
Era uma vez, quando o céu estava azul, a grama era mais verde e os dinossauros vagavam pela Terra ... Não, esqueça os dinossauros. Bem, em geral, era uma vez a idéia de distrair-se da programação da Web padrão e fazer algo mais louco. Poderia, é claro, ser qualquer coisa, mas a escolha recaiu sobre escrever seu próprio intérprete. O que posso dizer ...
Nunca escreva suas próprias linguagens de programação . Mas eu tenho alguma experiência com tudo isso, então decidi compartilhá-la. Vamos começar com o próprio fundamento - o lexer.
Prefácio
Antes de começar a entender que tipo de animal é "lexer", vale a pena descobrir do que os YaPs são feitos.
No mundo moderno, cada compilador / intérprete / transpilador / qualquer outra coisa do tipo (vamos chamar de "compilador" adicional, sem distinção entre tipos) é dividido em duas partes. Na terminologia dos tios inteligentes, essas peças são chamadas de "front-end" e "back-end". Não, não é isso que, ao trabalhar com a web, o que costumávamos chamar e a frente não está escrita em JS com HTML. Embora ... Ok.
A tarefa do primeiro frontend é pegar o
texto e transformá-lo em um
AST (árvore de sintaxe abstrata), verificando a sintaxe (e às vezes a semântica) no caminho. A tarefa do segundo back-end é fazer com que tudo funcione. Se o código for montado dentro do intérprete, o AST criará um conjunto de instruções para o processador virtual (máquina virtual), se o compilador, o conjunto de instruções para o processador real. Na vida, tudo é bem mais complicado e pode não ser implementado dessa maneira. Por exemplo, no caso do compilador GCC, tudo está confuso, mas Clang já é mais canônico, o LLVM é um representante típico do "back-end" para compiladores.
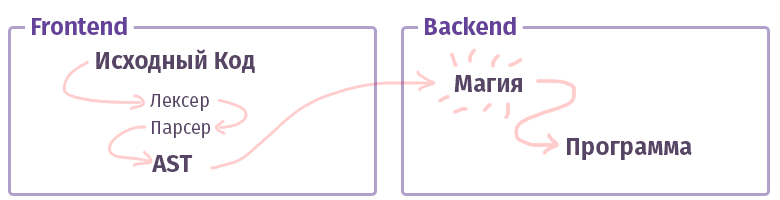
Agora vamos conhecer uma peça chamada frontend.
Análise lexical
A tarefa do lexer e o estágio da análise lexical é obter muitas e muitas letras como entrada e agrupá-las em algumas categorias - "tokens". Portanto, a análise lexical também é chamada de "tokenização". Esse é o primeiro estágio do processamento de texto que todo compilador existente produz.
Algo assim:
$tokens = ['class', '\w+', '}', '{']; var_dump(lex('class Example {}', $tokens));
A propósito, aqui já escrevemos várias ferramentas para facilitar a vida. As mesmas funções
prévias que costumávamos usar para analisar texto são bastante
capazes dessa tarefa. No entanto, existem ferramentas mais convenientes para esse assunto:
- Phlexy , escrito por Nikita Popov.
- Hoa é um kit de ferramentas composto por Lexer + Parser + Grammar.
- Port Yacc , escrito por Anthony Ferrara, que também é um kit de ferramentas complexo, e no qual o conhecido analisador Popov PHP é escrito, aplicável em ferramentas que usam análise de código.
- Railt Lexer minha implementação para PHP 7.1+
- Parle é uma extensão para PHP que permite um conjunto limitado de expressões PCRE (sem visuais e outras construções de sintaxe).
- E, finalmente, a função php padrão token_get_all , destinada diretamente à análise lexical do PHP.
Bem, está claro que existem muitos dispositivos que podem dividir o texto por tokens; talvez eu até tenha esquecido algo, como o
Doctrine lexer. Mas o que vem depois?
Tipos de Lexers
E como sempre, nem tudo é tão simples quanto parecia. Existem pelo menos duas categorias diferentes de lexers. Existe a opção usual, bastante trivial, para a qual você aplica as regras, e ela já divide tudo em tokens. A sua configuração não é muito diferente do exemplo mostrado por mim acima. No entanto, há outra opção chamada
multistate . Tais lexers são um pouco mais difíceis de entender, portanto, quero falar um pouco mais sobre eles.
A tarefa de um lexer de vários estados é exibir vários tokens, dependendo do estado anterior. Bem, por exemplo, no PHP, esses estados "transitórios" são formados usando as Tags <? Php +?> Tags, linhas internas, comentários e construções
HEREDOC /
NOWDOC .
Lembra do exemplo anterior com 4 tokens acima? Vamos modificá-lo um pouco para entender quais são esses estados:
class Example {
Nesse caso, se tivermos o lexer mais simples sem os amplos recursos do PCRE, obteremos o seguinte conjunto de tokens:
var_dump(lex(...));
Como você pode ver, recebemos um batente completamente banal nos elementos 3-5: O comentário foi recebido inesperadamente e foi dividido em tokens, embora devesse ter sido considerado como um todo.
Obviamente, com o PCRE funcional, esse token pode ser extraído com a ajuda de uma simples regularidade "
// [^ \ n] * \ n ", mas se não for? Ou queremos cortá-lo com as mãos? Em resumo, no caso de um lexer de vários estados - podemos dizer que todos os tokens devem estar no grupo
No1 , assim que o token "
// " for encontrado, uma transição para o grupo
No2 deverá ocorrer. E dentro do segundo grupo, a transição reversa, se o token "
\ n " for encontrado - a transição de volta para o primeiro grupo.
Algo assim:
$tokens = [ 'group-1' => [ 'class', '\w+', '{', '}', '//' => 'group-2'
Acho que agora está ficando mais claro como o HEREDOC é analisado, porque mesmo com todo o poder do PCRE, escrever um regular para este caso é extremamente problemático, já que essa sintaxe do HEREDOC suporta interpolação variável. Apenas tente analisar algo parecido com a função
token_get_all interna (note> 12 token):
<?php $example = 42; $a = <<<EOL Your answer is $example !!! EOL; var_dump(token_get_all(file_get_contents(__FILE__)));
Bem, parece que estamos prontos para começar a praticar.
Prática
Vamos lembrar o que temos em PHP para essas coisas? Bem, é claro, preg_match! Ok, desça. O algoritmo baseado em preg_match é implementado no
Hoa e
nesta implementação do Phelxy . Sua tarefa é bastante simples:
- Temos em mãos o texto fonte e uma série de regulares.
- Combinamos até encontrar algo adequado.
- Assim que encontrar uma peça, corte-a no texto e faça a correspondência.
Em forma de código, será algo parecido com isto:
Folha de código <?php class SimpleLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[$name] = \sprintf('/\G%s/isSum', $definition); } } public function lex(string $sources): iterable { [$offset, $length] = [0, \strlen($sources)]; while ($offset < $length) { [$name, $token] = $this->next($sources, $offset); yield $name => $token; $offset += \strlen($token); } } private function next(string $sources, int $offset): array { foreach ($this->tokens as $name => $pcre) { \preg_match($pcre, $sources, $matches, 0, $offset); $token = \reset($matches); if (\count($matches) && \strpos($sources, $token, $offset) === $offset) { return [$name, $token]; } } throw new \RuntimeException('Unrecognized token at offset ' . $offset); } }
Usando uma folha de código $lexer = new SimpleLexer([ 'T_CLASS' => 'class', 'T_CONST' => '\w+', 'T_BRACE_OPEN' => '{', 'T_BRACE_CLOSE' => '}', 'T_WHITESPACE' => '\s+', ]); echo \sprintf('| %-10s | %-20s |', 'VALUE', 'NAME') . "\n"; foreach ($lexer->lex('class Example {}') as $name => $token) { echo \sprintf('| %-10s | %-20s |', '"' . \trim($token, "\n") . '"', $name) . "\n"; }
Essa abordagem é bastante trivial e permite que alguns toques no teclado modifiquem o lexer na região do próximo método (), adicionando uma transição entre estados e transformando essa peça de masturbação em um lexer primitivo de vários estados. Na área
$ this-> tokens, basta adicionar algo como
$ this-> tokens [$ this-> state] .
No entanto, além do próprio primitivismo, há outra desvantagem, não fatal, como pode acontecer, mas ainda assim ... Essa implementação é incrivelmente lenta. No i7 7600k, cujo dono por acaso eu sou por acaso - um algoritmo semelhante processa cerca de 400 tokens por segundo e com um aumento em suas variações (ou seja, as definições que passamos ao construtor) - pode diminuir a velocidade da mudança de presidentes na Rússia ... desculpe Eu queria dizer, é claro, que funcionaria
muito lentamente .
Ok, o que podemos fazer? Para iniciantes, você pode entender o que está acontecendo de errado. O fato é que toda vez que chamamos
preg_match dentro da natureza da linguagem, um compilador com seu JIT chamado PCRE aumenta (e no PHP 7.3, o PCRE2 já está). Cada vez que ele analisa os regulares e coleta um analisador para eles, com o qual analisamos o texto para criar fichas. Parece um pouco estranho e tautológico. Mas, resumindo, cada token requer compilação de 1 a N regulares, onde N é o número de definições desses tokens. Ao mesmo tempo, vale a pena notar que mesmo o sinalizador "
S " aplicado e a otimização usando "
\ G " no construtor, onde expressões regulares para tokens são geradas, não ajudam.
Existe apenas uma maneira de sair dessa situação: você precisa analisar todo esse texto de uma só vez, ou seja, executando apenas uma função
preg_match . Resta resolver dois problemas:
- Como indicar que o resultado da expressão regular N1 corresponde ao token N2? I.e. como indicar que " \ w + ", por exemplo, é T_CONST .
- Como determinar a sequência de tokens como resultado. Como você sabe, o resultado de preg_match ou preg_match_all conterá tudo misturado. E mesmo com a ajuda de bandeiras passadas como o quarto argumento, a situação não mudará.
Aqui você pode fazer uma pausa e pensar um pouco. Bem ou não.
A solução para o primeiro problema é
denominada grupos PCRE , também chamados de "sub-máscaras". Usando as regras: "
(? <T_WHITESPACE> \ s + | <T_WORD> \ w + | ...) ", você pode obter todos os tokens de uma só vez, comparando-os com seus nomes. Como resultado da partida, uma matriz associativa será formada, consistindo nos pares "
[TOKEN_NAME => TOKEN_VALUE] ".
O segundo é um pouco mais complicado. Mas aqui você pode aplicar um truque tático e usar a função
preg_replace_callback . Sua peculiaridade é que o anonimato passado como o segundo argumento será chamado estritamente sequencialmente para cada token, do primeiro ao último.
Para não definhar - a implementação é a seguinte:
Outra aba de código class PregReplaceLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[] = \sprintf('(?<%s>%s)', $name, $definition); } } public function lex(string $sources): iterable { $result = []; \preg_replace_callback($this->compilePcre(), function (array $matches) use (&$result) { foreach (\array_reverse($matches) as $name => $value) { if (\is_string($name) && $value !== '') { $result[] = [$name, $value]; break; } } }, $sources); foreach ($result as [$name, $value]) { yield $name => $value; } } private function compilePcre(): string { return \sprintf('/\G(?:%s)/isSum', \implode('|', $this->tokens)); } }
E seu uso não é diferente da versão anterior. Ao mesmo tempo, a velocidade do trabalho aumenta de
400 para
57.000 tokens por segundo. É esse algoritmo que apliquei
na minha implementação , assumindo a reescrita do código-fonte Hoa. A propósito, se você usa Parle, pode espremer até
600.000 tokens por segundo. E a imagem geral se parece com isso (com o XDebug ativado no PHP 7.1, então os números são mais baixos, mas a proporção pode ser representada aproximadamente).
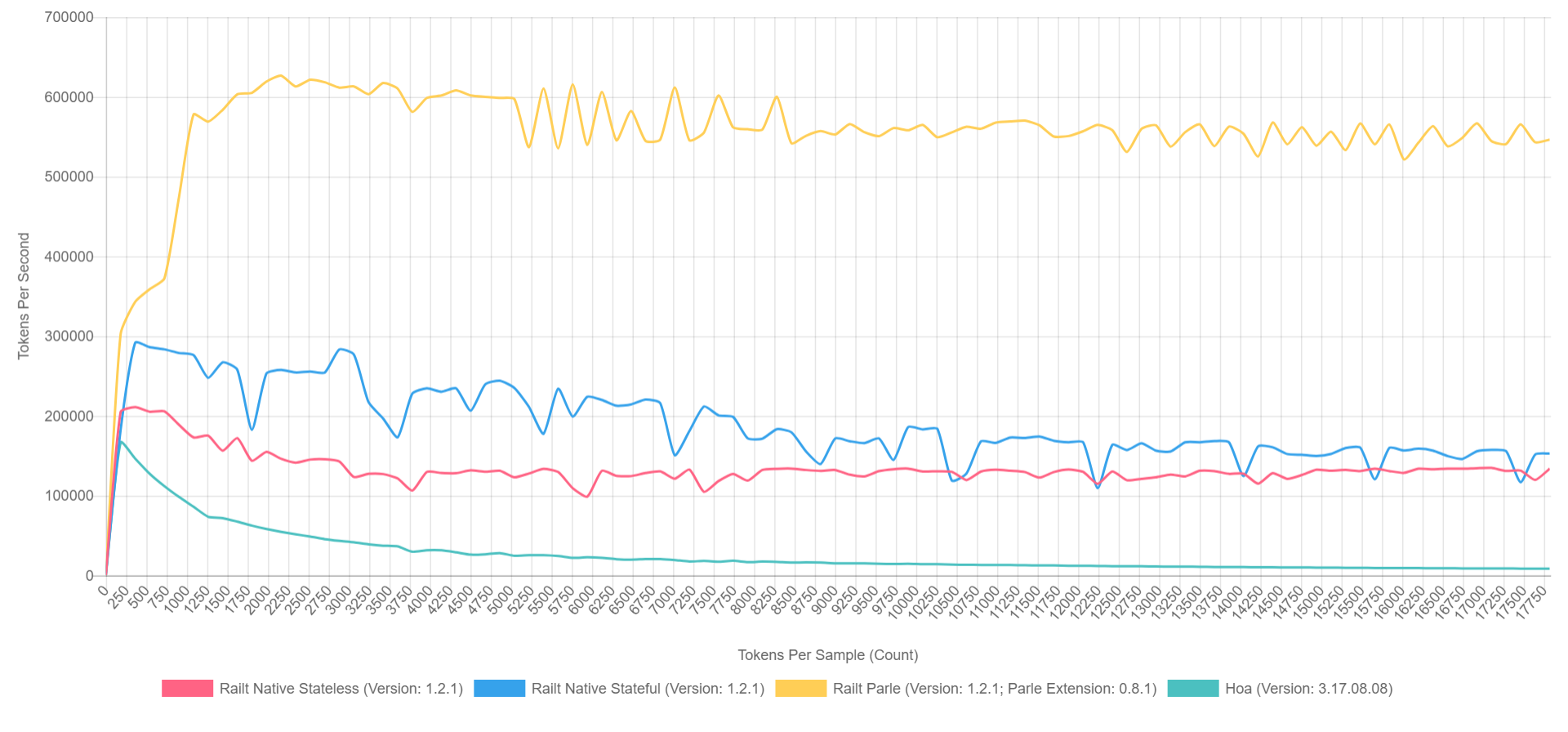
- Amarelo é a extensão nativa de Parle.
- Azul - implementação através de preg_replace_callback com pré-montado regular.
- Vermelho - tudo a mesma coisa, mas com a regularidade gerada durante a chamada para preg_replace_callback .
- Verde - implementação através de preg_match .
Porque
Bem, tudo isso, é claro, é maravilhoso, mas os impacientes estão ansiosos para fazer a pergunta: "Quem precisa disso?" No mundo abstrato do PHP, onde o princípio de "fig-fig-e-site-ready" domina - tais bibliotecas não são necessárias, seremos honestos. Mas se falamos sobre o ecossistema como um todo, podemos lembrar as bibliotecas notórias como
symfony / yaml ou
Doctrine . As anotações no Symfony são a mesma sub-linguagem no PHP, exigindo análise lexical e sintática separada. Além disso, existem transpilers CoffeeScript, Less e Scss / Sass ainda menos conhecidos, escritos em PHP. Bem, ou
Yay e
pré-processo com base nisso. Eu nem vou mencionar ferramentas de análise de código como phpmd ou phpcs. E geradores de documentação como phpDocumentnor ou Sami são bastante triviais. Cada um desses projetos, em um grau ou outro, utiliza análise lexical no primeiro estágio da análise de texto / código.
Esta não é uma lista completa de projetos e, talvez, espero que minha história o ajude a descobrir algo novo e a reabastecê-lo.
Posfácio
Olhando para o futuro, se houver alguém interessado no assunto de analisadores e compiladores, existem alguns relatórios interessantes sobre esse tópico, em particular dos caras do JetBrains:
Ainda assim, é claro, a maioria das performances de Andrei
Breslav (
abreslav ), que pode ser encontrada na imensidão do YouTube - eu aconselho você a assistir.
Bem, para os fãs de ficção,
existe um recurso que foi pessoalmente extremamente útil para mim.
Post post scriptum. Se você está em algum lugar selado na vastidão desse épico, pode informar com segurança o autor de qualquer forma conveniente para você.
Como um bônus, eu gostaria de dar
um exemplo de um simples lexer PHP , parece que não é tão assustador agora, e agora ainda está claro o que faz, certo? Embora a quem eu esteja enganando, os olhos sangram dos frequentadores. =)
Obrigada