No início de dezembro, Montreal sediou a 32ª conferência anual de
Sistemas de processamento de informações neurais sobre aprendizado de máquina. De acordo com uma tabela de classificação não oficial, esta conferência é o evento top 1 deste formato no mundo. Todos os ingressos para a conferência deste ano foram esgotados em um recorde de 13 minutos. Temos uma grande equipe de cientistas de dados do MTS, mas apenas um deles - Marina Yaroslavtseva (
magoli ) - teve a sorte de chegar a Montreal. Juntamente com Danila Savenkov (
danila_savenkov ), que ficou sem visto e acompanhou a conferência de Moscou, falaremos sobre os trabalhos que nos pareciam mais interessantes. Esta amostra é muito subjetiva, mas espero que lhe interesse.
 Redes neurais recorrentes relacionaisResumoCódigo
Redes neurais recorrentes relacionaisResumoCódigoAo trabalhar com sequências, geralmente é muito importante como os elementos da sequência se relacionam. A arquitetura padrão de redes de recorrência (GRU, LSTM) dificilmente pode modelar o relacionamento entre dois elementos que são bastante remotos um do outro. Até certo ponto, a atenção ajuda a lidar com isso (
https://youtu.be/SysgYptB198 ,
https://youtu.be/quoGRI-1l0A ), mas ainda assim não está certo. Atenção permite determinar o peso com o qual o estado oculto de cada uma das etapas da sequência afetará o estado oculto final e, consequentemente, a previsão. Estamos interessados na relação dos elementos da sequência.
No ano passado, novamente no NIPS, o Google sugeriu abandonar completamente a recorrência e usar
a atenção pessoal . A abordagem mostrou-se muito boa, embora principalmente em tarefas seq2seq (o artigo fornece resultados sobre tradução automática).
O artigo deste ano usa a ideia de atenção própria como parte do LSTM. Não há muitas mudanças:
- Alteramos o vetor de estado celular para a matriz "memória" M. Até certo ponto, a matriz de memória é composta por muitos vetores de estado celular (muitas células de memória). Obtendo um novo elemento da sequência, determinamos o quanto esse elemento deve atualizar cada uma das células da memória.
- Para cada elemento da sequência, atualizaremos essa matriz usando a atenção ao produto com vários pontos de cabeça (MHDPA, você pode ler sobre esse método no artigo mencionado no google). O resultado do MHPDA para o elemento atual da sequência e da matriz M é executado através de uma malha totalmente conectada, o sigmóide e a matriz M são atualizados da mesma maneira que o estado da célula no LSTM
Argumenta-se que é devido ao MHDPA que a rede pode levar em consideração a interconexão dos elementos de sequência, mesmo quando eles são removidos um do outro.
Como um problema de brinquedo, o modelo é solicitado na sequência de vetores para encontrar o vetor enésimo por distância do enésimo em termos de distância euclidiana. Por exemplo, há uma sequência de 10 vetores e pedimos que você encontre um que esteja em terceiro lugar, próximo ao quinto. É claro que, para responder a essa pergunta do modelo, é necessário avaliar de alguma forma as distâncias de todos os vetores ao quinto e classificá-los. Aqui, o modelo proposto pelos autores derrota com confiança LSTM e
DNC . Além disso, os autores comparam seu modelo com outras arquiteturas em Learning to Execute (aprendemos a executar algumas linhas de código, fornecemos o resultado), Mini-Pacman, Language Modeling e em todos os lugares relatamos os melhores resultados.
Imputação multivariada de séries temporais com redes adversas generativasResumoCódigo (embora eles não estejam vinculados aqui no artigo)
Em séries temporais multidimensionais, como regra, há um grande número de omissões, o que impede o uso de métodos estatísticos avançados. Soluções padrão - preenchendo com média / zero, excluindo casos incompletos, restaurando dados com base em expansões de matriz nessa situação, geralmente não funcionam, porque não podem reproduzir dependências de tempo e a distribuição complexa de séries temporais multidimensionais.
A capacidade das redes contraditórias generativas (GANs) de imitar qualquer distribuição de dados, em particular nas tarefas de "desenhar" faces e gerar sentenças, é amplamente conhecida. Mas, como regra, esses modelos requerem treinamento inicial em um conjunto de dados completo, sem lacunas, ou não levam em consideração a natureza consistente dos dados.
Os autores propõem complementar o GAN com um novo elemento - a Unidade Recorrente Fechada de Imputação (GRUI). A principal diferença do GRU usual é que o GRUI pode aprender com dados em intervalos de diferentes comprimentos entre as observações e ajustar o efeito das observações, dependendo da distância no tempo a partir do ponto atual. Um parâmetro de atenuação especial β é calculado, cujo valor varia de 0 a 1 e quanto menor, maior o intervalo de tempo entre a observação atual e a anterior não vazia.


O discriminador e o gerador GAN consistem em uma camada GRUI e uma camada totalmente conectada. Como de costume nos GANs, o gerador aprende a simular os dados de origem (nesse caso, basta preencher as lacunas nas linhas), e o discriminador aprende a distinguir as linhas preenchidas com o gerador das reais.
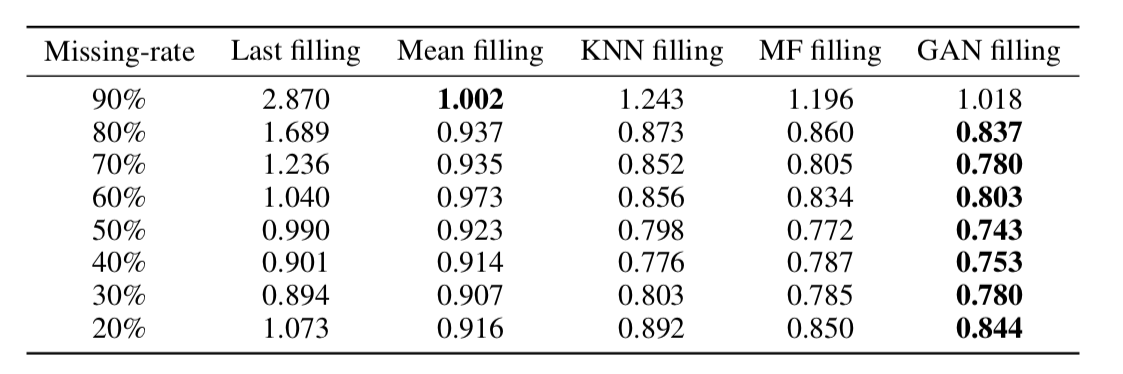
Como se viu, essa abordagem restaura os dados de maneira muito adequada, mesmo em séries temporais, com uma parcela muito grande de omissões (na tabela abaixo - recuperação de dados MSE no conjunto de dados KDD, dependendo da porcentagem de omissões e método de recuperação. Na maioria dos casos, o método baseado em GAN oferece a maior precisão recuperação).
 Sobre a dimensionalidade da incorporação de palavrasResumoCódigo
Sobre a dimensionalidade da incorporação de palavrasResumoCódigoA incorporação de palavras / representação vetorial de palavras é uma abordagem amplamente usada para várias aplicações da PNL: de sistemas de recomendação à análise da coloração emocional de textos e tradução automática.
Além disso, a questão de como definir otimamente um hiperparâmetro tão importante quanto a dimensão dos vetores permanece em aberto. Na prática, na maioria das vezes é selecionado por pesquisa empírica exaustiva ou definido por padrão, por exemplo, no nível 300. Ao mesmo tempo, uma dimensão muito pequena não permite refletir todas as relações significativas entre as palavras e muito grande pode levar à reciclagem.
Os autores do estudo propõem sua solução para esse problema, minimizando o parâmetro de perda de PIP, uma nova medida da diferença entre as duas opções de incorporação.
O cálculo é baseado em matrizes PIP que contêm os produtos escalares de todos os pares de representações vetoriais de palavras no corpus. A perda de PIP é calculada como a norma Frobenius entre as matrizes PIP de duas incorporações: treinadas em dados (incorporação treinada E_hat) e ideal, treinadas em dados ruidosos (incorporação de oráculo E).
Parece simples: você precisa escolher uma dimensão que minimize a perda de PIP, o único momento incompreensível é onde obter a incorporação do oráculo. Em 2015-2017, foram publicados vários trabalhos nos quais foi demonstrado que vários métodos para a construção de incorporamentos (word2vec, GloVe, LSA) fatoram implicitamente (diminuem a dimensão) a matriz de sinais do caso. No caso do word2vec (skip-gram), a matriz do sinal é
PMI , no caso do GloVe, é a matriz de contagens de log. É proposto pegar um dicionário de tamanho não muito grande, construir uma matriz de sinal e usar SVD para obter a incorporação do oráculo. Assim, a dimensão de incorporação do oráculo é igual à classificação da matriz de sinal (na prática, para um dicionário de 10k palavras, a dimensão será da ordem de 2k). Entretanto, nossa matriz empírica de sinais é sempre barulhenta e temos que recorrer a esquemas complicados para obter a incorporação do oráculo e estimar a perda de PIP por uma matriz barulhenta.
Os autores argumentam que, para selecionar a dimensão de incorporação ideal, basta usar um dicionário de 10 mil palavras, o que não é muito e permite executar esse procedimento em um período de tempo razoável.
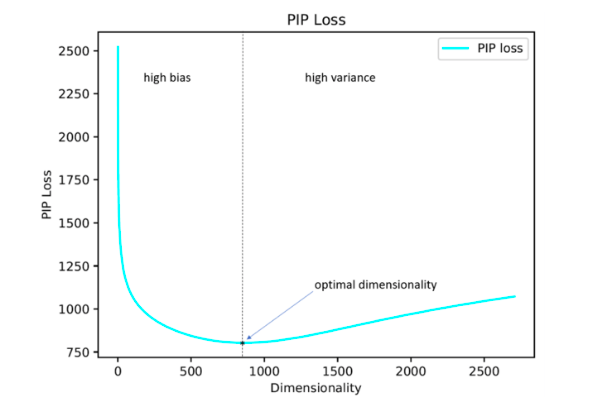
Como se viu, a dimensão de incorporação calculada dessa maneira na maioria dos casos com um erro de até 5% coincide com a dimensão ideal determinada com base em estimativas de especialistas. Aconteceu (esperado) que o Word2Vec e o GloVe praticamente não foram treinados novamente (a perda de PIP não cai em dimensões muito grandes), mas o LSA é treinado com muita força.
Usando o código publicado no github pelos autores, é possível procurar a dimensão ideal do Word2Vec (skip-gram), GloVe, LSA.
FRAGE: Representação Agnóstica de Palavras com FrequênciaResumoCódigoOs autores falam sobre como os casamentos funcionam de maneira diferente para palavras raras e populares. Por popular, quero dizer não parar palavras (não as consideramos), mas palavras informativas que não são muito raras.
As observações são as seguintes:
Se falamos de palavras populares, sua proximidade na medida do cosseno reflete muito bem
- sua afinidade semântica. Para palavras raras, isso não é verdade (o que é esperado) e (o que é menos esperado) o topo das palavras de cosseno mais próximas de uma palavra rara também são raras e, ao mesmo tempo, semanticamente sem relação. Ou seja, palavras raras e frequentes no espaço dos casamentos vivem em lugares diferentes (em cones diferentes, se estamos falando de cosseno)
- Durante o treinamento, os vetores de palavras populares são atualizados com muito mais frequência e, em média, ficam duas vezes mais longe da inicialização do que os vetores de palavras raras. Isso leva ao fato de que a incorporação de palavras raras é, em média, mais próxima da origem. Para ser sincero, sempre acreditei que, pelo contrário, palavras raras são geralmente mais longas e não sei como me relacionar com a afirmação dos autores =)
Qualquer que seja a relação entre as normas L2 dos casamentos, a separabilidade de palavras populares e raras não é um fenômeno muito bom. Queremos que os casamentos reflitam a semântica de uma palavra, não sua frequência.
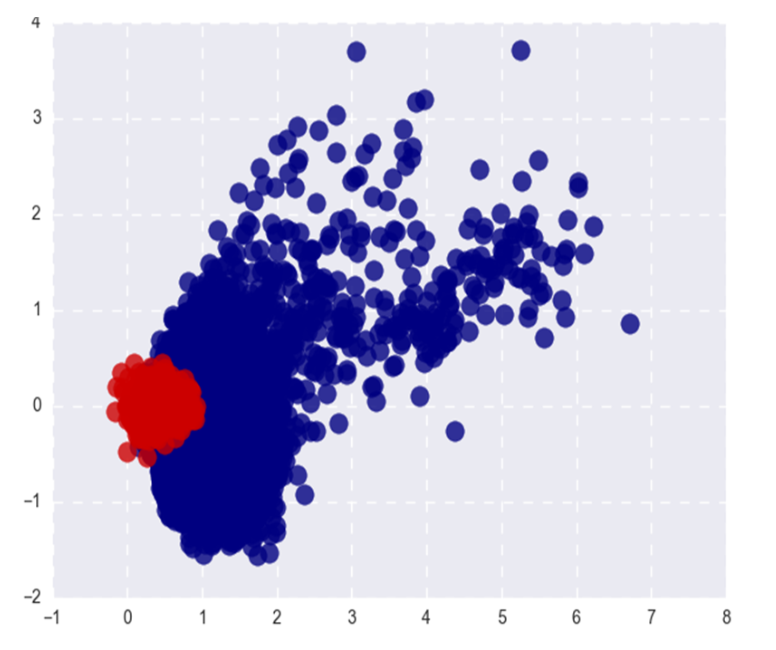
A imagem mostra as palavras populares (vermelhas) e raras (azuis) do Word2Vec após SVD. Popular aqui refere-se aos 20% principais de palavras em frequência.
Se o problema estivesse apenas nas normas L2 de casamentos, poderíamos normalizá-las e viver felizes, mas, como eu disse no primeiro parágrafo, palavras raras também são separadas das populares pela proximidade do cosseno (em coordenadas polares).
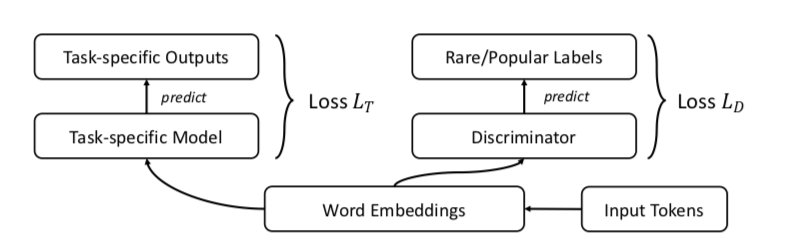
Os autores sugerem, é claro, GAN. Vamos fazer o mesmo que antes, mas adicione um discriminador que tentará distinguir entre palavras populares e raras (novamente, consideramos popular o% n das palavras na frequência).
Parece algo como isto:
Os autores testam a abordagem nas tarefas de similaridade de palavras, tradução automática, classificação de texto e modelagem de idiomas e em todos os lugares com desempenho superior à linha de base. Na semelhança de palavras, afirma-se que a qualidade cresce especialmente de maneira notável em palavras raras.
Um exemplo: cidadania. Questões de pular grama: felicidade, pakistans, demitir, reforçar. Questões de FRAGE: população, status, dignidade, bürger. As palavras cidadão e cidadãos em FRAGE estão em 79º e 7º lugares, respectivamente (na proximidade da cidadania); em pular grama, eles não estão entre os 10000 melhores.
Por alguma razão, os autores postaram o código apenas para tradução automática e modelagem de linguagem, similaridade de palavras e tarefas de classificação de texto no repositório, infelizmente, não são representadas.
Alinhamento não modal supervisionado dos espaços de incorporação de fala e textoResumoCódigo: sem código, mas eu gostaria
Estudos recentes mostraram que dois espaços vetoriais treinados usando algoritmos de incorporação (por exemplo, word2vec) em corpos de texto em dois idiomas diferentes podem ser comparados entre si sem marcação e correspondência de conteúdo entre os dois edifícios. Em particular, essa abordagem é usada para tradução automática no Facebook. Uma das principais propriedades dos espaços de incorporação é usada: dentro deles, palavras semelhantes devem estar geometricamente próximas e palavras diferentes, pelo contrário, devem estar longe uma da outra. Supõe-se que, em geral, a estrutura do espaço vetorial seja preservada, independentemente do idioma em que o corpus se destinava ao ensino.
Os autores do artigo foram além e aplicaram uma abordagem semelhante ao campo do reconhecimento e tradução automáticos de fala. Propõe-se treinar o espaço vetorial separadamente para o corpus de texto no idioma de interesse (por exemplo, Wikipedia), separadamente para o corpus de fala gravada (em formato de áudio), possivelmente em outro idioma, previamente dividido em palavras, e depois comparar esses dois espaços da mesma maneira que em dois casos de texto.
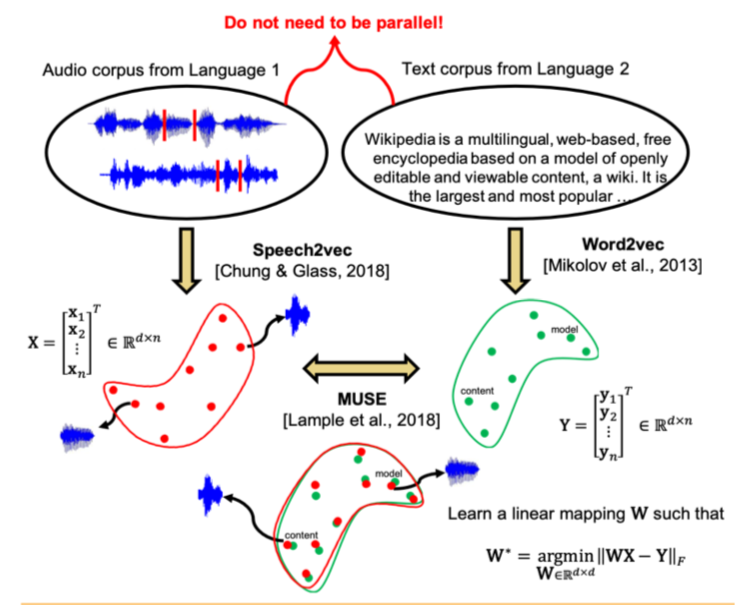
Para o corpus de texto, o word2vec é usado e, para a fala, uma abordagem semelhante, chamada por Speech2vec, é baseada no LSTM e nas metodologias usadas para o word2vec (CBOW / skip-gram), portanto, pressupõe-se que ele combine palavras precisamente por características contextuais e semânticas, e não está soando.
Depois que os dois espaços vetoriais são treinados e há dois conjuntos de incorporações - S (no corpo da fala), consistindo em n incorporações da dimensão d1 e T (no corpo do texto), consistindo em m incorporações da dimensão d2, é necessário compará-las. Idealmente, temos um dicionário que determina qual vetor de S corresponde a qual vetor de T. Em seguida, duas matrizes são formadas para comparação: k combinações são selecionadas de S, que formam uma matriz X do tamanho d1 xk; a partir de T, k também são selecionados casamentos correspondentes (de acordo com o dicionário) previamente selecionados de S, e é obtida uma matriz Y de tamanho d2 x k. Em seguida, você precisa encontrar um mapeamento linear W de modo que:
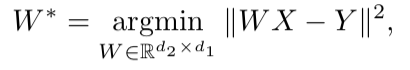
Porém, como o artigo considera a abordagem não supervisionada, inicialmente não há dicionário; portanto, é proposto um procedimento para gerar um dicionário sintético, composto de duas partes. Primeiro, obtemos a primeira aproximação de W usando treinamento de domínio-adversário (um modelo competitivo como GAN, mas em vez do gerador - um mapeamento linear de W, com o qual tentamos tornar S e T indistinguíveis um do outro, e o discriminador tenta determinar a origem real da incorporação). Em seguida, com base nas palavras cujas incorporações mostraram a melhor correspondência entre si e são mais frequentemente encontradas nos dois edifícios, um dicionário é formado. Depois disso, ocorre o refinamento de W de acordo com a fórmula acima.
Essa abordagem fornece resultados comparáveis ao aprendizado dos dados rotulados, o que pode ser muito útil na tarefa de reconhecer e traduzir a fala de idiomas raros para os quais há muito poucos casos paralelos de texto de fala ou estão ausentes.
Detecção de anomalias profundas usando transformações geométricasResumoCódigoUma abordagem bastante incomum na detecção de anomalias, que, segundo os autores, derrota bastante outras abordagens.
A idéia é a seguinte: vamos apresentar K diferentes transformações geométricas (uma combinação de turnos, rotação de 90 graus e reflexão) e aplicá-las a cada imagem do conjunto de dados original. A imagem obtida como resultado da i-ésima transformação agora pertencerá à classe i, ou seja, haverá K classes no total, cada uma delas será representada pelo número de imagens originalmente no conjunto de dados. Agora, ensinaremos uma classificação multiclasse sobre essa marcação (os autores escolheram ampla resnet).
Agora podemos obter vetores K y (Ti (x)) da dimensão K para uma nova imagem, onde Ti é a i-ésima transformação, x é a imagem, y é a saída do modelo. A definição básica de "normalidade" é a seguinte:
Aqui, para a imagem x, adicionamos as probabilidades previstas das classes corretas para todas as transformações. Quanto maior a "normalidade", maior a probabilidade de a imagem ser tirada da mesma distribuição que a amostra de treinamento. Os autores afirmam que isso já funciona muito bem, mas, no entanto, oferecem uma maneira mais complexa que funciona ainda um pouco melhor. Assumiremos que o vetor y (Ti (x)) para cada transformação de Ti é
Dirichlet distribuído e tomaremos o logaritmo de probabilidade como uma medida da “normalidade” da imagem. Os parâmetros de distribuição do Dirichlet são estimados em um conjunto de treinamento.
Os autores relatam o incrível aumento de desempenho em comparação com outras abordagens.
Uma estrutura unificada simples para detectar amostras fora de distribuição e ataques adversosResumoCódigoA identificação na amostra para a aplicação do modelo de casos significativamente diferente da distribuição da amostra de treinamento é um dos principais requisitos para a obtenção de resultados confiáveis de classificação. Ao mesmo tempo, as redes neurais são conhecidas por seu recurso com um alto grau de confiança (e incorretamente) para classificar objetos que não foram encontrados no treinamento ou intencionalmente corrompidos (exemplos adversários).
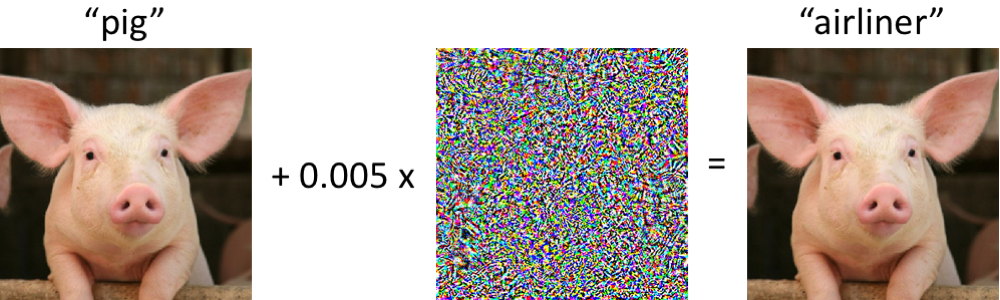
Os autores do artigo oferecem um novo método para identificar esses e outros casos "ruins". A abordagem é implementada da seguinte forma: primeiro, uma rede neural com a saída softmax usual é treinada, depois a saída de sua penúltima camada é obtida e o classificador generativo é treinado nela. Seja x - que é alimentado na entrada do modelo para um objeto de classificação específico, y - o rótulo da classe correspondente, suponha que tenhamos um classificador softmax pré-treinado no formato:
Onde wc e bc são os pesos e constantes da camada softmax para as classes cef (.) É a saída do penúltimo DNN da soja.
Além disso, sem nenhuma alteração no classificador pré-treinado, é feita uma transição para o classificador generativo, a saber, análise discriminante. Supõe-se que os recursos extraídos da penúltima camada do classificador softmax tenham uma distribuição normal multidimensional, cada componente correspondente a uma classe. Então a distribuição condicional pode ser especificada através do vetor de médias da distribuição multidimensional e sua matriz de covariância:
Para avaliar os parâmetros do classificador generativo, as médias empíricas são calculadas para cada classe, bem como a covariância dos casos da amostra de treinamento {(x1, y1), ..., (xN, yN)}:
onde N é o número de casos da classe correspondente no conjunto de treinamento. Então, uma medida de confiabilidade é calculada na amostra de teste - a distância de Mahalanobis entre o caso de teste e a distribuição de classe normal mais próxima desse caso.
Como se viu, essa métrica funciona de maneira muito mais confiável em objetos atípicos ou danificados, sem fornecer estimativas elevadas, como a camada softmax. Na maioria das comparações de dados diferentes, o método proposto mostrou resultados que excederam o estado da arte atual ao encontrar os dois casos que não estavam no treinamento e estragaram intencionalmente.
Além disso, os autores consideram outra aplicação interessante de sua metodologia: use o classificador generativo para destacar novas classes no teste que não estava em treinamento e atualize os parâmetros do próprio classificador para que possa determinar essa nova classe no futuro.
Exemplos Adversários que Enganam a Visão por Computador e os Humanos por Tempo LimitadoResumo:
https://arxiv.org/abs/1802.08195adversarial examples . , . adversarial example . , , , , , , , adversarial attacks.

adversarial examples. adversarial examples , ( , ).
, adversarial example, . , , 63 . accuracy 10% , adversarial. , adversarial , . , perturbation perturbation , accuracy .
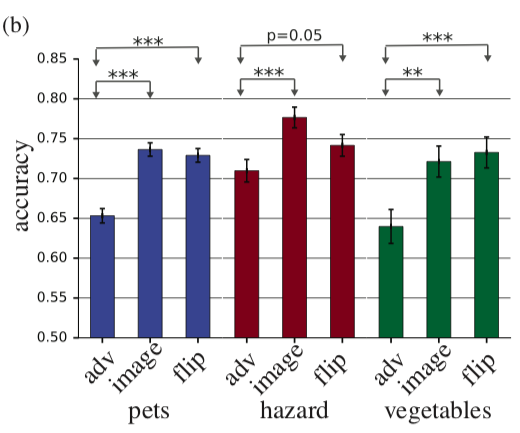
adv — adversarial example, image — , flip — + adversarial perturbation, .
Sanity Checks for Saliency MapsAbstract— . deep learning, saliency maps. Saliency maps . saliency map, , “”.

: “ saliency maps?” , :
- Saliency map
- Saliency map ,
, : cascading randomization ( , , saliency map) independent randomization ( ). : , saliency maps.
saliency map , , saliency maps. : “To our surprise, some widely deployed saliency methods are independent of both the data the model was trained on, and the model parameters”, — . , , saliency maps, , cascading randomization:
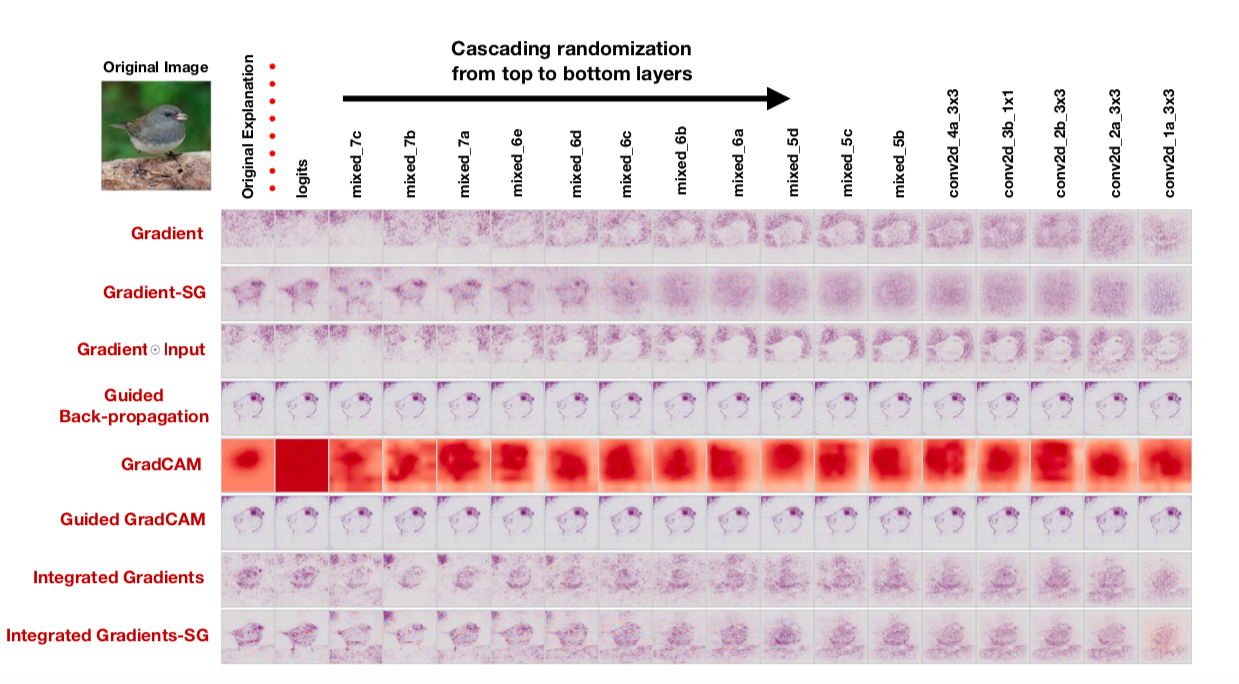
, . , saliency maps .
, — saliency maps , , confirmation bias. , .
An intriguing failing of convolutional neural networks and the CoordConv solutionAbstract:
https://arxiv.org/abs/1807.03247: , 10 .
Uber. , , , . , :
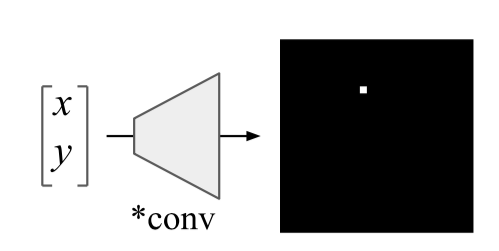
: ( CoodrConv ) i j, :
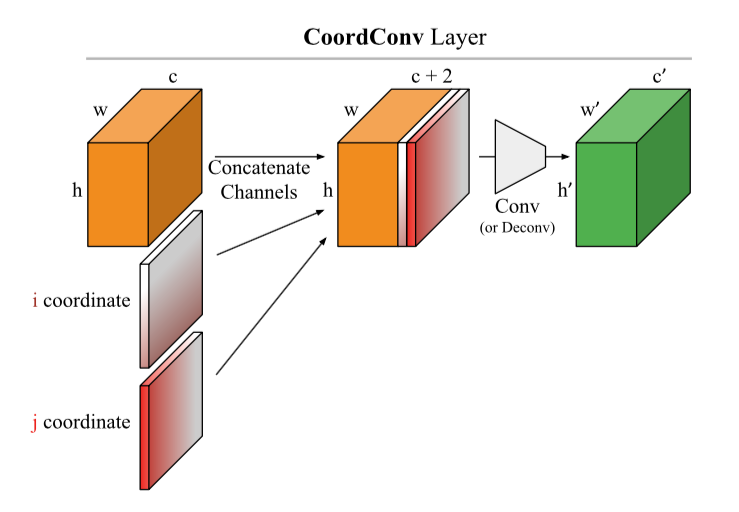
, :
- ImageNet'. , , , ,
- CoordConv object detection. MNIST, Faster R-CNN, IoU 21%
- CoordConv GAN .
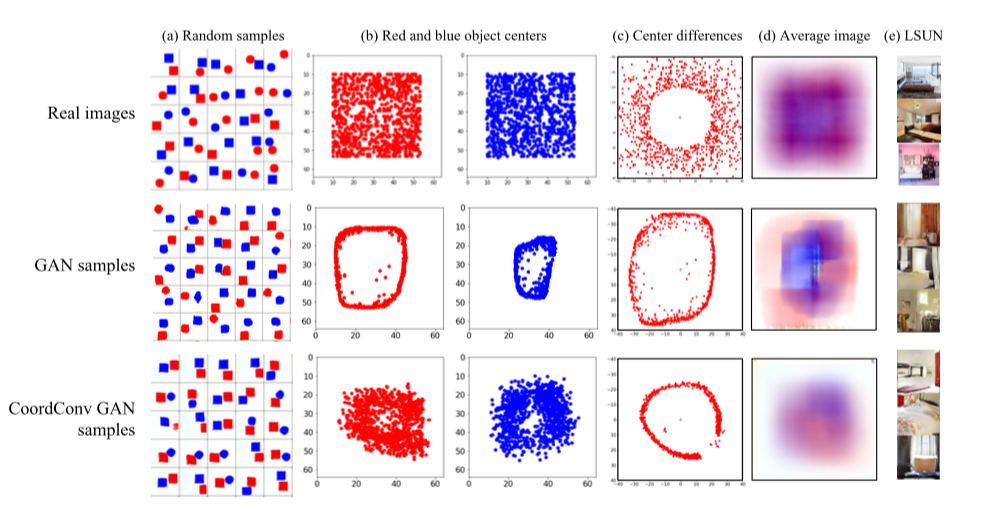
GAN' : LSUN. , — c. , GAN' , , . CoordConv , . LSUN d , , CoordConv GAN,
- 4. CoordConv A2C ( ) .
, , . CoordConv
U-net :
https://arxiv.org/abs/1812.01429, https://www.kaggle.com/c/tgs-salt-identification-challenge/discussion/69274 ,
https://github.com/mjDelta/Kaggle-RSNA-Pneumonia-Detection-Challenge .
.
Regularizing by the Variance of the Activations' Sample-VariancesAbstractbatch normalization. - . : S1 S2 :
onde σ2 são variações da amostra em S1 e S2, respectivamente, β é o coeficiente positivo treinado. Os autores chamam isso de perda de constância de variação (VCL) e a adicionam à perda total.
Na seção sobre experimentos, os autores reclamam de como os resultados dos artigos de outras pessoas não são reproduzidos e se comprometem a definir um código reproduzível (apresentado). Primeiro, eles experimentaram uma pequena malha de 11 camadas no conjunto de dados de imagens pequenas (CIFAR-10 e CIFAR-100). Concluímos que a VCL está provando, se você usar Leaky ReLU ou ELU como ativações, mas a normalização em lote funcionará melhor com ReLU. Em seguida, aumentam o número de camadas em 2 vezes e passam para o Tiny Imagenet - uma versão simplificada do Imagenet com 200 classes e uma resolução de 64x64. Na validação, o VCL supera a normalização de lote na grade com ELU, assim como ResNet-110 e DenseNet-40, mas supera Wide-ResNet-32. Um ponto interessante é que os melhores resultados são obtidos quando os subconjuntos S1 e S2 consistem em duas amostras.
Além disso, os autores testam o VCL em redes feed-forward e o VCL ganha um pouco mais frequentemente do que uma rede com normalização em lote ou sem regularização.
DropMax: Softmax variacional adaptávelResumoCódigoÉ proposto no problema de classificação em várias classes a cada iteração da descida do gradiente para cada amostra eliminar aleatoriamente algum número de classes incorretas. Além disso, a probabilidade com a qual abandonamos uma ou outra classe para um ou outro objeto também está sendo treinada. Como resultado, a rede “se concentra” em distinguir as classes mais difíceis de separar.
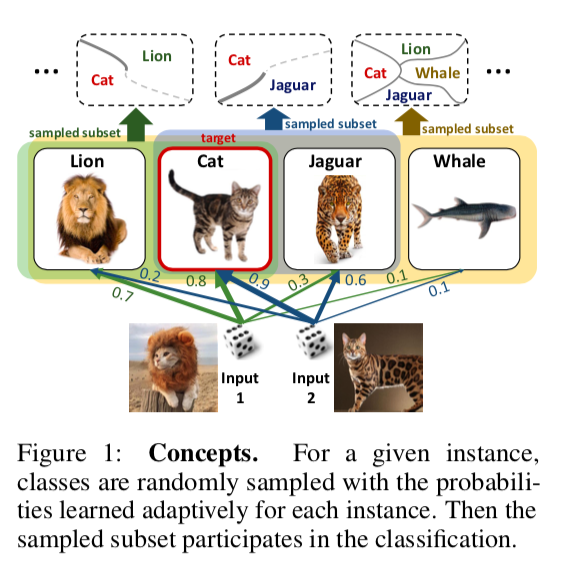
Experimentos nos subconjuntos MNIST, CIFAR e Imagenet mostram que o DropMax tem um desempenho melhor que o SoftMax padrão e algumas de suas modificações.
Modelos inteligentes precisos com interações em pares(Amigos não deixam amigos implantar modelos de caixa preta: a importância da inteligibilidade no aprendizado de máquina)
Resumo:
http://www.cs.cornell.edu/~yinlou/papers/lou-kdd13.pdfCódigo: não está lá. Estou muito interessado em saber como os autores atribuem um nome tão imperativo à falta de código. Acadêmicos, senhor =)
Você pode olhar para este pacote, por exemplo:
https://github.com/dswah/pyGAM . As interações entre os recursos foram adicionadas há pouco tempo (o que realmente distingue o GAM do GA2M).
Este artigo foi apresentado no âmbito do workshop “Interpretabilidade e robustez em áudio, fala e linguagem”, embora seja dedicado à interpretabilidade dos modelos em geral, e não ao campo da análise de som e fala. Provavelmente, todos foram confrontados, em certa medida, com o dilema de escolher entre a interpretabilidade do modelo e sua precisão. Se usarmos a regressão linear usual, podemos entender pelos coeficientes como cada variável independente afeta o dependente. Se usarmos modelos de "caixa preta", por exemplo, aumento de gradiente sem restrições de complexidade ou redes neurais profundas, um modelo ajustado corretamente em dados adequados será muito preciso, mas rastrear e explicar todos os padrões que o modelo encontrado nos dados será problemático. Portanto, será difícil explicar o modelo ao cliente e rastrear se ele aprendeu algo que não gostaríamos. A tabela abaixo fornece estimativas da interpretabilidade e precisão relativas de vários tipos de modelos.

Um exemplo de situação em que a baixa interpretabilidade do modelo está associada a grandes riscos: em um dos conjuntos de dados médicos, foi resolvido o problema de prever a probabilidade de o paciente morrer de pneumonia. O seguinte padrão interessante foi encontrado nos dados: se uma pessoa tem asma brônquica, a probabilidade de morrer de pneumonia é menor do que nas pessoas sem essa doença. Quando os pesquisadores se voltaram para a prática de médicos, descobriu-se que esse padrão realmente existe, pois as pessoas com asma no caso de pneumonia recebem a ajuda mais imediata e medicamentos fortes. Se treinássemos o xgboost nesse conjunto de dados, provavelmente ele teria capturado esse padrão, e nosso modelo classificaria os pacientes com asma como um grupo de baixo risco e, consequentemente, recomendaria uma prioridade e intensidade de tratamento mais baixas para eles.
Os autores do artigo oferecem uma alternativa que é interpretável e precisa ao mesmo tempo - este é o GA2M, uma subespécie de modelos aditivos generalizados.
O GAM clássico pode ser considerado como uma generalização adicional do GLM: um modelo é uma soma, cujo termo reflete a influência de apenas uma variável independente no dependente, mas a influência é expressa não por um coeficiente de peso, como no GLM, mas por uma função não paramétrica suave (como regra definida em partes) funções - estrias ou árvores de pequena profundidade, incluindo "tocos"). Devido a esse recurso, os GAMs podem modelar relacionamentos mais complexos do que um modelo linear simples. Por outro lado, as dependências aprendidas (funções) podem ser visualizadas e interpretadas.
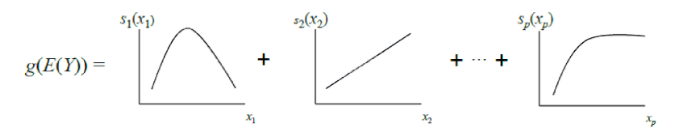
No entanto, os GAMs padrão ainda frequentemente não atingem a precisão dos algoritmos de caixa preta. Para corrigir isso, os autores do artigo oferecem um compromisso - para adicionar à equação do modelo, além das funções de uma variável, um pequeno número de funções de duas variáveis - pares cuidadosamente selecionados cuja interação é significativa para prever a variável dependente. Assim, o GA2M é obtido.
Primeiro, um GAM padrão é criado (sem levar em consideração a interação das variáveis) e, em seguida, pares de variáveis são adicionados passo a passo (o GAM restante é usado como variável de destino). Para o caso em que há muitas variáveis e a atualização do modelo após cada etapa é computacionalmente difícil, é proposto um algoritmo de classificação FAST, com o qual você pode pré-selecionar pares potencialmente úteis e evitar enumeração completa.
Essa abordagem permite obter qualidade próxima a modelos de complexidade ilimitada. A tabela mostra a taxa de erro dos modelos de aditivos generalizados em comparação com uma floresta aleatória para resolver o problema de classificação em diferentes conjuntos de dados e, na maioria dos casos, a qualidade da previsão para o GA2M com o FAST e para florestas aleatórias não é significativamente diferente.
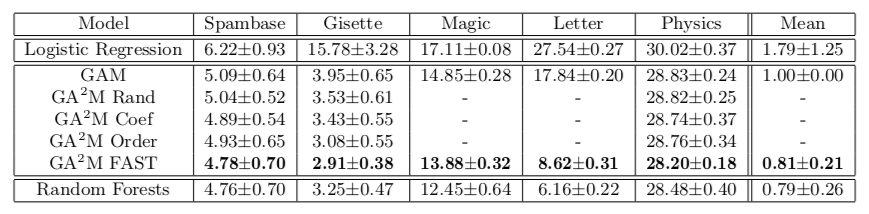
Gostaria de chamar a atenção para as características do trabalho dos acadêmicos que se oferecem para enviar esses aprimoramentos e leituras profundas ao forno. Observe que os conjuntos de dados nos quais os resultados são apresentados não contêm mais de 20 mil objetos (todos os conjuntos de dados do repositório UCI). Surge uma pergunta natural: não há realmente nenhum conjunto de dados aberto de tamanho normal para tais experimentos em 2018? Você pode ir além e comparar em um conjunto de dados de 50 objetos - existe a chance de o modelo constante não diferir significativamente de uma floresta aleatória.
O próximo ponto é a regularização. Em um grande número de sinais, é muito fácil treinar mesmo sem interações. Os autores podem acreditar que esse problema não existe, e o único problema é o modelo de caixa preta. Pelo menos no artigo, a regularização não é mencionada em nenhum lugar, embora seja obviamente necessário.
E o último, sobre interpretabilidade. Mesmo modelos lineares não são interpretáveis se tivermos muitos recursos. Quando você tem 10 mil pesos normalmente distribuídos (no caso de usar a regularização L2, será algo assim), é impossível dizer exatamente quais sinais são responsáveis pelo fato de o predizerprproba dar 0,86. Para interpretabilidade, queremos não apenas um modelo linear, mas um modelo linear com pesos esparsos. Parece que isso pode ser alcançado pela regularização de L1, mas aqui também não é tão simples. De um conjunto de recursos fortemente correlacionados, a regularização L1 escolherá um quase por acidente. O restante terá um peso 0, embora, se um desses recursos tiver capacidade preditiva, os outros claramente não sejam apenas ruído. Em termos de interpretação do modelo, isso pode ser bom; em termos de entendimento do relacionamento dos recursos e da variável de destino, isso é muito ruim. Ou seja, mesmo com modelos lineares, nem tudo é tão simples, mais detalhes sobre modelos interpretáveis e credíveis podem ser encontrados
aqui .
Visualização para aprendizado de máquina: UMAPAbsractCódigoNo dia dos tutoriais, um dos primeiros a ser apresentado foi o "Visualization for Machine Learning", do Google Brain. Como parte do tutorial, fomos informados sobre a história das visualizações, a partir do criador dos primeiros gráficos, bem como sobre vários recursos do cérebro humano, além de percepções e técnicas que podem ser usadas para chamar a atenção para a coisa mais importante da imagem, mesmo contendo muitos pequenos detalhes - por exemplo, destacando forma, cor, moldura, etc., como na figura abaixo. Vou pular esta parte, mas há uma
boa revisão .

Pessoalmente, eu estava mais interessado no tópico de visualização de conjuntos de dados multidimensionais, em particular, a abordagem de aproximação e projeção de coletores uniformes (UMAP) - um novo método não linear de redução de dimensão. Foi proposto em fevereiro deste ano, poucas pessoas o utilizam ainda, mas parece promissor tanto em termos de tempo de trabalho quanto em termos de qualidade da separação de classes em visualizações bidimensionais. Portanto, em diferentes conjuntos de dados, o UMAP está 2-10 vezes à frente do t-SNE e de outros métodos em termos de velocidade, e quanto maior a dimensão dos dados, maior a diferença no desempenho:
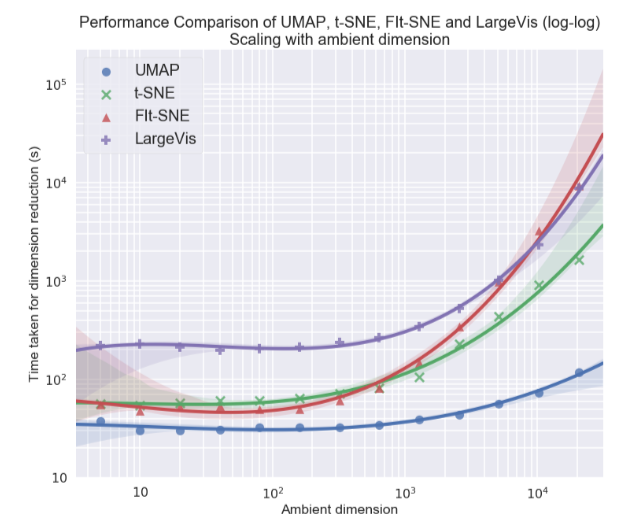
Além disso, diferentemente do t-SNE, o tempo de operação do UMAP é quase independente da dimensão do novo espaço no qual incorporaremos nosso conjunto de dados (veja a figura abaixo), o que o torna uma ferramenta adequada para outras tarefas (além da visualização) - em particular, para reduzir a dimensão antes de treinar o modelo.
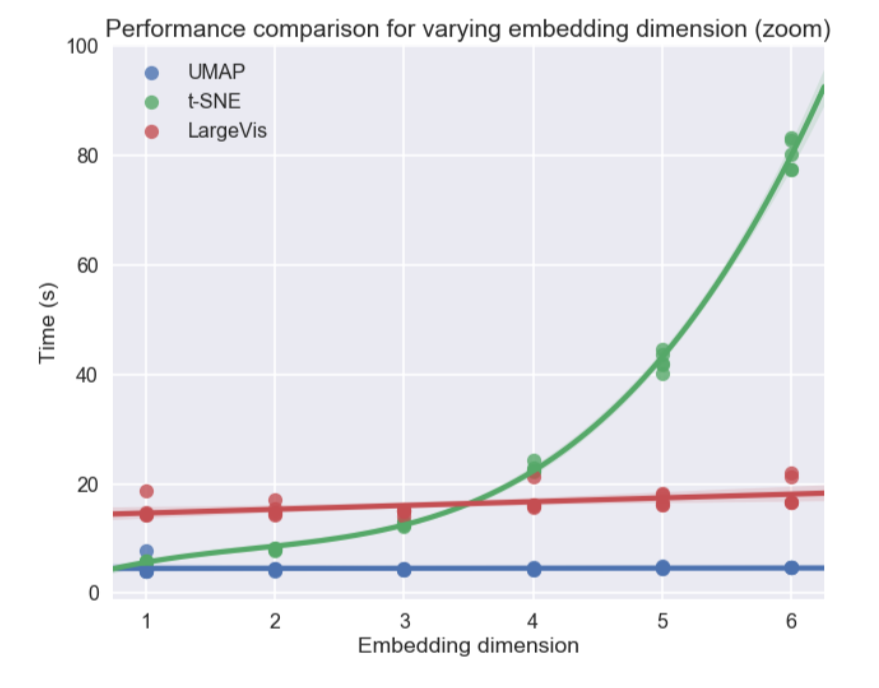
Ao mesmo tempo, os testes em diferentes conjuntos de dados mostraram que o UMAP não funciona pior para visualização, e o t-SNE é melhor em alguns locais: por exemplo, nos conjuntos de dados MNIST e Fashion MNIST, as classes são melhor separadas na versão com UMAP:
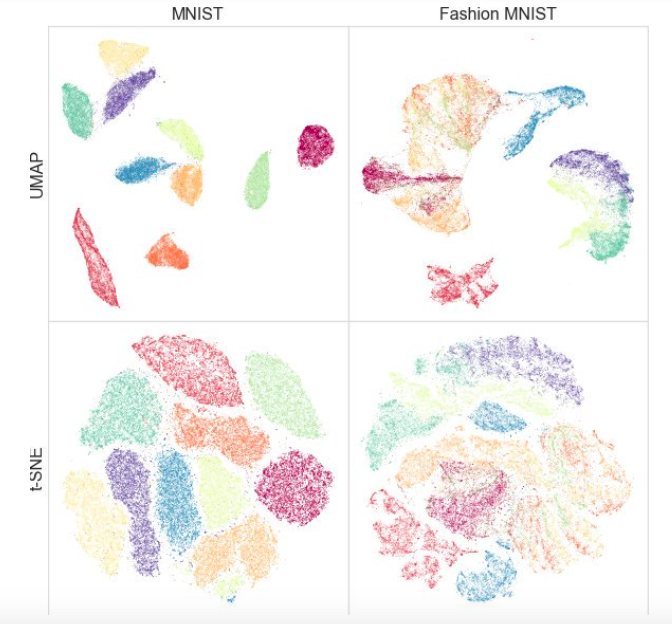
Uma vantagem adicional é uma implementação conveniente: a classe UMAP herda das classes sklearn, para que você possa usá-lo como um transformador regular no pipeline sklearn. Além disso, argumenta-se que o UMAP é mais interpretável que o t-SNE, como mantém melhor uma estrutura de dados global.
No futuro, os autores planejam adicionar suporte para treinamento semi-supervisionado - ou seja, se tivermos tags para pelo menos alguns dos objetos, podemos criar o UMAP com base nessas informações.
Quais artigos você gostou? Escreva comentários, faça perguntas, nós responderemos a eles.