O primeiro comentário sobre o maravilhoso artigo
Visão Subjetiva de uma Linguagem de Programação Ideal acabou sendo uma referência à
linguagem de programação Zig . Naturalmente, tornou-se interessante que tipo de linguagem é que afirma ser um nicho de C ++, D e Rust. Eu olhei - a linguagem parecia bonita e um tanto interessante. Sintaxe agradável, semelhante a si, abordagem original para tratamento de erros, corotinas integradas. Este artigo é uma breve visão geral da
documentação oficial intercalada com pensamentos e impressões próprios dos exemplos de código em execução.
Introdução
Instalar o compilador é bastante simples, para Windows - basta descompactar o pacote de distribuição em alguma pasta. Nós criamos o arquivo de texto hello.zig na mesma pasta, inserimos o código da documentação e o salvamos. A montagem é feita pelo comando
zig build-exe hello.zig
após o qual hello.exe aparece no mesmo diretório.
Além da montagem, o modo de teste de unidade está disponível; para isso, os blocos de teste são usados no código, e a montagem e o lançamento dos testes são realizados por
zig test hello.zig
Primeiras esquisitices
O compilador não suporta quebras de linha do Windows (\ r \ n). Obviamente, o fato de que as quebras de linha em cada sistema (Win, Nix, Mac) serem parte delas é selvageria e uma relíquia do passado. Mas não há nada a ser feito; basta selecionar, por exemplo, no Notepad ++ o formato que você deseja para o compilador.
A segunda estranheza que me deparei por acidente - as guias não são suportadas no código! Apenas espaços. Mas acontece :)
No entanto, isso está escrito honestamente na documentação - a verdade já está no fim.
Comentários
Outra singularidade é que o Zig não suporta comentários de várias linhas. Lembro que tudo foi feito corretamente no antigo turbo pascal - comentários de várias linhas aninhados foram suportados. Aparentemente, desde então, nenhum desenvolvedor de idiomas dominou uma coisa tão simples :)
Mas existem comentários documentais. Comece com ///. Deve estar em determinados lugares - na frente dos objetos correspondentes (variáveis, funções, classes ...). Se eles estiverem em outro lugar - um erro de compilação. Nada mal.
Declaração variável
Feito no estilo moderno agora (e ideologicamente correto), quando a palavra-chave (const ou var) é escrita primeiro, depois o nome, depois o tipo e, em seguida, o valor inicial. I.e. inferência de tipo automática está disponível. As variáveis devem ser inicializadas - se você não especificar um valor inicial, haverá um erro de compilação. No entanto, é fornecido um valor indefinido especial, que pode ser usado explicitamente para especificar variáveis não inicializadas.
var i:i32 = undefined;
Saída do console
Para experimentos, precisamos de saída para o console - em todos os exemplos, este é o método usado. No campo de plug-ins
const warn = std.debug.warn;
e o código está escrito assim:
warn("{}\n{}\n", false, "hi");
O compilador possui alguns erros, que são honestamente relatados ao tentar gerar um número inteiro ou um ponto de ponto flutuante da seguinte maneira:
erro: erro do compilador: literais inteiro e flutuante na função var args devem ser convertidos. github.com/ziglang/zig/issues/557
Tipos de dados
Tipos primitivos
Aparentemente, os nomes dos tipos são obtidos do Rust (i8, u8, ... i128, u128), também existem tipos especiais para compatibilidade binária C, 4 tipos de tipos de ponto flutuante (f16, f32, f64, f128). Existe um tipo bool. Existe um tipo de comprimento nulo e um retorno especial, que discutirei mais adiante.
Você também pode construir tipos inteiros de qualquer tamanho em bits, de 1 a 65535. O nome do tipo começa com a letra i ou u e, em seguida, o comprimento em bits é gravado.
// ! var j:i65535 = 0x0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF;
No entanto, não foi possível obter esse valor no console - ocorreu um erro no LLVM durante a compilação.
Em geral, essa é uma solução interessante, embora ambígua (IMHO: o suporte a literais numéricos exatamente longos no nível do compilador esteja correto, mas nomear tipos dessa maneira não é muito bom, é melhor fazê-lo honestamente através de um tipo de modelo). E por que o limite é 65535? Bibliotecas como o GMP não parecem impor essas restrições?
Literais de string
Essas são matrizes de caracteres (sem zero no final). Para literais com um zero final, o prefixo 'c' é usado.
const normal_bytes = "hello"; const null_terminated_bytes = c"hello";
Como a maioria dos idiomas, o Zig suporta seqüências de escape padrão e a inserção de caracteres Unicode através de seus códigos (\ uNNNN, \ UNNNNNN, onde N é um dígito hexadecimal).
Literais de várias linhas são formados usando duas barras invertidas no início de cada linha. Não são necessárias aspas. Ou seja, algumas tentativas de criar cadeias brutas, mas o IMHO não tem êxito - a vantagem das cadeias brutas é que você pode inserir qualquer parte do texto de qualquer lugar do código - e, idealmente, não altera nada, mas aqui você deve adicionar \\ no início de cada linha.
const multiline = \\#include <stdio.h> \\ \\int main(int argc, char **argv) { \\ printf("hello world\n"); \\ return 0; \\} ;
Literais inteiros
Tudo está em idiomas semelhantes a si. Fiquei muito satisfeito com o fato de que, para literais octais, o prefixo 0o é usado, e não apenas zero, como em C. Literais binários com o prefixo 0b também são suportados. Literais de ponto flutuante podem ser hexadecimais (como é feito na
extensão GCC ).
Operações
Obviamente, existem operações C aritméticas, lógicas e bit a bit padrão. Operações abreviadas são suportadas (+ = etc.). Em vez de && e || as palavras-chave e e ou são usadas. Um ponto interessante é que operações com semântica envolvente garantida também são suportadas. Eles se parecem com isso:
a +% b a +%= b
Nesse caso, operações aritméticas comuns não garantem o estouro e seus resultados durante o estouro são considerados indefinidos (e erros de compilação são gerados para constantes). IMHO isso é um pouco estranho, mas aparentemente é feito de algumas considerações profundas de compatibilidade com a semântica da linguagem C.
Matrizes
Literais de matriz são assim:
const msg = []u8{ 'h', 'e', 'l', 'l', 'o' }; const arr = []i32{ 1, 2, 3, 4 };
Strings são matrizes de caracteres, como em C. Indexação clássica com colchetes. As operações de adição (concatenação) e multiplicação de matrizes são fornecidas. É uma coisa muito interessante, e se tudo estiver claro com concatenação e multiplicação - fiquei esperando até que alguém o implementasse e agora espero :) No Assembler (!) Há uma operação dup que permite gerar dados duplicados. Agora em Zig:
const one = []i32{ 1, 2, 3, 4 }; const two = []i32{ 5, 6, 7, 8 }; const c = one ++ two; // { 1,2,3,4,5,6,7,8 } const pattern = "ab" ** 3; // "ababab"
Ponteiros
A sintaxe é semelhante a C.
var x: i32 = 1234; // const x_ptr = &x; //
Para desreferenciar (pegar valores pelo ponteiro), uma operação incomum do postfix é usada:
x_ptr.* == 5678; x_ptr.* += 1;
O tipo de ponteiro é definido explicitamente, definindo um asterisco na frente do nome do tipo
const x_ptr : *i32 = &x;
Fatias (fatias)
Uma estrutura de dados incorporada à linguagem que permite fazer referência a uma matriz ou parte dela. Contém um ponteiro para o primeiro elemento e o número de elementos. É assim:
var array = []i32{ 1, 2, 3, 4 }; const slice = array[0..array.len];
Parece ter sido tirado do Go, não tenho certeza. E também não tenho certeza se vale a pena incorporar em um idioma, enquanto a implementação em qualquer idioma OOP de algo assim é muito elementar.
Estruturas
Uma maneira interessante de declarar uma estrutura: uma constante é declarada, cujo tipo é exibido automaticamente como "tipo" (tipo) e é isso que é usado como o nome da estrutura. E a própria estrutura (struct) é "sem nome".
const Point = struct { x: f32, y: f32, };
É impossível especificar um nome da maneira usual em linguagens do tipo C, no entanto, o compilador exibe o nome do tipo de acordo com certas regras - em particular, no caso considerado acima, ele coincidirá com o nome da constante “tipo”.
Em geral, o idioma não garante a ordem dos campos e seu alinhamento na memória. Se forem necessárias garantias, estruturas "empacotadas" devem ser usadas.
const Point2 = packed struct { x: f32, y: f32, };
Inicialização - no estilo dos designadores de Sishny:
const p = Point { .x = 0.12, .y = 0.34, };
Estruturas podem ter métodos. No entanto, colocar um método em uma estrutura é simplesmente usar a estrutura como um espaço para nome; ao contrário do C ++, nenhum parâmetro implícito é passado.
Transferências
Em geral, o mesmo que em C / C ++. Existem alguns meios internos convenientes de acessar meta-informações, por exemplo, o número de campos e seus nomes, implementados por macros de sintaxe incorporadas ao idioma (chamadas de funções internas na documentação).
Para "compatibilidade binária com C", algumas enumerações externas são fornecidas.
Para indicar o tipo que deve estar subjacente à enumeração, uma construção do formulário
packed enum(u8)
onde u8 é o tipo de base.
As enumerações podem ter métodos semelhantes às estruturas (por exemplo, usar um nome de enumeração como espaço para nome).
Sindicatos
Pelo que entendi, a união em Zig é uma soma de tipo algébrica, ou seja contém um campo de tag oculto que determina qual dos campos de união está "ativo". A “ativação” de outro campo é realizada por uma reatribuição completa de toda a associação. Exemplo de documentação
const assert = @import("std").debug.assert; const mem = @import("std").mem; const Payload = union { Int: i64, Float: f64, Bool: bool, }; test "simple union" { var payload = Payload {.Int = 1234}; // payload.Float = 12.34; // ! assert(payload.Int == 1234); // payload = Payload {.Float = 12.34}; assert(payload.Float == 12.34); }
Os sindicatos também podem usar explicitamente enumerações para a tag.
// Unions can be given an enum tag type: const ComplexTypeTag = enum { Ok, NotOk }; const ComplexType = union(ComplexTypeTag) { Ok: u8, NotOk: void, };
As uniões, como enumerações e estruturas, também podem fornecer seu próprio espaço para nome para métodos.
Tipos opcionais
O Zig possui suporte opcional embutido. Um ponto de interrogação é adicionado antes do nome do tipo:
const normal_int: i32 = 1234; // normal integer const optional_int: ?i32 = 5678; // optional integer
Curiosamente, Zig implementa uma coisa sobre a possibilidade de que eu suspeitava, mas não tinha certeza se estava certa ou não. Os ponteiros são compatíveis com as opções sem adicionar um campo oculto adicional (“tag”), que armazena um sinal da validade do valor; e null é usado como um valor inválido. Assim, os tipos de referência representados no Zig por ponteiros nem precisam de memória adicional para “opcionalidade”. Ao mesmo tempo, é proibido atribuir valores nulos a ponteiros regulares.
Tipos de erro
Eles são semelhantes aos tipos opcionais, mas, em vez da marca booleana (“realmente inválida”), um elemento de enumeração correspondente ao código de erro é usado. A sintaxe é semelhante às opções, um ponto de exclamação é adicionado em vez de um ponto de interrogação. Assim, esses tipos podem ser usados, por exemplo, para retornar de funções: o resultado do objeto da operação bem-sucedida da função é retornado ou um erro com o código correspondente é retornado. Os tipos de erro são uma parte importante do sistema de tratamento de erros do idioma Zig. Para obter mais detalhes, consulte a seção Tratamento de erros.
Tipo nulo
Variáveis como void e operações com elas são possíveis no Zig
var x: void = {}; var y: void = {}; x = y;
nenhum código é gerado para essas operações; esse tipo é útil principalmente para metaprogramação.
Há também um tipo de c_void para compatibilidade com C.
Operadores de controle e funções
Eles incluem: blocos, alternar, enquanto, por, se, mais, interromper, continuar. Para agrupar o código, colchetes padrão são usados. Apenas blocos, como em C / C ++, são usados para limitar o escopo das variáveis. Blocos podem ser considerados como expressões. Não há goto no idioma, mas existem rótulos que podem ser usados com as instruções break e continue. Por padrão, esses operadores trabalham com loops; no entanto, se um bloco tiver um rótulo, você poderá usá-lo.
var y: i32 = 123; const x = blk: { y += 1; break :blk y; // blk y };
A instrução switch difere do operador por não ter uma "explicação", ou seja, apenas uma condição (caso) é executada e o comutador sai. A sintaxe é mais compacta: em vez de maiúsculas e minúsculas, a seta "=>" é usada. Switch também pode ser considerado uma expressão.
As instruções while e if são geralmente as mesmas que em todos os idiomas semelhantes a C. A declaração for é mais parecida com foreach. Todos eles podem ser considerados como expressões. Dos novos recursos, while e for, assim como se, pode ter um bloco else que é executado se não houver iteração de loop.
E aqui é hora de falar sobre um recurso comum para o switch, enquanto, de alguma forma, é emprestado do conceito de loops foreach - variáveis de "captura". É assim:
while (eventuallyNullSequence()) |value| { sum1 += value; } if (opt_arg) |value| { assert(value == 0); } for (items[0..1]) |value| { sum += value; }
Aqui, o argumento while é uma certa "fonte" de dados, que pode ser opcional, para uma matriz ou uma fatia, e uma variável localizada entre duas linhas verticais contém um valor "expandido" - ou seja, o elemento atual da matriz ou fatia (ou um ponteiro para ele), o valor interno do tipo opcional (ou um ponteiro para ele).
Adiar e errar as declarações
A declaração de execução adiada emprestada do Go. Funciona da mesma maneira - o argumento desse operador é executado ao sair do escopo em que o operador é usado. Além disso, é fornecido o operador errdefer, que é acionado se um tipo de erro com um código de erro ativo for retornado da função. Isso faz parte do sistema original de tratamento de erros do Zig.
Operador inacessível
O elemento da programação do contrato. Uma palavra-chave especial, que é colocada onde o gerenciamento não deve vir sob nenhuma circunstância. Se ele chegar lá, nos modos Debug e ReleaseSafe, um pânico é gerado, e no ReleaseFast o otimizador lança esses ramos completamente.
voltar
Tecnicamente, é um tipo compatível em expressões com qualquer outro tipo. Isso é possível devido ao fato de que um objeto desse tipo nunca retornará. Como os operadores são expressões no Zig, é necessário um tipo especial para expressões que nunca serão avaliadas. Isso acontece quando o lado direito da expressão transfere irrevogavelmente o controle para algum lugar externo. Para tais declarações quebram, continuam, retornam, loops inacessíveis e infinitos e funções que nunca retornam o controle. Para comparação, uma chamada para uma função regular (retornando controle) não é um operador de retorno normal, porque, embora o controle seja transferido para fora, ele será retornado ao ponto de chamada mais cedo ou mais tarde.
Assim, as seguintes expressões se tornam possíveis:
fn foo(condition: bool, b: u32) void { const a = if (condition) b else return; @panic("do something with a"); }
A variável a obtém o valor retornado pela instrução if / else. Para isso, as partes (if e else) devem retornar uma expressão do mesmo tipo. A parte if retorna bool, a parte else é do tipo noreturn, tecnicamente compatível com qualquer tipo, como resultado, o código é compilado sem erros.
Funções
A sintaxe é clássica para idiomas desse tipo:
fn add(a: i8, b: i8) i8 { return a + b; }
Em geral, as funções parecem bastante padrão. Até o momento, não notei sinais de funções de primeira classe, mas meu conhecimento da linguagem é muito superficial, posso estar errado. Embora talvez isso ainda não tenha sido feito.
Outro recurso interessante é que, no Zig, ignorar valores retornados só pode ser explicitamente feito usando o sublinhado _
_ = foo();
Há uma reflexão que permite obter várias informações sobre a função
const assert = @import("std").debug.assert; test "fn reflection" { assert(@typeOf(assert).ReturnType == void); // assert(@typeOf(assert).is_var_args == false); // }
Execução de código em tempo de compilação
O Zig fornece um recurso poderoso - execução de código escrito em zig no momento da compilação. Para que o código seja executado em tempo de compilação, envolva-o em um bloco com a palavra-chave comptime. A mesma função pode ser chamada em tempo de compilação e em tempo de execução, o que permite escrever código universal. Obviamente, existem algumas limitações associadas a diferentes contextos do código. Por exemplo, na documentação de muitos exemplos, o comptime é usado para verificar o tempo de compilação:
// array literal const message = []u8{ 'h', 'e', 'l', 'l', 'o' }; // get the size of an array comptime { assert(message.len == 5); }
Mas é claro que o poder desse operador está longe de ser totalmente divulgado aqui. Assim, na descrição da linguagem, é dado um exemplo clássico do uso efetivo de macros sintáticas - a implementação de uma função semelhante à printf, mas analisando a sequência de formatação e conduzindo toda a verificação de tipo necessária de argumentos no estágio de compilação.
Além disso, a palavra comptime é usada para indicar os parâmetros das funções em tempo de compilação, que são semelhantes às funções do modelo C ++.
fn max(comptime T: type, a: T, b: T) T { return if (a > b) a else b; }
Tratamento de erros
O Zig inventou um sistema original de tratamento de erros que não era como outros idiomas. Isso pode ser chamado de "exceções explícitas" (nesse idioma, a explicitação geralmente é um dos idiomas). Também se parece com os códigos de retorno Go, mas funciona de maneira diferente.
O sistema de processamento de erros do Zig é baseado em enumerações especiais para implementar códigos de erro personalizados (erro) e construídos com base em "tipos de erro" (soma algébrica do tipo, combinando o tipo de função retornado e o código de erro).
As enumerações de erro são declaradas da mesma maneira que as enumerações regulares:
const FileOpenError = error { AccessDenied, OutOfMemory, FileNotFound, }; const AllocationError = error { OutOfMemory, };
No entanto, todos os códigos de erro recebem valores maiores que zero; Além disso, se você declarar um código com o mesmo nome em duas enumerações, ele receberá o mesmo valor. No entanto, conversões implícitas entre diferentes enumerações de erros são proibidas.
A palavra-chave anyerror significa uma enumeração que inclui todos os códigos de erro.
Como os tipos opcionais, o idioma suporta a geração de tipos de erro usando sintaxe especial. O tipo! U64 é uma forma abreviada de anyerror! U64, que por sua vez significa uma união (opção), que inclui o tipo u64 e o tipo anyerror (como eu o entendo, o código 0 é reservado para indicar a ausência de um erro e a validade do campo de dados, o restante dos códigos é códigos de erro).
A palavra-chave catch permite capturar o erro e transformá-lo em um valor padrão:
const number = parseU64(str, 10) catch 13;
Portanto, se ocorrer um erro na função parseU64 retornando o tipo! U64, o catch "interceptará" e retornará o valor padrão 13.
A palavra-chave try permite que você "encaminhe" o erro para o nível superior (ou seja, para o nível da função de chamada). Ver código
fn doAThing(str: []u8) !void { const number = try parseU64(str, 10); // ... }
equivalente a isso:
fn doAThing(str: []u8) !void { const number = parseU64(str, 10) catch |err| return err; // ... }
Aqui acontece o seguinte: parseU64 é chamado, se um erro é retornado - é interceptado pela instrução catch, na qual o código de erro é extraído usando a sintaxe "capture", colocada na variável err, retornada via! Void para a função de chamada.
O operador Errdefer descrito anteriormente também se refere ao tratamento de erros. O código do argumento de erro é executado apenas se a função retornar um erro.
Mais algumas possibilidades. Usando o || você pode mesclar conjuntos de erros
const A = error{ NotDir, PathNotFound, }; const B = error{ OutOfMemory, PathNotFound, }; const C = A || B;
O Zig também fornece recursos como rastreamento de erros. Isso é algo semelhante a um rastreamento de pilha, mas contém informações detalhadas sobre o erro que ocorreu e como ele se propagou ao longo da cadeia de tentativas, do local da ocorrência até a principal função do programa.
Portanto, o sistema de tratamento de erros no Zig é uma solução muito original, que não se parece com exceções no C ++ ou nos códigos de retorno no Go. Podemos dizer que essa solução tem um determinado preço - mais 4 bytes, que devem ser retornados juntamente com cada valor retornado; vantagens óbvias são visibilidade e transparência absolutas. Ao contrário do C ++, aqui a função não pode gerar uma exceção desconhecida em algum lugar profundo da cadeia de chamadas. Tudo o que a função retorna - ela retorna explicitamente e apenas explicitamente.Coroutines
O Zig possui corotinas embutidas. Essas são funções criadas com a palavra-chave assíncrona, com a qual as funções do alocador e do desalocador são transferidas (como eu entendo, para uma pilha adicional). test "create a coroutine and cancel it" { const p = try async<std.debug.global_allocator> simpleAsyncFn(); comptime assert(@typeOf(p) == promise->void); cancel p; assert(x == 2); } async<*std.mem.Allocator> fn simpleAsyncFn() void { x += 1; }
async retorna um objeto especial do tipo promessa-> T (onde T é o tipo de retorno da função). Usando esse objeto, você pode controlar a corotina.Os níveis mais baixos incluem as palavras-chave suspender, retomar e cancelar. Usando a suspensão, a execução da rotina é pausada e passada para o programa de chamada. A sintaxe do bloco de suspensão é possível, tudo dentro do bloco é executado até que a corotina seja realmente suspensa.resume pega um argumento do tipo promessa-> T e retoma a execução da corotina de onde foi suspensa.cancelar libera memória de rotina.Esta figura mostra a transferência de controle entre o programa principal (na forma de um teste) e a corotina. Tudo é bem simples: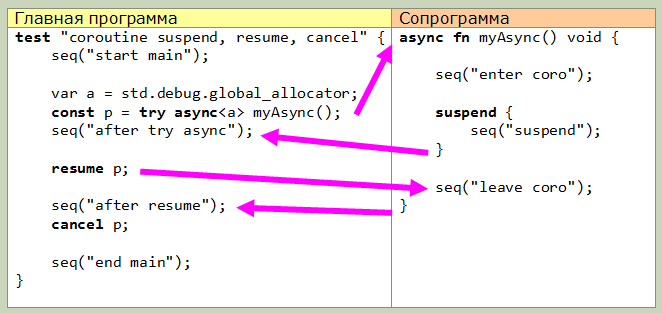 O segundo recurso (nível superior) é o uso de aguardar. Essa é a única coisa que, francamente, eu não entendi (infelizmente, a documentação ainda é muito escassa). Aqui está o diagrama de transferência de controle real de um exemplo ligeiramente modificado da documentação, talvez isso explique algo para você:
O segundo recurso (nível superior) é o uso de aguardar. Essa é a única coisa que, francamente, eu não entendi (infelizmente, a documentação ainda é muito escassa). Aqui está o diagrama de transferência de controle real de um exemplo ligeiramente modificado da documentação, talvez isso explique algo para você: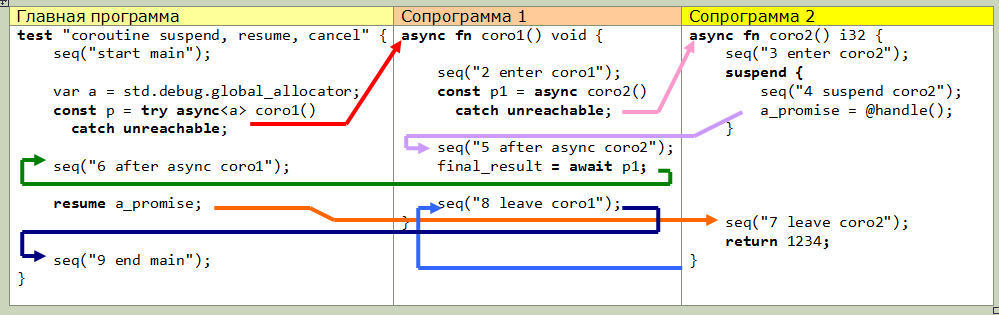
Funções incorporadas
funções embutidas - um conjunto razoavelmente grande de funções integradas ao idioma e não requer a conexão de nenhum módulo. Talvez seja mais correto chamar algumas delas de "macros sintáticas integradas", porque os recursos de muitos vão muito além das funções. os built-in fornecem acesso às ferramentas de reflexão (sizeOf, tagName, TagType, typeInfo, typeName, typeOf), com seus módulos de ajuda (importação) conectados. Outros são mais parecidos com o clássico C / C ++ interno - eles implementam conversões de tipo de baixo nível, várias operações como sqrt, popCount, slhExact, etc. É muito provável que a lista de funções internas mude à medida que o idioma se desenvolve.Em conclusão
É muito agradável que esses projetos apareçam e se desenvolvam. Embora a linguagem C seja conveniente, concisa e familiar para muitos, ainda está desatualizada e, por razões de arquitetura, não pode suportar muitos conceitos de programação modernos. O C ++ está em desenvolvimento, mas objetivamente reprojetado, está se tornando cada vez mais difícil a cada nova versão, e pelos mesmos motivos arquiteturais e devido à necessidade de compatibilidade com versões anteriores, nada pode ser feito sobre isso. A ferrugem é interessante, mas com um limiar de entrada muito alto, o que nem sempre é justificado. D é uma boa tentativa, mas existem algumas falhas menores, parece que inicialmente a linguagem foi criada com maior probabilidade sob a influência do Java, e os recursos subsequentes foram introduzidos de alguma forma, de alguma forma, não como deveriam. Obviamente, Zig é outra dessas tentativas. A linguagem é interessante, e é interessante ver o que sai dela.