No mundo do PHP, as ferramentas de migração da estrutura de banco de dados são bem conhecidas -
Doctrine ,
Phinx , do CakePHP, do
Laravel , do
Yii - e essa é a primeira coisa que vem à mente. Certamente há uma dúzia a mais. E a maioria deles trabalha com migrações - comandos para fazer alterações incrementais no esquema do banco de dados.
Não vou descrever por que isso ocorre, existem muitos posts sobre esse tópico no Habré. Por exemplo:
Além disso, o desenvolvimento da minha
experiência como equipe, com uma constante mudança na estrutura do banco de dados em diferentes ramos.
API bruta vs API PHP
Escrevemos migrações em SQL puro. Muitas ferramentas fornecem API PHP para escrever instruções traduzidas em código SQL. Agora eu não entendo por que isso é? Essa ferramenta sempre será limitada em suas capacidades. Eles não permitem escrever instruções específicas para um mecanismo específico; você ainda precisa usar SQL puro. Não estou falando de escrever procedimentos e pontos de vista.
Alguém reclamou que ele não queria aprender a sintaxe dos comandos ALTER ... Bem, eu não sei, abri o diretório e escrevi exemplos da montanha, especialmente em um projeto grande.
As migrações de dados (INSERT, UPDATE) também são sempre escritas em SQL. Porque você nunca pode confiar na versão atual do ORM e Models. Em uma revisão eles estão, na outra não mais.
Por exemplo:
Rollback Country::delete()->where(....)->execute();
Deseja reverter o estado do banco de dados. E essa classe PHP não está mais no repositório. Você precisa procurar o último commit onde ele estava e reverter a partir daí. Brrr ...
Portanto, o SQL é simples e confiável:
Transações em DDL
Com a transição para o PostgreSQL, eu esqueci as migrações interrompidas como um pesadelo - a migração caiu no meio, algo enrolou, algo não estava lá, sente e edite as canetas ... Isso nos forçou a escrever comandos de linha única atômicos e executá-los um de cada vez. Tudo é simples com as transações: se algo quebra - tudo volta (bem, quase tudo))). Apenas conserte e reinicie. A montagem automática funciona com um estrondo; se algo cair, ele rapidamente se ajusta e sobe.
Vistas (vistas) e funções
O problema aqui é que eles não podem ser atualizados incrementalmente, como ALTER nas tabelas. Precisa de DROP e CREATE. I.e. no diferencial (texto da migração) não está nada claro o que mudou no final. Especialmente quando a lógica é distorcida, é bastante inconveniente. Por exemplo:
O que mudou aqui?
Paramos com o fato de que ao lado das migrações há um pai, onde a visão e o código do procedimento atuais são armazenados, que são atualizados e copiados na migração de reversão.
E agora o diff se torna como:

De volta ao Avito, criamos uma solução interessante para
versionar o código de procedimento armazenado.Em geral, esse caso levanta um bom problema - como examinar o histórico de alterações em um objeto específico da estrutura do banco de dados. Para cada tabela, quero ver o histórico de alterações relacionadas à solução de tarefas específicas.

Encontrou em Habré uma
abordagem interessante para automação de correção de alterações na estrutura do banco de dados.
Trabalhar com ramificações
Minha dor eterna é como alternar entre dois ramos A e B, cada um com edições na estrutura do banco de dados.

É necessário reverter as migrações na ramificação A (também devemos lembrar quais e quantas), depois alternar para a ramificação B e reverter novas migrações. Tudo bem, se nossas edições forem compatíveis e eu puder simplesmente mudar para o segundo ramo e fazer migrações adicionais de B.
E se não? E se eu tiver mais de um ramo assim? E depois reverter todos esses estados de revisão? Eu sempre odiei isso ...
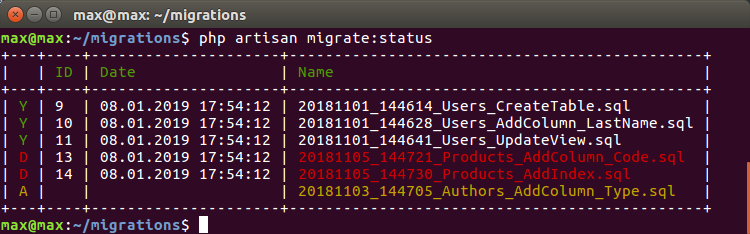
Agora, ao mudar para o ramo de outra pessoa, posso excluir automaticamente as migrações de outras pessoas e rolar as atuais:
onde:
D - Migrações A que foram iniciadas na ramificação A, mas não estão na ramificação atual, e é recomendável excluí-las
A - B-migrações que apareceram na nova ramificação e precisam ser roladas
Torna-se incrivelmente conveniente ao testar e montar automaticamente em uma base. Quando não há sentido ou oportunidade para cada filial criar uma base do zero. Alterne para a ramificação e sincronize automaticamente o estado do banco de dados.
Numeração e ordem de execução
Todas as ferramentas que eu conheço são migrações com carimbo de tempo e uma boa solução. Se eu escrever várias migrações, a sequência necessária será preservada. Outro desenvolvedor pode ter qualquer data em outro segmento, até o meu - mas não importa em que ordem vamos rolar com ele, nossas alterações são independentes uma da outra. Mesmo se trabalharmos com a mesma tabela (adicionar por coluna), todas as alterações necessárias ocorrerão em qualquer ordem. O principal é que a sequência de minhas edições dependentes seja respeitada.

Não considero casos em que precisamos editar a mesma coisa - esses pontos são sempre consistentes. Bem, ou haverá uma falha no estágio de montagem e teste.
Aqui está um exemplo interessante.
Fazemos edições diferentes em uma visualização ou procedimento, ou seja, nessas estruturas que são atualizadas através da exclusão. I.e. Por exemplo, adicionei a coluna col_A à exibição e meu colega col_B. Assim, se o código dele for lançado após o meu, a coluna dele não terá a minha coluna:
CREATE VIEW vusers AS SELECT login, name,
| ramo-A | ramo-B |
|---|
DROP VIEW vusers; CREATE VIEW vusers AS SELECT login, name, col_A, | DROP VIEW vusers; CREATE VIEW vusers AS SELECT login, name, col_B, |
Nesse caso, um ramo deve ficar dependente de outro.
Outro caso interessante são as correções nas migrações.
O ponto principal é que a migração aplicada não será mais aplicada novamente, independentemente de quantas alterações você fizer (será necessário reverter primeiro e depois aplicá-la novamente). I.e. Você enviou a migração para teste, todas as regras e, em seguida, percebeu e fez uma pequena edição. Mas o teste ou outro servidor em que você o usou não saberá sobre isso.
Nesses casos, renomeamos o arquivo de migração, adicionando um novo número de versão, para que o migrador comece a interpretá-lo como 2 comandos - reverter 1 e reverter 2,
por exemplo:

Reversão
Sempre escreva ROLLBACK, mesmo que não possa retornar a base ao seu estado original. Por exemplo, DROP TABLE, que tipo de ROLLBACK pode ser?
Nesses casos, escrevemos uma CREATE TABLE vazia. A conclusão é que o sistema dev sempre pode alternar facilmente entre os ramos. Para o PROD, o gerenciamento de revisão irreversível já está decidido em um nível diferente. Posso fazer uma cópia da tabela ou renomeá-la em vez de excluí-la. Mas o princípio de escrever a migração - a reversão É OBRIGADA a retornar a ESTRUTURA da base ao nível inicial, e os dados já são possíveis.
Em um ambiente de combate, usei uma reversão apenas 1-2 vezes na minha vida. E em dev o tempo todo. Portanto, eu sempre verifico se a reversão retorna tudo ao estado desejado.
Freqüentemente, os desenvolvedores podem cometer erros na reversão. Porque eles se concentram principalmente em novas edições, são testados e trabalham com eles. Outras pessoas e processos já estão trabalhando com a reversão. Portanto, eu sempre testo migrações UP - ROLLBACK - UP
Um ponto interessante aparece em uma base de teste permanente (o banco de dados não é excluído). Eles escreveram uma migração, a reversão funciona bem, eles a enviaram para teste, o testador gerou dados em um novo formato, tenta reverter, mas não fornece novos dados. Exemplo clássico
ALTER TABLE abc ALTER COLUMN code SET NULL
Ótimo! Após o teste, o banco de dados está cheio de valores NULL. ROLLBACK:
ALTER TABLE abc ALTER COLUMN code SET NOT NULL
e vice-versa :-(
Você precisa adicionar o comando:
DELETE FROM abc WHERE code IS NULL
A dificuldade é que você precisa manter isso em mente e não automatizá-lo se não estivermos falando sobre recriar o banco de dados do zero todas as vezes.
Um pouco sobre exclusão de dados
Normalmente, tentamos NÃO excluir tabelas e colunas preenchidas de uma só vez. É melhor renomear ou fazer uma cópia e excluí-la mais tarde, quando tudo se acalmar e os dados perderem relevância:
ALTER TABLE user_logs RENAME TO user_logs_20190223;
Migrador
Agora estamos trabalhando com o Laravel - ele possui um mecanismo de gerenciamento de migração padrão e familiar. Se você quiser, escreva mesmo em SQL puro, embora ainda esteja na classe PHP. Mas minhas repetidas tentativas de fazê-lo funcionar da maneira que precisávamos resultaram em um repositório separado:
- A solução consiste em 2 partes - lib e implementação para um console específico (Laravel, Symfony). Você pode integrar-se a qualquer console, ou pelo menos no focinho da web.
- Não há configuração e conexão - por que, quando já está em seu projeto. Agarre sua conexão à interface e pronto.
- A reversão do SQL é armazenada no banco de dados. Isso é necessário para alternar entre ramificações.
- Testado no Postgesql, Mysql (sem transações). É adequado, em princípio, para quaisquer bases e estruturas, porque o formato bruto é usado.
Referências
-
migrations-lib-
implementação sob Laravel / Artisan-
implementação no Symfony / Console