 A classificação de texto
A classificação de texto é uma das tarefas mais comuns na
PNL e na formação de professores, quando o conjunto de dados contém documentos de texto e etiquetas são usadas para treinar o classificador de texto.
Do ponto de vista da PNL, a tarefa de classificar o texto é realizada ensinando representação no nível das palavras usando incorporação de palavras e treinando representação no nível do texto usado como uma função para classificação.
O tipo de métodos baseados em codificação ignora pequenos detalhes e chaves para classificação (uma vez que a representação geral no nível do texto é estudada compactando as representações no nível da palavra).
 Métodos baseados em codificação para classificar texto com correspondência no nível do texto
Métodos baseados em codificação para classificar texto com correspondência no nível do textoEXAME - Novo método de classificação de texto
Pesquisadores da Universidade Shandong e da Universidade Nacional de Cingapura
propuseram um novo modelo de classificação de texto que incorpora sinais de correspondência no nível de palavras na tarefa de classificação de texto. Seu método usa um mecanismo de interação para introduzir dicas detalhadas no nível da palavra no processo de classificação.
Para resolver o problema de incluir sinais de correspondência mais precisos no nível das palavras, os pesquisadores propuseram
o cálculo explícito das estimativas de correspondência entre palavras e classes .
A idéia principal é calcular a matriz de interação a partir de uma representação no nível da palavra que carregará as chaves correspondentes no nível da palavra. Cada entrada nesta matriz é uma avaliação da correspondência entre uma palavra e uma classe específica.
A estrutura de classificação de texto proposta denominada EXAM - Modelo de interação explícita (
GitHub ) contém três componentes principais:
- codificador de nível de palavra,
- camada de interação e
- camada de agregação.
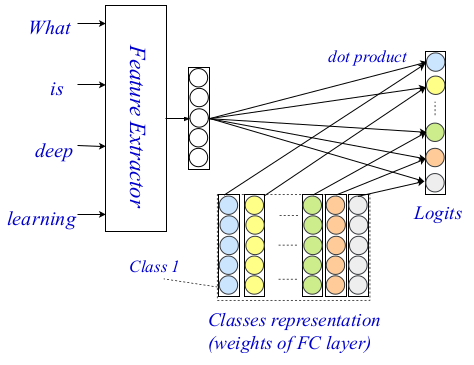
Essa arquitetura de três camadas permite codificar e classificar o texto usando sinais e sugestões pequenos e generalizados. A arquitetura inteira é mostrada na imagem abaixo.
 Arquitetura do EXAME
Arquitetura do EXAMENo passado, os codificadores em nível de palavra foram amplamente estudados na comunidade da PNL, e surgiram codificadores muito poderosos. Os autores usam o método sovermenny como um codificador no nível das palavras e, em seu trabalho, descrevem em detalhes dois outros componentes de sua arquitetura: o nível de interação e agregação.
A camada de interação, a principal contribuição e a novidade no método proposto são baseadas no conhecido mecanismo de interação. Os pesquisadores usam uma
matriz de apresentação treinada para codificar cada uma das classes, para que depois possam calcular as estimativas de interação entre as classes. As pontuações finais são afixadas usando um produto pontual como uma função da interação entre a palavra alvo e cada classe. Funções mais complexas não foram consideradas devido ao aumento da complexidade dos cálculos.
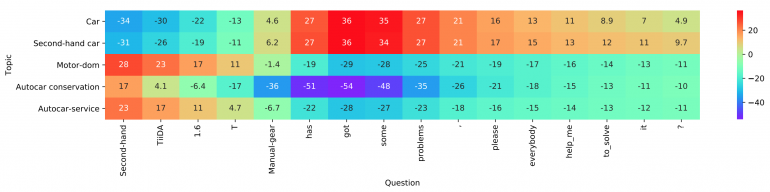 Visualização de camadas
Visualização de camadasPor fim, eles usam um MLP simples e totalmente conectado de duas camadas como camada de agregação. Eles também mencionam que um nível mais complexo de agregação, incluindo CNN ou LSTM, pode ser usado aqui. O MLP é usado para calcular os logits finais de classificação usando a matriz de interação e as codificações no nível da palavra. A entropia cruzada é usada como uma função de perda para otimização.
Notas
Para avaliar a estrutura proposta para a classificação do texto, os pesquisadores realizaram extensas experiências em condições de várias classes e várias marcas. Eles mostram que seu método é muito superior aos métodos modernos relevantes modernos.
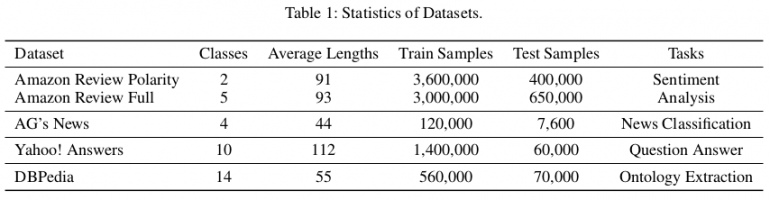 Estatísticas de conjuntos de dados usados para avaliação
Estatísticas de conjuntos de dados usados para avaliaçãoPara avaliação, eles estabelecem três tipos básicos diferentes de modelos:
- Modelos baseados no desenvolvimento de atributos;
- Modelos profundos baseados em caracteres
- Modelos profundos baseados em palavras.
Os autores usaram conjuntos de dados de referência disponíveis ao público (Zhang, Zhao e LeCun 2015) para avaliar o método proposto. No total, existem seis conjuntos de dados de texto de classificação que correspondem às tarefas de análise de humor, classificação de notícias, perguntas e respostas e extração de ontologias, respectivamente. No artigo, eles mostram que o EXAM alcança o melhor desempenho entre três conjuntos de dados: AG, Yah. A. e DBP. A avaliação e a comparação com outros métodos podem ser vistas nas tabelas abaixo.
![Precisão do conjunto de testes [%] em tarefas de classificação de documentos com várias classes e comparação com outros métodos](https://habrastorage.org/getpro/habr/post_images/de7/8d8/b60/de78d8b6017c9624c347b0fb645ae0ae.png)

Conclusões
Este trabalho é uma importante contribuição para o processamento de linguagem natural (PNL). Este é o primeiro trabalho que introduz dicas de correspondência de nível de palavra mais precisas na classificação de texto em modelos de redes neurais profundas. O modelo proposto fornece indicadores avançados para vários conjuntos de dados.
Tradução - Stanislav Litvinov