Continuamos a experimentar os formatos das mitaps. Recentemente, em um ringue de boxe,
colidimos com um barramento de dados centralizado e Service Mesh. Desta vez, decidimos tentar algo mais pacífico - StandUp, ou seja, um microfone aberto. O tópico foi escolhido no banco de dados em memória.

Em que casos devo mudar para a memória? Como e por que escalar? E no que vale a pena prestar atenção? As respostas estão nos discursos dos palestrantes, que abordaremos neste post.
Mas primeiro, imagine os alto-falantes:
- Andrey Trushkin, Chefe do Centro de Inovação e Tecnologias Avançadas do Promsvyazbank
- Vladislav Shpileva, desenvolvedor Tarantool
- Artyom Shitov, arquiteto de soluções GridGain
Mudar para a memória
As tendências atuais do mercado financeiro impõem requisitos muito mais rigorosos ao tempo de resposta e operação da automação de processos em geral. Além disso, quase todas as maiores instituições financeiras hoje procuram construir seus próprios ecossistemas.
Nesse sentido, vemos por nós mesmos duas principais aplicações de soluções na memória. O primeiro é o armazenamento em cache dos dados de integração. De acordo com o cenário clássico, em grandes empresas, existem vários sistemas automatizados que fornecem dados a pedido do usuário. Ou um sistema externo - mas, neste caso, o iniciador na maioria dos casos é o usuário. Tradicionalmente, esses sistemas armazenavam dados estruturados de uma certa maneira no banco de dados, acessando-os sob demanda.
Hoje, esses sistemas não atendem mais aos requisitos em termos de carga. Aqui não devemos esquecer as chamadas remotas desses sistemas pelos sistemas do consumidor. Isso implica a necessidade de revisar abordagens para armazenamento e apresentação de dados - para usuários, sistemas automatizados ou serviços individuais. Saída lógica - armazenamento de dados relevantes usados pelos serviços no nível da camada na memória; existem muitos casos de sucesso semelhantes no mercado.
Este foi o primeiro caso. O segundo é eficaz, do ponto de vista técnico, para o gerenciamento de processos de negócios. Os sistemas BPM tradicionais automatizam a execução de determinadas operações de acordo com um algoritmo predefinido. E, em muitos casos, surgem questões: por que esses sistemas não são suficientemente eficientes e rápidos o suficiente?
Normalmente, esses sistemas gravam cada etapa (ou um pequeno conjunto de etapas, projetado como uma transação comercial) no banco de dados. Portanto, eles estão ligados ao tempo de resposta e à interação com esses sistemas. Agora, o número de instâncias de processos de negócios em execução simultaneamente em tempo real é de magnitude superior a 10 anos atrás. Portanto, os sistemas modernos de gerenciamento de processos de negócios devem ter desempenho significativamente mais alto e garantir a execução de aplicativos descentralizados. Além disso, hoje todas as empresas estão caminhando para a formação de um grande ambiente de microsserviço. O desafio é que diferentes instâncias dos processos de negócios possam compartilhar e usar com eficiência dados operacionais. Dentro da estrutura da orquestração, faz sentido armazená-los em uma solução na memória.
Problema de reconciliação
Suponha que tenhamos um grande número de nós e serviços, que vários processos de negócios sejam realizados, cujas ações são implementadas na forma de microsserviços. Para melhorar o desempenho, cada um deles começa a gravar seu estado em uma instância de memória local. Temos um grande número de instâncias locais. Como garantir relevância e consistência para todos?
Usamos áreas de zoneamento na memória. Por exemplo, dependendo do domínio comercial. Quando cortamos um domínio comercial, determinamos que determinados microsserviços / processos comerciais funcionam apenas dentro da estrutura da zona responsável pelo domínio correspondente. Dessa forma, podemos acelerar a atualização do cache e toda a solução na memória.
Ao mesmo tempo, o cache responsável pelo domínio opera no modo de replicação completa - o número limitado de nós devido à distribuição entre domínios garante a velocidade e a correção da solução nesse modo. O zoneamento e a fragmentação máxima ajudam a resolver os problemas de sincronização, operação de cluster, etc. em um grande número total de nós.
Naturalmente, muitas vezes surgem dúvidas sobre a confiabilidade das soluções na memória. Sim, nem tudo pode ser colocado lá. Para garantir a confiabilidade, sempre temos bancos de dados próximos à memória. Por exemplo, para problemas importantes nos relatórios que precisam ser reunidos, o que pode ser difícil em um grande número de nós. Então, qual é a nossa visão hoje: a
sinergia das duas abordagens .
Também é importante notar que essas duas abordagens também não são totalmente corretas apenas para contrastar. E, ao mesmo tempo, concentre-se neles. Fabricantes e colaboradores de sistemas avançados de virtualização em contêiner, como o Kubernetes, já nos oferecem opções para armazenamento confiável a longo prazo. Já surgiram bons casos industriais para implementar soluções, nos quais o armazenamento é realizado em um formato virtualizado.
Um dos maiores jornais dos EUA oferece aos seus leitores a oportunidade de receber qualquer edição on-line publicada desde o início da publicação deste jornal no século XIX. Podemos imaginar o nível de carga. O armazenamento é implementado por eles através da plataforma Apache Kafka, implantada no Kubernetes. Aqui está outra opção para armazenar informações e fornecer acesso a elas sob uma grande carga para um grande número de clientes. Ao projetar novas soluções, essa opção também merece atenção.
Escalando bancos de dados na memória com Tarantool
Suponha que tenhamos um servidor. Aceita pedidos, armazena dados. De repente, há mais solicitações e dados, o servidor para de lidar com a carga. Você pode carregar mais hardware no servidor e ele aceitará mais solicitações. Mas esse é um beco sem saída por três razões ao mesmo tempo: alto custo, recursos técnicos limitados e problemas com tolerância a falhas. Em vez disso, existe uma escala horizontal: "amigos" vêm ao servidor para ajudá-lo a concluir tarefas. Os dois principais tipos de escala horizontal são replicação e sharding.
A replicação ocorre quando há muitos servidores, todos eles armazenam os mesmos dados e as solicitações do cliente estão espalhadas por todos esses servidores. É assim que a computação, não os dados, é dimensionada. Isso funciona quando os dados são colocados em um nó, mas há tantas solicitações de cliente que um servidor não pode lidar com isso. Além disso, a tolerância a falhas é bastante aprimorada aqui.
O sharding é usado para dimensionar dados: muitos servidores são criados e eles armazenam dados diferentes. Então você dimensiona os cálculos e os dados. Mas a tolerância a falhas neste caso é baixa. Se um servidor falhar, parte dos dados será perdida.
Existe uma terceira abordagem - combiná-los. Dividimos o cluster em sub-clusters, chamados de conjuntos de réplicas. Cada um deles armazena os mesmos dados e os dados não se cruzam entre os conjuntos de réplicas. O resultado é o dimensionamento de dados, computação e tolerância a falhas.
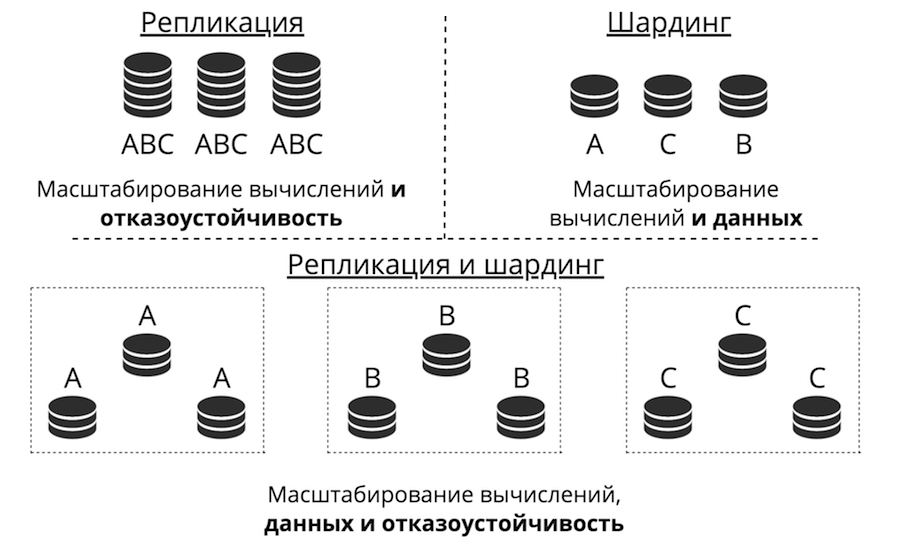
Replicação
A replicação pode ser de dois tipos: assíncrona e síncrona. Assíncrono é quando as solicitações do cliente não esperam até que os dados se espalhem pelas réplicas: basta gravar em uma réplica. Assim que os dados chegam ao disco, para o log, a transação é bem-sucedida e, algum dia, em segundo plano, esses dados são replicados. Síncrona - quando uma transação é dividida em 2 fases: preparar e confirmar. A confirmação não retornará êxito até que os dados sejam replicados para algum quorum de réplicas.
A replicação assíncrona é obviamente mais rápida, porque não há nada na rede. Os dados serão enviados para a rede em segundo plano e a transação em si, conforme registrada no log, foi concluída. Mas há um problema: réplicas podem ficar atrás uma da outra, fora de sincronia.
A replicação síncrona é mais confiável, mas muito mais lenta e mais difícil de implementar. Existem protocolos complexos. No Tarantool, você pode escolher qualquer um desses tipos de replicação, dependendo da tarefa.

O atraso das réplicas dá origem não apenas à dessincronização, mas também ao problema de ignorância do mestre: ele não sabe como passar suas alterações para a réplica. As alterações geralmente são fornecidas de forma incremental - elas são aplicadas e, da mesma forma, elas voam para a réplica. Mas o que fazer com eles se a réplica não estiver disponível? Por exemplo, tudo pode ser configurado no Tarantool, e o assistente se torna muito flexível.
Outro desafio: como tornar a topologia complexa? O Mail.ru, por exemplo, possui uma topologia com centenas de Tarantool. Ele possui um kernel tarantool ao qual as tarântulas de réplica para backups estão ligadas em um círculo. No Tarantool, você pode criar topologias completamente arbitrárias, a replicação com isso permanece perfeitamente.
Sharding
Agora vamos para o dimensionamento de dados: sharding. Pode ser de dois tipos: intervalos e hashes. O sharding de intervalo é quando todos os dados são classificados por alguma chave de sharding, e essa sequência grande é dividida em intervalos para que cada intervalo tenha aproximadamente a mesma quantidade de dados. E cada intervalo é inteiramente armazenado em qualquer nó físico. Mas geralmente esse sharding não é necessário. Além disso, é sempre muito complicado.
Há também sharding com hashes. É apenas apresentado em Tarantool. É muito mais fácil implementar, usar e quase sempre adequado, em vez de intervalos de sharding. Funciona assim: consideramos a função hash do registro e retorna o número do nó físico no qual armazenar. Existem problemas: em primeiro lugar, é difícil concluir rapidamente uma consulta complexa.
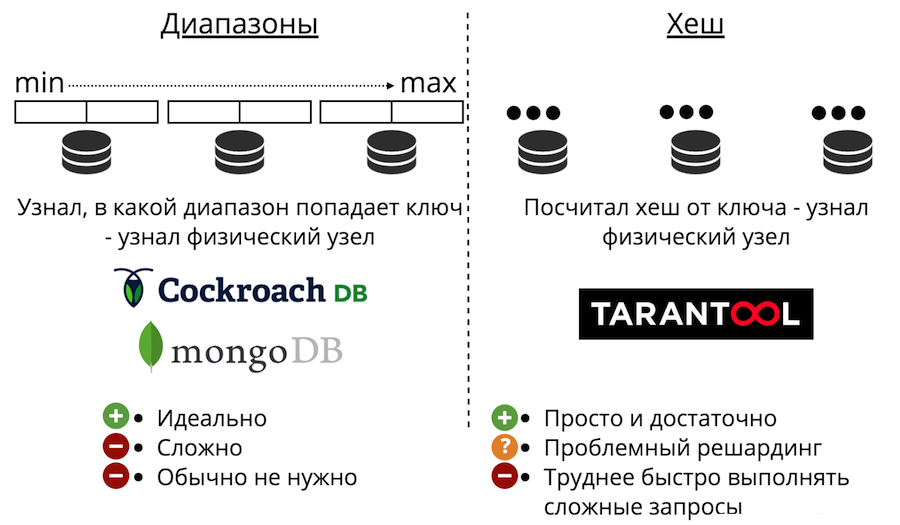
Em segundo lugar, há o problema de compartilhar novamente. Há algum tipo de função de fragmento que retorna o número do fragmento físico no qual a chave deve ser salva. E quando o número de nós muda, a função shard também muda. Isso significa que, para todos os dados que estão no cluster, eles deverão ser recalculados e verificados novamente. Além disso, no sharding clássico, alguns dados não serão transferidos para um novo nó, mas simplesmente embaralhados entre os nós antigos. Transferências inúteis não podem ser reduzidas a zero no sharding clássico.
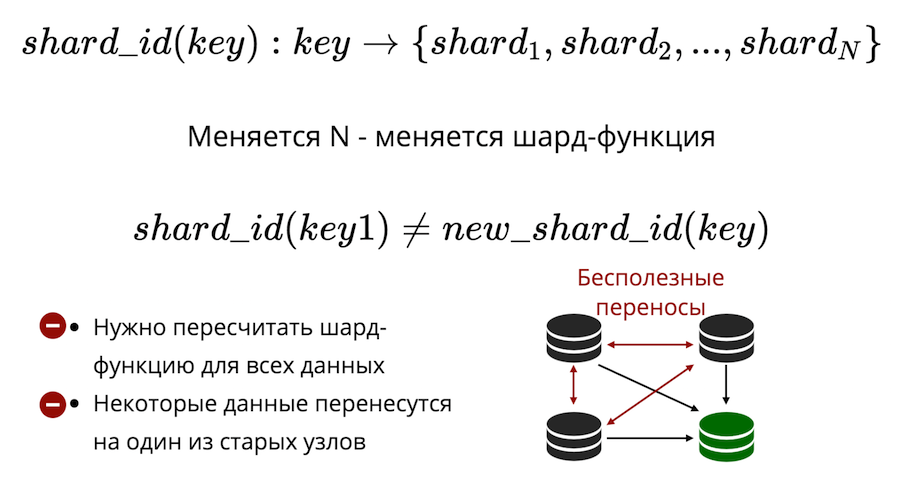
O Tarantool usa sharding virtual: os dados são distribuídos não em nós físicos, mas em nós virtuais. Balde virtual em um cluster virtual. E histórias virtuais são apresentadas em físicas. E já está garantido que cada andar virtual esteja inteiramente em um andar físico.
Como isso resolve o problema da revenda? O fato é que o número de buckets é fixo e excede seriamente o número de nós físicos. Portanto, não importa o tamanho físico do seu cluster, o bucket sempre será suficiente para armazenar dados e distribuí-los uniformemente. E devido ao fato de a função shard ser inalterada, você não precisará recalcular quando a composição do cluster for alterada.
Como resultado, obtemos
três tipos de sharding: intervalos, hashes e buckets virtuais . No caso de intervalos e intervalos, há um problema de pesquisa física.
Como resolver isso? A primeira maneira: apenas proíba o compartilhamento de compartilhamento. Para compartilhar novamente, você precisará criar um novo cluster e transferir tudo para lá. A segunda maneira: sempre vá para todos os nós. Mas isso não faz sentido, porque você precisa escalar, e os cálculos não escalam dessa maneira. Terceira opção: um módulo proxy, que serve como um tipo de roteador para baldes. Você o inicia, envia uma solicitação para lá, indicando o número do bucket, e ele envia sua solicitação como proxy para o nó físico desejado.
Exemplo avançado de memória com o exemplo da plataforma GridGain
A empresa possui requisitos adicionais de banco de dados. Ele quer que tudo isso seja tolerante a falhas e catastrófico. Ele quer alta disponibilidade: para que nada se perca, para que você possa se recuperar rapidamente. Também é necessária escalabilidade fácil e barata, suporte descomplicado, confiança na plataforma e mecanismos de acesso eficientes.
Todas essas idéias não são novas. Muitas dessas coisas são, em um grau ou outro, implementadas em DBMSs clássicos, em particular, replicação entre data centers.
O In-Memory não é mais uma tecnologia de inicialização, são produtos maduros usados nas maiores empresas do mundo (Barclays, Citi Group, Microsoft etc.). Supõe-se que todos esses requisitos sejam atendidos.
Portanto, se uma catástrofe acontecer repentinamente, deve haver uma oportunidade de se recuperar do backup. E se estamos falando de uma organização financeira, é importante que esse backup seja consistente, e não apenas uma cópia de todas as unidades. Para que não exista uma situação em que em algumas partes dos nós os dados foram restaurados no momento X e, no outro, no momento Y. É muito importante ter o Point-in-time Recovery, para que, mesmo em uma situação de corrupção de dados ou de um acidente particularmente grave, minimize a quantidade de perdas.
É importante poder enviar dados para o disco. Para que o cluster não fique sobrecarregado e continue a trabalhar ainda mais devagar. E para sair rapidamente do disco e depois bombear os dados para a memória.
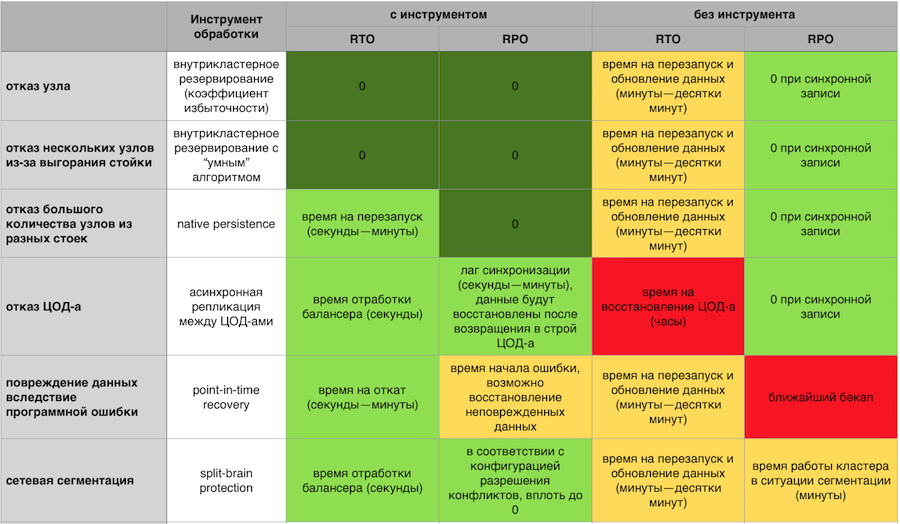 Resposta na memória a falhas com e sem componentes de tolerância a falhas GridGain
Resposta na memória a falhas com e sem componentes de tolerância a falhas GridGainUm cluster de failover deve ser dimensionado facilmente na horizontal e na vertical. Não tenho vontade de pagar pelo meu servidor e observar como metade dos recursos está ociosa. Não quero ter centenas de processos que precisam ser gerenciados. Eu quero um sistema simples do ponto de vista do suporte, com entrada / saída fácil de nós do cluster e um sistema de monitoramento desenvolvido e maduro.
Considere o MongoDB nesta perspectiva. Todo mundo que trabalhou com o MongoDB está ciente de um grande número de processos. Se tivermos um MongoDB sombreado de 5 shards, cada shard terá um conjunto de réplicas de três processos (com uma taxa de redundância de 3). E são 15 processos apenas nos próprios dados. O armazenamento de configuração de cluster é outro mais três processos, no total, obtém 18, e isso não inclui roteadores. Se você quiser 20 shards, seja bem-vindo de mais de 63 processos (por exemplo, outros 8, total de 71).
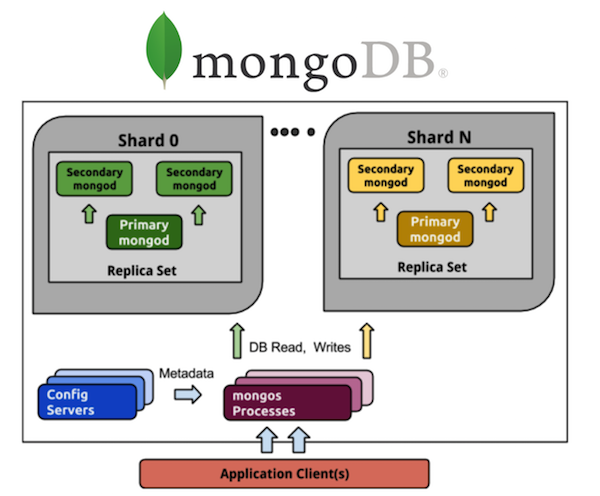
Compare com Cassandra. Tomamos todos os mesmos 5 shards - são 5 processos e 5 nós com a mesma taxa de redundância de 3, o que é muito mais simples em termos de controle. Quero 20 shards - são 20 processos. Posso dimensionar meu cluster para qualquer número de nós, não necessariamente um múltiplo de 3 (ou para outro valor do coeficiente de redundância). Muito mais fácil e barato de implementar e manter do que conjuntos de réplicas.

Além disso, você precisa confiar no sistema para entender o que as pessoas estão por trás de cada produto. Idealmente, a licença deve ser de código aberto ou núcleo aberto. Para que, em caso de morte do fornecedor, algo possa ser feito. Também é bom se o código-fonte for gerenciado por uma comunidade independente - todos nos lembramos de como o MongoDB e o Redis alteraram as licenças a pedido da empresa de gerenciamento. Como a Aerospike introduziu restrições na edição da comunidade de "código aberto" no início do ano.
Precisa de acesso efetivo aos dados. Quase todos têm uma linguagem de consulta estruturada de uma forma ou de outra. Na maioria das vezes eles usam SQL, é necessário que a adaptação com essa linguagem seja o mais fácil possível. Isso ajudará a execução da consulta distribuída, quando você não precisar enviar uma solicitação separadamente para cada nó, mas poderá se comunicar com o cluster como em uma "janela única". Sem pensar do ponto de vista da API, este é um conjunto de nós (lembre-se de como é difícil trabalhar com o Memcache em grandes volumes, mesmo no nível mais simples de put / get, sem consultas SQL potencialmente complexas), garantias DDL e ACID distribuídas.
E, finalmente, suporte. Se algo de repente não funcionar, a empresa simplesmente perde dinheiro. Para algumas áreas, isso não é crítico, mas geralmente é importante que alguém seja responsável pelo produto e seu trabalho. Que era possível a qualquer momento fazer uma reclamação, e ela foi rapidamente resolvida.
Com este post, estamos completando o ano do Promsvyazbank em Habré. Reunimos os desejos de Ano Novo para os moradores de Khabrovsk em um pequeno vídeo: