
tl; dr: o Adblock Radio reconhece anúncios de áudio usando aprendizado de máquina e técnicas semelhantes ao Shazam. O principal mecanismo de código aberto : use-o em seus produtos! Você pode unir forças para oferecer suporte a mais estações de rádio e podcasts.
Poucas pessoas gostam de ouvir anúncios de rádio.
Lancei o projeto
AdblockRadio.com para que os ouvintes possam pular anúncios em sua rádio favorita da Internet. O algoritmo é de
código aberto publicado e este artigo descreve como ele funciona.
O Adblock Radio já testou dados reais de
mais de 60 estações de rádio em sete países . Também é compatível com podcasts e funciona muito bem!
Comparado às implementações anteriores, nosso algoritmo oferece uma abordagem universal, processando threads de várias fontes. Das implementações anteriores, uma
conta com metadados de rádio na Internet , mas apenas uma pequena fração do rádio é compatível com esse método. Outra implementação
reconhece jingles conhecidos , mas em muitos casos o início e o fim dos intervalos comerciais não são marcados pelo jingle.
Além de detectar comerciais, o algoritmo proposto pode distinguir a conversa da música. Portanto, também permite evitar conversas e ouvir apenas música.
Este é um relatório do meu trabalho pessoal há quase três anos. Lancei o Adblock Radio no final de 2015, alguns meses depois de me formar na faculdade de física de fusão de plasma. Quando a Adblock Radio
ganhou fama em 2016, recebi ameaças de advogados de estações de rádio francesas (mais abaixo). Eu tive que fechar parcialmente o site, mudar a arquitetura do sistema, estudar melhor as consequências legais, etc. Hoje, acredito que o AdBlock Radio será muito melhor desenvolvido no paradigma da
inovação aberta .
Este artigo possui três partes. Eles são projetados para diferentes públicos. Você pode rolar para baixo ou clicar no nome para ir diretamente para a seção desejada.
- Detecção de anúncios: estratégias comprovadas . Para pessoas tecnicamente experientes, cientistas, especialistas em análise de dados ... Aqui estão vários métodos técnicos que tentei detectar anúncios, incluindo reconhecimento de fala, impressões digitais sonoras e aprendizado de máquina. Pensamentos sobre opções para trabalhos futuros.
- Não é recomendável executar o Adblock Radio na nuvem . Para desenvolvedores de software e pessoas interessadas em direitos autorais. Discutiremos quão difícil é encontrar um compromisso satisfatório entre as limitações técnicas e legais ao iniciar o Adblock Radio em serviços em nuvem. Por esses motivos, é melhor executar o Adblock Radio apenas em dispositivos de usuário final.
- Você pode integrar o Adblock Radio ao seu player . Para fabricantes, proprietários de produtos, designers de UX, técnicos ... Estou pensando em idéias para integrar um algoritmo de código aberto em produtos finais, incluindo reprodutores de carros, e enfatizando a necessidade de feedback dos usuários sobre casos de mau funcionamento. Isso é necessário para manter o sistema. Finalmente, aqui estão algumas dicas sobre como criar as interfaces de usuário corretas. Espero muito feedback sobre esse tópico.
 O Adblock Radio traz de volta o prazer de ouvir rádio
O Adblock Radio traz de volta o prazer de ouvir rádioDetecção de anúncios: estratégias comprovadas
Para bloquear um anúncio, primeiro você precisa detectá-lo. O objetivo é detectar anúncios no fluxo de áudio sem qualquer ajuda da estação de rádio. Esta não é uma tarefa fácil. Eu tentei várias abordagens antes de obter um bom resultado.
1. Métodos simples (não funcionam)
Volume
A primeira idéia é verificar o volume do som, porque o anúncio é muito alto! Para publicidade,
a compressão acústica é frequentemente usada. Esse é um critério interessante, mas não basta distinguir a publicidade. Por exemplo, essa estratégia funciona muito bem para estações de música clássica, onde os anúncios geralmente são mais altos que a música. Mas o pop é tão alto quanto a publicidade. Além disso, algumas propagandas podem ser deliberadamente silenciosas para evitar a detecção.
Bloqueio de relógio
Outra idéia é que a publicidade é transmitida em uma programação em um horário específico. Até certo ponto, isso é verdade, mas não há precisão. Por exemplo, vi o
programa matinal na estação francesa não começar exatamente na mesma hora, com variações de até dois minutos. As estações de rádio podem facilmente contornar esse bloqueio, mudando aleatoriamente seus programas por várias dezenas de segundos.
Metadados
A solução óbvia é confiar nos
metadados ICY / Shoutcast para jogadores como o
VLC exibirem informações sobre o fluxo. Infelizmente, esses dados são quebrados na maioria dos casos. Pode-se obter informações da transmissão ao vivo nos sites das estações de rádio (desenvolvi uma
ferramenta para isso ), mas na maioria das vezes o anúncio não é identificado como está. Geralmente, durante a publicidade no site, é exibido o nome da música ou programa anterior. Uma exceção notável é a
Jazz Radio , que escreve
“la musique revient vite ...” durante os comerciais (a música voltará em breve). Em conclusão, deve-se notar que esta é uma estratégia não confiável, uma vez que as estações de rádio podem facilmente mudar os metadados.
Marcação manual
Afinal, a detecção de anúncios é possível sem qualquer algoritmo! Você pode simplesmente pedir a alguns ouvintes para pressionar um botão quando um anúncio começa e termina. Outros ouvintes se beneficiarão com isso. Esta é a estratégia do decodificador
TiVo Bolt . Permite remover anúncios em canais estabelecidos em um horário definido. Isso fornece excelentes resultados, mas não se adapta bem a milhares de estações de rádio.
A desvantagem é que é difícil iniciar o sistema do zero. Pode não haver público suficiente na nova estação para uma operação adequada. Os primeiros ouvintes ficarão chateados e vão embora, de modo que a estação nunca reunirá uma audiência grande o suficiente.
Outra dificuldade é que as estações de rádio desejam enviar sinais falsos para sabotar o sistema. Requer um mecanismo de moderação, um sistema de consenso ou um limite para votação.
Crowdsourcing é uma boa ideia. Eu acho que parece ainda melhor se o algoritmo faz a maior parte do trabalho, deixando um mínimo para as pessoas. Foi o que eu fiz.
2. Reconhecimento de fala e análise de campo lexical (falha)
A publicidade é sempre o mesmo tópico e campo lexical: comprar um carro, obter cupons de supermercado, inscrever-se em seguros etc. Se você reconhecer a fala, poderá usar
ferramentas padrão
para combater o spam . Este foi o meu primeiro caminho de pesquisa no final de 2015, mas não consegui implementar o reconhecimento de fala.
Como iniciante no processamento de fala, comecei lendo
o Processamento de fala de Huang , um ótimo livro, embora um pouco datado. Coloquei minhas mãozinhas sujas no
CMU Sphinx , o melhor mecanismo de reconhecimento de voz livre da época.
A primeira tentativa deu resultados muito ruins e exigiu cálculos intensivos na CPU. Utilizei os parâmetros padrão: dicionário francês padrão (lista de possíveis palavras e fonemas correspondentes), modelo de linguagem (probabilidades de sequências de palavras) e modelo acústico (conexão de fonemas com a forma de ondas sonoras).
Tentativas de melhorar o sistema foram inúteis: o reconhecimento ainda funcionou mal. Configurei o modelo de vocabulário e idioma em um pequeno conjunto de dados, compartilhando o som
com uma ferramenta de diarização . Ele também
adaptou o modelo acústico MLLR à estação de rádio Europe 1 (francesa), na qual treinou o sistema.
Em geral, a idéia de reconhecimento de fala teve que ser abandonada. Isto é provavelmente para especialistas. No entanto, no futuro, você poderá retornar a ele. Desde 2015, houve um progresso significativo no reconhecimento de fala. Novas ferramentas de código aberto foram publicadas, como o
Mozilla Deep Speech .
3. Base de publicidade de crowdsourcing, detecção por impressões digitais sonoras (encorajador)
A primeira versão do Adblock Radio em 2016 trabalhou com um banco de dados de comerciais. O sistema ouvia continuamente o fluxo de som em busca de publicidade. Os resultados foram realmente promissores, mas era difícil manter essa base atualizada.
A técnica de busca de impressões digitais é semelhante ao que o
Shazam faz em seus servidores para reconhecer músicas. Esse tipo de algoritmo é conhecido como
ponto de referência . Eu o adaptei para trabalhar com streaming e
abri o código fonte .
A impressão digital é adequada para detectar comerciais, porque eles são transmitidos repetidamente da mesma forma. Pela mesma razão, ele reconhece a música. Mas essa técnica não funciona na fala, porque as pessoas nunca pronunciam palavras da mesma maneira. Isso só é possível com a retransmissão dos programas à noite, o que não nos interessa. Portanto, publicidade e música (como “não anunciando”) devem ser inseridas no banco de dados de impressões digitais, mas não faz sentido processar a fala.
Essencialmente, impressões digitais sonoras são a conversão de algumas características do som em uma série de números denominados impressões digitais. Se muitas impressões ao vivo coincidirem com a base, podemos concluir que a publicidade está sendo transmitida. Para uma resolução ideal, intervalo de tempo e frequência, é necessário algum ajuste. Padrões diferentes devem variar bem. No entanto, o sistema deve funcionar mesmo com uma pequena alteração nos algoritmos de compressão de som ou se o rádio tiver alterado as configurações do equalizador. Por fim, você deve limitar o número de impressões para não carregar recursos de computação.
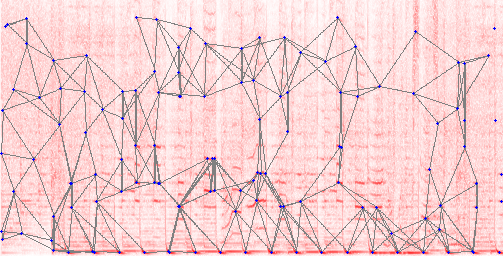 Exemplo de cálculo de impressões sonoras. Fundo vermelho - espectrograma. Reflete a mudança na intensidade do som na frequência (baixas frequências abaixo). Nesse mapa, os picos espectrais são identificados (pontos azuis) e conectados (linhas cinzas). A posição, comprimento e orientação de cada linha cinza é convertida em um número único, uma impressão
Exemplo de cálculo de impressões sonoras. Fundo vermelho - espectrograma. Reflete a mudança na intensidade do som na frequência (baixas frequências abaixo). Nesse mapa, os picos espectrais são identificados (pontos azuis) e conectados (linhas cinzas). A posição, comprimento e orientação de cada linha cinza é convertida em um número único, uma impressãoA classificação binária fornece o resultado: a amostra é um anúncio ou não. Se analisarmos casos de erros, o sistema quase sempre produziu um resultado falso negativo, ou seja, perdeu anúncios e muito raramente notou um bom conteúdo como publicidade. Os usuários podem denunciar anúncios não detectados com um clique, o que fornece uma excelente interface de usuário. O som correspondente é adicionado automaticamente ao banco de dados. Eu moderava essas ações a posteriori.
Era difícil manter o banco de dados atualizado, pois os comerciais geralmente mudam e os anúncios são transmitidos com pouca variação. Eles também são atualizados com frequência, em alguns casos a cada poucos dias. Alguns fluxos com um número insuficiente de ouvintes são muito pouco reconhecidos.
Explorei estratégias interessantes para automatizar parcialmente o trabalho dos ouvintes. Os anúncios são transmitidos da mesma maneira várias vezes por dia. Isso pode ser usado para identificá-los. Registros pesquisados para
sequências máximas de repetição (MRS). Outro conteúdo também é repetido, por exemplo, músicas e jingles (protetores de tela). Classifiquei todas as seqüências por comprimento e colhi amostras com uma duração de cerca de 30 segundos, típica de comerciais. Assim, muitas vezes conseguiu pegar um anúncio. Mas, às vezes, um coro de músicas ou até previsões meteorológicas gravadas apareciam.
Encontrei uma maneira de filtrar a maioria das repetições musicais:
analisei as playlists da estação, baixei as músicas e as integrei ao banco de dados com o rótulo "no ads". Portanto, mais e mais candidatos à MRS acabaram sendo comerciais reais. Mas, ainda assim, nem todos, a assistência ao usuário permaneceu necessária.
Foi necessário menos trabalho manual, mas a carga do servidor já era um problema. Olhando para trás, a escolha do SQLite para essas operações de banco de dados com uso intensivo de recursos e tempo não foi a melhor.
Felizmente, o algoritmo teve alguns segundos para determinar se o som é um anúncio publicitário ou não. Isso ocorre porque os rádios da Internet usam um buffer de áudio, geralmente de 4 a 30 segundos, que não é reproduzido imediatamente no dispositivo do usuário final. Isso ajuda a evitar interrupções na transmissão no caso de uma perda temporária da rede.
Usei esse atraso no buffer de pós-processamento para tornar as previsões de algoritmos mais estáveis e sensíveis ao contexto. Imediatamente antes de reproduzir o som no dispositivo do usuário final, o algoritmo analisa os resultados das previsões que ainda estão no buffer, bem como as mais antigas que já foram reproduzidas. Ele corta pontos de dados questionáveis com várias correspondências de impressões digitais, mostrando
histerese . Ele também leva em consideração o tempo médio ponderado para atenuar possíveis falhas.
 Adblock Radio em algum momento de 2016. O destaque vermelho das estações de rádio em que o anúncio está sendo exibido atualmente parecia muito legal! Os usuários podem marcar anúncios ignorados com um botão azul. O botão música na nuvem, na parte superior, permite exportar um fluxo MP3 personalizado com o anúncio removido e, se essa função estiver configurada, transições suaves entre estações de rádio. Abaixo estão os botões e funções adicionais.
Adblock Radio em algum momento de 2016. O destaque vermelho das estações de rádio em que o anúncio está sendo exibido atualmente parecia muito legal! Os usuários podem marcar anúncios ignorados com um botão azul. O botão música na nuvem, na parte superior, permite exportar um fluxo MP3 personalizado com o anúncio removido e, se essa função estiver configurada, transições suaves entre estações de rádio. Abaixo estão os botões e funções adicionais.4. Classificação de publicidade, conversação e música no aprendizado de máquina (quase pronto!)
A próxima versão do algoritmo analisa a acústica: de sons baixos a altos e sua mudança no tempo. Novos comerciais desconhecidos são detectados quase tão bem quanto os antigos nos quais o treinamento ocorreu, apenas por sinais de ruído e importância. Este é um método mais complexo para analisar o volume do som (consulte a discussão anterior).
Para isso, usei ferramentas de aprendizado de máquina, a biblioteca
Keras , conectada ao
Tensorflow . Isso deu resultados muito bons com pouco uso da CPU. Esta versão trabalhou em produção por mais de um ano, desde o início de 2017 até meados de 2018. Agora é possível distinguir conversas e música; portanto, a classificação se tornou mais precisa: em vez de "publicidade / não publicidade" - "publicidade / conversa / música".
Vamos estudar os detalhes. O som é convertido em um mapa 2D, onde a intensidade do som é apresentada em função da frequência e do tempo (em uma escala de cerca de quatro segundos). Este cartão é conceitualmente semelhante ao cartão vermelho no capítulo sobre impressões digitais. A principal diferença é que, em vez do espectro clássico de Fourier, usei
coeficientes Mel-cepstrais relevantes no contexto do reconhecimento de fala.
Os cartões sequenciais com diferentes carimbos de data / hora foram analisados como imagens em uma
rede neural recorrente , como
LSTM (memória de curto prazo). Cada cartão foi analisado independentemente do outro (RNN
sem preservação de estado ), mas os cartões se sobrepuseram. As cartas duravam 4 segundos e a cada segundo uma nova aparecia. O resultado final para cada cartão foi o vetor
softmax , por exemplo,
ad: 72%, talk: 11%, music 17% . Essas previsões foram processadas usando o mesmo método descrito na seção de impressões digitais.
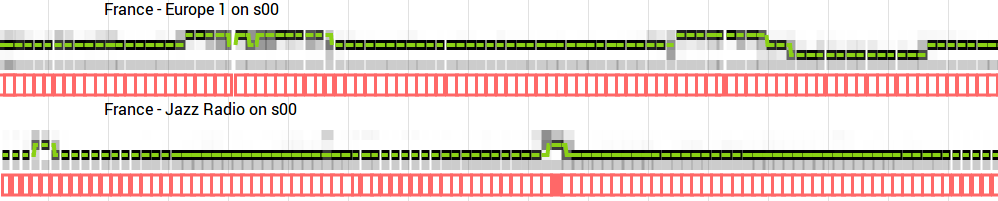 Visualize os resultados típicos de aprendizado de máquina para duas estações de rádio. O eixo horizontal representa cerca de 17 minutos. A linha verde se move entre três posições: publicidade na parte superior, conversa no meio e música na parte inferior (mais próxima de um fundo cinza uniforme). Áreas vermelhas - intervalos de escuta do usuário. Se o algoritmo fornecer uma previsão incorreta, o usuário poderá corrigi-lo
Visualize os resultados típicos de aprendizado de máquina para duas estações de rádio. O eixo horizontal representa cerca de 17 minutos. A linha verde se move entre três posições: publicidade na parte superior, conversa no meio e música na parte inferior (mais próxima de um fundo cinza uniforme). Áreas vermelhas - intervalos de escuta do usuário. Se o algoritmo fornecer uma previsão incorreta, o usuário poderá corrigi-loInicialmente, treinei uma rede neural em um conjunto de dados muito pequeno. Desenvolvi a interface do usuário (veja a imagem acima) para visualizar previsões e poderia adicionar mais dados para treinar modelos com melhor desempenho. No momento da redação deste artigo, o conjunto de dados de treinamento contém cerca de dez dias de áudio: 66 horas de publicidade, 96 horas de conversação e 73 horas de música.
Apesar do bom trabalho, a precisão da classificação ainda se mostrou um pouco menor que as expectativas dos usuários (consulte a seção sobre melhorias futuras abaixo). No treinamento, a precisão da previsão da categoria foi de 95%, mas as classificações incorretas restantes deixaram os usuários insatisfeitos.
Nota para especialistas em processamento de dados: é habitual fornecer resultados formais, dividindo o conjunto de dados em subconjuntos de treinamento e teste. Eu acho que isso não faz sentido aqui, porque o conjunto de dados está sendo construído gradualmente em dados onde os modelos anteriores foram confundidos. Isso significa que o conjunto de dados contém mais patologias do que a transmissão média e a precisão será subestimada. Será necessário um trabalho separado para medir indicadores reais. O operador pode marcar segmentos contínuos de gravações de áudio convencionais como dados de teste, calcular a precisão e recuperar os dados. Essa verificação regular permitirá monitorar o desempenho dos filtros.A categorização da publicidade / conversas / música adicionou conveniência aos ouvintes. No entanto, essa classificação complicou a interface do usuário e ficou mais difícil trabalhar com os relatórios do usuário. Se a bandeira indicar que algum conteúdo não é música, é propaganda ou conversa? Aqui você precisa de moderação imediata, não pós-factum.
Para melhorar ainda mais a qualidade, desenvolvi a versão mais recente do Adblock Radio, que melhora um pouco essa estratégia.
5. A combinação de classificação sonora e correspondência de impressões digitais (sucesso!)
Meu melhor algoritmo é
publicado no Github . Para aumentar a confiabilidade, ele combina conceitos de duas tentativas anteriores: classificação acústica e banco de dados de impressões digitais.
Um preditor de aprendizado de máquina devidamente treinado fornece a classificação correta da maioria dos materiais de origem, mas não funciona em algumas situações (consulte a seção sobre melhorias futuras abaixo). O papel do módulo de correspondência de impressões digitais é reduzir os erros do módulo de aprendizado de máquina.
Nem todos os dados de treinamento conhecidos são inseridos no banco de dados de impressões digitais, mas apenas um pequeno subconjunto em que o aprendizado de máquina mostra erros. Eu chamo de "banco de dados da lista quente". O tamanho pequeno ajuda a reduzir a taxa de erro geral, mantendo a carga da CPU baixa.
Em um laptop comum, o algoritmo consome apenas 5 a 10% da CPU nos arquivos e 10 a 20% no ar.
Melhorias futuras
Alguns tipos de conteúdo ainda são problemáticos.
O detector funciona imperfeitamente em alguns tipos específicos de conteúdo de áudio:
- A música hip-hop é frequentemente reconhecida como publicidade. Você pode solucionar o problema adicionando faixas à lista direta, mas isso é muita música. Uma rede neural mais geral poderia ser desenvolvida, possivelmente à custa do desempenho.
- os anúncios de álbuns de música são frequentemente reconhecidos como música. Mas bloquear impressões digitais levará a falsos positivos quando uma música real for transmitida. O problema pode ser resolvido por uma análise mais profunda do contexto, mas é difícil no ar, onde o contexto é conhecido apenas alguns segundos à frente.
- Os anúncios de talk show geralmente são reconhecidos como conversa. Existem limites borrados, porque é uma conversa e um anúncio. Vemos o limite de possibilidades do classificador de publicidade / conversação / música. Para classificação por impressões digitais, usei a classe ad_self por algum tempo, que contém anúncios de talk show em estações específicas, mas com a introdução do algoritmo de aprendizado de máquina, parei de fazer isso. Convém recriar essa classe. Outra opção é uma melhor análise do contexto.
- publicidade nativa, onde o host lê o texto do patrocínio. No rádio, isso é raro e mais frequentemente em podcasts. O próximo passo lógico para bloquear essa publicidade é a introdução do software de reconhecimento de fala.
Cadeias de Markov para pós-processamento mais estável
A estabilidade pós-processamento pode ser melhorada. Atualmente, apenas limites de confiança são usados. Quando o valor limite é atingido, a última previsão confiável é realizada. Assim, o sistema às vezes salva um erro.
Os ciclos de publicidade, conversas e música são bastante cíclicos em todas as transmissões. Por exemplo, a publicidade geralmente dura alguns minutos. Para cada período de um intervalo comercial, você pode calcular a probabilidade de uma transição para outro estado (conversa ou música). Essa probabilidade ajudará a interpretar melhor as previsões barulhentas do algoritmo: é apenas um pequeno segmento de música no anúncio ou a quebra de publicidade foi concluída? Aqui,
os modelos ocultos de Markov serão uma boa área de pesquisa.
Rádio analógico ainda não suportado
Os sinais analógicos (FM) não foram testados e atualmente não são suportados. O ruído analógico substitui os métodos usados aqui. Podem ser necessários filtros e / ou algoritmos de reconhecimento de impressão digital resistentes ao ruído. Se isso acontecer, o programa poderá encontrar aplicativos mais amplos entre os usuários. No entanto, o rádio está mudando cada vez mais para tecnologias digitais sem ruído, como o
DAB e o rádio na Internet.
Não é recomendável executar o Adblock Radio na nuvem
Idealmente, o Adblock Radio deve ser executado apenas em dispositivos terminais. Mas agora os serviços em nuvem estão na moda. Além disso, essa é uma ótima ideia de negócio! O Adblock Radio testou duas opções de arquitetura com esse paradigma. No entanto, a experiência mostra que essa não é a melhor opção por razões técnicas e legais.
Opção 1. Retransmitir do servidor
O servidor pode retransmitir o conteúdo de áudio com tags de anúncio / conversa / música para os ouvintes. Testamos em 2016. Aqui surgem problemas legais, uma vez que a retransmissão do fluxo pode ser considerada uma falsificação e / ou violação de direitos autorais (embora eu não seja advogado). Também não tem uma boa escala, porque agora você é uma CDN e deve arcar com os custos.
Por uma piada, no domingo, quando eu estava fora por motivos familiares, a Rádio Adblock recebeu muito popular,
da qual ela caiu . Curiosidade: alguns dias depois, a
France Inter , uma importante estação de rádio pública francesa,
anunciou a Adblock Radio no horário nobre (mas sem nomeá-la). Esta é uma decisão editorial inesperada no contexto do fato de que os reguladores decidiram em 2016
relaxar as restrições à publicidade nas estações de rádio estatais , o que exacerbou a
disputa entre os funcionários e a administração da Radio France .
Algumas semanas depois, recebi ameaças do advogado da rede de rádio privada francesa
Les Indés Radio , supostamente com base em violação de direitos autorais e marca registrada. Não tendo recursos financeiros para proteção séria, tive que remover alguns fluxos do site, fechar parcialmente o site e alterar a arquitetura do sistema. Ao mesmo tempo, essa rede de rádio se recusou a cooperar na busca de um compromisso. Como vejo nos logs que eles continuaram monitorando meu site (às vezes com contas pseudônimas), eles também consultaram
seus advogados . Que honra para mim! Olhando para trás, eles ganharam tempo com sucesso, mas nada mais. Olá pessoal do Indés! Espero que você goste de ler isso!
xoxoxo .
 Declaração de amor da Les Indés, uma rede de 131 estações de rádio francesas
Declaração de amor da Les Indés, uma rede de 131 estações de rádio francesasOpção 2. O servidor retransmite o som, mas em particular
Isso pressupõe análise no servidor e retransmitindo o som limpo para um usuário específico. Esse sistema pode ser isento da lei de direitos autorais como sua própria cópia privada da mídia. Se o servidor for gerenciado pelo usuário final e a fonte original for legal e oficialmente disponível em sua região, provavelmente tudo estará legalmente limpo. Veja a discussão do
Station Ripper [FR] e
VCast [FR] para mais informações. Mas os usuários raramente são conhecedores de tecnologia para alugar e instalar um servidor por conta própria.
É muito tentador colocar o servidor sob o controle de terceiros, mas isso gera problemas legais, porque o operador que está fazendo a cópia e o usuário final não são a mesma pessoa. Nesse caso, restrições legais são impostas, pelo menos na França. O serviço de Internet francês
Wizzgo [FR] encontrou essa regra em 2008. Mais recentemente, nos EUA, o serviço de televisão
Aereo foi encerrado, embora tenha tomado precauções ao distribuir um
sintonizador separado (!) Para
cada cliente .
No momento, o serviço
Molotov.TV [FR] está lutando contra os detentores de direitos autorais que desejam
limitar suas funções [FR] , apesar da influência significativa de seus cofundadores.
O imposto de cópia particular [FR] deve ser
pago à organização oficial . A quantia é determinada por
cálculos bastante opacos [FR] e
aumenta [FR] a cada ano, atingindo várias dezenas de eurocentes por usuário por mês. Essa placa ficou tão alta que o Molotov.TV recentemente
removeu os recursos de seu serviço para usuários gratuitos [FR] . (Nota: agradeço sinceramente aos jornalistas do site francês
NextINpact pela excelente cobertura deste tópico).
Pagar não é suficiente: a lei exige que entidades como a Molotov.TV
assinem acordos [FR] com empresas com direitos autorais sobre a funcionalidade de seus serviços. Tente chegar a um acordo com as empresas de rádio se você começar a cortar seus anúncios.
Opção 3. O servidor envia apenas metadados
Outra opção é que o usuário e o servidor escutem o mesmo rádio da Internet ao mesmo tempo. Nesse caso, o servidor analisa o som e envia os metadados de classificação do usuário (anúncio / conversa / música), mas não o conteúdo de áudio. Desde 2017, o
adblockradio.com trabalha nessa arquitetura. Ele conta com a CDN, portanto, não incorre em nenhum custo em relação à transmissão de áudio.
Essa arquitetura elimina o problema de violação de direitos autorais (exoneração de responsabilidade: não sou advogado). No entanto, ainda pode haver alguma incerteza quanto às leis de marcas registradas. Recentemente (outubro de 2018), os
proprietários de rádios da
Skyrock exigiram que o conteúdo fosse removido nessa base.
 Romance do Departamento Jurídico de Skyrock
Romance do Departamento Jurídico de SkyrockAlém de considerações legais, há um problema técnico com a sincronização adequada entre áudio e metadados. Na maioria dos casos, tudo funciona bem com um intervalo de sincronização de menos de dois segundos. Mas algumas estações de rádio possuem CDNs estranhas / mal-intencionadas ou injetam anúncios dinamicamente no fluxo. Isso significa que os fluxos entre o servidor e diferentes clientes podem variar significativamente. Por exemplo, na
Rádio FG , as defasagens foram observadas até 20 segundos e na
Rádio Jazz - até 45 segundos. Isso desaponta os ouvintes.
A sincronização pode ser totalmente implementada comparando blocos de dados entre o servidor e o usuário. Infelizmente, isso não funciona em navegadores da Web, porque a maioria das CDNs nas estações de rádio da Internet não usa
cabeçalhos CORS . Portanto, o JavaScript no navegador não poderá ler o conteúdo de áudio para comparação. Para o trabalho, você precisará de módulos independentes separados (por exemplo,
Electron ), módulos Flash (sim) ou extensões da Web, o que parece um pouco redundante.
Você pode integrar o Adblock Radio ao seu player
Este projeto não é para usuários finais, mas para empresas que lançam um produto em massa. Você pode fazer isso!
Os desenvolvedores têm duas opções para integrar o Adblock Radio. Primeiro, o
SDK simplesmente pega metadados do servidor adblockradio.com. Esta não é uma solução ideal pelos motivos descritos acima (problemas legais e de sincronização). É melhor executar um
algoritmo de análise completo.
De software
- Aplicativos móveis para rádio na Internet e podcasts. Os modelos Keras precisam ser convertidos para o Tensorflow nativo, e a biblioteca Keras + Tensorflow pode ser substituída pelo Tensorflow Lite para Android e iOS . As rotinas do Node.JS são implementadas usando o plug-in React Native ou, em casos extremos, com o Termux .
- extensões de navegador funcionam com Tensorflow JS e SQL.js. A extensão pode controlar o controle deslizante de volume nos diretórios populares de rádio da Internet, como TuneIn ou Radio.de . Eu já trabalhei nessa extensão. Foi divertido bisbilhotar jogadores em JavaScript para obter esse controle. Dependendo da implementação, lembre-se dos problemas de sincronização que discutimos acima.
Hardware
- alarmes digitais e projetos amadores, sujeitos à disponibilidade de energia computacional e acesso à rede suficientes. Plataformas como Raspberry Pi Zero / A / B devem ser suficientes para analisar um único fluxo, embora o RPi 3B / 3B + seja recomendado para controle paralelo de vários fluxos. O Tensorflow está no Raspbian .
- alto-falantes conectados, como o Sonos . O algoritmo em si não funcionará em tais equipamentos; portanto, você precisa processar dados na nuvem ou em um dispositivo separado na mesma rede local (por exemplo, no Raspberry). Ótima idéia para uma campanha de crowdfunding.
Rádio Adblock no carro
O carro é um dos lugares mais populares para ouvir rádio. Lá, as pessoas realmente precisam de um bloqueador de anúncios. Mas esse também é o contexto em que a implementação do Adblock Radio não é fácil. Afinal, o sistema deve receber feedback para filtrar efetivamente novos anúncios, para que o programa precise de uma conexão de rede. Vejo três conceitos possíveis para produtos automotivos com o Adblock Radio.
- Uma aplicação compatível com os sistemas de informação e lazer dos carros modernos . Provavelmente, a maneira mais fácil de transmitir dados é através do smartphone do usuário. O smartphone também pode ser usado separadamente - com um aplicativo móvel, transmitindo rádio pela Internet, via saída de áudio, conectando-se ao AUX ou Bluetooth do carro. Também pode ser integrado ao sistema de informação e entretenimento do carro, no espírito do Apple Car Play , Android Auto e MirrorLink . Seria fantástico ouvir rádio terrestre (FM, DAB). Mas é necessário trabalho para determinar em quais configurações específicas o Adblock Radio pode acessar a saída de áudio do sintonizador de rádio e, ao mesmo tempo, controlá-lo (volume, canal).
- Adaptador de hardware universal, interface de usuário dedicada . Também é possível desenvolver equipamentos personalizados semelhantes aos adaptadores DAB existentes para automóveis . Esses dispositivos sintonizam estações de rádio e transmitem dados de áudio para o sistema veicular via conector AUX ou via canal FM não utilizado, como os adaptadores antigos do iPod FM . O acesso à rede pode passar por um smartphone via Bluetooth. Soluções alternativas, como Sigfox e LoRa , podem ser consideradas se a taxa de bits e o preço forem adequados. Uma interface de usuário especial deve ser desenvolvida, separada do dispositivo principal do carro. No final, isso pode ser muito caro.
- Um dispositivo minimalista que entra no receptor de FM . Um dispositivo tão pequeno pode controlar o sintonizador, se necessário. Precisa de uma interface padrão, mas fácil de conectar. Os interruptores do volante são um bom candidato, mas os usuários finais não podem modificá-los facilmente para essa finalidade. Então você precisa invadir o sistema.
Este dispositivo sem cabeça terá um sintonizador de FM e microfone para analisar qual estação o usuário está ouvindo (correlação cruzada). Quando um anúncio é detectado, o dispositivo emite dados RDS falsos (como avisos de trânsito ) para enganar o sintonizador do carro e mudar de estação durante o anúncio. FM-.
, . , . , , . , , DAB.
, . , .
Adblock Radio , , . , .
: () , .
.
. , , adblockradio.com.
, -. . , ,
, .
: UX
: . , . !
adblockradio.com :
, - . , ,
. .
 - Adblock Radio
- Adblock Radio , . . , . . ! ,
, . . , . . ! ,. adblockradio.com , . (
Github ),
. 10 ( , , 7.30 7.20). — . . , .
, . , ? , ( ) .
 . . , , — . (ads),
. . , , — . (ads),— . , , . . -, «» , : , , , . . ,
- .
Conclusão
, . . , , , WiFi-. (FM, DAB+). , , .
Adblock Radio.- : , , . ? , .
- : , , . Electron.
- : , Adblock Radio . .
! , .