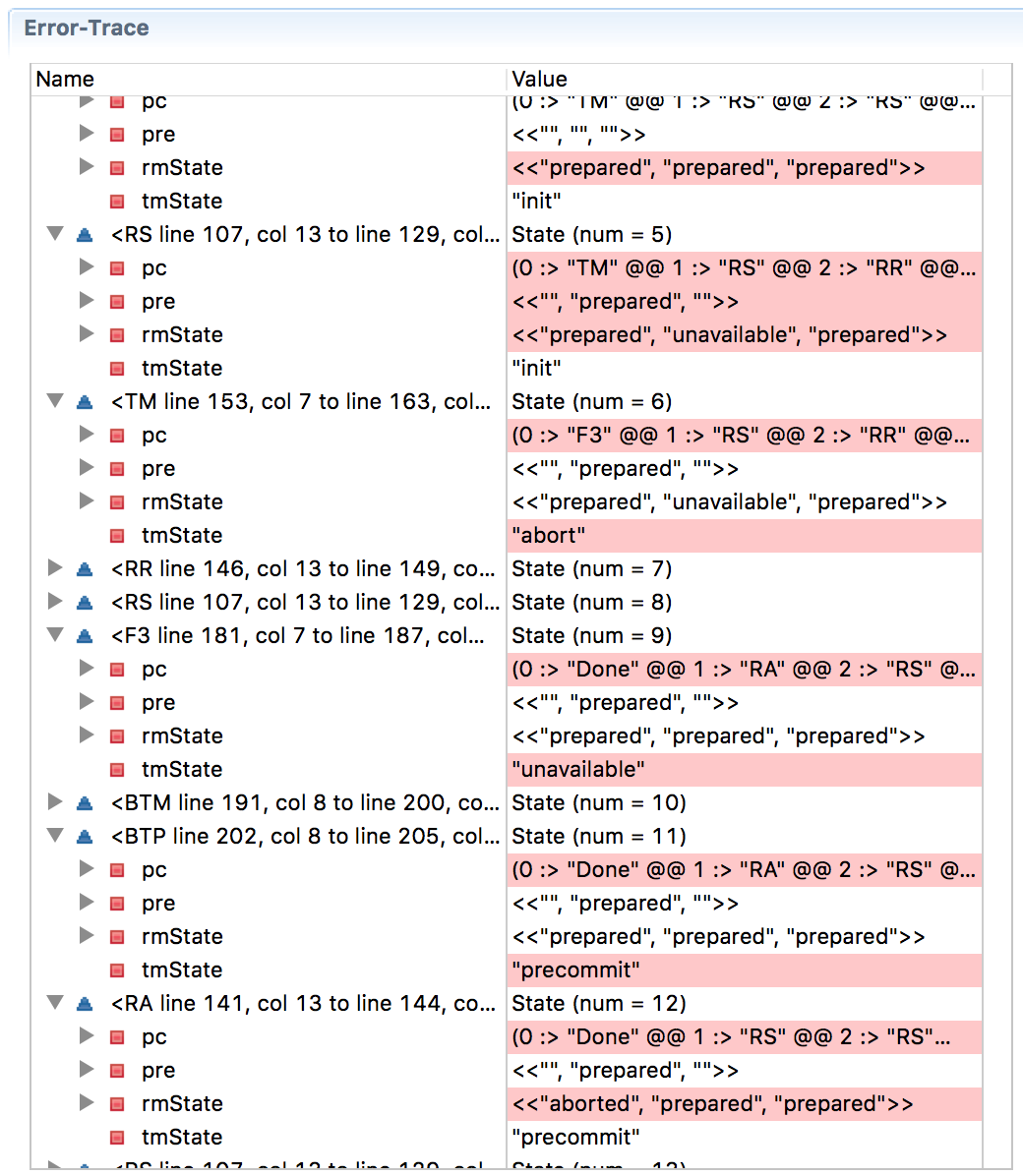
Aqui está uma confirmação trifásica modelada em TLA + (
versão em pdf ) e abaixo está um rastreio de erro que mostra que desta vez o progresso foi violado (na
página da Wikipedia sobre uma confirmação trifásica , uma situação é descrita quando o RM1 congela após receber uma decisão antes da confirmação e RM2 e RM3 confirmam confirmar, o que viola a consistência).
Paxos está tentando tornar o mundo um lugar melhor.

Mas nem tudo está perdido, a esperança não morreu.
Nós temos Paxos . Ele age ordenadamente dentro da estrutura do teorema da FLP. A inovação do Paxos é que ele é
sempre seguro (mesmo com detectores imprecisos, execução assíncrona e falhas) e,
finalmente, conclui a transação quando o consenso se torna possível.
Você pode emular a TM em um cluster com três nós Paxos, e isso resolverá o problema de inconsistência da TM / BTM. Ou, como Gray e Lampport mostraram em um
artigo científico sobre consenso na confirmação de transações , se o RM usar o contêiner Paxos para armazenar suas decisões simultaneamente com a resposta da TM, isso eliminará uma etapa extra no algoritmo de protocolo padrão.