TL; DR: GitHub: // PastorGL / AQLSelectEx .
Uma vez, não na estação fria, mas já na temporada de inverno, e especificamente alguns meses atrás, para um projeto em que eu estava trabalhando (algo geoespacial baseado em Big Data), eu precisava de um armazenamento NoSQL / Key-Value rápido.
Nós mastigamos terabytes de códigos-fonte com a ajuda do Apache Spark, mas o resultado final dos cálculos, diminuiu para uma quantidade ridícula (apenas milhões de registros), precisa ser armazenado em algum lugar. E é muito desejável armazenar de maneira que possa ser encontrado e enviado rapidamente usando os metadados associados a cada linha do resultado (este é um dígito) (mas existem muitos).
Os formatos da pilha Khadupov nesse sentido são de pouca utilidade, e os bancos de dados relacionais em milhões de registros diminuem a velocidade, e o conjunto de metadados não é tão fixo que se encaixa bem no esquema rígido de um RDBMS - PostgreSQL comum no nosso caso. Não, normalmente suporta JSON, mas ainda tem problemas com índices em milhões de registros. Os índices aumentam, torna-se necessário particionar a tabela e um incômodo com a administração começa que nafig-nafig.
Historicamente, o MongoDB era usado como NoSQL no projeto, mas com o tempo, o monga se mostrou cada vez pior (especialmente em termos de estabilidade), por isso foi gradualmente desativado. Uma busca rápida por uma alternativa mais moderna, rápida, com menos bugs e geralmente melhor levou ao Aerospike . Muitos caras grandes têm isso a favor, e eu decidi verificar.
Os testes mostraram que, de fato, os dados são armazenados na história diretamente do trabalho do Spark com um apito, e a pesquisa em muitos milhões de registros é muito mais rápida do que no mong. E ela come menos memória. Mas acabou um "mas". A API do cliente da solda aero é puramente funcional e não declarativa.
Para a gravação da história, isso não é importante, pois todos os tipos de campos de cada registro resultante devem ser determinados localmente no trabalho em si - e o contexto não é perdido. O estilo funcional está em vigor aqui, especialmente porque escrever um código de uma maneira diferente não funcionará. Mas no focinho da web, que deve enviar o resultado para o mundo exterior, e é um aplicativo da web comum da primavera, seria muito mais lógico formar um SQL SELECT padrão a partir de um formulário do usuário, no qual estaria cheio de AND e OR - ou seja, predicados , - na cláusula WHERE.
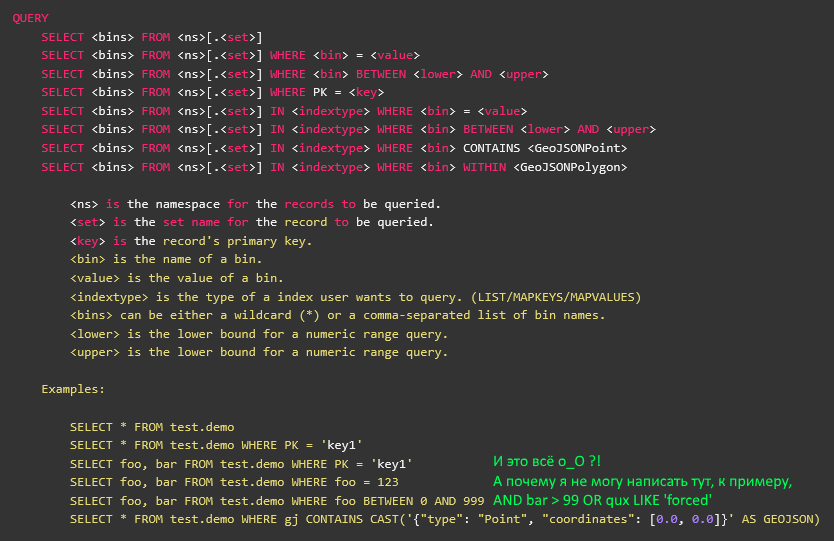
Vou explicar a diferença com um exemplo tão sintético:
SELECT foo, bar, baz, qux, quux FROM namespace.set WITH (baz!='a') WHERE (foo>2 AND (bar<=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)
- é legível e relativamente claro quais registros o cliente deseja receber. Se você lançar essa solicitação no log diretamente, ela poderá ser puxada posteriormente para depuração manualmente. O que é muito conveniente ao analisar todos os tipos de situações estranhas.
Agora, vejamos a chamada para a API predicada em um estilo funcional:
Statement reference = new Statement(); reference.setSetName("set"); reference.setNamespace("namespace"); reference.setBinNames("foo", "bar", "baz", "qux", "quux"); reference.setFillter(Filter.stringNotEqual("baz", "a")); reference.setPredExp(
Aqui está o muro do código, e mesmo na notação polonesa inversa . Não, eu entendo que a máquina de pilha é simples e conveniente para implementação do ponto de vista do programador do mecanismo, mas para confundir e escrever predicados no RPN a partir do aplicativo cliente ... Eu pessoalmente não quero pensar no fornecedor, quero-me como consumidor dessa API Foi conveniente. E predicados, mesmo com uma extensão de cliente do fornecedor (conceitualmente semelhante à API Java Persistence Criteria), é inconveniente para a gravação. E ainda não há SELECT legível no log de consulta.
Em geral, o SQL foi inventado para escrever consultas com base em critérios em uma linguagem de pássaro, quase natural. Então, alguém se pergunta, que diabos?
Espere, algo não está certo ... No KDPV, há uma captura de tela da documentação oficial do aerosoldering, na qual SELECT está completamente descrito?
Sim, descrito. Isso é apenas AQL - este é um utilitário de terceiros escrito pelo pé esquerdo traseiro em uma noite escura e abandonado pelo fornecedor há três anos durante a versão anterior do aero spike. Não tem nada a ver com a biblioteca cliente, embora esteja escrita em um sapo - inclusive.
A versão de três anos atrás não tinha uma API de predicado e, portanto, no AQL não há suporte para predicados, e tudo isso depois de WHERE é na verdade uma chamada para o índice (secundário ou primário). Bem, isto é, mais perto da extensão SQL como USE ou WITH. Ou seja, você não pode simplesmente pegar fontes AQL, desmontá-las em peças de reposição e usá-las em seu aplicativo para chamadas predicadas.
Além disso, como eu disse, foi escrito na noite escura com o pé esquerdo traseiro e é impossível olhar para a gramática ANTLR4, que o AQL analisa a consulta sem lágrimas. Bem, para o meu gosto. Por alguma razão, eu adoro quando a definição declarativa de gramática não é misturada com pedaços de código de sapos, e macarrão muito legal é produzido lá.
Felizmente, também pareço saber como fazer o ANTLR. É verdade que, durante muito tempo, não peguei um verificador e a última vez que o escrevi na terceira versão. Quarto - é muito melhor, porque quem quer escrever um tour manual do AST, se tudo foi escrito antes de nós, e se houver um visitante normal, então vamos começar.
Tomamos a sintaxe do SQLite como base e tentamos jogar fora tudo o que é desnecessário. Precisamos apenas de SELECT, e nada mais.
grammar SQLite; simple_select_stmt : ( K_WITH K_RECURSIVE? common_table_expression ( ',' common_table_expression )* )? select_core ( K_ORDER K_BY ordering_term ( ',' ordering_term )* )? ( K_LIMIT expr ( ( K_OFFSET | ',' ) expr )? )? ; select_core : K_SELECT ( K_DISTINCT | K_ALL )? result_column ( ',' result_column )* ( K_FROM ( table_or_subquery ( ',' table_or_subquery )* | join_clause ) )? ( K_WHERE expr )? ( K_GROUP K_BY expr ( ',' expr )* ( K_HAVING expr )? )? | K_VALUES '(' expr ( ',' expr )* ')' ( ',' '(' expr ( ',' expr )* ')' )* ; expr : literal_value | BIND_PARAMETER | ( ( database_name '.' )? table_name '.' )? column_name | unary_operator expr | expr '||' expr | expr ( '*' | '/' | '%' ) expr | expr ( '+' | '-' ) expr | expr ( '<<' | '>>' | '&' | '|' ) expr | expr ( '<' | '<=' | '>' | '>=' ) expr | expr ( '=' | '==' | '!=' | '<>' | K_IS | K_IS K_NOT | K_IN | K_LIKE | K_GLOB | K_MATCH | K_REGEXP ) expr | expr K_AND expr | expr K_OR expr | function_name '(' ( K_DISTINCT? expr ( ',' expr )* | '*' )? ')' | '(' expr ')' | K_CAST '(' expr K_AS type_name ')' | expr K_COLLATE collation_name | expr K_NOT? ( K_LIKE | K_GLOB | K_REGEXP | K_MATCH ) expr ( K_ESCAPE expr )? | expr ( K_ISNULL | K_NOTNULL | K_NOT K_NULL ) | expr K_IS K_NOT? expr | expr K_NOT? K_BETWEEN expr K_AND expr | expr K_NOT? K_IN ( '(' ( select_stmt | expr ( ',' expr )* )? ')' | ( database_name '.' )? table_name ) | ( ( K_NOT )? K_EXISTS )? '(' select_stmt ')' | K_CASE expr? ( K_WHEN expr K_THEN expr )+ ( K_ELSE expr )? K_END | raise_function ;
Hmm ... Tanta coisa para SELECT demais. E se for fácil livrar-se do excesso, há mais uma coisa ruim em relação à própria estrutura da solução alternativa resultante.
O objetivo final é converter na API de predicado com seu RPN e uma máquina de pilha implícita. E aqui o expr atômico não contribui de forma alguma para essa transformação, porque implica análise normal da esquerda para a direita. Sim e definido recursivamente.
Ou seja, podemos obter nosso exemplo sintético, mas ele será lido exatamente como está escrito, da esquerda para a direita:
(foo>2 (bar<=3 foo>5) quux _ '%force%') (qux _('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}')
Existem colchetes que determinam a prioridade da análise (o que significa que você precisa se movimentar para frente e para trás na pilha) e também alguns operadores se comportam como chamadas de função.
E precisamos desta sequência:
foo 2 > bar 3 <= foo 5 > quux ".*force.*" _ qux "{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}" _
Brr, lata, pobre cérebro para ler. Mas sem colchetes, não há reversões e mal-entendidos com a ordem da chamada. E como podemos traduzir um para o outro?
E então, em um cérebro ruim, acontece um choc! - Olá, este é um Shunting Yard clássico de muitos. prof. Dijkstra! Normalmente, xamãs okolobigdatovskih como eu não precisam de algoritmos, porque simplesmente transferimos os protótipos já escritos por satanistas de dados de python para o sapo e, em seguida, para um desempenho longo e tedioso da solução obtida por métodos puramente de engenharia (== xamanísticos), e não científicos .
Mas, de repente, tornou-se necessário conhecer o algoritmo. Ou pelo menos uma idéia disso. Felizmente, nem todos os cursos universitários foram esquecidos nos últimos anos e, como me lembro de máquinas empilhadas, também posso descobrir algo mais sobre os algoritmos associados.
Ok Em uma gramática aprimorada pelo Shunting Yard, um SELECT no nível superior seria assim:
select_stmt : K_SELECT ( STAR | column_name ( COMMA column_name )* ) ( K_FROM from_set )? ( (K_USE | K_WITH) index_expr )? ( K_WHERE where_expr )? ; where_expr : ( atomic_expr | OPEN_PAR | CLOSE_PAR | logic_op )+ ; logic_op : K_NOT | K_AND | K_OR ; atomic_expr : column_name ( equality_op | regex_op ) STRING_LITERAL | ( column_name | meta_name ) ( equality_op | comparison_op ) NUMERIC_LITERAL | column_name map_op iter_expr | column_name list_op iter_expr | column_name geo_op cast_expr ;
Ou seja, os tokens correspondentes aos colchetes são significativos e não deve haver uma expr recursiva. Em vez disso, haverá um monte de todos os private_expr e todos são finitos.
No código do sapo, que implementa o visitante para essa árvore, as coisas são um pouco mais viciantes - em estrita conformidade com o algoritmo, que por si só processa a lógica pendente_op e equilibra os colchetes. Não darei um trecho ( veja você mesmo o GC ), mas darei a seguinte consideração.
Torna-se claro por que os autores do aero spike não se incomodaram com o suporte de predicado no AQL e o abandonaram há três anos. Porque é estritamente digitado, e o próprio pico aéreo é apresentado como uma história sem esquema. E, portanto, é impossível pegar e estripar uma consulta do SQL sem um esquema predeterminado. Opa
Mas nós somos chamuscados e, mais importante, arrogantes. Precisamos de um esquema com tipos de campos, para que haja um esquema com tipos de campos. Além disso, a biblioteca do cliente já possui todas as definições necessárias, elas apenas precisam ser coletadas. Embora eu tenha que escrever muito código para cada tipo (veja o mesmo link, da linha 56).
Agora inicialize ...
final HashMap FOO_BAR_BAZ = new HashMap() {{ put("namespace.set0", new HashMap() {{ put("foo", ParticleType.INTEGER); put("bar", ParticleType.DOUBLE); put("baz", ParticleType.STRING); put("qux", ParticleType.GEOJSON); put("quux", ParticleType.STRING); put("quuux", ParticleType.LIST); put("corge", ParticleType.MAP); put("corge.uier", ParticleType.INTEGER); }}); put("namespace.set1", new HashMap() {{ put("grault", ParticleType.INTEGER); put("garply", ParticleType.STRING); }}); }}; AQLSelectEx selectEx = AQLSelectEx.forSchema(FOO_BAR_BAZ);
... e pronto, agora nossa consulta sintética se destaca de maneira simples e clara da aerossoldagem:
Statement statement = selectEx.fromString("SELECT foo,bar,baz,qux,quux FROM namespace.set WITH (baz='a') WHERE (foo>2 AND (bar <=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)");
E para converter o formulário do focinho da web para o próprio pedido, pegamos uma tonelada de código escrito há muito tempo no focinho da web ... quando finalmente chega ao projeto, caso contrário, o cliente o colocou na prateleira por enquanto. É uma pena, caramba, eu passei quase uma semana.
Espero ter gastado com benefícios, e a biblioteca AQLSelectEx seja útil para alguém, e a abordagem em si será um tutorial um pouco mais realista do que outros artigos do hub que lidam com a ANTLR.