
Então, é hora de falar sobre a próxima geração de processadores multicelulares: MultiClet S1. Se esta é a primeira vez que você os conhece, verifique a história e a ideologia da arquitetura nestes artigos:
No momento, o novo processador está em desenvolvimento, mas os primeiros resultados já apareceram e você pode avaliar do que ele será capaz.
Vamos começar com as maiores mudanças: recursos básicos.
Características
Está previsto atingir os seguintes indicadores:
- Número de células: 64
- Processo técnico: 28 nm
- Frequência de clock: 1,6 GHz
- O tamanho da memória no chip: 8 MB
- Área de cristal: 40mm 2
- Consumo de energia: 6 W
Os números reais serão anunciados com base nos resultados dos testes de amostras fabricadas em 2019. Além das características do próprio chip, o processador suporta até 16 GB de RAM padrão DDR4 3200MHz, barramento PCI Express e PLL.
Deve-se notar que o processo de fabricação de 28 nm é a faixa familiar mais baixa que não requer permissões especiais de uso, por isso foi ele quem foi escolhido. Pelo número de células, diferentes opções foram consideradas: 128 e 256, mas com um aumento na área do cristal, a porcentagem de rejeitos aumenta. Estabelecemos 64 células e, consequentemente, uma área relativamente pequena, o que proporcionará um rendimento maior de cristais adequados na placa. É possível um maior desenvolvimento na estrutura do
ICS (sistema no caso) , onde será possível combinar vários cristais de 64 células em um caso.
Deve-se dizer que o objetivo e o uso do processador estão mudando radicalmente. O S1 não será um microprocessador projetado para incorporação, como P1 e R1, mas um acelerador de cálculos. Assim como a GPGPU, uma placa baseada em S1 pode ser inserida na placa-mãe PCI Express de um PC comum e usada para processamento de dados.
Arquitetura
No S1, o "multicel" é agora a unidade computacional mínima: um conjunto de 4 células executando uma certa sequência de comandos. Inicialmente, planejava-se combinar multicélulas em grupos chamados cluster para execução conjunta de comandos: um cluster precisava conter 4 multicells, no total havia 4 clusters separados no cristal. No entanto, cada célula tem uma conexão completa com todas as outras células do aglomerado e, com um aumento no grupo de ligações, torna-se excessiva, o que complica muito o design topológico do microcircuito e reduz suas características. Portanto, eles decidiram abandonar a divisão de cluster, uma vez que a complicação não justifica os resultados. Além disso, para obter o desempenho máximo, é mais benéfico executar o código em paralelo em cada multicell. Total, agora o processador contém 16 multicélulas separadas.
Um multicelular, embora constituído por 4 células, difere de um R1 de 4 células, no qual cada célula possui sua própria memória, seu próprio bloco de comandos de amostra e sua própria ULA. S1 é organizado de maneira um pouco diferente. A ALU possui 2 partes: um bloco aritmético de ponto flutuante e um bloco aritmético inteiro. Cada célula possui um bloco inteiro separado, mas existem apenas dois blocos com um ponto flutuante em uma multicélula e, portanto, dois pares de células os dividem entre si. Isso foi feito principalmente para reduzir a área do cristal: a aritmética de ponto flutuante de 64 bits, em contraste com a aritmética inteira, ocupa muito espaço. Ter uma ALU em cada célula acabou sendo redundante: os comandos de busca não fornecem o carregamento da ALU e eles estão ociosos. Embora reduza o número de blocos da ALU e mantenha o ritmo de busca de comandos e dados, como a prática demonstrou, o tempo total para resolver problemas praticamente não muda ou muda um pouco, e os blocos da ALU estão totalmente carregados. Além disso, a aritmética de ponto flutuante não é usada com tanta freqüência quanto com número inteiro.
Uma vista esquemática dos blocos dos processadores R1 e S1 é mostrada no diagrama abaixo. Aqui:
- CU (Unidade de controle) - unidade de busca de instruções
- ALU FX - unidade lógica aritmética da aritmética inteira
- ALU FP - Unidade lógica aritmética da aritmética de ponto flutuante
- DMS (Data Memory Scheduler) - unidade de controle de memória de dados
- DM - memória de dados
- PMS (Program Memory Scheduler) - programa de controle de memória
- PM - memória de programa
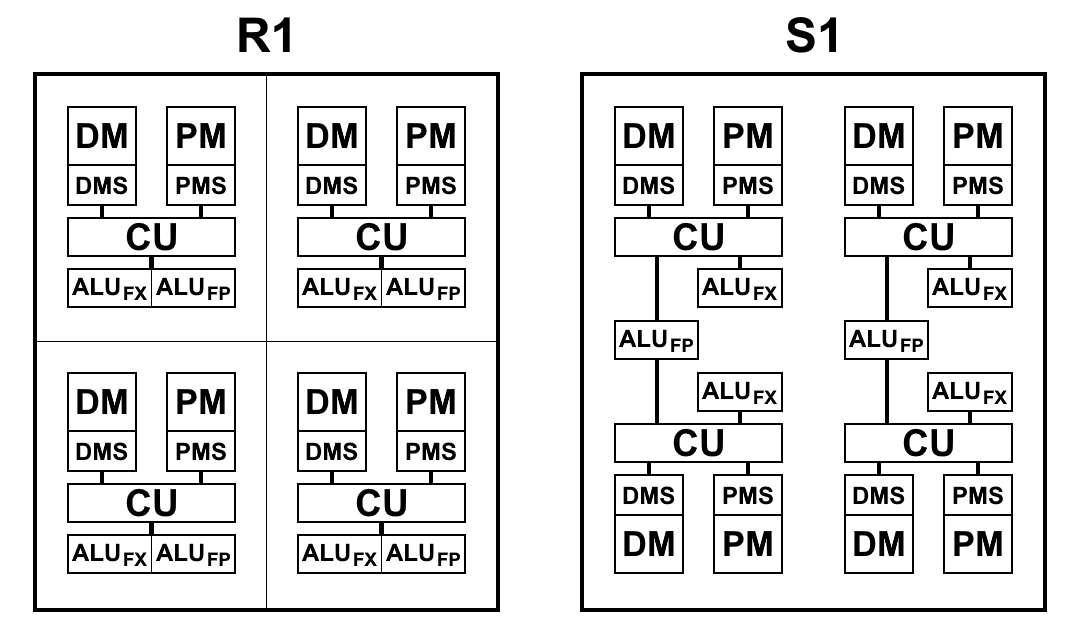
Diferenças arquitetônicas S1:
- As equipes agora podem acessar os resultados da equipe dos parágrafos anteriores. Essa é uma alteração muito importante que permite acelerar significativamente as transições ao ramificar o código. Os processadores P1 e R1 não tiveram escolha a não ser gravar os resultados desejados na memória e lê-los imediatamente de volta com os primeiros comandos no novo parágrafo. Mesmo ao usar memória em um chip, as operações de gravação e leitura levam de 2 a 5 ciclos cada, o que pode ser salvo simplesmente referindo-se ao resultado do comando do parágrafo anterior
- A gravação na memória e nos registros agora ocorre imediatamente, e não no final de um parágrafo, o que permite que você comece a escrever comandos antes do final do parágrafo. Como resultado, o tempo de inatividade potencial entre parágrafos é reduzido.
- O sistema de comando foi otimizado, a saber:
- Adicionado aritmética de número inteiro de 64 bits: adição, subtração, multiplicação de números de 32 bits, que retorna um resultado de 64 bits.
- O método de leitura da memória foi alterado: agora para qualquer comando, você pode simplesmente especificar o endereço do qual deseja ler os dados como argumento, enquanto a ordem de execução dos comandos de leitura e gravação é preservada.
Também tornou obsoleto um comando de leitura de memória separado. Em vez disso, o comando load value é usado na opção load (anteriormente, get ), especificando o endereço na memória como argumento:
.data foo: .long 0x1234 .text habr: load_l foo ; foo load_l [foo] ; 0x1234 add_l [foo], 0xABCD ; ; complete
- Foi adicionado um formato de comando que permite o uso de 2 argumentos constantes.
Anteriormente, era possível especificar uma constante apenas como um segundo argumento, o primeiro argumento sempre deve ser um link para o resultado no comutador. A alteração se aplica a todas as equipes de dois argumentos. O campo constante é sempre de 32 bits, portanto esse formato permite, por exemplo, gerar constantes de 64 bits com um comando.
Foi:
load_l 0x12345678 patch_q @1, 0xDEADBEEF
Tornou-se:
patch_q 0x12345678, 0xDEADBEEF
- Tipos de dados vetoriais modificados e suplementados.
O que costumava ser chamado de tipos de dados "compactados" agora pode ser chamado de vetorial com segurança. Em P1 e R1, as operações em números compactados levaram apenas uma constante como o segundo argumento, isto é, por exemplo, ao adicionar, cada elemento do vetor foi adicionado com o mesmo número e isso não pôde ser aplicado de maneira inteligente. Agora, operações semelhantes podem ser aplicadas a dois vetores completos. Além disso, essa maneira de trabalhar com vetores é totalmente consistente com o mecanismo de vetores no LLVM, que agora permite ao compilador gerar código usando tipos de vetores.
patch_q 0x00010002, 0x00030004 patch_q 0x00020003, 0x00040005 mul_ps @1, @2 ; - 00020006000C0014
- Sinalizadores do processador removidos.
Como resultado, foram removidas cerca de 40 equipes baseadas apenas nos valores das bandeiras. Isso reduziu significativamente o número de equipes e, consequentemente, a área do cristal. E todas as informações necessárias agora são armazenadas diretamente na célula do switch.
- Ao comparar com zero, em vez do sinalizador zero, agora apenas o valor no comutador é usado
- Em vez do sinalizador, agora é usado um bit correspondente ao tipo de comando: 7º para byte, 15º para abreviação, 31º para long, 63º para long, 63º para quad. Devido ao fato de o caractere se multiplicar até o 63º bit, independentemente do tipo, você pode comparar números de tipos diferentes:
.data long: .long -0x1000 byte: .byte -0x10 .text habr: a := load_b [byte] ; 0xFFFFFFFFFFFFFFF0, ; byte 7 63. b := loadu_b [byte] ; 0x00000000000000F0, ; .. loadu_b c := load_l [long] ; 0xFFFFFFFFFFFFF000. ge_l @a, @c ; " " 1: ; 31 , . lt_s @a, @b ; 1, .. b complete
- O sinalizador de transporte não é mais necessário, pois há aritmética de 64 bits
- O tempo de transição de parágrafo para parágrafo foi reduzido para 1 medida (em vez de 2-3 em R1)
Compilador baseado em LLVM
O compilador da linguagem C para S1 é semelhante ao R1 e, como a arquitetura não mudou fundamentalmente, os problemas descritos no artigo anterior, infelizmente, não desapareceram.
No entanto, no processo de implementação do novo sistema de comando, a quantidade de código de saída diminuiu por si só, simplesmente devido à atualização do sistema de comando. Além disso, existem muitas otimizações menores que reduzirão o número de instruções no código, algumas das quais já foram executadas (por exemplo, gerar constantes de 64 bits com uma única instrução). Mas há otimizações ainda mais sérias que precisam ser feitas e elas podem ser construídas em ordem crescente de eficiência e complexidade de implementação:
- A capacidade de gerar todos os comandos de dois argumentos com duas constantes.
Gerar uma constante de 64 bits via patch_q é apenas um caso especial, mas precisamos de um caso geral. De fato, o objetivo dessa otimização é permitir que as equipes substituam apenas o primeiro argumento como uma constante, uma vez que o segundo argumento sempre pode ser uma constante, e isso tem sido implementado há muito tempo. Esse não é um caso muito frequente, mas, por exemplo, quando você precisa chamar uma função e escrever o endereço de retorno na parte superior da pilha, pode
load_l func wr_l @1, #SP
otimizar para
wr_l func, #SP
- A capacidade de substituir o acesso à memória por meio de um argumento em qualquer comando.
Por exemplo, se você precisar adicionar dois números da memória, poderá
load_l [foo] load_l [bar] add_l @1, @2
otimizar para
add_l [foo], [bar]
Essa otimização é uma extensão da anterior, no entanto, a análise já é necessária aqui: essa substituição só pode ser realizada se os valores carregados forem usados apenas uma vez neste comando de adição e em nenhum outro lugar. Se o resultado da leitura for usado mesmo em apenas dois comandos, é mais lucrativo ler da memória uma vez como um comando separado e nos outros dois referenciá-lo através do switch.
- Otimização da transferência de registros virtuais entre unidades base.
Para R1, a transferência de todos os registradores virtuais foi feita através da memória, o que gera um número muito grande de leituras e gravações na memória, mas simplesmente não havia outra maneira de transferir dados entre parágrafos. S1 permite acessar os resultados dos comandos dos parágrafos anteriores; portanto, teoricamente, muitas operações de memória podem ser removidas, o que daria o maior efeito entre todas as otimizações. No entanto, essa abordagem ainda é limitada pela opção: não mais que 63 resultados anteriores, tão longe de toda transferência do registro virtual pode ser implementada dessa maneira. Como fazer isso não é uma tarefa trivial, e uma análise das possibilidades para resolvê-lo ainda precisa ser feita. As fontes do compilador podem aparecer em domínio público; portanto, se alguém tiver idéias e você desejar ingressar no desenvolvimento, você poderá fazê-lo.
Benchmarks
Como o processador ainda não foi lançado no chip, é difícil avaliar seu desempenho real. No entanto, o código do kernel RTL já está pronto, o que significa que você pode fazer uma avaliação usando simulação ou FPGA. Para executar os seguintes benchmarks, usamos uma simulação usando o programa ModelSim para calcular o tempo exato de execução (em medidas). Como é difícil simular todo o cristal e leva muito tempo, portanto, uma multicélula foi simulada e o resultado foi multiplicado por 16 (se a tarefa foi projetada para multithreading), pois cada multicélula pode funcionar completamente independentemente das outras.
Ao mesmo tempo, a modelagem multicelular foi realizada no Xilinx Virtex-6 para testar o desempenho do código do processador em hardware real.
Coremark
CoreMark - um conjunto de testes para uma avaliação abrangente do desempenho de microcontroladores e processadores centrais, bem como de seus compiladores C. Como você pode ver, o processador S1 não é um nem o outro. No entanto, pretende-se executar um código absolutamente arbitrário, ou seja, qualquer pessoa que possa estar executando no processador central. Portanto, o CoreMark é adequado para avaliar o desempenho do S1 não pior.
O CoreMark contém trabalho com listas vinculadas, matrizes, uma máquina de estado e cálculo de soma de
CRC . Em geral, a maior parte do código acaba sendo estritamente sequencial (que testa a força do
paralelismo multicelular de
hardware ) e com muitas ramificações, motivo pelo qual os recursos do compilador desempenham um papel significativo no desempenho final. O código compilado contém alguns parágrafos curtos e, apesar do aumento da velocidade de transição entre eles, a ramificação inclui o trabalho com memória, o que gostaríamos de evitar ao máximo.
Cartão de pontuação CoreMark:
| Multiclet R1 (compilador llvm) | Multiclet S1 (compilador llvm) | Elbrus-4C (R500 / E) | Texas Inst. AM5728 ARM Cortex-A15 | Baikal-t1 | Intel Core i7 7700K |
|---|
| Ano de fabricação | 2015 | 2019 | 2014 | 2018 | 2016 | 2017 |
| Frequência de clock, MHz | 100 | 1600 | 700 | 1500 | 1200 | 4500 |
| Pontuação geral do CoreMark | 59. | 18356 | 1214 | 15789 | 13142 | 182128 |
| Coremark / MHz | 0,59 | 11,47 | 5.05 | 10,53 | 10,95 | 40,47 |
O resultado de um multicell é 1147, ou 0,72 / MHz, que é maior que o de R1. Isso fala das vantagens do desenvolvimento de arquitetura multicelular no novo processador.
Wheatstone
Whetstone - um conjunto de testes para medir o desempenho do processador ao trabalhar com números de ponto flutuante. Aqui a situação é muito melhor: o código também é seqüencial, mas sem um grande número de ramificações e com boa simultaneidade interna.
O Whetstone consiste em muitos módulos, o que permite medir não apenas o resultado geral, mas também o desempenho em cada módulo específico:
- Elementos de matriz
- Matriz como parâmetro
- Saltos condicionais
- Aritmética de número inteiro
- Funções trigonométricas (tan, sin, cos)
- Chamadas de procedimento
- Referências de matriz
- Funções padrão (sqrt, exp, log)
Eles são divididos em categorias: os módulos 1, 2 e 6 medem o desempenho das operações de ponto flutuante (linhas MFLOPS1-3); módulos 5 e 8 - funções matemáticas (COS MOPS, EXP MOPS); módulos 4 e 7 - aritmética de números inteiros (FIXPT MOPS, IGUAL MOPS); módulo 3 - saltos condicionais (SE MOPS). Na tabela abaixo, a segunda linha do MWIPS é um indicador geral.
Ao contrário do CoreMark, o Whetstone será comparado em um núcleo ou, como no nosso caso, em uma multicélula. Como o número de núcleos é muito diferente em diferentes processadores, para a pureza do experimento, consideramos os indicadores por megahertz.
Cartão de pontuação da pedra de amolar:
| CPU | MultiClet R1 | MultiClet S1 | Core i7 4820K | ARM v8-A53 |
|---|
| Frequência, MHz | 100 | 1600 | 3900 | 1300 |
| MWIPS / MHz | 0,311 | 0,343 | 0,887 | 0,642 |
| MFLOPS1 / MHz | 0,157 | 0,156 | 0,341 | 0,268 |
| MFLOPS2 / MHz | 0,153 | 0,111 | 0,308 | 0,241 |
| MFLOPS3 / MHz | 0,029 | 0,124 | 0,167 | 0,239 |
| MOPS COS / MHz | 0,018 | 0,008 | 0,023 | 0,028 |
| MOPS EXP / MHz | 0,008 | 0,005 | 0,014 | 0,004 |
| FIXPT MOPS / MHz | 0,714 | 0,116 | 0,998 | 1.197 |
| SE MOPS / MHz | 0,081 | 0,196 | 1,504 | 1.436 |
| MOPS IGUAIS / MHz | 0,143 | 0,149 | 0,251 | 0,439 |
O Whetstone contém operações computacionais muito mais diretamente do que o CoreMark (o que é muito perceptível quando se olha o código abaixo), por isso é importante lembrar aqui: o número de ALUs de ponto flutuante é reduzido pela metade. No entanto, a velocidade de computação quase não foi afetada, em comparação com R1.
Alguns módulos se encaixam muito bem em uma arquitetura multicelular. Por exemplo, o módulo 2 conta muitos valores em um ciclo e, graças ao suporte total de números de ponto flutuante de precisão dupla, tanto pelo processador quanto pelo compilador, após a compilação, obtemos parágrafos grandes e bonitos que realmente revelam os recursos computacionais de uma arquitetura multicelular:
Parágrafo grande e bonito para 120 equipes pa: SR4 := loadu_q [#SP + 16] SR5 := loadu_q [#SP + 8] SR6 := loadu_l [#SP + 4] SR7 := loadu_l [#SP] setjf_l @0, @SR7 SR8 := add_l @SR6, 0x8 SR9 := add_l @SR6, 0x10 SR10 := add_l @SR6, 0x18 SR11 := loadu_q [@SR6] SR12 := loadu_q [@SR8] SR13 := loadu_q [@SR9] SR14 := loadu_q [@SR10] SR15 := add_d @SR11, @SR12 SR11 := add_d @SR15, @SR13 SR15 := sub_d @SR11, @SR14 SR11 := mul_d @SR15, @SR5 SR15 := add_d @SR12, @SR11 SR12 := sub_d @SR15, @SR13 SR15 := add_d @SR14, @SR12 SR12 := mul_d @SR15, @SR5 SR15 := sub_d @SR11, @SR12 SR16 := sub_d @SR12, @SR11 SR17 := add_d @SR11, @SR12 SR11 := add_d @SR13, @SR15 SR13 := add_d @SR14, @SR11 SR11 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR11 SR15 := add_d @SR17, @SR11 SR16 := add_d @SR14, @SR13 SR13 := div_d @SR16, @SR4 SR14 := sub_d @SR15, @SR13 SR15 := mul_d @SR14, @SR5 SR14 := add_d @SR12, @SR15 SR12 := sub_d @SR14, @SR11 SR14 := add_d @SR13, @SR12 SR12 := mul_d @SR14, @SR5 SR14 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR11, @SR14 SR11 := add_d @SR13, @SR15 SR14 := mul_d @SR11, @SR5 SR11 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR13, @SR11 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR4 := loadu_q @SR4 SR5 := loadu_q @SR5 SR6 := loadu_q @SR6 SR7 := loadu_q @SR7 SR15 := mul_d @SR13, @SR5 SR8 := loadu_q @SR8 SR9 := loadu_q @SR9 SR10 := loadu_q @SR10 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR17 SR14 := mul_d @SR13, @SR5 SR5 := add_d @SR16, @SR14 SR13 := add_d @SR11, @SR5 SR5 := div_d @SR13, @SR4 wr_q @SR15, @SR6 wr_q @SR12, @SR8 wr_q @SR14, @SR9 wr_q @SR5, @SR10 complete
popcnt
Para refletir as características da própria arquitetura (independentemente do compilador), mediremos algo escrito no assembler, levando em consideração todos os recursos da arquitetura. Por exemplo, contando os bits da unidade em um número de 512 bits (popcnt). Por óbvio, pegaremos os resultados de uma multicélula, para que possam ser comparados com R1.
Tabela de comparação, o número de ciclos de clock por ciclo de cálculo de 32 bits:
| Algoritmo | Multiclet r1 | Multiclet S1 (um multicell) |
|---|
| Bithacks | 5.0 | 2.625 |
Novas instruções vetoriais atualizadas foram usadas aqui, o que nos permitiu reduzir pela metade o número de instruções em comparação com o mesmo algoritmo implementado no assembler R1. A velocidade do trabalho, respectivamente, aumentou quase duas vezes.
popcnt bithacks: b0 := patch_q 0x1, 0x1 v0 := loadu_q [v] v1 := loadu_q [v+8] v2 := loadu_q [v+16] v3 := loadu_q [v+24] v4 := loadu_q [v+32] v5 := loadu_q [v+40] v6 := loadu_q [v+48] v7 := loadu_q [v+56] b1 := patch_q 0x55555555, 0x55555555 i00 := slr_pl @v0, @b0 i01 := slr_pl @v1, @b0 i02 := slr_pl @v2, @b0 i03 := slr_pl @v3, @b0 i04 := slr_pl @v4, @b0 i05 := slr_pl @v5, @b0 i06 := slr_pl @v6, @b0 i07 := slr_pl @v7, @b0 b2 := patch_q 0x33333333, 0x33333333 i10 := and_q @i00, @b1 i11 := and_q @i01, @b1 i12 := and_q @i02, @b1 i13 := and_q @i03, @b1 i14 := and_q @i04, @b1 i15 := and_q @i05, @b1 i16 := and_q @i06, @b1 i17 := and_q @i07, @b1 b3 := patch_q 0x2, 0x2 i20 := sub_pl @v0, @i10 i21 := sub_pl @v1, @i11 i22 := sub_pl @v2, @i12 i23 := sub_pl @v3, @i13 i24 := sub_pl @v4, @i14 i25 := sub_pl @v5, @i15 i26 := sub_pl @v6, @i16 i27 := sub_pl @v7, @i17 i30 := and_q @i20, @b2 i31 := and_q @i21, @b2 i32 := and_q @i22, @b2 i33 := and_q @i23, @b2 i34 := and_q @i24, @b2 i35 := and_q @i25, @b2 i36 := and_q @i26, @b2 i37 := and_q @i27, @b2 i40 := slr_pl @i20, @b3 i41 := slr_pl @i21, @b3 i42 := slr_pl @i22, @b3 i43 := slr_pl @i23, @b3 i44 := slr_pl @i24, @b3 i45 := slr_pl @i25, @b3 i46 := slr_pl @i26, @b3 i47 := slr_pl @i27, @b3 b4 := patch_q 0x4, 0x4 i50 := and_q @i40, @b2 i51 := and_q @i41, @b2 i52 := and_q @i42, @b2 i53 := and_q @i43, @b2 i54 := and_q @i44, @b2 i55 := and_q @i45, @b2 i56 := and_q @i46, @b2 i57 := and_q @i47, @b2 i60 := add_pl @i50, @i30 i61 := add_pl @i51, @i31 i62 := add_pl @i52, @i32 i63 := add_pl @i53, @i33 i64 := add_pl @i54, @i34 i65 := add_pl @i55, @i35 i66 := add_pl @i56, @i36 i67 := add_pl @i57, @i37 b5 := patch_q 0xf0f0f0f, 0xf0f0f0f i70 := slr_pl @i60, @b4 i71 := slr_pl @i61, @b4 i72 := slr_pl @i62, @b4 i73 := slr_pl @i63, @b4 i74 := slr_pl @i64, @b4 i75 := slr_pl @i65, @b4 i76 := slr_pl @i66, @b4 i77 := slr_pl @i67, @b4 b6 := patch_q 0x1010101, 0x1010101 i80 := add_pl @i70, @i60 i81 := add_pl @i71, @i61 i82 := add_pl @i72, @i62 i83 := add_pl @i73, @i63 i84 := add_pl @i74, @i64 i85 := add_pl @i75, @i65 i86 := add_pl @i76, @i66 i87 := add_pl @i77, @i67 b7 := patch_q 0x18, 0x18 i90 := and_q @i80, @b5 i91 := and_q @i81, @b5 i92 := and_q @i82, @b5 i93 := and_q @i83, @b5 i94 := and_q @i84, @b5 i95 := and_q @i85, @b5 i96 := and_q @i86, @b5 i97 := and_q @i87, @b5 iA0 := mul_pl @i90, @b6 iA1 := mul_pl @i91, @b6 iA2 := mul_pl @i92, @b6 iA3 := mul_pl @i93, @b6 iA4 := mul_pl @i94, @b6 iA5 := mul_pl @i95, @b6 iA6 := mul_pl @i96, @b6 iA7 := mul_pl @i97, @b6 iB0 := slr_pl @iA0, @b7 iB1 := slr_pl @iA1, @b7 iB2 := slr_pl @iA2, @b7 iB3 := slr_pl @iA3, @b7 iB4 := slr_pl @iA4, @b7 iB5 := slr_pl @iA5, @b7 iB6 := slr_pl @iA6, @b7 iB7 := slr_pl @iA7, @b7 wr_q @iB0, c wr_q @iB1, c+8 wr_q @iB2, c+16 wr_q @iB3, c+24 wr_q @iB4, c+32 wr_q @iB5, c+40 wr_q @iB6, c+48 wr_q @iB7, c+56 complete
Ethereum
Os benchmarks são, é claro, bons, mas temos uma tarefa específica: criar um acelerador de computação, e seria bom saber como ele lida com tarefas reais. As criptomoedas modernas são as mais adequadas para essa verificação, porque os algoritmos de mineração são executados em muitos dispositivos diferentes e, portanto, podem servir como referência para comparação. Começamos com o Ethereum e o algoritmo Ethash, que é executado diretamente no dispositivo de mineração.
A escolha do Ethereum deveu-se às seguintes considerações. Como você sabe, algoritmos como o Bitcoin são implementados com muita eficiência por chips ASIC especializados, de modo que o uso de processadores ou placas de vídeo para minerar o Bitcoin e seus clones se torna economicamente desvantajoso devido ao baixo desempenho e alto consumo de energia. A comunidade de mineradores, na tentativa de fugir dessa situação, está desenvolvendo criptomoedas em outros princípios algorítmicos, concentrando-se no desenvolvimento de algoritmos que usam processadores de uso geral ou placas de vídeo para mineração. É provável que esta tendência continue no futuro. Ethereum é a criptomoeda mais famosa com base nessa abordagem. A principal ferramenta para mineração do Ethereum são as placas de vídeo, que em termos de eficiência (hashrate / TDP) estão significativamente (várias vezes) à frente dos processadores de uso geral.
Ethash é um algoritmo chamado de
limite de memória , ou seja, seu tempo de cálculo é limitado principalmente pela quantidade e velocidade da memória, e não pela velocidade dos próprios cálculos. Agora, para a mineração Ethereum, as placas de vídeo são as mais adequadas, mas sua capacidade de executar muitas operações simultaneamente não ajuda muito, e ainda permanecem na velocidade da RAM, o que é claramente demonstrado
neste artigo . A partir daí, você pode tirar uma foto ilustrando a operação do algoritmo para explicar por que isso acontece.
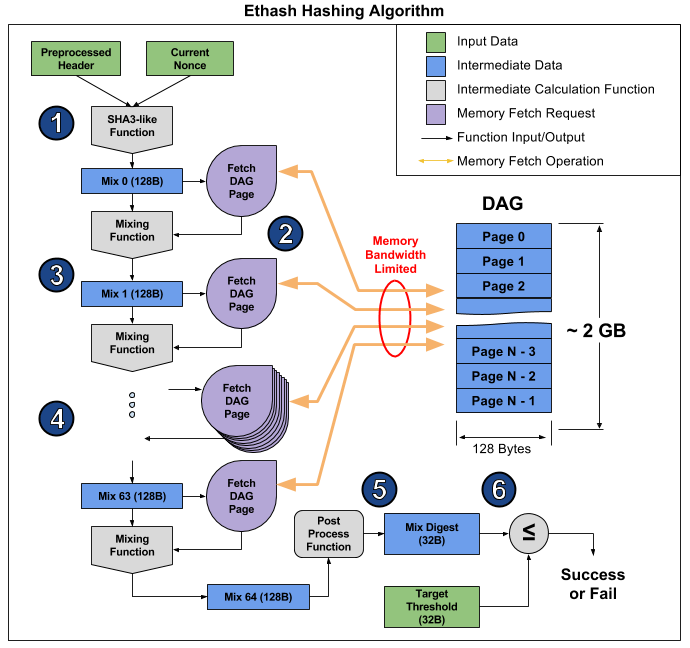
O artigo divide o algoritmo em 6 pontos, mas é possível distinguir três estágios para uma obviedade ainda maior:
- Início: SHA-3 (512) para calcular o Mix 0 original de 128 bytes (ponto 1)
- Recálculo de 64 vezes da matriz Mix, lendo os próximos 128 bytes e misturando-os com os anteriores através da função de mixagem, para um total de 8 kilobytes (parágrafos 2-4)
- Finalização e verificação do resultado
A leitura aleatória de 128 bytes da RAM leva muito mais tempo do que parece. Se você usar a placa de vídeo MSI RX 470, que possui 2048 dispositivos de computação e uma largura de banda de memória máxima de 211,2 GB / s, para equipar cada dispositivo, você precisa de 1 / (211,2 GB / (128 b * 2048)) = 1241 ns ou cerca de 1496 ciclos em uma determinada frequência. Dado o tamanho da função de mixagem, podemos assumir que leva várias vezes mais tempo para ler a memória de uma placa de vídeo do que para recalcular as informações recebidas. Como resultado, o estágio 2 do algoritmo leva muito tempo, muito mais do que os estágios 1 e 3, que no final têm pouco efeito no desempenho, apesar de conterem mais cálculos (principalmente no SHA-3). Você pode ver o hashrate desta placa de vídeo: 26.375 megachashes / s teóricos (limitado apenas pela largura de banda da memória) versus 24 megachehes / s reais, ou seja, os estágios 1 e 3 levam apenas 10% do tempo.
No S1, todos os 16 multicells podem funcionar em paralelo e em código diferente. Além disso, a RAM de canal duplo será instalada, ao longo de um canal para 8 multicells. No estágio 2 do algoritmo Ethash, nosso plano é o seguinte: uma multicélula lê 128 bytes da memória e começa a recontá-los, depois a próxima lê a memória e reconta, e assim por diante até o dia 8, ou seja, uma multicélula, após ler 128 bytes de memória, possui 7 * [tempo de leitura de 128 bytes] para recalcular a matriz. Supõe-se que essa leitura levará 16 ciclos, ou seja, 112 medidas são dadas para recontagem. O cálculo da função de mixagem leva aproximadamente o mesmo ciclo de clock, portanto, o S1 está próximo da proporção ideal de largura de banda da memória e desempenho do processador. Como o tempo não é desperdiçado no segundo estágio, as partes restantes do algoritmo devem ser otimizadas o máximo possível, pois elas realmente afetam o desempenho.
Para avaliar a velocidade de computação SHA-3 (Keccak), um programa C foi desenvolvido e testado, com base no qual sua versão ideal no assembler está sendo criada. A programação de avaliação mostra que uma multicélula executa o cálculo de SHA-3 (Keccak) em 1550 ciclos de clock. Portanto, o tempo total para calcular um hash por um multicelular será 1550 + 64 * (16 + 112) = 9742 ciclos. Com uma frequência de 1,6 GHz e 16 multicélulas paralelas, a taxa de hash do processador será de 2,6 MHash / s.| Acelerador | MultiClet S1 | NVIDIA GeForce GTX 980 Ti | Radeon RX 470 | Radeon RX Vega 64 | NVIDIA GeForce GTX 1060 | NVIDIA GeForce GTX 1080 Ti |
|---|
| Preço | | $ 650 | $ 180 | $ 500 | $ 300 | $ 700 |
| Taxa de hash | 2,6 MHash / s | 21,6 MHash / s | 25,8 MHash / s | 43,5 MHash / s | 25 MHash / s | 55 MHash / s |
| TDP | 6 W | 250 W | 120 W | 295 W | 120 W | 250 W |
| Hashrate / TDP | 0,43 | 0,09 | 0,22 | 0,15 | 0,22 | 0,21 |
| Tecnologia de processo | 28 nm | 28 nm | 14 nm | 14 nm | 16 nm | 16 nm |
Ao usar o MultiClet S1 como uma ferramenta de mineração, 20 ou mais processadores podem realmente ser instalados nas placas. Nesse caso, o hashrate de uma placa desse tipo será igual ou superior ao hashrates das placas de vídeo existentes, enquanto o consumo de energia de uma placa com S1 será metade, mesmo que o de placas de vídeo com padrões topográficos de 16 e 14 nm.Concluindo, devo dizer que a principal tarefa agora é a fabricação de uma placa multiprocessadora para um minerador de criptomoeda multicelular e um supercomputador. A competitividade está planejada para ser alcançada devido ao pequeno consumo de energia e arquitetura, o que é adequado para computação arbitrária.O processador ainda está em desenvolvimento, mas você já pode iniciar a programação em linguagem assembly, bem como avaliar a versão atual do compilador. Já existe um SDK mínimo contendo montador, vinculador, compilador e modelo funcional, no qual você pode iniciar e testar seus programas.