Amigos, no final de janeiro, iniciaremos um novo curso chamado "MS SQL Server Developer ". Antecipando seu lançamento, pedimos à professora do curso, Kristina Kucherova , que preparasse um artigo de autor. Este artigo será útil se você tiver uma tabela muito popular no produto com acesso 24 horas por dia, 7 dias por semana e, de repente, perceberá que precisa urgentemente adicionar um índice e não interromper nada no processo.Então o que fazer? O método tradicional CREATE INDEX WITH (ONLINE = ON) não é adequado para você, porque, por exemplo, causa uma falha no sistema e um ataque cardíaco do seu DBA, todas as partes superiores monitoram atentamente o tempo de resposta do seu sistema e, se aumentar, eles procuram você e seu DBA para conversar sobre os valores superestimados da sua remuneração pelo trabalho.
Os scripts e as técnicas descritas foram usadas em um sistema com uma carga de 400 mil solicitações por minuto, versões do SQL Server 2012 e 2016 (Enterprise).
Existem duas abordagens muito diferentes para criar um índice, que são usadas dependendo do tamanho da tabela.
Caso nº 1. Uma mesa pequena, mas muito popular
Uma tabela de 50 mil registros (pequeno), mas muito popular (vários milhares de acessos por minuto). Você precisa de um novo índice e um tempo de inatividade mínimo e bloqueios na mesa.
No aplicativo, todo acesso ao banco de dados é apenas através de procedimentos.
Se ocorrer um erro, o aplicativo tentará acessar a tabela novamente.

Qual é o problema de aplicar esse índice simplesmente, você pergunta? Com a frase WITH ONLINE = ON (sim, tivemos sorte, e este foi Enterprise).
O fato é que, com esse acesso ativo, leva algum tempo para obter um bloqueio (mesmo o mínimo necessário com a opção with Online = ON). No processo de espera, novas solicitações são enfileiradas, a fila está se acumulando, a CPU está crescendo, o DBA está suando e apertando os olhos nervosamente em direção aos desenvolvedores, enquanto nos gráficos de monitoramento de aplicativos seu tempo de resposta começa a aumentar sem problemas, mas inevitavelmente. Seu vice-presidente de engenharia está interessado em saber se, devido a esse aumento no tempo de resposta, haverá algum tipo de tempo de inatividade do sistema, que, no final do ano, a disponibilidade do aplicativo será estimada em não cinco (99.999), mas menor? E então a empresa possui contratos, obrigações e multas pesadas em caso de disponibilidade reduzida e, é claro, não esqueceremos as perdas de reputação.
O que fizemos para evitar essa situação infeliz?
O sistema ainda precisa de um índice.
Eles assumiram os direitos de todos, exceto a sessão atual nesta tabela.
Aplique o índice.
Sim, a solução tem um sinal de menos: todos que se voltaram para a mesa nesses segundos receberão acesso negado. Se seu aplicativo normalmente lida com essa situação e repete a consulta no banco de dados, você deve examinar mais de perto essa opção. No caso do nosso projeto, esse método funcionou bem. Novamente, você pode remover com segurança ONLINE = ON, pois sabemos que apenas a sessão terá acesso à tabela durante a criação do índice.
Código para aplicação do índice:
REVOKE EXECUTE ON [dbo].[spUserLogin] TO [User1] REVOKE EXECUTE ON [dbo].[spUserLogin] TO [User2] REVOKE EXECUTE ON [dbo].[spUserCreate] TO [User1] REVOKE EXECUTE ON [dbo].[spUserCreate] TO [User2] CREATE NONCLUSTERED INDEX IX_Users_Email_Status ON [dbo].[Users] ([Email],[Status]); GRANT EXECUTE ON [dbo].[spUserCreate] TO [User1] GRANT EXECUTE ON [dbo].[spUserCreate] TO [User2] GRANT EXECUTE ON [dbo].[spUserLogin] TO [User1] GRANT EXECUTE ON [dbo].[spUserLogin] TO [User2]
Programação do tempo de resposta e porcentagem de erros durante o teste sob carga.
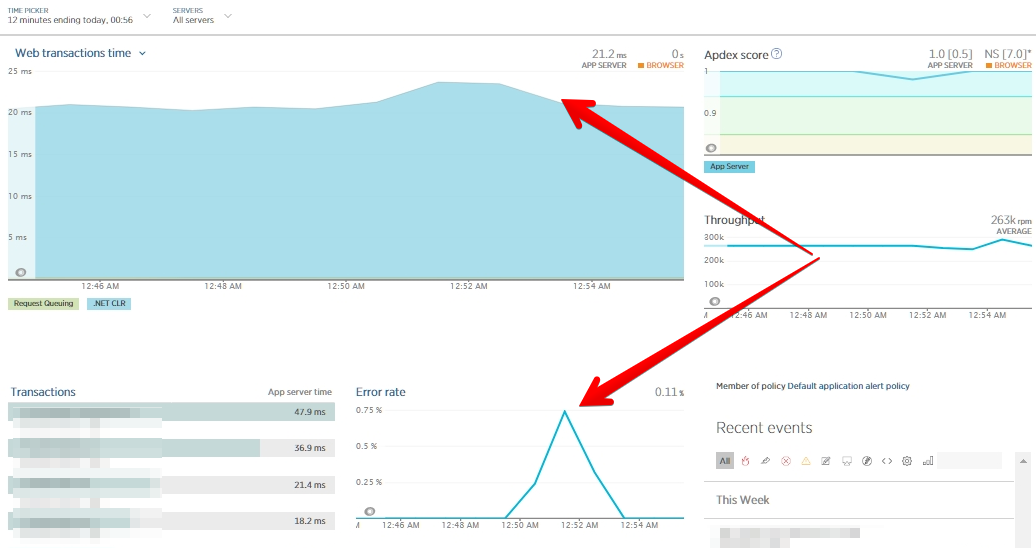
O método pode ser aplicado se, como no caso descrito, você tiver uma tabela pequena e souber que, sem carga, o índice será criado em segundos (ou em um tempo aceitável para você). Ao mesmo tempo, como você pode ver no gráfico acima, o tempo de resposta do aplicativo não aumentará, embora seja possível observar que a taxa de erro em segundos sem acesso à tabela foi maior.
Caso nº 2. Mesa grande
Se você possui uma tabela grande e precisa alterar os índices, geralmente a maneira mais simples de vender é criar uma tabela ao lado dela com o índice correto e transferir gradualmente os dados para uma nova tabela.
Existem 2 maneiras:
- Se você possui um procedimento especial para modificar uma tabela, basta alterar o código do procedimento para que novos dados sejam inseridos apenas na nova tabela, a exclusão é de ambos, a atualização também foi aplicada a ambos e a seleção foi feita a partir de duas tabelas com UNION ALL.
- Se houver muitas partes diferentes do código nas quais é possível alterar os dados na tabela, existem dois truques populares: exibir com gatilhos ou reescrever todas as partes do código para inserir dados em uma nova tabela, excluir das duas e atualizar as duas tabelas. Uma visualização com gatilhos é uma opção quando você cria uma visualização com duas tabelas e a renomeia, renomeia sua tabela atual para TableOld e visualiza para Tabela. Em seguida, você recebe automaticamente todas as chamadas de tabela para a visualização. Aqui, com a renomeação, também pode haver um problema, porque o SchemaLock é necessário, mas a renomeação passa muito rapidamente.
Uma versão um pouco mais detalhada sobre a reescrita de chamadas para uma nova tabela:
- Você tem a tabela Pedidos, crie uma nova tabela PedidosNovo com o mesmo esquema, mas com o índice desejado. Ao mesmo tempo, se você usar Indentity, precisará definir o primeiro valor da identidade na nova tabela como igual ao valor máximo da tabela antiga + a etapa da mudança ou a diferença que você pode se desviar do valor máximo em Pedidos.
- Crie um OrdersView, dentro do qual uma seleção de Orders UNION ALL OrdersNew
- Altere todos os procedimentos / chamadas para selecionar dados da visualização, insira-os em OrdersNew, exclua e modifique as duas tabelas.
- Migrar dados da tabela antiga para a nova, por exemplo, assim:
DECLARE @rowcount INT, @batchsize INT = 4999; SET IDENTITY_INSERT dbo.OrdersNew ON; SET @rowcount = @batchsize; WHILE @rowcount = @batchsize BEGIN BEGIN TRY DELETE TOP (@batchsize) FROM dbo.Orders OUTPUT deleted.Id ,deleted.Column1 ,deleted.Column2 ,deleted.Column3 INTO dbo.OrdersNew (Id ,Column1 ,Column2 ,Column3); SET @rowcount = @@ROWCOUNT; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_MESSAGE() AS ErrorMessage; THROW; END CATCH; END; SET IDENTITY_INSERT dbo.OrdersNew OFF;
- Retorne todos os procedimentos para a versão antes da migração - com uma tabela. Isso pode ser feito através da alteração ou da remoção e criação de procedimentos (então não se esqueça dos direitos), e você pode renomear a nova tabela para Pedidos, excluindo a tabela e a visualização vazias.
Na etapa 2, era possível, se o carregamento permitir, renomear a tabela principal Orders -> OrdersOld e OrdersView -> Orders e a própria exibição para OrdersOld UNION ALL Orders OrdersNew, então você não precisa alterar todos os locais onde há uma seleção da tabela.
Ao mover blocos de uma tabela para outra, os dados serão fragmentados.
Se a tabela que está sendo alterada for usada ativamente para leitura, mas os dados nela raramente forem alterados, você poderá novamente usar acionadores - escrever uma cópia de todas as alterações na 3ª tabela - transferir dados da tabela através de bcp out e bcp in (ou inserção em massa) para uma nova tabela , crie índices após a transferência de dados e aplique as alterações da tabela com o log de alterações - e alterne uma tabela para outra - a atual, renomeando-a para TableOld e a nova de TableNew para Table.
A probabilidade de erros nessa situação é um pouco maior; portanto, teste a aplicação de alterações e diferentes casos de comutação neste caso.
As opções descritas não são as únicas. Eles foram usados por mim em um banco de dados do SQL Server muito carregado e não causaram problemas durante o aplicativo, o que agradou a nossa equipe de DBA. Essa rejeição geralmente não é necessária para bases com um modo de carregamento mais calmo, quando você pode aplicar com segurança alterações nas horas de menor atividade. Os usuários do projeto que usaram as abordagens descritas estão localizados nos EUA e na Europa e usam ativamente o aplicativo nos dias de semana e fins de semana, e as tabelas nas quais as alterações foram aplicadas são usadas constantemente no trabalho. Objetos mais "mais silenciosos" geralmente eram modificados por scripts automáticos gerados pelo Redgate Toolkit após a revisão dos scripts pelo desenvolvedor e um dos DBAs.
Bom para todos! Compartilhe nos comentários se você usou algum desses métodos ou descreva seu método! Também convidamos você para uma aula aberta e um dia aberto de nosso novo curso "MS SQL Server Developer"