Olá colegas!

Na última publicação do ano seguinte, queríamos mencionar o Aprendizado por Reforço - um tópico para o qual já estamos traduzindo um
livro .
Julgue por si mesmo: havia um artigo elementar no Medium, que descrevia o contexto do problema, descrevia o algoritmo mais simples com a implementação em Python. O artigo tem vários gifs. E motivação, recompensa e escolha da estratégia certa no caminho para o sucesso são coisas que serão extremamente úteis para cada um de nós no próximo ano.
Boa leitura!
O aprendizado reforçado é uma forma de aprendizado de máquina na qual o agente aprende a agir no ambiente, realizando ações e desenvolvendo a intuição, após o que observa os resultados de suas ações. Neste artigo, mostrarei como entender e formular o problema de aprender com reforço e depois resolvê-lo em Python.
Recentemente, nos acostumamos ao fato de que os computadores jogam jogos contra seres humanos - como bots em jogos multiplayer ou como rivais em jogos one-on-one: digamos, em Dota2, PUB-G, Mario. A empresa de pesquisa
Deepmind se
preocupou com as notícias quando seu programa AlphaGo de 2016 venceu o campeão sul-coreano em 2016. Se você é um jogador ávido, pode ouvir as cinco partidas do Dota 2 OpenAI Five, onde carros lutaram contra pessoas e derrotaram os melhores jogadores do Dota2 em várias partidas. (Se você estiver interessado nos detalhes, o algoritmo é analisado em detalhes
aqui e é examinado como as máquinas tocaram).

A versão mais recente do OpenAI Five
leva Roshan .
Então, vamos começar com a pergunta central. Por que precisamos de treinamento reforçado? É usado apenas em jogos ou é aplicável em cenários realistas para resolver problemas aplicados? Se esta é sua primeira vez lendo um treinamento de reforço, você simplesmente não consegue imaginar a resposta para essas perguntas. De fato, o aprendizado reforçado é uma das tecnologias mais amplamente utilizadas e de rápido desenvolvimento no campo da inteligência artificial.
Aqui estão algumas áreas nas quais os sistemas de aprendizado por reforço são especialmente procurados:
- Veículos não tripulados
- Indústria de jogos
- Robótica
- Sistemas Recomendadores
- Publicidade e Marketing
Visão geral e antecedentes da aprendizagem por reforçoEntão, como o fenômeno do aprendizado com reforço se formou quando temos tantos métodos de aprendizado profundo e à máquina à nossa disposição? "Ele foi inventado por Rich Sutton e Andrew Barto, supervisor de pesquisa de Rich, que o ajudaram a preparar o doutorado". O paradigma tomou forma nos anos 80 e foi arcaico. Posteriormente, Rich acreditava que ela tinha um grande futuro, e ela acabaria por receber reconhecimento.
O aprendizado reforçado suporta a automação no ambiente em que é implantado. Tanto o aprendizado de máquina quanto o aprendizado profundo operam aproximadamente da mesma maneira - eles são organizados de forma diferente, mas ambos os paradigmas suportam a automação. Então, por que surgiu o treinamento de reforço?
É uma reminiscência do processo natural de aprendizagem em que o processo / modelo atua e recebe feedback sobre como ela consegue lidar com a tarefa: boa e não.
Máquina e aprendizado profundo também são opções de treinamento, no entanto, são mais personalizados para identificar padrões nos dados disponíveis. No aprendizado por reforço, por outro lado, essa experiência é adquirida por tentativa e erro; o sistema encontra gradualmente as opções certas ou o ideal global. Uma vantagem adicional séria do aprendizado reforçado é que, nesse caso, não é necessário fornecer um conjunto extenso de dados de treinamento, como no ensino com um professor. Alguns pequenos fragmentos serão suficientes.
O conceito de aprendizagem por reforçoImagine ensinar seus gatos novos truques; mas, infelizmente, os gatos não entendem a linguagem humana, então você não pode pegar e dizer a eles o que vai brincar com eles. Portanto, você agirá de maneira diferente: imitar a situação, e o gato tentará responder de uma maneira ou de outra em resposta. Se o gato reagiu da maneira que você queria, você despeja leite nele. Você entende o que vai acontecer a seguir? Mais uma vez, em uma situação semelhante, o gato executará a ação desejada novamente e com um entusiasmo ainda maior, esperando que seja alimentado ainda melhor. É assim que a aprendizagem ocorre em um exemplo positivo; mas, se você tentar "educar" um gato com incentivos negativos, por exemplo, olhe estritamente para ele e franze a testa, ele geralmente não aprende nessas situações.
O aprendizado reforçado funciona da mesma forma. Dizemos à máquina algumas informações e ações e, em seguida, recompensamos a máquina, dependendo da saída. Nosso objetivo final é maximizar as recompensas. Agora vamos ver como reformular o problema acima em termos de aprendizado por reforço.
- O gato age como um "agente" exposto ao "ambiente".
- O ambiente é uma casa ou área de lazer, dependendo do que você está ensinando ao gato.
- As situações decorrentes do treinamento são chamadas de "estados". No caso de um gato, exemplos de condições são quando o gato "corre" ou "rasteja debaixo da cama".
- Os agentes reagem executando ações e passando de um "estado" para outro.
- Depois que o estado muda, o agente recebe uma “recompensa” ou uma “multa”, dependendo da ação que ele tomou.
- "Estratégia" é uma metodologia para escolher uma ação para obter os melhores resultados.
Agora que descobrimos o que é aprendizagem por reforço, vamos falar em detalhes sobre as origens e a evolução da aprendizagem por reforço e aprendizagem profunda com reforço, discutir como esse paradigma nos permite resolver problemas impossíveis de aprender com ou sem um professor e também observe o seguinte fato curioso: atualmente, o mecanismo de pesquisa do Google é otimizado usando algoritmos de aprendizado por reforço.
Entendendo a terminologia de aprendizado por reforçoO agente e o ambiente desempenham papéis importantes no algoritmo de aprendizado por reforço. O ambiente é o mundo em que o agente precisa sobreviver. Além disso, o agente recebe sinais de reforço do ambiente (recompensa): este é um número que descreve o quão bom ou ruim o estado atual do mundo pode ser considerado. O objetivo do agente é maximizar a recompensa total, o chamado "ganho". Antes de escrever nossos primeiros algoritmos de aprendizado por reforço, você precisa entender a seguinte terminologia.

- Estados : Um estado é uma descrição completa de um mundo em que não falta um único fragmento da informação que caracteriza esse mundo. Pode ser uma posição, fixa ou dinâmica. Como regra, esses estados são escritos na forma de matrizes, matrizes ou tensores de ordem superior.
- Ação : A ação geralmente depende das condições ambientais e, em diferentes ambientes, o agente executa ações diferentes. Muitas ações válidas do agente são registradas em um espaço chamado "espaço de ação". Normalmente, o número de ações no espaço é finito.
- Ambiente : este é o local em que o agente existe e com o qual ele interage. Diferentes tipos de recompensas, estratégias etc. são usados para diferentes ambientes.
- Recompensas e ganhos : Você precisa monitorar constantemente a função de recompensa R ao treinar com reforços. É essencial ao configurar um algoritmo, otimizá-lo e também quando você parar de aprender. Depende do estado atual do mundo, da ação que acabou de ser realizada e do próximo estado do mundo.
- Estratégias : uma estratégia é uma regra segundo a qual um agente escolhe a próxima ação. O conjunto de estratégias também é chamado de "cérebro" do agente.
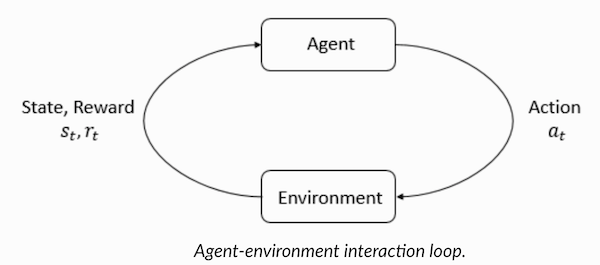
Agora que nos familiarizamos com a terminologia de aprendizado por reforço, vamos resolver o problema usando os algoritmos apropriados. Antes disso, você precisa entender como formular esse problema e, ao resolvê-lo, confiar na terminologia do treinamento com reforço.
Solução de táxiEntão, passamos a resolver o problema com o uso de algoritmos de reforço.
Suponha que tenhamos uma zona de treinamento para um táxi não tripulado, que treinamos para entregar passageiros ao estacionamento em quatro pontos diferentes (
R,G,Y,B ). Antes disso, você precisa entender e definir o ambiente em que começamos a programar em Python. Se você está apenas começando a aprender Python, recomendo
este artigo para você .
O ambiente para resolver um problema de táxi pode ser configurado usando o
ginásio da OpenAI - esta é uma das bibliotecas mais populares para resolver problemas com treinamento de reforço. Bem, antes de usar o ginásio, você precisa instalá-lo em sua máquina, e um gerenciador de pacotes Python chamado pip é conveniente para isso. A seguir está o comando de instalação.
pip install gymA seguir, vamos ver como nosso ambiente será exibido. Todos os modelos e a interface para esta tarefa já estão configurados no ginásio e nomeados sob
Taxi-V2 . O trecho de código abaixo é usado para exibir esse ambiente.
“Temos quatro locais (indicados por letras diferentes); nossa tarefa é pegar um passageiro em um ponto e deixá-lo em outro. Recebemos +20 pontos para um pouso de passageiros bem-sucedido e perdemos 1 ponto para cada etapa gasta nele. Há também uma penalidade de 10 pontos para cada embarque e desembarque não intencional de um passageiro. ” (Fonte:
gym.openai.com/envs/Taxi-v2 )
Aqui está a saída que veremos em nosso console:

Táxi V2 ENV
Ótimo, o
env é o coração do OpenAi Gym, é uma interface de ambiente unificado. A seguir, são apresentados métodos env que consideramos úteis:
env.reset : redefine o ambiente e retorna um estado inicial aleatório.
env.step(action) :
env.step(action) desenvolvimento do meio ambiente um passo no tempo.
env.step(action) : retorna as seguintes variáveis
observation : Observação do meio ambiente.reward : reward se sua ação foi benéfica.done : indica se conseguimos pegar e deixar o passageiro adequadamente, também conhecido como "um episódio".info : informações adicionais, como desempenho e latência, necessárias para fins de depuração.env.render : exibe um quadro do ambiente (útil para renderizar)
Então, depois de examinar o ambiente, vamos tentar entender melhor o problema. Os táxis são o único carro nesse estacionamento. O estacionamento pode ser dividido em uma grade
5x5 , onde temos 25 locais de táxi possíveis. Esses 25 valores são um dos elementos do nosso espaço de estados. Atenção: no momento, nosso táxi está localizado no ponto com coordenadas (3, 1).
Existem 4 pontos no ambiente em que os passageiros podem embarcar: são
R, G, Y, B ou
[(0,0), (0,4), (4,0), (4,3)] em coordenadas ( horizontalmente; verticalmente), se fosse possível interpretar o ambiente acima em coordenadas cartesianas. Se você também levar em conta outro (1) estado do passageiro: dentro do táxi, poderá tomar todas as combinações de localizações de passageiros e seus destinos para calcular o número total de estados em nosso ambiente para treinamento em táxi: temos quatro (4) destinos e cinco (4+ 1) localizações de passageiros.
Portanto, em nosso ambiente para um táxi, existem 5 × 5 × 5 × 4 = 500 estados possíveis. Um agente lida com uma das 500 condições e entra em ação. No nosso caso, as opções são as seguintes: mover-se em uma direção ou outra, ou a decisão de pegar / deixar o passageiro. Em outras palavras, temos à disposição seis ações possíveis:
pickup, drop, norte, leste, sul, oeste (Os últimos quatro valores são as direções nas quais um táxi pode se mover.)
Este é o
action space : o conjunto de todas as ações que nosso agente pode
action space em um determinado estado.
Como fica claro na ilustração acima, um táxi não pode executar determinadas ações em algumas situações (paredes interferem). No código que descreve o ambiente, simplesmente atribuímos uma penalidade de -1 para cada acerto na parede e um táxi colidindo com a parede. Assim, essas multas se acumularão, de modo que o táxi tentará não bater nas paredes.
Tabela de recompensa: Ao criar um ambiente de táxi, também pode ser criada uma tabela de recompensa primária chamada P. Você pode considerá-la uma matriz, em que o número de estados corresponde ao número de linhas e o número de ações ao número de colunas. Ou seja, estamos falando da matriz
states × actions .
Como absolutamente todas as condições são registradas nessa matriz, é possível visualizar os valores de recompensa padrão atribuídos ao estado que escolhemos ilustrar:
>>> import gym >>> env = gym.make("Taxi-v2").env >>> env.P[328] {0: [(1.0, 433, -1, False)], 1: [(1.0, 233, -1, False)], 2: [(1.0, 353, -1, False)], 3: [(1.0, 333, -1, False)], 4: [(1.0, 333, -10, False)], 5: [(1.0, 333, -10, False)] }
A estrutura deste dicionário é a seguinte:
{action: [(probability, nextstate, reward, done)]} .
- Os valores de 0 a 5 correspondem às ações (sul, norte, leste, oeste, pickup, dropoff) que um táxi pode executar no estado atual mostrado na ilustração.
- feito permite que você julgue quando deixamos o passageiro com sucesso no ponto desejado.
Para resolver esse problema sem nenhum treinamento com reforço, você pode definir o estado de destino, fazer uma seleção de espaços e, se conseguir atingir o estado de destino para um determinado número de iterações, suponha que esse momento corresponda à recompensa máxima. Em outros estados, o valor da recompensa se aproxima do máximo se o programa agir corretamente (se aproxima da meta) ou acumula multas se cometer erros. Além disso, o valor da multa não pode atingir valores inferiores a -10.
Vamos escrever um código para resolver esse problema sem treinamento de reforço.
Como temos uma tabela P com valores de recompensa padrão para cada estado, podemos tentar organizar a navegação de nosso táxi apenas com base nessa tabela.
Criamos um loop infinito, rolando até o passageiro chegar ao destino (um episódio) ou, em outras palavras, até que a taxa de recompensa atinja 20. O método
env.action_space.sample() seleciona automaticamente uma ação aleatória do conjunto de todas as ações disponíveis . Considere o que acontece:
import gym from time import sleep
Conclusão:
créditos: OpenAI
O problema foi resolvido, mas não otimizado, ou esse algoritmo não funcionará em todos os casos. Precisamos de um agente de interação adequado para que o número de iterações gastas pela máquina / algoritmo para resolver o problema permaneça mínimo. Aqui, o algoritmo Q-learning nos ajudará, cuja implementação consideraremos na próxima seção.
Introdução ao Q-LearningAbaixo está o mais popular e um dos algoritmos de aprendizado por reforço mais simples. O ambiente recompensa o agente pelo treinamento gradual e pelo fato de que, em um determinado estado, ele dá o passo mais ideal. Na implementação discutida acima, tivemos uma tabela de recompensa "P", segundo a qual nosso agente aprenderá. Com base na tabela de recompensas, ele escolhe a próxima ação, dependendo de quão útil seja, e atualiza outro valor, chamado Q-value. Como resultado, é criada uma nova tabela, chamada Q-table, exibida na combinação (Status, Ação). Se os valores Q forem melhores, obteremos recompensas mais otimizadas.
Por exemplo, se um táxi estiver em um estado em que o passageiro esteja no mesmo ponto que o táxi, é extremamente provável que o valor Q para a ação de "retirada" seja maior do que para outras ações, por exemplo, "deixe o passageiro" ou "vá para o norte" "
Os valores Q são inicializados com valores aleatórios e, à medida que o agente interage com o ambiente e recebe várias recompensas executando determinadas ações, os valores Q são atualizados de acordo com a seguinte equação:

Isso levanta a questão: como inicializar valores Q e como calculá-los. À medida que as ações são executadas, os valores Q são executados nesta equação.
Aqui, Alpha e Gamma são os parâmetros do algoritmo Q-learning. Alfa é o ritmo da aprendizagem e gama é o fator de desconto. Ambos os valores podem variar de 0 a 1 e às vezes são iguais a um. A gama pode ser igual a zero, mas a alfa não, porque o valor das perdas durante a atualização deve ser compensado (a taxa de aprendizado é positiva). O valor alfa aqui é o mesmo de quando leciona com um professor. A gama determina a importância que queremos dar às recompensas que nos aguardam no futuro.
Este algoritmo está resumido abaixo:
- Etapa 1: inicialize a tabela Q, preenchendo-a com zeros, e para os valores Q, definimos constantes arbitrárias.
- Etapa 2: agora deixe o agente responder ao ambiente e tentar ações diferentes. Para cada alteração de estado, selecionamos uma de todas as ações possíveis nesse estado (S).
- Etapa 3: vá para o próximo estado (S ') com base nos resultados da ação anterior (a).
- Etapa 4: para todas as ações possíveis do estado (S '), selecione uma com o valor Q mais alto.
- Etapa 5: atualize os valores da tabela Q de acordo com a equação acima.
- Etapa 6: Transforme o próximo estado no atual.
- Etapa 7: se o estado de destino for atingido, concluímos o processo e repetimos.
Q-learning em Python import gym import numpy as np import random from IPython.display import clear_output
Ótimo, agora todos os seus valores serão armazenados na variável
q_table .
Portanto, seu modelo é treinado em condições ambientais e agora sabe como selecionar com mais precisão os passageiros. E você se familiarizou com o fenômeno do aprendizado por reforço e pode programar o algoritmo para resolver um novo problema.
Outras técnicas de aprendizado por reforço:
- Processos de tomada de decisão de Markov (MDP) e equações de Bellman
- Programação dinâmica: RL baseada em modelo, iteração de estratégia e iteração de valor
- Deep Q-Training
- Métodos de descida de gradiente de estratégia
- Sarsa
O código para este exercício está localizado em:
vihar / python-reforço-aprendizagem