
A principal tarefa dos serviços comerciais (e não comerciais também) é estar sempre disponível para o usuário. Embora todos falhem, a questão é o que a equipe de TI faz para minimizá-los. Traduzimos um artigo de Ben Treynor, Mike Dahlin, Vivek Rau e Betsy Beyer “Cálculo da confiabilidade do serviço”, que diz, incluindo, por exemplo, o Google, por que 100% é um ponto de referência errado para o indicador de confiabilidade, qual é a “regra dos quatro noves” e como, na prática, prever matematicamente a viabilidade de interrupções grandes e pequenas do serviço e / ou de seus componentes críticos - a quantidade esperada de tempo de inatividade, o tempo necessário para detectar uma falha e o tempo para restaurar o serviço.
Cálculo da confiabilidade do serviço
Seu sistema é tão confiável quanto seus componentes
Ben Trainor, Mike Dalin, Vivec Rau, Betsy Beyer
Conforme descrito no livro " Engenharia de confiabilidade do site: Confiabilidade e confiabilidade como no Google " (doravante referido como livro de SRE), o desenvolvimento de produtos e serviços do Google pode atingir alta velocidade de liberação de novas funções, mantendo o SLO agressivo (objetivos de nível de serviço, metas de nível de serviço) ) para garantir alta confiabilidade e resposta rápida. Os SLOs exigem que o serviço esteja quase sempre em boas condições e quase sempre rápido. Além disso, os SLOs também indicam os valores exatos disso "quase sempre" para um serviço específico. Os SLOs são baseados nas seguintes observações:
Geralmente, para qualquer serviço ou sistema de software, 100% é o ponto de referência errado para o indicador de confiabilidade, pois nenhum usuário pode notar a diferença entre 100% e 99.999% de disponibilidade. Entre o usuário e o serviço, existem muitos outros sistemas (laptop, Wi-Fi doméstico, provedor, fonte de alimentação ...), e todos esses sistemas agregados estão disponíveis não em 99,999% dos casos, mas com muito menos frequência. Portanto, a diferença entre 99,999% e 100% é perdida devido a fatores aleatórios causados pela inacessibilidade de outros sistemas, e o usuário não se beneficia do fato de termos investido muito esforço em atingir essa última fração da porcentagem de disponibilidade do sistema. Exceções sérias a esta regra são freios e marcapassos antibloqueio!
Para uma discussão detalhada de como os SLOs se relacionam com os SLIs (indicadores de nível de serviço) e os SLAs (acordos de nível de serviço), consulte o capítulo Nível de serviço de destino do SRE. Este capítulo também descreve em detalhes como selecionar métricas relevantes para um serviço ou sistema específico, o que, por sua vez, determina a escolha do SLO apropriado para esse serviço ou sistema.
Este artigo estende o tópico SLO para se concentrar nos componentes de serviço. Em particular, examinaremos como a confiabilidade de componentes críticos afeta a confiabilidade de um serviço, bem como como projetar sistemas para mitigar o impacto ou reduzir o número de componentes críticos.
A maioria dos serviços oferecidos pelo Google visa fornecer 99,99% (às vezes chamado de "quatro noves") de acessibilidade para os usuários. Para alguns serviços, um número menor é indicado no contrato do usuário, no entanto, a meta de 99,99% é armazenada dentro da empresa. Essa barra superior oferece uma vantagem em situações em que os usuários reclamam do desempenho do serviço muito antes da violação dos termos do contrato, uma vez que o objetivo número 1 da equipe do SRE é fazer os usuários felizes com os serviços. Para muitos serviços, uma meta interna de 99,99% representa o meio termo, que equilibra custo, complexidade e confiabilidade. Para alguns outros, em particular os serviços globais de nuvem, a meta interna é de 99,999%.
Confiabilidade 99,99%: observações e conclusões
Vejamos algumas observações e conclusões importantes sobre o design e a operação do serviço com uma confiabilidade de 99,99%, e depois passemos à prática.
Observação nº 1: causas de falhas
As falhas ocorrem por dois motivos principais: problemas com o próprio serviço e problemas com componentes críticos do serviço. Um componente crítico é um componente que, no caso de uma falha, causa uma falha correspondente na operação de todo o serviço.
Observação nº 2: Matemática de confiabilidade
A confiabilidade depende da frequência e duração do tempo de inatividade. É medido através de:
- Freqüência ociosa ou inversa: MTTF (tempo médio até a falha).
- Tempo de inatividade, MTTR (tempo médio para reparo). O tempo de inatividade é determinado pelo tempo do usuário: desde o início do mau funcionamento até a retomada da operação normal do serviço.
Assim, a confiabilidade é matematicamente definida como MTTF / (MTTF + MTTR) usando as unidades apropriadas.
Conclusão # 1: Regra de noves extras
Um serviço não pode ser mais confiável do que todos os seus componentes críticos combinados. Se seu serviço procura garantir a disponibilidade em um nível de 99,99%, todos os componentes críticos devem estar disponíveis significativamente mais de 99,99% do tempo.
Dentro do Google, usamos a seguinte regra geral: os componentes críticos devem fornecer noves adicionais em comparação com a confiabilidade declarada do seu serviço - no exemplo acima, 99,999% de disponibilidade - porque qualquer serviço terá vários componentes críticos, além de seus próprios problemas específicos. Isso é chamado de "regra dos noves extras".
Se você possui um componente crítico que não fornece noves suficientes (um problema relativamente comum!), Você deve minimizar as consequências negativas.
Conclusão No. 2: Matemática da frequência, tempo de detecção e tempo de recuperação
Um serviço não pode ser mais confiável que o produto da frequência de incidentes e do tempo de detecção e recuperação. Por exemplo, três desligamentos totais por ano de 20 minutos cada levam a um total de 60 minutos de tempo de inatividade. Mesmo que o serviço funcionasse perfeitamente no resto do ano, seria impossível 99,99% de confiabilidade (não mais que 53 minutos de inatividade por ano).
Essa é uma observação matemática simples, mas geralmente é ignorada.
Conclusão das conclusões nºs 1 e 2
Se o nível de confiabilidade em que seu serviço depende não puder ser alcançado, devem ser feitos esforços para corrigir a situação - aumentando a disponibilidade do serviço ou minimizando as consequências negativas, conforme descrito acima. Reduzir as expectativas (isto é, confiabilidade declarada) também é uma opção, e geralmente a mais verdadeira: deixe claro para o serviço dependente de você que ele deve reconstruir seu sistema para compensar o erro na confiabilidade do seu serviço ou reduzir suas próprias metas de nível de serviço . Se você mesmo não eliminar a discrepância, uma falha suficientemente longa do sistema exigirá inevitavelmente ajustes.
Aplicação prática
Vejamos um exemplo de serviço com uma confiabilidade de destino de 99,99% e elabore os requisitos para seus componentes e trabalhe com suas falhas.
Figuras
Suponha que seu serviço de 99,99% esteja disponível com as seguintes características:
- Uma grande interrupção e três pequenas interrupções por ano. Parece assustador, mas observe que um nível de confiança de 99,99% implica em um tempo de inatividade em larga escala de 20 a 30 minutos e em alguns desligamentos parciais curtos por ano. (A matemática indica que: a) a falha de um segmento não é considerada uma falha de todo o sistema do ponto de vista do SLO eb) a confiabilidade total é calculada pela soma da confiabilidade dos segmentos.)
- Cinco componentes críticos na forma de outros serviços independentes com confiabilidade de 99,999%.
- Cinco segmentos independentes que não podem falhar um após o outro.
- Todas as alterações são realizadas gradualmente, um segmento de cada vez.
O cálculo matemático da confiabilidade será o seguinte:
Requisitos de componentes
- O limite total de erros para o ano é de 0,01% de 525.600 minutos por ano ou 53 minutos (com base no ano de 365 dias, no pior cenário).
- O limite alocado para o desligamento de componentes críticos é de cinco componentes críticos independentes, com um limite de 0,001% cada = 0,005%; 0,005% de 525.600 minutos por ano ou 26 minutos.
- O limite de erro restante do seu serviço é 53-26 = 27 minutos.
Requisitos de resposta de desligamento
- Tempo de inatividade esperado: 4 (1 desligamento total e 3 desligamentos que afetam apenas um segmento)
- O efeito cumulativo das interrupções previstas: (1 × 100%) + (3 × 20%) = 1,6
- Detecção e recuperação de falhas após: 27 / 1,6 = 17 minutos
- Tempo alocado para o monitoramento para detectar uma falha e notificá-la: 2 minutos
- Tempo concedido ao especialista de plantão para iniciar a análise do alerta: 5 minutos. (O sistema de monitoramento deve rastrear violações de SLO e enviar um sinal ao pager de plantão toda vez que ocorre uma falha do sistema. Muitos serviços do Google são suportados por engenheiros de turno e turno de plantão que respondem a perguntas urgentes.)
- Tempo restante para minimizar efetivamente os efeitos adversos: 10 minutos
Conclusão: alavancagem para aumentar a confiabilidade do serviço
Vale a pena examinar cuidadosamente os números apresentados, pois enfatizam o ponto fundamental: existem três alavancas principais para aumentar a confiabilidade do serviço.
- Reduza a frequência de interrupções - por meio de políticas de liberação, testes, avaliações periódicas da estrutura do projeto, etc.
- Reduza seu tempo de inatividade médio com segmentação, isolamento geográfico, degradação gradual ou isolamento do cliente.
- Reduza o tempo de recuperação - com monitoramento, operações de resgate com um botão (por exemplo, retornando a um estado anterior ou adicionando energia em espera), práticas de prontidão operacional, etc.
Você pode equilibrar esses três métodos para simplificar a implementação da tolerância a falhas. Por exemplo, se for difícil obter um MTTR de 17 minutos, concentre-se em reduzir o tempo de inatividade médio. Estratégias para minimizar os efeitos adversos e mitigar os efeitos dos componentes críticos são discutidas em mais detalhes posteriormente neste artigo.
Esclarecimento “Regras para noves adicionais” para componentes aninhados
Um leitor aleatório pode concluir que cada link adicional na cadeia de dependência requer nove adicionais; portanto, nove adicionais são necessários para dependências de segunda ordem, três adicionais são necessários para dependências de terceira ordem, etc.
Esta é a conclusão errada. É baseado em um modelo ingênuo de uma hierarquia de componentes na forma de uma árvore com uma ramificação constante em cada nível. Nesse modelo, como mostrado na Fig. 1, existem 10 componentes de primeira ordem exclusivos, 100 componentes de segunda ordem exclusivos, 1.000 componentes de terceira ordem exclusivos, etc., resultando em um total de 1.111 serviços exclusivos, mesmo se a arquitetura estiver limitada a quatro camadas. Um ecossistema de serviços altamente confiáveis com tantos componentes críticos independentes é claramente irrealista.
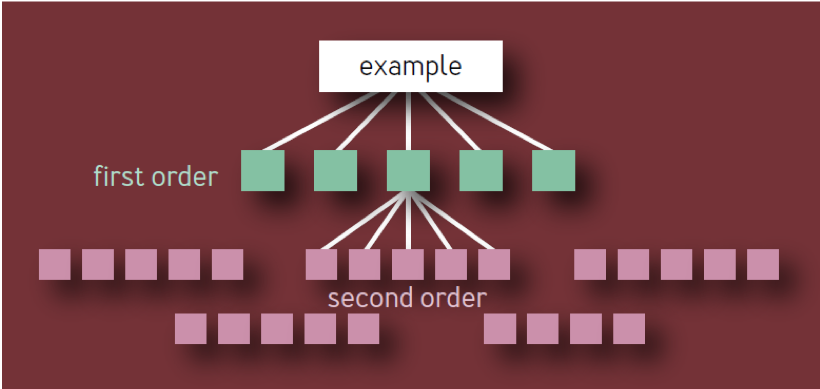
Fig. 1 - Hierarquia de componentes: modelo inválido
Um componente crítico por si só pode causar a falha de todo o serviço (ou segmento de serviço), independentemente de onde esteja na árvore de dependência. Portanto, se um determinado componente de X for exibido como uma dependência de vários componentes de primeira ordem, X deverá ser contado apenas uma vez, pois sua falha levará a uma falha de serviço, independentemente de quantos serviços intermediários também sejam afetados.
Uma leitura correta da regra é a seguinte:
- Se um serviço tiver N componentes críticos exclusivos, cada um deles contribuirá com 1 / N para a falta de confiabilidade de todo o serviço causado por esse componente, não importa quão baixo seja na hierarquia de componentes.
- Cada componente deve ser contado apenas uma vez, mesmo que apareça várias vezes na hierarquia de componentes (em outras palavras, apenas componentes únicos são contados). Por exemplo, ao calcular os componentes do Serviço A na Fig. 2, o Serviço B deve ser considerado apenas uma vez.
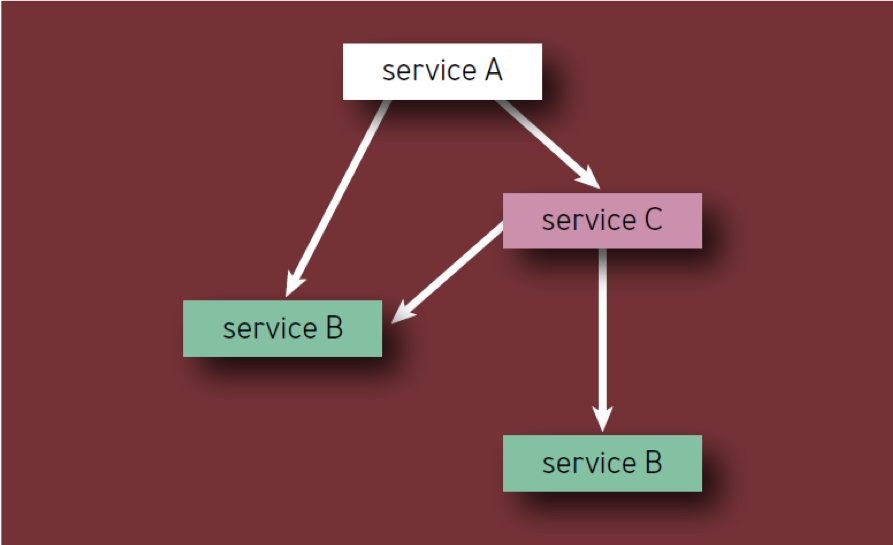
Fig. 2 - Componentes na hierarquia
Por exemplo, considere um serviço hipotético A com um limite de erro de 0,01 por cento. Os proprietários do serviço estão prontos para gastar metade desse limite em seus próprios erros e perdas e metade em componentes críticos. Se o serviço tiver N tais componentes, cada um deles receberá 1 / N do limite de erro restante. Os serviços típicos geralmente têm de 5 a 10 componentes críticos e, portanto, cada um deles pode recusar apenas um décimo ou um vigésimo grau do limite de erro do Serviço A. Portanto, como regra, as partes críticas do serviço devem ter nove confiabilidade adicionais.
Limites de erro
O conceito de limites de erro é abordado com alguns detalhes no livro SRE, mas aqui deve ser mencionado. Os engenheiros do Google SR usam limites de erro para equilibrar a confiabilidade e o ritmo das atualizações. Esse limite determina o nível aceitável de falha do serviço por um determinado período de tempo (geralmente um mês). O limite de erro é de apenas 1 menos o SLO do serviço; portanto, o serviço disponível de 99,99% disponível discutido anteriormente possui um "limite" de 0,01% na falta de confiabilidade. Até o serviço esgotar seu limite de erros dentro de um mês, a equipe de desenvolvimento estará livre (dentro do motivo) para lançar novas funções, atualizações etc.
Se o limite de erro for esgotado, as alterações no serviço serão suspensas (com exceção de correções de segurança urgentes e alterações destinadas a causar a violação em primeiro lugar) até que o serviço reponha a reserva no limite de erro ou até que o mês mude. Muitos serviços no Google usam um método de janela deslizante para o SLO, para que o limite de erros seja restaurado gradualmente. Para serviços sérios com um SLO de mais de 99,99%, é recomendável usar uma redefinição zero trimestral em vez de mensal, porque o número de tempo de inatividade permitido é pequeno.
Os limites de erro eliminam a tensão entre departamentos que poderiam surgir entre engenheiros de SR e desenvolvedores de produtos, fornecendo a eles uma ferramenta comum de avaliação de risco baseada em dados para o lançamento de um produto. Eles também dão aos engenheiros e equipes de desenvolvimento de SR um objetivo comum de desenvolver métodos e tecnologias que lhes permitam inovar mais rapidamente e lançar produtos sem um "orçamento inchado".
Estratégias críticas de redução e mitigação de componentes
Neste ponto, neste artigo, estabelecemos o que pode ser chamado de "Regra de Ouro para Confiabilidade de Componentes" . Isso significa que a confiabilidade de qualquer componente crítico deve ser 10 vezes maior que o nível-alvo de confiabilidade de todo o sistema, para que sua contribuição para a falta de confiabilidade do sistema permaneça no nível de erro. Daqui resulta que, no caso ideal, a tarefa é tornar o máximo possível de componentes não críticos. Isso significa que os componentes podem aderir a um nível mais baixo de confiabilidade, dando aos desenvolvedores a oportunidade de inovar e assumir riscos.
A estratégia mais simples e óbvia para reduzir dependências críticas é eliminar pontos únicos de falha sempre que possível. Um sistema maior deve poder operar de forma aceitável sem nenhum componente que não seja dependência crítica ou SPOF.
De fato, você provavelmente não pode se livrar de todas as dependências críticas; mas você pode seguir algumas diretrizes de design do sistema para otimizar a confiabilidade. Embora isso nem sempre seja possível, é mais fácil e mais eficiente obter alta confiabilidade do sistema se você depositar confiabilidade nos estágios de design e planejamento, e não depois que o sistema funcionar e afetar os usuários reais.
Avaliação da estrutura do projeto
Ao planejar um novo sistema ou serviço, ou ao redesenhar ou aprimorar um sistema ou serviço existente, uma revisão da arquitetura ou do projeto pode revelar uma infraestrutura comum, bem como dependências internas e externas.
Infraestrutura compartilhada
Se o seu serviço usar uma infraestrutura compartilhada (por exemplo, o principal serviço de banco de dados usado por vários produtos disponíveis para os usuários), considere se essa infraestrutura é usada corretamente. Identifique claramente os proprietários da infraestrutura compartilhada como participantes adicionais do projeto. Além disso, cuidado com as sobrecargas de componentes - para isso, coordene cuidadosamente o processo de inicialização com os proprietários desses componentes.
Dependências internas e externas
Às vezes, um produto ou serviço depende de fatores fora do controle da sua empresa - por exemplo, de bibliotecas ou serviços de software e dados de terceiros. A identificação desses fatores minimizará as consequências imprevisíveis de seu uso.
Planejar e projetar sistemas com cuidado
Ao projetar seu sistema, preste atenção aos seguintes princípios:
Redundância e isolamento
Você pode tentar reduzir o impacto do componente crítico criando várias instâncias independentes dele. Por exemplo, se o armazenamento de dados em uma instância garantir 99,9% da disponibilidade desses dados, o armazenamento de três cópias em três cópias amplamente distribuídas fornecerá, em teoria, um nível de disponibilidade de 1 a 0,013 ou nove noves, se a instância falhar independentemente, com correlação zero.
No mundo real, a correlação nunca é zero (observe as falhas da rede de backbone que afetam muitas células ao mesmo tempo); portanto, a confiabilidade real nunca chegará perto de nove e nove, mas excede em muito três.
Da mesma forma, o envio de uma RPC (chamada de procedimento remoto) para um pool de servidores no mesmo cluster pode fornecer 99% de disponibilidade dos resultados, enquanto o envio de três RPCs simultâneos para três pools de servidores diferentes e a aceitação da primeira resposta ajudará a atingir o nível de disponibilidade superior a três noves (veja acima). Essa estratégia também pode diminuir o atraso do tempo de resposta se os pools de servidores estiverem equidistantes do remetente RPC. (Como o custo do envio de três RPCs ao mesmo tempo é alto, o Google geralmente aloca estrategicamente o tempo para essas chamadas: a maioria dos nossos sistemas espera um pouco do tempo alocado antes do envio do segundo RPC e um pouco mais de tempo antes do envio do terceiro RPC.)
Reserva e sua aplicação
Configure o lançamento e a portabilidade do software para que os sistemas continuem funcionando quando partes individuais falham (à prova de falhas) e se isolam quando ocorrem problemas. O princípio básico aqui é que, quando você conectar a pessoa para ativar a reserva, é provável que você exceda o seu limite de erro.
Assincronia
Para impedir que os componentes se tornem críticos, projete-os de forma assíncrona sempre que possível. Se um serviço espera uma resposta RPC de uma de suas partes não críticas, o que mostra uma forte desaceleração no tempo de resposta, essa desaceleração piorará desnecessariamente o desempenho do serviço pai. Definir o RPC para um componente não crítico para o modo assíncrono liberará o tempo de resposta do serviço pai de ser vinculado ao desempenho desse componente. E embora a assincronia possa complicar o código e a infraestrutura do serviço, ainda assim esse compromisso vale a pena.
Planejamento de recursos
Verifique se todos os componentes são fornecidos com tudo que você precisa. , — .
, \ .
, . . . , .
SLO. , , . , , , MTTR .
, . :
, , , . :
, : , , . — , . , , , .
, . , Google , 10 .
Conclusão
Embora os leitores provavelmente estejam familiarizados com alguns ou muitos dos conceitos descritos neste artigo, exemplos específicos de seu uso os ajudarão a entender melhor sua essência e a transmitir esse conhecimento para outras pessoas. Nossas recomendações não são simples, mas inatingíveis. Vários serviços do Google demonstraram repetidamente confiabilidade além de quatro noves, não devido a esforços ou inteligência sobre-humanos, mas devido à aplicação criteriosa dos princípios e melhores práticas desenvolvidas ao longo de muitos anos (consulte o SRE, Apêndice B: Diretrizes Práticas para Serviços em Operações Industriais).