Pouco mais de um ano com a minha participação, ocorreu o seguinte "diálogo":
.Net App : Hey Entity Framework, por favor, me dê muitos dados!
Estrutura de entidades : desculpe, eu não entendi você. Como assim?
.Net App : Sim, acabei de receber uma coleção de 100 mil transações. E agora precisamos verificar rapidamente a correção dos preços dos valores mobiliários que são indicados lá.
Entity Framework : Ahh, bem, vamos tentar ...
.Net App : Aqui está o código:
var query = from p in context.Prices join t in transactions on new { p.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; query.ToList();
Estrutura da entidade :

Clássico Eu acho que muitas pessoas estão familiarizadas com esta situação: quando eu realmente quero "lindamente" e rapidamente faço uma pesquisa no banco de dados usando o JOIN da coleção local e o DbSet . Geralmente essa experiência é decepcionante.
Neste artigo (que é uma tradução gratuita do meu outro artigo ), conduzirei uma série de experimentos e tentarei diferentes maneiras de contornar essa limitação. Haverá um código (sem complicações), pensamentos e algo como um final feliz.
1. Introdução
Todo mundo conhece o Entity Framework , muitos o utilizam todos os dias e há muitos bons artigos sobre como prepará-lo corretamente (use consultas mais simples, use os parâmetros em Ignorar e Aceitar, use o VIEW, solicite apenas os campos necessários, monitore o cache de consultas e outro), no entanto, o tema JOIN da coleção local e DbSet ainda é um ponto fraco.
Desafio
Suponha que exista um banco de dados com preços e que haja uma coleção de transações para as quais você precisa verificar a exatidão dos preços. E suponha que tenhamos o seguinte código.
var localData = GetDataFromApiOrUser(); var query = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId join t in localData on new { s.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; var result = query.ToList();
Este código não funciona no Entity Framework 6 . No Entity Framework Core - funciona, mas tudo será feito no lado do cliente e no caso de milhões de registros no banco de dados - isso não é uma opção.
Como eu disse, tentarei maneiras diferentes de contornar isso. Do simples ao complexo. Para minhas experiências, eu uso o código do repositório a seguir. O código é escrito usando: C # , .Net Core , EF Core e PostgreSQL .
Também tirei algumas métricas: tempo gasto e consumo de memória. Isenção de responsabilidade: se o teste foi realizado por mais de 10 minutos, eu o interrompi (a restrição é de cima). Máquina de teste Intel Core i5, 8 GB de RAM, SSD.
Esquema do banco de dados
Apenas 3 tabelas: preços , valores mobiliários e fontes de preços . Preços - contém 10 milhões de entradas.
Método 1. Ingênuo
Vamos começar de forma simples e usar o seguinte código:
Código para o método 1 var result = new List<Price>(); using (var context = CreateContext()) { foreach (var testElement in TestData) { result.AddRange(context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId)); } }
A idéia é simples: em um loop, lemos os registros do banco de dados, um de cada vez, e adicionamos à coleção resultante. Este código tem apenas uma vantagem - simplicidade. E uma desvantagem é a baixa velocidade: mesmo se houver um índice no banco de dados, na maioria das vezes será necessário comunicação com o servidor de banco de dados. As métricas são as seguintes:
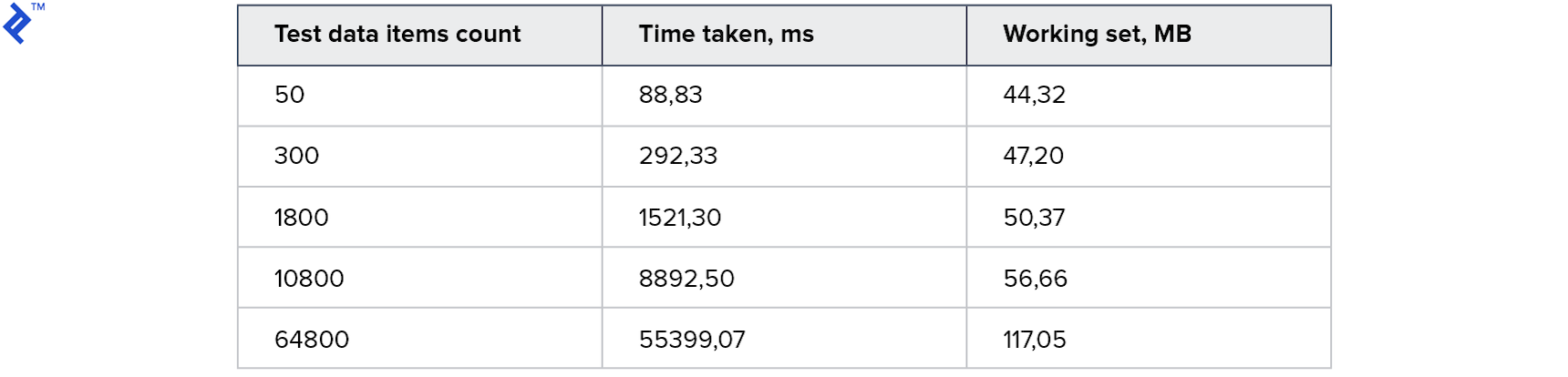
O consumo de memória é pequeno. Uma coleção grande leva 1 minuto. Para começar, não é ruim, mas eu quero isso mais rápido.
Método 2: paralelo ingênuo
Vamos tentar adicionar paralelismo. A idéia é acessar o banco de dados a partir de vários threads.
Código para o método 2 var result = new ConcurrentBag<Price>(); var partitioner = Partitioner.Create(0, TestData.Count); Parallel.ForEach(partitioner, range => { var subList = TestData.Skip(range.Item1) .Take(range.Item2 - range.Item1) .ToList(); using (var context = CreateContext()) { foreach (var testElement in subList) { var query = context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId); foreach (var el in query) { result.Add(el); } } } });
Resultado:
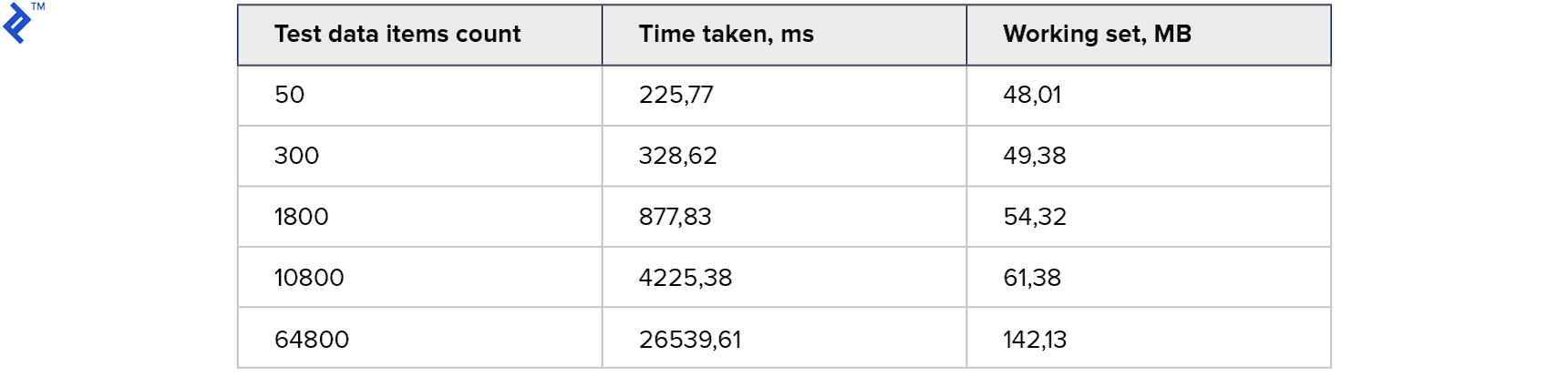
Para coleções pequenas, essa abordagem é ainda mais lenta que o primeiro método. E para os maiores - duas vezes mais rápido. Curiosamente, 4 threads foram gerados na minha máquina, mas isso não levou à aceleração de 4x. Isso sugere que a sobrecarga nesse método é significativa: no lado do cliente e no servidor. O consumo de memória aumentou, mas não significativamente.
Método 3: vários contém
Hora de tentar outra coisa e tentar reduzir a tarefa para uma consulta. Isso pode ser feito da seguinte maneira:
- Prepare 3 coleções exclusivas de Ticker , PriceSourceId e Date
- Execute a solicitação e use 3 Contém
- Verifique novamente os resultados localmente
Código para o método 3 var result = new List<Price>(); using (var context = CreateContext()) {
O problema aqui é que o tempo de execução e a quantidade de dados retornados são altamente dependentes dos dados em si (na consulta e no banco de dados). Ou seja, apenas um conjunto de dados necessários pode retornar e registros extras podem ser retornados (até 100 vezes mais).
Isso pode ser explicado usando o exemplo a seguir. Suponha que exista a seguinte tabela com dados:

Suponha também que eu precise de preços para o Ticker1 com TradedOn = 01-01-2018 e para o Ticker2 com TradedOn = 02-01-2018 .
Em seguida, valores exclusivos para Ticker = ( Ticker1 , Ticker2 )
E valores exclusivos para TradedOn = ( 2018-01-01 , 2018-01-02 )
No entanto, 4 registros serão retornados como resultado, porque eles realmente correspondem a essas combinações. O ruim é que, quanto mais campos são usados, maior a chance de obter registros extras como resultado.
Por esse motivo, os dados obtidos por esse método devem ser filtrados adicionalmente no lado do cliente. E essa é a maior desvantagem.
As métricas são as seguintes:
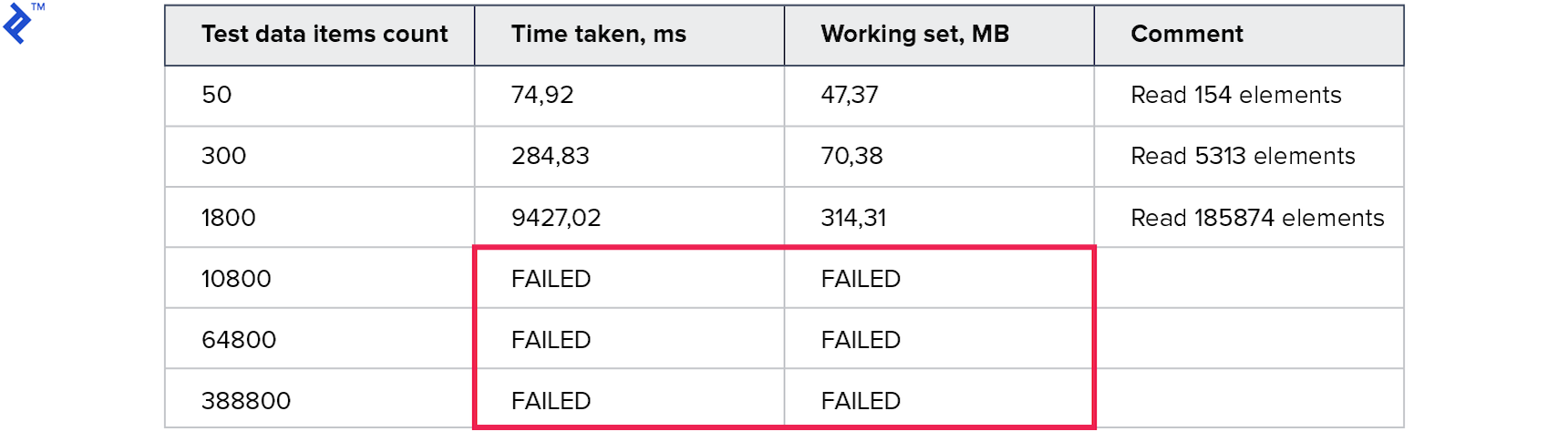
O consumo de memória é pior que todos os métodos anteriores. O número de linhas lidas é muitas vezes maior que o número solicitado. Os testes para grandes coleções foram interrompidos porque foram executados por mais de 10 minutos. Este método não é bom.
Método 4. Construtor de Predicado
Vamos tentar do outro lado: a boa e velha expressão . Com eles, você pode criar 1 consulta grande no seguinte formato:
… (.. AND .. AND ..) OR (.. AND .. AND ..) OR (.. AND .. AND ..) …
Isso dá esperança de que seja possível criar 1 solicitação e obter apenas os dados necessários para 1 chamada. Código:
Código para o método 4 var result = new List<Price>(); using (var context = CreateContext()) { var baseQuery = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId select new TestData() { Ticker = s.Ticker, TradedOn = p.TradedOn, PriceSourceId = p.PriceSourceId, PriceObject = p }; var tradedOnProperty = typeof(TestData).GetProperty("TradedOn"); var priceSourceIdProperty = typeof(TestData).GetProperty("PriceSourceId"); var tickerProperty = typeof(TestData).GetProperty("Ticker"); var paramExpression = Expression.Parameter(typeof(TestData)); Expression wholeClause = null; foreach (var td in TestData) { var elementClause = Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, tradedOnProperty), Expression.Constant(td.TradedOn) ), Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, priceSourceIdProperty), Expression.Constant(td.PriceSourceId) ), Expression.Equal( Expression.MakeMemberAccess( paramExpression, tickerProperty), Expression.Constant(td.Ticker)) )); if (wholeClause == null) wholeClause = elementClause; else wholeClause = Expression.OrElse(wholeClause, elementClause); } var query = baseQuery.Where( (Expression<Func<TestData, bool>>)Expression.Lambda( wholeClause, paramExpression)).Select(x => x.PriceObject); result.AddRange(query); }
O código acabou sendo mais complicado do que nos métodos anteriores. Construir manualmente o Expression não é a operação mais fácil e rápida.
Métricas:
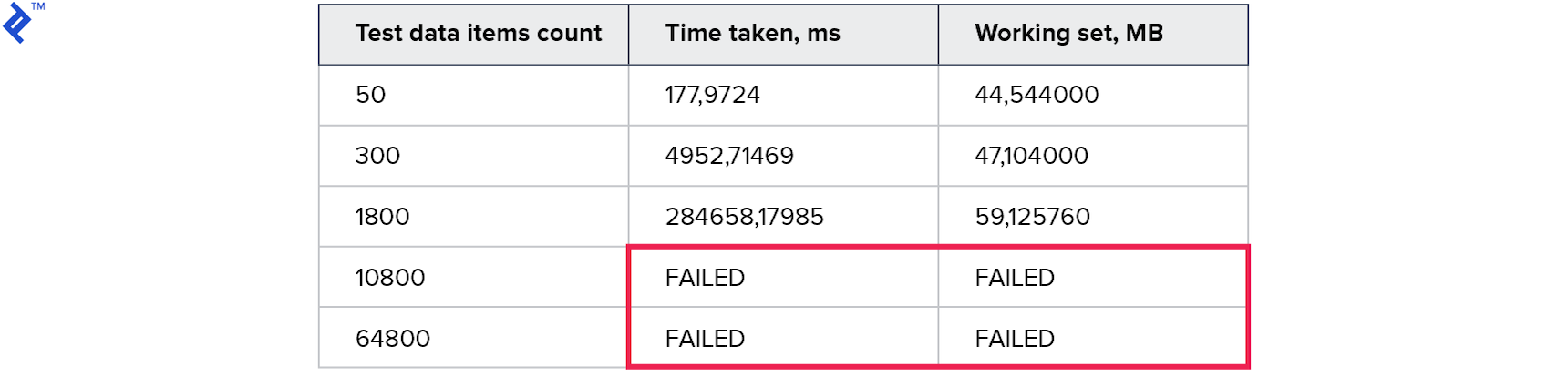
Os resultados temporários foram ainda piores do que no método anterior. Parece que a sobrecarga durante a construção e ao andar pela árvore acabou sendo muito mais do que o ganho do uso de uma solicitação.
Método 5: tabela de dados de consulta compartilhada
Vamos tentar outra opção:
Criei uma nova tabela no banco de dados na qual gravarei os dados necessários para concluir a solicitação (implicitamente, preciso de um novo DbSet no contexto).
Agora, para obter o resultado, você precisa:
- Iniciar transação
- Carregar dados da consulta para uma nova tabela
- Execute a própria consulta (usando a nova tabela)
- Reverter uma transação (para limpar a tabela de dados para consultas)
O código fica assim:
Código para o método 5 var result = new List<Price>(); using (var context = CreateContext()) { context.Database.BeginTransaction(); var reducedData = TestData.Select(x => new SharedQueryModel() { PriceSourceId = x.PriceSourceId, Ticker = x.Ticker, TradedOn = x.TradedOn }).ToList();
Primeiras métricas:
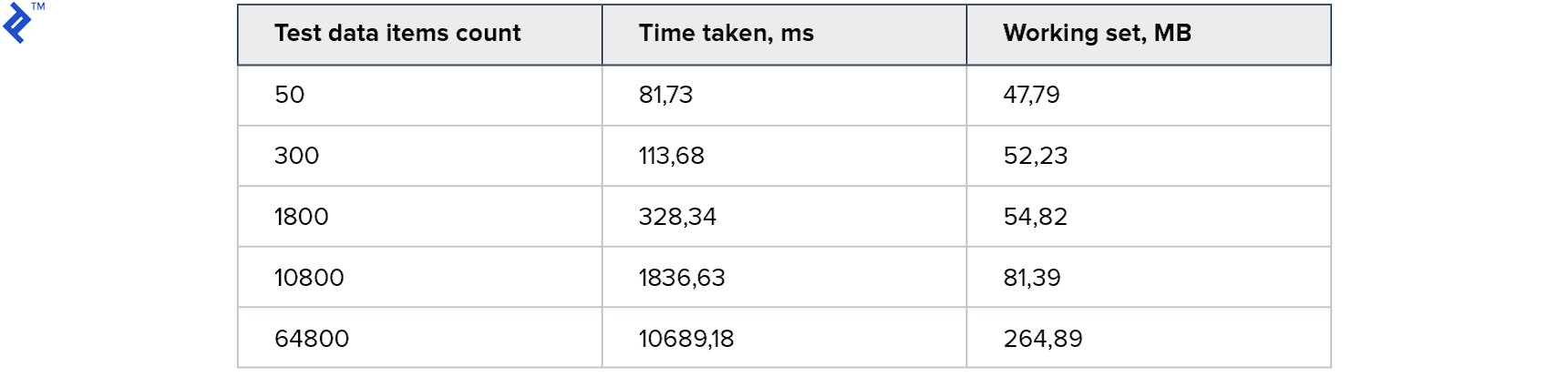
Todos os testes funcionaram e funcionaram rapidamente! O consumo de memória também é aceitável.
Assim, através do uso de uma transação, esta tabela pode ser usada simultaneamente por vários processos. E como essa é uma tabela existente, todos os recursos do Entity Framework estão disponíveis para nós: você só precisa carregar os dados na tabela, criar uma consulta usando JOIN e executá-la. À primeira vista, é disso que você precisa, mas há desvantagens significativas:
- Você deve criar uma tabela para um tipo específico de consulta
- É necessário usar transações (e desperdiçar recursos de DBMS nelas)
- E a própria idéia de que você precisa ESCREVER algo, quando precisa ler, parece estranha. E na Read Replica, simplesmente não funciona.
E o resto é uma solução mais ou menos funcional que já pode ser usada.
Método 6. Extensão MemoryJoin
Agora você pode tentar melhorar a abordagem anterior. Os pensamentos são:
- Em vez de usar uma tabela específica para um tipo de consulta, você pode usar alguma opção generalizada. Ou seja, crie uma tabela com um nome como shared_query_data e adicione vários campos Guid , vários Long , vários String etc. a ele. Nomes simples podem ser usados : Guid1 , Guid2 , String1 , Long1 , Date2 , etc. Em seguida, esta tabela pode ser usada para 95% dos tipos de consulta. Os nomes das propriedades podem ser "ajustados" posteriormente usando a perspectiva Selecionar .
- Em seguida, você precisa adicionar um DbSet para shared_query_data .
- Mas e se, em vez de gravar dados no banco de dados, transmitir valores usando a construção VALUES ? Ou seja, é necessário que na consulta SQL final, em vez de acessar shared_query_data, haja um apelo a VALUES . Como fazer isso?
- No Entity Framework Core - apenas usando o FromSql .
- No Entity Framework 6 - é necessário usar DbInterception - ou seja, altere o SQL gerado adicionando a construção VALUES imediatamente antes da execução. Isso resultará em uma limitação: em uma única solicitação, não mais que uma construção VALUES . Mas vai funcionar!
- Como não vamos gravar no banco de dados, obtemos a tabela shared_query_data criada na primeira etapa, não é necessária? Resposta: sim, não é necessário, mas o DbSet ainda é necessário, pois o Entity Framework deve conhecer o esquema de dados para criar consultas. Acontece que precisamos de um DbSet para algum modelo generalizado que não exista no banco de dados e seja usado apenas para inspirar o Entity Framework, que ele sabe o que está fazendo.
Converter IEnumerable em IQueryable Example- A entrada recebeu uma coleção de objetos do seguinte tipo:
class SomeQueryData { public string Ticker {get; set;} public DateTimeTradedOn {get; set;} public int PriceSourceId {get; set;} }
- Temos à nossa disposição DbSet com os campos String1 , String2 , Date1 , Long1 , etc
- Deixe o Ticker ser armazenado em String1 , TradedOn em Date1 e PriceSourceId em Long1 ( int mapeia em long , para não criar campos para int e long separados)
- Então FromSql + VALUES será assim:
var query = context.QuerySharedData.FromSql( "SELECT * FROM ( VALUES (1, 'Ticker1', @date1, @id1), (2, 'Ticker2', @date2, @id2) ) AS __gen_query_data__ (id, string1, date1, long1)")
- Agora você pode fazer uma projeção e retornar um IQueryable conveniente usando o mesmo tipo que estava na entrada:
return query.Select(x => new SomeQueryData() { Ticker = x.String1, TradedOn = x.Date1, PriceSourceId = (int)x.Long1 });
Consegui implementar essa abordagem e até projetá-la como um pacote NuGet EntityFrameworkCore.MemoryJoin (o código também está disponível). Apesar do nome conter a palavra Core , o Entity Framework 6 também é suportado. Eu o chamei de MemoryJoin , mas na verdade ele envia dados locais para o DBMS na construção VALUES e todo o trabalho é feito nele.
O código é o seguinte:
Código para o método 6 var result = new List<Price>(); using (var context = CreateContext()) {
Métricas:
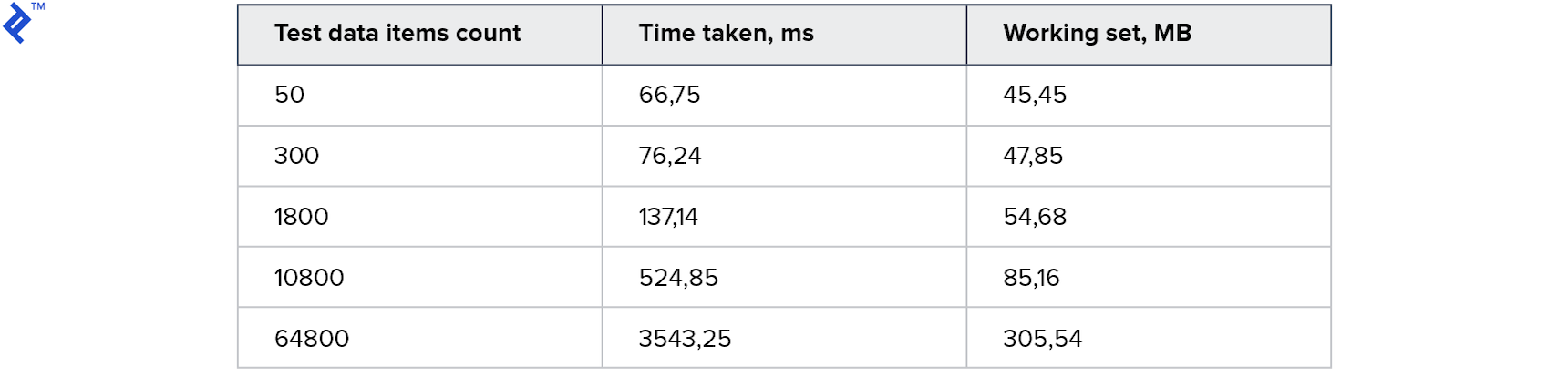
Este é o melhor resultado que eu já tentei. O código era muito simples e direto e, ao mesmo tempo, trabalhava para a Read Replica.
Um exemplo de uma solicitação gerada para receber 3 elementos SELECT "p"."PriceId", "p"."ClosePrice", "p"."OpenPrice", "p"."PriceSourceId", "p"."SecurityId", "p"."TradedOn", "t"."Ticker", "t"."TradedOn", "t"."PriceSourceId" FROM "Price" AS "p" INNER JOIN "Security" AS "s" ON "p"."SecurityId" = "s"."SecurityId" INNER JOIN ( SELECT "x"."string1" AS "Ticker", "x"."date1" AS "TradedOn", CAST("x"."long1" AS int4) AS "PriceSourceId" FROM ( SELECT * FROM ( VALUES (1, @__gen_q_p0, @__gen_q_p1, @__gen_q_p2), (2, @__gen_q_p3, @__gen_q_p4, @__gen_q_p5), (3, @__gen_q_p6, @__gen_q_p7, @__gen_q_p8) ) AS __gen_query_data__ (id, string1, date1, long1) ) AS "x" ) AS "t" ON (("s"."Ticker" = "t"."Ticker") AND ("p"."PriceSourceId" = "t"."PriceSourceId")
Aqui você também pode ver como o modelo generalizado (com os campos String1 , Date1 , Long1 ) usando Select se transforma no modelo usado no código (com os campos Ticker , TradedOn , PriceSourceId ).
Todo o trabalho é realizado em uma consulta no servidor SQL. E este é um pequeno final feliz, sobre o qual falei no início. No entanto, o uso desse método requer compreensão e as seguintes etapas:
- Você precisa adicionar um DbSet adicional ao seu contexto (embora a própria tabela possa ser omitida )
- No modelo generalizado, que é usado por padrão, são declarados 3 campos dos tipos Guid , String , Double , Long , Date , etc. Isso deve ser suficiente para 95% dos tipos de solicitação. E se você passar uma coleção de objetos com 20 campos para FromLocalList , uma exceção será lançada, dizendo que o objeto é muito complexo. Essa é uma restrição simples e pode ser contornada - você pode declarar seu tipo e adicionar pelo menos 100 campos lá. No entanto, mais campos são mais lentos para o trabalho.
- Mais detalhes técnicos estão descritos no meu artigo .
Conclusão
Neste artigo, apresentei meus pensamentos sobre o tópico JOIN collection local e DbSet. Pareceu-me que meu desenvolvimento usando VALUES poderia ser de interesse da comunidade. Pelo menos não encontrei essa abordagem quando resolvi esse problema. Pessoalmente, esse método me ajudou a superar vários problemas de desempenho em meus projetos atuais, talvez também o ajude.
Alguém dirá que o uso do MemoryJoin é muito "obscuro" e precisa ser mais desenvolvido, e até então você não precisa usá-lo. Esta é exatamente a razão pela qual fiquei muito duvidosa e, durante quase um ano, não escrevi este artigo. Concordo que gostaria que o trabalho fosse mais fácil (espero que um dia), mas também digo que a otimização nunca foi uma tarefa dos juniores. A otimização sempre exige um entendimento de como a ferramenta funciona. E se houver uma oportunidade de obter aceleração em ~ 8 vezes ( Naive Parallel vs MemoryJoin ), eu dominaria 2 pontos e documentação.
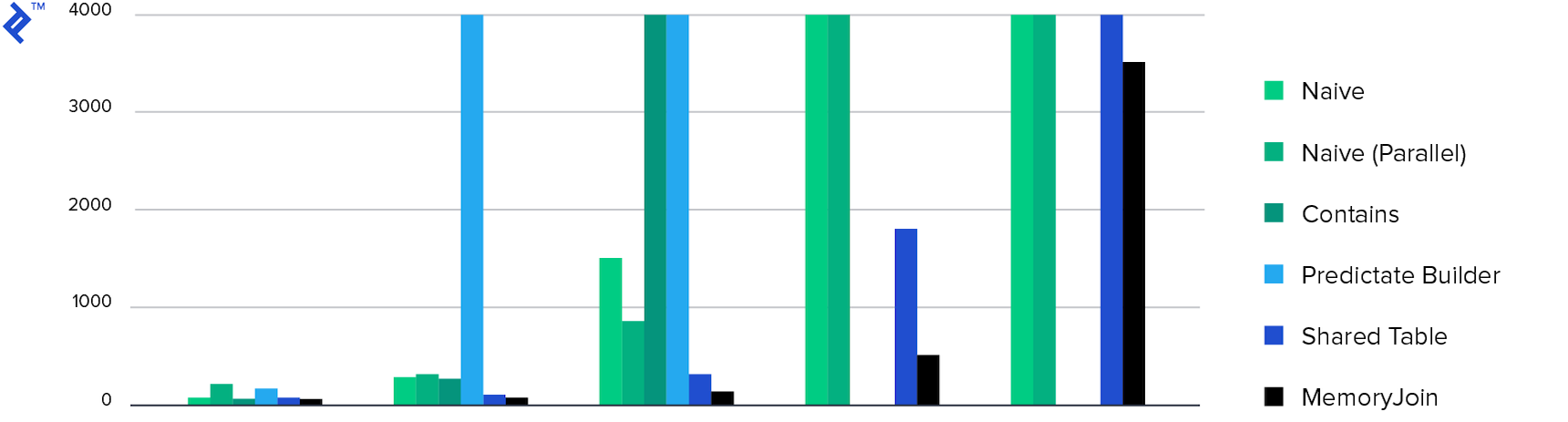
E, finalmente, os diagramas:
Tempo gasto. Apenas 4 métodos concluíram a tarefa em menos de 10 minutos e o MemoryJoin é a única maneira de concluir a tarefa em menos de 10 segundos.
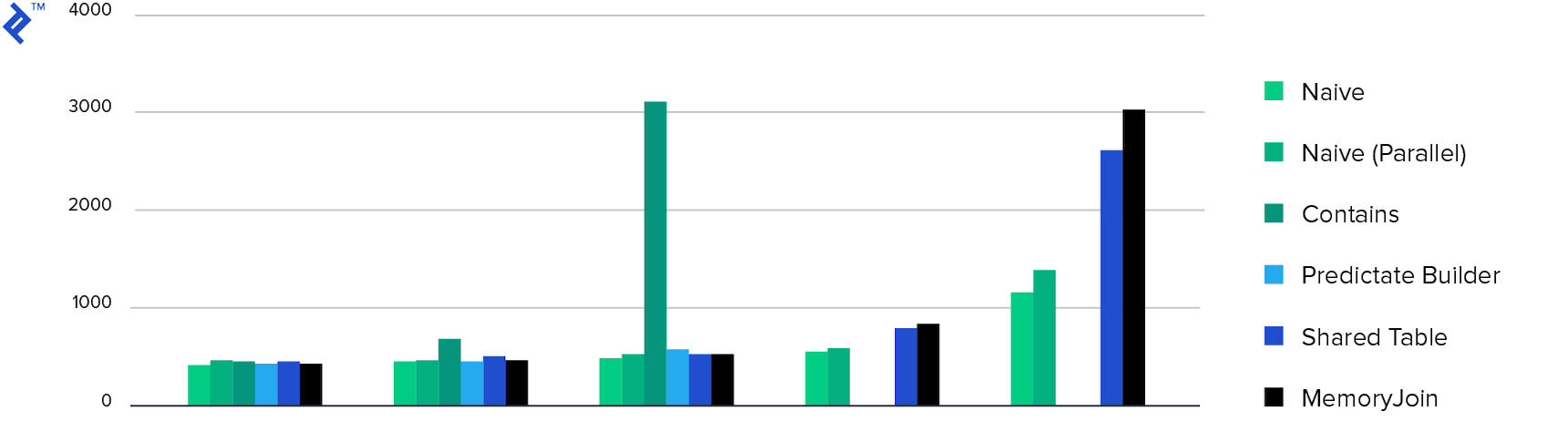
Consumo de memória. Todos os métodos mostraram aproximadamente o mesmo consumo de memória, exceto Múltiplos Contém . Isso ocorre devido à quantidade de dados retornados.
Obrigado pela leitura!