Em um artigo anterior do HSE de São Petersburgo, mostramos como o aprendizado de máquina pode procurar bugs no código do programa. Neste post, falaremos sobre como nós, juntamente com a JetBrains Research, estamos tentando usar uma das seções mais interessantes, modernas e de rápido crescimento do aprendizado de máquina - o aprendizado por reforço - tanto em problemas práticos reais quanto em exemplos de modelos.

Sobre mim
Meu nome é Nikita Sazanovich. Até junho de 2018, estudei na SPbAU por três anos e depois, juntamente com meus outros colegas de classe, fui transferido para o HSE St. Petersburg, onde agora estou terminando meus estudos de graduação. Recentemente, também trabalho como pesquisador na JetBrains Research. Antes de entrar na universidade, eu gostava de programação esportiva e jogava pela seleção da Bielorrússia.
Treinamento de reforço
O aprendizado por reforço é um ramo do aprendizado de máquina em que um agente, interagindo com o ambiente, recebe reforço (daí o nome) na forma de uma recompensa positiva ou negativa. Dependendo dessas solicitações, o agente altera seu comportamento. O objetivo final desse processo é receber a maior recompensa possível ou, de outra maneira, alcançar as ações que o agente definiu.
Os agentes operam sob condições e selecionam ações. Por exemplo, no problema de sair do labirinto, nossos estados serão as coordenadas xey, e as ações serão para cima / baixo / esquerda / direita. O esquema geral é assim:
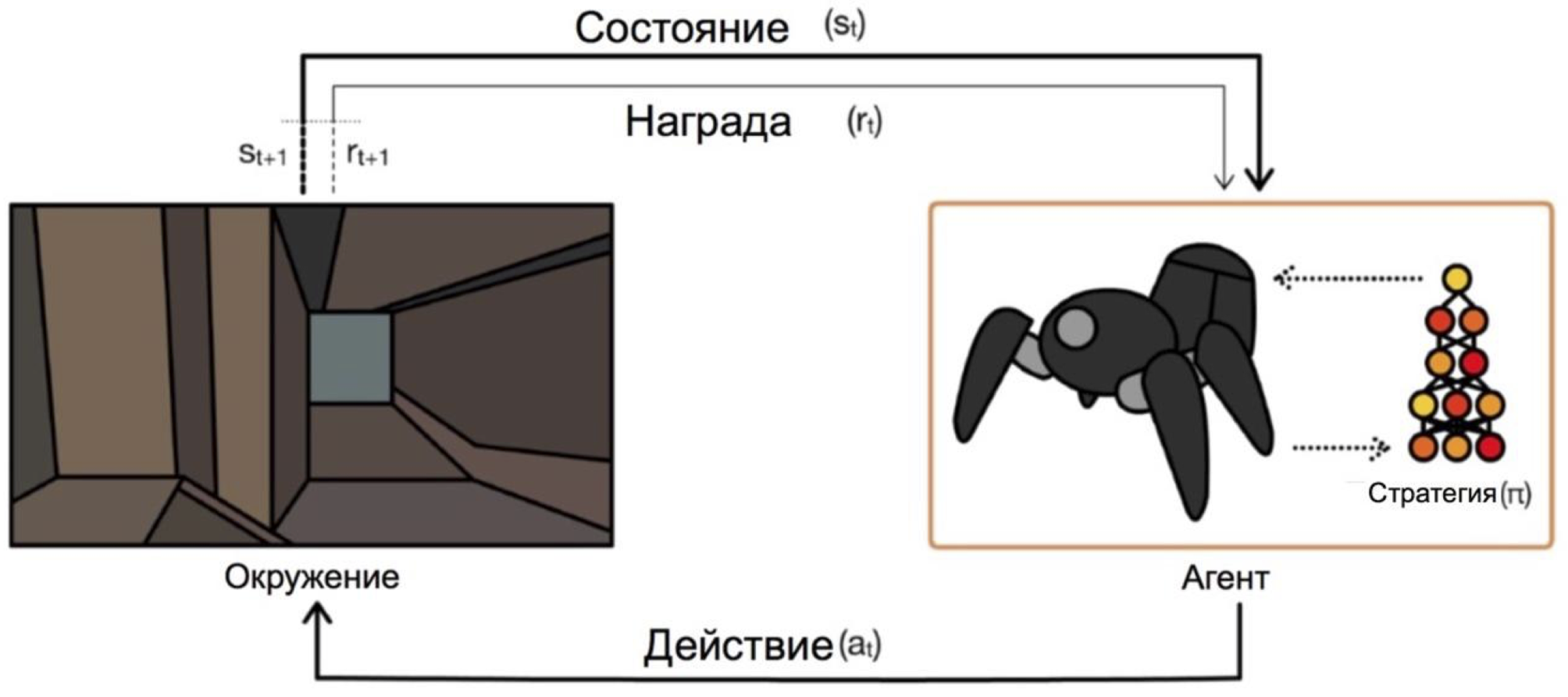
O principal problema na transição de tarefas fictícias / simples (como o mesmo labirinto) para tarefas reais / práticas é este: recompensas em tais problemas são geralmente muito raras. Se queremos que um agente, por exemplo, entregue pizza no mapa da cidade, ele entenderá que fez algo bem, apenas entregando o pedido na porta, e isso só acontecerá se você seguir uma sequência longa e correta de ações.
Esse problema pode ser resolvido fornecendo ao agente exemplos iniciais de como "tocar" - as chamadas demonstrações especializadas.
Tarefa de aprendizagem
O problema do modelo que será discutido no artigo é o Dota 2.
Dota 2 é um popular jogo MOBA no qual uma equipe de cinco heróis deve derrotar uma equipe adversária destruindo sua "fortaleza". O Dota 2 é considerado um jogo bastante complicado, possui esports com prêmios no torneio principal de US $ 25000000 .
Você pode ouvir sobre os sucessos recentes do OpenAI no Dota 2. Primeiro, eles criaram um bot individual e derrotaram jogadores profissionais , depois trocaram para um jogo de 5x5 e mostraram resultados impressionantes neste verão, embora tenham perdido para equipes profissionais.

O único problema é que eles treinaram o agente para um jogo individual, de acordo com eles , em 60.000 CPUs e 256 K80 GPUs na nuvem do Azure. Eles, é claro, têm a oportunidade de pedir tanto poder. Mas se você tiver menos poder, precisará usar truques. Um desses truques é o uso de jogos já jogados por pessoas.
Demonstrações no jogo
Na maioria dos casos, as demonstrações são gravadas artificialmente: você apenas conclui uma tarefa / joga um jogo e, de alguma forma, coleta as ações que tomou. Portanto, você coleta alguns dados que podem ser incorporados no treinamento de várias maneiras. Até agora eu fiz isso, mas como exatamente - ficará claro após a parte sobre o esquema de interação com o cliente do jogo.
Um objetivo maior e mais aventureiro é obter mais dados do acesso aberto. Uma das razões para escolher o Dota 2 para acelerar o aprendizado foi um recurso como o dotabuff . São coletadas estatísticas diferentes sobre o jogo, mas, mais importante, há replays completos de jogos. E eles podem ser classificados por classificação.
Até agora, eu não tentei como gigabytes de tais dados ajudariam muito em comparação com vários episódios. Perceber que a coleta de dados era bastante simples: você obtém links para jogos dotabuff, baixa jogos e usa o analisador de jogos Dota 2 .
Pacote com o cliente do jogo para treinamento
Temos um jogo Dota 2 cujo cliente existe nas plataformas Windows, Linux e macOS. Mas ainda assim, geralmente o treinamento ocorre em algum tipo de script python, e nele você cria um ambiente, seja um labirinto, uma máquina subindo uma colina ou algo assim. Mas não há ambiente para o Dota 2. Portanto, eu próprio tive que criar esse wrapper, o que foi bastante interessante tecnicamente. Acabou fazendo assim:
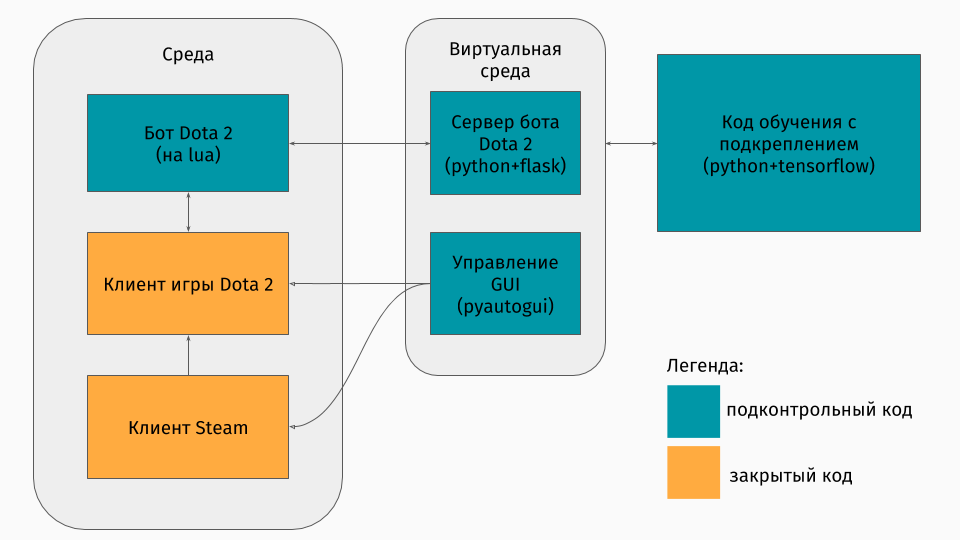
A primeira parte é um script para se comunicar com o cliente do jogo. Felizmente, para o Dota 2, existe uma API oficial para a criação de bots: Dota Bot Scripting . É implementado como inserções na linguagem Lua, que, como se viu, é popular no desenvolvimento de jogos. O script bot, interagindo com o cliente do jogo, extrai no momento certo as informações em que estamos interessados (por exemplo, coordenadas no mapa, posições dos oponentes) e envia o json com ele para o servidor.
A segunda parte é o próprio invólucro. Ele foi projetado como um servidor que processa toda a lógica de iniciar o Steam, Dota e receber json de um script dentro do jogo. O gerenciamento de jogos e clientes de lançamento é organizado pelo pyautogui , e a comunicação com a inserção da lua no jogo é feita pelo servidor Flask.
A terceira parte consiste no próprio algoritmo de aprendizado. Esse algoritmo seleciona ações, recebe os seguintes estados e recompensas do servidor, atrás dos quais toda a comunicação com o jogo fica oculta, e melhora seu comportamento.
Aprendendo com especialistas
O algoritmo em si não é particularmente importante neste artigo, porque essas técnicas podem ser usadas com qualquer algoritmo. Usamos o DQN (sobre o qual você pode ler no hub ). Em essência, essa é uma rede neural profunda + algoritmo de aprendizado de Q. Sim, esse é exatamente o DQN que o DeepMind criou para jogar os jogos da Atari.
Também é mais interessante falar sobre como usar jogos anteriores. Tentei duas abordagens: modelagem de recompensa com base em potencial e conselhos de ação.
A idéia geral das abordagens é que o agente receberá uma recompensa não apenas pelos objetivos da tarefa (por exemplo, no final do labirinto ou por escalar a montanha), mas também durante o treinamento a cada passo. Essa recompensa extra mostrará como o agente trabalha para alcançar o objetivo final. Claro, eu gostaria de perguntar automaticamente, e não selecionar as regras / condições. As abordagens a seguir ajudam a conseguir isso.
A essência da modelagem de recompensa baseada em potencial é que alguns estados inicialmente nos parecem mais promissores do que outros, e com base nisso modificamos as recompensas reais que o algoritmo recebe. Fazemos assim: onde - adjudicação modificada, - a recompensa é real, - fator de desconto do algoritmo de aprendizado (não muito importante para nós), mas e existe o nosso potencial para a condição que visitamos durante . Um exemplo simples é superar um labirinto.
Suponha que exista um labirinto no qual queremos vir da célula (0,0) para a célula (5,5). Então, nosso potencial para o estado (x, y) pode ser menos a distância euclidiana de (x, y) ao nosso objetivo (5.5): . Ou seja, quanto mais próximos estivermos da linha de chegada, maior o potencial do estado (por exemplo, , , ) Por isso, motivamos o agente de qualquer maneira para abordar a meta.
Para o Dota 2, a ideia é a mesma, mas os potenciais são definidos um pouco mais complicados:

Imagine que apenas queremos passar pelos mesmos estados do manifestante. Então, quanto mais estados passamos, maior o potencial. Colocamos o potencial do estado pela porcentagem de conclusão do replay, se houver uma condição próxima à nossa. Isso tem significados diferentes em várias tarefas. Mas é no Dota 2 que isso significa que, a princípio, queremos que o bot chegue ao centro (afinal, no início das manifestações existem apenas alguns passos para o centro), e então o estado do jogador humano é mantido (boa saúde, distância segura dos oponentes etc.) )
O segundo método, ação-conselho, foi retirado deste artigo . Sua essência é que agora aconselhamos o agente não a utilidade dos estados, mas a utilidade das ações. Por exemplo, em nosso jogo Dota 2, pode haver esse conselho: se houver um lacaio inimigo perto de você, então ataque-o; se você não alcançou o centro, siga em sua direção; se você perder a saúde, retire-se para a sua torre. E este artigo descreve um método para especificar essas dicas sem pensar no próprio programador - automaticamente.
Os potenciais são gerados de acordo com este princípio: potencial de ação capaz de
aumentos na presença de condições relacionadas com o mesmo
ação nas manifestações. Recompensa adicional por ação no diagrama acima
varia conforme .
Vale a pena notar aqui que já definimos potenciais para ações nos estados.
Resultados
Para começar, observo que o objetivo do jogo foi um pouco simplificado, porque ensinei tudo no meu laptop. O objetivo do agente era infligir o maior número possível de ataques, o que parece ser um alvo real em alguma aproximação. Para fazer isso, você primeiro precisa chegar ao centro do mapa e depois atacar os oponentes, tentando não morrer. Para acelerar o aprendizado, apenas algumas (1 a 3) demonstrações de dois minutos foram registradas por mim.
O treinamento de um agente usando qualquer uma das abordagens leva apenas 20 horas em um computador pessoal (na maioria das vezes é necessário para renderizar um jogo do Dota 2) e, a julgar pelos gráficos da OpenAI, o treinamento em seus servidores leva várias semanas.
Exposição curta do jogo ao usar a abordagem de modelagem de recompensa baseada em potencial:
E para a abordagem do conselho de ação:
Essas anotações foram feitas em uma velocidade de treinamento de x10. Imprecisões no comportamento do agente ao se mudar para o centro ainda são visíveis, mas ainda assim a luta no centro mostra as manobras aprendidas. Por exemplo, recuar com pouca saúde.
Você também pode ver as diferenças nas abordagens: com a modelagem de recompensa baseada em potencial, o agente se move sem problemas, porque "Passa por potencial"; com conselhos de ação, o bot joga mais agressivamente no centro, pois recebe dicas sobre o ataque.
Sumário
Percebo imediatamente que alguns pontos foram omitidos intencionalmente: qual algoritmo era exatamente, como o estado foi representado e se é possível treinar um agente para jogar com jogadores reais, etc.
Antes de tudo, neste artigo, eu queria mostrar que, no caso de treinamento reforçado, você nem sempre precisa escolher entre um ambiente muito simples (fuga do labirinto) ou um custo de treinamento muito alto (de acordo com meus cálculos superficiais, o OpenAI custou esses servidores para treinamento no Azure $ 4715 por hora). Existem técnicas que podem acelerar o aprendizado, e eu falei sobre apenas uma delas - o uso de demonstrações. É importante observar que, dessa maneira, você não apenas repete o demonstrador, mas apenas "retira-se" dele. É importante que, com treinamento adicional, o agente tenha a oportunidade de superar os especialistas.
Se você estiver interessado nos detalhes, o código do processo de treinamento pode ser encontrado no GitHub .