OSGI não é difícil
Já vi muitas vezes que o OSGI é difícil. Além disso, ele próprio já teve essa opinião. Ano em 2009, para ser exato. Naquela época, coletamos projetos usando o Maven Tycho e os implantamos no Equinox. E era realmente mais difícil do que desenvolver e montar projetos para JavaEE (naquele momento, apenas aparecia a versão do EJB 3, para a qual trocamos). O Equinox era muito menos conveniente que o Weblogic, por exemplo, e os benefícios do OSGI não eram óbvios para mim naquela época.
Mas, depois de muitos anos, tive que iniciar um projeto em um novo emprego, concebido com base no Apache Camel e Apache Karaf. Não era minha idéia, eu conhecia Camel há muito tempo e decidi ler sobre Karaf, mesmo sem uma oferta. Eu li uma noite e percebi - aqui está, simples e pronta, quase a mesma solução para alguns problemas de um JavaEE típico, semelhante ao que eu já havia feito de joelhos usando Weblogic WLST, Jython e Maven Aether.
Então, digamos que você decida experimentar o OSGI na plataforma Karaf. Por onde começamos?
Se você quer uma compreensão mais profunda
Obviamente, você pode começar lendo a documentação. E é possível com Habré - havia artigos muito bons aqui, digamos há muito tempo. Mas, em geral, o karaf recebeu até agora imerecidamente pouca atenção. Houve mais algumas críticas a
isto ou a
isto . É melhor pular
essa menção ao karaf. Como se costuma dizer, não leia jornais soviéticos durante a noite ... pois eles dirão lá que o karaf é uma estrutura OSGI - para que você não acredite. As estruturas OSGI são Apache Felix ou Eclipse Equinox, com base nas quais o karaf simplesmente funciona. Você pode escolher qualquer um deles.
Deve-se notar que, quando o Jboss Fuse ou Apache ServiceMix é mencionado, ele deve ser lido como "Karaf, com componentes pré-instalados", ou seja, de fato - a mesma coisa, coletada apenas pelo fornecedor. Eu não recomendaria começar com isso na prática, mas é bem possível ler artigos de revisão sobre o ServiceMix, por exemplo.
Para começar, tentarei determinar aqui muito brevemente o que é OSGI e para que ele pode ser usado.
Em geral, o OSGI é uma ferramenta para criar aplicativos Java a partir de módulos. Um analógico próximo pode ser considerado, por exemplo, JavaEE, e, até certo ponto, os contêineres OSGI podem executar módulos JavaEE (por exemplo, aplicativos da Web na forma de Guerra) e, por outro lado, muitos contêineres JavaEE contêm OSGI como meio de implementar a modularidade " " Ou seja, JavaEE e OSGI são coisas semelhantes à compatibilidade e complementares com êxito.
Uma parte importante de qualquer sistema modular é a definição do próprio módulo. No caso do OSGI, o módulo é chamado de pacote configurável e é um arquivo jar conhecido por todos os desenvolvedores com algumas adições (ou seja, é muito semelhante aqui, por exemplo, ao war or ear). Por analogia com o JavaEE, os pacotes configuráveis podem exportar e importar serviços, que são essencialmente métodos de classe (ou seja, um serviço é uma interface ou todos os métodos públicos de uma classe).
Os metadados do pacote configurável são familiares a todos os META-INF / MANIFEST.MF. Os cabeçalhos do manifesto OSGI não se cruzam com os cabeçalhos do JRE, respectivamente, fora do pacote configurável do contêiner OSGI é um jar comum. É significativo que entre os metadados sempre haja:
Bundle-SymbolicName: com.example.myosgi Bundle-Version: 1.0.0
Essas são as "coordenadas" do pacote configurável, e o fato de podermos ter duas ou mais versões instaladas e funcionando simultaneamente do mesmo pacote configurável em um contêiner é importante.
Semelhante ao JavaEE, os pacotes configuráveis têm um ciclo de vida semelhante a este:
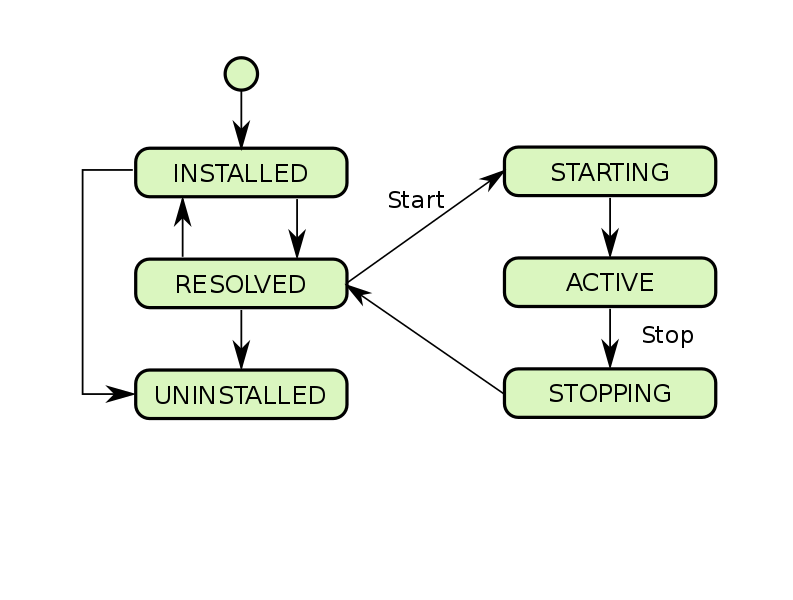
Além dos serviços, os pacotes configuráveis também podem importar e exportar pacotes (pacotes, no sentido usual do termo para java). Pacotes exportados são definidos dentro do pacote configurável e disponibilizados para outros componentes quando o pacote configurável é instalado no sistema. Os importados são definidos em algum lugar externo, devem ser exportados por alguém e fornecidos ao pacote pelo contêiner antes que ele comece a funcionar.
As importações de pacotes podem ser declaradas opcionais, bem como as importações de serviços. E é bastante significativo que a importação e a exportação contenham uma indicação da versão (ou intervalo de versões).
Diferenças do JavaEE
Bem, é bom que eles sejam parecidos - nós entendemos. E como eles diferem?
Na minha opinião, a principal diferença é que o OSGI nos dá muito mais flexibilidade. Quando o pacote está no estado INICIADO, as possibilidades são limitadas apenas pela sua imaginação. Digamos que você possa criar facilmente threads (sim, sim, eu sei sobre o ManagedExecutorService), pools de conexão com bancos de dados, etc. Um contêiner não assume o controle de todos os recursos na mesma extensão que o JavaEE.
Você pode exportar novos serviços no processo. Tente dizer no JavaEE criar dinamicamente um novo servlet? E aqui é bem possível, além disso, o contêiner do servlet karaf criado com base no jetty será imediatamente detectado pelo servlet criado e estará disponível para os clientes em uma URL específica.
Embora isso seja uma pequena simplificação, mas se o aplicativo JavaEE em sua forma clássica consistir principalmente em componentes:
- passivo, aguardando uma ligação do cliente
- definido estaticamente, ou seja, no momento da implantação do aplicativo.
Por outro lado, um aplicativo baseado em OSGI pode conter:
- componentes programados ativos e passivos, realizando pesquisas, bem, ouvindo um soquete, etc.
- serviços podem ser definidos e publicados dinamicamente
- Você pode se inscrever em eventos de estrutura, por exemplo, ouvir o registro de serviços, pacotes configuráveis, etc., receber links para outros pacotes configuráveis e serviços e fazer muito mais.
Sim, no JavaEE, muito disso também é parcialmente possível (por exemplo, através do JNDI), mas no caso do OSGI, na prática, isso é facilitado. Embora haja provavelmente mais alguns riscos aqui.
Diferenças entre karaf e OSGI puro
Além da estrutura do karaf, existem muitas coisas úteis. Em essência, o karaf é uma ferramenta para gerenciar convenientemente a estrutura OSGI - instalando pacotes configuráveis (incluindo grupos), configurando-os, monitorando, descrevendo o modelo e garantindo a segurança e assim por diante.
E vamos praticar já?
Bem, então, vamos começar imediatamente com a instalação. Não há muito o que escrever aqui - vá para karaf.apache.org, faça o download do pacote de distribuição, descompacte-o. As versões do karaf diferem no suporte a diferentes especificações OSGI (4, 5 ou 6) e versões Java. Eu não recomendo a família 2.x, mas aqui estão 3 (se você tiver Java 8, como o meu) e 4 podem ser usados, embora hoje apenas a família 4.x esteja em desenvolvimento (versão atual 4.2.2, ela suporta OSGI 6 e Java até 10).
O Karaf funciona bem no Windows e Linux, tudo o que você precisa para criar um serviço e a execução automática estão disponíveis. Também é declarado o suporte para MacOS e muitos outros tipos de Unix.
Geralmente, você pode iniciar o karaf imediatamente se estiver na Internet. Caso contrário, geralmente vale a pena consertar o arquivo de configuração, indicando onde você possui repositórios. Geralmente será um Nexus corporativo, ou seja, Artifactory, quem quiser o que. A configuração do karaf está localizada na pasta etc da distribuição. Os nomes dos arquivos de configuração não são muito óbvios, mas nesse caso você precisa do arquivo org.ops4j.pax.url.mvn.cfg. O formato deste arquivo é propriedades do java.
Você pode especificar o (s) repositório (s) no próprio arquivo de configuração, listando a lista de URLs nas configurações ou simplesmente mostrando onde está o settings.xml. Lá, o karaf levará a localização do seu proxy, o que geralmente é necessário saber na intranet.
O Kafar precisa de várias portas, estas são HTTP, HTTPS (se a web estiver configurada, por padrão não), SSH, RMI, JMX. Se eles estiverem ocupados com você, ou você quiser executar várias cópias no mesmo host, será necessário alterá-las também. Existem aproximadamente cinco dessas portas.
Portas como jmx e rmi - aqui: org.apache.karaf.management.cfg, ssh - org.apache.karaf.shell.cfg, para alterar as portas http / https, você precisará criar (provavelmente não) o arquivo etc / org.ops4j.pax.web.cfg e escreva o valor org.osgi.service.http.port = port que você precisa.
Então você pode definitivamente iniciá-lo e, como regra, tudo começará. Para uso industrial, obviamente, você precisará fazer alterações no arquivo bin / setenv ou bin / setenv.bat, por exemplo, para alocar a quantidade necessária de memória, mas primeiro, para ver, isso não é necessário.
Você pode iniciar o Karaf imediatamente com o console, o comando karaf ou executá-lo em segundo plano com o comando start server e, em seguida, conectar-se a ele via SSH. Este é um SSH completamente padrão, com suporte para SCP e SFTP. Você pode executar comandos e copiar arquivos para frente e para trás. É possível conectar-se a qualquer cliente, por exemplo, minha ferramenta favorita é o Far NetBox. O login está disponível por login e senha, bem como por chaves. Em crianças jsch, com tudo o que isso implica.
Eu recomendo ter uma janela de console adicional imediatamente para exibir os logs localizados em data / log / karaf.log (e outros arquivos geralmente estão lá, embora isso seja personalizável). Os logs são úteis para você, a partir de mensagens curtas no console, nem tudo está claro.
Eu recomendaria instalar a web imediatamente e o console da web hawtio. Essas duas coisas facilitarão muito a navegação do que está acontecendo no contêiner e a condução do processo a partir de lá em grande parte (como bônus, você terá o jolokia e a capacidade de monitorar via http). A instalação do hawtio é feita por dois comandos do console do karaf (
como descrito aqui ) e, infelizmente, hoje a versão do karaf 3.x não é mais suportada (você terá que procurar versões mais antigas do hawtio).
Os Https não serão imediatamente retirados da caixa; para isso, é necessário fazer alguns esforços, como gerar certificados, etc. A implementação é baseada no jetty; portanto, todos esses esforços são feitos da mesma maneira.
OK, começou, o que vem a seguir?

Na verdade, o que você esperava? Eu disse que seria ssh. Guia funciona, se isso.
É hora de instalar algum aplicativo. Um aplicativo para OSGI é um pacote configurável ou consiste em vários pacotes configuráveis. O Karaf pode implantar aplicativos em vários formatos:
- Um pacote configurável jar, com ou sem um manifesto OSGI
- xml contendo Spring DM ou Blueprint
- xml que contém o chamado recurso, que é uma coleção de pacotes configuráveis, outros recursos e recursos (arquivos de configuração)
- Arquivo .kar contendo vários recursos e um repositório maven com dependências
- Aplicativos JavaEE (sob algumas condições adicionais), por exemplo .war
Existem várias maneiras de fazer isso:
- coloque o aplicativo na pasta deploy
- instale a partir do console com o comando install
- instale o recurso com o comando do recurso: instalar console
- kar: install
Bem, em geral, isso é bastante semelhante ao que um contêiner JavaEE típico pode fazer, mas é um pouco mais conveniente (eu diria que é muito mais conveniente).
Jarra simples
A opção mais fácil é instalar um jar comum. Se você o possui no repositório maven, o comando é suficiente para instalar:
install mvn:groupId/artifactId/version
Ao mesmo tempo, Karaf percebe que ele tem um jarro regular à sua frente e o processa, criando um invólucro em tempo real, o chamado wrapper, gerando um manifesto padrão, com importações e exportações de pacotes.
A sensação de instalar apenas um jar geralmente não é muito grande, pois esse pacote será passivo - ele apenas exporta classes que estarão disponíveis para outros pacotes.
Este método é usado para instalar componentes como o Apache Commons Lang, por exemplo:
install mvn:org.apache.commons.lang3/commons-lang/3.8.1
Mas não funcionou :) Aqui estão as coordenadas corretas:
install mvn:org.apache.commons/commons-lang3/3.8.1
Vamos ver o que aconteceu: list -u nos mostrará os pacotes e suas fontes:
karaf@root()> list -u START LEVEL 100 , List Threshold: 50 ID | State | Lvl | Version | Name | Update location ------------------------------------------------------------------------------------------------- 87 | Installed | 80 | 3.8.1 | Apache Commons Lang | mvn:org.apache.commons/commons-lang3/3.8.1 88 | Installed | 80 | 3.6.0 | Apache Commons Lang | mvn:org.apache.commons/commons-lang3/3.6
Como você pode ver, é bem possível instalar duas versões de um componente. Atualizar local - é aqui que obtemos o pacote e onde ele pode ser atualizado, se necessário.
Contexto Jar e Spring
Se houver um contexto de primavera dentro do seu jar, as coisas ficam mais interessantes. O Karaf Deployer pesquisa automaticamente contextos xml na pasta META-INF / spring e os cria se todos os pacotes externos necessários ao pacote foram encontrados com êxito.
Assim, todos os serviços que estavam dentro dos contextos já serão iniciados. Se você tiver o Camel Spring lá, por exemplo, as rotas do Camel também serão iniciadas. Isso significa que dizemos que um serviço REST ou um serviço escutando uma porta TCP, você já pode iniciar. Obviamente, o lançamento de vários serviços que escutam em uma porta não funcionará dessa maneira.
Contexto XML do Just Spring
Se você tivesse, por exemplo, definições de JDBC DataSources dentro do Spring Context, poderá instalá-las separadamente no Karaf. I.e. pegue um arquivo xml contendo apenas um DataSource na forma de <bean> ou qualquer outro conjunto de componentes, você pode colocá-lo na pasta deploy. O contexto será lançado da maneira padrão. O único problema é que os DataSources criados dessa maneira não serão visíveis para outros pacotes configuráveis. Eles precisam ser exportados para OSGI como serviços. Sobre isso - um pouco mais tarde.
Spring dm
Qual é a diferença entre o Spring DM (versão habilitada para OSGI) e o Spring clássico? Portanto, no caso clássico, todos os beans no contexto são criados no estágio de inicialização do contexto. Os novos não podem aparecer, os antigos não irão a lugar algum. No caso do OSGI, novos pacotes configuráveis podem ser instalados e pacotes antigos removidos. O ambiente está se tornando mais dinâmico, você precisa responder de alguma forma.
O método de resposta é chamado de serviços. Um serviço geralmente é uma determinada interface, com métodos próprios, publicados por alguns pacotes. Um serviço possui metadados que permitem sua pesquisa e distinção de outro serviço que implementa uma interface semelhante (obviamente, de outro DataSource). Os metadados são um conjunto simples de propriedades de valor-chave.
Como os serviços podem aparecer e desaparecer, aqueles que precisam deles podem se inscrever nos serviços na inicialização ou ouvir eventos para descobrir sua aparência ou desaparecimento. No nível do Spring DM, em XML, isso é implementado como dois elementos, serviço e referência, cujo objetivo básico é bastante simples: publicar o bean existente a partir do contexto como um serviço e assinar um serviço externo publicando-o no contexto atual da primavera.
Assim, ao inicializar um pacote, o contêiner encontrará os serviços externos necessários e publicará os pacotes implementados dentro dele, tornando-os acessíveis a partir do exterior. Um pacote configurável é iniciado somente depois que os links de serviço são resolvidos.
De fato, tudo é um pouco mais complicado, porque o pacote pode usar uma lista de serviços semelhantes e se inscrever imediatamente na lista. I.e. um serviço, em geral, possui uma propriedade como cardinalidade, que assume o valor 0..N. Nesse caso, a assinatura, em que 0..1 é indicado, descreve um serviço opcional e, nesse caso, o pacote configurável é iniciado com êxito, mesmo que não exista esse serviço no sistema (e, em vez de um link para ele, ele receberá um stub).
Observo que um serviço é qualquer interface (ou você pode publicar apenas classes), para que você possa publicar o java.util.Map com dados como um serviço.
Entre outras coisas, o serviço permite especificar metadados e a referência permite procurar um serviço por esses metadados.
Blueprint
Blueprint é a encarnação mais recente do Spring DM, que é um pouco mais simples. Ou seja, se no Spring você possui elementos XML personalizados, eles não estão aqui, pois são desnecessários. Às vezes, isso ainda causa inconveniência, mas com franqueza - com pouca frequência. Se você não estiver migrando um projeto do Spring, poderá começar imediatamente com o Blueprint.
A essência aqui é a mesma: o XML, que descreve os componentes dos quais o contexto do pacote configurável é montado. Para quem conhece a primavera, não há nada desconhecido.
Aqui está um exemplo de como descrever um DataSource e exportá-lo como um serviço:
<?xml version="1.0" encoding="UTF-8"?> <blueprint xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0"> <bean id="dataSource" class="oracle.jdbc.pool.OracleDataSource"> <property name="URL" value="URL"/> <property name="user" value="USER"/> <property name="password" value="PASSWORD"/> </bean> <service interface="javax.sql.DataSource" ref="dataSource" id="ds"> <service-properties> <entry key="osgi.jndi.service.name" value="jdbc/ds"/> </service-properties> </service> </blueprint>
Bem, implantamos esse arquivo na pasta de implantação e analisamos os resultados do comando list. Eles viram que o pacote não foi iniciado - no status Indtalled. Tentamos iniciar e recebemos uma mensagem de erro.
Agora na lista de pacotes configuráveis no status Falha. O que houve? Obviamente, ele também precisa de dependências, neste caso, um Jar com classes JDBC Oracle ou, mais precisamente, o pacote oracle.jdbc.pool.
Nós encontramos o jar necessário no repositório, ou baixamos do site Oracle e instalamos, conforme descrito anteriormente. Nosso DataSource foi iniciado.
Como usar tudo isso? O link do serviço é chamado na referência Blueprint (em algum lugar, no contexto de outro pacote configurável):
<reference id="dataSource" interface="javax.sql.DataSource"/>
Então, esse bean se torna, como sempre, uma dependência para outros beans (no exemplo camel-sql):
<bean id="sql" class="org.apache.camel.component.sql.SqlComponent"> <property name="dataSource" ref="dataSource"/> </bean>
Jar e ativador
A maneira canônica de inicializar pacotes configuráveis é usar uma classe que implementa a interface do Activator. Essa é uma interface típica do ciclo de vida que contém métodos de início e parada que passam pelo
contexto . Dentro deles, o pacote configurável geralmente inicia seus encadeamentos, se necessário, começa a escutar portas, assina serviços externos usando a API OSGI e assim por diante. Esta é talvez a maneira mais complexa, básica e flexível. Por três anos eu nunca precisei disso.
Definições e configuração
É claro que essa configuração do DataSource, como mostra o exemplo, poucas pessoas precisam. Login, senha e muito mais, tudo é codificado dentro do XML. É necessário remover esses parâmetros.
<property name="url" value="${oracle.ds.url}"/> <property name="user" value="${oracle.ds.user}"/> <property name="password" value="${oracle.ds.password}"/>
A solução é bastante simples e semelhante à usada na primavera clássica: em um certo ponto do ciclo de vida do contexto, os valores das propriedades são substituídos por várias fontes.
Sobre isso, terminaremos a primeira parte. Se houver interesse neste tópico, continue. Vamos considerar como montar aplicativos a partir de pacotes configuráveis, configurar, monitorar e implantar sistemas automaticamente nesta plataforma.