→
Testando projetos Node.js. Parte 1. Anatomia e tipos de testeHoje, na segunda parte da tradução do material dedicado aos testes dos projetos Node.js., falaremos sobre avaliar a eficácia dos testes e analisar a qualidade do código.
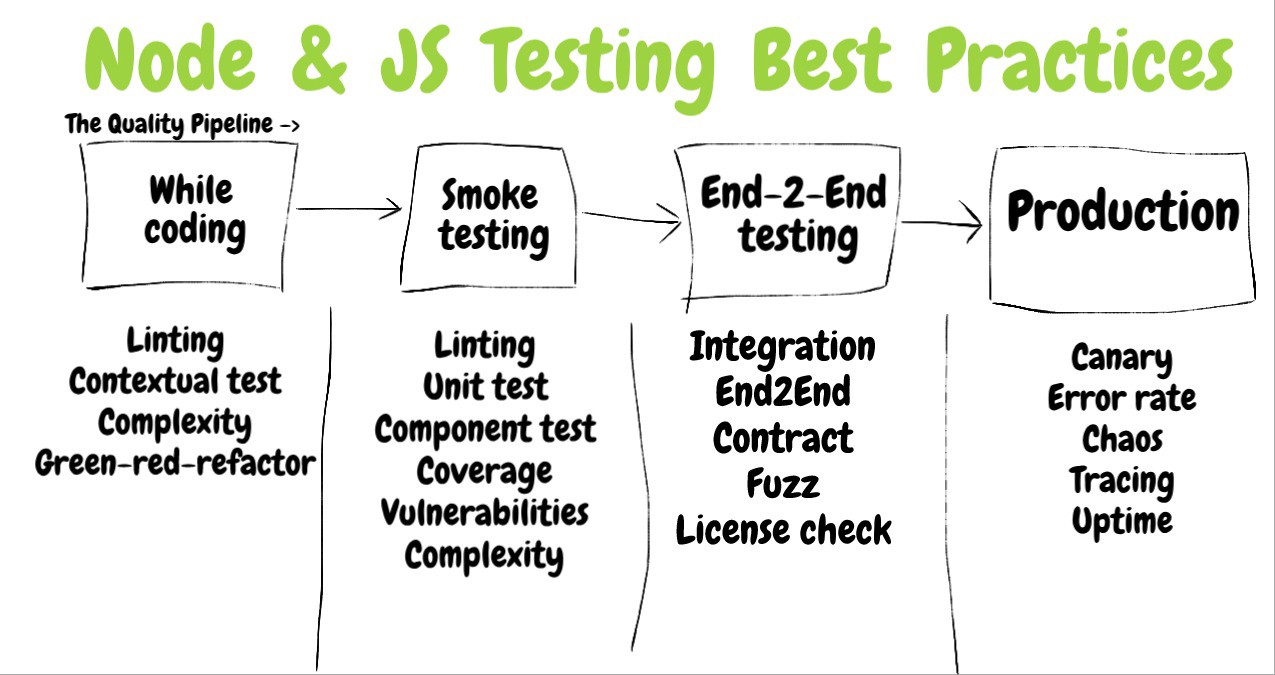
Seção 3. Avaliação da eficácia dos testes
19. Alcance um nível suficientemente alto de cobertura de código com testes para ganhar confiança em sua operação correta. Geralmente, aproximadamente 80% de cobertura fornece bons resultados.
Recomendações
O objetivo do teste é garantir que o programador possa continuar trabalhando produtivamente no projeto, garantindo que o que já foi feito esteja correto. Obviamente, quanto maior o volume do código testado, mais forte a confiança de que tudo funciona como deveria. O indicador de cobertura de código por testes indica quantas linhas (ramificações, comandos) foram verificadas por testes. Qual deve ser esse indicador? É claro que 10 a 30% é muito pouco para dar confiança de que o projeto funcionará sem erros. Por outro lado, o desejo de 100% de cobertura do código com testes pode ser um prazer muito caro e pode distrair o desenvolvedor dos fragmentos mais importantes do programa, forçando-o a procurar no código aqueles lugares que os testes existentes não alcançam. Se você der uma resposta mais completa à pergunta sobre qual deve ser a cobertura do código com testes, podemos dizer que o indicador pelo qual devemos nos esforçar depende do aplicativo que está sendo desenvolvido. Por exemplo, se você estiver escrevendo um software para a próxima geração do Airbus A380, 100% é um indicador que nem é discutido. Mas se você criar um site no qual as galerias de caricaturas serão exibidas, provavelmente 50% já é demais. Embora os especialistas em testes digam que o nível de cobertura do código com os testes que você deve buscar depende do projeto, muitos deles mencionam os 80%, o que provavelmente é adequado para a maioria dos aplicativos. Por exemplo,
aqui estamos falando de algo na região de 80 a 90% e, de acordo com o autor deste material, 100% de cobertura do código com testes o deixa desconfiado, pois pode indicar que o programador escreve testes apenas para obter número bonito no relatório.
Para usar os indicadores dos testes de cobertura de código, você precisará configurar corretamente seu sistema para integração contínua (IC, integração contínua). Isso permitirá, se o indicador correspondente não atingir um determinado limite, interromper a montagem do projeto.
Veja como configurar o Jest para coletar informações de cobertura de teste. Além disso, você pode configurar os limites de cobertura não para todo o código, mas focando em componentes individuais. Além disso, considere detectar uma diminuição na cobertura do teste. Isso acontece, por exemplo, ao adicionar novo código a um projeto. O controle desse indicador incentivará os desenvolvedores a aumentar o volume do código testado ou, pelo menos, manter esse volume no nível existente. Em vista do exposto, a cobertura do código com testes é apenas um indicador quantificado, o que não é suficiente para avaliar completamente a confiabilidade dos testes. Além disso, como será mostrado abaixo, seus altos níveis ainda não significam que o código “coberto com testes” esteja realmente verificado.
Consequências do desvio das recomendações
A confiança do programador na alta qualidade do código e indicadores relacionados relacionados ao teste andam de mãos dadas. Um programador não pode deixar de ter medo de erros se não souber que a maior parte do código de seu projeto é coberta por testes. Essas preocupações podem retardar o seu projeto.
Exemplo
Veja como é um relatório típico de cobertura de teste.
Relatório de cobertura de teste gerado por IstambulAbordagem correta
Aqui está um exemplo de configuração do nível desejado de cobertura de teste do código do componente e o nível geral deste indicador no Jest.
Definindo o nível desejado de cobertura de código com testes para todo o projeto e para um componente específico▍20. Examine os relatórios sobre a cobertura do código com testes para identificar partes desprotegidas do código e outras anomalias
Recomendações
Alguns problemas tendem a passar por uma variedade de sistemas de detecção de erros. Pode ser difícil detectar essas coisas usando ferramentas tradicionais. Talvez isso não se aplique a erros reais. Em vez disso, estamos falando sobre um comportamento inesperado do aplicativo, que pode ter consequências devastadoras. Por exemplo, muitas vezes acontece que alguns fragmentos de código nunca são usados ou raramente são chamados. Por exemplo, você acha que os mecanismos da classe
PricingCalculator sempre
PricingCalculator usados para definir o preço de um produto, mas, na verdade, essa classe não é usada, e há registros de 10.000 produtos no banco de dados e na loja online em que o sistema é usado, muitas vendas ... Relatórios sobre cobertura de código com testes ajudam o desenvolvedor a entender se o aplicativo funciona da maneira que deve funcionar. Além disso, nos relatórios, você pode descobrir qual código de projeto não foi testado. Se você se concentrar em um indicador geral que indique que os testes cobrem 80% do código, não poderá descobrir se partes críticas do aplicativo estão sendo testadas. Para gerar esse relatório, basta configurar corretamente a ferramenta usada para executar os testes. Esses relatórios geralmente parecem bastante bonitos e sua análise, que não leva muito tempo, permite detectar todo tipo de surpresa.
Consequências do desvio das recomendações
Se você não sabe quais partes do seu código não foram testadas, não sabe onde pode esperar problemas.
Abordagem incorreta
Veja o próximo relatório e pense no que lhe parece incomum.
Relatório indicando comportamento incomum do sistemaO relatório é baseado em um cenário real de uso de aplicativos e permite que você veja um comportamento incomum do programa associado aos usuários que efetuam logon no sistema. Ou seja, um número inesperadamente grande de tentativas malsucedidas de entrar no sistema chama sua atenção em comparação com as bem-sucedidas. Após analisar o projeto, verificou-se que o motivo era um erro no frontend, devido ao qual a parte da interface do projeto enviava constantemente solicitações correspondentes à API do servidor para a entrada no sistema.
21. Avalie a cobertura do código lógico com testes usando teste de mutação
Recomendações
As métricas tradicionais de benchmarking podem não ser confiáveis. Portanto, no relatório, pode haver um valor de 100%, mas, ao mesmo tempo, absolutamente todas as funções do projeto retornarão valores incorretos. Como explicar isso? O fato é que o indicador de cobertura de código pelos testes indica apenas quais linhas de código foram executadas sob o controle do sistema de teste, mas não depende se algo foi realmente verificado, ou seja, se as instruções do teste foram visando verificar a exatidão dos resultados do código. É semelhante a uma pessoa que, retornando de uma viagem de negócios ao exterior, mostra carimbos no passaporte. Os selos provam que ele foi a algum lugar, mas eles não dizem nada sobre se ele fez o que fez em viagem de negócios.
Aqui, os testes de mutação podem nos ajudar, o que nos permite descobrir quanto código foi realmente testado, e não apenas visitado pelo sistema de teste. Para teste mutacional, você pode usar a biblioteca
Stryker JS. Aqui estão os princípios pelos quais ele funciona:
- Ela intencionalmente altera o código, criando erros nele. Por exemplo, o código
newOrder.price===0 transforma em newOrder.price!=0 . Esses "erros" são chamados de mutações. - Ela faz testes. Se eles acabam sendo aprovados, então temos problemas, porque os testes não cumprem sua tarefa de detectar erros e os "mutantes", como dizem, "sobrevivem". Se os testes indicarem erros no código, tudo estará em ordem - os "mutantes" "morrem".
Se acontecer que todos os "mutantes" foram "mortos" (ou, pelo menos, a maioria deles não sobreviveu), isso proporciona um nível mais alto de confiança na alta qualidade do código e nos testes que o testam do que as métricas tradicionais para cobrir o código com testes. Ao mesmo tempo, o tempo necessário para configurar e realizar testes mutacionais é comparável ao necessário ao usar testes convencionais.
Consequências do desvio das recomendações
Se o indicador tradicional de cobertura de código por testes indicar que 85% do código é coberto por testes, isso não significa que os testes possam detectar erros nesse código.
Abordagem incorreta
Aqui está um exemplo de 100% de cobertura do código com testes, nos quais o código não foi completamente testado.
function addNewOrder(newOrder) { logger.log(`Adding new order ${newOrder}`); DB.save(newOrder); Mailer.sendMail(newOrder.assignee, `A new order was places ${newOrder}`); return {approved: true}; } it("Test addNewOrder, don't use such test names", () => { addNewOrder({asignee: "John@mailer.com",price: 120}); });
Abordagem correta
Aqui está o relatório de teste de mutação gerado pela biblioteca Stryker. Ele permite que você descubra quanto código não foi testado (isso é indicado pelo número de "mutantes" "sobreviventes").
Relatório StrykerOs resultados deste relatório permitem, com mais confiança do que os indicadores usuais de cobertura de código com testes, dizer que os testes funcionam conforme o esperado.
- Uma mutação é um código que foi deliberadamente modificado pela biblioteca Stryker para testar a eficácia de um teste.
- O número de "mutantes" "mortos" (mortos) mostra o número de defeitos de código criados intencionalmente ("mutantes") que foram identificados durante o teste.
- O número de "sobreviventes" "mutantes" (sobreviventes) permite descobrir quantos testes de defeitos de código não foram encontrados.
Seção 4. Integração Contínua, Outros Indicadores de Qualidade de Código
22. Aproveite os recursos do linter e interrompa o processo de construção do projeto quando ele detectar problemas que eles relatam
Recomendações
Hoje, os linters são ferramentas poderosas que podem identificar problemas sérios de código. É recomendável, além de algumas regras básicas de linting (como as implementadas pelos
plugins eslint-plugin-standard e
eslint-config-airbnb ), usar regras especializadas. Por exemplo, estas são as regras implementadas por meio do
plugin eslint-plugin-chai-expect para verificar a correção do código de teste, essas são as regras do
plugin eslint-plugin-promessa que controlam o trabalho com promessas, essas são as regras do
eslint-plugin-security que verificam o código quanto à disponibilidade contém expressões regulares perigosas. Aqui também é possível mencionar o
plug-in eslint-plugin-you-not-need-lodash-underscore , que permite encontrar no código o uso de métodos de bibliotecas externas que possuem análogos em JavaScript puro.
Consequências do desvio das recomendações
Chegou um dia chuvoso, o projeto apresenta falhas contínuas na produção e não há informações sobre pilhas de erros nos logs. O que aconteceu Como se viu, o que o código lança como exceção não é realmente um objeto de erro. Como resultado, informações sobre a pilha não entram nos logs. De fato, em tal situação, o programador pode matar contra a parede ou, o que é muito melhor, passar 5 minutos configurando o linter, o que detectará facilmente o problema e garantirá ao projeto problemas semelhantes que possam surgir no futuro.
Abordagem incorreta
Aqui está o código que, inadvertidamente, lança um objeto comum como uma exceção, enquanto aqui você precisa de um objeto do tipo
Error . Caso contrário, os dados sobre a pilha não entrarão no log. O ESLint encontra o que poderia causar problemas de produção, ajudando a evitar esses problemas.
ESLint ajuda a encontrar um bug no seu código23. Feedback mais rápido para desenvolvedores que usam integração contínua local
Recomendações
Usando um sistema centralizado de integração contínua, que ajuda a controlar a qualidade do código, testando-o, usando o linter, verificando se há vulnerabilidades? Nesse caso, verifique se os desenvolvedores podem executar este sistema localmente. Isso permitirá que eles verifiquem instantaneamente seu código, o que acelera o
feedback e reduz o tempo de desenvolvimento do projeto. Por que isso é assim? Um processo eficaz de desenvolvimento e teste envolve muitas operações repetidas ciclicamente. O código é testado, o desenvolvedor recebe um relatório e, se necessário, o código é refatorado, após o que tudo é repetido. Quanto mais rápido o ciclo de feedback funciona, mais rapidamente os desenvolvedores recebem relatórios sobre o teste de código, mais iterações de aprimoramento desse código podem ser executadas. Se demorar muito tempo para obter um relatório de teste, isso pode levar à baixa qualidade do código. Digamos que alguém estava trabalhando em algum módulo, depois começou a trabalhar em outra coisa e, em seguida, recebeu um relatório sobre o módulo, indicando que o módulo precisa ser aprimorado. No entanto, já ocupado com assuntos completamente diferentes, o desenvolvedor não prestará atenção suficiente ao módulo do problema.
Alguns provedores de soluções de IC (digamos que isso se aplica ao
CircleCI ) permitem executar o pipeline de CI localmente. Algumas ferramentas pagas, como
Wallaby.js (o autor observa que ele não está conectado a este projeto), podem obter rapidamente informações valiosas sobre a qualidade do código. Além disso, o desenvolvedor pode simplesmente adicionar o script npm apropriado ao
package.json , que executa verificações de qualidade de código (testa, analisa com um linter, procura por vulnerabilidades) e até usa o pacote
simultâneo para acelerar as verificações. Agora, para verificar o código de forma abrangente, será suficiente executar um único comando, como
npm run quality , e obter imediatamente um relatório. Além disso, se os testes de código indicarem que há problemas, você poderá cancelar as confirmações usando git hooks (a biblioteca
husky pode ser útil para resolver esse problema).
Consequências do desvio das recomendações
Se um desenvolvedor receber um relatório sobre a qualidade do código um dia após escrever esse código, é provável que esse relatório se transforme em um documento formal, e os testes de código serão separados do trabalho, não se tornando sua parte natural.
Abordagem correta
Aqui está um script npm que verifica a qualidade do código. A realização de verificações é paralelizada. O script é executado ao tentar enviar novo código para o repositório. Além disso, o desenvolvedor pode iniciá-lo por sua própria iniciativa.
"scripts": { "inspect:sanity-testing": "mocha **/**--test.js --grep \"sanity\"", "inspect:lint": "eslint .", "inspect:vulnerabilities": "npm audit", "inspect:license": "license-checker --failOn GPLv2", "inspect:complexity": "plato .", "inspect:all": "concurrently -c \"bgBlue.bold,bgMagenta.bold,yellow\" \"npm:inspect:quick-testing\" \"npm:inspect:lint\" \"npm:inspect:vulnerabilities\" \"npm:inspect:license\"" }, "husky": { "hooks": { "precommit": "npm run inspect:all", "prepush": "npm run inspect:all" } }
§24. Realize testes de ponta a ponta em um espelho realista do ambiente de produção
Recomendações
No vasto ecossistema de Kubernetes, ainda existe um consenso em usar ferramentas adequadas para implantar ambientes locais, embora essas ferramentas apareçam com bastante frequência. Uma abordagem possível aqui é executar um Kubernetes “minimizado” usando ferramentas como
Minikube ou
MicroK8s , que permitem criar ambientes leves que se assemelham aos reais. Outra abordagem é testar projetos em um ambiente Kubernetes "real" remoto. Alguns provedores de IC (como o
Codefresh ) possibilitam a interação com os ambientes internos do Kubernetes, o que simplifica o trabalho dos pipelines de CI ao testar projetos do mundo real. Outros permitem que você trabalhe com ambientes remotos do Kubernetes.
Consequências do desvio das recomendações
O uso de várias tecnologias na produção e teste requer o suporte de dois modelos de desenvolvimento e leva à separação de equipes de programadores e especialistas em DevOps.
Abordagem correta
Aqui está um exemplo de uma cadeia de ICs, que, como dizem, em tempo real cria um cluster Kubernetes (isso é obtido
aqui ).
deploy: stage: deploy image: registry.gitlab.com/gitlab-examples/kubernetes-deploy script: - ./configureCluster.sh $KUBE_CA_PEM_FILE $KUBE_URL $KUBE_TOKEN - kubectl create ns $NAMESPACE - kubectl create secret -n $NAMESPACE docker-registry gitlab-registry --docker-server="$CI_REGISTRY" --docker-username="$CI_REGISTRY_USER" --docker-password="$CI_REGISTRY_PASSWORD" --docker-email="$GITLAB_USER_EMAIL" - mkdir .generated - echo "$CI_BUILD_REF_NAME-$CI_BUILD_REF" - sed -e "s/TAG/$CI_BUILD_REF_NAME-$CI_BUILD_REF/g" templates/deals.yaml | tee ".generated/deals.yaml" - kubectl apply --namespace $NAMESPACE -f .generated/deals.yaml - kubectl apply --namespace $NAMESPACE -f templates/my-sock-shop.yaml environment: name: test-for-ci
▍25. Esforce-se para paralelizar a execução do teste
Recomendações
Se o sistema de teste estiver bem organizado, ele se tornará seu amigo fiel, 24 horas por dia, pronto para relatar problemas com o código. Para fazer isso, os testes devem ser realizados muito rapidamente. Na prática, verifica-se que executar 500 testes de unidade no modo de thread único que usam o processador intensivamente leva muito tempo. E esses testes precisam ser realizados com bastante frequência. Felizmente, ferramentas modernas para executar testes (
Jest ,
AVA , uma
extensão para Mocha ) e plataformas de CI podem executar testes em paralelo usando vários processos, o que pode melhorar significativamente a velocidade de recebimento de relatórios de teste. Algumas plataformas de IC sabem paralelizar testes entre contêineres, o que melhora ainda mais o ciclo de feedback. Para paralelizar com êxito a execução de testes, local ou remoto, os testes não devem depender um do outro. Testes independentes podem ser executados em diferentes processos sem problemas.
Consequências do desvio das recomendações
Obter resultados do teste uma hora depois de enviar o código ao repositório enquanto trabalha nos novos recursos do projeto é uma ótima maneira de reduzir a utilidade dos resultados do teste.
Abordagem correta
Graças à execução paralela de testes, a biblioteca
mocha-parallel-test e a estrutura
Jest ignoram facilmente o Mocha (
essa é a fonte dessa informação).
Ferramentas de teste de desempenho de teste§26. Proteja-se de questões legais usando a verificação de licença e verificação de código de plágio
Recomendações
Talvez agora você não esteja particularmente preocupado com problemas com a lei e plágio. No entanto, por que não verificar seu projeto quanto a problemas semelhantes? Existem muitas ferramentas disponíveis para organizar essas inspeções. Por exemplo, são
verificadores de licença e verificadores de plágio (este é um pacote comercial, mas existe a possibilidade de seu uso gratuito). É fácil integrar essas verificações ao pipeline do IC e verificar o projeto, por exemplo, a presença de dependências com licenças limitadas ou a presença de código copiado do StackOverflow e provavelmente infringindo os direitos autorais de outra pessoa.
Consequências do desvio das recomendações
O desenvolvedor, inadvertidamente, pode usar o pacote com uma licença que não é adequada ao seu projeto ou copiar o código comercial, o que pode levar a problemas legais.
Abordagem correta
Instale o pacote do verificador de licença localmente ou em um ambiente de IC:
npm install -g license-checker
Verificaremos as licenças com ele e, se ele encontrar algo que não nos convém, reconheceremos a verificação como malsucedida. O sistema de CI, ao detectar que algo deu errado durante a verificação das licenças, interromperá a montagem do projeto.
license-checker --summary --failOn BSD
Verificação de licença27. Verifique constantemente o projeto em busca de dependências vulneráveis
Recomendações
Até pacotes altamente respeitados e confiáveis, como o Express, têm vulnerabilidades. Para identificar essas vulnerabilidades, você pode usar ferramentas especiais - como a ferramenta padrão para
auditar pacotes npm ou o projeto
snyk comercial, que possui uma versão gratuita. Essas verificações, juntamente com outras, podem fazer parte do pipeline do IC.
Consequências do desvio das recomendações
Para proteger seu projeto contra vulnerabilidades de suas dependências sem usar ferramentas especiais, você precisará monitorar constantemente as publicações sobre essas vulnerabilidades. Esta é uma tarefa que consome muito tempo.
Abordagem correta
Aqui estão os resultados da verificação do projeto usando o NPM Audit.
Relatório de pacote de verificação de vulnerabilidade28. Automatize atualizações de dependência
Recomendações
O caminho para o inferno é pavimentado com boas intenções. Essa ideia é totalmente aplicável ao
package-lock.json , cuja utilização, por padrão, bloqueia as atualizações do pacote. Isso acontece mesmo nos casos em que os projetos são trazidos a um estado
npm install npm update comandos
npm install e
npm update . Isso leva, na melhor das hipóteses, ao uso de pacotes desatualizados ou, na pior, à aparência de código vulnerável no projeto. As equipes de desenvolvimento, como resultado, dependem da atualização manual de informações sobre versões adequadas de pacotes ou de utilitários como
ncu , que, novamente, são iniciados manualmente. O processo de atualização de dependências é melhor automatizado, concentrando-se no uso das versões mais confiáveis dos pacotes usados no projeto. Essa não é a única solução correta, no entanto, ao automatizar as atualizações de pacotes, existem algumas abordagens dignas de nota. O primeiro é
injetar algo como verificar pacotes usando
npm-outdated ou
npm-check-updates (ncu) no pipeline do IC. Isso ajudará a identificar pacotes obsoletos e incentivará os desenvolvedores a atualizá-los. A segunda abordagem é usar ferramentas comerciais que verificam o código e fazem automaticamente solicitações pull destinadas a atualizar dependências. No campo da atualização automática de dependências, somos confrontados com outra questão interessante sobre a política de atualização. Se atualizada com cada novo patch, a atualização pode colocar muito estresse no sistema. Se você atualizar imediatamente após o lançamento da próxima versão principal do pacote, isso poderá levar ao uso de soluções instáveis no projeto (vulnerabilidades em muitos pacotes são encontradas exatamente nos primeiros dias após o lançamento,
leia sobre o incidente com o escopo do eslint). « », , . , 1.3.1, 1.3.2, 1.3.8.
, , , .
ncu , , , .
ncu▍29. , Node.js
, Node.js-, , Node.js .
- . — , , , Jenkins .
- , Docker.
- . , , . (, ), , , , .
- , , , . — , , , .
- , . , feature, — master, , ( ).
- . , .
- .
- (, Docker) .
- , , , . ,
node_modules .
, , .
▍30.
, . , , , Node.js , . CI-, , « ». , , , . , , mySQL, — Postgres. , Node.js, — 8, 9 10. , . CI-.
, , , . , , .
CI- Travis Node.js.
language: node_js node_js: - "7" - "6" - "5" - "4" install: - npm install script: - npm run test
Sumário
, , . , , .
Caros leitores! ?
