O primeiro serviço no Nomad I foi lançado em setembro de 2016. No momento, eu o uso como programador e apoio como administrador de dois clusters Nomad - um "lar" para meus projetos pessoais (6 máquinas micro-virtuais no Hetzner Cloud e ArubaCloud em 5 data centers diferentes na Europa) e o segundo em funcionamento (cerca de 40 servidores virtuais e físicos privados) em dois data centers).
Nos últimos tempos, muita experiência foi acumulada com o ambiente Nomad. No artigo, descreverei os problemas encontrados pelo Nomad e como lidar com eles.

Yamal nomad cria instância de entrega contínua do seu software © National Geographic Russia
1. O número de nós do servidor por data center
Solução: um nó do servidor é suficiente para um data center.
A documentação não indica explicitamente quantos nós do servidor são necessários em um datacenter. É indicado apenas que são necessários 3-5 nós por região, o que é lógico para o consenso do protocolo de jangada.
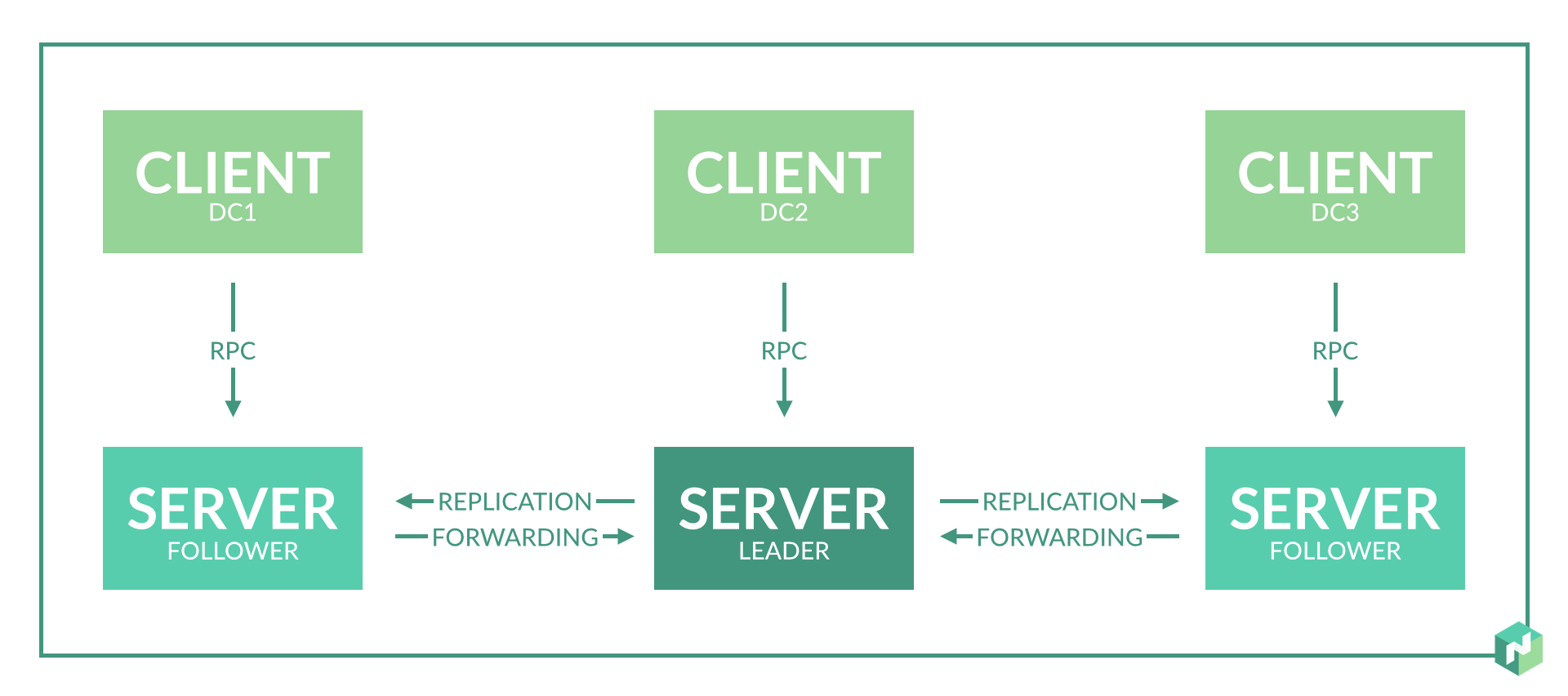
No começo, planejei 2-3 nós de servidor em cada data center para fornecer redundância.
Após o uso, descobriu-se:
- Isso simplesmente não é necessário, pois, no caso de uma falha no nó no datacenter, a função do nó do servidor para os agentes nesse datacenter será desempenhada por outros nós na região.
- Acontece ainda pior se o problema 8 não for resolvido. Quando o assistente é reeleito, podem ocorrer inconsistências e o Nomad reiniciará parte dos serviços.
2. Recursos do servidor para o nó do servidor
Solução: uma pequena máquina virtual é suficiente para o nó do servidor. No mesmo servidor, é permitido executar outros serviços que não consomem muitos recursos.
O consumo de memória do daemon Nomad depende do número de tarefas em execução. Consumo de CPU - com base no número de tarefas e no número de servidores / agentes na região (não linear).
No nosso caso: para 300 tarefas em execução, o consumo de memória é de cerca de 500 MB para o nó principal atual.
Em um cluster em funcionamento, uma máquina virtual para um nó do servidor: 4 CPU, 6 GB RAM.
Lançamento adicional: Consul, Etcd, Vault.
3. Consenso sobre a falta de data centers
Solução: criamos três data centers virtuais e três nós de servidor para dois data centers físicos.
O trabalho do Nomad na região é baseado no protocolo de jangada. Para uma operação correta, você precisa de pelo menos três nós de servidor localizados em diferentes datacenters. Isso permitirá a operação correta com uma perda completa da conectividade de rede com um dos data centers.
Mas temos apenas dois data centers. Assumimos um compromisso: selecionamos um data center em que confiamos mais e criamos um nó de servidor adicional. Fazemos isso introduzindo um data center virtual adicional, que estará fisicamente localizado no mesmo data center (consulte o parágrafo 2 do problema 1).
Solução alternativa: dividimos os data centers em regiões separadas.
Como resultado, os data centers funcionam de forma independente e o consenso é necessário apenas dentro de um data center. Dentro de um datacenter, nesse caso, é melhor criar três nós de servidor implementando três datacenters virtuais em um físico.
Essa opção é menos conveniente para a distribuição de tarefas, mas oferece uma garantia de 100% da independência dos serviços em caso de problemas de rede entre os data centers.
4. "Servidor" e "agente" no mesmo servidor
Solução: válida se você tiver um número limitado de servidores.
A documentação do Nomad diz que fazer isso é indesejável. Mas se você não tiver a oportunidade de alocar máquinas virtuais separadas para nós do servidor, poderá colocar os nós do servidor e do agente no mesmo servidor.
Executar simultaneamente significa iniciar o daemon Nomad no modo cliente e no servidor.
O que isso ameaça? Com uma carga pesada na CPU deste servidor, o nó do servidor Nomad funcionará de maneira instável, perda de consenso e pulsações, é possível recarregar o serviço.
Para evitar isso, aumentamos os limites da descrição do problema nº 8.
5. Implementação de namespaces
Solução: talvez através da organização de um data center virtual.
Às vezes, você precisa executar parte dos serviços em servidores separados.
A solução é a primeira, simples, mas mais exigente em recursos. Dividimos todos os serviços em grupos de acordo com sua finalidade: frontend, backend, ... Adicione metatributos aos servidores, prescreva os atributos a serem executados para todos os serviços.
A segunda solução é simples. Adicionamos novos servidores, prescrevemos meta atributos para eles, prescrevemos esses atributos de inicialização para os serviços necessários, e todos os outros serviços prescrevem uma proibição de inicialização em servidores com esse atributo.
A terceira solução é complicada. Criamos um datacenter virtual: inicie o Consul para um novo datacenter, inicie o nó do servidor Nomad para esse datacenter, sem esquecer o número de nós do servidor para esta região. Agora você pode executar serviços individuais neste data center virtual dedicado.
6. Integração com o Vault
Solução: Evite as dependências circulares do Nomad <-> Vault.
O Vault lançado não deve ter nenhuma dependência do Nomad. O endereço do Vault registrado no Nomad deve, de preferência, apontar diretamente para o Vault, sem camadas de balanceadores (mas válidas). A reserva de cofre neste caso pode ser feita via DNS - Consul DNS ou externo.
Se os dados do Vault forem gravados nos arquivos de configuração do Nomad, o Nomad tentará acessar o Vault na inicialização. Se o acesso não tiver êxito, o Nomad se recusa a iniciar.
Cometi um erro com uma dependência cíclica há muito tempo, que uma vez destruiu completamente o cluster Nomad. O Vault foi iniciado corretamente, independentemente do Nomad, mas o Nomad examinou o endereço do Vault através dos balanceadores que estavam sendo executados no próprio Nomad. A reconfiguração e a reinicialização dos nós do servidor Nomad causaram uma reinicialização dos serviços do balanceador, o que levou a uma falha ao iniciar os próprios nós do servidor.
7. Lançando importantes serviços estaduais
Solução: válida, mas não.
É possível executar PostgreSQL, ClickHouse, Redis Cluster, RabbitMQ, MongoDB via Nomad?
Imagine que você tenha um conjunto de serviços importantes, cujo trabalho está vinculado à maioria dos outros serviços. Por exemplo, um banco de dados no PostgreSQL / ClickHouse. Ou armazenamento geral de curto prazo no Redis Cluster / MongoDB. Ou um barramento de dados no Redis Cluster / RabbitMQ.
Todos esses serviços de alguma forma implementam um esquema tolerante a falhas: Stolon / Patroni for PostgreSQL, sua própria implementação de jangada no Redis Cluster, sua própria implementação de cluster no RabbitMQ, MongoDB, ClickHouse.
Sim, todos esses serviços podem ser iniciados pelo Nomad com referência a servidores específicos, mas por quê?
Plus - facilidade de lançamento, um único formato de script, como outros serviços. Não precisa se preocupar com scripts ansible / qualquer outra coisa.
Menos é um ponto adicional de falha, que não oferece nenhuma vantagem. Pessoalmente, abandonei completamente o cluster Nomad duas vezes por vários motivos: uma vez "em casa", uma vez trabalhando. Isso foi nos estágios iniciais da introdução do Nomad e devido à negligência.
Além disso, o Nomad começa a se comportar mal e reiniciar os serviços devido ao problema número 8. Mas, mesmo que esse problema seja resolvido, o perigo permanece.
8. A estabilização do trabalho e do serviço é reiniciada em uma rede instável
Solução: use as opções de ajuste de pulsação.
Por padrão, o Nomad é configurado para que qualquer problema de rede a curto prazo ou carga de CPU cause perda de consenso e reeleição do assistente ou marque o nó do agente como inacessível. E isso leva a reinicializações espontâneas de serviços e sua transferência para outros nós.
Estatísticas do cluster "inicial" antes de corrigir o problema: a vida útil máxima do contêiner antes de reiniciar é de aproximadamente 10 dias. Aqui, ainda é sobrecarregado executar o agente e o servidor em um servidor e colocá-lo em 5 centros de dados diferentes na Europa, o que implica uma grande carga na CPU e uma rede menos estável.
Estatísticas do cluster de trabalho antes de corrigir o problema: a vida útil máxima do contêiner antes de reiniciar é mais de 2 meses. Tudo aqui é relativamente bom por causa dos servidores separados para os nós do Nomad e da excelente rede entre os data centers.
Valores padrão
heartbeat_grace = "10s" min_heartbeat_ttl = "10s" max_heartbeats_per_second = 50.0
A julgar pelo código: nessa configuração, as pulsações são feitas a cada 10 segundos. Com a perda de duas pulsações, começa a reeleição do mestre ou a transferência de serviços do nó do agente. Configurações controversas, na minha opinião. Nós os editamos dependendo do aplicativo.
Se você possui todos os serviços em execução em várias instâncias e é distribuído pelos data centers, provavelmente não importa para você um longo período de determinação da inacessibilidade do servidor (cerca de 5 minutos, no exemplo abaixo) - tornamos menos frequente o intervalo de pulsação e um período mais longo de determinação da inacessibilidade. Este é um exemplo de configuração do meu cluster inicial:
heartbeat_grace = "300s" min_heartbeat_ttl = "30s" max_heartbeats_per_second = 10.0
Se você tiver boa conectividade de rede, servidores separados para nós do servidor e o período para determinar a inacessibilidade do servidor for importante (há algum serviço em execução em uma instância e é importante transferi-lo rapidamente), aumente o período para determinar a inacessibilidade (heartbeat_grace). Opcionalmente, você pode fazer mais pulsações (diminuindo min_heartbeat_ttl) - isso aumentará levemente a carga na CPU. Exemplo de configuração de cluster de trabalho:
heartbeat_grace = "60s" min_heartbeat_ttl = "10s" max_heartbeats_per_second = 50.0
Essas configurações corrigem completamente o problema.
9. Iniciando Tarefas Periódicas
Solução: Serviços periódicos nômades podem ser usados, mas o cron é mais conveniente para suporte.
Nomad tem a capacidade de iniciar o serviço periodicamente.
A única vantagem é a simplicidade dessa configuração.
O primeiro ponto negativo é que, se o serviço for iniciado com freqüência, ele irá desarrumar a lista de tarefas. Por exemplo, na inicialização a cada 5 minutos, 12 tarefas extras serão adicionadas à lista a cada hora, até que o GC Nomad seja acionado, o que excluirá as tarefas antigas.
O segundo menos - não está claro como configurar corretamente o monitoramento de um serviço desse tipo. Como entender que um serviço inicia, cumpre e faz seu trabalho até o fim?
Como resultado, vim para a implementação "cron" de tarefas periódicas:
- Pode ser um cron regular em um contêiner em execução constante. Cron executa periodicamente um determinado script. Uma verificação de integridade do script é facilmente adicionada a esse contêiner, que verifica qualquer sinalizador que crie um script em execução.
- Pode ser um contêiner em execução constante, com um serviço em execução constante. Um lançamento periódico já foi implementado dentro do serviço. Um script-healthcheck semelhante ou http-healthcheck pode ser facilmente adicionado a esse serviço, que verifica o status imediatamente por seu "interior".
No momento em que escrevo a maior parte do tempo no Go, respectivamente, prefiro a segunda opção com o http healthcheck - on Go e o lançamento periódico, e o http healthcheck'i é adicionado com algumas linhas de código.
10. Prestação de serviços redundantes
Solução: Não existe uma solução simples. Existem mais duas opções difíceis.
O esquema de provisionamento fornecido pelos desenvolvedores do Nomad é oferecer suporte ao número de serviços em execução. Você diz que o nômade "lança-me 5 instâncias do serviço" e ele as inicia em algum lugar por lá. Não há controle sobre a distribuição. Instâncias podem ser executadas no mesmo servidor.
Se o servidor travar, as instâncias serão transferidas para outros servidores. Enquanto as instâncias estão sendo transferidas, o serviço não funciona. Esta é uma opção ruim de provisão de reserva.
Fazemos certo:
- Distribuímos instâncias nos servidores através de distinct_hosts .
- Distribuímos instâncias entre data centers. Infelizmente, apenas criando uma cópia do script do formulário service1, service2 com o mesmo conteúdo, nomes diferentes e uma indicação do lançamento em diferentes data centers.
No Nomad 0.9, aparecerá uma funcionalidade que resolverá esse problema: será possível distribuir serviços em uma proporção percentual entre servidores e data centers.
11. Web UI Nomad
Solução: a interface do usuário embutida é terrível, o hashi-ui é bonito.
O cliente do console executa a maioria das funcionalidades necessárias, mas às vezes você deseja ver os gráficos, pressione os botões ...
Nomad tem uma interface de usuário integrada. Não é muito conveniente (ainda pior que o console).
A única alternativa que conheço é o hashi-ui .
De fato, agora eu pessoalmente preciso do cliente do console apenas para "execução nômade". E mesmo isso planeja transferir para a CI.
12. Suporte para excesso de assinaturas da memória
Solução: não.
Na versão atual do Nomad, você deve especificar um limite estrito de memória para o serviço. Se o limite for excedido, o serviço será eliminado pelo OOM Killer.
Excesso de assinatura é quando os limites de um serviço podem ser especificados "de e para". Alguns serviços exigem mais memória na inicialização do que durante a operação normal. Alguns serviços podem consumir mais memória do que o normal por um curto período de tempo.
A escolha de uma restrição estrita ou flexível é um tópico para discussão, mas, por exemplo, o Kubernetes permite que o programador faça uma escolha. Infelizmente, nas versões atuais do Nomad não existe essa possibilidade. Eu admito que aparecerá em versões futuras.
13. Limpando o Servidor dos Serviços Nomad
Solução:
sudo systemctl stop nomad mount | fgrep alloc | awk '{print $3}' | xargs -I QQ sudo umount QQ sudo rm -rf /var/lib/nomad sudo docker ps | grep -v '(-1|-2|...)' | fgrep -v IMAGE | awk '{print $1}' | xargs -I QQ sudo docker stop QQ sudo systemctl start nomad
Às vezes "algo dá errado". No servidor, ele mata o nó do agente e se recusa a iniciar. Ou o nó do agente para de responder. Ou o nó do agente "perde" serviços neste servidor.
Isso às vezes acontecia com versões mais antigas do Nomad, agora isso não acontece ou muito raramente.
O que, neste caso, é o mais fácil de fazer, dado que o servidor de drenagem não produzirá o resultado desejado? Limpamos o servidor manualmente:
- Pare o agente nômade.
- Faça um valor na montagem que cria.
- Exclua todos os dados do agente.
- Removemos todos os contêineres filtrando os contêineres de serviço (se houver).
- Começamos o agente.
14. Qual é a melhor maneira de implantar o Nomad?
Solução: é claro, através do Consul.
O Consul neste caso não é de forma alguma uma camada extra, mas um serviço que se encaixa organicamente na infraestrutura, que oferece mais vantagens do que desvantagens: DNS, armazenamento KV, pesquisa de serviços, monitoramento da disponibilidade do serviço, capacidade de trocar informações com segurança.
Além disso, ele se desenrola tão facilmente quanto o próprio Nomad.
15. Qual é o melhor - Nomad ou Kubernetes?
Solução: depende de ...
Anteriormente, às vezes eu pensava em iniciar uma migração para o Kubernetes - fiquei muito irritado com a reinicialização espontânea periódica dos serviços (consulte o problema número 8). Mas, depois de uma solução completa para o problema, posso dizer: Nomad combina comigo no momento.
Por outro lado: o Kubernetes também possui uma recarga semi-espontânea de serviços - quando o agendador do Kubernetes redistribui as instâncias, dependendo da carga. Isso não é muito legal, mas é provável que esteja configurado.
Vantagens do Nomad: a infraestrutura é muito fácil de implantar, scripts simples, boa documentação, suporte interno ao Consul / Vault, o que, por sua vez, fornece: uma solução simples para o problema do armazenamento de senhas, DNS embutido, verificações de segurança fáceis de configurar.
Prós de Kubernetes: Agora é um "padrão de fato". Boa documentação, muitas soluções prontas, com boa descrição e padronização do lançamento.
Infelizmente, não tenho a mesma grande experiência no Kubernetes para responder inequivocamente à pergunta - o que usar para o novo cluster. Depende das necessidades planejadas.
Se você tem muitos namespaces planejados (problema número 5) ou seus serviços específicos consomem muita memória no início, liberando-a (problema número 12) - definitivamente o Kubernetes, porque esses dois problemas no Nomad não são totalmente resolvidos ou inconvenientes.