Oi Eu sou Dima e estou sentado em Python há algum tempo. Hoje, quero mostrar as diferenças entre duas estruturas assíncronas - Tornado e Aiohttp. Vou contar a história da escolha entre as estruturas do nosso projeto, como as corotinas do Tornado e do AsyncIO diferem. Mostrarei benchmarks e darei algumas dicas úteis sobre como entrar na natureza das estruturas e sair com êxito.

Como você sabe, o Avito é um serviço de anúncios bastante grande. Temos muitos dados e carga, 35 milhões de usuários todos os meses e 45 milhões de anúncios ativos diariamente. Trabalho como consultor técnico de um grupo de desenvolvimento de recomendações. Minha equipe escreve microsserviços, agora temos cerca de vinte deles. Uma carga está acumulando tudo isso - como 5k RPS.
Escolhendo uma estrutura assíncrona
Primeiro, vou contar como acabamos onde estamos agora. Em 2015, precisávamos escolher uma estrutura assíncrona, porque sabíamos:
- que você precisa fazer muitas solicitações para outros microsserviços: http, json, rpc;
- que você precisará coletar dados de diferentes fontes o tempo todo: Redis, Postgres, MongoDB.
Assim, temos muitas tarefas de rede e o aplicativo é ocupado principalmente com entrada / saída. A versão atual do python na época era 3.4, assíncrona e aguardada ainda não apareceu. Aiohttp também estava - na versão 0.x. O Tornado Assíncrono do Facebook apareceu em 2010. Muitos drivers de banco de dados foram escritos para ele que precisamos. O Tornado apresentou resultados estáveis nos benchmarks. Então paramos a nossa escolha nesse quadro.
Três anos depois, entendemos muito.
Primeiro, o Python 3.5 foi lançado com mecânica assíncrona / aguardada. Nós descobrimos qual é a diferença entre rendimento e rendimento e como o Tornado é consistente com aguardar (spoiler: não muito bom).
Em segundo lugar, encontramos problemas estranhos de desempenho com uma grande quantidade de corotina no agendador, mesmo quando a CPU não está totalmente ocupada.
Em terceiro lugar, descobrimos que, ao executar um grande número de solicitações HTTP para outros serviços Tornado, você precisa ser especialmente amigável com o resolvedor de DNS assíncrono, ele não respeita os tempos limite para estabelecer uma conexão e enviar a solicitação que especificamos. E, em geral, o melhor método para fazer solicitações HTTP no Tornado é o curl, o que é bastante estranho por si só.
Em sua
palestra na PyCon Russia 2018, Andrei Svetlov disse: “Se você deseja escrever algum tipo de aplicativo Web assíncrono, basta escrever em assíncrono, aguarde. Event loop, provavelmente, você não precisará disso em breve. Não entre na natureza dos frameworks para não ficar confuso. Não use primitivas de baixo nível, e tudo ficará bem com você ... ". Nos últimos três anos, infelizmente, tivemos que entrar no Tornado com bastante frequência, aprender muitas coisas interessantes a partir daí e ver tracebacks gigantes para chamadas de 30 a 40.
Rendimento vs rendimento de
Um dos maiores problemas para entender em python assíncrono é a diferença entre rendimento de e rendimento.
Guido Van Rossum escreveu mais sobre isso. Estou anexando a tradução com pequenas abreviações.
Já me perguntaram várias vezes por que o PEP 3156 insiste em usar yield-from em vez de yield, o que exclui a possibilidade de backport no Python 3.2 ou mesmo 2.7.
(...)
sempre que você quiser um resultado futuro, use o rendimento.
Isso é implementado da seguinte maneira. A função que contém yield é (obviamente) um gerador, portanto deve haver algum tipo de código iterativo. Vamos chamá-lo de planejador. De fato, o planejador não “itera” no sentido clássico (com loop for); em vez disso, ele suporta duas coleções futuras.
Vou chamar a primeira coleção de uma sequência "executável". Este é o futuro, cujos resultados estão disponíveis. Enquanto essa lista não estiver vazia, o planejador seleciona um item e executa uma etapa da iteração. Esta etapa chama o método gerador .send () com o resultado do futuro (que pode ser dados que acabaram de ser lidos do soquete); no gerador, esse resultado aparece como o valor de retorno da expressão de rendimento. Quando send () retorna um resultado ou é concluído, o planejador analisa o resultado (que pode ser StopIteration, outra exceção ou algum tipo de objeto).
(Se você está confuso, provavelmente deveria ler sobre como os geradores funcionam, em particular o método .send (). Talvez o PEP 342 seja um bom ponto de partida).
(...)
a segunda coleção futura suportada pelo planejador consiste no futuro, que ainda aguarda E / S. Eles são de alguma forma passados para o select / poll / shell etc. que fornece um retorno de chamada quando o descritor de arquivo está pronto para E / S. O retorno de chamada realmente executa a operação de E / S solicitada pelo futuro, define o valor futuro resultante para o resultado da operação de E / S e move o futuro para a fila de execução.
(...)
Agora chegamos ao mais interessante. Suponha que você esteja escrevendo um protocolo complexo. Dentro do seu protocolo, você lê bytes de um soquete usando o método recv (). Esses bytes chegam ao buffer. O método recv () é envolvido em um shell assíncrono, que define a E / S e retorna o futuro, que é executado quando a E / S é concluída, como expliquei acima. Agora, suponha que alguma outra parte do seu código deseje ler dados do buffer, uma linha por vez. Suponha que você tenha usado o método readline (). Se o tamanho do buffer for maior que o comprimento médio da linha, seu método readline () poderá simplesmente obter a próxima linha do buffer sem bloquear; mas às vezes o buffer não contém uma linha inteira, e o readline (), por sua vez, chama recv () no soquete.
Pergunta: readline () deve retornar futuro ou não? Não seria muito bom se ele às vezes retornasse uma sequência de bytes e, às vezes, futuro, forçando o chamador a executar verificação de tipo e rendimento condicional. Portanto, a resposta é que readline () deve sempre retornar o futuro. Quando readline () é chamado, ele verifica o buffer e, se encontrar pelo menos uma linha inteira, cria um futuro, define o resultado futuro de uma linha retirada do buffer e retorna futuro. Se o buffer não tiver uma linha inteira, ele iniciará a E / S e a esperará e, quando a E / S estiver concluída, será iniciada novamente.
(...)
Mas agora estamos criando muitos futuros que não exigem bloqueio de E / S, mas ainda forçam uma chamada ao agendador, porque readline () retorna o futuro, o rendimento é necessário ao chamador e isso significa uma chamada ao agendador.
O planejador pode transferir o controle diretamente para a corotina se perceber que o futuro, que já foi concluído, é exibido ou pode retornar o futuro à fila de execução. Este último desacelerará bastante o trabalho (desde que exista mais de uma corrotina executável), já que não apenas a espera no final da fila é necessária, mas a localidade da memória (se houver) provavelmente também está perdida.
(...)
O efeito final de tudo isso é que os autores da corotina precisam saber sobre o futuro da produção e, portanto, há uma barreira psicológica maior para reorganizar o código complexo em corotinas mais legíveis - muito mais fortes que a resistência existente, porque as chamadas de função no Python são muito lentas. E lembro-me de uma conversa com a Glyph que a velocidade é importante em uma estrutura de E / S assíncrona típica.
Agora vamos comparar isso com yield-from.
(...)
Você deve ter ouvido falar que “rendimento de S” é aproximadamente equivalente a “para i em S: rendimento i”. No caso mais simples, isso é verdade, mas isso não é suficiente para entender a rotina. Considere o seguinte (ainda não pense em E / S assíncrona):
def driver(g): print(next(g)) g.send(42) def gen1(): val = yield 'okay' print(val) driver(gen1())
Esse código imprime duas linhas contendo "okay" e "42" (e produz uma StopIteration sem tratamento, que você pode suprimir adicionando rendimento no final de gen1). Você pode ver esse código em ação no pythontutor.com no link .
Agora considere o seguinte:
def gen2(): yield from gen1() driver(gen2())
Funciona exatamente da mesma maneira . Agora pense. Como isso funciona? A extensão simples de produção no loop for não pode ser usada aqui, pois nesse caso o código retornaria None. (Experimente) . O rendimento de atua como um "canal transparente" entre driver e gen1. Ou seja, quando gen1 fornece o valor "ok", ele sai do gen2, através do yield-from, para o driver, e quando o driver envia 42 de volta ao gen2, esse valor é retornado novamente através do yield-from para o gen1 novamente (onde se torna o resultado do yield )
O mesmo aconteceria se o motorista lançasse um erro no gerador: o erro passa pelo rendimento do gerador interno que o processa. Por exemplo:
def throwing_driver(g): print(next(g)) g.throw(RuntimeError('booh')) def gen1(): try: val = yield 'okay' except RuntimeError as exc: print(exc) else: print(val) yield throwing_driver(gen1())
O código fornecerá "okay" e "bah", além do seguinte código:
def gen2(): yield from gen1()
(Veja aqui: goo.gl/8tnjk )
Agora, eu gostaria de apresentar gráficos simples (ASCII) para poder falar sobre esse tipo de código. Eu uso [f1 -> f2 -> ... -> fN) para representar a pilha com f1 na parte inferior (quadro de chamada mais antiga) e fN na parte superior (quadro de chamada mais recente), onde cada item da lista é um gerador e -> são rendimentos . O primeiro exemplo, driver (gen1 ()), não tem rendimento, mas possui um gerador gen1; portanto, é parecido com isto:
[ gen1 )
No segundo exemplo, gen2 chama gen1 usando yield-from, então fica assim:
[ gen2 -> gen1 )
Uso a notação matemática para o intervalo semi-aberto [...] para mostrar que outro quadro pode ser adicionado à direita quando o gerador mais à direita usa yield-from para chamar outro gerador, enquanto a extremidade esquerda é mais ou menos fixa. O final esquerdo é o que o motorista vê (ou seja, o agendador).
Agora estou pronto para retornar ao exemplo readline (). Podemos reescrever o readline () como um gerador que chama read (), outro gerador usando yield-from; o último, por sua vez, chama recv (), que faz a entrada / saída real do soquete. À nossa esquerda está o aplicativo, que também consideramos um gerador que chama readline (), novamente usando yield-from. O esquema é o seguinte:
[ app -> readline -> read -> recv )
Agora, o gerador recv () define E / S, liga-o ao futuro e o passa para o planejador usando * yield * (não yield-from!). O futuro vai para a esquerda, ao longo das duas setas de retorno do agendador (localizado à esquerda de "["). Observe que o planejador não sabe que contém uma pilha de geradores; tudo o que sabe é que ele contém o gerador mais à esquerda e que acaba de lançar um futuro. Quando a E / S é concluída, o planejador define o resultado futuro e o envia de volta ao gerador; o resultado se move para a direita, ao longo das duas flechas "Yiled-from" para o gerador de recv, que recebe os bytes que deseja ler do soquete como resultado da produção.
Em outras palavras, o planejador de estrutura yield-from manipula operações de E / S, exatamente como o planejador de estrutura baseado em rendimento que eu descrevi anteriormente. * Mas: * ele não precisa se preocupar com otimização quando o futuro já estiver executado, pois o planejador não participa da transferência de controle entre readline () e read () ou entre read () e recv () e vice-versa. Portanto, o planejador não participa quando o aplicativo () chama readline () e readline () pode atender à solicitação do buffer (sem chamar read ()) - a interação entre app () e readline () nesse caso é completamente processada pelo interpretador de bytecode Python O planejador pode ser mais simples, e o número de futuros criados e gerenciados pelo planejador é menor, porque não existem futuros criados e destruídos a cada chamada de corotina. O único futuro que ainda é necessário são aqueles que representam a E / S real, por exemplo, criada por recv ().
Se você leu até este ponto, merece uma recompensa. Omiti muitos detalhes da implementação, mas a ilustração acima reflete corretamente a imagem.
Outra coisa que eu gostaria de destacar. * Você pode * fazer parte do código usar yield-from e a outra parte usar yield. Mas o rendimento exige que todo elo da cadeia tenha um futuro, não apenas uma rotina. Como existem várias vantagens em usar o yield-from, desejo que o usuário não precise se lembrar de quando usar yield e, quando yield-from, é mais fácil sempre usar o yield-from. Uma solução simples ainda permite que recv () use yield-from para passar E / S futuras para o planejador: o método __iter__ é realmente o gerador que o futuro emite.
(...)
E mais uma coisa. Qual valor o retorno de retorno? Acontece que este é o valor de retorno do gerador * externo *.
(...)
Assim, embora as setas vinculem os quadros esquerdo e direito ao destino * produtivo *, eles também passam os valores de retorno usuais da maneira usual, um quadro de pilha por vez. Exceções são movidas da mesma maneira; é claro que, em cada nível, é necessário tentar / exceto para capturá-los.
Acontece que o rendimento é praticamente o mesmo que aguardar.
rendimento de vs assíncrono
def coro () ^ y = rendimento de um | async def async_coro (): y = aguarde um |
| 0 load_global | 0 load_global |
| 2 get_yield_from_iter | 2 get_awaitable |
| 4 load_const | 4 load_const |
| 6 rendimento_de | 6 rendimento_de |
| 8 store_fast | 8 store_fast |
| 10 load_const | 10 load_const
|
| 12 return_value | 12 return_value |
As duas corotinas das antigas e das novas escolas têm apenas uma pequena diferença: obter rendimento do iter versus esperar.
Por que isso é tudo? Tornado usa um rendimento simples. Antes da versão 5, ele conecta toda essa cadeia de chamadas através de rendimento, que é pouco compatível com o novo rendimento legal do paradigma / aguarda.
O benchmark assíncrono mais simples
É difícil encontrar uma estrutura realmente boa, escolhendo-a apenas de acordo com testes sintéticos. Na vida real, muitas coisas podem dar errado.
Peguei o Aiohttp versão 3.4.4, Tornado 5.1.1, uvloop 0.11, peguei o processador do servidor Intel Xeon, CPU E5 v4, 3.6 GHz, e nele com o Python 3.6.5 comecei a verificar a competitividade dos servidores web.
O problema típico que resolvemos com a ajuda de microsserviços e que funciona no modo assíncrono é semelhante a este. Nós receberemos pedidos. Para cada um deles, faremos uma solicitação para algum microsserviço, obteremos os dados a partir daí, acessaremos outros dois ou três microsserviços, também de forma assíncrona, em seguida, gravaremos os dados em algum lugar no banco de dados e retornaremos o resultado. Acontece muitos pontos em que vamos esperar.
Realizamos uma operação mais simples. Ligamos o servidor, dormimos 50 ms. Crie uma rotina e complete-a. Não teremos um RPS muito grande (pode não ser uma ordem de magnitude semelhante à que é vista em benchmarks totalmente sintéticos) com um atraso aceitável, devido ao fato de que muitas corotinas girarão simultaneamente em um servidor competitivo.
@tornado.gen.coroutine def old_school_work(): yield tornado.gen.sleep(SLEEP_TIME) async def work(): await tornado.gen.sleep(SLEEP_TIME)
Carregar - GET solicitações http. Duração - 300s, 1s - aquecimento, 5 repetições da carga.
 Resultados em percentis de tempo de resposta do serviço.
Resultados em percentis de tempo de resposta do serviço.O que são percentis?Você tem um grande número de números. O 95º percentil X significa que 95% dos valores nesta amostra são menores que X. Com uma probabilidade de 5%, seu número será maior que X.
Vimos que o Aiohttp fez um bom trabalho a 1000 RPS em um teste tão simples. Tudo até agora sem
uvloop .
Compare Tornado com as corotinas das escolas antigas (rendimento) e novas (assíncronas). Os autores recomendam fortemente o uso assíncrono. Podemos garantir que eles sejam realmente muito mais rápidos.
A 1200 RPS, o Tornado, mesmo com as novas corotinas da escola, já está começando a desistir, e o Tornado com as corotinas da velha escola está completamente deslumbrado. Se dormimos por 50 ms, e o microsserviço é responsável por 80 ms - isso não entra em nenhuma porta.
A nova escola do Tornado, com 1.500 RPS, desistiu completamente, enquanto o Aiohttp ainda está longe do limite de 3.000 RPS. O mais interessante ainda está por vir.
Pyflame, criando um perfil de microsserviço em funcionamento
Vamos ver o que está acontecendo neste momento com o processador.

Quando descobrimos como os microsserviços assíncronos do Python funcionam na produção, tentamos entender o que isso significava. Na maioria dos casos, o problema estava na CPU ou nos descritores. Existe uma excelente ferramenta de criação de perfil criada no Uber, o
criador de perfil
Pyflame , que é baseado na chamada do sistema ptrace.
Iniciamos algum serviço no contêiner e começamos a lançar uma carga de combate nele. Freqüentemente, essa não é uma tarefa muito trivial - criar exatamente uma carga que está em batalha, porque geralmente acontece que você executa testes sintéticos em testes de carga, olha e tudo funciona bem. Você empurra a carga de combate contra ele, e aqui o microsserviço começa a embotar.
Durante a operação, esse criador de perfil faz instantâneos da pilha de chamadas para nós. Você não pode alterar o serviço, basta executar o pyflame nas proximidades. Ele coletará um rastreamento de pilha uma vez em um determinado período de tempo e, em seguida, fará uma visualização interessante. Esse criador de perfil fornece muito pouca sobrecarga, especialmente quando comparado ao cProfile. O Pyflame também suporta programas multithread. Lançamos essa coisa diretamente no produto, e o desempenho não diminuiu muito.
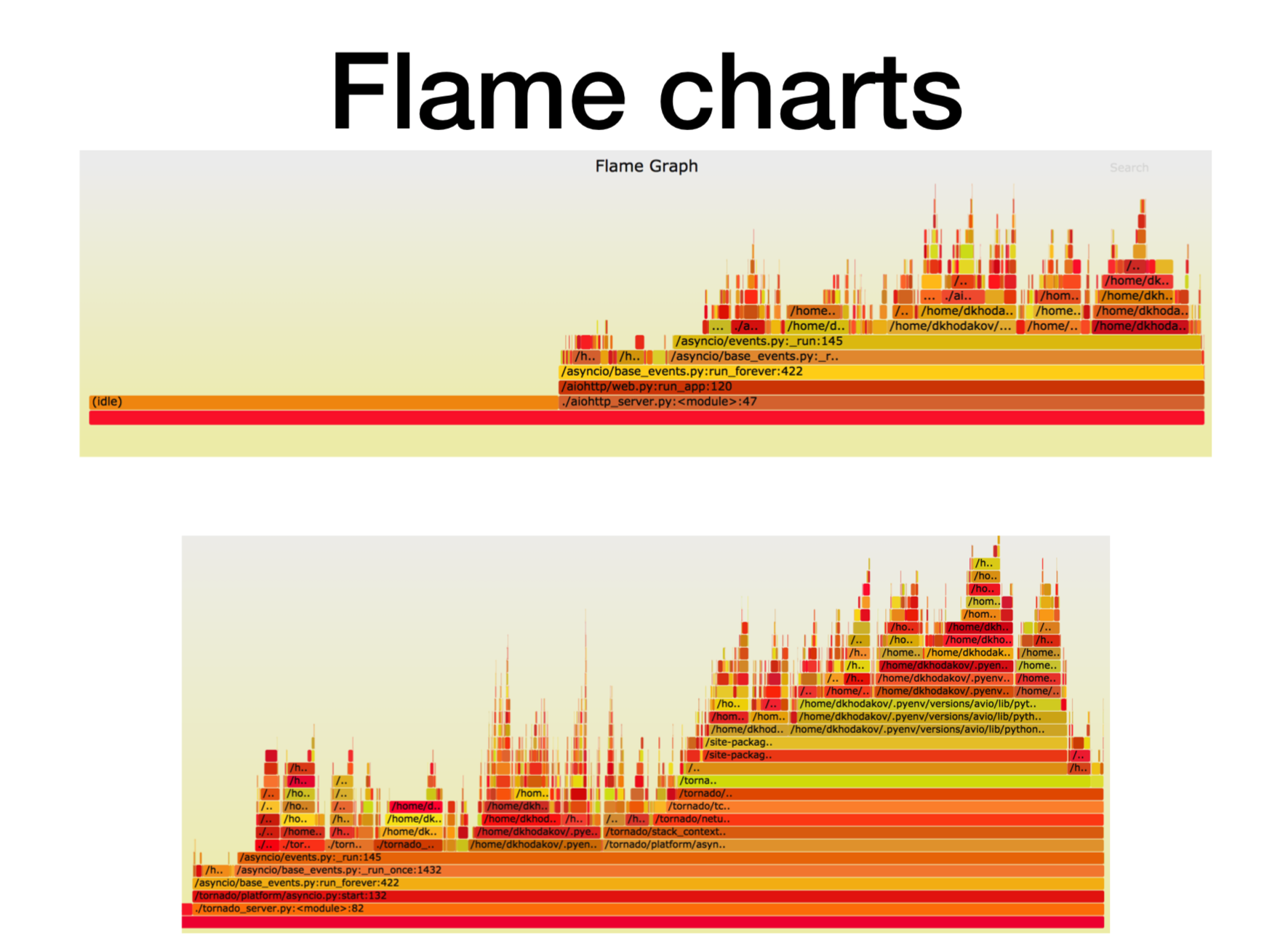
Aqui, o eixo X é a quantidade de tempo, o número de chamadas, quando o quadro de pilha estava na lista de todos os quadros de pilha Python. Essa é a quantidade aproximada de tempo do processador que gastamos nesse quadro específico da pilha.
Como você pode ver, aqui a maior parte do tempo no aiohttp fica ocioso. Tudo bem: é isso que queremos de um serviço assíncrono, para que ele lide com chamadas de rede na maioria das vezes. A profundidade da pilha neste caso é de cerca de 15 quadros.
No Tornado (segunda imagem) com a mesma carga, gasta-se muito menos tempo no modo inativo e a profundidade da pilha nesse caso é de cerca de 30 quadros.
Aqui está um
link para svg , você pode se torcer.
Referência assíncrona mais complexa
async def work():
Espere um tempo de execução de 125 ms.

Tornado com uvloop aguenta-se melhor. Mas o Aiohttp uvloop ajuda muito mais. O Aiohttp começa a se comportar mal em 2300-2400 RPS e, com o uvloop, expande significativamente a faixa de carga. Uma linha de importação e agora você tem um serviço muito mais produtivo.
Sumário
Resumirei o que queria transmitir a você hoje.
- Em primeiro lugar, lancei um determinado parâmetro de referência artificial, onde havia uma quantidade decente de longa rotina. Em nosso teste, o Aiohttp teve um desempenho melhor 2,5 vezes do que o Tornado.
- O segundo fato. O Uvloop ajuda muito a melhorar o desempenho do Aiohttp (melhor que o Tornado).
- Eu falei sobre o Pyflame, com o qual frequentemente perfilamos o aplicativo diretamente na produção.
- E também falamos sobre rendimento de (aguardar) versus rendimento.
Como resultado desses benchmarks, nossa equipe de recomendações (e algumas outras) quase mudou completamente para Aiohttp with Tornado para microsserviços em Python em produção.
- Para serviços de combate, o consumo de CPU caiu mais de 2 vezes.
- Começamos a respeitar o tempo limite para solicitações de http.
- Os serviços de latência caíram 2 a 5 vezes.
Aqui está um
link para o benchmark . Se estiver interessado, você pode repeti-lo. Obrigado a todos pela atenção. Faça perguntas, tentarei respondê-las.