A velocidades de mais de 1 bilhão de quadros por segundo, esse é sem dúvida o mais rápido dos clusters de console de 8 bits do mundo.
 Tetris Distribuído (1989)
Tetris Distribuído (1989)Como construir um computador assim?
Receita
Tome um punhado de silício, aplique treinamento de reforço, experiência com supercomputadores, paixão pela arquitetura de computadores, adicione suor e lágrimas, mexa 1000 horas até ferver - e pronto.
Por que alguém precisaria desse computador?
Em resumo: avançar para o aprimoramento da inteligência artificial.
 Uma das 48 placas IBM Neural Computer usadas para experimentos
Uma das 48 placas IBM Neural Computer usadas para experimentosE aqui está uma versão mais detalhada
Ano de 2016. O aprendizado profundo é onipresente. O reconhecimento de imagem pode ser considerado uma tarefa resolvida graças às redes neurais convolucionais, e meus interesses de pesquisa estão se esforçando para redes neurais com memória e aprendizado reforçado.
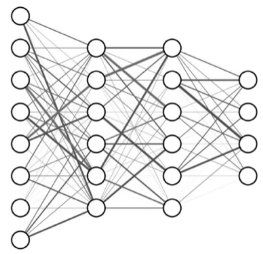
Especificamente, no trabalho de autoria do Google Deepmind, foi demonstrado que é possível atingir o nível de uma pessoa ou até superá-lo em vários jogos para o Atari 2600 (console de jogos doméstico, lançado em 1977), usando um algoritmo de aprendizado simples suportado pelo Deep Q-Neural Network. E tudo isso acontece simplesmente ao ver a jogabilidade. Isso chamou minha atenção.
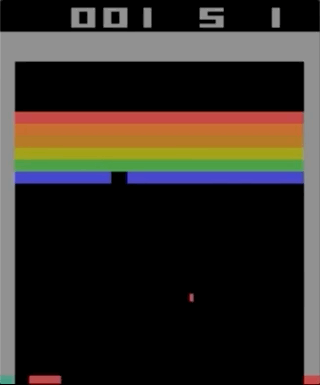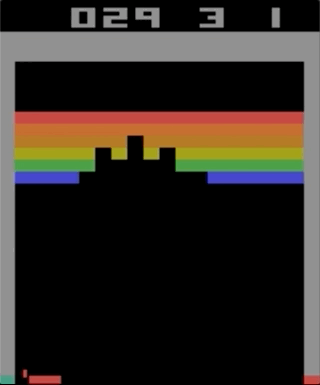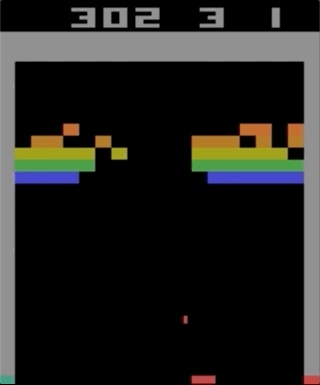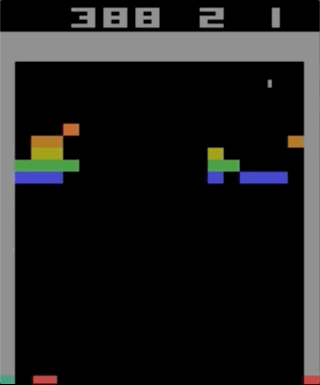 Um dos jogos com o Atari 2600, Breakout. A máquina foi treinada usando um algoritmo simples de aprendizado por reforço. Após milhões de iterações, o computador começou a tocar melhor que os humanos.
Um dos jogos com o Atari 2600, Breakout. A máquina foi treinada usando um algoritmo simples de aprendizado por reforço. Após milhões de iterações, o computador começou a tocar melhor que os humanos.Comecei a experimentar os jogos Atari 2600. Embora impressionante, o Breakout não pode ser chamado de complicado. A dificuldade pode ser determinada pelo grau de dificuldade de acordo com suas ações (joystick) e seus resultados (pontos). O problema aparece quando o efeito precisa esperar muito tempo.
 Ilustração de um problema ao usar jogos mais complexos como exemplo. Esquerda - fuga (ATARI 2600) [o autor estava errado, este é um jogo de Pong / aprox. trans.] com uma resposta muito rápida e feedback rápido. Direito - Mario Land (Nintendo Game Boy) não fornece informações instantâneas sobre os efeitos da ação; longos períodos de observações irrelevantes podem aparecer entre dois eventos importantes.
Ilustração de um problema ao usar jogos mais complexos como exemplo. Esquerda - fuga (ATARI 2600) [o autor estava errado, este é um jogo de Pong / aprox. trans.] com uma resposta muito rápida e feedback rápido. Direito - Mario Land (Nintendo Game Boy) não fornece informações instantâneas sobre os efeitos da ação; longos períodos de observações irrelevantes podem aparecer entre dois eventos importantes.Para tornar o aprendizado mais eficaz, pode-se imaginar tentativas de transferir parte do conhecimento de jogos mais simples. Essa tarefa agora permanece sem solução e é um tópico ativo para pesquisa. Uma
tarefa publicada recentemente da OpenAI está tentando medir exatamente isso.
A capacidade de transferir conhecimento não apenas aceleraria o treinamento - acredito que alguns problemas de aprendizagem não podem ser resolvidos na ausência de conhecimento básico. Precisamos de eficiência de dados. Tome o jogo Prince of Persia:

Não há pontos óbvios nele.
Demora 60 minutos para completar o jogo.

É possível aplicar a mesma abordagem usada ao escrever o trabalho no Atari 2600? Qual a probabilidade de você chegar ao fim pressionando teclas aleatórias?
Essa pergunta me levou a contribuir com a comunidade, que consiste em tentar resolver esse problema. De fato, temos a tarefa de galinha e ovos - precisamos de um algoritmo melhor que nos permita transmitir uma mensagem, mas isso requer pesquisa e experimentos são demorados, pois não temos um algoritmo mais eficiente.
 Um exemplo de transferência de conhecimento: imagine que aprendemos a jogar um jogo simples, como o da esquerda. Em seguida, salvamos conceitos como "corrida", "carro", "pista", "vitória" e aprendemos cores ou modelos tridimensionais. Argumentamos que conceitos comuns podem ser “transportados” entre os jogos. A semelhança dos jogos pode ser determinada pelo número de conhecimentos transferidos entre eles. Por exemplo, os jogos Tetris e F1 não serão semelhantes.
Um exemplo de transferência de conhecimento: imagine que aprendemos a jogar um jogo simples, como o da esquerda. Em seguida, salvamos conceitos como "corrida", "carro", "pista", "vitória" e aprendemos cores ou modelos tridimensionais. Argumentamos que conceitos comuns podem ser “transportados” entre os jogos. A semelhança dos jogos pode ser determinada pelo número de conhecimentos transferidos entre eles. Por exemplo, os jogos Tetris e F1 não serão semelhantes.Portanto, decidi usar a segunda abordagem ideal, evitando a desaceleração inicial, acelerando drasticamente o sistema. Meus objetivos eram:
- ambiente acelerado (imagine que o Prince of Persia possa ser concluído 100 vezes mais rápido) e o lançamento simultâneo de 100.000 jogos.
- um ambiente mais adequado para pesquisa (nos concentramos em tarefas, mas não em cálculos preliminares, temos acesso a vários jogos).
Inicialmente, pensei que o gargalo de desempenho dependesse de alguma forma da complexidade do código do emulador (por exemplo, a base de códigos Stella é grande e depende de abstrações de C ++ - não é a melhor opção para emuladores).
Consoles

No total, trabalhei em várias plataformas, começando com um dos primeiros jogos já criados (junto com o jogo Pong) - os Arcade Space Invaders, Atari 2600, NES e Game Boy. E tudo isso foi escrito em C.
Consegui atingir uma taxa de quadros máxima de 2000-3000 por segundo. Para começar a obter os resultados das experiências, precisamos de milhões ou bilhões de quadros, para que a diferença fosse enorme.
 Invasores de espaço trabalhando no FPGA - modo de depuração em baixa velocidade. O contador FPGA mostra o número de ciclos de relógio que passaram.
Invasores de espaço trabalhando no FPGA - modo de depuração em baixa velocidade. O contador FPGA mostra o número de ciclos de relógio que passaram.E então pensei - e se pudéssemos acelerar o ambiente certo com ferro. Por exemplo, os invasores espaciais originais foram para a CPU 8080 com uma frequência de 1 MHz. Consegui emular uma CPU 8080 de 40 MHz em um processador Xeon de 3 GHz. Nada mal, mas depois de colocar tudo isso dentro do FPGA, a frequência subiu para 400 MHz. Isso significava 24.000 FPS de um fluxo - o equivalente a um Xeon de 30 GHz! Eu mencionei que você pode compactar 100 processadores 8080 em um FPGA médio? Isso já gera 2,4 milhões de FPS.
 Invasores do espaço com aceleração de hardware de 100 MHz, um quarto da velocidade máxima
Invasores do espaço com aceleração de hardware de 100 MHz, um quarto da velocidade máxima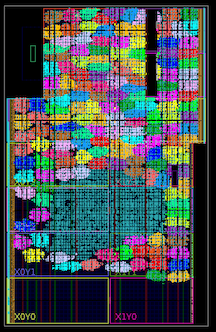 Mais de cem núcleos no interior do Xilinx Kintex 7045 FPGA (indicado por cores brilhantes; o ponto azul no meio é a lógica geral da demonstração).
Mais de cem núcleos no interior do Xilinx Kintex 7045 FPGA (indicado por cores brilhantes; o ponto azul no meio é a lógica geral da demonstração). Caminho de execução desigual
Caminho de execução desigualVocê pode perguntar, e a GPU? Em resumo, precisamos de simultaneidade como
MIMD , não
SIMD . Como estudante, trabalhei por algum tempo na
implementação de uma pesquisa em árvore Monte Carlo em uma GPU (essa pesquisa foi usada no AlphaGo).
Naquela época, passei inúmeras horas tentando fazer com que a GPU e outras peças de hardware trabalhassem no princípio do SIMD (IBM Cell, Xeon Phi, CPU AVX) para executar código semelhante, e nada resultou. Alguns anos atrás, comecei a pensar que seria bom poder desenvolver de forma independente um hardware projetado especificamente para resolver problemas relacionados ao treinamento de reforço.
 Simultaneidade MIMD
Simultaneidade MIMDATARI 2600, NES ou Game Boy?
Em 8080, implementei Space Invaders, NES, 2600 e Game Boy. E aqui estão alguns fatos sobre eles e os benefícios de cada um deles.
 NES Pacman
NES PacmanInvasores do espaço eram apenas um aquecimento. Conseguimos fazê-los funcionar, mas era apenas um jogo, então o resultado não foi muito útil.
O Atari 2600 é realmente o padrão na pesquisa de aprendizado por reforço. O processador MOS 6507 é uma versão simplificada do famoso 6502, seu design é mais elegante e mais eficiente que o do 8080. Escolhi 2600 não apenas por causa de certas limitações associadas aos jogos e seus gráficos.
Também implementei o NES (Nintendo Entertainment System), que compartilha a CPU com 2600. Existem jogos muito melhores que 2600. Mas os dois consoles sofrem com um pipeline de processamento gráfico excessivamente complexo e vários formatos de cartucho que precisam ser suportados.
Enquanto isso, redescobri o Nintendo Game Boy. E era isso que eu estava procurando.
Por que o Game Boy é tão legal?
 1049 jogos clássicos e 576 jogos para Game Boy Color
1049 jogos clássicos e 576 jogos para Game Boy ColorNo total, mais de 1000 jogos, uma variedade muito ampla, de alta qualidade, alguns deles são bastante complexos (Prince), os jogos podem ser agrupados e atribuídos complexidade à pesquisa sobre transferência de conhecimento e treinamento (por exemplo, existem opções para Tetris, jogos de corrida, Mario). Para resolver o jogo Prince of Persia, pode ser necessário transferir conhecimento de outro jogo similar no qual os pontos são claramente indicados (no Prince isso não é).
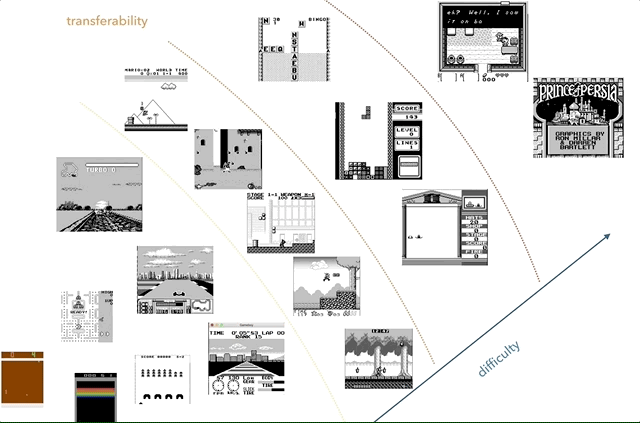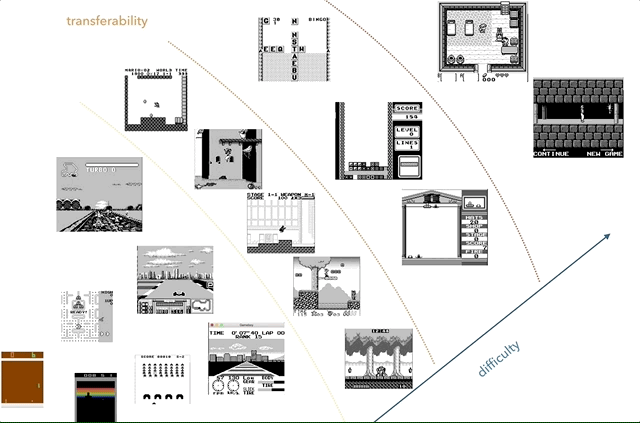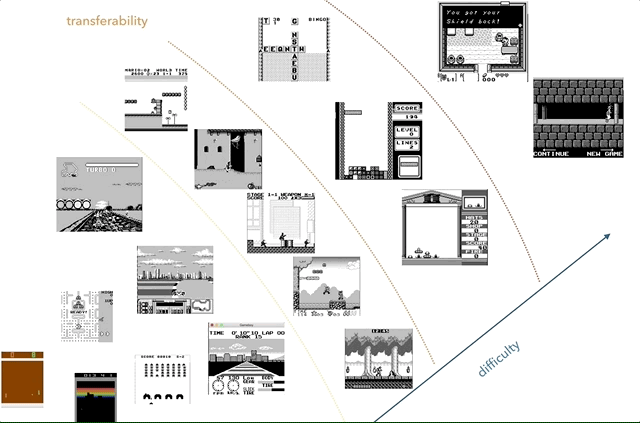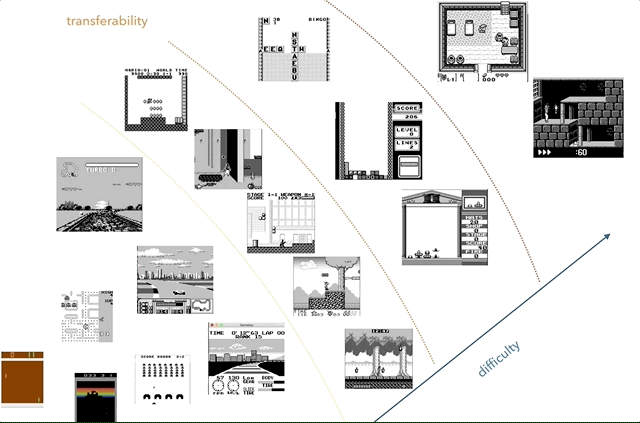 O Nintendo Game Boy é minha plataforma de pesquisa de transferência de conhecimento favorita. No gráfico, tentei agrupar os jogos de acordo com a complexidade (subjetiva) e semelhança (conceitos como corrida, salto, tiro, vários jogos como Tetris; alguém jogou HATRIS?).
O Nintendo Game Boy é minha plataforma de pesquisa de transferência de conhecimento favorita. No gráfico, tentei agrupar os jogos de acordo com a complexidade (subjetiva) e semelhança (conceitos como corrida, salto, tiro, vários jogos como Tetris; alguém jogou HATRIS?).O Game Boy clássico tem uma tela muito simples (160x144, cor de 2 bits), para que o pré-processamento se torne simples e você possa se concentrar em coisas importantes. Em 2600, até jogos simples têm muitas cores. Além disso, no Game Boy, os objetos são demonstrados muito melhor, sem piscar e sem a necessidade de tirar no máximo dois quadros consecutivos.

Nenhum layout de memória maluco, como o NES ou o 2600. A maioria dos jogos pode ser feita para trabalhar com 2-3 mapeadores.
Código compacto - eu consegui ajustar o emulador inteiro em C em não mais de 700 linhas de código, e minha implementação Verilog se encaixa em 500 linhas.
Existe a mesma versão simples do Space Invaders como no arcade.
E aqui está ele, meu Game Boy de matriz de 1989 e a versão FPGA que funciona via HDMI em uma tela 4K.

E aqui está o que meu velho Game Boy não pode:
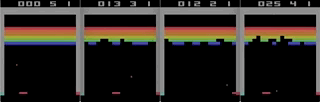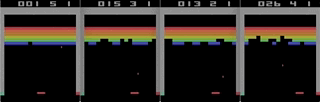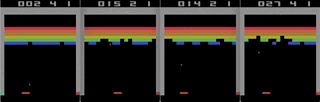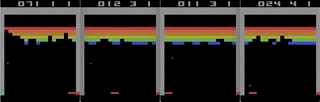
 Tetris acelerado com ferro - gravando a partir da tela em tempo real, a velocidade é 1/4 da máxima.
Tetris acelerado com ferro - gravando a partir da tela em tempo real, a velocidade é 1/4 da máxima.Existe algum benefício real nisso?
Sim existe. Até agora, testei o sistema em condições simples, com uma rede externa de regras que interage com os Game Boys individuais. Mais especificamente, usei o algoritmo A3C (Advantage Actor Critic) e pretendo descrevê-lo em um post separado. Meu colega o conectou à rede convolucional no FPGA e funciona.
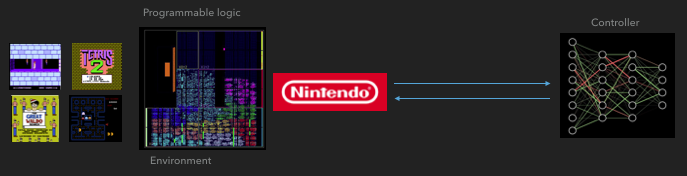 Como o FGPA se comunica com uma rede neural
Como o FGPA se comunica com uma rede neural A3C distribuído
A3C distribuído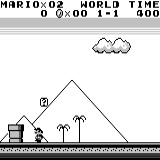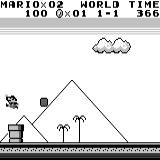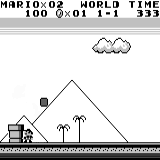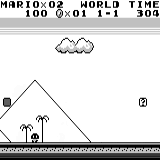 Mario land: condição inicial. Um toque de tecla aleatório não nos levará longe. O canto superior direito mostra o tempo restante. Se tivermos sorte, terminaremos rapidamente o jogo depois de tocar na gumba. Caso contrário, serão necessários 400 segundos para "perder".
Mario land: condição inicial. Um toque de tecla aleatório não nos levará longe. O canto superior direito mostra o tempo restante. Se tivermos sorte, terminaremos rapidamente o jogo depois de tocar na gumba. Caso contrário, serão necessários 400 segundos para "perder".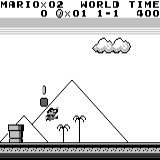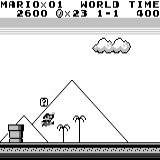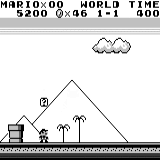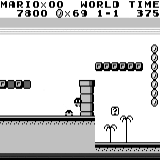 Mario terra: depois de uma hora de jogo, Mario aprendeu a correr, pular e até abriu uma sala secreta, rastejando em um cano.
Mario terra: depois de uma hora de jogo, Mario aprendeu a correr, pular e até abriu uma sala secreta, rastejando em um cano. Pac Man: após cerca de uma hora de treinamento, a rede neural foi capaz de terminar o jogo inteiro uma vez (depois de comer todos os pontos).
Pac Man: após cerca de uma hora de treinamento, a rede neural foi capaz de terminar o jogo inteiro uma vez (depois de comer todos os pontos).Conclusão
Eu gostaria de pensar que a próxima década será o período em que a supercomputação e a IA se encontrarão. Eu gostaria de ter um hardware que me permita me ajustar a um determinado nível para me adaptar ao algoritmo de IA desejado.
 Próxima décadaCódigo para Game Boy em C.
Próxima décadaCódigo para Game Boy em C.Depuração
As pessoas costumam me perguntar: qual foi a mais difícil? É isso aí - todo o projeto foi bastante doloroso. Para iniciantes, não há especificação para um Game Boy. Tudo o que aprendemos, conseguimos graças à engenharia reversa, ou seja, lançamos uma tarefa intermediária, como um jogo, e observamos como ela é realizada. Isso é muito diferente da depuração de software padrão, porque aqui depuramos o hardware que executa os programas. Eu tive que inventar maneiras diferentes de conseguir isso. E eu falei sobre o quão difícil é monitorar um processo quando ele é executado a uma frequência de 100 MHz? Ah, e não há impressão lá.
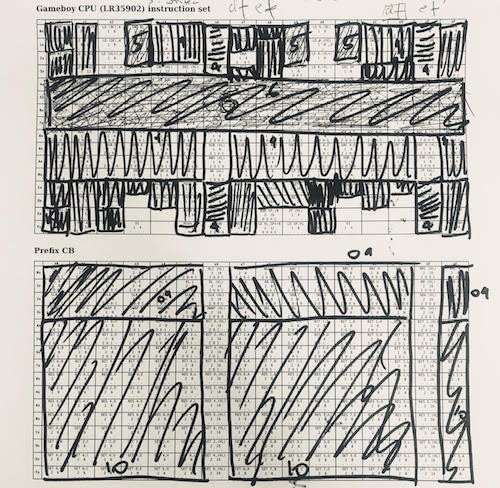 Uma abordagem para implementar uma CPU é agrupar instruções sobre suas funções. Com o 6502, é muito mais fácil. O LR35092 abarrotou muitas bobagens "aleatórias" e há muitas exceções. Eu usei essa tabela ao trabalhar com o CPU Game Boy. Usei uma estratégia gananciosa - peguei as maiores instruções, as implementei e as apaguei, depois as repeti. 1/4 das instruções é ALU, 1/4 é o carregamento do registro, que pode ser implementado rapidamente. Do outro lado do espectro, existem todos os tipos de coisas separadas, como “fazer upload de HL para SP com um sinal”, que precisavam ser processadas separadamente.
Uma abordagem para implementar uma CPU é agrupar instruções sobre suas funções. Com o 6502, é muito mais fácil. O LR35092 abarrotou muitas bobagens "aleatórias" e há muitas exceções. Eu usei essa tabela ao trabalhar com o CPU Game Boy. Usei uma estratégia gananciosa - peguei as maiores instruções, as implementei e as apaguei, depois as repeti. 1/4 das instruções é ALU, 1/4 é o carregamento do registro, que pode ser implementado rapidamente. Do outro lado do espectro, existem todos os tipos de coisas separadas, como “fazer upload de HL para SP com um sinal”, que precisavam ser processadas separadamente. Depuração: execute o código no hardware que você está depurando, anote o log da sua implementação e informações adicionais (isso mostra uma comparação do código Verilog à esquerda com o meu emulador C à direita). Em seguida, execute diff nos logs para encontrar inconsistências (azul). Uma das razões para usar a automação é que, em muitos casos, encontrei problemas após milhões de ciclos de execução quando um único sinalizador de CPU causava um efeito de bola de neve. Eu tentei várias abordagens, e essa acabou sendo a mais eficaz.
Depuração: execute o código no hardware que você está depurando, anote o log da sua implementação e informações adicionais (isso mostra uma comparação do código Verilog à esquerda com o meu emulador C à direita). Em seguida, execute diff nos logs para encontrar inconsistências (azul). Uma das razões para usar a automação é que, em muitos casos, encontrei problemas após milhões de ciclos de execução quando um único sinalizador de CPU causava um efeito de bola de neve. Eu tentei várias abordagens, e essa acabou sendo a mais eficaz. Você vai precisar de muito café!
Você vai precisar de muito café! Estes livros têm 40 anos. Foi incrível vasculhá-los e ver o mundo dos computadores através dos olhos daqueles usuários da época - eu me senti como um convidado do futuro.
Estes livros têm 40 anos. Foi incrível vasculhá-los e ver o mundo dos computadores através dos olhos daqueles usuários da época - eu me senti como um convidado do futuro.Pedido de Pesquisa OpenAI
No começo, eu queria trabalhar com jogos em termos de memória, conforme descrito em um
post da OpenAI.
Surpreendentemente, conseguir que o Q-learning funcione bem em entradas que representam estados de memória foi inesperadamente difícil.
Este projeto pode não ter uma solução. Seria inesperado descobrir que o Q-learning nunca conseguirá trabalhar com memória no Atari, mas há chances de que essa tarefa seja bastante difícil.
Considerando que os jogos no Atari usavam apenas 128 b de memória, parecia muito atraente processar esses 128 b em vez de quadros em tela cheia. Eu obtive resultados mistos, então comecei a descobrir.
E embora eu não possa provar que é impossível aprender com a memória, posso mostrar que a suposição de que a memória reflete o estado completo do jogo está errada. A CPU Atari 2600 (6507) usa 128 b de memória, mas ainda tem acesso a registros adicionais que vivem em um circuito separado (TIA, um adaptador para uma TV, algo como uma GPU). Esses registros são usados para armazenar e processar informações sobre objetos (raquete, foguete, bola, colisão). Em outras palavras, eles estarão inacessíveis se considerarmos apenas a memória. O NES e o Game Boy também têm registros adicionais que são usados para controlar a tela e rolar. Apenas uma memória não reflete o estado completo do jogo.
Somente o 8080 armazena dados diretamente na memória de vídeo, o que permite extrair todo o estado do jogo. Em outros casos, os registros "GPU" são conectados entre a CPU e o buffer de tela, enquanto estão fora da RAM.
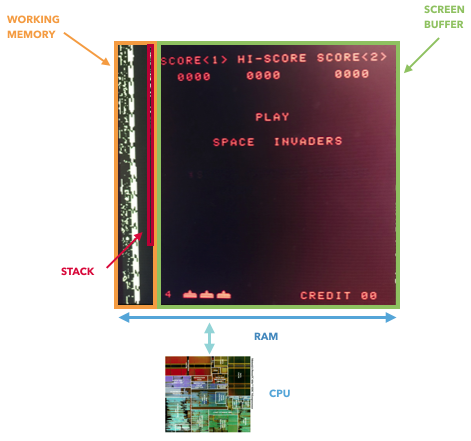
Um fato interessante: se você realizar pesquisas sobre a história da GPU, o 8080 pode ser o primeiro "acelerador gráfico" - ele possui um registro de deslocamento externo que permite mover invasores do espaço com um único comando, que descarrega a CPU.

Eof