Na Rostelecom, como em qualquer grande empresa, existe um data warehouse corporativo (WCD). Nosso WCD está em constante crescimento e expansão; nele construímos vitrines, relatórios e cubos de dados úteis. Em algum momento, fomos confrontados com o fato de que dados de baixa qualidade interferem conosco ao criar vitrines, as unidades resultantes não convergem para as unidades dos sistemas de origem e causam uma falta de entendimento dos negócios. Por exemplo, dados com valores nulos em chaves estrangeiras (chaves estrangeiras) não são conectados aos dados de outras tabelas.
Breve diagrama do WCD:
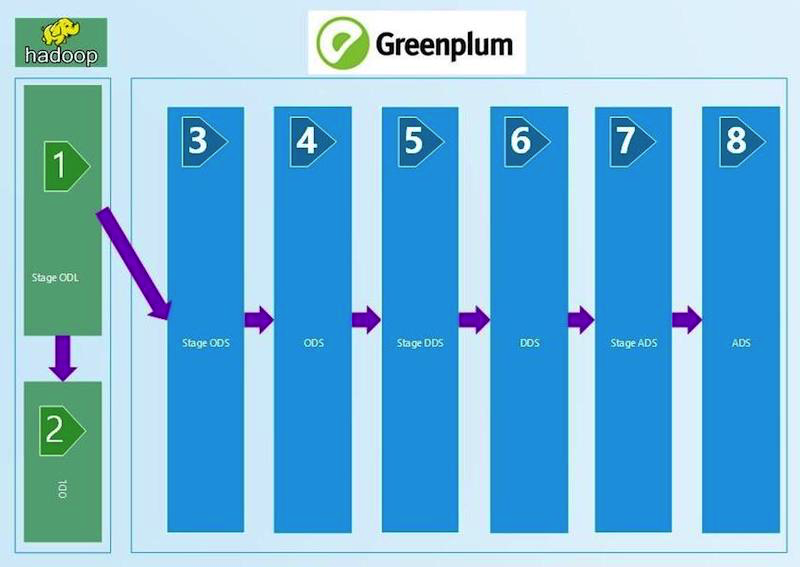
Entendemos que, para garantir a confiança na qualidade dos dados, precisávamos de um processo regular de reconciliação. Obviamente, automatizou e permitiu que cada um dos níveis tecnológicos garantisse a qualidade dos dados e sua convergência, tanto na vertical quanto na horizontal. Como resultado, analisamos simultaneamente três plataformas prontas para gerenciar reconciliações de vários fornecedores e criamos as nossas. Compartilhamos nossa experiência neste post.
Todos os inconvenientes das plataformas acabadas são conhecidos por todos: preço, flexibilidade limitada, falta de capacidade de adicionar e corrigir funcionalidades. As peças profissionais (dados em ouro, etc.), treinamento e suporte também estão fechados. Tendo apreciado isso, rapidamente esquecemos a compra e nos concentramos no desenvolvimento de nossa solução.
O núcleo do nosso sistema é escrito em Python, e o banco de dados de metadados para armazenar, registrar e armazenar resultados é escrito em Oracle. Existem muitas bibliotecas para Python, usamos o mínimo necessário para conexões Hive (pyhive), GreenPlum (pgdb), Oracle (cx_Oracle). Conectar um tipo diferente de fonte também não deve ser um problema.
O conjunto de dados resultante (conjunto de resultados) que colocamos na tabela Oracle resultante, avaliando o status da reconciliação (SUCCESS / ERROR). O APEX é configurado nas tabelas resultantes nas quais a visualização dos resultados é construída, conveniente para manutenção e gerenciamento.
Para executar verificações no Repositório, é usada a orquestra da Informatica, que baixa os dados. Após o recebimento do status de êxito do download, esses dados começam a ser verificados automaticamente. O uso de parametrização de consulta e metadados WCD permite o uso de modelos de reconciliação de consulta para conjuntos de tabelas.
Agora, sobre as reconciliações implementadas nesta plataforma.
Começamos com reconciliações técnicas, que comparam a quantidade de dados na entrada e nas camadas do WCD com a aplicação de certos filtros. Pegamos o arquivo ctl que veio para a entrada WCD, lemos o número de registros e o comparamos com a tabela no Stage ODL e / ou Stage ODS (1, 2, 3 no diagrama). O critério de verificação é definido na igualdade do número de registros (contagem). Se a quantidade convergir, o resultado será SUCESSO, sem erro e análise manual do erro.
Essa cadeia de reconciliações técnicas, comparada ao número de registros, se estende à camada ADS (8 no diagrama). Os filtros são alterados entre as camadas, que dependem do tipo de carregamento - DIM (livro de referência), HDIM (livro de referência histórico), FACT (tabelas de acumulação reais), etc. -, bem como da versão do SCD e da camada. Quanto mais próximos da camada de exibição, mais sofisticados são os algoritmos de filtragem que usamos.
Também foi realizada uma verificação técnica na entrada do Python, que detecta duplicatas nos campos-chave. No nosso GreenPlum, os campos-chave (PK) não são protegidos contra duplicatas pelas ferramentas do sistema de banco de dados. Por isso, escrevemos um script Python que lê os campos da tabela carregada a partir dos metadados PK e gera um script SQL que verifica se há duplicatas neles. A flexibilidade da abordagem nos permite usar a PK que consiste em um ou vários campos, o que é extremamente conveniente. Essa reconciliação se estende à camada STG ADS.
unique_check import sys import os from datetime import datetime log_tmstmp = datetime.now().strftime("%Y-%m-%d %H:%M:%S") def do_check(args, context): tab = args[0] data = [] fld_str = "" try: sql = """SELECT 't_'||lower(table_id) as tn, lower(column_name) as cn FROM src_column@meta_data WHERE table_id = '%s' and is_primary_key = 'Y'""" % (tab,) for fld in context['ora_get_data'](context['ora_con'], sql): fld_str = fld_str + (fld_str and ",") + fld[1] if fld_str: config = context['script_config'] con_gp = context['pg_open_con'](config['user'], config['pwd'], config['host'], config['port'], config['dbname']) sql = """select %s as pkg_id, 't_%s' as table_name, 'PK fields' as column_name, coalesce(sum(cnt), 0) as NOT_UNIQUE_PK, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS') as sys_creation from (select 1 as cnt from edw_%s.t_%s where %s group by %s having count(*) > 1 ) sq; """ % (context["package"] or '0',tab.lower(), args[1], tab.lower(), (context["package"] and ("package_id = " + context["package"]) or "1=1"), fld_str ) data.extend(context['pg_get_data'](con_gp, sql)) con_gp.close() except Exception as e: raise return data or [[(context["package"] or 0),'t_'+tab.lower(), None, 0, log_tmstmp]] if __name__ == '__main__': sys.exit(do_check([sys.argv[1], sys.argv[2]], {}))
Exemplo de código python de reconciliação de exclusividade. A chamada, a transferência dos parâmetros de conexão e a colocação dos resultados na tabela resultante são realizadas pelo módulo de controle em Python.A reconciliação pela ausência de valores NULL é construída de forma semelhante à anterior e também em Python. Lemos nos campos de metadados de carregamento que não podem ter valores vazios (NULL) e verificamos sua plenitude. A reconciliação é usada antes da camada DDS (6 no primeiro diagrama).
Na entrada do armazenamento, também é implementada uma análise de tendência dos pacotes de dados que chegam à entrada. A quantidade de dados recebidos quando um novo pacote chega é inserida na tabela de histórico. Com uma alteração significativa na quantidade de dados, a pessoa responsável pela tabela e o SI (sistema de origem) recebe uma notificação por email (nos planos), vê um erro no APEX antes do pacote de dados entrar no Warehouse e descobre o motivo disso com o SI.
Entre STG (STAGE) _ODS e ODS (camada de dados operacionais) (3 e 4 no diagrama), os campos de exclusão técnica são exibidos (indicador de exclusão = delete_ind), cuja correção também é verificada por meio de consultas SQL. A entrada ausente deve ser marcada como excluída no ODS.
O resultado do script de reconciliação é esperado para ver zero erros. No exemplo de reconciliação apresentado, os parâmetros ~ # PKG_ID # ~ são transmitidos pelo bloco de controle Python, e os parâmetros do tipo ~ P_JOIN_CONDITION ~ e ~ PERIOD_COL ~ são preenchidos a partir dos metadados da tabela, o próprio nome da tabela ~ TABLE ~ a partir dos parâmetros de inicialização.
A seguir, é apresentada uma reconciliação parametrizada. Exemplo de código de reconciliação SQL entre STG_ODS e ODS para o tipo HDIM:
select package_id as pkg_id, 'T_~TABLE~' as table_name, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS'), coalesce(empty_in_ods, 0) as empty_in_ods, coalesce(not_equal_md5, 0) as not_equal_md5, coalesce(deleted_in_ods, 0) as deleted_in_ods, coalesce(not_deleted_in_ods, 0) as not_deleted_in_ods, max_load_dttm from (select max (src.package_id) as package_id, sum (case when tgt.md5 is null then 1 else 0 end) as empty_in_ods, sum (case when src.md5<>tgt.md5 and tgt.~PK~ is not null and tgt.deleted_ind = 0 then 1 else 0 end) as not_equal_md5, sum (case when tgt.deleted_ind = 1 and src.md5=tgt.md5 then 1 else 0 end) as deleted_in_ods from EDW_STG_ODS.T_~TABLE~ src left join EDW_ODS.T_~TABLE~ tgt on ~P_JOIN_CONDITION~ and tgt.active_ind ='Y' where ~
Um exemplo de um código de reconciliação SQL entre STG_ODS e ODS para um tipo HDIM com parâmetros substituídos:
A partir do ODS, o histórico é mantido nos diretórios, portanto, deve ser verificado a ausência de interseções e lacunas. Isso é feito contando o número de valores incorretos no histórico e gravando o número resultante de erros na tabela resultante. Se houver erros de histórico na tabela, eles deverão ser pesquisados manualmente. A reconciliação depende do tipo de download - HDIM (guia de referência do histórico) em primeiro lugar. Realizamos reconciliações da correção do histórico para diretórios até a camada ADS.
Na camada DDS (6 no primeiro diagrama), diferentes SIs (sistemas de origem) são combinados em uma tabela; as tabelas HUB para gerar chaves substitutas para vincular dados de diferentes sistemas de origem são exibidas. Verificamos a existência de exclusividade com uma verificação de python semelhante à camada de estágio.
Na camada DDS, é necessário verificar se, após combinar com a tabela HUB, os valores dos tipos 0, -1, -2 não apareceram nos campos-chave, o que significa junção incorreta da tabela, falta de dados. Eles podem aparecer na ausência dos dados necessários na tabela HUB. E este é um erro para a análise manual.
As reconciliações mais complexas para os dados da camada de exibição do ADS (8 no primeiro diagrama). Para total confiança na convergência do resultado obtido, a verificação com um sistema de origem para agregação do valor das cobranças é implementada aqui. Por um lado, há uma classe de indicadores que incluem accruals agregados. Nós as coletamos por um mês nas janelas do WCD. Por outro lado, coletamos as mesmas cobranças do sistema de origem. É permitida uma discrepância não superior a 1% ou um valor absoluto determinado e acordado. Os conjuntos de resultados obtidos pela reconciliação são colocados em conjuntos de dados criados especialmente que recebem tabelas Oracle. A comparação de dados é feita na visualização Oracle. Visualização dos resultados no APEX. A presença de todo um conjunto de dados (conjunto de resultados) nos permite, se houver erros, aprofundar e analisar os dados detalhados do resultado, encontrar um artigo específico sobre o qual ocorreu a discrepância e procurar seus motivos.
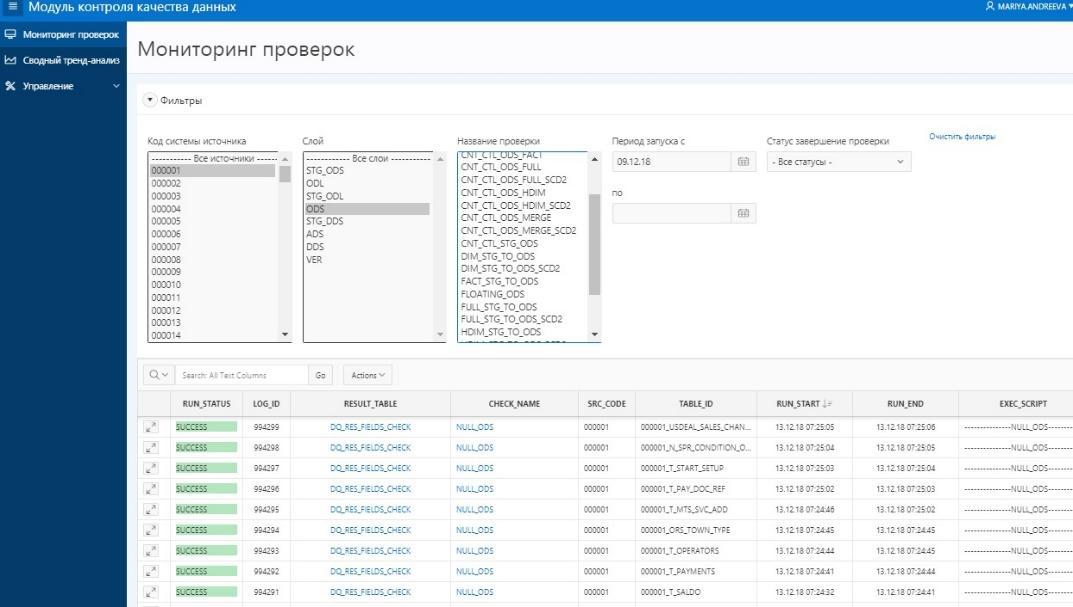 Apresentação dos resultados da reconciliação para usuários no APEX
Apresentação dos resultados da reconciliação para usuários no APEXNo momento, obtivemos um aplicativo viável e usado ativamente para reconciliar dados. Obviamente, temos planos de desenvolver ainda mais a quantidade e a qualidade das reconciliações e o desenvolvimento da própria plataforma. O próprio desenvolvimento nos permite alterar e modificar a funcionalidade com rapidez suficiente.
Este artigo foi preparado pela equipe de gerenciamento de dados Rostelecom